
Catatan penulis: Penjelasan mendalam mengenai dukungan input PDF pada API Model Bahasa Besar seperti GPT-4o, Claude, Gemini, DeepSeek, serta tiga solusi pemrosesan: ekstraksi teks, pemahaman gambar, dan sisi klien.
"Bisakah API Model Bahasa Besar menerima file PDF secara langsung?" Ini adalah salah satu pertanyaan yang paling sering diajukan oleh pengembang. Jawabannya lebih rumit dari yang Anda bayangkan—beberapa model sudah mendukung input PDF secara native (Claude, Gemini, GPT-4o), namun model seperti DeepSeek belum mendukungnya, dan biaya Token untuk dukungan native jauh lebih mahal dibandingkan dengan solusi ekstraksi teks.
Artikel ini akan mengulas status dukungan PDF pada API model utama dari sudut pandang pengembangan praktis, serta memberikan perbandingan lengkap dan contoh kode untuk 3 solusi pemrosesan PDF, guna membantu Anda memilih metode yang paling sesuai untuk skenario Anda.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami tingkat dukungan setiap Model Bahasa Besar terhadap PDF, serta menguasai 3 solusi pemrosesan mulai dari yang paling hemat biaya hingga yang paling praktis.

Poin Utama Dukungan Input PDF pada API Model Bahasa Besar
| Poin Utama | Penjelasan | Nilai |
|---|---|---|
| 3 Model Mendukung PDF Native | Claude (600 hal), Gemini (1000 hal), GPT-4o (100 hal) sudah mendukung | Tanpa pra-pemrosesan, langsung kirim via API |
| DeepSeek dsb. Belum Mendukung | Perlu ekstraksi teks atau konversi gambar terlebih dahulu | Perlu membangun alur pra-pemrosesan |
| Perbedaan Biaya Signifikan | PDF native 258-3000 token/hal, ekstraksi teks murni hanya 300-1500 | Hemat biaya hingga 10x lipat dengan memilih skema yang tepat |
| 3 Skema untuk Skenario Berbeda | Ekstraksi teks, pemahaman gambar, pemrosesan klien | Pilih sesuai kebutuhan, tidak perlu memaksakan satu cara |
Status Dukungan Native PDF pada API Model Bahasa Besar
Kabar baiknya, sejak tahun 2025, model bahasa besar utama telah mulai mendukung pengiriman PDF langsung melalui API. Implementasinya pada dasarnya sama—mengekstrak teks dari PDF sekaligus merender setiap halaman menjadi gambar, sehingga model dapat memahami konten teks dan elemen visual (grafik, tata letak, dll.) secara bersamaan.
Kabar buruknya, metode pemrosesan "saluran ganda teks + gambar" ini mengonsumsi token jauh lebih tinggi daripada input teks murni. Laporan 50 halaman jika dikirim langsung sebagai PDF bisa menghabiskan 100.000+ token, sedangkan jika teks diekstrak terlebih dahulu, mungkin hanya memakan 30.000 token.
Perbandingan Detail Dukungan PDF API Model Bahasa Besar
| Model | Dukungan PDF | Halaman Maks | File Maks | Metode Transmisi | Biaya Token per Hal |
|---|---|---|---|---|---|
| Claude | Mendukung (GA) | 600 hal | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | Mendukung | 1000 hal | 2 GB (Files API) | Inline / Files API / URL | ~258 (Termurah) |
| GPT-4o | Mendukung | 100 hal | 32 MB | Base64 / File Upload | ~765 (Gambar) + Teks |
| DeepSeek | Tidak | — | — | Perlu pra-pemrosesan | — |
| Llama / Qwen | Tidak | — | — | Perlu pra-pemrosesan | — |
🎯 Saran Pemilihan: Jika Anda perlu memproses PDF dalam jumlah besar, Gemini adalah yang paling hemat biaya (sekitar 258 token per halaman, ekstraksi teks native gratis). Jika membutuhkan dukungan dokumen terpanjang, Gemini juga yang terkuat (1000 halaman). Claude unggul dalam akurasi pemahaman, cocok untuk skenario presisi tinggi. Semua model ini dapat diakses secara terpadu melalui platform APIYI apiyi.com.
