
作者注:本文系统讲解 gpt-image-2 图片分层的真实原理、Python 后台处理现象、API 调用方式和成本优化方案,帮助开发者避免把工具链能力误认为模型原生能力。
如果你最近在使用 gpt-image-2 做海报、科研图、产品图或幻灯片,可能已经看到一个很有意思的现象:有人声称它能“图片分层”,甚至能在后台通过 Python 把一张图拆成可编辑对象。
这件事乍看像模型突然学会了 Photoshop,但实际更接近一个多工具链工作流:gpt-image-2 负责生成或编辑高质量图片,Python 脚本负责 OCR、背景修补、元素分割、SVG/PPTX/PSD 重建等后处理。
这不是又一篇入门科普,而是从 API 能力、图层原理、Python 后处理、成本计算和工程落地角度,完整拆解 gpt-image-2 图片分层到底能做到什么、不能做到什么。
核心价值:读完本文,你将明确 gpt-image-2 图片分层的边界,知道如何用 API易 apiyi.com 接入 gpt-image-2 官转 API,并设计一套可上线的“图片生成到可编辑素材”流程。
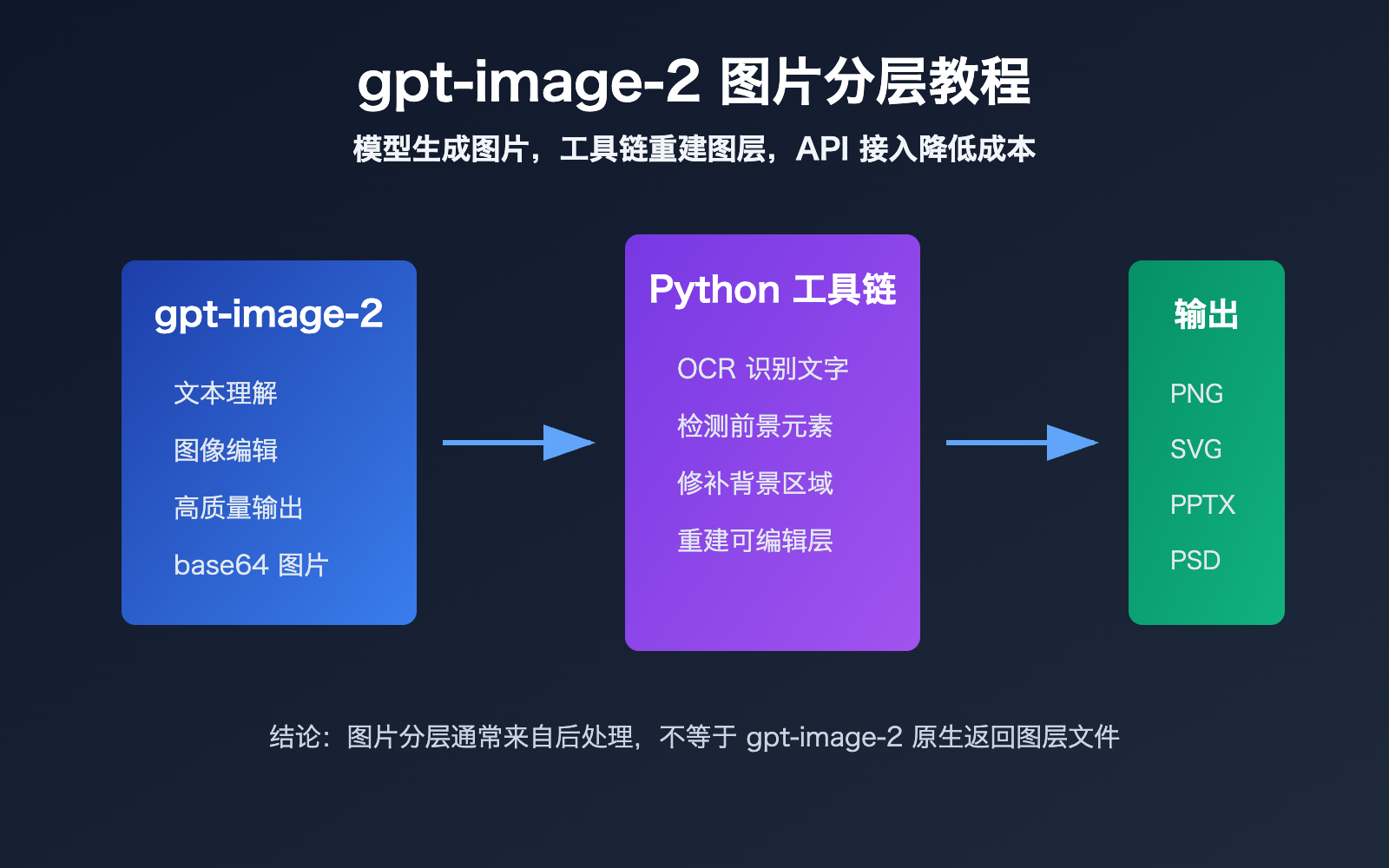
gpt-image-2 图片分层核心要点
gpt-image-2 图片分层的关键,是先区分“模型输出”和“产品工作流输出”。
OpenAI 官方模型页将 gpt-image-2 定义为用于快速、高质量图像生成与编辑的图像模型,支持文本输入、图像输入和图像输出,并可用于 Images API 的生成与编辑端点。
但从当前公开 API 形态看,开发者拿到的核心结果仍是图片数据,而不是 Photoshop 式的多图层工程文件。
| 要点 | 说明 | 对开发者的价值 |
|---|---|---|
| 模型原生能力 | gpt-image-2 负责理解提示词、参考图和编辑意图,输出最终图像 | 适合生成海报、产品图、插画和视觉稿 |
| 接口输出形态 | 官方文档围绕 b64_json、图片格式、尺寸、质量、token 用量等字段展开 |
便于服务端保存、上传、审计和计费 |
| 图片分层来源 | 多数可编辑图层来自 OCR、分割、修补、矢量化、PPTX/PSD 写入等后处理 | 能解释“为什么后台会跑 Python” |
| 成本优化方式 | 官转 API 可按官方原价口径接入,并结合充值赠送降低实际成本 | 适合批量生成、测试和生产集成 |
gpt-image-2 图片分层不是原生 PSD 输出
gpt-image-2 图片分层最容易被误解的一点,是把“最终用户看到的可编辑文件”当成“模型直接吐出的文件”。
在工程上,这两者完全不同。
模型直接输出的是一张图像,通常以 base64 图片数据或图片文件形式被应用接收。
如果某个产品可以把它变成 PPTX、SVG 或 PSD,通常说明产品在模型之后加了一层后处理系统。
这层系统可能由 Python 完成,因为 Python 在图像处理、OCR、深度学习推理和办公文档生成方面生态成熟。
例如,工程师可能先用 OCR 识别文字,再用 inpainting 把原图里的文字区域补干净,然后用 python-pptx 重建文本框和图片层。
这类流程可以让用户感觉“图片被分层了”,但本质上是从扁平图片反推可编辑结构。
这种反推并不总是完美。
文字越清晰、背景越简单、版式越规则,分层效果越好。
如果图片里有复杂纹理、半透明阴影、手写字、细碎装饰或高度重叠对象,后处理就很容易出现误检、漏检和边缘瑕疵。
