
Nota do autor: Detalhamos o suporte a entrada de PDF em Modelos de Linguagem Grande como GPT-4o, Claude, Gemini e DeepSeek, além de três soluções de processamento: extração de texto, compreensão de imagem e processamento via cliente.
"É possível enviar um PDF diretamente para a API de um Modelo de Linguagem Grande?" Esta é uma das perguntas mais frequentes entre desenvolvedores. A resposta é mais complexa do que você imagina — alguns modelos já possuem suporte nativo para entrada de PDF (Claude, Gemini, GPT-4o), enquanto outros, como o DeepSeek, ainda não suportam. Além disso, o custo de Token do suporte nativo é significativamente mais alto do que o das soluções de extração de texto.
Neste artigo, partindo de uma perspectiva de desenvolvimento prático, vamos analisar o status atual do suporte a PDF nas principais APIs de modelos e apresentar uma comparação completa de 3 soluções de processamento de PDF, com exemplos de código, para ajudar você a escolher a abordagem ideal para o seu cenário.
Valor central: Ao terminar este artigo, você entenderá o nível de suporte de cada modelo a arquivos PDF e dominará 3 soluções de processamento, da mais econômica à mais prática.
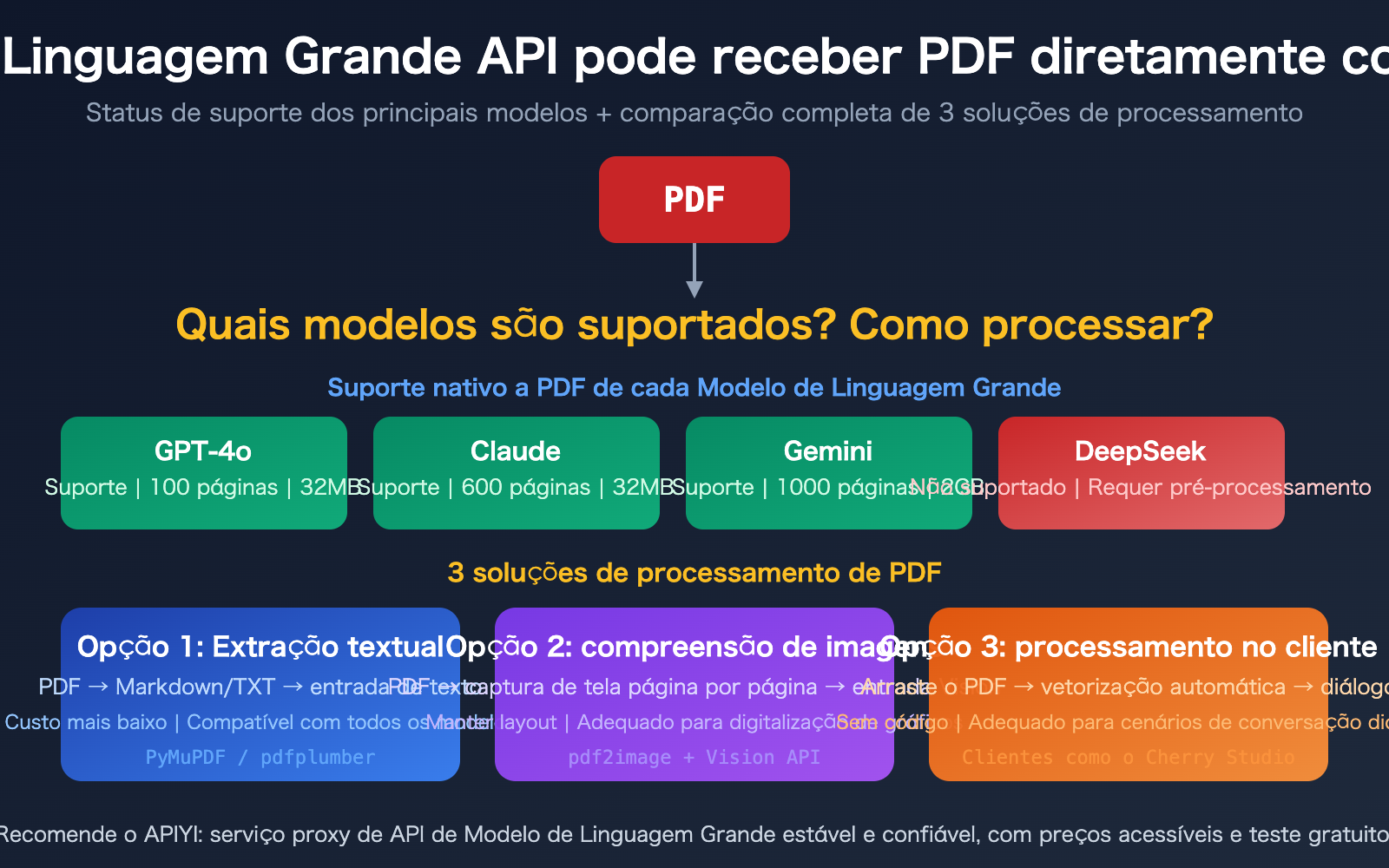
