
Note de l'auteur : Cet article explique en détail le fonctionnement réel de la segmentation d'images avec gpt-image-2, les processus de traitement backend en Python, les méthodes d'appel API et les stratégies d'optimisation des coûts. L'objectif est d'aider les développeurs à ne pas confondre les capacités natives du modèle avec celles de la chaîne d'outils.
Si vous avez utilisé gpt-image-2 récemment pour créer des affiches, des visuels scientifiques, des photos de produits ou des diapositives, vous avez peut-être remarqué un phénomène intéressant : certains prétendent qu'il peut "segmenter les images" ou même transformer une image en objets éditables via un traitement Python en arrière-plan.
À première vue, on pourrait croire que le modèle a soudainement appris à utiliser Photoshop, mais il s'agit en réalité d'un flux de travail multi-outils : gpt-image-2 se charge de générer ou d'éditer des images de haute qualité, tandis que des scripts Python gèrent la post-production (OCR, remplissage d'arrière-plan, segmentation d'éléments, reconstruction SVG/PPTX/PSD).
Ceci n'est pas une énième introduction pour débutants, mais une analyse complète sous l'angle des capacités API, des principes de calques, du post-traitement Python, du calcul des coûts et du déploiement technique pour comprendre ce que la segmentation d'images avec gpt-image-2 peut et ne peut pas faire.
Valeur ajoutée : Après avoir lu cet article, vous connaîtrez les limites de la segmentation d'images avec gpt-image-2, saurez comment intégrer l'API officielle via APIYI (apiyi.com) et concevoir un flux de travail "de la génération à l'édition" prêt pour la production.
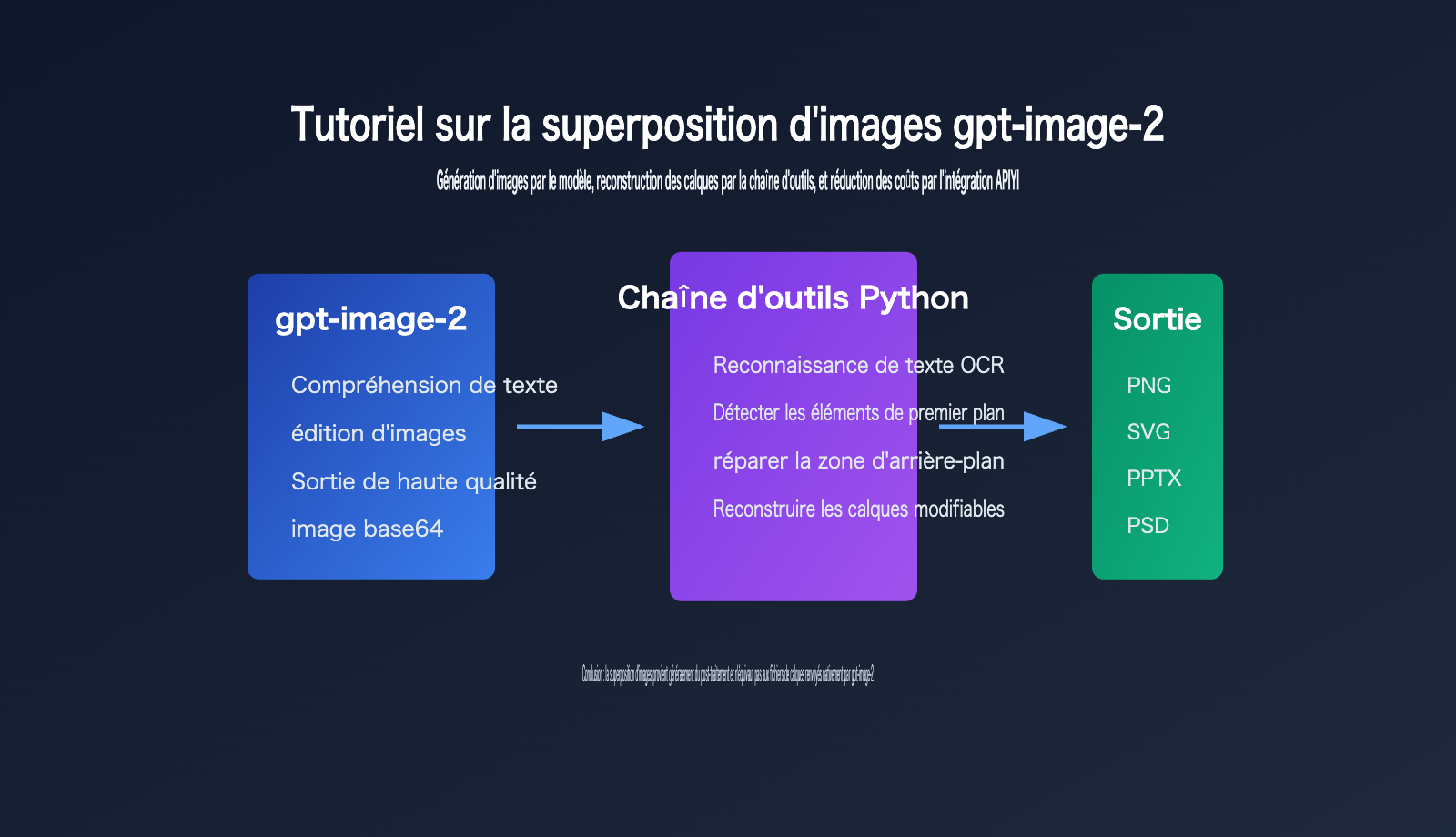
Points clés de la segmentation d'images avec gpt-image-2
La clé de la segmentation d'images avec gpt-image-2 réside dans la distinction entre la "sortie du modèle" et la "sortie du flux de travail produit".