gpt-image-2 图片分层需要关注模型与工具链边界
开发者做 gpt-image-2 图片分层时,应该把系统拆成两段。
第一段是生成段:让 gpt-image-2 输出视觉质量足够高、结构足够清晰、文本尽量准确的图片。
第二段是结构化段:用 Python 或其他后处理工具把扁平图片转换成可编辑对象。
两段目标不同,评估指标也不同。
生成段重点看提示词遵循、构图、文字准确率、画面一致性和输出成本。
结构化段重点看文字可编辑率、对象拆分准确率、背景修补自然度、导出文件兼容性和人工修正成本。
技术建议:如果你要验证 gpt-image-2 图片分层链路,建议先通过 API易 apiyi.com 接入 gpt-image-2 官转 API 跑通生成和编辑,再逐步叠加 OCR、分割、修补和导出模块。这样能把模型问题和后处理问题分开排查。
gpt-image-2 图片分层如何工作
gpt-image-2 图片分层可以理解为“扁平图像到结构化素材”的逆向工程。
它不只是简单抠图,而是结合视觉理解、传统图像处理和文档生成的完整流程。

gpt-image-2 图片分层第一步:生成适合分层的图片
要让 gpt-image-2 图片分层更稳定,生成阶段就要为后处理服务。
提示词应该明确要求版式清晰、元素边界明确、文字区域独立、背景纹理不要过度复杂。
如果目标是做 PPTX 或 SVG,建议使用扁平化设计、清晰色块、少量阴影和少量渐变。
如果目标是做 PSD,建议把主体、背景、文字、装饰元素的关系描述清楚。
一个常见误区是让模型生成非常复杂的电影海报,然后期待后处理工具自动拆出完美图层。
这在当前工程条件下并不现实。
分层效果高度依赖输入图片的可解析性。
gpt-image-2 图片分层第二步:检测文字和对象
Python 后台最常见的第一类任务是检测。
文字检测通常使用 OCR 模型识别字符内容、位置、字号和文本框边界。
对象检测或分割会识别人物、产品、图标、线条、背景区域等视觉对象。
如果是幻灯片或信息图,还可能识别标题、段落、表格、箭头、坐标轴和图例。
这一层并不是 gpt-image-2 自己“返回了层”,而是后处理模型从像素里推断层。
推断越准确,后续导出的 PPTX、SVG 或 PSD 越像原设计稿。
推断不准确时,最常见的问题包括文字框位置偏移、字体不一致、背景修补有痕迹、图标被拆碎。
gpt-image-2 图片分层第三步:修补背景和重建文件
当 OCR 识别出文字区域后,如果要让文字可编辑,通常需要从原图中擦掉文字。
擦掉文字后,背景会出现空洞。
这时就需要用 inpainting 或图像修补算法补齐背景。
然后,系统再把识别出的文字作为独立文本框写回 PPTX、SVG 或 PSD。
如果要做更细的对象图层,还需要为前景元素生成 mask,把对象抠出来,再写入不同图层。
这种流程听起来很像“模型会分层”,但准确说,它是“模型生成图片 + Python 解析图片 + 文档库重建图层”。
gpt-image-2 图片分层快速上手
下面给出一个面向开发者的 gpt-image-2 图片分层最小链路。
第一步先通过 API 获取图片。
第二步把图片保存为本地文件。
第三步再交给 OCR、分割、修补和导出模块。
gpt-image-2 图片分层极简 API 示例
以下示例演示通过统一接口调用 gpt-image-2 官转 API。
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
result = client.images.generate(
model="gpt-image-2",
