
2026 年 4 月 21 日,Google 在 Gemini API 公开预览中同步上线了两款下一代自主研究 Agent——Deep Research 与 Deep Research Max,两者都基于今年 2 月发布的 Gemini 3.1 Pro 模型。这是 Google 把"长期自主研究"从消费级产品向开发者 API 全面开放的关键一步,其中 Deep Research Max 在 DeepSearchQA 上拿下 93.3%,并继承了 Gemini 3.1 Pro 在 ARC-AGI-2 上 77.1% 的核心推理能力——是 Gemini 3 Pro 的两倍以上。
更重要的是,这一代 Deep Research 引入了三个工程级新特性:MCP (Model Context Protocol) 协议接入任意私有数据源、原生可视化输出 (HTML 表格 / SVG 图表 / 信息图)、Web 与私有数据跨源融合。这意味着开发者第一次可以通过一个 API 调用,让 Agent 同时检索公网 + 公司内网 + 第三方专业数据,并直接产出可嵌入仪表盘的可视化报告。
本文基于 Google 官方发布资料和 Gemini API 文档,把 Deep Research Max 的 4 个核心突破、与普通 Deep Research 的差异、ARC-AGI-2 77.1% 的真实意义、以及国内开发者怎么接入这套能力,一次性讲清楚。

一、Deep Research Max 是什么:Gemini 3.1 Pro 驱动的自主研究 Agent
Deep Research 不是新概念,Google 早在 2024 年底就在 Gemini App 中向消费者开放了基础版,能让 AI 替你跑一遍 web 检索并写一份带引用的报告。但消费版功能受限、API 不对外开放、不能接私有数据,工程化落地价值有限。
这次的 Deep Research / Deep Research Max 是一次架构级重写。Google 把它定义为"下一代自主研究 Agent"——能自主规划、执行、综合多步研究任务,跨越 web、MCP 服务器、URL Context、代码执行、文件检索等多种工具源,最终产出带引用的结构化报告。两个版本同时上线,分别面向不同的工程需求。
| 对比维度 | Deep Research (标准版) | Deep Research Max | 适用场景 |
|---|---|---|---|
| 优化目标 | 速度与延迟 | 综合性与深度 | – |
| 推理时长 | 短 (秒级到分钟级) | 长 (分钟级到小时级) | – |
| 测试时计算 (test-time compute) | 标准 | 扩展 | – |
| 多轮迭代 | 1-2 轮 | 多轮深度推理 | – |
| 调用模式 | 同步 / 实时交互 | 异步 / 后台任务 | – |
| 成本 | 较低 | 较高 | – |
| 典型用例 | 对话式研究助手、客服中台 | 投研报告、行业分析、尽调 | – |
Google 在官方发布博客中明确指出:Deep Research Max 是给那些可以接受异步等待、追求最高质量综合性产出的工作流准备的。如果你做的是企业内部尽调、深度行业研究、长报告自动生成,Max 是更合适的选择;如果是面向 C 端实时交互的 AI 助理,标准版的低延迟更友好。
💡 接入建议:Deep Research 与 Max 都通过 Gemini API 的付费层级开放,国内开发者可以直接通过 API易 apiyi.com 调用 Gemini 3.1 Pro 系列接口,平台已经统一封装为 OpenAI 兼容协议,能避免跨境网络与账号注册等门槛。
二、Deep Research Max 的 4 大核心突破
这次发布最值得关注的,是工程能力的 4 个跨越式升级。它们合起来才让 Deep Research Max 具备了真正的"企业级自主研究 Agent"形态。
