
作者注:深度分析 Claude Opus 4.6 Thinking 模型通过 API 中转调用时 content should be a valid list 报错的根本原因,解析 /v1/messages 与 /v1/chat/completions 两种端点的格式差异和兼容方案
你有没有遇到过这个场景:用 claude-opus-4-6-thinking 模型,通过 /v1/chat/completions(OpenAI 格式)调用一切正常,但切到 /v1/messages(Anthropic 原生格式)反而报错 content: Input should be a valid list?这个看起来违反直觉的现象,其实揭示了 Thinking 模型在两种 API 格式之间的深层兼容性问题。本文将从 API 底层格式出发,彻底讲清楚报错原因和正确的调用方式。
核心价值: 读完本文,你将理解 Thinking 模型在两种 API 格式中的行为差异,解决 content should be a valid list 报错,并掌握多轮对话中 thinking blocks 的正确处理方式。

Claude Thinking 模型 API 兼容性核心要点
先直接回答这个"反直觉"现象的本质。
| 要点 | 说明 | 影响 |
|---|---|---|
| 报错根因 | 中转将 content: "string" 传给了期望 content: [list] 的 /v1/messages |
格式不匹配导致 400 错误 |
| OpenAI 格式能跑通 | /v1/chat/completions 允许 content 为字符串,自动剥离 thinking blocks |
格式简单,兼容性好 |
| Anthropic 格式报错 | /v1/messages 严格要求 content 为内容块列表,且 thinking 必须排首位 |
中转格式转换不完整 |
| 模型名差异 | claude-opus-4-6-thinking 是中转平台别名,官方模型名是 claude-opus-4-6 |
thinking 通过参数而非模型名启用 |
| 正确做法 | 使用 OpenAI 格式调用,或确保中转正确处理 content 格式转换 | 选对端点 + 正确传参 |
Claude Thinking 模型 API 报错的技术本质
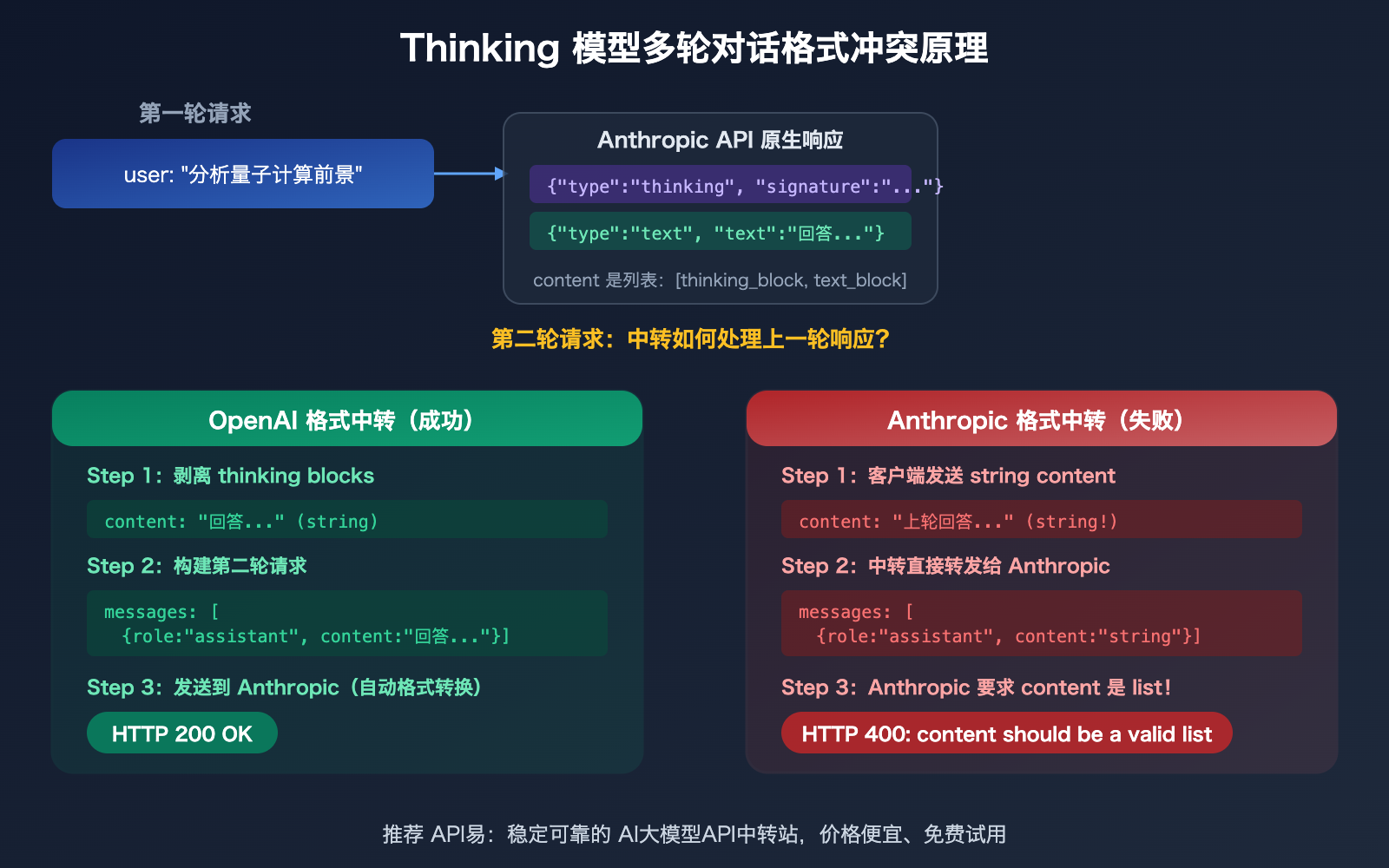
这个错误信息 content: Input should be a valid list 揭示了一个关键的格式差异:
Anthropic 原生 API(/v1/messages) 的 content 字段必须是一个 内容块数组(list):
{
"role": "assistant",
"content": [
{"type": "thinking", "thinking": "让我分析这个问题...", "signature": "CpcH..."},
{"type": "text", "text": "这是我的回答..."}
]
}
OpenAI 兼容格式(/v1/chat/completions) 的 content 可以是 纯字符串:
{
"role": "assistant",
"content": "这是我的回答..."
}