La page officielle du modèle OpenAI définit gpt-image-2 comme un modèle d'image destiné à la génération et à l'édition rapides et de haute qualité, prenant en charge les entrées texte et image, et utilisable via les points de terminaison de génération et d'édition de l'API Images.
Cependant, au vu de l'API publique actuelle, le résultat principal obtenu par les développeurs reste des données d'image, et non des fichiers de projet multicouches de type Photoshop.
| Point clé | Description | Valeur pour le développeur |
|---|---|---|
| Capacité native du modèle | gpt-image-2 interprète l'invite, l'image de référence et l'intention d'édition pour générer l'image finale | Idéal pour générer des affiches, des photos de produits, des illustrations et des maquettes |
| Format de sortie API | La documentation officielle se concentre sur b64_json, le format d'image, les dimensions, la qualité, la consommation de jetons, etc. |
Facilite le stockage côté serveur, le téléchargement, l'audit et la facturation |
| Origine de la segmentation | La plupart des calques éditables proviennent du post-traitement (OCR, segmentation, remplissage, vectorisation, écriture PPTX/PSD) | Explique "pourquoi Python tourne en arrière-plan" |
| Optimisation des coûts | L'API officielle permet une intégration au tarif standard, combinée à des bonus de recharge pour réduire les coûts réels | Adapté à la génération par lots, aux tests et à l'intégration en production |
La segmentation d'images avec gpt-image-2 n'est pas une sortie PSD native
L'erreur la plus fréquente concernant la segmentation d'images avec gpt-image-2 est de considérer que le "fichier éditable vu par l'utilisateur final" est le fichier directement produit par le modèle.
Techniquement, ce sont deux choses totalement différentes.
Le modèle produit directement une image, généralement reçue par l'application sous forme de données base64 ou de fichier image.
Si un produit permet de la convertir en PPTX, SVG ou PSD, cela signifie généralement qu'une couche de post-traitement a été ajoutée après le modèle.
Cette couche est souvent réalisée en Python, car cet écosystème est mature pour le traitement d'image, l'OCR, l'inférence par apprentissage profond et la génération de documents bureautiques.
Par exemple, un ingénieur peut utiliser l'OCR pour identifier le texte, puis l'inpainting pour nettoyer la zone de texte sur l'image originale, avant d'utiliser python-pptx pour reconstruire les zones de texte et les calques d'image.
Ce type de flux donne à l'utilisateur l'impression que "l'image a été segmentée", alors qu'il s'agit en réalité d'une rétro-ingénierie d'une structure éditable à partir d'une image aplatie.
Cette rétro-ingénierie n'est pas toujours parfaite.
Plus le texte est clair, l'arrière-plan simple et la mise en page régulière, meilleur sera le résultat de la segmentation.
Si l'image contient des textures complexes, des ombres semi-transparentes, du texte manuscrit, des décorations fines ou des objets fortement superposés, le post-traitement risque facilement de produire des erreurs de détection, des omissions ou des défauts sur les bords.
La segmentation d'images avec gpt-image-2 nécessite de surveiller la frontière entre modèle et chaîne d'outils
Lorsqu'ils développent une solution de segmentation d'images avec gpt-image-2, les développeurs doivent diviser le système en deux parties.
La première partie est la phase de génération : permettre à gpt-image-2 de produire une image avec une qualité visuelle suffisante, une structure claire et un texte aussi précis que possible.
La seconde partie est la phase de structuration : utiliser Python ou d'autres outils de post-traitement pour convertir l'image aplatie en objets éditables.
Les objectifs des deux phases diffèrent, tout comme les indicateurs d'évaluation.
La phase de génération se concentre sur le respect de l'invite, la composition, la précision du texte, la cohérence visuelle et le coût de production.
La phase de structuration se concentre sur le taux d'éditabilité du texte, la précision de la segmentation des objets, le naturel du remplissage d'arrière-plan, la compatibilité des fichiers exportés et le coût de la correction manuelle.
Conseil technique : Si vous souhaitez valider la chaîne de segmentation d'images avec gpt-image-2, il est recommandé d'intégrer d'abord l'API officielle via APIYI (apiyi.com) pour tester la génération et l'édition, puis d'ajouter progressivement les modules d'OCR, de segmentation, de remplissage et d'exportation. Cela permet d'isoler les problèmes liés au modèle de ceux liés au post-traitement.
Comment fonctionne la segmentation d'images avec gpt-image-2
La segmentation d'images avec gpt-image-2 peut être vue comme une ingénierie inverse : transformer une image "plate" en ressources structurées.
Il ne s'agit pas d'un simple détourage, mais d'un processus complet combinant compréhension visuelle, traitement d'image traditionnel et génération de documents.
