
ملاحظة من المؤلف: دليل شامل حول دعم نماذج اللغة الكبيرة مثل GPT-4o وClaude وGemini وDeepSeek لمدخلات PDF، مع استعراض لثلاثة حلول معالجة: الاستخراج النصي، فهم الصور، والمعالجة عبر العميل.
"هل يمكنني إرسال ملف PDF مباشرة إلى واجهة برمجة تطبيقات (API) الخاصة بنموذج لغة كبير؟" هذا أحد أكثر الأسئلة شيوعاً بين المطورين. الإجابة أكثر تعقيداً مما تتخيل؛ فبينما تدعم بعض النماذج ملفات PDF أصلياً (مثل Claude وGemini وGPT-4o)، لا تزال نماذج أخرى مثل DeepSeek لا تدعم ذلك، كما أن تكلفة الرموز (Tokens) في الدعم الأصلي أعلى بكثير من حلول الاستخراج النصي.
في هذا المقال، سنستعرض من منظور تطويري واقعي حالة دعم ملفات PDF في واجهات برمجة التطبيقات لأهم نماذج اللغة الكبيرة، وسنقدم مقارنة كاملة مع أمثلة برمجية لـ 3 حلول لمعالجة ملفات PDF، لمساعدتك في اختيار الطريقة الأنسب لمشروعك.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتضح لك درجة دعم كل نموذج لملفات PDF، وستتقن 3 طرق للمعالجة تتراوح بين الأكثر توفيراً للتكاليف والأكثر سهولة في التنفيذ.

النقاط الجوهرية لدعم ملفات PDF في واجهات برمجة تطبيقات (API) النماذج اللغوية الكبيرة
| النقطة | الشرح | القيمة |
|---|---|---|
| 3 نماذج تدعم PDF أصلياً | Claude (600 صفحة)، Gemini (1000 صفحة)، GPT-4o (100 صفحة) تدعمها جميعاً | لا حاجة للمعالجة المسبقة، إرسال مباشر عبر API |
| نماذج مثل DeepSeek لا تدعمها بعد | تتطلب استخراج النصوص أو تحويلها إلى صور أولاً | تتطلب بناء مسار معالجة مسبقة |
| فروقات ضخمة في التكلفة | PDF الأصلي يستهلك 258-3000 توكن لكل صفحة، بينما النص المستخرج يستهلك 300-1500 فقط | اختيار المسار الصحيح يوفر 10 أضعاف التكلفة في السيناريوهات الضخمة |
| 3 حلول لكل منها سيناريو | استخراج النصوص، فهم الصور، المعالجة عبر العميل | اختر ما يناسب احتياجك، لا تلتزم بطريقة واحدة |
الوضع الحالي لدعم ملفات PDF في واجهات برمجة تطبيقات النماذج اللغوية الكبيرة
الخبر السار هو أنه منذ عام 2025، بدأت النماذج اللغوية الكبيرة الرائدة في دعم إرسال ملفات PDF مباشرة عبر API. وتعتمد جميعها تقريباً على نفس الآلية: استخراج النصوص من ملف PDF، وفي الوقت نفسه تحويل كل صفحة إلى صورة، مما يسمح للنموذج بفهم المحتوى النصي والعناصر المرئية (مثل الرسوم البيانية وتخطيط الصفحة) في آن واحد.
الخبر السيئ هو أن طريقة المعالجة هذه "القائمة على النص + الصور" تستهلك عدد توكنز (Tokens) أعلى بكثير من إدخال النصوص البحتة. فتقرير مكون من 50 صفحة إذا تم إرساله كملف PDF مباشرة، قد يستهلك أكثر من 100 ألف توكن، بينما إذا استخرجت النص أولاً ثم أرسلته، فقد تحتاج إلى 30 ألف توكن فقط.