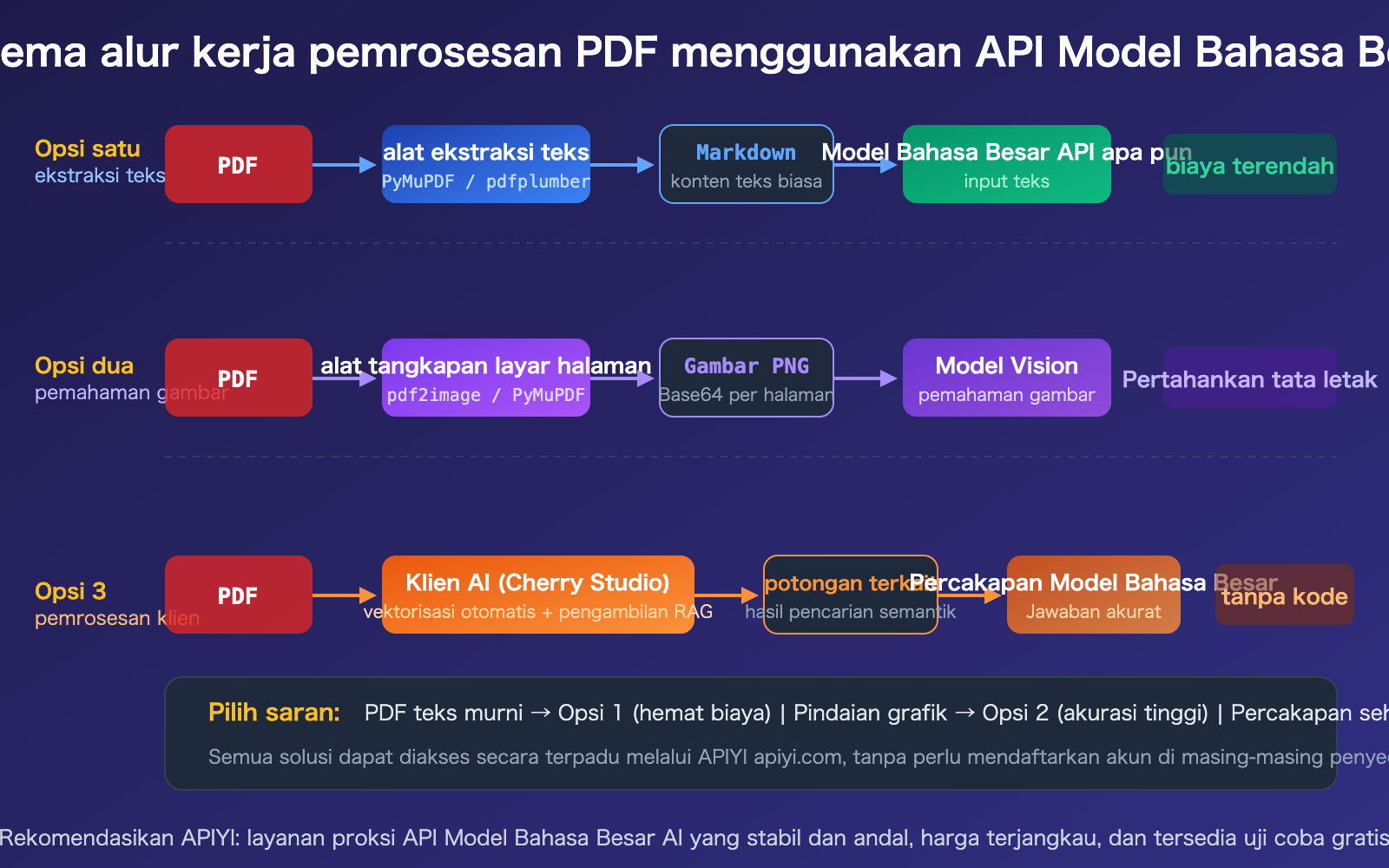
Solusi Pemrosesan PDF dengan API Model Bahasa Besar 1: Ekstraksi Teks
Ini adalah solusi yang paling umum dan hemat biaya. Pertama, gunakan pustaka Python untuk mengekstrak PDF menjadi Markdown atau teks biasa, lalu kirim teks tersebut sebagai petunjuk ke API Model Bahasa Besar mana pun.