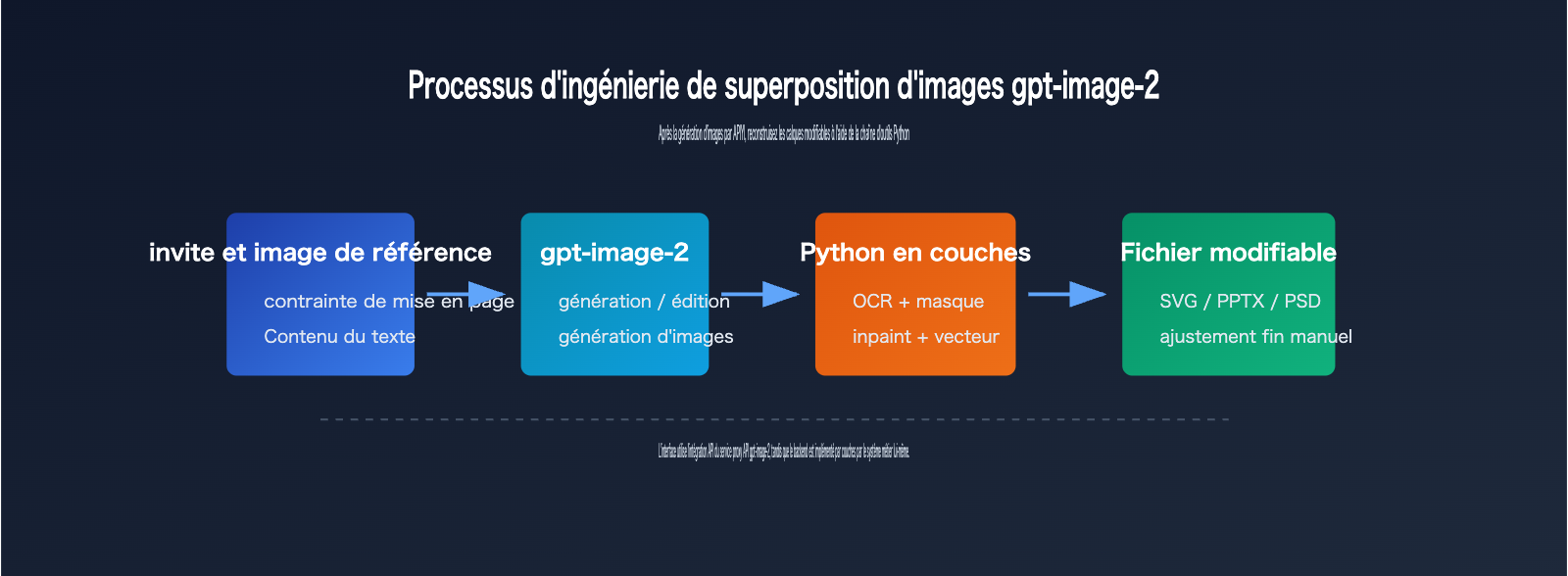
Étape 1 de la segmentation : Générer une image adaptée
Pour que la segmentation avec gpt-image-2 soit stable, la phase de génération doit être optimisée pour le post-traitement.
Votre invite doit explicitement demander une mise en page claire, des bordures d'éléments nettes, des zones de texte indépendantes et éviter les textures d'arrière-plan trop complexes.
Si l'objectif est de créer un PPTX ou un SVG, privilégiez un design plat, des aplats de couleurs, peu d'ombres et peu de dégradés.
Si vous visez le format PSD, décrivez clairement les relations entre le sujet, l'arrière-plan, le texte et les éléments décoratifs.
Une erreur courante consiste à demander au modèle une affiche de film complexe en espérant que les outils de post-traitement extraient automatiquement des calques parfaits. Ce n'est pas réaliste dans les conditions techniques actuelles. La qualité de la segmentation dépend fortement de la lisibilité de l'image source.
Étape 2 de la segmentation : Détection du texte et des objets
La première catégorie de tâches en backend Python est la détection.
La détection de texte utilise généralement des modèles OCR pour identifier le contenu, la position, la taille de la police et les limites des blocs de texte.
La détection ou segmentation d'objets identifie les personnes, produits, icônes, lignes et zones d'arrière-plan. Pour les diapositives ou infographies, on peut également identifier les titres, paragraphes, tableaux, flèches et légendes.
Ici, ce n'est pas gpt-image-2 qui "renvoie des calques", mais le modèle de post-traitement qui les déduit à partir des pixels. Plus l'inférence est précise, plus le résultat exporté (PPTX, SVG ou PSD) sera fidèle au design original.
Étape 3 de la segmentation : Restauration de l'arrière-plan et reconstruction
Une fois le texte identifié par l'OCR, il faut l'effacer de l'image originale pour le rendre éditable. Cela crée des "trous" dans l'arrière-plan.
On utilise alors des algorithmes d'inpainting (remplissage) pour reconstituer le fond. Ensuite, le système réinsère le texte identifié dans des blocs de texte indépendants au sein du PPTX, SVG ou PSD.
Pour des calques d'objets plus fins, on génère des masques pour les éléments de premier plan afin de les isoler sur des calques distincts.
Ce processus ressemble à une "segmentation par le modèle", mais il s'agit techniquement d'une combinaison : "génération d'image par le modèle + analyse par Python + reconstruction via des bibliothèques de documents".
Démarrage rapide avec la segmentation gpt-image-2
Voici la chaîne minimale pour les développeurs.