Pontos principais sobre o suporte a entrada de PDF em APIs de Modelos de Linguagem Grandes
| Ponto | Descrição | Valor |
|---|---|---|
| 3 modelos com suporte nativo a PDF | Claude (600 págs), Gemini (1000 págs), GPT-4o (100 págs) já suportam | Sem pré-processamento, envio direto via API |
| DeepSeek e outros ainda não suportam | Requer extração de texto ou conversão para imagem | Necessário criar fluxo de pré-processamento |
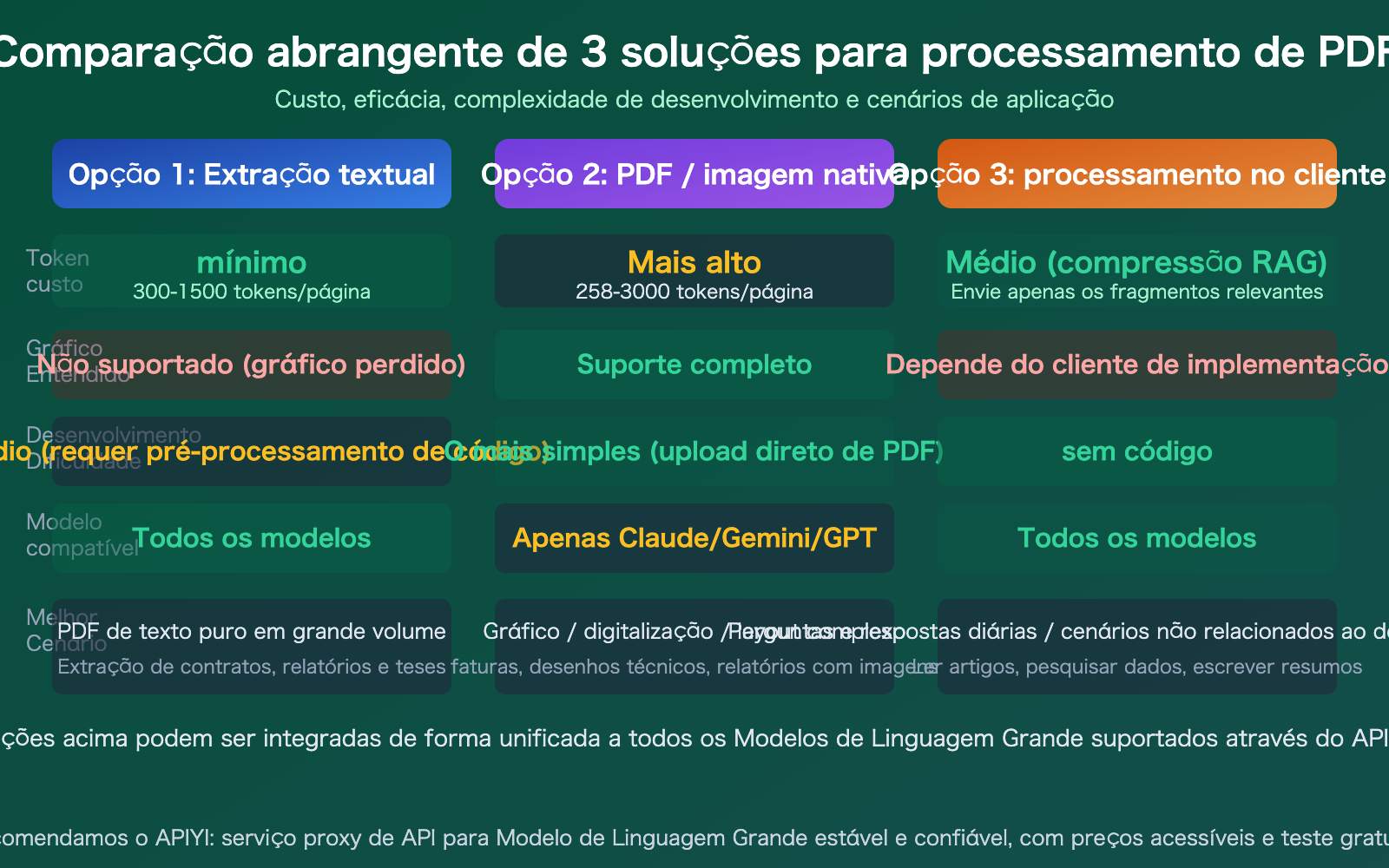
| Diferença de custo enorme | PDF nativo: 258-3000 tokens/pág; extração de texto: 300-1500 | Escolher a estratégia certa economiza até 10x em larga escala |
| 3 abordagens para diferentes cenários | Extração de texto, compreensão de imagem, processamento no cliente | Escolha conforme a necessidade, sem rigidez |
Status atual do suporte nativo a PDF em APIs de Modelos de Linguagem Grandes
A boa notícia é que, desde 2025, os principais Modelos de Linguagem Grandes passaram a suportar o envio direto de PDFs via API. A implementação é basicamente a mesma: extrair o texto do PDF e, simultaneamente, renderizar cada página como uma imagem, permitindo que o modelo compreenda tanto o conteúdo textual quanto elementos visuais (gráficos, layout, etc.).
