
Note de l'auteur : Analyse détaillée de la prise en charge des PDF par les API des grands modèles de langage (GPT-4o, Claude, Gemini, DeepSeek, etc.), ainsi que trois solutions de traitement : extraction textuelle, compréhension d'images et traitement côté client.
« Est-il possible d'envoyer directement un PDF à l'API d'un grand modèle de langage ? » C'est l'une des questions les plus fréquentes chez les développeurs. La réponse est plus nuancée qu'il n'y paraît : certains modèles prennent nativement en charge les PDF (Claude, Gemini, GPT-4o), tandis que d'autres, comme DeepSeek, ne le font pas encore. De plus, le coût en jetons (tokens) pour une prise en charge native est nettement plus élevé que celui d'une solution d'extraction textuelle.
Dans cet article, nous examinerons la situation actuelle de la prise en charge des PDF par les principales API de grands modèles de langage, du point de vue du développement. Nous comparerons également 3 solutions de traitement de PDF avec des exemples de code, afin de vous aider à choisir la méthode la plus adaptée à vos besoins.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez parfaitement le niveau de prise en charge des PDF par chaque modèle et maîtriserez trois approches, de la plus économique à la plus simple.

Points clés sur la prise en charge des PDF par les API des grands modèles de langage
| Point clé | Description | Valeur |
|---|---|---|
| 3 acteurs avec support natif | Claude (600 pages), Gemini (1000 pages), GPT-4o (100 pages) sont compatibles | Pas de prétraitement, envoi direct via API |
| DeepSeek et autres non supportés | Nécessite une extraction textuelle ou une conversion en image en amont | Nécessite la mise en place d'un flux de prétraitement |
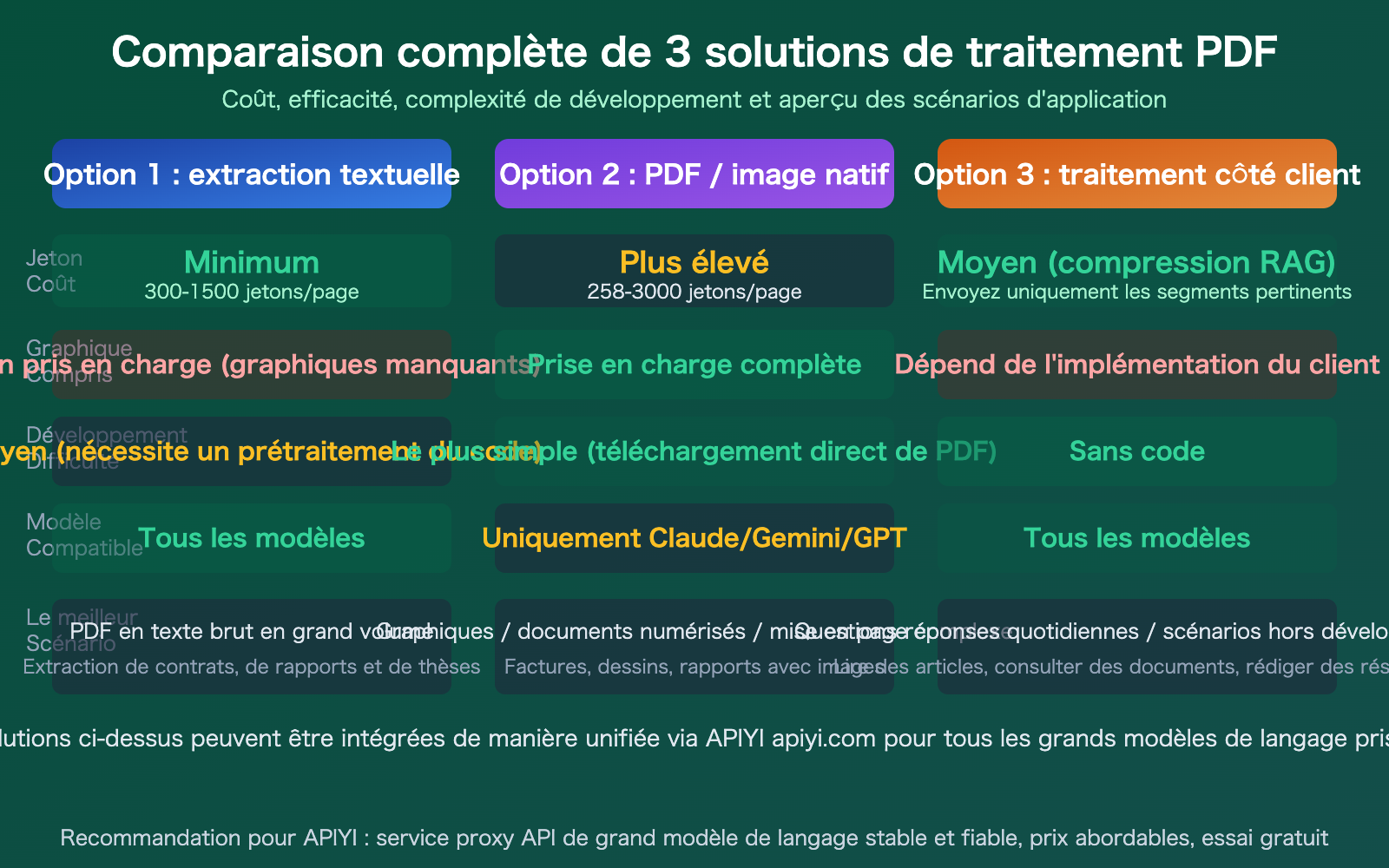
| Coûts très variables | PDF natif : 258-3000 tokens/page ; extraction texte pur : 300-1500 | Choisir la bonne méthode permet d'économiser jusqu'à 10x |
