
作者注:详解 GPT-4o、Claude、Gemini、DeepSeek 等大模型 API 对 PDF 输入的支持情况,以及文字化提取、图片理解、客户端 3 种处理方案
"大模型 API 能不能直接传 PDF 进去?"这是开发者最常问的问题之一。答案比你想象的复杂——部分模型已原生支持 PDF 输入(Claude、Gemini、GPT-4o),但 DeepSeek 等模型尚不支持,且原生支持的 Token 成本远高于文字化提取方案。
本文将从实际开发角度出发,梳理各主流大模型 API 的 PDF 支持现状,并给出 3 种 PDF 处理方案的完整对比和代码示例,帮你选出最适合自己场景的方式。
核心价值: 读完本文,你将清楚每个大模型对 PDF 的支持程度,并掌握从最省钱到最省事的 3 种处理方案。

大模型 API PDF 输入支持核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| 3 家已原生支持 PDF | Claude(600 页)、Gemini(1000 页)、GPT-4o(100 页)均已支持 | 无需预处理,API 直传即可 |
| DeepSeek 等尚不支持 | 需前置文字化提取或图片转换 | 需搭建预处理流程 |
| 成本差异巨大 | 原生 PDF 每页 258-3000 tokens,纯文本提取仅 300-1500 | 大批量场景选对方案可省 10 倍成本 |
| 3 种方案各有适用场景 | 文字化提取、图片理解、客户端处理 | 按需选择,不必强求一种方案 |
大模型 API 对 PDF 的原生支持现状
好消息是,2025 年以来主流大模型已陆续支持 API 直传 PDF。它们的实现方式基本一致——提取 PDF 中的文本,同时将每一页渲染为图片,让模型同时理解文字内容和视觉元素(图表、版面布局等)。
坏消息是,这种"文本 + 图片双通道"处理方式的 Token 消耗远高于纯文本输入。一份 50 页的报告如果直接传 PDF,可能消耗 10 万+ tokens,而先提取文本再传入可能只需要 3 万 tokens。
各大模型 API PDF 支持详细对比
| 模型 | 是否支持 PDF | 最大页数 | 最大文件 | 传输方式 | 每页 Token 成本 |
|---|---|---|---|---|---|
| Claude | 支持(GA) | 600 页 | 32 MB | Base64 / URL / Files API | 1500-3000 |
| Gemini | 支持 | 1000 页 | 2 GB(Files API) | Inline / Files API / URL | ~258(最便宜) |
| GPT-4o | 支持 | 100 页 | 32 MB | Base64 / File Upload | ~765(图片)+ 文本 |
| DeepSeek | 不支持 | — | — | 需预处理 | — |
| Llama / Qwen | 不支持 | — | — | 需预处理 | — |
🎯 选择建议: 如果你需要大批量处理 PDF,Gemini 的成本最低(每页约 258 tokens,原生文本提取免费)。如果需要最长文档支持,也是 Gemini 最强(1000 页)。Claude 在理解准确度上表现出色,适合高精度场景。这些模型都可以通过 API易 apiyi.com 平台统一接入调用。
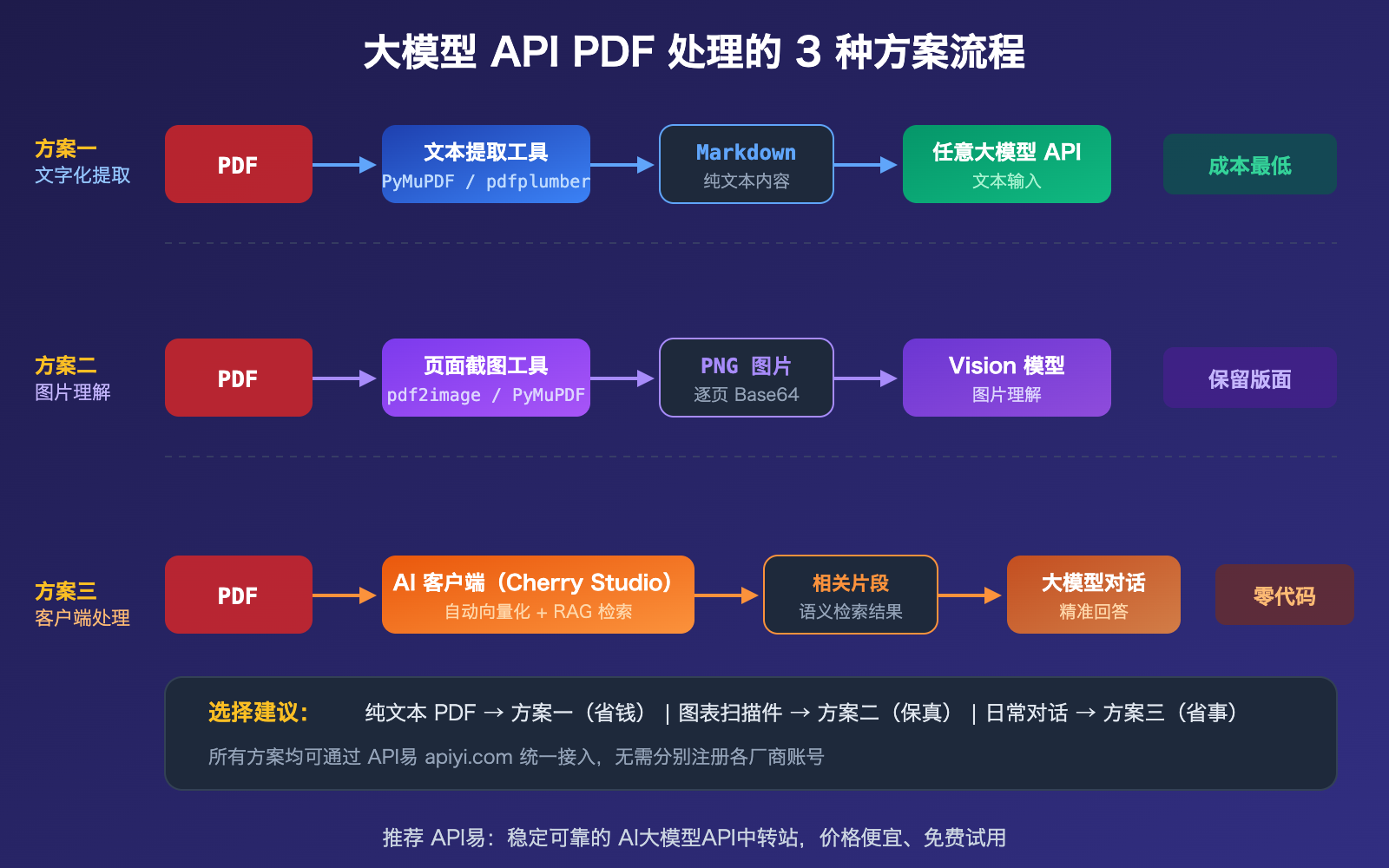
大模型 API PDF 处理方案一:文字化提取
这是最通用、成本最低的方案。先用 Python 库将 PDF 提取为 Markdown 或纯文本,再将文本作为 prompt 传给任意大模型 API。
PDF 文字化提取工具对比
| 工具 | 速度 | 最佳场景 | 特点 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/文档 | 通用文本 + 表格提取 | 速度与质量最佳平衡,输出 Markdown |