A má notícia é que esse processamento de "canal duplo texto + imagem" consome muito mais tokens do que uma entrada de texto puro. Um relatório de 50 páginas enviado como PDF pode consumir mais de 100 mil tokens, enquanto a extração prévia do texto pode reduzir esse consumo para cerca de 30 mil tokens.
Comparativo detalhado de suporte a PDF em APIs
| Modelo | Suporta PDF | Máx. Páginas | Máx. Arquivo | Método de envio | Custo por pág (tokens) |
|---|---|---|---|---|---|
| Claude | Sim (GA) | 600 págs | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | Sim | 1000 págs | 2 GB (Files API) | Inline / Files API / URL | ~258 (mais barato) |
| GPT-4o | Sim | 100 págs | 32 MB | Base64 / Upload de arquivo | ~765 (imagem) + texto |
| DeepSeek | Não | — | — | Requer pré-processamento | — |
| Llama / Qwen | Não | — | — | Requer pré-processamento | — |
🎯 Dica de escolha: Se você precisa processar PDFs em grande volume, o Gemini oferece o menor custo (aprox. 258 tokens por página, com extração de texto nativa gratuita). Se precisar de suporte para documentos longos, o Gemini também é o mais robusto (1000 páginas). O Claude se destaca pela precisão na compreensão, sendo ideal para cenários de alta exigência. Todos esses modelos podem ser acessados de forma unificada através da plataforma APIYI (apiyi.com).
