
작성자 주: GPT-4o, Claude, Gemini, DeepSeek 등 대규모 언어 모델 API의 PDF 입력 지원 현황과 텍스트 추출, 이미지 이해, 클라이언트 처리라는 3가지 해결 방안을 자세히 설명합니다.
"대규모 언어 모델 API에 PDF를 직접 넣을 수 있나요?" 이는 개발자들이 가장 많이 묻는 질문 중 하나예요. 답은 생각보다 복잡합니다. 일부 모델은 PDF 입력을 기본적으로 지원하지만(Claude, Gemini, GPT-4o), DeepSeek와 같은 모델은 아직 지원하지 않거든요. 게다가 기본 지원 방식을 사용하면 텍스트 추출 방식보다 토큰 비용이 훨씬 많이 듭니다.
이번 글에서는 실제 개발 관점에서 주요 대규모 언어 모델 API의 PDF 지원 현황을 정리하고, 3가지 PDF 처리 방식에 대한 완벽한 비교와 코드 예제를 통해 여러분의 상황에 가장 적합한 방법을 선택할 수 있도록 도와드릴게요.
핵심 가치: 이 글을 읽고 나면 각 대규모 언어 모델의 PDF 지원 수준을 명확히 파악하고, 가장 경제적인 방법부터 가장 간편한 방법까지 3가지 처리 전략을 마스터하게 될 거예요.

대규모 언어 모델 API의 PDF 입력 지원 핵심 요약
| 요점 | 설명 | 가치 |
|---|---|---|
| 3개 모델 기본 지원 | Claude(600페이지), Gemini(1000페이지), GPT-4o(100페이지) 지원 | 전처리 없이 API로 바로 전송 가능 |
| DeepSeek 등 미지원 | 텍스트 추출이나 이미지 변환 과정 필요 | 별도의 전처리 파이프라인 구축 필요 |
| 비용 차이 극심 | 기본 PDF는 페이지당 258-3000 토큰, 텍스트 추출 시 300-1500 | 대량 처리 시 적절한 선택으로 비용 10배 절감 가능 |
| 3가지 방식의 장점 | 텍스트 추출, 이미지 이해, 클라이언트 처리 | 상황에 맞춰 최적의 방식 선택 |
대규모 언어 모델 API의 PDF 지원 현황
반가운 소식은 2025년부터 주요 대규모 언어 모델들이 API를 통한 PDF 직접 전송을 지원하기 시작했다는 점입니다. 이들의 구현 방식은 대체로 비슷합니다. PDF에서 텍스트를 추출함과 동시에 각 페이지를 이미지로 렌더링하여, 모델이 텍스트 내용과 시각적 요소(차트, 레이아웃 등)를 동시에 이해하도록 합니다.
하지만 아쉬운 점은 이러한 '텍스트 + 이미지 듀얼 채널' 처리 방식의 토큰 소모량이 순수 텍스트 입력보다 훨씬 많다는 것입니다. 50페이지 분량의 보고서를 PDF로 직접 전송하면 10만 토큰 이상이 소모될 수 있지만, 텍스트를 미리 추출해 전달하면 3만 토큰 정도로 충분할 수 있습니다.
주요 모델 API의 PDF 지원 상세 비교
| 모델 | PDF 지원 여부 | 최대 페이지 | 최대 파일 크기 | 전송 방식 | 페이지당 토큰 비용 |
|---|---|---|---|---|---|
| Claude | 지원 (GA) | 600 페이지 | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | 지원 | 1000 페이지 | 2 GB (Files API) | Inline / Files API / URL | ~258 (가장 저렴) |
| GPT-4o | 지원 | 100 페이지 | 32 MB | Base64 / File Upload | ~765 (이미지) + 텍스트 |
| DeepSeek | 미지원 | — | — | 전처리 필요 | — |
| Llama / Qwen | 미지원 | — | — | 전처리 필요 | — |
🎯 선택 가이드: 대량의 PDF를 처리해야 한다면 비용이 가장 저렴한 Gemini(페이지당 약 258 토큰, 기본 텍스트 추출 무료)를 추천합니다. 가장 긴 문서를 다뤄야 할 때도 1000페이지를 지원하는 Gemini가 유리합니다. Claude는 이해 정확도가 뛰어나 고정밀 작업에 적합합니다. 이 모든 모델은 APIYI(apiyi.com) 플랫폼을 통해 통합적으로 호출할 수 있습니다.