prompt="生成一张适合后续分层的产品发布海报,纯色背景,文字区域清晰,元素边界明确",
size="1024x1024",
quality="medium",
output_format="png"
)
image_bytes = base64.b64decode(result.data[0].b64_json)
open("poster.png", "wb").write(image_bytes)
这段代码的重点不是“立刻得到 PSD”,而是先得到一张适合后处理的清晰图片。
如果你看到服务端继续调用 Python,通常就是进入了 OCR、mask、inpainting 或导出阶段。
gpt-image-2 图片分层完整处理骨架
下面是一个更接近真实项目的处理骨架。
它没有绑定具体 OCR 或分割模型,只展示模块边界。
from pathlib import Path
def generate_image(prompt: str) -> Path:
"""调用 gpt-image-2 官转 API,保存扁平图片。"""
# client = OpenAI(api_key="YOUR_APIYI_KEY", base_url="https://vip.apiyi.com/v1")
# response = client.images.generate(model="gpt-image-2", prompt=prompt)
return Path("poster.png")
def detect_layout(image_path: Path) -> dict:
"""OCR、对象检测、版式识别。"""
return {"texts": [], "objects": [], "background_regions": []}
def rebuild_editable_file(image_path: Path, layout: dict) -> Path:
"""修补背景并导出 SVG、PPTX 或 PSD。"""
return Path("poster-editable.pptx")
prompt = "生成一张文字清晰、元素分离、适合分层编辑的 AI 产品海报"
image_path = generate_image(prompt)
layout = detect_layout(image_path)
editable_path = rebuild_editable_file(image_path, layout)
print(editable_path)
在生产环境中,建议把 generate_image 和 rebuild_editable_file 拆成异步任务。
图片生成本身可能需要等待,后处理也可能消耗 CPU 或 GPU。
对于需要批量生成海报、商品图、科研图的团队,API 调用和后处理任务最好进入队列,并记录每一步的耗时与失败原因。
快速开始建议:API易 apiyi.com 的 gpt-image-2 官转 API 适合先跑通生成阶段,后续再接入自己的 Python 分层模块。这样既能保持官方模型能力,又能把业务侧的可编辑文件逻辑掌握在自己系统里。
gpt-image-2 图片分层提示词模板
如果最终目标是“可分层”,提示词要比普通文生图更克制。
| 目标 | 推荐提示词写法 | 不推荐写法 |
|---|---|---|
| 海报分层 | 背景为纯色或低复杂度渐变,标题文字独立,主体产品边缘清晰 | 生成复杂电影级海报,很多纹理和烟雾 |