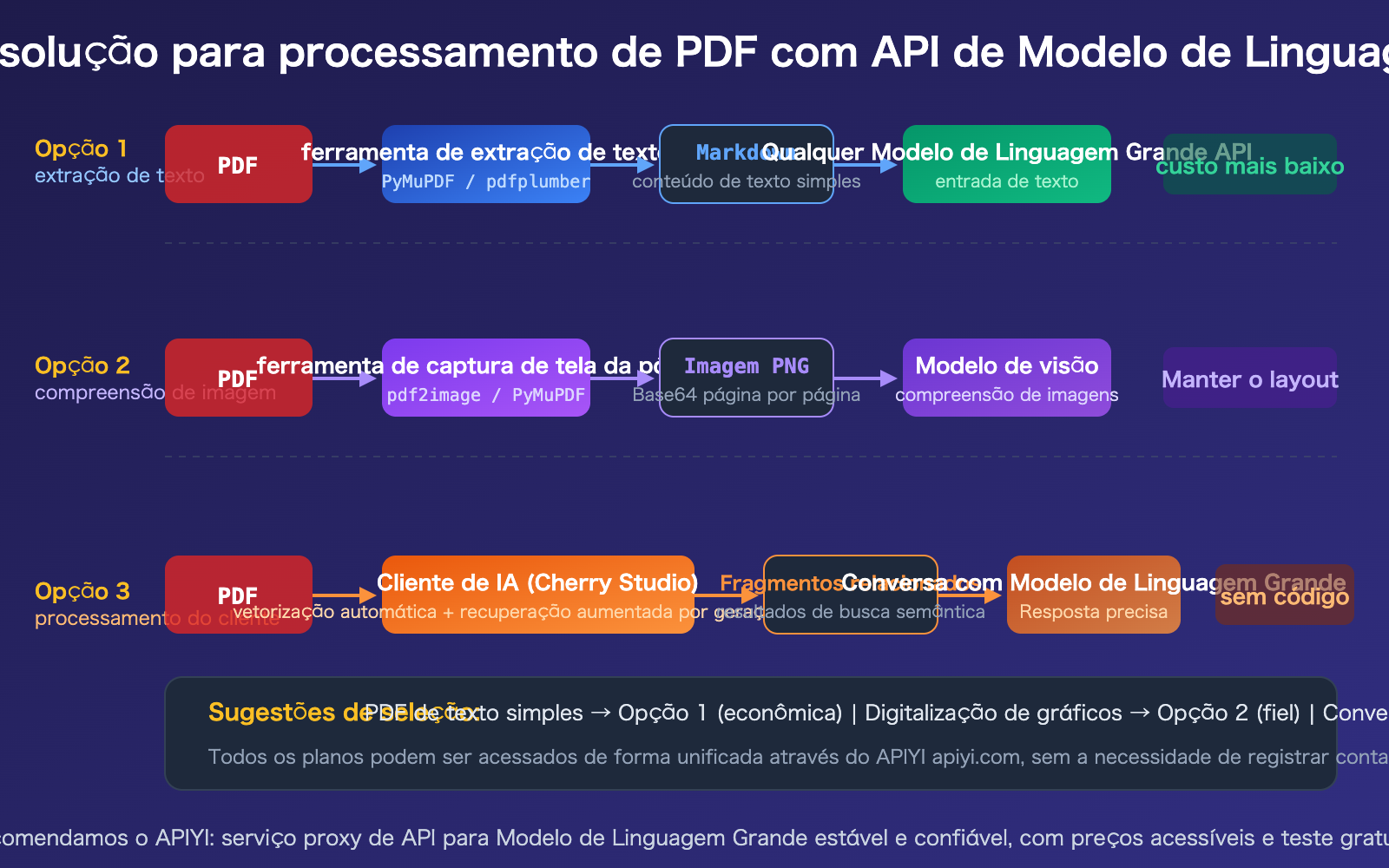
Solução 1 para processamento de PDF com API de Modelo de Linguagem Grande: Extração de texto
Esta é a solução mais comum e de menor custo. Primeiro, usamos uma biblioteca Python para extrair o PDF em formato Markdown ou texto puro e, em seguida, enviamos o texto como um comando para qualquer API de Modelo de Linguagem Grande.