مقارنة تفصيلية لدعم PDF في واجهات برمجة تطبيقات النماذج
| النموذج | دعم PDF | الحد الأقصى للصفحات | الحد الأقصى للملف | طريقة النقل | تكلفة التوكن لكل صفحة |
|---|---|---|---|---|---|
| Claude | مدعوم (GA) | 600 صفحة | 32 ميجابايت | Base64 / URL / Files API | 1500-3000 |
| Gemini | مدعوم | 1000 صفحة | 2 جيجابايت (Files API) | Inline / Files API / URL | ~258 (الأرخص) |
| GPT-4o | مدعوم | 100 صفحة | 32 ميجابايت | Base64 / File Upload | ~765 (صور) + نص |
| DeepSeek | غير مدعوم | — | — | يتطلب معالجة مسبقة | — |
| Llama / Qwen | غير مدعوم | — | — | يتطلب معالجة مسبقة | — |
🎯 نصيحة للاختيار: إذا كنت بحاجة إلى معالجة كميات كبيرة من ملفات PDF، فإن Gemini هو الأقل تكلفة (حوالي 258 توكن لكل صفحة، مع استخراج نصي مجاني). وإذا كنت بحاجة إلى دعم لأطول المستندات، فإن Gemini هو الأقوى أيضاً (1000 صفحة). أما Claude فيتميز بدقة فهم عالية، مما يجعله مناسباً للسيناريوهات التي تتطلب دقة فائقة. يمكنك الوصول إلى كل هذه النماذج واستدعاؤها بشكل موحد عبر منصة APIYI (apiyi.com).
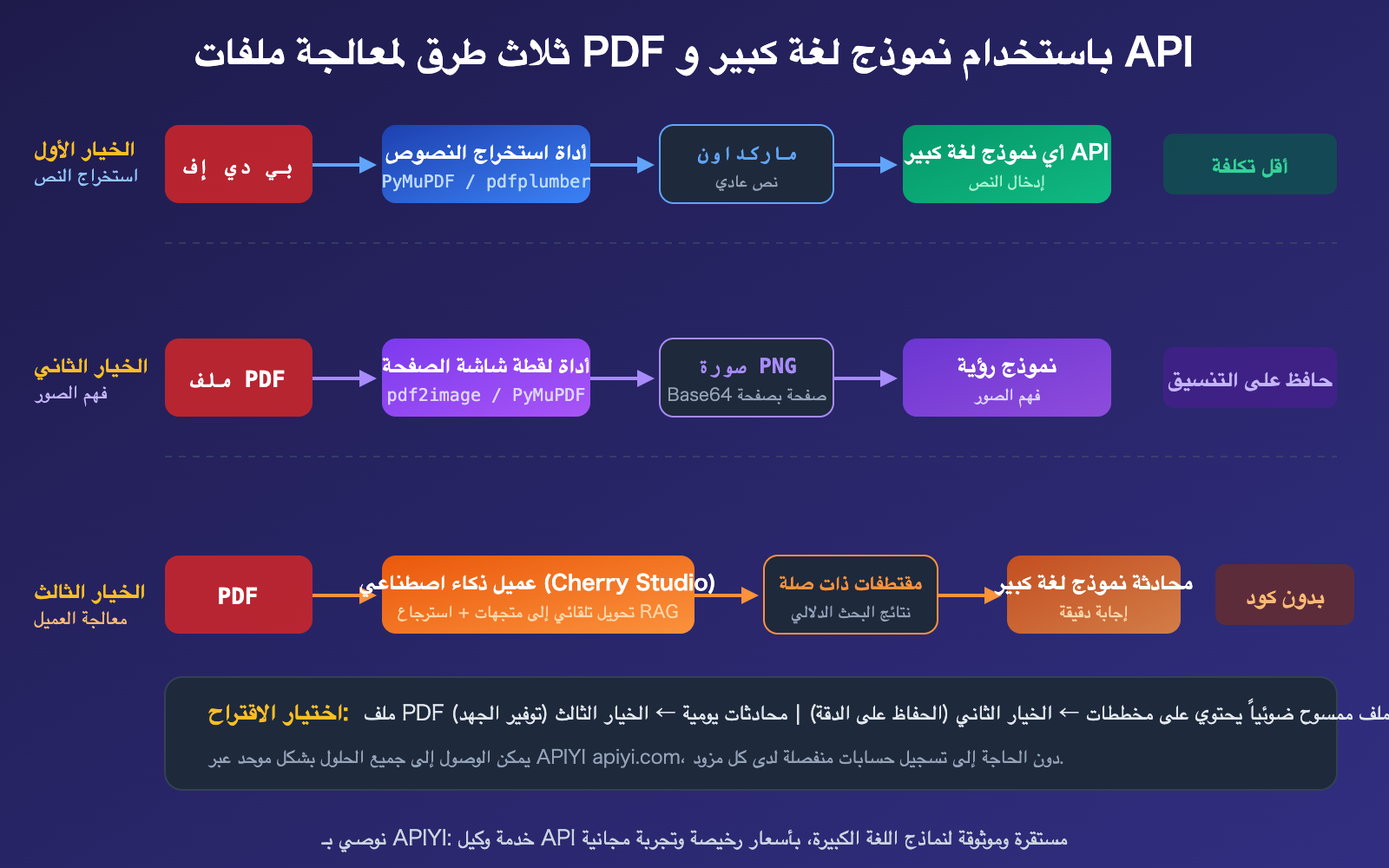
حل معالجة ملفات PDF عبر API لنماذج اللغة الكبيرة (1): الاستخراج النصي
يُعد هذا الحل الأكثر شيوعاً والأقل تكلفة. تعتمد الفكرة على استخدام مكتبات Python لتحويل ملف PDF إلى تنسيق Markdown أو نص خام، ثم إرسال هذا النص كموجه (Prompt) إلى أي API خاص بنموذج لغة كبير.
مقارنة أدوات استخراج النصوص من ملفات PDF
| الأداة | السرعة | أفضل سيناريو للاستخدام | المميزات |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14 ثانية/وثيقة | النصوص العامة + استخراج الجداول | أفضل توازن بين السرعة والجودة، مخرجات Markdown |