| PPT 分层 | 使用扁平信息图风格,包含清晰标题、图标、箭头和三段说明 | 生成艺术感强烈的抽象视觉 |
| 商品图分层 | 产品位于画面中央,背景干净,投影柔和,边界明确 | 让产品与背景强烈融合 |
| SVG 重建 | 几何图形、线条、色块、少量文字,避免真实照片纹理 | 大量细碎纹理、复杂人物和透明材质 |
好的提示词会显著降低后处理难度。
从工程角度看,“适合生成”和“适合分层”不是同一个目标。
普通用户想要视觉冲击,分层系统想要结构清晰。
如果你要做自动化素材生产,应该优先选择结构清晰。
gpt-image-2 图片分层中的 Python 后台现象分析
用户看到 Python 在后台处理 gpt-image-2 图片分层,通常有三种可能。
第一种是 API 封装脚本。
开发者为了减少重复代码,会写 Python 脚本调用 gpt-image-2,自动保存图片、记录参数、处理错误和重试。
这种脚本不代表模型内部由 Python 运行。
第二种是图片后处理脚本。
例如,把输出图片交给 OCR、分割模型、背景修补模型、矢量化工具或 PPTX/PSD 生成库。
这种脚本才是“分层感”的主要来源。
第三种是 Agent 工作流脚本。
如果用户通过 ChatGPT、Codex、Claude Code 或其他 Agent 工具调用图片生成,Agent 可能会自动选择一个 Python 工具完成下载、转换、裁剪、拼图或文件生成。
这仍然是产品层的工具调用,不是 gpt-image-2 API 原生返回多图层。
gpt-image-2 图片分层为什么常用 Python
Python 适合 gpt-image-2 图片分层,不是因为它神秘,而是因为生态完整。
| 处理阶段 | 常见 Python 任务 | 典型价值 |
|---|---|---|
| API 调用 | 调用 Images API,保存 base64 图片,记录请求参数 | 稳定生成图片 |
| OCR | 识别文字内容、位置和文本框 | 将图片文字变成可编辑文本 |
| 分割 | 生成主体、背景、图标、线条的 mask | 拆分视觉对象 |
| 修补 | 擦除文字或对象后补齐背景 | 形成干净底图 |
| 导出 | 写入 SVG、PPTX、PSD 或其他格式 | 交付可编辑文件 |
这种链路的好处是灵活。
开发者可以根据业务场景选择不同 OCR 模型、分割模型和导出格式。
坏处是结果稳定性不完全由 gpt-image-2 决定。
如果 OCR 识别错字,或者背景修补失败,即使原图质量很好,最终可编辑文件也会出问题。
gpt-image-2 图片分层不是安全策略里的“layers”
还有一个容易混淆的词是 “layers”。
OpenAI 的安全材料中会提到 image input layers、image output layers、multiple layers of protection 等表达。
这里的 layers 指安全检测层、输入输出检测层或防护层,不是 Photoshop 图层。
如果只看到英文里的 layers,就直接翻译成“图片图层”,很容易造成误读。
做技术选型时,建议始终回到 API 字段和输出格式。
如果接口没有返回图层列表、mask 列表、对象树或 PSD 文件,那么它就不能被视为原生图片分层接口。
gpt-image-2 图片分层的可靠性判断标准
要判断一个 gpt-image-2 图片分层方案是否可靠,可以看四个指标。
第一,看它是否明确区分原图输出和后处理输出。