Perbandingan Alat Ekstraksi Teks PDF
| Alat | Kecepatan | Skenario Terbaik | Fitur |
|---|---|---|---|
| PyMuPDF4LLM | ~0,14 dtk/dokumen | Teks umum + ekstraksi tabel | Keseimbangan terbaik antara kecepatan dan kualitas, output Markdown |
| pdfplumber | Sedang | Ekstraksi data tabel | Ekstraksi tabel berbasis koordinat, presisi tinggi |
| Marker-PDF | ~11 dtk/dokumen | Konversi tata letak kompleks | Retensi struktur terbaik, kecepatan lebih lambat |
| PyPDF2 | Cepat | PDF teks sederhana | Ringan, cocok untuk ekstraksi teks dasar |
Contoh Kode Ekstraksi Teks PDF
import pymupdf4llm
import openai
# Langkah 1: Konversi PDF ke Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Langkah 2: Kirim ke API Model Bahasa Besar
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Tolong rangkum poin-poin utama dari laporan ini:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Lihat kode lengkap untuk pemrosesan PDF dengan gambar (solusi pemahaman gambar)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""Mengonversi setiap halaman PDF menjadi gambar Base64"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# Konversi PDF ke gambar
images = pdf_pages_to_images("report.pdf")
# Membangun pesan multi-gambar
content = [{"type": "text", "text": "Tolong analisis grafik dan data dalam dokumen PDF ini:"}]
for img_b64 in images[:10]: # Perhatikan untuk membatasi jumlah halaman agar tidak melebihi batas token
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
Saran: Solusi ekstraksi teks kompatibel dengan semua Model Bahasa Besar (termasuk DeepSeek, Llama, dll., yang tidak mendukung PDF secara langsung). Melalui APIYI apiyi.com, Anda dapat menggunakan satu kunci API yang sama untuk menguji model apa pun.
Solusi Pemrosesan PDF dengan API Model Bahasa Besar 2: Input PDF Native
Jika Anda menggunakan Claude, Gemini, atau GPT-4o, Anda dapat langsung mengirimkan PDF melalui API tanpa perlu pra-pemrosesan apa pun.
Contoh Input PDF Native untuk Claude API
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Gunakan domain root untuk Claude
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "Tolong rangkum poin-poin utama dokumen ini"}
]
}]
)
print(message.content[0].text)
Contoh Input PDF Native untuk Gemini API
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"Tolong rangkum poin-poin utama dokumen ini"
]
)
print(response.text)
🎯 Catatan Biaya: Meskipun input PDF native adalah yang paling praktis, biaya tokennya jauh lebih tinggi daripada solusi teks biasa. Sebagai contoh, untuk PDF 50 halaman: Gemini menghabiskan sekitar 12.900 token (paling murah), Claude sekitar 75.000-150.000 token, dan GPT-4o sekitar 40.000+ token. Untuk skenario skala besar, pastikan untuk mengevaluasi biaya dan disarankan untuk memantau penggunaan melalui fitur statistik penggunaan di APIYI apiyi.com.
Solusi Pemrosesan PDF untuk Model Bahasa Besar API Bagian 3: Pemrosesan Klien
Untuk skenario percakapan sehari-hari (di luar pengembangan kode), menggunakan klien AI adalah cara yang paling praktis. Sebagai contoh, Cherry Studio mendukung fitur tarik-lepas (drag-and-drop) lampiran PDF secara langsung, yang secara otomatis melakukan vektorisasi dan pencarian semantik, sehingga hanya potongan teks yang relevan yang dikirim ke Model Bahasa Besar.
Keunggulan Solusi Klien
- Tanpa Kode: Cukup tarik dan lepas PDF untuk mulai mengobrol.
- Hemat Token: Melalui pencarian RAG, hanya potongan teks yang relevan yang dikirim, bukan keseluruhan dokumen.
- Peralihan Model: Mendukung konfigurasi berbagai platform API seperti APIYI.
- Basis Pengetahuan Lokal: Dapat menyusun beberapa file PDF menjadi basis pengetahuan untuk kueri berulang.
Hal yang Perlu Diperhatikan Saat Menggunakan Klien untuk PDF
- Kontrol Ukuran File: Terlalu banyak halaman PDF akan menyebabkan waktu vektorisasi menjadi terlalu lama.
- Perhatikan Biaya Token: Meskipun RAG akan memadatkan konten, dokumen yang panjang tetap dapat menghasilkan biaya yang cukup tinggi.
- Pilih Model yang Sesuai: Gunakan model yang lebih terjangkau untuk tanya jawab sederhana (seperti GPT-4o-mini), dan gunakan model unggulan untuk analisis yang kompleks.
Saran: Konfigurasikan APIYI apiyi.com sebagai penyedia API di klien seperti Cherry Studio, sehingga Anda dapat mengakses semua model seperti Claude, Gemini, dan GPT hanya dengan satu kunci API.

Pertanyaan Umum
Q1: Solusi apa yang sebaiknya digunakan untuk memproses PDF dengan DeepSeek?
