
Nota del autor: Análisis detallado sobre el soporte de entrada de PDF en las API de Modelos de Lenguaje Grande como GPT-4o, Claude, Gemini y DeepSeek, además de tres soluciones de procesamiento: extracción de texto, comprensión de imágenes y gestión del lado del cliente.
"¿Puedo enviar un PDF directamente a la API de un Modelo de Lenguaje Grande?" Esta es una de las preguntas más frecuentes entre los desarrolladores. La respuesta es más compleja de lo que parece: algunos modelos ya tienen soporte nativo para PDF (Claude, Gemini, GPT-4o), mientras que otros como DeepSeek aún no lo tienen. Además, el costo en tokens del soporte nativo es significativamente más alto que el de las soluciones de extracción de texto.
En este artículo, analizaremos desde una perspectiva de desarrollo el estado actual del soporte de PDF en las principales API de modelos, y presentaremos una comparación completa junto con ejemplos de código de 3 soluciones de procesamiento de PDF, para ayudarte a elegir la que mejor se adapte a tu caso de uso.
Valor principal: Tras leer este artículo, entenderás el nivel de soporte de PDF de cada modelo y dominarás 3 soluciones de procesamiento, desde la más económica hasta la más sencilla.

Puntos clave sobre el soporte de entrada de PDF en las API de Modelos de Lenguaje Grandes
| Punto clave | Descripción | Valor |
|---|---|---|
| 3 modelos con soporte nativo | Claude (600 págs.), Gemini (1000 págs.), GPT-4o (100 págs.) ya lo soportan | Sin preprocesamiento, carga directa vía API |
| DeepSeek y otros aún no | Requieren extracción de texto previa o conversión a imagen | Necesitan flujo de preprocesamiento |
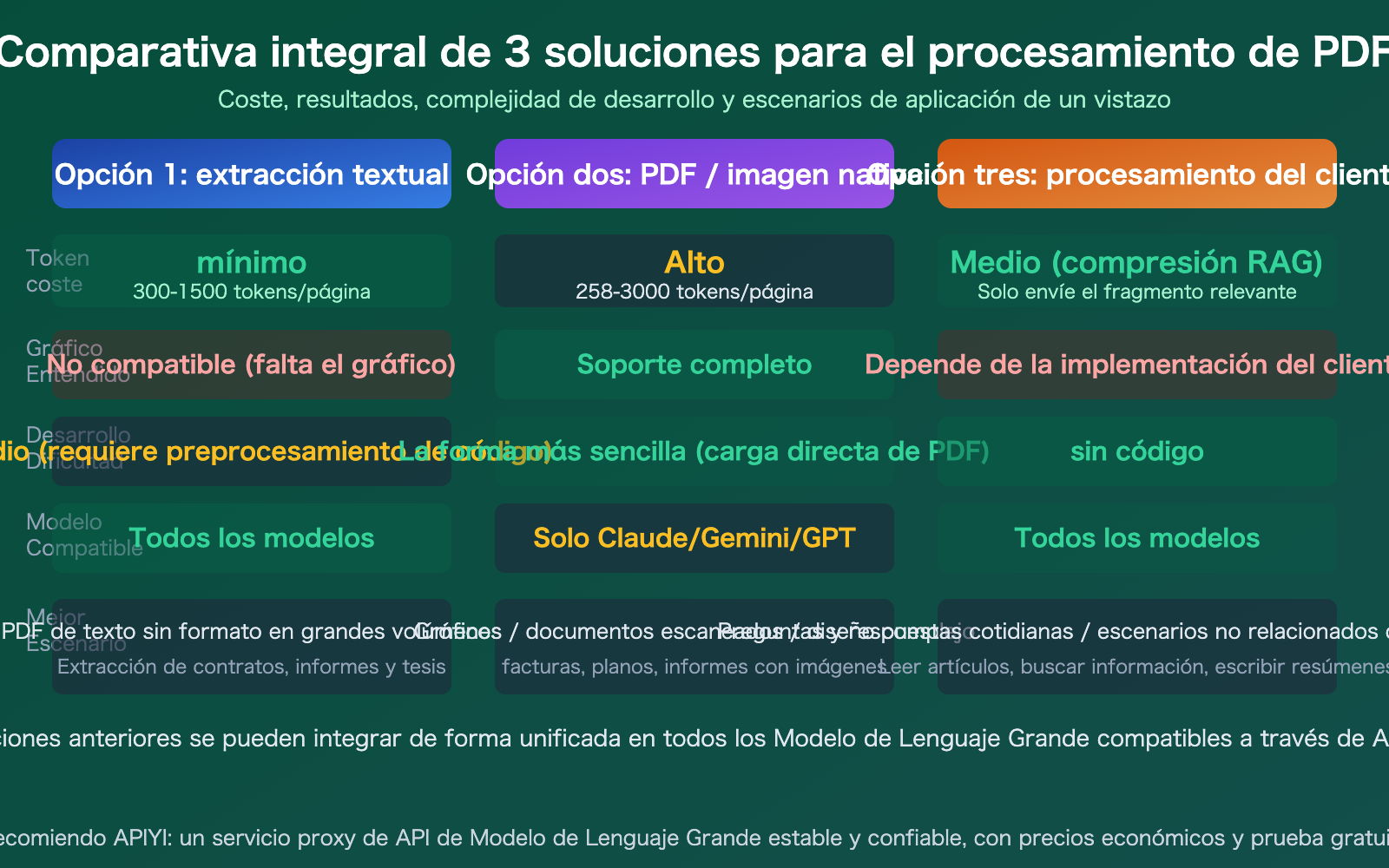
| Diferencias de coste enormes | El PDF nativo cuesta 258-3000 tokens/pág., la extracción de texto solo 300-1500 | Elegir la estrategia correcta ahorra hasta 10 veces en costes |