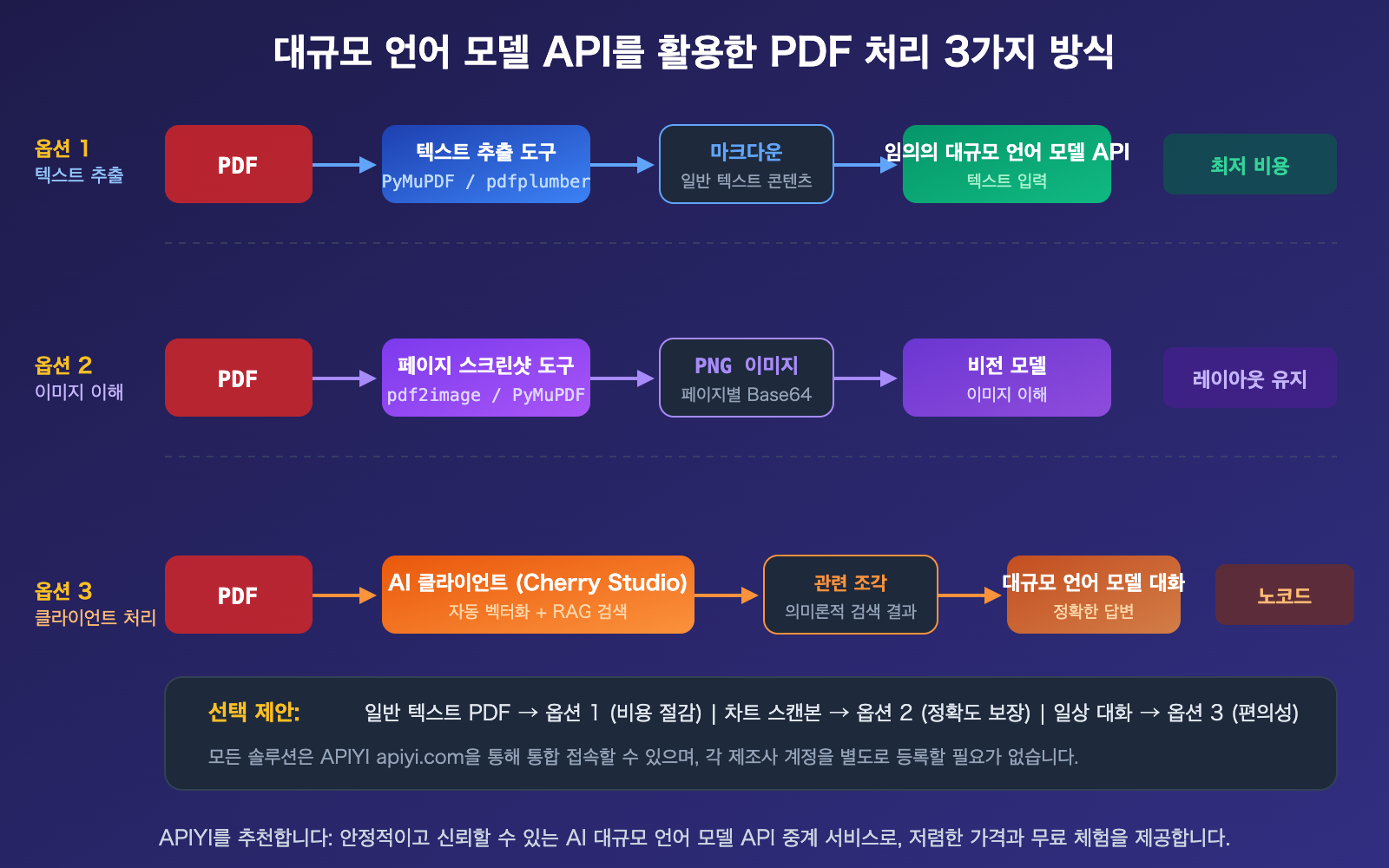
대규모 언어 모델 API PDF 처리 솔루션 1: 텍스트 추출 방식
가장 범용적이고 비용 효율적인 방식입니다. 먼저 Python 라이브러리를 사용해 PDF를 마크다운이나 일반 텍스트로 추출한 다음, 해당 텍스트를 프롬프트로 만들어 대규모 언어 모델 API에 전달하는 방식이죠.