Exemple d'API minimal pour la segmentation
Cet exemple montre comment appeler l'API gpt-image-2 via une interface unifiée.
from openai import OpenAI
import base64
client = OpenAI(
api_key="VOTRE_CLE_APIYI",
base_url="https://vip.apiyi.com/v1"
)
result = client.images.generate(
model="gpt-image-2",
prompt="Générer une affiche de lancement de produit adaptée à une segmentation ultérieure, fond uni, zones de texte claires, bordures d'éléments nettes",
size="1024x1024",
quality="medium",
output_format="png"
)
image_bytes = base64.b64decode(result.data[0].b64_json)
open("poster.png", "wb").write(image_bytes)
L'objectif ici n'est pas d'obtenir un PSD instantanément, mais une image propre pour le post-traitement.
Structure de traitement complète
Voici un squelette de traitement proche d'un projet réel, sans dépendance à un modèle OCR spécifique.
from pathlib import Path
def generate_image(prompt: str) -> Path:
"""Appel de l'API gpt-image-2 pour sauvegarder une image plate."""
# client = OpenAI(api_key="VOTRE_CLE_APIYI", base_url="https://vip.apiyi.com/v1")
# response = client.images.generate(model="gpt-image-2", prompt=prompt)
return Path("poster.png")
def detect_layout(image_path: Path) -> dict:
"""OCR, détection d'objets, reconnaissance de mise en page."""
return {"texts": [], "objects": [], "background_regions": []}
def rebuild_editable_file(image_path: Path, layout: dict) -> Path:
"""Remplissage du fond et export SVG, PPTX ou PSD."""
return Path("poster-editable.pptx")
prompt = "Générer une affiche produit IA avec du texte clair et des éléments séparés pour édition"
image_path = generate_image(prompt)
layout = detect_layout(image_path)
editable_path = rebuild_editable_file(image_path, layout)
print(editable_path)
En production, séparez generate_image et rebuild_editable_file en tâches asynchrones.
Conseil de démarrage : L'API gpt-image-2 via APIYI (apiyi.com) est idéale pour valider la phase de génération avant d'intégrer vos propres modules Python de segmentation. Cela permet de conserver la puissance du modèle officiel tout en gardant la logique de vos fichiers éditables dans votre système.
Modèles d'invites pour la segmentation
| Objectif | Invite recommandée | À éviter |
|---|---|---|
| Affiche | Fond uni ou dégradé simple, titres indépendants, bords nets | Affiche de film complexe, textures, fumée |
| PPT | Style infographie plate, titres, icônes, flèches, explications | Style abstrait très artistique |
| Produit | Produit centré, fond propre, ombre portée douce | Fusion forte entre produit et fond |
| SVG | Formes géométriques, lignes, aplats, peu de texte | Textures détaillées, personnages complexes |
Une bonne invite réduit considérablement la difficulté du post-traitement. Pour une production automatisée, privilégiez toujours la clarté structurelle.
Analyse du traitement Python en arrière-plan pour la segmentation d'images avec gpt-image-2
Lorsqu'un utilisateur observe Python traiter la segmentation d'images avec gpt-image-2 en arrière-plan, il y a généralement trois explications possibles.
La première est le script d'encapsulation de l'API.
Pour éviter la duplication de code, les développeurs écrivent souvent des scripts Python qui appellent gpt-image-2, enregistrent automatiquement les images, consignent les paramètres, et gèrent les erreurs ainsi que les tentatives de reconnexion.
Ce type de script ne signifie pas que le modèle fonctionne en interne avec Python.
La seconde est le script de post-traitement d'image.
Par exemple, transmettre l'image générée à un modèle d'OCR, un modèle de segmentation, un outil de remplissage d'arrière-plan, un outil de vectorisation ou une bibliothèque de génération PPTX/PSD.
C'est ce type de script qui est la source principale de l'effet de « segmentation ».
La troisième est le script de flux de travail Agent.
Si l'utilisateur invoque la génération d'images via ChatGPT, Codex, Claude Code ou d'autres outils d'Agent, l'Agent peut sélectionner automatiquement un outil Python pour effectuer le téléchargement, la conversion, le recadrage, l'assemblage ou la génération de fichiers.
Il s'agit toujours d'un appel d'outil au niveau du produit, et non d'une segmentation native retournée par l'API gpt-image-2.
Pourquoi Python est-il couramment utilisé pour la segmentation d'images avec gpt-image-2 ?
Python est adapté à la segmentation d'images avec gpt-image-2, non pas par mystère, mais grâce à son écosystème complet.
| Étape de traitement | Tâches Python courantes | Valeur typique |
|---|---|---|
| Appel API | Appeler l'API Images, enregistrer l'image en base64, consigner les paramètres | Génération d'images stable |
| OCR | Identifier le contenu textuel, la position et les zones de texte | Transformer le texte de l'image en texte éditable |
| Segmentation | Générer des masques pour le sujet, l'arrière-plan, les icônes, les lignes | Séparer les objets visuels |
| Remplissage | Combler l'arrière-plan après avoir effacé du texte ou des objets | Créer une image de fond propre |
| Exportation | Écrire en SVG, PPTX, PSD ou autres formats | Livrer des fichiers éditables |
L'avantage de cette chaîne est sa flexibilité.
Les développeurs peuvent choisir différents modèles d'OCR, de segmentation et formats d'exportation en fonction du scénario métier.
L'inconvénient est que la stabilité des résultats ne dépend pas uniquement de gpt-image-2.
Si l'OCR identifie mal un caractère ou si le remplissage d'arrière-plan échoue, même si la qualité de l'image originale est excellente, le fichier éditable final sera défectueux.