| 3 enfoques según el caso | Extracción de texto, comprensión de imagen, procesamiento en cliente | Elige según tus necesidades, no fuerces un solo método |
Estado actual del soporte nativo de PDF en las API de Modelos de Lenguaje Grandes
La buena noticia es que, desde 2025, los principales Modelos de Lenguaje Grandes han comenzado a soportar la carga directa de PDF a través de sus API. Su implementación es básicamente la misma: extraen el texto del PDF y, al mismo tiempo, renderizan cada página como una imagen, permitiendo que el modelo comprenda tanto el contenido textual como los elementos visuales (gráficos, diseño, maquetación, etc.).
La mala noticia es que este método de procesamiento de "doble canal texto + imagen" consume muchos más tokens que una entrada de texto puro. Si envías un informe de 50 páginas directamente como PDF, podrías consumir más de 100,000 tokens, mientras que si extraes el texto primero, podrías necesitar solo 30,000 tokens.
Comparativa detallada del soporte de PDF en las API de modelos
| Modelo | ¿Soporta PDF? | Máx. páginas | Archivo máx. | Método de transmisión | Coste en tokens por pág. |
|---|---|---|---|---|---|
| Claude | Sí (GA) | 600 págs. | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | Sí | 1000 págs. | 2 GB (Files API) | Inline / Files API / URL | ~258 (el más barato) |
| GPT-4o | Sí | 100 págs. | 32 MB | Base64 / Carga de archivo | ~765 (imagen) + texto |
| DeepSeek | No | — | — | Requiere preprocesamiento | — |
| Llama / Qwen | No | — | — | Requiere preprocesamiento | — |
🎯 Recomendación: Si necesitas procesar grandes volúmenes de PDF, Gemini es la opción más económica (aprox. 258 tokens por página, extracción de texto nativa gratuita). Si requieres soporte para documentos muy extensos, Gemini también es el más potente (1000 páginas). Claude destaca por su precisión de comprensión, ideal para escenarios de alta exigencia. Todos estos modelos pueden integrarse y utilizarse de forma unificada a través de la plataforma APIYI apiyi.com.