PDF 텍스트 추출 도구 비교
| 도구 | 속도 | 최적 활용 사례 | 특징 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14초/문서 | 일반 텍스트 + 표 추출 | 속도와 품질의 최적 균형, 마크다운 출력 |
| pdfplumber | 보통 | 표 데이터 추출 | 좌표 기반 표 추출, 높은 정확도 |
| Marker-PDF | ~11초/문서 | 복잡한 레이아웃 보존 | 구조 보존력이 가장 우수하나 속도가 느림 |
| PyPDF2 | 빠름 | 단순 텍스트 PDF | 가볍고 기본적인 텍스트 추출에 적합 |
PDF 텍스트 추출 코드 예시
import pymupdf4llm
import openai
# 1단계: PDF를 마크다운으로 변환
md_text = pymupdf4llm.to_markdown("report.pdf")
# 2단계: 대규모 언어 모델 API로 전달
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"이 보고서의 핵심 요점을 정리해 주세요:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
PDF 이미지 포함 처리 전체 코드 보기 (이미지 이해 솔루션)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""PDF의 각 페이지를 Base64 이미지로 변환"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# PDF를 이미지로 변환
images = pdf_pages_to_images("report.pdf")
# 다중 이미지 메시지 구성
content = [{"type": "text", "text": "이 PDF 문서에 있는 차트와 데이터를 분석해 주세요:"}]
for img_b64 in images[:10]: # 토큰 초과 방지를 위해 페이지 수 제한
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
제언: 텍스트 추출 방식은 PDF를 직접 지원하지 않는 모델(DeepSeek, Llama 등)을 포함한 모든 대규모 언어 모델과 호환됩니다. APIYI(apiyi.com)를 통하면 동일한 API 키로 다양한 모델을 호출하여 테스트할 수 있습니다.
대규모 언어 모델 API PDF 처리 솔루션 2: 네이티브 PDF 입력
Claude, Gemini 또는 GPT-4o를 사용 중이라면 별도의 전처리 과정 없이 API를 통해 PDF를 직접 전달할 수 있습니다.
Claude API 네이티브 PDF 입력 예시
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Claude는 루트 도메인 사용
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "이 문서의 핵심 요점을 정리해 주세요"}
]
}]
)
print(message.content[0].text)
Gemini API 네이티브 PDF 입력 예시
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"이 문서의 핵심 요점을 정리해 주세요"
]
)
print(response.text)
🎯 비용 안내: 네이티브 PDF 입력 방식은 편리하지만, 순수 텍스트 방식보다 토큰 비용이 상당히 높습니다. 50페이지 PDF를 예로 들면, Gemini는 약 12,900 토큰(가장 저렴), Claude는 약 75,000~150,000 토큰, GPT-4o는 약 40,000 토큰 이상이 소모됩니다. 대량 처리 시에는 반드시 비용을 검토하시고, APIYI(apiyi.com)의 사용량 통계 기능을 통해 소모량을 모니터링하는 것을 권장합니다.
대규모 언어 모델 API PDF 처리 솔루션 3: 클라이언트 활용
일상적인 대화 시나리오(코드 개발이 아닌 경우)에서는 AI 클라이언트를 사용하는 것이 가장 간편합니다. Cherry Studio를 예로 들면, PDF 파일을 직접 드래그 앤 드롭하여 자동으로 벡터화하고 의미론적 검색을 수행하며, 관련 내용만 대규모 언어 모델에 전달할 수 있습니다.
클라이언트 솔루션의 장점
- 코드 제로: PDF를 끌어다 놓기만 하면 바로 대화 시작
- 토큰 절약: RAG 검색을 통해 전체 내용이 아닌 관련 조각만 전송
- 모델 간 전환: APIYI 등 여러 API 플랫폼 구성 지원
- 로컬 지식 베이스: 여러 PDF를 지식 베이스로 구축하여 반복적으로 조회 가능
클라이언트 사용 시 주의사항
- 파일 크기 제어: PDF 페이지가 너무 많으면 벡터화 시간이 길어질 수 있음
- 토큰 비용 주의: RAG가 내용을 압축하더라도 긴 문서는 여전히 높은 비용이 발생할 수 있음
- 적절한 모델 선택: 간단한 질문은 저렴한 모델(예: GPT-4o-mini)을, 복잡한 분석은 플래그십 모델을 사용하세요
제안: Cherry Studio와 같은 클라이언트에서 APIYI(apiyi.com)를 API 제공업체로 구성하면, 하나의 키로 Claude, Gemini, GPT 등 모든 모델에 액세스할 수 있습니다.

자주 묻는 질문 (FAQ)
Q1: DeepSeek으로 PDF를 처리하려면 어떤 방식을 써야 하나요?