| 3 approches selon les besoins | Extraction texte, compréhension d'image, traitement client | Choisissez selon votre cas d'usage, pas de solution unique |
État actuel du support natif des PDF par les API
La bonne nouvelle est que, depuis 2025, les principaux grands modèles de langage prennent en charge l'envoi direct de PDF via API. Leur méthode est globalement identique : ils extraient le texte du PDF tout en rendant chaque page sous forme d'image, permettant au modèle de comprendre à la fois le contenu textuel et les éléments visuels (graphiques, mise en page, etc.).
La mauvaise nouvelle est que ce traitement "double canal texte + image" consomme beaucoup plus de tokens qu'une simple entrée textuelle. Un rapport de 50 pages transmis directement en PDF peut consommer plus de 100 000 tokens, alors qu'une extraction préalable du texte pourrait réduire ce chiffre à 30 000 tokens.
Comparaison détaillée du support PDF par API
| Modèle | Support PDF | Nb pages max | Fichier max | Mode de transfert | Coût tokens/page |
|---|---|---|---|---|---|
| Claude | Oui (GA) | 600 pages | 32 Mo | Base64 / URL / Files API | 1500-3000 |
| Gemini | Oui | 1000 pages | 2 Go (Files API) | Inline / Files API / URL | ~258 (le moins cher) |
| GPT-4o | Oui | 100 pages | 32 Mo | Base64 / File Upload | ~765 (image) + texte |
| DeepSeek | Non | — | — | Prétraitement requis | — |
| Llama / Qwen | Non | — | — | Prétraitement requis | — |
🎯 Conseil de sélection : Si vous devez traiter de gros volumes de PDF, Gemini est le plus économique (environ 258 tokens par page, extraction de texte native gratuite). Pour les documents très longs, Gemini reste également le plus performant (1000 pages). Claude excelle en précision de compréhension, idéal pour des scénarios exigeants. Tous ces modèles peuvent être appelés de manière centralisée via la plateforme APIYI apiyi.com.
