
Авторское примечание: подробный разбор поддержки PDF в API больших языковых моделей (GPT-4o, Claude, Gemini, DeepSeek и др.), а также три способа обработки: текстовая экстракция, анализ изображений и клиентская обработка.
«Можно ли передать PDF напрямую в API большой языковой модели?» — это один из самых частых вопросов от разработчиков. Ответ сложнее, чем кажется: некоторые модели уже поддерживают PDF «из коробки» (Claude, Gemini, GPT-4o), в то время как другие, например DeepSeek, пока нет. Кроме того, нативная поддержка обходится значительно дороже по токенам, чем предварительная текстовая экстракция.
В этой статье мы разберем текущую ситуацию с поддержкой PDF в API популярных моделей и сравним 3 способа обработки PDF с примерами кода, чтобы вы могли выбрать оптимальный вариант для своего проекта.
Ключевая ценность: после прочтения вы будете точно знать, какие модели работают с PDF, и освоите три метода обработки — от самых бюджетных до самых простых в реализации.
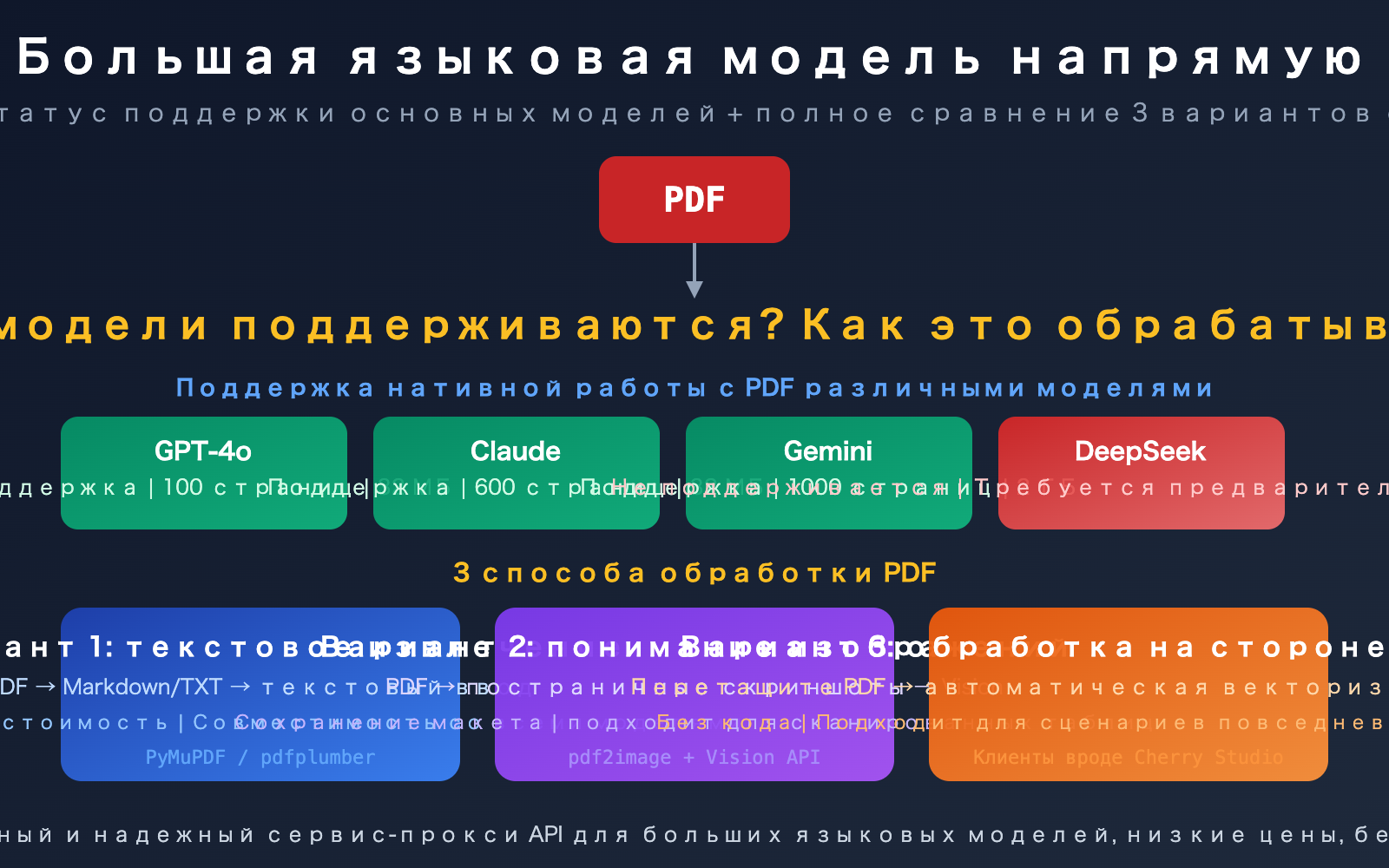
Основные моменты поддержки PDF в API больших языковых моделей
| Пункт | Описание | Ценность |
|---|---|---|
| 3 модели с нативной поддержкой PDF | Claude (600 стр.), Gemini (1000 стр.), GPT-4o (100 стр.) | Не нужна предобработка, прямая передача через API |
| DeepSeek и другие пока не поддерживают | Требуется предварительное извлечение текста или конвертация в изображения | Нужно настраивать конвейер предобработки |
| Огромная разница в стоимости | Нативный PDF: 258–3000 токенов на страницу; чистый текст: 300–1500 | Правильный выбор стратегии экономит до 10 раз на больших объемах |
| 3 сценария использования | Извлечение текста, визуальное понимание, клиентская обработка | Выбирайте под задачу, не обязательно использовать один метод |