| pdfplumber | متوسطة | استخراج بيانات الجداول | استخراج الجداول بناءً على الإحداثيات، دقة عالية |
| Marker-PDF | ~11 ثانية/وثيقة | تحويل التنسيقات المعقدة | الحفاظ على الهيكل بشكل ممتاز، لكنه أبطأ |
| PyPDF2 | سريعة | ملفات PDF النصية البسيطة | خفيفة الوزن، مناسبة لاستخراج النصوص الأساسية |
مثال برمجي لاستخراج النصوص من PDF
import pymupdf4llm
import openai
# الخطوة 1: تحويل PDF إلى Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# الخطوة 2: الإرسال إلى API الخاص بنموذج اللغة الكبير
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"يرجى تلخيص النقاط الرئيسية في هذا التقرير:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
عرض الكود الكامل لمعالجة ملفات PDF التي تحتوي على صور (خيار فهم الصور)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""تحويل كل صفحة في PDF إلى صورة Base64"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# تحويل PDF إلى صور
images = pdf_pages_to_images("report.pdf")
# بناء رسالة تحتوي على صور متعددة
content = [{"type": "text", "text": "يرجى تحليل الرسوم البيانية والبيانات الموجودة في مستند PDF هذا:"}]
for img_b64 in images[:10]: # انتبه لعدد الصفحات لتجنب تجاوز نافذة السياق
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
نصيحة: يتوافق حل الاستخراج النصي مع جميع نماذج اللغة الكبيرة (بما في ذلك DeepSeek وLlama وغيرها التي لا تدعم PDF مباشرة). يمكنك استخدام مفتاح API واحد عبر APIYI (apiyi.com) لاختبار أي نموذج تريده.
حل معالجة ملفات PDF عبر API لنماذج اللغة الكبيرة (2): الإدخال المباشر لملفات PDF
إذا كنت تستخدم Claude أو Gemini أو GPT-4o، يمكنك إرسال ملف PDF مباشرة عبر الـ API دون الحاجة إلى أي معالجة مسبقة.