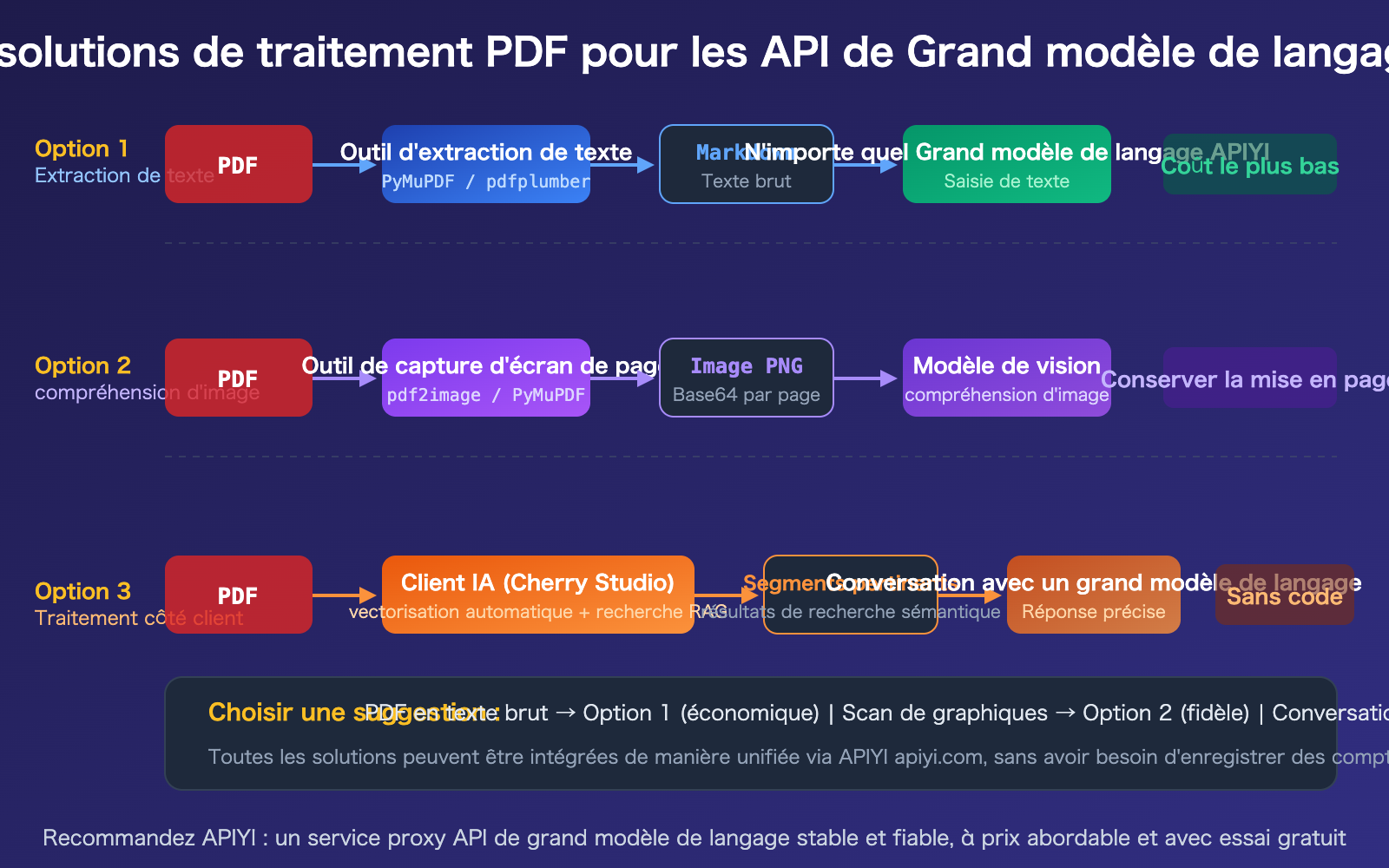
Solution 1 de traitement de PDF par API de Grand modèle de langage : Extraction textuelle
C'est la solution la plus polyvalente et la plus économique. Il suffit d'utiliser une bibliothèque Python pour extraire le PDF en Markdown ou en texte brut, puis de transmettre ce texte en tant qu'invite à n'importe quelle API de Grand modèle de langage.