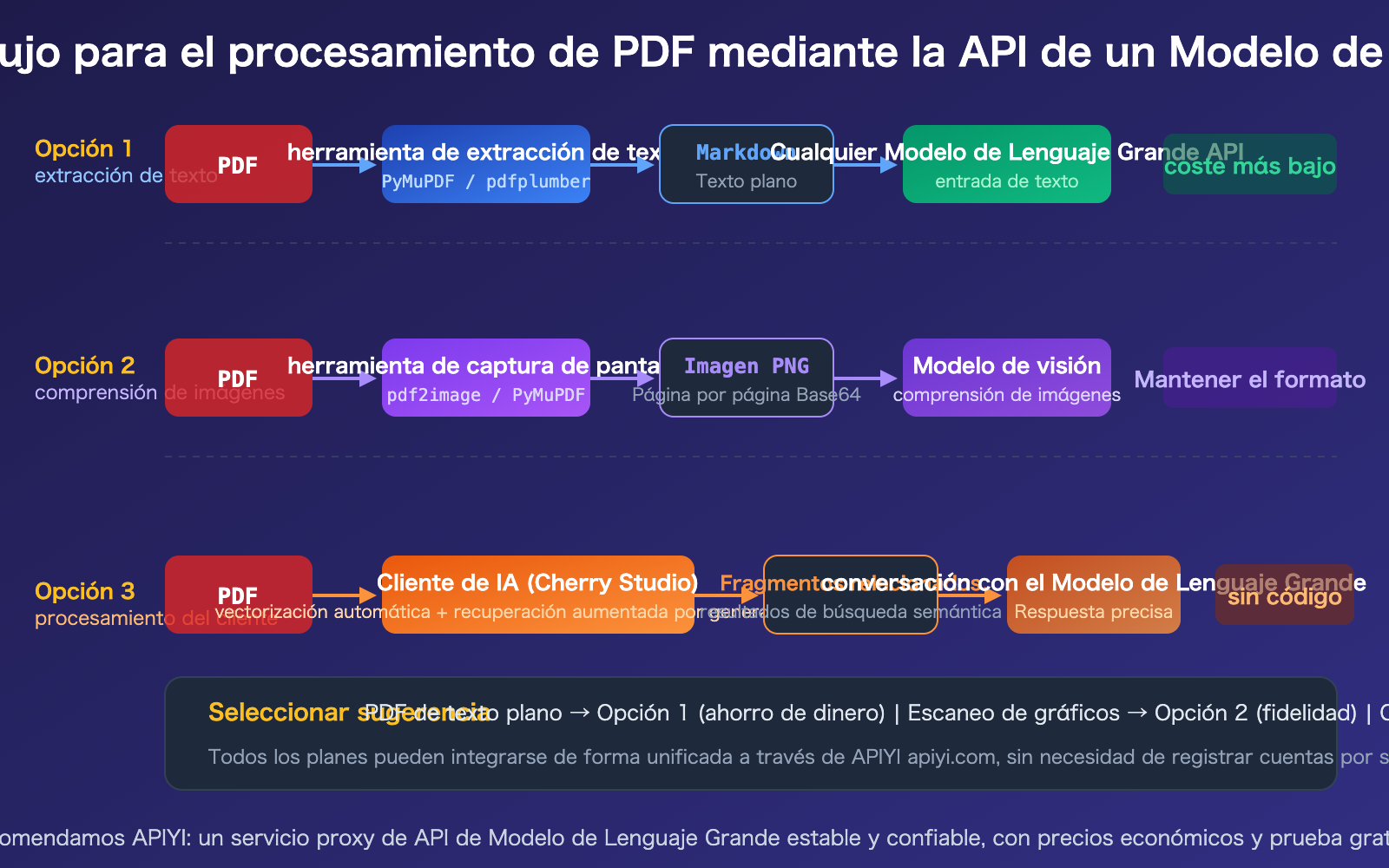
Solución 1 para el procesamiento de PDF con API de Modelos de Lenguaje Grande: Extracción de texto
Esta es la solución más común y económica. Primero, utilizamos una librería de Python para extraer el PDF a formato Markdown o texto plano, y luego enviamos ese texto como una indicación a cualquier API de Modelo de Lenguaje Grande.
