
저자 주: Claude Opus 4.6 Thinking 모델을 API 중계 서비스를 통해 호출할 때 발생하는 content should be a valid list 오류의 근본 원인을 깊이 분석하고, /v1/messages와 /v1/chat/completions 두 가지 엔드포인트의 형식 차이와 호환성 해결 방안을 설명합니다.
이런 상황을 겪어보신 적 있나요? claude-opus-4-6-thinking 모델을 사용할 때, /v1/chat/completions(OpenAI 형식)로 호출하면 아무 문제가 없는데, /v1/messages(Anthropic 네이티브 형식)로 전환하면 오히려 content: Input should be a valid list 오류가 발생하는 경우 말이에요. 직관에 반하는 이 현상은 사실 Thinking 모델이 두 API 형식 사이에서 가진 심층적인 호환성 문제를 드러내고 있습니다. 이 글은 API의 저수준 형식부터 시작하여 오류 원인과 올바른 호출 방식을 완전히 이해할 수 있도록 설명해 드릴게요.
핵심 가치: 이 글을 읽고 나면, Thinking 모델이 두 API 형식에서 어떻게 다르게 동작하는지 이해하게 되고, content should be a valid list 오류를 해결하며, 다중 턴 대화에서 thinking blocks를 올바르게 처리하는 방법을 익히게 될 거예요.

Claude Thinking 모델 API 호환성 핵심 포인트
먼저 이 "반직관적" 현상의 본질부터 직접 답변해 드리겠습니다.
| 포인트 | 설명 | 영향 |
|---|---|---|
| 에러 근본 원인 | 중계 서비스가 content: "string"을 content: [list]를 기대하는 /v1/messages로 전달 |
형식 불일치로 인한 400 에러 |
| OpenAI 형식이 작동하는 이유 | /v1/chat/completions는 content를 문자열로 허용하고 자동으로 thinking 블록을 제거 |
형식이 단순하고 호환성이 좋음 |
| Anthropic 형식이 에러나는 이유 | /v1/messages는 content를 반드시 콘텐츠 블록 목록으로 요구하며 thinking은 반드시 첫 번째여야 함 |
중계 형식 변환이 불완전함 |
| 모델명 차이 | claude-opus-4-6-thinking은 중계 플랫폼 별칭, 공식 모델명은 claude-opus-4-6 |
thinking은 모델명이 아닌 매개변수로 활성화됨 |
| 올바른 방법 | OpenAI 형식으로 호출하거나, 중계 서비스가 content 형식 변환을 올바르게 처리하도록 보장 | 올바른 엔드포인트 선택 + 올바른 매개변수 전달 |
Claude Thinking 모델 API 에러의 기술적 본질
content: Input should be a valid list라는 에러 메시지는 중요한 형식 차이를 보여줍니다:
Anthropic 네이티브 API(/v1/messages) 의 content 필드는 반드시 콘텐츠 블록 배열(list) 이어야 합니다:
{
"role": "assistant",
"content": [
{"type": "thinking", "thinking": "이 문제를 분석해보겠습니다...", "signature": "CpcH..."},
{"type": "text", "text": "이것이 제 답변입니다..."}
]
}
OpenAI 호환 형식(/v1/chat/completions) 의 content는 순수 문자열일 수 있습니다:
{
"role": "assistant",
"content": "이것이 제 답변입니다..."
}
API 중계 플랫폼(예: APIYI 백엔드)의 채널 구성이 /v1/messages 형식일 때, 업스트림 클라이언트가 OpenAI 형식의 문자열 content를 보내면 중계 서비스는 "string"을 [{"type": "text", "text": "string"}]으로 변환해야 합니다. 이 변환이 불완전할 때—특히 Thinking 모델의 응답이 다음 대화 라운드로 다시 전달될 때—Input should be a valid list 에러가 발생합니다.
Claude Thinking 모델 API 두 가지 엔드포인트 형식 상세 비교
이것이 이 문제를 이해하는 핵심입니다: 두 엔드포인트는 content 필드에 대해 근본적으로 다른 요구사항을 가지고 있습니다.