第二,看它是否能展示每个图层的来源,例如 OCR 文本层、背景底图层、前景对象层。
第三,看它是否允许人工修正。
第四,看它是否能复现同一张图的分层结果。
如果一个系统只说“AI 自动分层”,却不说明 OCR、mask、修补和导出逻辑,开发者就要谨慎评估。
方案建议:实际项目中可以通过官转通道获取 gpt-image-2 的稳定生成能力,再把 Python 分层能力做成内部服务。这样既能使用官方通道能力,又不会把后处理黑盒绑定到单一工具。
gpt-image-2 图片分层 API 成本与 86 折口径
gpt-image-2 图片分层的成本要拆开算。
模型生成是一部分成本。
OCR、分割、修补、导出和存储是另一部分成本。
如果只看最终“生成一个可编辑文件多少钱”,很容易误判预算。
gpt-image-2 图片分层官方价格参考
根据 OpenAI 官方 API 定价页,gpt-image-2 的公开价格口径包括图像输入、缓存图像输入、图像输出、文本输入和缓存文本输入。
| 计费项 | 官方价格口径 | 在图片分层中的含义 |
|---|---|---|
| Image input | 8.00 美元 / 100 万 tokens | 输入参考图、编辑图、素材图时产生 |
| Cached image input | 2.00 美元 / 100 万 tokens | 可复用的缓存图像输入成本 |
| Image output | 30.00 美元 / 100 万 tokens | 输出图片本身的主要成本 |
| Text input | 5.00 美元 / 100 万 tokens | 提示词、编辑指令、版式说明 |
| Cached text input | 1.25 美元 / 100 万 tokens | 可缓存提示词的成本优化空间 |
官方价格是做预算的基础。
但真实项目里,还要考虑失败重试、批量队列、后处理算力、人工验收和存储成本。
如果你需要频繁生成多版海报,建议在提示词、尺寸、质量和重试策略上做成本控制。
gpt-image-2 图片分层使用官转 API 的成本口径
API易 apiyi.com 的 gpt-image-2 官转 API 可以按官方原价口径接入,适合希望保持官方模型通道、同时减少对接复杂度的团队。
用户提到的充值活动是:充值 100 美金赠送 10% 余额。
严格按“100 美金到账 110 美金可用余额”计算,等效单位成本约为官方原价的 90.9%。
如果按平台活动展示和综合折扣口径折算,可对外理解为接近官网 86 折的优惠区间,具体以实际充值到账和平台结算规则为准。
| 接入方式 | 价格基准 | 优点 | 注意事项 |
|---|---|---|---|
| OpenAI 官方 API | 官方价格 | 原生通道,文档完整 | 需要自行处理账号、支付、额度和风控 |
| gpt-image-2 官转 API | 官方原价口径 | 接入快,统一接口,便于团队管理 | 需按平台规则充值和结算 |
| 充值活动 | 充值 100 美金送 10% | 可降低实际单位成本 | 折扣口径以实际到账为准 |
| 自建反向方案 | 不固定 | 灵活性高 | 合规、稳定性和维护成本更高 |
成本建议:如果你要做 gpt-image-2 图片分层的产品化测试,推荐先用 API易 apiyi.com 的官转 API 跑 50 到 100 张样本,记录每张图的生成成本、分层成功率和人工修正时间,再决定是否扩大批量调用。
gpt-image-2 图片分层成本优化清单
成本优化不要只盯单价。
更重要的是减少无效生成。