2.1 第一个突破:原生 MCP 协议支持,接入任意第三方数据
Model Context Protocol (MCP) 是 Anthropic 主导的开放协议,目标是让 AI Agent 能用统一的方式接入任意外部工具和数据源。Deep Research Max 是 Google 系生态中第一个把 MCP 作为一等公民集成的产品。开发者只需要把私有 / 第三方数据封装成 MCP 服务器,Agent 就能像调用原生工具一样去检索它们。
Google 在发布会上同时披露了首批 MCP 合作伙伴:FactSet、S&P Global、PitchBook 三家金融数据巨头都在与 Google 合作设计 MCP 服务器,让共同客户能把这些专业金融数据流接入 Deep Research 工作流。这意味着金融、法律、医疗等专业领域的研究 Agent 终于有了标准化的接入路径,不再需要为每家数据源重写适配层。
2.2 第二个突破:原生可视化输出,告别纯文本报告
传统 LLM 输出基本只能返回 markdown 文本,要想加图表只能再调用一次绘图 API 或者 Code Interpreter 出图。Deep Research Max 直接在推理过程中原生生成 HTML 表格、SVG 图表、信息图,这些可视化产物是 Agent 推理流的有机组成部分,而不是事后补丁。
实际产出形态包括:结构化 HTML 表格 (可以直接嵌入网页)、可缩放的 SVG 图表 (饼图、柱状图、时间线等)、布局完整的信息图 (适合直接发邮件或贴 Slack)。如果项目集成了 Nano Banana 这类高质量图像模型,Deep Research 还能调用它生成更复杂的视觉化产物。这一改动让 Deep Research 的输出从"带引用的长 markdown"升级成"可直接嵌入仪表盘的多模态报告"。

2.3 第三个突破:Web 与私有数据跨源融合
之前的 Deep Research 只能搜公网,企业用户的最大痛点——把 SaaS 内文档、CRM 数据、ERP 报表等私有信息融进研究——没法解决。新版本可以在一次 API 调用中同时启用 Google Search、远程 MCP 服务器、URL Context、Code Execution 和 File Search,Agent 会自主决定该用哪个工具。
更重要的是开发者也可以完全关闭 Web 访问,让 Agent 只在指定的私有数据源里跑研究。对金融、法律、医疗等对数据合规高度敏感的行业,这个开关是真正的解锁键——可以确保 Agent 不会无意中泄露内部信息到公网搜索查询里。这是企业 AI 落地中长期被忽视但极其重要的合规细节。
2.4 第四个突破:性能跃迁 – 三大基准全面提升
Google 发布的官方基准对比显示,Deep Research Max 相比 2024 年 12 月版本有显著性能提升:
| 基准测试 | 2024 年 12 月版本 | Deep Research Max (2026/04) | 提升幅度 |
|---|---|---|---|
| DeepSearchQA | 66.1% | 93.3% | +27.2 个百分点 |
| Humanity's Last Exam | 46.4% | 54.6% | +8.2 个百分点 |
| ARC-AGI-2 (基础模型) | 31.1% (Gemini 3 Pro) | 77.1% (Gemini 3.1 Pro) | 提升 2× 以上 |
DeepSearchQA 这个基准专门评估自主网络检索 + 综合推理能力,93.3% 的得分已经接近上限。这意味着 Deep Research Max 在"自主搜资料并写出准确答案"这个核心任务上,几乎不会再被同类竞品拉开差距。
三、ARC-AGI-2 77.1% 的真实意义
