
title: "大規模言語モデルAPIでPDFを扱うには?3つの実装パターンを徹底解説"
description: "大規模言語モデルAPIでPDFを直接読み込めるのか?GPT-4o、Claude、Gemini、DeepSeekの対応状況を整理し、文字抽出、画像認識、クライアント側処理という3つの実装戦略を詳しく解説します。"
作者注:GPT-4o、Claude、Gemini、DeepSeekなどの大規模言語モデルAPIにおけるPDF入力のサポート状況と、テキスト抽出、画像認識、クライアント側処理という3つのアプローチについて詳しく解説します。
「大規模言語モデルAPIにPDFを直接渡せるのか?」これは開発者から最も頻繁に寄せられる質問の一つです。答えは想像以上に複雑です。結論から言うと、一部のモデルはPDF入力をネイティブでサポートしています(Claude、Gemini、GPT-4o)。しかし、DeepSeekなどのモデルはまだ対応しておらず、ネイティブサポートを利用する場合、テキスト抽出方式に比べてトークンコストが大幅に高くなるという点に注意が必要です。
本記事では、実際の開発現場の視点から、主要な大規模言語モデルAPIのPDFサポート状況を整理し、3つのPDF処理手法の比較とコード例を紹介します。あなたのプロジェクトに最適な方法を見つけるヒントにしてください。
核心的な価値: 本記事を読めば、各モデルのPDF対応状況が明確になり、コスト効率重視から利便性重視まで、3つの処理手法を使いこなせるようになります。

大規模言語モデル API の PDF 入力サポート:主要ポイント
| ポイント | 説明 | 価値 |
|---|---|---|
| 3社がネイティブ対応 | Claude(600ページ)、Gemini(1000ページ)、GPT-4o(100ページ)が対応済み | 前処理不要、APIで直接送信可能 |
| DeepSeek等は未対応 | テキスト抽出や画像変換などの前処理が必要 | 前処理パイプラインの構築が必要 |
| コストに大きな差 | ネイティブPDFは1ページあたり258〜3000トークン、テキスト抽出なら300〜1500トークン | 大量処理時は適切な手法選択でコストを1/10に削減可能 |
| 3つの手法を使い分け | テキスト抽出、画像理解、クライアント処理 | 用途に合わせて選択し、最適化が可能 |
大規模言語モデル API による PDF ネイティブサポートの現状
朗報として、2025年以降、主要な大規模言語モデルが続々と API での PDF 直接送信に対応しました。その仕組みは基本的に共通しており、PDF からテキストを抽出すると同時に、各ページを画像としてレンダリングすることで、モデルがテキスト内容と視覚要素(グラフ、レイアウトなど)の両方を理解できるようにしています。
一方で懸念点として、この「テキスト+画像」のデュアルチャネル処理は、純粋なテキスト入力よりもトークン消費量が大幅に増えるという点があります。例えば 50 ページのレポートをそのまま PDF で送信すると 10 万トークン以上消費する可能性がありますが、事前にテキストを抽出してから送信すれば、わずか 3 万トークン程度で済む場合もあります。
各大規模言語モデル API の PDF サポート詳細比較
| モデル | PDF対応 | 最大ページ数 | 最大ファイルサイズ | 送信方式 | 1ページあたりのトークンコスト |
|---|---|---|---|---|---|
| Claude | 対応(GA) | 600 ページ | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | 対応 | 1000 ページ | 2 GB(Files API) | Inline / Files API / URL | ~258(最安) |