Текущая ситуация с нативной поддержкой PDF в API больших языковых моделей
Хорошая новость: с 2025 года основные большие языковые модели начали поддерживать прямую передачу PDF через API. Их подход практически идентичен: они извлекают текст из PDF и одновременно рендерят каждую страницу как изображение, позволяя модели понимать как текстовое содержимое, так и визуальные элементы (графики, верстку и т.д.).
Плохая новость: такой метод обработки «текст + изображение» потребляет значительно больше токенов, чем просто текстовый ввод. Если отправить 50-страничный отчет в формате PDF напрямую, это может «съесть» более 100 000 токенов, тогда как при предварительном извлечении текста может потребоваться всего 30 000 токенов.
Подробное сравнение поддержки PDF в API различных моделей
| Модель | Поддержка PDF | Макс. страниц | Макс. размер файла | Способ передачи | Стоимость (токены/стр.) |
|---|---|---|---|---|---|
| Claude | Да (GA) | 600 стр. | 32 МБ | Base64 / URL / Files API | 1500-3000 |
| Gemini | Да | 1000 стр. | 2 ГБ (Files API) | Inline / Files API / URL | ~258 (самый дешевый) |
| GPT-4o | Да | 100 стр. | 32 МБ | Base64 / Загрузка файла | ~765 (изображение) + текст |
| DeepSeek | Нет | — | — | Нужна предобработка | — |
| Llama / Qwen | Нет | — | — | Нужна предобработка | — |
🎯 Совет по выбору: Если вам нужно обрабатывать большие объемы PDF, Gemini предлагает самую низкую стоимость (около 258 токенов на страницу, нативное извлечение текста бесплатно). Если нужна работа с самыми длинными документами, Gemini также вне конкуренции (1000 страниц). Claude демонстрирует отличную точность понимания, что подходит для сценариев, требующих высокого качества. Все эти модели можно подключить через сервис-прокси API APIYI (apiyi.com).