很多开发者看到"77.1%"的数字会下意识觉得"还行",但要理解 ARC-AGI-2 这个基准的难度,才能知道这个分数的真实含金量。
3.1 ARC-AGI-2 是什么
ARC-AGI-2 由 ARC Prize 组织维护,专门测试 AI 在全新的、训练数据中绝对没见过的逻辑模式上的抽象推理能力。它通过几个示例 (input → output 对) 让模型推断隐含规则,再用规则去解未见过的新输入。人类基准是 60%,所以 77.1% 已经超过了人类平均水平。
这个基准的核心难度在于:模型不能靠记忆刷分。任何模式都是新生成的,跟训练语料无关。这也是为什么 ARC-AGI-2 被业内视为衡量"真正抽象推理能力"的金标准之一。
3.2 横向对比:Gemini 3.1 Pro 是当前最强
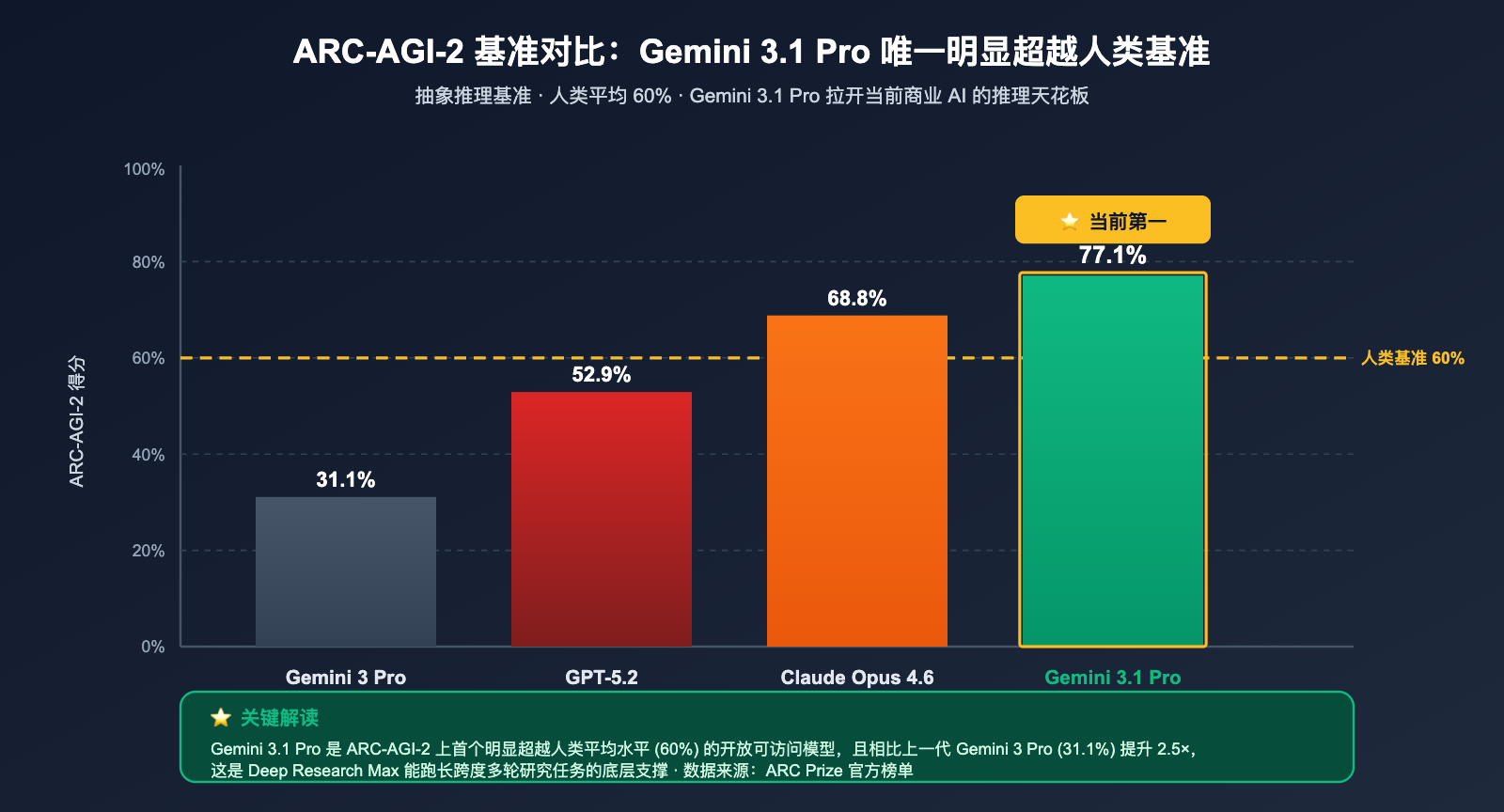
| 模型 | ARC-AGI-2 得分 | vs 人类基准 (60%) | 备注 |
|---|---|---|---|
| Gemini 3.1 Pro | 77.1% | +17.1 pp | 首个明显超越人类的开放模型 |
| Claude Opus 4.6 | 68.8% | +8.8 pp | Anthropic 旗舰 |
| 人类基准 | 60.0% | – | 平均水平 |
| GPT-5.2 | 52.9% | -7.1 pp | OpenAI |
| Gemini 3 Pro | 31.1% | -28.9 pp | 上一代 |
可以看到 Gemini 3.1 Pro 不仅超越了所有商业大模型,更是唯一一个明显超过人类基准的开放可访问模型。这是当前商业 AI 第一次在严格的"全新逻辑推理"基准上拉开和人类的差距。Deep Research Max 直接继承了这一推理能力——这也是它能跑长跨度、多轮迭代研究任务的底层支撑。
🎯 能力建议:如果你的产品是面向研究、咨询、投研、法律分析等高强度推理场景,Gemini 3.1 Pro + Deep Research Max 的组合应该立即纳入技术评估。可以通过 API易 apiyi.com 平台快速接入测试,平台已经支持包括 Gemini 3.1 Pro 在内的多家旗舰模型 OpenAI 兼容调用。
四、Deep Research Max API 快速上手
理论说完,下面给出能直接跑起来的最精简调用代码。Deep Research Max 走的是 Gemini API 标准接口,付费层级开放预览。
4.1 基础调用:让 Agent 跑一份 web 研究
from google import genai
from google.genai import types
# 通过 API易统一中转点接入,避免跨境网络问题
client = genai.Client(
api_key="your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com"}
)
response = client.models.generate_content(
model="deep-research-max-preview-04-2026",
contents="分析 2026 年上半年全球嵌入模型市场格局,列出 Top 5 厂商及其差异化优势",
config=types.GenerateContentConfig(
tools=[types.Tool(google_search={})], # 启用 Google Search
thinking_config=types.ThinkingConfig(thinking_level="max") # Max 档思考预算
)
)
print(response.text) # 输出完整研究报告(含原生 HTML 表格 / SVG 图表)