Comparativa de herramientas para la extracción de texto de PDF
| Herramienta | Velocidad | Mejor escenario | Características |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/doc | Texto general + extracción de tablas | El mejor equilibrio entre velocidad y calidad, salida en Markdown |
| pdfplumber | Media | Extracción de datos tabulares | Extracción de tablas a nivel de coordenadas, alta precisión |
| Marker-PDF | ~11s/doc | Conversión fiel de diseños complejos | Conserva mejor la estructura, velocidad más lenta |
| PyPDF2 | Rápida | PDF de texto plano simple | Ligero, ideal para extracción de texto básica |
Ejemplo de código para la extracción de texto de PDF
import pymupdf4llm
import openai
# Paso 1: Convertir PDF a Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Paso 2: Enviar a la API del Modelo de Lenguaje Grande
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Por favor, resume los puntos clave de este informe:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Ver el código completo para el procesamiento de PDF con imágenes (solución de comprensión de imágenes)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""Convertir cada página de un PDF a una imagen Base64"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# Convertir PDF a imágenes
images = pdf_pages_to_images("report.pdf")
# Construir mensaje con múltiples imágenes
content = [{"type": "text", "text": "Por favor, analiza los gráficos y datos de este documento PDF:"}]
for img_b64 in images[:10]: # Nota: controla el número de páginas para evitar exceder los tokens
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
Sugerencia: La solución de extracción de texto es compatible con todos los Modelos de Lenguaje Grande (incluyendo DeepSeek, Llama, etc., que no soportan PDF nativamente). A través de APIYI (apiyi.com), puedes usar la misma clave API para probar cualquier modelo.
Solución 2 para el procesamiento de PDF con API de Modelos de Lenguaje Grande: Entrada nativa de PDF
Si utilizas Claude, Gemini o GPT-4o, puedes pasar el PDF directamente a través de la API sin necesidad de preprocesamiento.
Ejemplo de entrada nativa de PDF con la API de Claude
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Claude usa el dominio raíz
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "Por favor, resume los puntos clave de este documento"}
]
}]
)
print(message.content[0].text)
Ejemplo de entrada nativa de PDF con la API de Gemini
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"Por favor, resume los puntos clave de este documento"
]
)
print(response.text)
🎯 Recordatorio de costos: Aunque la entrada nativa de PDF es la más cómoda, el costo en tokens es significativamente mayor que en la solución de texto plano. Tomando como ejemplo un PDF de 50 páginas: Gemini consume aproximadamente 12,900 tokens (el más barato), Claude entre 75,000 y 150,000 tokens, y GPT-4o más de 40,000 tokens. En escenarios de gran volumen, asegúrate de evaluar los costos; se recomienda monitorear el consumo a través de la función de estadísticas de uso de APIYI (apiyi.com).
Solución 3 para el procesamiento de PDF con API de Modelos de Lenguaje Grande: Clientes de escritorio
Para escenarios de conversación diaria (fuera del desarrollo de código), utilizar un cliente de IA es la forma más sencilla. Tomando como ejemplo a Cherry Studio, este permite arrastrar y soltar archivos PDF directamente, completando automáticamente la vectorización y la recuperación semántica, enviando al Modelo de Lenguaje Grande solo los fragmentos relevantes.
Ventajas de la solución mediante cliente
- Sin código: Arrastra el PDF y comienza a conversar.
- Ahorro de tokens: Gracias a la recuperación RAG, solo se envían los fragmentos pertinentes en lugar del documento completo.
- Cambio entre modelos: Soporta la configuración de múltiples plataformas de API, incluyendo APIYI.
- Base de conocimientos local: Puedes crear una base de conocimientos con varios PDF y consultarlos repetidamente.
Consideraciones al procesar PDF mediante clientes
- Controla el tamaño del archivo: Un PDF con demasiadas páginas puede hacer que el tiempo de vectorización sea excesivo.
- Ten en cuenta los costos de tokens: Aunque el RAG comprime el contenido, los documentos extensos aún pueden generar costos elevados.
- Elige el modelo adecuado: Para preguntas y respuestas sencillas, usa modelos económicos (como GPT-4o-mini); para análisis complejos, utiliza modelos insignia.
Sugerencia: Configura APIYI (apiyi.com) como proveedor de API en clientes como Cherry Studio para acceder a todos los modelos, incluyendo Claude, Gemini y GPT, utilizando una sola clave API.