مثال على الإدخال المباشر لـ PDF عبر Claude API
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # استخدم النطاق الرئيسي لـ Claude
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "يرجى تلخيص النقاط الرئيسية في هذا المستند"}
]
}]
)
print(message.content[0].text)
مثال على الإدخال المباشر لـ PDF عبر Gemini API
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"يرجى تلخيص النقاط الرئيسية في هذا المستند"
]
)
print(response.text)
🎯 تنبيه بشأن التكلفة: على الرغم من أن الإدخال المباشر لملفات PDF هو الأكثر سهولة، إلا أن تكلفة الـ Tokens أعلى بكثير من حل النص الخام. على سبيل المثال، في ملف PDF مكون من 50 صفحة: يستهلك Gemini حوالي 12,900 token (الأرخص)، بينما يستهلك Claude حوالي 75,000-150,000 token، وGPT-4o حوالي 40,000+ token. في حالات الاستخدام واسع النطاق، تأكد من تقييم التكلفة، وننصح باستخدام ميزة مراقبة الاستهلاك عبر APIYI (apiyi.com).
حل معالجة ملفات PDF عبر API للنماذج اللغوية الكبيرة (3): المعالجة عبر العميل
بالنسبة لسيناريوهات المحادثة اليومية (بعيداً عن تطوير الأكواد)، يعد استخدام عميل AI هو الطريقة الأكثر سهولة. لنأخذ تطبيق Cherry Studio كمثال؛ فهو يدعم سحب ملفات PDF وإفلاتها مباشرة، حيث يقوم تلقائياً بإتمام عملية التحويل إلى متجهات (Vectorization) والبحث الدلالي، ثم يرسل فقط الأجزاء ذات الصلة إلى نموذج اللغة الكبير.
مزايا حل المعالجة عبر العميل
- بدون برمجة: اسحب ملف PDF وابدأ المحادثة فوراً.
- توفير الـ Token: من خلال تقنية RAG، يتم إرسال الأجزاء ذات الصلة فقط بدلاً من كامل محتوى الملف.
- التبديل بين النماذج: يدعم إعداد منصات API متعددة مثل APIYI.
- قاعدة معرفية محلية: يمكنك إنشاء قاعدة معرفية من عدة ملفات PDF والاستعلام عنها بشكل متكرر.
ملاحظات عند معالجة ملفات PDF عبر العميل
- التحكم في حجم الملف: كثرة صفحات ملف PDF قد تؤدي إلى استغراق وقت طويل في عملية التحويل إلى متجهات.
- الانتباه لتكلفة الـ Token: على الرغم من أن تقنية RAG تضغط المحتوى، إلا أن المستندات الطويلة قد تظل مكلفة.
- اختيار النموذج المناسب: استخدم نماذج اقتصادية للأسئلة البسيطة (مثل GPT-4o-mini)، واستخدم النماذج الرائدة للتحليلات المعقدة.
نصيحة: قم بإعداد APIYI (عبر apiyi.com) كمزود لخدمة الـ API في تطبيقات مثل Cherry Studio، وستتمكن من الوصول إلى جميع النماذج مثل Claude وGemini وGPT باستخدام مفتاح API واحد.

الأسئلة الشائعة
س1: ما هي الطريقة المثلى لمعالجة ملفات PDF باستخدام DeepSeek؟
لا يدعم API الخاص بـ DeepSeek حالياً إدخال ملفات PDF مباشرة. نوصي باستخدام الخيار الأول (الاستخراج النصي): قم أولاً بتحويل ملف PDF إلى نص Markdown باستخدام مكتبة PyMuPDF4LLM، ثم استخدم APIYI (apiyi.com) لاستدعاء نموذج DeepSeek لتحليل النص. إذا كان ملف PDF يحتوي على مخططات أو رسوم بيانية، يمكنك تحويل الصفحات إلى صور واستخدام نموذج يدعم الرؤية (مثل GPT-4o) لفهم محتواها.
س2: أيهما أفضل: الإدخال المباشر لملف PDF أم الاستخراج النصي؟
يعتمد الأمر على محتوى ملف PDF. بالنسبة لملفات PDF النصية البحتة (مثل العقود والتقارير)، فإن النتائج متقاربة، لكن الاستخراج النصي أكثر توفيراً للتكلفة. أما الملفات التي تحتوي على مخططات، أو تنسيقات معقدة، أو مستندات ممسوحة ضوئياً، فإن الإدخال المباشر يعطي نتائج أفضل بكثير لأن النموذج يستطيع فهم النصوص والعناصر البصرية في آن واحد. ننصح بالبدء باختبار الاستخراج النصي، والتحول للإدخال المباشر إذا لم تكن النتائج مرضية.