这段代码做了三件事:选定 Deep Research Max 模型、启用 Google Search 工具、设置最高档思考级别。Agent 会自主规划检索路径,多轮迭代分析,最后产出一份带引用和可视化的完整报告。
4.2 进阶调用:接入 MCP 服务器跑私有数据研究
如果要用 Deep Research Max 跑公司内部数据 (例如 CRM、内部 wiki),需要把数据源封装成 MCP 服务器,再在调用时声明:
response = client.models.generate_content(
model="deep-research-max-preview-04-2026",
contents="分析公司 Q1 销售管线中流失率最高的客户类型",
config=types.GenerateContentConfig(
tools=[
types.Tool(mcp_servers=[
{"url": "https://your-internal-mcp.company.com", "auth": "..."}
]),
types.Tool(file_search={"corpora": ["sales-docs-corpus"]}),
],
thinking_config=types.ThinkingConfig(thinking_level="max")
)
)
注意这里没有启用 google_search,意味着 Agent 完全在私有数据范围内跑研究,不会向 Google 发出任何外部查询。这是企业合规场景下最关键的一个能力。
4.3 标准版与 Max 版的切换
如果你的场景是面向 C 端的实时对话,速度比深度更重要,把 model 名换成 deep-research-preview-04-2026 即可。两者的接口完全兼容,差异只在内部计算预算和迭代轮数。
💡 快速试用建议:第一次接入时建议先用标准版 Deep Research 跑几个 demo 熟悉 Agent 的输出风格,再升级到 Max 跑真实业务任务。我们建议通过 API易 apiyi.com 平台直接接入,平台同时支持 Gemini 3.1 Pro、Deep Research、Deep Research Max 在内的多家模型 OpenAI 兼容调用,便于切换对比。
五、Deep Research Max 影响分析:哪些工作流会被重塑
新工具的发布只是起点,真正的价值在于它会改变哪些既有工作流。基于发布资料和早期社区反馈,下面 4 个领域受到的冲击最大。
5.1 投研与行业分析
这是 Google 在发布会上明确点名的场景。FactSet、S&P Global、PitchBook 三家金融数据商联手做 MCP 服务器,目标就是让买方分析师能通过一句自然语言指令同时调用财报数据、行业研究、并购数据库,自动产出可视化研报。原本要花 2 天写的初稿,现在可能 30 分钟就能跑出来。这不是替代分析师,而是把他们从机械的资料检索中解放出来。
5.2 企业尽调与合规审查
法律和合规团队做尽调时最大的痛点是"既要查公开信息又要看内部档案"。Deep Research Max 的"私有数据 only"模式让律师可以放心地把客户数据丢给 Agent 跑分析,不用担心被搜索引擎记录。配合原生可视化输出,最终的尽调报告可以直接在 Notion / Confluence 嵌入。
5.3 学术综述与文献研究
学者写综述类论文最耗时的环节是把 200+ 篇文献快速消化成一个论点框架。Deep Research Max 的多轮深度推理能在一次调用里读完几十篇 PDF 并生成结构化 outline。配合 1M Token 上下文窗口,单篇调用就能消化整个研究方向的核心文献。
5.4 SaaS 产品中的 AI 助理升级