| pdfplumber | 中等 | 表格数据提取 | 坐标级表格提取,精度高 |
| Marker-PDF | ~11s/文档 | 复杂版面保真转换 | 结构保留最好,速度较慢 |
| PyPDF2 | 快 | 简单纯文本 PDF | 轻量级,适合基础文本提取 |
PDF 文字化提取代码示例
import pymupdf4llm
import openai
# 步骤1: PDF 转 Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# 步骤2: 传给大模型 API
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"请总结这份报告的核心要点:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
查看 PDF 带图处理的完整代码(图片理解方案)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""将 PDF 每页转为 Base64 图片"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# PDF 转图片
images = pdf_pages_to_images("report.pdf")
# 构建多图消息
content = [{"type": "text", "text": "请分析这份 PDF 文档中的图表和数据:"}]
for img_b64 in images[:10]: # 注意控制页数,避免 Token 超量
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
建议: 文字化提取方案兼容所有大模型(包括 DeepSeek、Llama 等不支持 PDF 的模型),通过 API易 apiyi.com 可以用同一个 API Key 调用任意模型进行测试。
大模型 API PDF 处理方案二:原生 PDF 输入
如果你使用的是 Claude、Gemini 或 GPT-4o,可以直接将 PDF 通过 API 传入,无需任何预处理。
Claude API 原生 PDF 输入示例
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Claude 用根域名
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "请总结这份文档的核心要点"}
]
}]
)
print(message.content[0].text)
Gemini API 原生 PDF 输入示例
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"请总结这份文档的核心要点"
]
)
print(response.text)
🎯 成本提醒: 原生 PDF 输入虽然最方便,但 Token 成本显著高于纯文本方案。以一份 50 页 PDF 为例:Gemini 约消耗 12,900 tokens(最便宜),Claude 约 75,000-150,000 tokens,GPT-4o 约 40,000+ tokens。大批量场景务必评估成本,建议通过 API易 apiyi.com 的用量统计功能监控消耗。
大模型 API PDF 处理方案三:客户端处理
对于日常对话场景(非代码开发),使用 AI 客户端是最省事的方式。以 Cherry Studio 为例,它支持直接拖入 PDF 附件,自动完成向量化和语义检索,只将相关片段发送给大模型。
客户端方案优势
- 零代码: 拖入 PDF 即可开始对话
- 节省 Token: 通过 RAG 检索只发送相关片段,而非全文
- 多模型切换: 支持配置 API易等多个 API 平台
- 本地知识库: 可将多份 PDF 建成知识库,反复查询