Comparaison des outils d'extraction textuelle de PDF
| Outil | Vitesse | Scénario idéal | Caractéristiques |
|---|---|---|---|
| PyMuPDF4LLM | ~0,14s/doc | Texte général + extraction de tableaux | Meilleur équilibre vitesse/qualité, sortie Markdown |
| pdfplumber | Moyen | Extraction de données tabulaires | Extraction de tableaux par coordonnées, haute précision |
| Marker-PDF | ~11s/doc | Conversion fidèle de mises en page complexes | Meilleure conservation de la structure, mais plus lent |
| PyPDF2 | Rapide | PDF avec texte simple | Léger, adapté à l'extraction de texte de base |
Exemple de code pour l'extraction textuelle de PDF
import pymupdf4llm
import openai
# Étape 1 : Conversion du PDF en Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Étape 2 : Transmission à l'API du Grand modèle de langage
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Veuillez résumer les points clés de ce rapport :\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Voir le code complet pour le traitement de PDF avec images (approche par compréhension d’image)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""Convertit chaque page du PDF en image Base64"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# Conversion PDF en images
images = pdf_pages_to_images("report.pdf")
# Construction du message multi-images
content = [{"type": "text", "text": "Veuillez analyser les graphiques et les données de ce document PDF :"}]
for img_b64 in images[:10]: # Attention à limiter le nombre de pages pour éviter de dépasser la fenêtre de contexte
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
Conseil : La méthode d'extraction textuelle est compatible avec tous les Grands modèles de langage (y compris DeepSeek, Llama, etc., qui ne supportent pas nativement les PDF). Grâce à APIYI (apiyi.com), vous pouvez utiliser la même clé API pour tester n'importe quel modèle.
Solution 2 de traitement de PDF par API de Grand modèle de langage : Entrée PDF native
Si vous utilisez Claude, Gemini ou GPT-4o, vous pouvez transmettre le PDF directement via l'API, sans aucune prétraitement.
Exemple d'entrée PDF native pour l'API Claude
import anthropic
import base64
client = anthropic.Anthropic(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com" # Utiliser le domaine racine pour Claude
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "Veuillez résumer les points clés de ce document"}
]
}]
)
print(message.content[0].text)
Exemple d'entrée PDF native pour l'API Gemini
from google import genai
client = genai.Client(
api_key="VOTRE_CLE_API",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"Veuillez résumer les points clés de ce document"
]
)
print(response.text)
🎯 Rappel sur les coûts : Bien que l'entrée PDF native soit la plus pratique, le coût en jetons (tokens) est nettement plus élevé que pour une solution textuelle. Prenons l'exemple d'un PDF de 50 pages : Gemini consomme environ 12 900 jetons (le moins cher), Claude environ 75 000 à 150 000 jetons, et GPT-4o plus de 40 000 jetons. Pour les scénarios à gros volume, assurez-vous d'évaluer les coûts ; nous vous recommandons de surveiller votre consommation via les outils de statistiques d'APIYI (apiyi.com).
Solution de traitement PDF par API pour grands modèles : approche client
Pour les conversations quotidiennes (hors développement de code), l'utilisation d'un client IA est la méthode la plus simple. Prenons l'exemple de Cherry Studio : il permet de glisser-déposer directement des fichiers PDF, gère automatiquement la vectorisation et la recherche sémantique, et n'envoie que les extraits pertinents au grand modèle de langage.
Avantages de la solution client
- Zéro code : glissez un PDF et commencez à discuter.
- Économie de jetons (Token) : grâce à la recherche RAG, seuls les segments pertinents sont envoyés, et non le document complet.
- Commutation multi-modèles : permet de configurer plusieurs plateformes d'API, dont APIYI.
- Base de connaissances locale : possibilité de créer une base de connaissances à partir de plusieurs PDF pour des requêtes répétées.
Points d'attention pour le traitement de PDF via client
- Contrôle de la taille des fichiers : un nombre trop élevé de pages dans un PDF peut entraîner un temps de vectorisation excessif.
- Attention aux coûts en jetons : bien que le RAG compresse le contenu, les documents longs peuvent tout de même générer des coûts élevés.
- Choix du modèle adapté : utilisez un modèle économique (comme GPT-4o-mini) pour des questions-réponses simples, et un modèle phare pour des analyses complexes.
Conseil : Configurez APIYI (apiyi.com) comme fournisseur d'API dans des clients comme Cherry Studio pour accéder à tous les modèles (Claude, Gemini, GPT, etc.) avec une seule clé API.
FAQ
Q1 : Quelle méthode utiliser pour traiter des PDF avec DeepSeek ?