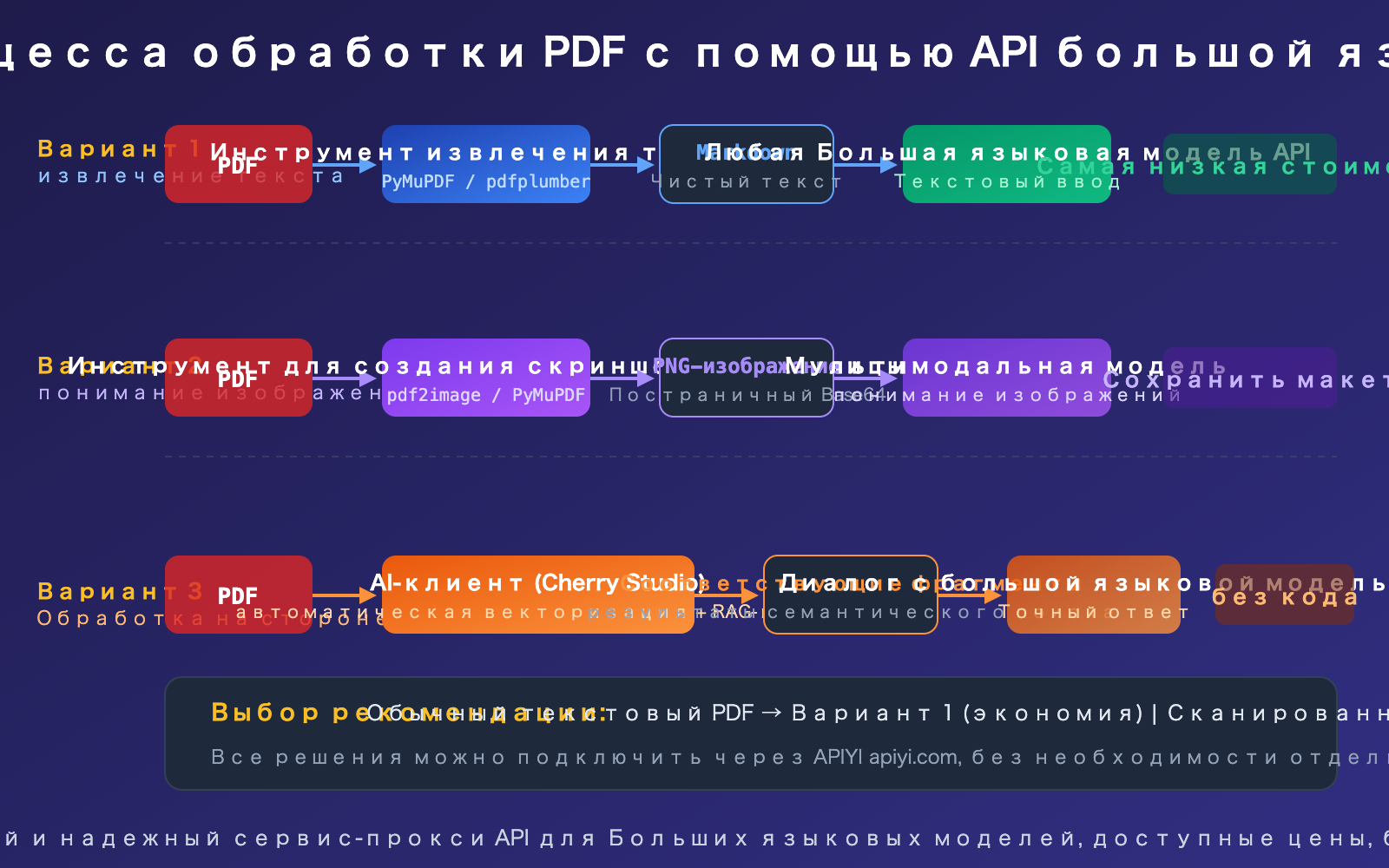
Вариант 1 обработки PDF через API большой языковой модели: текстовая экстракция
Это самый универсальный и бюджетный способ. Сначала мы используем Python-библиотеки для преобразования PDF в Markdown или обычный текст, а затем передаем этот текст в качестве промпта в API любой большой языковой модели.