第一,使用结构化提示词,减少因为构图不清晰导致的重试。
第二,先用中等质量跑版式验证,再对最终版本提高质量。
第三,把模板提示词缓存起来,减少重复文本输入成本。
第四,对同一产品图使用统一参考图和布局规范,降低后处理难度。
第五,把失败样本分类,区分是模型生成失败,还是 Python 分层失败。
第六,对需要可编辑交付的场景优先使用扁平信息图风格。
这些做法往往比单纯追求更低单价更有效。
gpt-image-2 图片分层方案对比
不同团队对 gpt-image-2 图片分层的要求不同。
有的人只想改标题,有的人想导出 PPTX,有的人想得到完整 PSD,有的人只是想生成结构清晰的 SVG。
下面的对比可以帮助你选择合适路线。

gpt-image-2 图片分层路线一:继续用图片编辑
如果只是改局部内容,最简单的办法不是分层,而是继续用 gpt-image-2 编辑。
例如改标题、改颜色、换背景、替换产品图、增加小图标等,都可以通过图片编辑接口完成。
这条路线成本最低,系统复杂度也最低。
缺点是每次编辑都要重新生成局部或整图,不能像设计软件一样精确选择单个图层。
适合内容运营、社媒配图、快速海报等场景。
gpt-image-2 图片分层路线二:导出 SVG 或 PPTX
如果图片是图表、流程图、科研海报或信息图,SVG/PPTX 重建往往比 PSD 更实用。
因为这类图片的元素通常是文字、图标、线条、矩形、箭头和少量装饰。
OCR 可以识别文字,矢量化可以重建线条和色块,PPTX 库可以创建可编辑文本框。
这条路线适合企业知识库、科研展示、销售材料和培训课件。
它不追求百分百还原所有像素,而是追求“可编辑”和“够像”。
gpt-image-2 图片分层路线三:生成 PSD 或多层素材包
PSD 分层最复杂。
如果要把人物、产品、背景、文字、阴影、装饰分别拆成图层,系统需要更强的分割和修补能力。
对于复杂照片风格图像,自动 PSD 很难做到设计师级别。
更现实的策略是生成“半自动 PSD”:系统先拆出背景、主体、文字和若干关键对象,设计师再人工修正。
这条路线适合品牌设计、电商主图、广告创意和需要长期复用的高价值素材。
gpt-image-2 图片分层常见问题
gpt-image-2 图片分层能直接输出 PSD 吗?
从当前公开 API 形态看,不能把它理解成“直接输出 PSD 图层文件”。
官方文档强调的是图像生成、图像编辑、base64 图片数据、输出格式、尺寸、质量和 token 用量。
如果某个产品能导出 PSD,通常是额外接入了 Photoshop、PSD 写入库或自研后处理模块。
gpt-image-2 图片分层里的 Python 是模型内部代码吗?
一般不是。
用户看到的 Python 更可能是外部工作流脚本。
它可能负责调用 API、保存图片、运行 OCR、生成 mask、修补背景、矢量化图形或写入 PPTX/PSD。
这些脚本属于应用层,而不是模型本体。
gpt-image-2 图片分层为什么看起来很像真的图层?
因为后处理系统可以从像素中重建结构。
例如,文字识别后可以变成可编辑文本框。
产品主体通过 mask 可以变成独立图片层。
背景经修补后可以变成干净底图。
这些层叠起来,就很像从设计软件导出的工程文件。
gpt-image-2 图片分层适合所有图片吗?
不适合。
适合分层的图片通常有清晰布局、明确边界、少量文字、背景不复杂、元素不高度重叠。
不适合分层的图片包括复杂摄影、强纹理插画、透明材质、大量细碎装饰和高度艺术化构图。
gpt-image-2 图片分层如何提高成功率?