很多 SaaS 产品都已经在塞 AI Copilot,但目前的实现大多是"包装一下 GPT-4 + RAG"。Deep Research 标准版 (低延迟) 给了这类产品一个升级路径:把 Copilot 换成真正的自主 Agent,能跨越 web 数据、产品内数据、用户私有数据综合回答问题,而不是只在文档里翻关键词。
六、Deep Research Max 与同类产品对比
把 Deep Research Max 放到行业坐标系里看一下。当前主流的"研究 / 深度推理"产品大致分三类。
| 产品 | 厂商 | 自主研究 | MCP 支持 | 原生可视化 | 私有数据 | 综合评分 |
|---|---|---|---|---|---|---|
| Deep Research Max | ✅ 多轮深度 | ✅ 一等公民 | ✅ HTML/SVG 原生 | ✅ Web off 模式 | ⭐⭐⭐⭐⭐ | |
| OpenAI Deep Research | OpenAI | ✅ 多轮 | 部分 | 部分 | 部分 | ⭐⭐⭐⭐ |
| Anthropic Claude Research | Anthropic | ✅ | ✅ MCP 原生 | ❌ 文本为主 | ✅ | ⭐⭐⭐⭐ |
| Perplexity Deep Research | Perplexity | ✅ Web 为主 | ❌ | 部分 | ❌ | ⭐⭐⭐ |
| 自建 RAG + Agent | 各家 | 取决于实现 | 取决于实现 | 需自研 | ✅ | ⭐⭐ |
可以看出 Deep Research Max 在 4 个核心维度上都做到了最完整:多轮深度推理 + MCP 一等公民支持 + 原生可视化 + 私有数据跨源融合。这是当前商业产品中工程化最成熟的研究 Agent 方案。
📌 选型建议:如果你的应用对深度推理、私有数据合规、可视化输出都有要求,Deep Research Max 是当前最优解;如果只需要轻量级 web 检索助理,可以选 Perplexity 或者 Deep Research 标准版。可以通过 API易 apiyi.com 一站式接入并对比这些模型,避免重复配置多家供应商的鉴权和接口。
七、Deep Research Max 常见问题 FAQ
Q1: Deep Research Max 和普通 Gemini 3.1 Pro 有什么区别?
Gemini 3.1 Pro 是底层基础模型,提供推理能力;Deep Research Max 是建立在 3.1 Pro 之上的自主研究 Agent,封装了多工具调用、多轮迭代、原生可视化等 Agent 能力。简单说,3.1 Pro 是"大脑",Deep Research Max 是"装好了手脚和工具的研究员"。
Q2: 国内开发者怎么调用 Deep Research Max?
Deep Research Max 是 Gemini API 付费层级的功能,国内直接访问需要解决跨境网络和支付问题。最简便的路径是通过 API易 apiyi.com 这类统一中转平台,可以用人民币付费,调用接口与官方完全兼容,且支持 Gemini 3.1 Pro 系列在内的多家模型一站式接入。
Q3: Deep Research Max 比标准版贵多少?
Google 没有公布具体倍数,但从"扩展 test-time compute、多轮深度迭代"的描述推断,Max 单次调用成本会显著高于标准版,可能在 3-10 倍区间。建议非高价值任务先用标准版跑,需要顶级深度时再切到 Max。
Q4: 我能自己写 MCP 服务器接入 Deep Research Max 吗?
可以。MCP 是开放协议,任何团队都可以按规范实现自己的 MCP 服务器,把 ERP、CRM、内部知识库等数据封装为标准接口暴露给 Agent。Google 也明确表示欢迎社区贡献 MCP 服务器实现。
Q5: Deep Research Max 的输出可以直接嵌入网页吗?