Сравнение инструментов для текстовой экстракции PDF
| Инструмент | Скорость | Лучший сценарий | Особенности |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14с/док | Общий текст + таблицы | Идеальный баланс скорости и качества, вывод в Markdown |
| pdfplumber | Средняя | Извлечение табличных данных | Покоординатное извлечение таблиц, высокая точность |
| Marker-PDF | ~11с/док | Сохранение сложной верстки | Лучшее сохранение структуры, но работает медленнее |
| PyPDF2 | Быстро | Простые PDF с текстом | Легковесный, подходит для базового извлечения |
Пример кода для текстовой экстракции PDF
import pymupdf4llm
import openai
# Шаг 1: Конвертация PDF в Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Шаг 2: Передача в API большой языковой модели
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Пожалуйста, сделай краткую выжимку основных моментов этого отчета:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Посмотреть полный код для обработки PDF с изображениями (метод визуального анализа)
import fitz # PyMuPDF
import base64
import openai
def pdf_pages_to_images(pdf_path, dpi=200):
"""Преобразование каждой страницы PDF в изображение Base64"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
pix = page.get_pixmap(dpi=dpi)
img_bytes = pix.tobytes("png")
b64 = base64.b64encode(img_bytes).decode()
images.append(b64)
return images
# PDF в изображения
images = pdf_pages_to_images("report.pdf")
# Формирование сообщения с несколькими изображениями
content = [{"type": "text", "text": "Проанализируй графики и данные в этом PDF-документе:"}]
for img_b64 in images[:10]: # Важно: контролируйте количество страниц, чтобы не превысить лимит токенов
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
print(response.choices[0].message.content)
Совет: Метод текстовой экстракции совместим со всеми большими языковыми моделями (включая DeepSeek, Llama и другие, которые не поддерживают PDF напрямую). Через APIYI (apiyi.com) вы можете использовать один и тот же API-ключ для тестирования любой модели.
Вариант 2 обработки PDF через API большой языковой модели: нативный ввод PDF
Если вы используете Claude, Gemini или GPT-4o, вы можете передавать PDF напрямую через API без какой-либо предварительной обработки.
Пример нативного ввода PDF для Claude API
import anthropic
import base64
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Для Claude используйте корневой домен
)
with open("report.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": pdf_data}},
{"type": "text", "text": "Пожалуйста, выдели основные моменты этого документа"}
]
}]
)
print(message.content[0].text)
Пример нативного ввода PDF для Gemini API
from google import genai
client = genai.Client(
api_key="YOUR_API_KEY",
http_options={"api_version": "v1beta", "base_url": "https://api.apiyi.com"}
)
with open("report.pdf", "rb") as f:
pdf_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"),
"Пожалуйста, выдели основные моменты этого документа"
]
)
print(response.text)
🎯 Напоминание о стоимости: Хотя нативный ввод PDF — самый удобный способ, стоимость в токенах значительно выше, чем при текстовом методе. Например, для PDF на 50 страниц: Gemini расходует около 12 900 токенов (самый дешевый вариант), Claude — около 75 000–150 000 токенов, GPT-4o — более 40 000 токенов. При обработке больших объемов обязательно оценивайте затраты — рекомендуем использовать функцию мониторинга потребления на APIYI (apiyi.com).
Решение для обработки PDF через API больших моделей, часть 3: Клиентские приложения
Для повседневных задач (не связанных с разработкой кода) использование AI-клиентов — самый простой и эффективный путь. Возьмем для примера Cherry Studio: он поддерживает прямое перетаскивание PDF-файлов, автоматически выполняет векторизацию и семантический поиск, отправляя большой языковой модели только релевантные фрагменты текста.
Преимущества клиентских решений
- Без написания кода: просто перетащите PDF и начинайте диалог.
- Экономия токенов: благодаря RAG-поиску отправляются только нужные фрагменты, а не весь документ целиком.
- Переключение между моделями: поддержка настройки API-ключей от различных провайдеров, включая APIYI.
- Локальная база знаний: возможность объединять несколько PDF-файлов в единую базу знаний для многократных запросов.
На что обратить внимание при работе с PDF через клиент
- Контроль размера файла: слишком большое количество страниц в PDF может привести к долгой векторизации.
- Расходы на токены: хотя RAG сжимает объем данных, работа с длинными документами все равно может потребовать значительных затрат.
- Выбор подходящей модели: для простых вопросов и ответов используйте бюджетные модели (например, GPT-4o-mini), а для сложного анализа — флагманские модели.
Совет: настройте APIYI (apiyi.com) в качестве провайдера API в таких клиентах, как Cherry Studio. Это позволит вам получить доступ ко всем моделям, включая Claude, Gemini и GPT, используя всего один API-ключ.