La segmentation d'images avec gpt-image-2 n'est pas liée aux « layers » de sécurité
Il existe un terme qui prête souvent à confusion : « layers ».
Dans la documentation de sécurité d'OpenAI, on trouve des expressions comme image input layers, image output layers, ou multiple layers of protection.
Ici, « layers » désigne des couches de détection de sécurité, des couches de détection d'entrée/sortie ou des couches de protection, et non des calques Photoshop.
Si vous voyez « layers » dans un texte anglais, le traduire directement par « calques d'image » peut facilement mener à une mauvaise interprétation.
Lors de vos choix techniques, il est conseillé de toujours se référer aux champs de l'API et aux formats de sortie.
Si l'interface ne renvoie pas de liste de calques, de liste de masques, d'arborescence d'objets ou de fichier PSD, elle ne peut pas être considérée comme une interface native de segmentation d'images.
Critères de fiabilité pour la segmentation d'images avec gpt-image-2
Pour déterminer si une solution de segmentation d'images avec gpt-image-2 est fiable, vous pouvez examiner quatre indicateurs.
Premièrement, vérifiez si elle distingue clairement la sortie de l'image originale de la sortie du post-traitement.
Deuxièmement, vérifiez si elle peut montrer la source de chaque calque, par exemple : calque de texte OCR, calque d'arrière-plan, calque d'objets au premier plan.
Troisièmement, vérifiez si elle permet une correction manuelle.
Quatrièmement, vérifiez si elle peut reproduire le même résultat de segmentation pour une même image.
Si un système se contente de dire « segmentation automatique par IA » sans expliquer la logique d'OCR, de masque, de remplissage et d'exportation, les développeurs doivent rester prudents.
Suggestion de solution : Dans les projets réels, vous pouvez obtenir la capacité de génération stable de gpt-image-2 via un canal de transfert officiel, puis transformer la capacité de segmentation Python en un service interne. Cela permet d'utiliser la puissance du canal officiel sans lier la boîte noire du post-traitement à un outil unique.
Coûts de l'API de segmentation d'images gpt-image-2 et calcul de la remise de 14 %
Le coût de la segmentation d'images avec gpt-image-2 doit être calculé par étapes.
La génération par le modèle représente une partie du coût.
L'OCR, la segmentation, le remplissage, l'exportation et le stockage en constituent une autre.
Si l'on ne regarde que le « prix de génération d'un fichier éditable », il est facile de mal évaluer le budget.
Référence des prix officiels pour la segmentation d'images avec gpt-image-2
Selon la page de tarification officielle de l'API OpenAI, les prix publics de gpt-image-2 incluent l'entrée d'image, l'entrée d'image en cache, la sortie d'image, l'entrée de texte et l'entrée de texte en cache.
| Poste de facturation | Tarification officielle | Signification dans la segmentation d'image |
|---|---|---|
| Image input | 8,00 $ / 1 million de tokens | Généré lors de l'entrée d'images de référence, d'édition ou de matériaux |
| Cached image input | 2,00 $ / 1 million de tokens | Coût d'entrée d'image en cache réutilisable |
| Image output | 30,00 $ / 1 million de tokens | Coût principal de la sortie de l'image elle-même |
| Text input | 5,00 $ / 1 million de tokens | Invites, instructions d'édition, spécifications de mise en page |
| Cached text input | 1,25 $ / 1 million de tokens | Espace d'optimisation des coûts pour les invites en cache |
Les prix officiels constituent la base du budget.
Cependant, dans un projet réel, il faut aussi prendre en compte les tentatives de reconnexion en cas d'échec, les files d'attente par lots, la puissance de calcul pour le post-traitement, la validation humaine et les coûts de stockage.
Si vous devez générer fréquemment plusieurs versions d'affiches, il est conseillé de contrôler les coûts en jouant sur les invites, les dimensions, la qualité et les stratégies de réessai.
Coûts de l'API de transfert officiel pour la segmentation d'images gpt-image-2
L'API de transfert officiel gpt-image-2 d'APIYI (apiyi.com) permet une intégration basée sur les tarifs officiels, ce qui convient aux équipes souhaitant conserver le canal du modèle officiel tout en réduisant la complexité de l'intégration.
L'offre promotionnelle mentionnée par les utilisateurs est : 100 $ rechargés offrent 10 % de solde supplémentaire.
En calculant strictement sur la base de « 100 $ versés pour 110 $ de solde disponible », le coût unitaire équivalent est d'environ 90,9 % du prix officiel.
Si l'on prend en compte les promotions de la plateforme et la remise globale, on peut considérer qu'il s'agit d'une remise proche de 14 % (soit environ 86 % du prix officiel), sous réserve des règles de règlement de la plateforme.
| Mode d'accès | Base de prix | Avantages | Remarques |
|---|---|---|---|
| API officielle OpenAI | Prix officiel | Canal natif, documentation complète | Gestion autonome des comptes, paiements, quotas et risques |
| API de transfert gpt-image-2 | Prix officiel | Intégration rapide, interface unifiée, gestion d'équipe | Recharge et règlement selon les règles de la plateforme |
| Offre de recharge | 100 $ + 10 % offerts | Réduit le coût unitaire réel | La remise dépend du montant réellement crédité |
| Solution inverse auto-hébergée | Variable | Grande flexibilité | Coûts de conformité, de stabilité et de maintenance plus élevés |
Conseil de coût : Si vous effectuez des tests de mise en produit pour la segmentation d'images avec gpt-image-2, il est recommandé d'utiliser d'abord l'API de transfert officiel d'APIYI (apiyi.com) pour traiter 50 à 100 échantillons, d'enregistrer le coût de génération, le taux de réussite de la segmentation et le temps de correction humaine par image, avant de décider d'augmenter le volume des appels.