현재 DeepSeek API는 PDF 직접 입력을 지원하지 않습니다. 따라서 '방식 1(텍스트 추출)'을 권장합니다. 먼저 PyMuPDF4LLM을 사용하여 PDF를 마크다운 텍스트로 변환한 뒤, APIYI(apiyi.com)를 통해 DeepSeek API를 호출하여 분석하는 방식입니다. 만약 PDF에 도표가 포함되어 있다면, 해당 페이지를 이미지로 변환한 후 Vision 기능을 지원하는 모델(예: GPT-4o)을 사용하여 이해시키는 것이 좋습니다.
Q2: 네이티브 PDF 입력과 텍스트 추출 방식 중 무엇이 더 효과적인가요?
PDF 내용에 따라 다릅니다. 텍스트 위주의 PDF(계약서, 보고서 등)는 두 방식의 결과가 비슷하며, 텍스트 추출 방식이 비용 면에서 더 경제적입니다. 반면 도표, 복잡한 레이아웃, 스캔본이 포함된 PDF는 모델이 텍스트와 시각적 요소를 동시에 이해할 수 있는 네이티브 입력 방식이 훨씬 효과적입니다. 우선 텍스트 추출 방식으로 테스트해 보시고, 결과가 만족스럽지 않을 때 네이티브 입력으로 전환하는 것을 추천합니다.
Q3: PDF 처리 시 토큰 비용을 어떻게 제어하나요?
몇 가지 실용적인 팁을 알려드립니다:
- 대량 처리 시 Gemini를 우선적으로 고려하세요(페이지당 258 토큰으로 비용이 가장 저렴합니다).
- 전체 문서를 한 번에 전달하지 말고, 필요한 페이지만 추출하여 사용하세요.
- 텍스트 추출 후 요약이나 청크(Chunk) 단위로 나누어 처리하여 너무 긴 텍스트가 한꺼번에 입력되지 않도록 하세요.
- APIYI(apiyi.com)의 사용량 대시보드를 통해 실제 소모량을 상시 모니터링하세요.
요약
대규모 언어 모델 API의 PDF 입력 지원 핵심 포인트:
- 일부 모델은 네이티브 지원: Claude(600페이지), Gemini(1000페이지), GPT-4o(100페이지)는 PDF 직접 업로드가 가능하지만, DeepSeek 등은 아직 지원하지 않습니다.
- 상황에 맞는 3가지 방식 선택: 텍스트 추출 방식은 비용이 가장 저렴하고 모든 모델과 호환되며, 네이티브 입력은 가장 편리하지만 비용이 높습니다. 클라이언트 기반 처리는 일상적인 대화에 적합합니다.
- 비용 차이: 동일한 PDF라도 Gemini 네이티브 입력이 가장 저렴하며(페이지당 약 258 토큰), 순수 텍스트 추출 방식을 사용하면 비용을 50% 이상 더 절감할 수 있습니다.
사용자의 상황에 맞는 적절한 방식을 선택하면 높은 토큰 비용에 대한 부담 없이 효율적으로 PDF를 처리할 수 있습니다.
APIYI(apiyi.com)를 통해 주요 모델들을 통합적으로 이용해 보세요. 플랫폼에서 제공하는 무료 크레딧을 통해 Claude, Gemini, GPT, DeepSeek 등 모든 주류 모델의 API를 간편하게 호출할 수 있습니다.
📚 참고 자료
-
OpenAI PDF 입력 가이드: PDF를 API로 직접 업로드하는 공식 문서
- 링크:
platform.openai.com/docs/guides/pdf-files - 설명: GPT-4o PDF 입력에 대한 상세 사양 및 제한 사항
- 링크:
-
Claude PDF 지원 문서: Anthropic 공식 PDF 처리 가이드
- 링크:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - 설명: Claude PDF 입력의 3가지 방식 및 모범 사례
- 링크:
-
Gemini 문서 처리: Google 공식 문서 이해 능력 설명
- 링크:
ai.google.dev/gemini-api/docs/document-processing - 설명: Gemini PDF 처리의 제한 사항 및 요금 정책
- 링크:
-
PyMuPDF4LLM 문서: PDF 텍스트 추출 도구
- 링크:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 설명: 가장 빠른 PDF-Markdown 변환 도구
- 링크:
-
APIYI 플랫폼 문서: 주요 대규모 언어 모델 API 통합 접속
- 링크:
docs.apiyi.com - 설명: API 키 획득, 모델 목록 및 모델 호출 예제
- 링크:
작성자: APIYI 기술팀
기술 교류: 댓글로 자유롭게 의견을 나눠주세요. 더 많은 자료는 APIYI 문서 센터(docs.apiyi.com)에서 확인하실 수 있습니다.