| GPT-4o | 対応 | 100 ページ | 32 MB | Base64 / File Upload | ~765(画像)+ テキスト |
| DeepSeek | 未対応 | — | — | 前処理が必要 | — |
| Llama / Qwen | 未対応 | — | — | 前処理が必要 | — |
🎯 選択のアドバイス: 大量の PDF を処理する必要がある場合、Gemini が最も低コスト(1ページあたり約 258 トークン、ネイティブテキスト抽出は無料)です。長文ドキュメントのサポートにおいても Gemini が最強(1000 ページ)です。Claude は理解の正確性に優れており、高精度が求められるシーンに適しています。これらのモデルはすべて、APIYI (apiyi.com) プラットフォームを通じて統合的に呼び出すことができます。
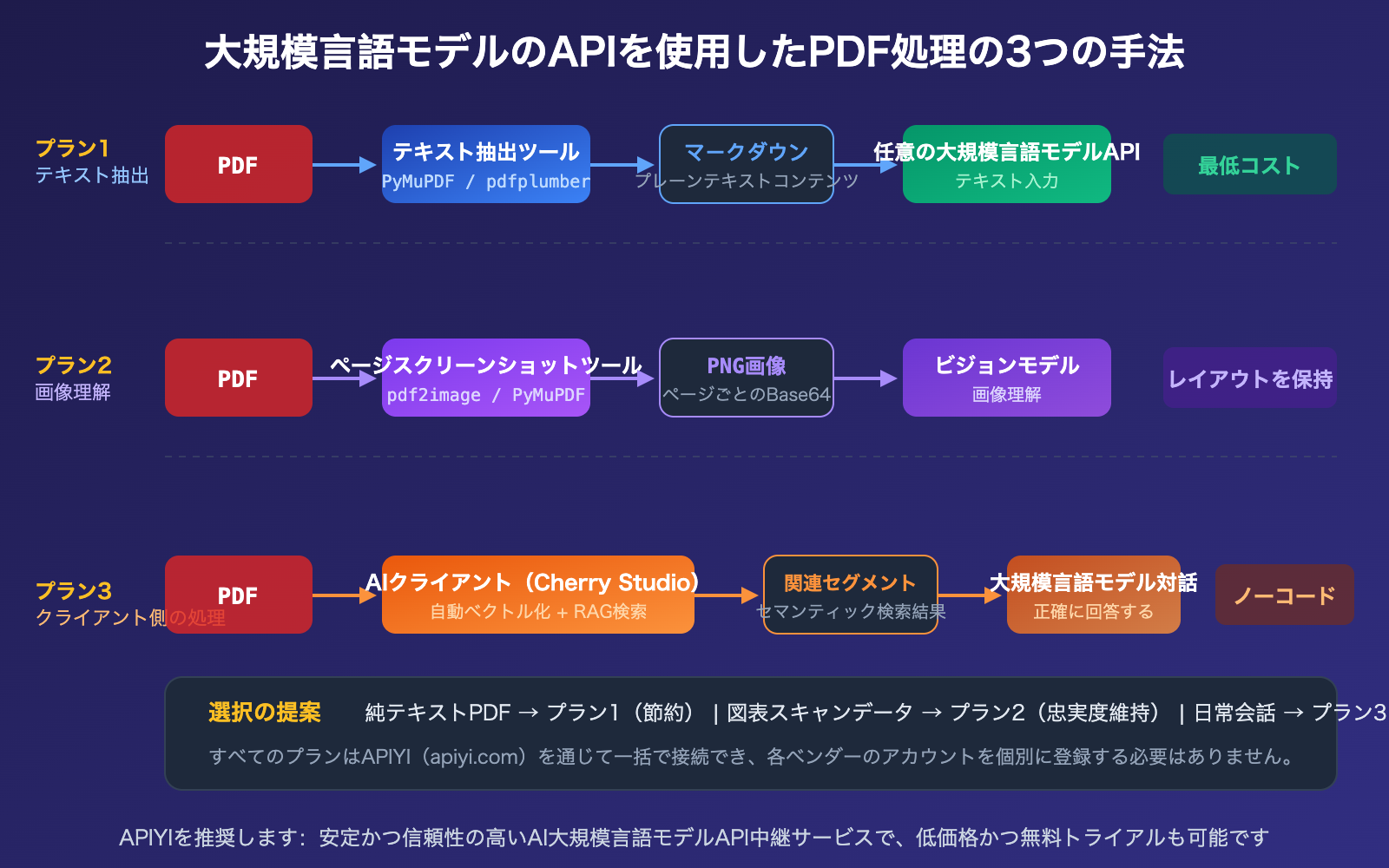
大規模言語モデル API による PDF 処理ソリューション 1:テキスト抽出
これは最も汎用性が高く、コストを抑えられる手法です。まず Python ライブラリを使用して PDF を Markdown またはプレーンテキストに変換し、そのテキストをプロンプトとして任意の大規模言語モデル API に送信します。
PDF テキスト抽出ツールの比較
| ツール | 速度 | 最適な用途 | 特徴 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14秒/文書 | 一般的なテキスト + 表の抽出 | 速度と品質のバランスが最高、Markdown 出力 |
| pdfplumber | 中程度 | 表データ抽出 | 座標ベースの表抽出、精度が高い |
| Marker-PDF | ~11秒/文書 | 複雑なレイアウトの忠実な変換 | 構造保持が最も優れているが、速度は遅め |
| PyPDF2 | 高速 | シンプルな純テキスト PDF | 軽量で、基本的なテキスト抽出に適している |
PDF テキスト抽出のコード例
import pymupdf4llm
import openai
# ステップ1: PDF を Markdown に変換
md_text = pymupdf4llm.to_markdown("report.pdf")
# ステップ2: 大規模言語モデル API に送信
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"このレポートの核心的なポイントを要約してください:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
PDF の画像処理を含む完全なコード(画像理解ソリューション)を表示
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""PDF の各ページを Base64 画像に変換"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# PDF を画像に変換
images = pdf_pages_to_images("report.pdf")
# マルチ画像メッセージの構築
content = [{"type": "text", "text": "この PDF 文書内の図表とデータを分析してください:"}]
for img_b64 in images[:10]: # トークン超過を避けるため、ページ数を制限してください