Comparação de ferramentas de extração de texto de PDF
| Ferramenta | Velocidade | Melhor cenário | Características |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/doc | Texto geral + extração de tabelas | Melhor equilíbrio entre velocidade e qualidade, saída em Markdown |
| pdfplumber | Média | Extração de dados de tabelas | Extração de tabelas baseada em coordenadas, alta precisão |
| Marker-PDF | ~11s/doc | Conversão com fidelidade de layout complexo | Melhor preservação da estrutura, velocidade mais lenta |
| PyPDF2 | Rápida | PDFs de texto simples | Leve, ideal para extração de texto básica |
Exemplo de código para extração de texto de PDF
import pymupdf4llm
import openai
# Passo 1: Converter PDF para Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Passo 2: Enviar para a API do Modelo de Linguagem Grande
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Por favor, resuma os pontos principais deste relatório:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Ver código completo para processamento de PDF com imagens (solução de compreensão de imagem)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""Converte cada página do PDF em uma imagem Base64"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# Converter PDF para imagens
images = pdf_pages_to_images("report.pdf")
# Construir mensagem com múltiplas imagens
content = [{"type": "text", "text": "Por favor, analise os gráficos e dados neste documento PDF:"}]
for img_b64 in images[:10]: # Atenção ao controle de páginas para evitar excesso de tokens
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
Sugestão: A solução de extração de texto é compatível com todos os Modelos de Linguagem Grande (incluindo DeepSeek, Llama, etc., que não suportam PDF nativamente). Através da APIYI (apiyi.com), você pode usar a mesma chave API para testar qualquer modelo.
Solução 2 para processamento de PDF com API de Modelo de Linguagem Grande: Entrada nativa de PDF
Se você estiver usando Claude, Gemini ou GPT-4o, pode enviar o PDF diretamente via API, sem necessidade de pré-processamento.
Exemplo de entrada nativa de PDF com a API Claude
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Claude usa o domínio raiz
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "Por favor, resuma os pontos principais deste documento"}
]
}]
)
print(message.content[0].text)
Exemplo de entrada nativa de PDF com a API Gemini
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"Por favor, resuma os pontos principais deste documento"
]
)
print(response.text)
🎯 Lembrete de custo: Embora a entrada nativa de PDF seja a mais conveniente, o custo em tokens é significativamente maior do que a solução de texto puro. Tomando como exemplo um PDF de 50 páginas: o Gemini consome cerca de 12.900 tokens (o mais barato), o Claude cerca de 75.000-150.000 tokens e o GPT-4o cerca de 40.000+ tokens. Em cenários de grande volume, avalie os custos e utilize a função de estatísticas de uso da APIYI (apiyi.com) para monitorar o consumo.
Solução 3 para processamento de PDF com API de Modelos de Linguagem Grande: Uso de Clientes
Para cenários de conversação diária (que não envolvem desenvolvimento de código), usar um cliente de IA é a forma mais prática. Tomando o Cherry Studio como exemplo, ele permite arrastar e soltar anexos PDF diretamente, realizando automaticamente a vetorização e a recuperação semântica, enviando ao Modelo de Linguagem Grande apenas os trechos relevantes.
Vantagens da solução via cliente
- Zero código: Basta arrastar o PDF para começar a conversar.
- Economia de tokens: Através da recuperação RAG, apenas os trechos relevantes são enviados, e não o documento completo.
- Alternância entre modelos: Suporta a configuração de vários provedores de API, como a APIYI.
- Base de conhecimento local: É possível criar uma base de conhecimento com vários PDFs para consultas recorrentes.
Cuidados ao processar PDFs via cliente
- Controle o tamanho do arquivo: PDFs com muitas páginas podem tornar o tempo de vetorização excessivamente longo.
- Atenção aos custos de tokens: Embora o RAG comprima o conteúdo, documentos muito longos ainda podem gerar custos elevados.
- Escolha o modelo adequado: Use modelos mais baratos para perguntas e respostas simples (como o GPT-4o-mini) e modelos de ponta para análises complexas.
Sugestão: Configure a APIYI (apiyi.com) como provedor de API em clientes como o Cherry Studio para acessar todos os modelos, incluindo Claude, Gemini e GPT, usando uma única chave API.