可以。原生输出包含 HTML 表格、SVG 图表、结构化布局,这些产物可以直接嵌入网页 / 仪表盘 / 邮件。这是 Deep Research Max 相比传统 LLM 输出的核心差异化优势之一。
Q6: 完全禁用 Web 访问后,Agent 还能正常工作吗?
可以。Agent 会只在你指定的 MCP 服务器、File Search 语料、URL Context 等私有数据源中跑研究。这正是企业合规场景的核心使用模式——数据完全不出企业边界。
Q7: Deep Research Max 的上下文窗口是多大?
继承自 Gemini 3.1 Pro,输入上下文 1,048,576 Tokens (约 1M),输出最大 65,536 Tokens (约 65K)。这意味着单次调用就能消化几十篇长论文或者整个产品文档库。
Q8: ARC-AGI-2 77.1% 是不是说 Gemini 3.1 Pro 通用能力都是最强?
不能这么直接推断。ARC-AGI-2 测的是抽象推理,77.1% 说明 Gemini 3.1 Pro 在这个特定维度上领先;但代码、多模态、中文理解等其他维度需要看各自的基准。从综合表现看,Gemini 3.1 Pro 是当前第一梯队的旗舰模型之一。
Q9: Deep Research Max 会取代 RAG 系统吗?
短期不会完全取代,更可能是互补关系。RAG 在"特定企业数据精确召回"场景仍有不可替代的成本与延迟优势;Deep Research Max 适合"多源融合 + 深度推理 + 可视化产出"的高价值任务。最佳实践是用 RAG 做一线问答,遇到深度需求时升级到 Deep Research Max。
Q10: 中文场景下 Deep Research Max 表现如何?
Gemini 3.1 Pro 的多语言能力包括中文,Deep Research Max 继承了这一基础。但需要注意 Google Search 工具默认是英文优先,中文研究任务建议同时启用 Google Search 中文域 + 中文 MCP 服务器,可以显著提升信息覆盖度。
八、总结:Deep Research Max 落地核心要点
回顾全文,关于 Google Deep Research Max,开发者最需要记住的几个核心要点:
第一,Deep Research Max 是 2026 年最值得关注的自主研究 Agent,4 大核心突破——MCP 支持、原生可视化、跨源融合、性能跃迁——一次性把企业级研究 Agent 工程化推进到了可落地阶段。第二,两个版本各有定位:标准版优化速度延迟适合实时交互,Max 版优化深度综合性适合异步深度任务,按场景选择即可。第三,ARC-AGI-2 77.1% 不是数字游戏,它意味着底层 Gemini 3.1 Pro 已经在抽象推理这个核心能力上明确超越人类平均水平,配合 Deep Research Max 的工具调用框架,长跨度复杂研究任务终于有了商业级可用方案。
第四,MCP 协议会成为下一代 Agent 的事实标准,Google 把它做成一等公民支持是一个明确的信号。Anthropic 也是 MCP 主推方,配合 Cursor、Claude Desktop 等已有支持,整个生态正在围绕 MCP 形成。开发者现在投入学习和实现 MCP 服务器是高 ROI 的选择。第五,国内接入路径清晰:Deep Research / Max 走 Gemini API 付费预览层级,通过 API易 apiyi.com 等统一中转平台可以快速完成从注册、付费到调用的全流程,不需要自己解决跨境网络与海外信用卡问题。
🎯 最终建议:如果你正在构建研究 / 咨询 / 分析 / 教育 / 法律相关的 AI 产品,立即把 Deep Research Max 纳入技术选型评估。它代表了当前商业 AI Agent 工程化的最高水平,先动手者会拿到最大的产品差异化红利。可以通过 API易 apiyi.com 平台快速接入测试,配合 Gemini 3.1 Pro 的 1M 上下文与多模态能力,把传统 RAG / 智能客服 / 内容生成等场景升级到下一代自主 Agent 形态。
Deep Research Max 的发布只是开始。Google 已经在博客中明确表示这是"a step change for autonomous research agents"——一次阶跃式变化。能否抓住这次工具迭代的窗口期,直接决定了 AI 产品在 2026 年下半年的竞争位置。
作者:APIYI 技术团队 | 关注 AI 大模型落地实战,更多技术内容欢迎访问 API易 apiyi.com