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
推奨: テキスト抽出ソリューションは、すべてのモデル(DeepSeek や Llama など、PDF を直接サポートしていないモデルを含む)と互換性があります。APIYI (apiyi.com) を通じれば、同じ API キーで任意のモデルを呼び出してテスト可能です。
大規模言語モデル API による PDF 処理ソリューション 2:ネイティブ PDF 入力
Claude、Gemini、または GPT-4o を使用している場合、前処理なしで API に直接 PDF を渡すことができます。
Claude API ネイティブ PDF 入力の例
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Claude はルートドメインを使用
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "この文書の核心的なポイントを要約してください"}
]
}]
)
print(message.content[0].text)
Gemini API ネイティブ PDF 入力の例
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"この文書の核心的なポイントを要約してください"
]
)
print(response.text)
🎯 コストに関する注意: ネイティブ PDF 入力は最も便利ですが、トークンコストは純テキストソリューションよりも大幅に高くなります。50ページの PDF を例に挙げると、Gemini は約 12,900 トークン(最も安価)、Claude は約 75,000〜150,000 トークン、GPT-4o は約 40,000 トークン以上を消費します。大量処理を行う場合は必ずコストを試算してください。APIYI (apiyi.com) の利用統計機能で消費量を監視することをお勧めします。
大規模言語モデル API PDF 処理ソリューション 3:クライアントアプリでの処理
日常的な対話シーン(コード開発以外)では、AI クライアントアプリを使用するのが最も手軽な方法です。例えば「Cherry Studio」のようなツールを使えば、PDF ファイルをドラッグ&ドロップするだけで、自動的にベクトル化とセマンティック検索が行われ、関連する断片のみが大規模言語モデルに送信されます。
クライアントアプリ利用のメリット
- ノーコード: PDF をドラッグ&ドロップするだけで対話を開始可能
- トークン節約: RAG(検索拡張生成)により、全文ではなく関連する断片のみを送信
- モデルの切り替え: APIYI などの複数の API プラットフォームを設定可能
- ローカルナレッジベース: 複数の PDF をナレッジベースとして構築し、繰り返し検索が可能
クライアントアプリで PDF を扱う際の注意点
- ファイルサイズの管理: PDF のページ数が多すぎると、ベクトル化に時間がかかります
- トークン料金への注意: RAG は内容を圧縮しますが、長大なドキュメントではそれなりのコストが発生する可能性があります
- 適切なモデルの選択: 簡単な質問には安価なモデル(GPT-4o-mini など)、複雑な分析にはフラッグシップモデルを選択しましょう
推奨: Cherry Studio などのクライアントアプリに APIYI (apiyi.com) を API プロバイダーとして設定すれば、1 つの API キーで Claude、Gemini、GPT などのあらゆるモデルにアクセスできます。

よくある質問
Q1: DeepSeek で PDF を処理するにはどの方法が最適ですか?