当 API 中转平台(如 APIYI 后台)的渠道配置为 /v1/messages 格式时,如果上游客户端发送的是 OpenAI 格式的字符串 content,中转需要把 "string" 转换为 [{"type": "text", "text": "string"}]。如果这个转换不完整——特别是对 Thinking 模型的响应回传到下一轮对话时——就会触发 Input should be a valid list 错误。
Claude Thinking 模型 API 两种端点格式详细对比
这是理解这个问题的关键:两种端点对 content 字段的要求根本不同。
Claude Thinking 模型 API 格式差异
| 对比维度 | /v1/chat/completions(OpenAI) |
/v1/messages(Anthropic) |
|---|---|---|
| content 类型 | string 或 array |
必须是 array(内容块列表) |
| thinking 返回 | 不返回详细思考过程 | 返回 thinking 类型内容块 |
| signature 传递 | 放在 provider_specific_fields |
直接在 thinking 块的 signature 字段 |
| 多轮对话 | 纯文本传递,无需关心 thinking 排序 | assistant 消息必须以 thinking 块开头 |
| thinking 启用方式 | 模型名后缀或参数 | thinking: {"type": "adaptive"} 参数 |
| prompt caching | 不支持 | 支持 |
| 思考过程可见 | 不可见 | 可见(summarized thinking) |
Claude Thinking 模型 API 请求格式对比
OpenAI 格式调用(推荐用于中转场景):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-6-thinking", # 中转平台别名
messages=[
{"role": "user", "content": "分析量子计算的商业前景"}
],
max_tokens=16000
)
print(response.choices[0].message.content)
查看 Anthropic 原生格式调用代码
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
response = client.messages.create(
model="claude-opus-4-6", # 官方模型名,不带 -thinking
max_tokens=16000,
thinking={
"type": "adaptive" # 通过参数启用 thinking
},
messages=[
{"role": "user", "content": "分析量子计算的商业前景"}
]
)
# 响应中 content 是列表,包含 thinking 块和 text 块
for block in response.content:
if block.type == "thinking":
print(f"[思考过程] {block.thinking[:100]}...")