Preguntas frecuentes
P1: ¿Qué solución debería usar para procesar PDFs con DeepSeek?
La API de DeepSeek no admite actualmente la entrada directa de archivos PDF. Te recomiendo usar la solución 1 (extracción a texto): primero convierte el PDF a texto Markdown usando PyMuPDF4LLM y, luego, realiza la invocación del modelo a través de APIYI (apiyi.com) para analizarlo. Si el PDF contiene gráficos, puedes convertir las páginas en imágenes y utilizar un modelo con capacidades multimodales (como GPT-4o) para su interpretación.
P2: ¿Qué funciona mejor: la entrada nativa de PDF o la extracción a texto?
Depende del contenido del PDF. Para PDFs de solo texto (contratos, informes), los resultados son similares, pero la extracción a texto es más económica. Para PDFs con gráficos, diseños complejos o documentos escaneados, la entrada nativa funciona notablemente mejor, ya que el modelo puede comprender tanto el texto como los elementos visuales simultáneamente. Te sugiero probar primero con la extracción a texto y cambiar a la entrada nativa si los resultados no son suficientes.
P3: ¿Cómo controlar los costos de tokens al procesar PDFs?
Aquí tienes algunos consejos prácticos:
- Para escenarios de gran volumen, prioriza Gemini (solo 258 tokens por página, el costo más bajo).
- Extrae solo las páginas necesarias; no envíes el documento completo de una sola vez.
- Tras la extracción a texto, realiza resúmenes o segmentación para evitar enviar textos demasiado largos.
- Monitorea el consumo real a través del panel de uso de APIYI (apiyi.com).
Resumen
Puntos clave sobre el soporte de entrada de PDF en la API de Modelos de Lenguaje Grandes:
- Soporte nativo en algunos modelos: Claude (600 páginas), Gemini (1000 páginas) y GPT-4o (100 páginas) permiten enviar PDFs directamente, mientras que otros como DeepSeek aún no lo admiten.
- Elige la solución según tus necesidades: La extracción a texto tiene el costo más bajo y es compatible con todos los modelos; la entrada nativa es la más cómoda pero más costosa; y el procesamiento en cliente es ideal para conversaciones cotidianas.
- Diferencias de costos significativas: Para un mismo PDF, la entrada nativa de Gemini es la más económica (~258 tokens/página), y la solución de extracción de texto plano puede reducir los costos en más de un 50% adicional.
Al elegir la solución correcta según tu caso de uso, podrás procesar PDFs de manera eficiente sin preocuparte por costos elevados de tokens.
Te recomendamos integrar los principales modelos a través de APIYI (apiyi.com), una plataforma que ofrece cuotas gratuitas y soporte para la invocación del modelo de todas las opciones líderes, incluyendo Claude, Gemini, GPT y DeepSeek.
📚 Referencias
-
Guía de entrada de PDF de OpenAI: Documentación oficial para la carga directa de PDF vía API
- Enlace:
platform.openai.com/docs/guides/pdf-files - Descripción: Especificaciones detalladas y limitaciones para la entrada de PDF en GPT-4o
- Enlace:
-
Documentación de soporte de PDF de Claude: Guía oficial de Anthropic para el procesamiento de PDF
- Enlace:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - Descripción: 3 métodos y mejores prácticas para la entrada de PDF en Claude
- Enlace:
-
Procesamiento de documentos de Gemini: Explicación de las capacidades de comprensión de documentos de Google
- Enlace:
ai.google.dev/gemini-api/docs/document-processing - Descripción: Limitaciones y precios del procesamiento de PDF en Gemini
- Enlace:
-
Documentación de PyMuPDF4LLM: Herramienta de extracción de texto de PDF
- Enlace:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Descripción: La herramienta más rápida para convertir PDF a Markdown
- Enlace:
-
Documentación de la plataforma APIYI: Acceso unificado a las API de los principales modelos
- Enlace:
docs.apiyi.com - Descripción: Obtención de clave API, lista de modelos y ejemplos de invocación del modelo
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios; para más información, visita el centro de documentación de APIYI en docs.apiyi.com