使用客户端处理 PDF 的注意事项
- 控制文件大小: PDF 页数过多会导致向量化时间过长
- 注意 Token 费用: 虽然 RAG 会压缩内容,但长文档仍可能产生较高费用
- 选择合适模型: 简单问答可用便宜模型(如 GPT-4o-mini),复杂分析用旗舰模型
建议: 在 Cherry Studio 等客户端中配置 API易 apiyi.com 作为 API 提供商,即可通过一个 Key 访问 Claude、Gemini、GPT 等所有模型。

常见问题
Q1: 用 DeepSeek 处理 PDF 应该用哪种方案?
DeepSeek API 目前不支持直接输入 PDF。推荐使用方案一(文字化提取):先用 PyMuPDF4LLM 将 PDF 转为 Markdown 文本,再通过 API易 apiyi.com 调用 DeepSeek API 进行分析。如果 PDF 包含图表,可以先将页面转为图片,使用支持 Vision 的模型(如 GPT-4o)进行理解。
Q2: 原生 PDF 输入和文字化提取哪个效果更好?
取决于 PDF 内容。纯文本 PDF(合同、报告)两者效果接近,文字化提取更省钱。包含图表、复杂版面或扫描件的 PDF,原生输入效果明显更好,因为模型能同时理解文字和视觉元素。建议先用文字化方案测试,效果不够再切换原生输入。
Q3: 如何控制 PDF 处理的 Token 费用?
几个实用技巧:
- 大批量场景优先用 Gemini(每页仅 258 tokens,成本最低)
- 只提取需要的页面,不要一次传整份文档
- 文字化提取后先做摘要/分块,避免传入过长文本
- 通过 API易 apiyi.com 的用量面板监控实际消耗
总结
大模型 API PDF 输入支持的核心要点:
- 部分模型已原生支持: Claude(600 页)、Gemini(1000 页)、GPT-4o(100 页)可直接传 PDF,DeepSeek 等暂不支持
- 3 种方案按需选择: 文字化提取成本最低且兼容所有模型,原生输入最方便但贵,客户端处理适合日常对话
- 成本差异显著: 同一份 PDF,Gemini 原生输入最便宜(~258 tokens/页),纯文本提取方案可再降 50% 以上成本
根据你的场景选对方案,就能高效处理 PDF 而不被高额 Token 费用吓到。
推荐通过 API易 apiyi.com 统一接入各大模型,平台提供免费额度,支持 Claude、Gemini、GPT、DeepSeek 等全部主流模型的 API 调用。
📚 参考资料
-
OpenAI PDF 输入指南: API 直传 PDF 的官方文档
- 链接:
platform.openai.com/docs/guides/pdf-files - 说明: GPT-4o PDF 输入的详细规格和限制
- 链接:
-
Claude PDF 支持文档: Anthropic 官方 PDF 处理指南
- 链接:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - 说明: Claude PDF 输入的 3 种方式和最佳实践
- 链接:
-
Gemini 文档处理: Google 官方文档理解能力说明
- 链接:
ai.google.dev/gemini-api/docs/document-processing - 说明: Gemini PDF 处理的限制和定价
- 链接:
-
PyMuPDF4LLM 文档: PDF 文字化提取工具
- 链接:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 说明: 速度最快的 PDF 转 Markdown 工具
- 链接:
-
API易平台文档: 统一接入各大模型 API
- 链接:
docs.apiyi.com - 说明: API Key 获取、模型列表和调用示例
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心