Liste de contrôle pour l'optimisation des coûts de segmentation d'images gpt-image-2
L'optimisation des coûts ne doit pas se limiter au prix unitaire.
Il est plus important de réduire les générations inutiles.
Premièrement, utilisez des invites structurées pour réduire les tentatives de reconnexion dues à une composition peu claire.
Deuxièmement, utilisez une qualité moyenne pour valider la mise en page avant d'augmenter la qualité pour la version finale.
Troisièmement, mettez en cache les invites de modèle pour réduire les coûts d'entrée de texte répétitifs.
Quatrièmement, utilisez des images de référence et des normes de mise en page uniformes pour les mêmes produits afin de faciliter le post-traitement.
Cinquièmement, classez les échantillons ayant échoué pour distinguer les échecs de génération du modèle des échecs de segmentation Python.
Sixièmement, privilégiez le style d'infographie plate pour les scénarios nécessitant une livraison éditable.
Ces pratiques sont souvent plus efficaces que la simple recherche d'un prix unitaire plus bas.
Comparaison des solutions de segmentation d'images pour gpt-image-2
Les besoins en matière de segmentation d'images pour gpt-image-2 varient considérablement d'une équipe à l'autre.
Certains souhaitent simplement modifier un titre, d'autres veulent exporter au format PPTX, obtenir un fichier PSD complet ou simplement générer un SVG à la structure claire.
Le comparatif ci-dessous vous aidera à choisir la stratégie adaptée.
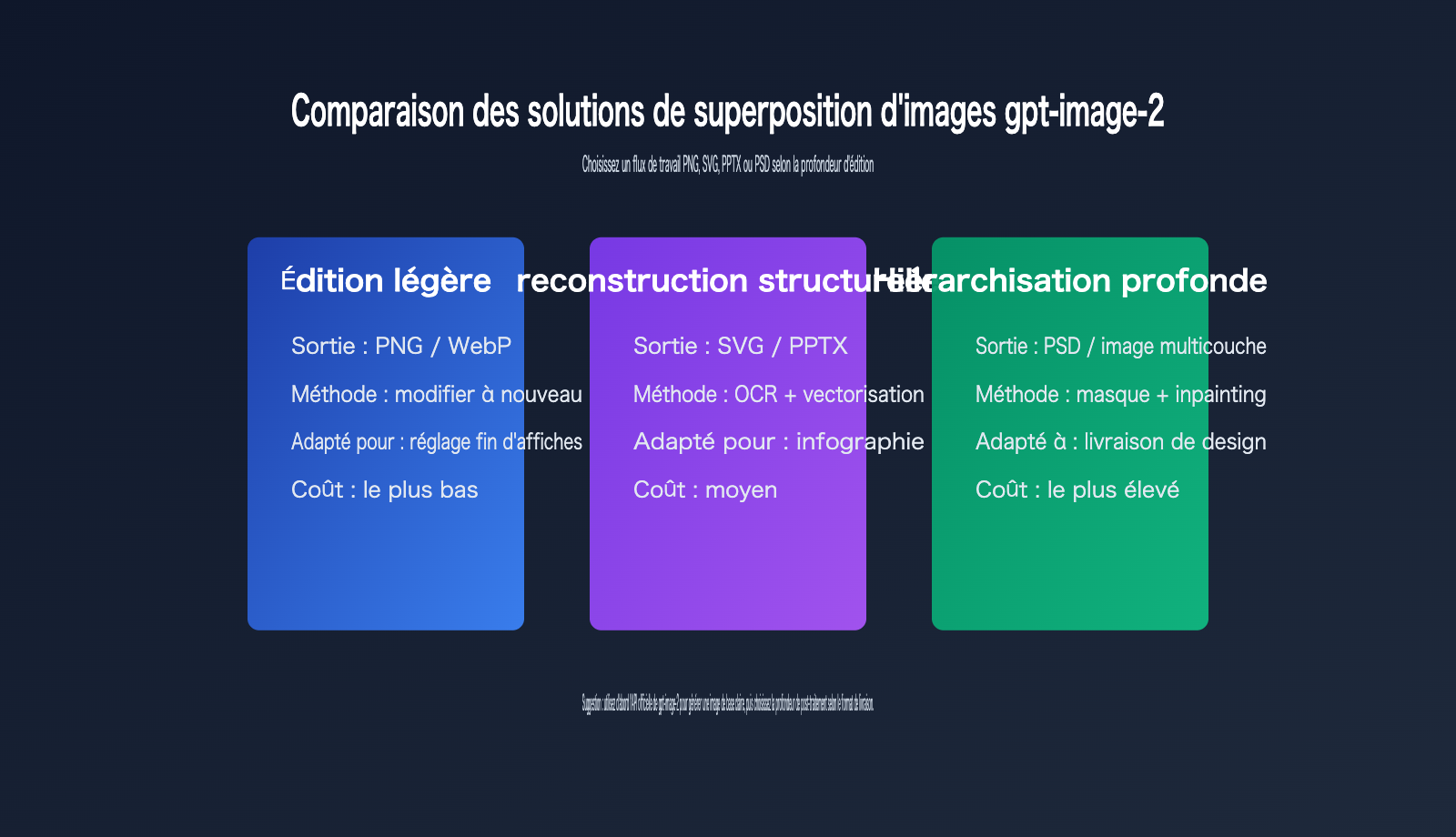
Solution 1 : Continuer avec l'édition d'image
Si vous n'avez besoin que de modifier une partie du contenu, la méthode la plus simple n'est pas la segmentation, mais de poursuivre l'édition directement dans gpt-image-2.