L'API DeepSeek ne prend pas en charge l'entrée directe de fichiers PDF pour le moment. Nous recommandons la solution 1 (extraction textuelle) : convertissez d'abord le PDF en texte Markdown à l'aide de PyMuPDF4LLM, puis utilisez l'APIYI apiyi.com pour appeler l'API DeepSeek afin d'effectuer l'analyse. Si le PDF contient des graphiques, vous pouvez convertir les pages en images et utiliser un modèle prenant en charge la vision (comme GPT-4o) pour les interpréter.
Q2 : Quelle est la meilleure option entre l’entrée PDF native et l’extraction textuelle ?
Tout dépend du contenu du PDF. Pour les PDF contenant uniquement du texte (contrats, rapports), les deux méthodes offrent des résultats similaires, mais l'extraction textuelle est plus économique. Pour les PDF contenant des graphiques, des mises en page complexes ou des documents numérisés, l'entrée native est nettement plus performante, car le modèle peut comprendre simultanément le texte et les éléments visuels. Nous vous conseillons de tester d'abord la solution textuelle et de passer à l'entrée native si les résultats ne sont pas satisfaisants.
Q3 : Comment contrôler les coûts en tokens lors du traitement de PDF ?
Voici quelques astuces pratiques :
- Pour les gros volumes, privilégiez Gemini (seulement 258 tokens par page, le coût le plus bas).
- N'extrayez que les pages nécessaires au lieu de transmettre tout le document d'un coup.
- Après l'extraction textuelle, effectuez un résumé ou un découpage pour éviter de transmettre des textes trop longs.
- Surveillez votre consommation réelle via le tableau de bord d'APIYI apiyi.com.
Conclusion
Les points clés concernant la prise en charge des PDF par les API des grands modèles de langage :
- Prise en charge native par certains modèles : Claude (600 pages), Gemini (1000 pages) et GPT-4o (100 pages) acceptent les PDF directement, contrairement à DeepSeek qui ne le permet pas encore.
- Trois solutions selon vos besoins : L'extraction textuelle est la moins coûteuse et compatible avec tous les modèles, l'entrée native est la plus pratique mais plus onéreuse, et le traitement côté client est idéal pour les conversations quotidiennes.
- Différences de coûts significatives : Pour un même PDF, l'entrée native via Gemini est la plus économique (~258 tokens/page), tandis que la solution d'extraction textuelle peut réduire les coûts de plus de 50 % supplémentaires.
En choisissant la bonne solution pour votre cas d'usage, vous pourrez traiter efficacement vos PDF sans craindre des factures de tokens exorbitantes.
Nous vous recommandons d'utiliser APIYI apiyi.com pour accéder de manière centralisée aux différents modèles. La plateforme offre un crédit gratuit et prend en charge l'invocation du modèle pour tous les principaux services, incluant Claude, Gemini, GPT et DeepSeek.
📚 Références
-
Guide d'entrée PDF d'OpenAI: Documentation officielle pour l'envoi direct de PDF via API
- Lien :
platform.openai.com/docs/guides/pdf-files - Description : Spécifications détaillées et limites pour l'entrée PDF avec GPT-4o
- Lien :
-
Documentation du support PDF de Claude: Guide officiel d'Anthropic sur le traitement des PDF
- Lien :
docs.anthropic.com/en/docs/build-with-claude/pdf-support - Description : 3 méthodes et bonnes pratiques pour l'entrée PDF avec Claude
- Lien :
-
Traitement de documents avec Gemini: Explications de Google sur les capacités de compréhension documentaire
- Lien :
ai.google.dev/gemini-api/docs/document-processing - Description : Limites et tarification du traitement PDF par Gemini
- Lien :
-
Documentation PyMuPDF4LLM: Outil d'extraction de texte pour PDF
- Lien :
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Description : L'outil le plus rapide pour convertir des PDF en Markdown
- Lien :
-
Documentation de la plateforme APIYI: Accès unifié aux API des principaux modèles
- Lien :
docs.apiyi.com - Description : Obtention de clé API, liste des modèles et exemples d'invocation du modèle
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans les commentaires. Pour plus de ressources, consultez le centre de documentation APIYI sur docs.apiyi.com.