Perguntas Frequentes
Q1: Qual é a melhor forma de processar PDFs com o DeepSeek?
A API do DeepSeek não suporta a entrada direta de arquivos PDF atualmente. Recomendamos a Opção 1 (extração de texto): primeiro, utilize o PyMuPDF4LLM para converter o PDF em texto Markdown e, em seguida, utilize o APIYI (apiyi.com) para realizar a invocação do modelo DeepSeek para análise. Se o PDF contiver gráficos, você pode converter as páginas em imagens e usar um modelo com suporte a visão (como o GPT-4o) para interpretá-las.
Q2: Qual funciona melhor: entrada nativa de PDF ou extração de texto?
Depende do conteúdo do PDF. Para PDFs de texto puro (contratos, relatórios), os resultados são semelhantes, sendo a extração de texto mais econômica. Para PDFs que contêm gráficos, layouts complexos ou documentos digitalizados, a entrada nativa funciona visivelmente melhor, pois o modelo consegue compreender elementos textuais e visuais simultaneamente. Sugerimos testar primeiro com a extração de texto e, caso o resultado não seja satisfatório, mudar para a entrada nativa.
Q3: Como controlar os custos de tokens no processamento de PDFs?
Algumas dicas práticas:
- Em cenários de grande volume, priorize o Gemini (apenas 258 tokens por página, o custo mais baixo).
- Extraia apenas as páginas necessárias; não envie o documento inteiro de uma só vez.
- Após a extração de texto, faça um resumo ou divida em blocos para evitar o envio de textos muito longos.
- Monitore o consumo real através do painel de uso do APIYI (apiyi.com).
Resumo
Pontos principais sobre o suporte à entrada de PDFs em APIs de Modelo de Linguagem Grande:
- Suporte nativo em alguns modelos: Claude (600 páginas), Gemini (1000 páginas) e GPT-4o (100 páginas) aceitam PDFs diretamente, enquanto o DeepSeek e outros ainda não suportam.
- Escolha entre 3 opções conforme a necessidade: A extração de texto tem o menor custo e é compatível com todos os modelos; a entrada nativa é a mais conveniente, porém mais cara; e o processamento via cliente é ideal para conversas cotidianas.
- Diferenças de custo significativas: Para o mesmo PDF, a entrada nativa do Gemini é a mais barata (~258 tokens/página), e a solução de extração de texto puro pode reduzir os custos em mais de 50%.
Escolhendo a estratégia certa para o seu cenário, você consegue processar PDFs com eficiência sem se assustar com custos elevados de tokens.
Recomendamos utilizar o APIYI (apiyi.com) para acessar de forma unificada os principais modelos. A plataforma oferece créditos gratuitos e suporta a invocação do modelo para todos os principais modelos do mercado, incluindo Claude, Gemini, GPT e DeepSeek.
📚 Referências
-
Guia de entrada de PDF da OpenAI: Documentação oficial para envio direto de PDF via API
- Link:
platform.openai.com/docs/guides/pdf-files - Descrição: Especificações detalhadas e limitações para entrada de PDF no GPT-4o
- Link:
-
Documentação de suporte a PDF do Claude: Guia oficial da Anthropic para processamento de PDF
- Link:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - Descrição: As 3 formas de entrada de PDF no Claude e melhores práticas
- Link:
-
Processamento de documentos no Gemini: Explicação oficial do Google sobre a capacidade de compreensão de documentos
- Link:
ai.google.dev/gemini-api/docs/document-processing - Descrição: Limitações e precificação do processamento de PDF no Gemini
- Link:
-
Documentação do PyMuPDF4LLM: Ferramenta de extração de texto de PDFs
- Link:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Descrição: A ferramenta mais rápida para converter PDF em Markdown
- Link:
-
Documentação da plataforma APIYI: Acesso unificado às APIs dos principais modelos
- Link:
docs.apiyi.com - Descrição: Obtenção de chave API, lista de modelos e exemplos de invocação do modelo
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, acesse a central de documentação da APIYI em docs.apiyi.com