Claude Thinking 모델 API 형식 차이
| 비교 차원 | /v1/chat/completions (OpenAI) |
/v1/messages (Anthropic) |
|---|---|---|
| content 타입 | string 또는 array |
반드시 array (콘텐츠 블록 목록) |
| thinking 반환 | 상세한 사고 과정을 반환하지 않음 | thinking 타입 콘텐츠 블록 반환 |
| signature 전달 | provider_specific_fields에 배치 |
thinking 블록의 signature 필드에 직접 |
| 다중 턴 대화 | 순수 텍스트 전달, thinking 정렬을 신경 쓸 필요 없음 | assistant 메시지는 반드시 thinking 블록으로 시작해야 함 |
| thinking 활성화 방식 | 모델명 접미사 또는 매개변수 | thinking: {"type": "adaptive"} 매개변수 |
| prompt 캐싱 | 지원하지 않음 | 지원함 |
| 사고 과정 가시성 | 보이지 않음 | 보임 (summarized thinking) |
Claude Thinking 모델 API 요청 형식 비교
OpenAI 형식 호출 (중계 시나리오에 권장):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-6-thinking", # 중계 플랫폼 별칭
messages=[
{"role": "user", "content": "양자 컴퓨팅의 비즈니스 전망 분석"}
],
max_tokens=16000
)
print(response.choices[0].message.content)
Anthropic 네이티브 형식 호출 코드 보기
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
response = client.messages.create(
model="claude-opus-4-6", # 공식 모델명, -thinking 없음
max_tokens=16000,
thinking={
"type": "adaptive" # 매개변수로 thinking 활성화
},
messages=[
{"role": "user", "content": "양자 컴퓨팅의 비즈니스 전망 분석"}
]
)
# 응답의 content는 목록이며, thinking 블록과 text 블록을 포함
for block in response.content:
if block.type == "thinking":
print(f"[사고 과정] {block.thinking[:100]}...")
elif block.type == "text":
print(f"[답변] {block.text}")
핵심 차이점:
- 모델명은
claude-opus-4-6입니다 (-thinking접미사 없음) - thinking은
thinking={"type": "adaptive"}매개변수로 활성화됩니다 - 응답 content는 콘텐츠 블록 목록이며 문자열이 아닙니다
- 다중 턴 대화 시에는 전체 content 목록(thinking 블록 포함)을 다시 전달해야 합니다
🎯 호출 권장사항: 중계 플랫폼을 통해 Claude Thinking 모델을 호출하는 경우,
/v1/chat/completions(OpenAI 형식)을 우선 사용하세요. 호환성이 가장 좋습니다.
APIYI apiyi.com 플랫폼의 OpenAI 호환 엔드포인트는 Thinking 모델에 대한 형식 적응이 이미 되어 있으며, thinking blocks의 변환을 자동으로 처리합니다.
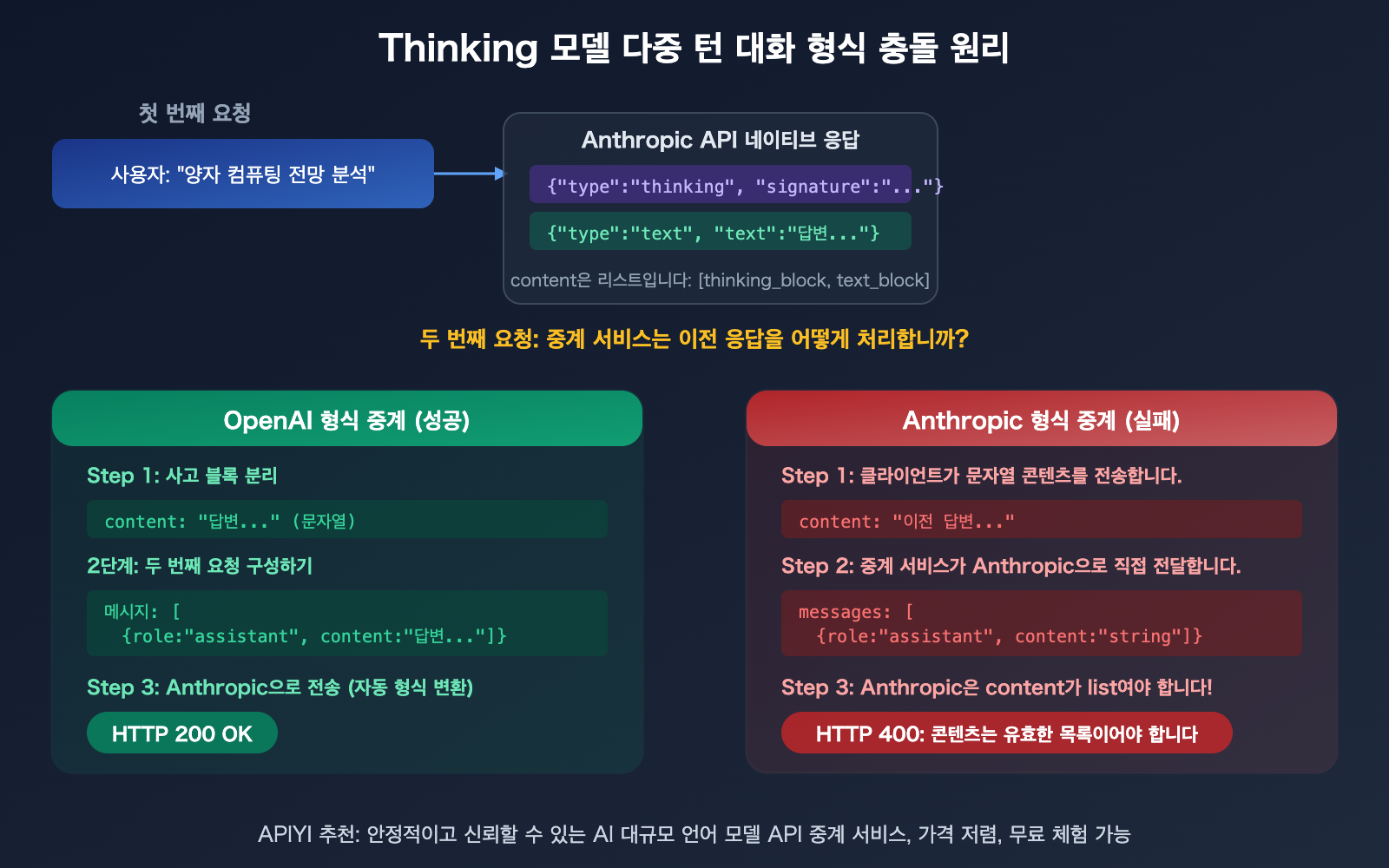
Claude Thinking 모델 API: 왜 OpenAI 형식이 더 잘 동작할까요?