先从提示词开始优化。
要求模型输出结构清晰、边界明确、文字区域独立、背景低复杂度。
然后限制图片尺寸和风格,避免让后处理系统面对过多细节。
最后用样本集评估 OCR 准确率、对象拆分准确率和人工修正时间。
在 API 调用层,建议统一管理 gpt-image-2 官转 API 请求,方便记录成本和失败样本。
gpt-image-2 图片分层是否一定要用 API?
如果只是个人偶尔生成图片,可以用图形界面。
如果要做批量生成、自动审核、素材入库、可编辑文件导出或团队协作,就应该使用 API。
API 能让每一步可追踪、可重试、可计费,也方便和内部 Python 后处理服务衔接。
gpt-image-2 图片分层的 86 折如何理解?
用户提到的口径是通过该平台接入 gpt-image-2 官转 API,按官方原价计费,同时充值 100 美金赠送 10%。
从纯数学角度,100 美金获得 110 美金余额,等效约 90.9% 单位成本。
如果平台在活动展示、综合结算或特定通道中给出“官网 86 折”口径,应以实际到账、后台计费和活动说明为准。
写入预算表时,建议同时保留“官方原价”“充值赠送后折算”“平台活动展示折扣”三列,避免财务口径混乱。
gpt-image-2 图片分层 Key Takeaways
- gpt-image-2 图片分层的核心判断是:模型通常输出扁平图片,图层多来自后处理工具链。
- Python 后台处理并不神秘,它常用于 API 调用、OCR、mask、inpainting、矢量化和文件导出。
- 如果接口没有返回 PSD、对象树、图层列表或 mask 列表,就不应宣传为模型原生分层能力。
- 想提高分层成功率,提示词必须服务于后处理,尽量让画面结构清晰、元素边界明确。
- 轻量编辑可以继续调用 gpt-image-2,结构化交付更适合 SVG/PPTX,深度设计交付才考虑 PSD。
- gpt-image-2 官转 API 适合做生成端接入,Python 分层服务适合由业务系统自行控制。
- 成本计算要同时看官方模型价格、充值赠送、后处理算力、失败重试和人工修正时间。
gpt-image-2 图片分层参考资料
本文写作前参考了英文网络资料,并结合公开 API 文档进行交叉判断。
- OpenAI GPT Image 2 模型页:developers.openai.com/api/docs/models/gpt-image-2
- OpenAI Images and vision 文档:developers.openai.com/api/docs/guides/images-vision
- OpenAI Images API Reference:developers.openai.com/api/reference/resources/images
- OpenAI API Pricing:openai.com/api/pricing
- Reddit GPT Image 2 Python skill 讨论:reddit.com/r/ClaudeCode/comments/1stokpq
- Reddit GPT Image 2 to editable slide 讨论:reddit.com/r/ChatGPT/comments/1suwjp8
这些资料共同指向一个结论:gpt-image-2 的生成与编辑能力很强,但可编辑图层通常是应用层工作流的结果。
gpt-image-2 图片分层总结
gpt-image-2 图片分层最重要的不是追逐“是否原生 PSD”这个单点答案,而是建立正确的系统边界。
在生成端,gpt-image-2 负责把提示词和参考图转成高质量图片。
在工程端,Python 工具链负责把扁平图片解析成文字、对象、背景和可编辑文件。
把这两段拆清楚,开发者就能更准确地评估效果、成本和可维护性。
如果你的目标是做批量海报、PPT 图表、产品视觉或设计素材自动化,建议先用 gpt-image-2 生成结构清晰的底图,再根据交付格式选择 SVG、PPTX 或 PSD 后处理。
接入层可以优先使用 API易 apiyi.com 的 gpt-image-2 官转 API,按官方原价口径进行模型调用,并结合充值 100 美金送 10% 的活动降低实际使用成本。
当你把“模型能力”“后处理能力”“交付格式”“成本口径”分开管理后,gpt-image-2 图片分层就不再是一个玄学功能,而是一套可以验证、可以扩展、可以上线的视觉生产流程。
技术交流与模型接入测试可关注 API易 apiyi.com,适合需要统一调用 gpt-image-2、GPT 系列与多模型 API 的开发者团队。