Par exemple, modifier un titre, changer des couleurs, remplacer un arrière-plan, substituer une image de produit ou ajouter de petites icônes peut être réalisé via l'interface d'édition d'image.
Cette approche est la moins coûteuse et la moins complexe techniquement.
L'inconvénient est que chaque modification nécessite une nouvelle génération (partielle ou totale), sans la précision d'une sélection de calque comme dans un logiciel de design.
C'est idéal pour la gestion de contenu, les visuels de réseaux sociaux ou la création rapide d'affiches.
Solution 2 : Exportation SVG ou PPTX
Si l'image est un graphique, un organigramme, une affiche scientifique ou une infographie, la reconstruction en SVG/PPTX est souvent plus pratique qu'un PSD.
En effet, les éléments de ces images sont généralement des textes, des icônes, des lignes, des rectangles, des flèches et quelques décorations.
L'OCR permet d'identifier le texte, la vectorisation permet de reconstruire les lignes et les aplats de couleur, et les bibliothèques PPTX permettent de créer des zones de texte éditables.
Cette solution est adaptée aux bases de connaissances d'entreprise, aux présentations scientifiques, aux supports de vente et aux supports de formation.
L'objectif n'est pas une reproduction parfaite au pixel près, mais la "modifiabilité" et une fidélité visuelle suffisante.
Solution 3 : Génération de PSD ou de packs de ressources multi-calques
La segmentation PSD est la plus complexe.
Pour séparer les personnages, produits, arrière-plans, textes, ombres et décorations en calques distincts, le système doit disposer de capacités de segmentation et de retouche avancées.
Pour des images de style photographique complexe, un PSD automatique atteint rarement le niveau d'un designer professionnel.
Une stratégie plus réaliste consiste à générer un "PSD semi-automatique" : le système extrait d'abord l'arrière-plan, le sujet, le texte et quelques objets clés, puis le designer effectue les corrections manuelles.
Cette approche convient au design de marque, aux visuels e-commerce, à la création publicitaire et aux ressources de haute valeur destinées à être réutilisées sur le long terme.
Questions fréquentes sur la segmentation d'images avec gpt-image-2
gpt-image-2 peut-il exporter directement un PSD ?
Au vu de l'API publique actuelle, il ne faut pas considérer cela comme une "exportation directe de fichier PSD par calques".
La documentation officielle met l'accent sur la génération d'images, l'édition, les données d'image en base64, les formats de sortie, les dimensions, la qualité et la consommation de jetons.
Si un produit permet d'exporter un PSD, c'est généralement grâce à l'intégration supplémentaire de Photoshop, d'une bibliothèque d'écriture PSD ou d'un module de post-traitement propriétaire.
Le code Python dans la segmentation d'image gpt-image-2 fait-il partie du modèle ?
Généralement non.
Le code Python que vous voyez est probablement un script de workflow externe.
Il peut être responsable de l'appel à l'API, de l'enregistrement des images, de l'exécution de l'OCR, de la génération de masques, de la retouche d'arrière-plan, de la vectorisation ou de l'écriture de fichiers PPTX/PSD. Ces scripts appartiennent à la couche applicative, et non au modèle lui-même.
Pourquoi la segmentation gpt-image-2 semble-t-elle si réaliste ?
Parce que le système de post-traitement peut reconstruire la structure à partir des pixels.
Par exemple, après la reconnaissance de texte, celui-ci peut être transformé en zone de texte éditable. Le sujet principal peut devenir un calque indépendant via un masque, et l'arrière-plan peut être nettoyé. Une fois superposés, ces éléments ressemblent à un fichier de travail issu d'un logiciel de design.
La segmentation gpt-image-2 est-elle adaptée à toutes les images ?
Non.
Les images adaptées à la segmentation ont généralement une mise en page claire, des bordures nettes, peu de texte, un arrière-plan simple et des éléments qui ne se chevauchent pas trop.
Les images complexes (photographies détaillées, illustrations texturées, matériaux transparents, décorations fines ou compositions artistiques) sont moins adaptées.
Comment améliorer le taux de réussite de la segmentation ?
Commencez par optimiser vos invites (prompts).
Demandez au modèle de produire une structure claire, des bordures nettes, des zones de texte indépendantes et un arrière-plan peu complexe.
Limitez ensuite les dimensions et le style de l'image pour éviter de surcharger le système de post-traitement.
Enfin, utilisez un jeu d'échantillons pour évaluer la précision de l'OCR, la qualité du découpage des objets et le temps nécessaire aux corrections manuelles. Au niveau de l'appel API, il est conseillé de centraliser la gestion des requêtes via le service proxy API de gpt-image-2 pour faciliter le suivi des coûts et des échecs.
Faut-il obligatoirement utiliser l'API ?
