
Diferencias entre Claude Fable 5 y Mythos 5: dos encapsulamientos del mismo Modelo de Lenguaje Grande, 5 diferencias clave explicadas
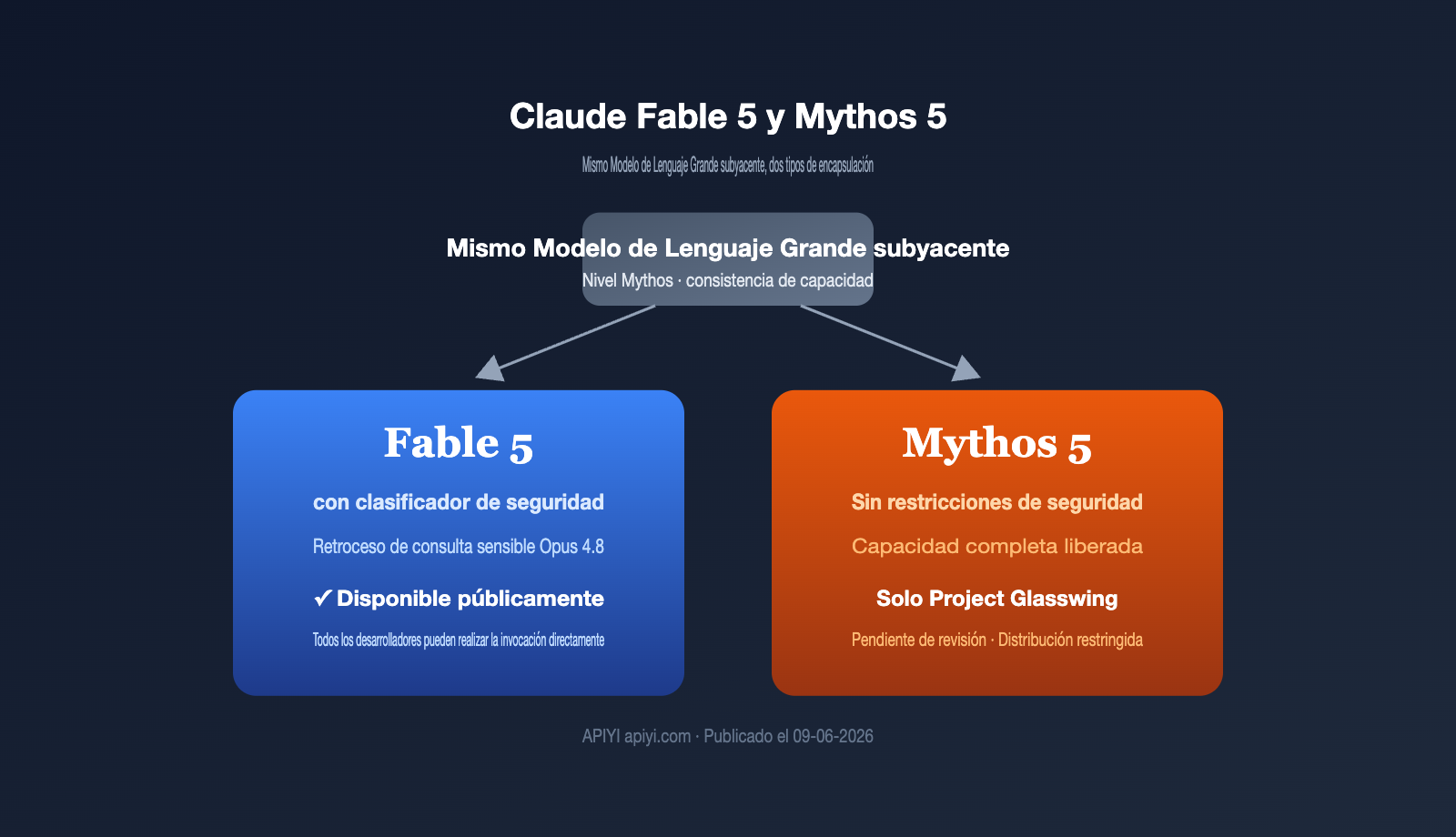
El 9 de junio de 2026, Anthropic lanzó dos nombres de golpe: Claude Fable 5 y Claude Mythos 5. Muchos pensaron que se trataba de dos modelos distintos, pero en realidad son dos empaquetados del mismo modelo base. Lo que realmente los separa no es su capacidad, sino su política de seguridad. Este artículo responde … Leer más