DeepSeek API は現在、PDF の直接入力をサポートしていません。推奨されるのは「テキスト抽出(文字化)」アプローチです。まず PyMuPDF4LLM を使用して PDF を Markdown テキストに変換し、その後 APIYI (apiyi.com) を経由して DeepSeek API を呼び出し分析を行います。PDF に図表が含まれている場合は、ページを画像に変換し、Vision 対応モデル(GPT-4o など)を使用して理解させるのが効果的です。
Q2: ネイティブの PDF 入力とテキスト抽出では、どちらが効果的ですか?
PDF の内容によります。純粋なテキストベースの PDF(契約書やレポートなど)であれば両者の効果に大差はなく、テキスト抽出の方がコストを抑えられます。一方、図表や複雑なレイアウト、スキャンされた文書を含む PDF の場合は、モデルがテキストと視覚要素を同時に理解できるため、ネイティブ入力の方が明らかに優れた結果を出します。まずはテキスト抽出で試し、精度が不十分な場合にネイティブ入力へ切り替えることをお勧めします。
Q3: PDF 処理のトークン費用を抑えるにはどうすればよいですか?
いくつかの実用的なテクニックを紹介します:
- 大量処理が必要な場合は Gemini を優先する(1ページあたりわずか 258 トークンで、コストが最も低い)
- 文書全体を一度に送信せず、必要なページだけを抽出する
- テキスト抽出後に要約や分割を行い、長すぎるテキストの入力を避ける
- APIYI (apiyi.com) の利用状況パネルで実際の消費量を監視する
まとめ
大規模言語モデル API による PDF 入力サポートの要点は以下の通りです:
- 一部モデルはネイティブ対応: Claude(600ページ)、Gemini(1000ページ)、GPT-4o(100ページ)は PDF を直接送信可能ですが、DeepSeek などは現在未対応です。
- 3つの手法を用途に合わせて選択: テキスト抽出はコストが最も低く全モデルと互換性があり、ネイティブ入力は最も手軽ですがコストが高めです。クライアント側での処理は日常的な対話に適しています。
- コスト差は顕著: 同じ PDF でも、Gemini のネイティブ入力が最も安価(1ページあたり約 258 トークン)であり、純粋なテキスト抽出手法を使えばさらにコストを 50% 以上削減可能です。
用途に応じて適切な手法を選択すれば、高額なトークン費用を気にすることなく効率的に PDF を処理できます。
主要なモデルを一括して利用するには、APIYI (apiyi.com) を通じた接続がおすすめです。プラットフォームでは無料枠も提供されており、Claude、Gemini、GPT、DeepSeek など、すべての主要モデルの API 呼び出しに対応しています。
📚 参考資料
-
OpenAI PDF 入力ガイド: PDFをAPIで直接送信するための公式ドキュメント
- リンク:
platform.openai.com/docs/guides/pdf-files - 説明: GPT-4oにおけるPDF入力の詳細な仕様と制限事項
- リンク:
-
Claude PDF サポートドキュメント: Anthropic公式のPDF処理ガイド
- リンク:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - 説明: ClaudeにおけるPDF入力の3つの手法とベストプラクティス
- リンク:
-
Gemini ドキュメント処理: Google公式のドキュメント理解能力に関する説明
- リンク:
ai.google.dev/gemini-api/docs/document-processing - 説明: GeminiにおけるPDF処理の制限事項と料金体系
- リンク:
-
PyMuPDF4LLM ドキュメント: PDFテキスト抽出ツール
- リンク:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 説明: PDFをMarkdownに変換する最速のツール
- リンク:
-
APIYIプラットフォームドキュメント: 各種大規模言語モデルAPIの統合アクセス
- リンク:
docs.apiyi.com - 説明: APIキーの取得、モデル一覧、およびモデル呼び出しのサンプルコード
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。その他の資料については、APIYIのドキュメントセンター(docs.apiyi.com)をご覧ください。