Часто задаваемые вопросы
Q1: Какой способ лучше использовать для обработки PDF с помощью DeepSeek?
API DeepSeek на данный момент не поддерживает прямую загрузку PDF. Рекомендуем использовать первый вариант (извлечение текста): сначала конвертируйте PDF в Markdown-текст с помощью PyMuPDF4LLM, а затем отправьте его на анализ через API DeepSeek с помощью сервиса-прокси API APIYI (apiyi.com). Если в PDF есть графики или таблицы, можно сначала преобразовать страницы в изображения и использовать мультимодальную модель (например, GPT-4o) для их анализа.
Q2: Что работает лучше: нативный ввод PDF или извлечение текста?
Все зависит от содержимого PDF. Для текстовых документов (контракты, отчеты) результаты будут схожими, но извлечение текста обойдется дешевле. Если PDF содержит графики, сложную верстку или является сканом, нативный ввод будет работать значительно лучше, так как модель сможет одновременно анализировать текст и визуальные элементы. Советуем сначала протестировать вариант с извлечением текста, а если результат не устроит — переходить на нативный ввод.
Q3: Как контролировать расходы токенов при обработке PDF?
Вот несколько полезных советов:
- Для больших объемов данных отдавайте предпочтение Gemini (всего 258 токенов на страницу, самая низкая стоимость).
- Извлекайте только нужные страницы, не загружайте весь документ целиком.
- После извлечения текста сделайте краткое резюме или разбейте его на части, чтобы не передавать слишком длинные фрагменты.
- Отслеживайте фактическое потребление через панель мониторинга на APIYI (apiyi.com).
Итоги
Ключевые моменты при работе с PDF через API больших языковых моделей:
- Нативная поддержка: Claude (600 страниц), Gemini (1000 страниц) и GPT-4o (100 страниц) поддерживают прямую загрузку PDF, в то время как DeepSeek и другие модели пока нет.
- Выбор из 3 вариантов: извлечение текста — самый дешевый и универсальный способ; нативный ввод — самый удобный, но дорогой; клиентская обработка подходит для повседневных задач.
- Разница в стоимости: при обработке одного и того же PDF нативный ввод через Gemini самый выгодный (~258 токенов на страницу), а вариант с извлечением чистого текста позволяет сократить расходы еще на 50% и более.
Выбирайте подходящий метод в зависимости от вашей задачи, и вы сможете эффективно работать с PDF, не переплачивая за токены.
Рекомендуем использовать APIYI (apiyi.com) для единого доступа к популярным моделям. Платформа предоставляет бесплатные лимиты и поддерживает вызовы API для всех основных моделей, включая Claude, Gemini, GPT и DeepSeek.
📚 Справочные материалы
-
Руководство OpenAI по вводу PDF: Официальная документация по прямой передаче PDF через API
- Ссылка:
platform.openai.com/docs/guides/pdf-files - Описание: Подробные спецификации и ограничения для ввода PDF в GPT-4o
- Ссылка:
-
Документация по поддержке PDF в Claude: Официальное руководство Anthropic по обработке PDF
- Ссылка:
docs.anthropic.com/en/docs/build-with-claude/pdf-support - Описание: 3 способа ввода PDF в Claude и лучшие практики
- Ссылка:
-
Обработка документов в Gemini: Официальное описание возможностей понимания документов от Google
- Ссылка:
ai.google.dev/gemini-api/docs/document-processing - Описание: Ограничения и тарификация при обработке PDF в Gemini
- Ссылка:
-
Документация PyMuPDF4LLM: Инструмент для извлечения текста из PDF
- Ссылка:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Описание: Самый быстрый инструмент для конвертации PDF в Markdown
- Ссылка:
-
Платформа APIYI: Единый доступ к API различных моделей
- Ссылка:
docs.apiyi.com - Описание: Получение API-ключа, список моделей и примеры вызова моделей
- Ссылка:
Автор: Техническая команда APIYI
Техническое обсуждение: Приглашаем к дискуссии в комментариях. Дополнительные материалы доступны в документации APIYI по адресу docs.apiyi.com