Si vous générez des images occasionnellement, une interface graphique suffit.
Si vous prévoyez une génération en masse, une vérification automatique, un archivage de ressources, une exportation de fichiers éditables ou une collaboration d'équipe, l'utilisation de l'API est recommandée.
L'API permet de rendre chaque étape traçable, répétable et facturable, tout en facilitant l'intégration avec vos services de post-traitement Python internes.
Comment comprendre la remise sur la segmentation d'images gpt-image-2 ?
La tarification via le service proxy API de gpt-image-2 se base sur le prix officiel, avec souvent des bonus (par exemple, 10 % offerts pour 100 $ rechargés).
Mathématiquement, 100 $ donnent 110 $ de crédit, soit un coût unitaire réduit d'environ 90,9 %.
Si une plateforme affiche une "remise de 14 %" (soit 86 % du prix), référez-vous toujours aux conditions réelles de facturation et aux explications de l'offre. Lors de l'établissement de votre budget, conservez trois colonnes : "Prix officiel", "Coût après bonus" et "Remise affichée", afin d'éviter toute confusion comptable.
Points clés sur la segmentation d'images avec gpt-image-2
- Le principe fondamental de la segmentation d'images avec gpt-image-2 est le suivant : le modèle génère généralement des images plates ; les calques proviennent le plus souvent de la chaîne d'outils de post-traitement.
- Le traitement backend en Python n'a rien de mystérieux ; il est couramment utilisé pour l'invocation du modèle, l'OCR, les masques, l'inpainting, la vectorisation et l'exportation de fichiers.
- Si l'interface ne renvoie pas de PSD, d'arborescence d'objets, de liste de calques ou de liste de masques, il ne faut pas présenter cela comme une capacité de segmentation native du modèle.
- Pour améliorer le taux de réussite de la segmentation, l'invite doit être conçue pour le post-traitement, en veillant à ce que la structure de l'image soit claire et les contours des éléments bien définis.
- Pour des modifications légères, vous pouvez continuer à utiliser gpt-image-2 ; pour une livraison structurée, privilégiez le format SVG/PPTX, et réservez le format PSD aux livraisons de design approfondies.
- L'API officielle de gpt-image-2 est idéale pour l'intégration côté génération, tandis que le service de segmentation Python est mieux géré directement par vos systèmes métier.
- Le calcul des coûts doit prendre en compte simultanément le prix officiel du modèle, les bonus de recharge, la puissance de calcul du post-traitement, les tentatives en cas d'échec et le temps de correction manuelle.
Références pour la segmentation d'images avec gpt-image-2
Cet article a été rédigé en consultant des ressources anglophones et en recoupant les informations avec la documentation officielle de l'API.
- Page du modèle OpenAI GPT Image 2 : developers.openai.com/api/docs/models/gpt-image-2
- Documentation OpenAI Images and vision : developers.openai.com/api/docs/guides/images-vision
- Référence de l'API OpenAI Images : developers.openai.com/api/reference/resources/images
- Tarification de l'API OpenAI : openai.com/api/pricing
- Discussion Reddit sur les compétences Python de GPT Image 2 : reddit.com/r/ClaudeCode/comments/1stokpq
- Discussion Reddit sur la conversion de GPT Image 2 vers des diapositives modifiables : reddit.com/r/ChatGPT/comments/1suwjp8
Ces documents convergent vers une conclusion unique : bien que les capacités de génération et d'édition de gpt-image-2 soient puissantes, la disponibilité de calques modifiables est généralement le résultat d'un flux de travail au niveau applicatif.
Résumé de la segmentation d'images avec gpt-image-2
Pour gpt-image-2, l'essentiel n'est pas de savoir si l'on obtient un fichier PSD "natif", mais plutôt d'établir des limites système claires.
Côté génération, gpt-image-2 se charge de transformer vos invites et votre image de référence en une image de haute qualité.
Côté ingénierie, la chaîne d'outils Python prend le relais pour analyser l'image aplatie et en extraire le texte, les objets, l'arrière-plan et les éléments éditables.
En distinguant bien ces deux étapes, les développeurs peuvent évaluer avec précision les résultats, les coûts et la maintenabilité du projet.
Si votre objectif est d'automatiser la création d'affiches en série, de graphiques pour PPT, de visuels produits ou de ressources de design, je vous conseille d'utiliser d'abord gpt-image-2 pour générer une image de base à la structure claire, puis d'effectuer un post-traitement pour obtenir le format de livraison souhaité (SVG, PPTX ou PSD).
Pour la couche d'intégration, vous pouvez privilégier l'API officielle de gpt-image-2 via APIYI (apiyi.com). Vous bénéficierez d'une tarification alignée sur les tarifs officiels pour chaque invocation du modèle, tout en optimisant vos coûts grâce à leur offre promotionnelle (10 % offerts pour tout rechargement de 100 $).
Une fois que vous gérez séparément les capacités du modèle, le post-traitement, le format de livraison et le suivi des coûts, la segmentation d'images avec gpt-image-2 cesse d'être un concept flou pour devenir un véritable processus de production visuelle : vérifiable, évolutif et prêt pour la mise en production.
Pour les échanges techniques et les tests d'intégration de modèles, n'hésitez pas à suivre APIYI (apiyi.com). C'est la solution idéale pour les équipes de développeurs ayant besoin d'une interface unifiée pour appeler gpt-image-2, la série GPT et d'autres API multimodales.