API DeepSeek saat ini tidak mendukung input PDF secara langsung. Kami merekomendasikan solusi pertama (ekstraksi teks): gunakan PyMuPDF4LLM untuk mengubah PDF menjadi teks Markdown, lalu panggil API DeepSeek melalui APIYI apiyi.com untuk dianalisis. Jika PDF berisi grafik, Anda bisa mengubah halaman tersebut menjadi gambar terlebih dahulu, lalu gunakan model yang mendukung Vision (seperti GPT-4o) untuk memahaminya.
Q2: Mana yang lebih baik, input PDF asli atau ekstraksi teks?
Tergantung pada konten PDF Anda. Untuk PDF berbasis teks murni (kontrak, laporan), hasilnya hampir sama, namun ekstraksi teks jauh lebih hemat biaya. Untuk PDF yang berisi grafik, tata letak kompleks, atau hasil pindai (scan), input asli memberikan hasil yang jauh lebih baik karena model dapat memahami teks dan elemen visual secara bersamaan. Disarankan untuk mencoba metode ekstraksi teks terlebih dahulu, dan beralih ke input asli jika hasilnya kurang memuaskan.
Q3: Bagaimana cara mengontrol biaya token untuk pemrosesan PDF?
Berikut beberapa tips praktis:
- Untuk skenario volume besar, prioritaskan penggunaan Gemini (hanya 258 token per halaman, biaya paling rendah).
- Ekstrak hanya halaman yang diperlukan, jangan mengirim seluruh dokumen sekaligus.
- Setelah ekstraksi teks, lakukan ringkasan atau pembagian blok (chunking) terlebih dahulu untuk menghindari input teks yang terlalu panjang.
- Pantau konsumsi aktual melalui dasbor penggunaan di APIYI apiyi.com.
Kesimpulan
Poin utama mengenai dukungan input PDF pada API Model Bahasa Besar:
- Beberapa model sudah mendukung secara asli: Claude (600 halaman), Gemini (1000 halaman), dan GPT-4o (100 halaman) dapat menerima PDF secara langsung, sementara DeepSeek dan lainnya belum mendukung.
- Pilih dari 3 solusi sesuai kebutuhan: Ekstraksi teks memiliki biaya terendah dan kompatibel dengan semua model, input asli paling praktis namun lebih mahal, dan pemrosesan sisi klien cocok untuk percakapan sehari-hari.
- Perbedaan biaya yang signifikan: Untuk PDF yang sama, input asli Gemini adalah yang termurah (~258 token/halaman), sedangkan solusi ekstraksi teks murni dapat menekan biaya hingga 50% lebih hemat lagi.
Pilihlah solusi yang tepat sesuai skenario Anda agar dapat memproses PDF secara efisien tanpa khawatir dengan biaya token yang membengkak.
Kami merekomendasikan penggunaan APIYI apiyi.com untuk mengakses berbagai Model Bahasa Besar secara terpadu. Platform ini menyediakan kuota gratis dan mendukung pemanggilan API untuk semua model utama seperti Claude, Gemini, GPT, DeepSeek, dan lainnya.
📚 Referensi
-
Panduan Input PDF OpenAI: Dokumentasi resmi untuk pengiriman langsung PDF via API
- Tautan:
platform.openai.com/docs/guides/pdf-files - Penjelasan: Spesifikasi dan batasan detail untuk input PDF pada GPT-4o
- Tautan:
-
Dokumentasi Dukungan PDF Claude: Panduan resmi Anthropic untuk pemrosesan PDF
- Tautan:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - Penjelasan: 3 metode input PDF dan praktik terbaik untuk Claude
- Tautan:
-
Pemrosesan Dokumen Gemini: Penjelasan kemampuan pemahaman dokumen resmi Google
- Tautan:
ai.google.dev/gemini-api/docs/document-processing - Penjelasan: Batasan dan penetapan harga pemrosesan PDF pada Gemini
- Tautan:
-
Dokumentasi PyMuPDF4LLM: Alat ekstraksi teks PDF
- Tautan:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Penjelasan: Alat tercepat untuk konversi PDF ke Markdown
- Tautan:
-
Dokumentasi Platform APIYI: Akses terpadu ke API berbagai Model Bahasa Besar
- Tautan:
docs.apiyi.com - Penjelasan: Cara mendapatkan kunci API, daftar model, dan contoh pemanggilan model
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Mari berdiskusi di kolom komentar, untuk materi lebih lanjut silakan kunjungi pusat dokumentasi APIYI di docs.apiyi.com