elif block.type == "text":
print(f"[回答] {block.text}")
关键区别:
- 模型名是
claude-opus-4-6(不带-thinking后缀) - thinking 通过
thinking={"type": "adaptive"}参数启用 - 响应 content 是内容块列表,不是字符串
- 多轮对话时必须把完整的 content 列表(含 thinking 块)传回
🎯 调用建议: 如果你通过中转平台调用 Claude Thinking 模型,优先使用
/v1/chat/completions(OpenAI 格式),兼容性最好。
API易 apiyi.com 平台的 OpenAI 兼容端点已针对 Thinking 模型做了格式适配,自动处理 thinking blocks 的转换。
Claude Thinking 模型 API 为什么 OpenAI 格式反而能跑通
这是最违反直觉的部分:用"非原生"的 OpenAI 格式调用 Claude Thinking 模型,兼容性反而更好。原因有三:
原因一:content 格式宽容度不同
OpenAI 格式允许 content 是纯字符串 "hello",也允许是内容块数组 [{"type":"text","text":"hello"}]。Anthropic 原生格式只接受内容块数组,字符串格式直接报错。
当客户端代码用字符串方式传递 content(这是 OpenAI SDK 的默认行为),中转如果走 OpenAI 格式通道,客户端和上游端点格式一致,没有转换问题。但如果走 Anthropic 格式通道,字符串就不被接受了。
原因二:thinking blocks 的自动剥离
OpenAI 兼容模式会自动把 Claude 响应中的 thinking blocks 剥离掉,只返回最终文本。这意味着:
- 客户端不会收到 thinking blocks
- 下一轮对话时不需要传回 thinking blocks
- 不存在 thinking 块排序问题
Anthropic 原生格式则要求在多轮对话中完整保留 thinking blocks,并且 assistant 消息必须以 thinking 块开头。如果中转没有正确处理这个排序要求,就会报错。
原因三:thoughtSignature 的传递问题
如前文所述,Anthropic 格式的 thinking blocks 包含加密签名(signature),必须原样回传。OpenAI 格式直接跳过了这个环节——不返回签名,也不需要传回签名。
🎯 选型建议: 通过 API 中转调用 Claude Thinking 模型,优先用
/v1/chat/completions格式,避免 thinking blocks 格式兼容问题。
API易 apiyi.com 的 OpenAI 兼容端点已经对 Thinking 模型做了完整适配。
Claude Thinking 模型 API 调用方案对比
Claude Thinking 模型 API 三种调用方案
| 方案 | 端点 | 格式兼容性 | thinking 可见 | prompt caching |
|---|---|---|---|---|
| OpenAI 格式中转 | /v1/chat/completions |
最好(string content) | 不可见 | 不支持 |
| Anthropic 原生直连 | /v1/messages |
需严格遵循格式 | 可见 | 支持 |
| Anthropic 格式中转 | /v1/messages(中转) |
取决于中转实现 | 取决于中转 | 部分支持 |
Claude Thinking 模型 API 模型名称差异
不同平台对 Thinking 模型的命名方式不同,这也是常见混淆点:
| 平台 | 模型名 | thinking 启用方式 |
|---|---|---|
| Anthropic 官方 | claude-opus-4-6 |
thinking: {"type": "adaptive"} 参数 |
| API 中转(如 API易) | claude-opus-4-6-thinking |
模型名后缀隐式启用 |
| OpenRouter | anthropic/claude-opus-4.6 |
参数启用 |
| AWS Bedrock | anthropic.claude-opus-4-6-v1 |
参数启用 |
在 Anthropic 官方 API 中,没有 claude-opus-4-6-thinking 这个模型名。-thinking 后缀是中转平台的命名约定,让用户通过模型名直接启用 thinking 功能,无需手动设置参数。
提示: 如果你在 API易 apiyi.com 使用
claude-opus-4-6-thinking模型名,平台会自动在请求中添加thinking: {"type": "adaptive"}参数。这样你用 OpenAI SDK 就能直接获得 thinking 能力,无需修改代码。
Claude Thinking 模型 API 常见踩坑和解决方案

常见问题
Q1: 用 OpenAI 格式调 Thinking 模型,会不会失去思考能力?
