
Différences entre Claude Fable 5 et Mythos 5 : deux encapsulations pour un même grand modèle de langage, 5 différences clés expliquées
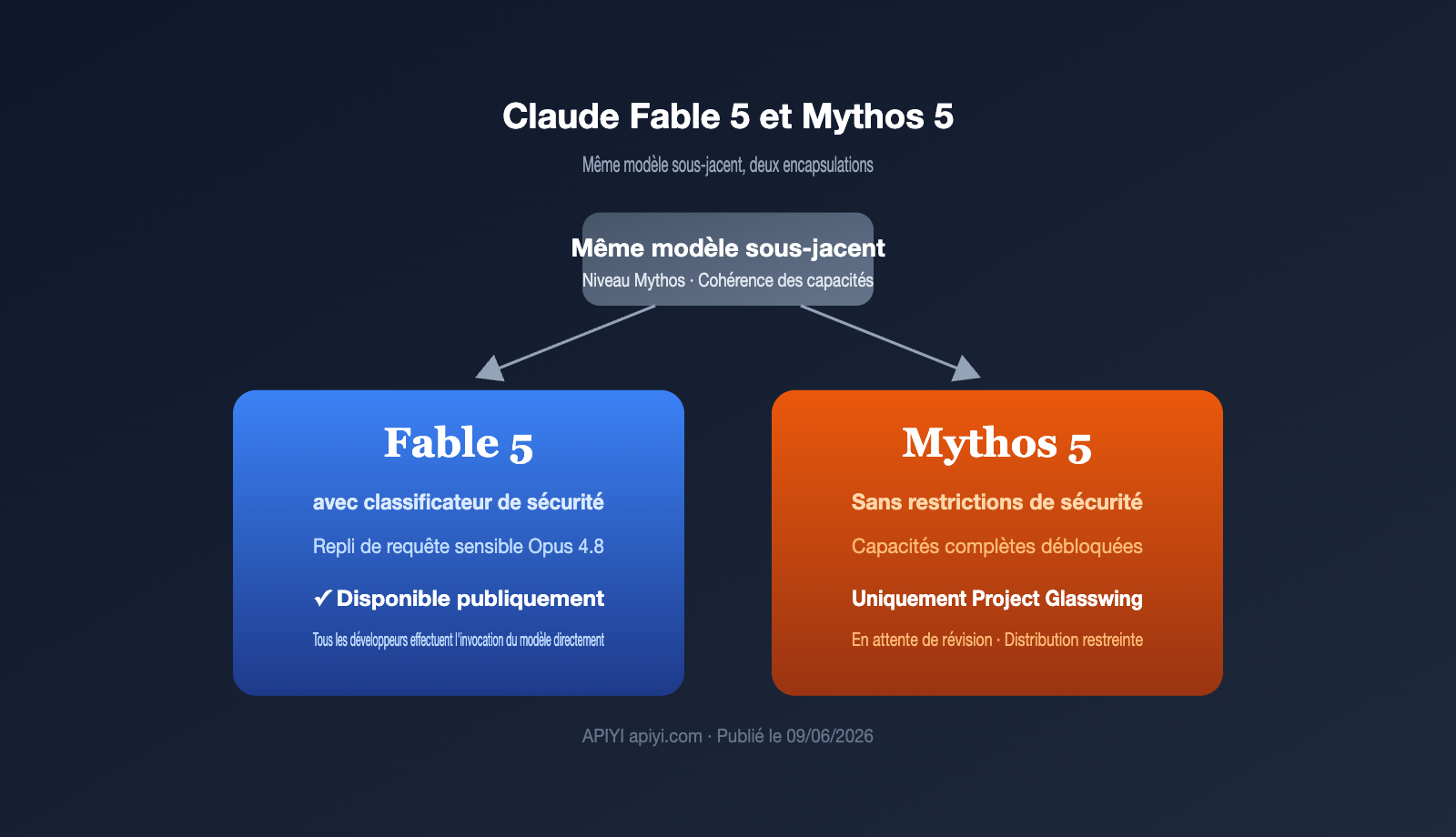
Le 9 juin 2026, Anthropic a dévoilé deux noms d'un coup : Claude Fable 5 et Claude Mythos 5. Beaucoup ont cru qu'il s'agissait de deux modèles distincts, alors qu'il s'agit en réalité de deux encapsulations du même modèle sous-jacent. Ce qui les différencie vraiment, ce n'est pas leur capacité, mais leur politique de sécurité. … Lire la suite