س3: كيف يمكنني التحكم في تكلفة الـ Token عند معالجة ملفات PDF؟
إليك بعض النصائح العملية:
- في سيناريوهات المعالجة بكميات كبيرة، استخدم Gemini (يستهلك 258 Token فقط لكل صفحة، وهو الأقل تكلفة).
- قم باستخراج الصفحات التي تحتاجها فقط، ولا تقم برفع المستند بالكامل دفعة واحدة.
- بعد الاستخراج النصي، قم بعمل ملخص أو تقسيم للنص لتجنب إدخال نصوص طويلة جداً.
- راقب الاستهلاك الفعلي من خلال لوحة التحكم في منصة APIYI (apiyi.com).
الخلاصة
النقاط الجوهرية لدعم إدخال ملفات PDF في نماذج اللغة الكبيرة:
- دعم أصلي في بعض النماذج: تدعم نماذج Claude (حتى 600 صفحة)، وGemini (حتى 1000 صفحة)، وGPT-4o (حتى 100 صفحة) رفع ملفات PDF مباشرة، بينما لا يدعم DeepSeek ذلك حالياً.
- ثلاثة خيارات حسب الحاجة: الاستخراج النصي هو الأقل تكلفة ومتوافق مع جميع النماذج، الإدخال المباشر هو الأكثر سهولة ولكنه أغلى ثمناً، بينما المعالجة عبر العميل (Client-side) مناسبة للمحادثات اليومية.
- فروق كبيرة في التكلفة: بالنسبة لنفس ملف PDF، يعتبر الإدخال المباشر عبر Gemini هو الأرخص (~258 Token لكل صفحة)، ويمكن لخيارات الاستخراج النصي الصرف تقليل التكلفة بنسبة تزيد عن 50%.
اختر الطريقة المناسبة لسيناريو عملك، وستتمكن من معالجة ملفات PDF بكفاءة دون القلق بشأن تكاليف الـ Token المرتفعة.
نوصي باستخدام منصة APIYI (apiyi.com) للوصول الموحد إلى مختلف النماذج، حيث توفر المنصة رصيداً مجانياً وتدعم استدعاء API لجميع النماذج الرئيسية مثل Claude، وGemini، وGPT، وDeepSeek.
📚 المراجع
-
دليل إدخال ملفات PDF في OpenAI: الوثائق الرسمية للإرسال المباشر لملفات PDF عبر API
- الرابط:
platform.openai.com/docs/guides/pdf-files - الوصف: المواصفات والقيود التفصيلية لإدخال ملفات PDF في نموذج GPT-4o
- الرابط:
-
وثائق دعم PDF في Claude: دليل معالجة ملفات PDF الرسمي من Anthropic
- الرابط:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - الوصف: الطرق الثلاث لإدخال ملفات PDF في Claude وأفضل الممارسات
- الرابط:
-
معالجة المستندات في Gemini: شرح قدرات فهم المستندات الرسمي من Google
- الرابط:
ai.google.dev/gemini-api/docs/document-processing - الوصف: قيود معالجة ملفات PDF في Gemini وتسعيرها
- الرابط:
-
وثائق PyMuPDF4LLM: أداة استخراج النصوص من ملفات PDF
- الرابط:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - الوصف: الأداة الأسرع لتحويل ملفات PDF إلى صيغة Markdown
- الرابط:
-
وثائق منصة APIYI: الوصول الموحد لواجهات برمجة التطبيقات (API) لنماذج اللغة الكبيرة
- الرابط:
docs.apiyi.com - الوصف: كيفية الحصول على مفتاح API، قائمة النماذج، وأمثلة على استدعاء النموذج
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تبادل الخبرات: نرحب بمناقشاتكم في قسم التعليقات، وللمزيد من المعلومات يمكنكم زيارة مركز وثائق APIYI عبر الرابط docs.apiyi.com