不会。模型的思考(thinking)过程发生在 Anthropic 服务端,与调用端点格式无关。用 OpenAI 格式调用时,模型仍然会进行完整的思考推理,只是思考过程的文字摘要不会返回给客户端。最终回答的质量和深度是一样的——你得到的是"经过深思熟虑的答案",只是看不到"思考过程的文字记录"。
Q2: 什么场景必须用 /v1/messages 原生格式?
两种场景需要原生格式:1)你需要看到模型的思考过程(summarized thinking),用于调试、教育或展示推理链;2)你需要使用 prompt caching 降低成本——缓存功能只在 /v1/messages 端点可用。如果这两个需求都没有,用 OpenAI 格式更省心。通过 API易 apiyi.com 的 OpenAI 兼容端点调用最简单。
Q3: APIYI 后台渠道配置为 /v1/messages 时,怎么解决兼容问题?
两个方案:1)将渠道切换为 OpenAI 类型(/v1/chat/completions),从根本上避免格式转换问题;2)如果必须用 /v1/messages 渠道,需要确保中转层正确地将客户端的 string content 转换为 list 格式,并在多轮对话中正确处理 thinking blocks 的排序和 signature 传递。方案 1 更简单可靠。
Q4: adaptive thinking 和旧版 extended thinking 有什么区别?
Opus 4.6 推荐使用 thinking: {"type": "adaptive"}(自适应思考),模型根据问题复杂度自动决定是否思考以及思考多深。旧版 thinking: {"type": "enabled", "budget_tokens": N} 在 Opus 4.6 和 Sonnet 4.6 上已弃用。新版还增加了 effort 参数(low/medium/high/max)来控制思考深度,默认 high。
总结
Claude Thinking 模型 API 兼容性问题的核心要点:
- 报错根因是 content 格式不匹配: Anthropic 原生 API 严格要求 content 为列表(list),而 OpenAI 格式允许字符串——中转渠道如果走
/v1/messages但客户端发的是字符串,就会报Input should be a valid list - OpenAI 格式兼容性更好: 自动剥离 thinking blocks、不需要传回 signature、content 可以是字符串——中转场景首选
- -thinking 后缀是中转约定,不是官方模型名: 官方模型名是
claude-opus-4-6,thinking 通过参数启用
通过 API 中转调用 Claude Thinking 模型,最简单的方案就是统一使用 OpenAI 兼容格式。
推荐通过 API易 apiyi.com 调用,平台已针对 Thinking 模型做了格式兼容优化,提供免费额度和多模型统一接口。
📚 参考资料
-
Claude API Extended Thinking 文档: 思考模式的完整 API 参考
- 链接:
platform.claude.com/docs/en/build-with-claude/extended-thinking - 说明: 包含 adaptive thinking、effort 参数、内容块格式的详细说明
- 链接:
-
Claude API OpenAI SDK 兼容性文档: OpenAI 格式调用 Claude 的官方指南
- 链接:
platform.claude.com/docs/en/api/openai-sdk - 说明: 包含兼容性限制和不支持的功能列表
- 链接:
-
Claude API 错误码参考: 所有 API 错误类型的说明
- 链接:
platform.claude.com/docs/en/api/errors - 说明: 包含 invalid_request_error 的具体排查方法
- 链接:
-
API易文档中心: 通过 OpenAI 兼容接口调用 Claude Thinking 模型
- 链接:
docs.apiyi.com - 说明: 已针对 Thinking 模型做格式适配,自动处理 thinking blocks 转换
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心