이것은 가장 직관에 반대되는 부분입니다: "비네이티브"인 OpenAI 형식으로 Claude Thinking 모델을 호출할 때 오히려 호환성이 더 좋습니다. 그 이유는 세 가지입니다:
이유 1: content 형식의 허용 범위 차이
OpenAI 형식은 content가 순수 문자열 "hello"일 수도 있고, 내용 블록 배열 [{"type":"text","text":"hello"}]일 수도 있도록 허용합니다. Anthropic 네이티브 형식은 내용 블록 배열만 허용하며, 문자열 형식은 바로 오류를 발생시킵니다.
클라이언트 코드가 문자열 방식으로 content를 전달할 때(이것은 OpenAI SDK의 기본 동작입니다), 중계가 OpenAI 형식 채널을 통해 이루어지면 클라이언트와 업스트림 엔드포인트의 형식이 일치하여 변환 문제가 없습니다. 하지만 Anthropic 형식 채널을 통해 이루어지면 문자열은 허용되지 않습니다.
이유 2: thinking 블록의 자동 제거
OpenAI 호환 모드는 Claude 응답의 thinking 블록을 자동으로 제거하고 최종 텍스트만 반환합니다. 이는 다음을 의미합니다:
- 클라이언트는 thinking 블록을 받지 않습니다
- 다음 대화 라운드에서 thinking 블록을 다시 전달할 필요가 없습니다
- thinking 블록 정렬 문제가 존재하지 않습니다
Anthropic 네이티브 형식은 다중 라운드 대화에서 thinking 블록을 완전히 보존할 것을 요구하며, assistant 메시지는 반드시 thinking 블록으로 시작해야 합니다. 중계가 이 정렬 요구사항을 올바르게 처리하지 않으면 오류가 발생합니다.
이유 3: thoughtSignature의 전달 문제
앞서 설명한 대로, Anthropic 형식의 thinking 블록에는 암호화된 서명(signature)이 포함되어 있으며, 이는 원래 그대로 다시 전달되어야 합니다. OpenAI 형식은 이 단계를 직접 건너뜁니다—서명을 반환하지도 않고, 서명을 다시 전달할 필요도 없습니다.
🎯 선택 제안: API 중계를 통해 Claude Thinking 모델을 호출할 때는
/v1/chat/completions형식을 우선 사용하여 thinking 블록 형식 호환성 문제를 피하세요.
APIYI apiyi.com의 OpenAI 호환 엔드포인트는 이미 Thinking 모델에 대해 완전히 적응되었습니다.
Claude Thinking 모델 API 호출 방식 비교
Claude Thinking 모델 API 세 가지 호출 방식
| 방식 | 엔드포인트 | 형식 호환성 | thinking 가시성 | 프롬프트 캐싱 |
|---|---|---|---|---|
| OpenAI 형식 중계 | /v1/chat/completions |
최상(string content 허용) | 보이지 않음 | 지원 안 함 |
| Anthropic 네이티브 직접 연결 | /v1/messages |
형식을 엄격히 준수해야 함 | 보임 | 지원 |
| Anthropic 형식 중계 | /v1/messages(중계) |
중계 구현에 따라 다름 | 중계에 따라 다름 | 부분 지원 |
Claude Thinking 모델 API 모델 이름 차이
다른 플랫폼에서 Thinking 모델의 명명 방식이 다릅니다. 이것도 흔한 혼란점입니다:
| 플랫폼 | 모델 이름 | thinking 활성화 방식 |
|---|---|---|
| Anthropic 공식 | claude-opus-4-6 |
thinking: {"type": "adaptive"} 파라미터 |
| API 중계(예: APIYI) | claude-opus-4-6-thinking |
모델 이름 접미사로 암시적 활성화 |
| OpenRouter | anthropic/claude-opus-4.6 |
파라미터 활성화 |
| AWS Bedrock | anthropic.claude-opus-4-6-v1 |
파라미터 활성화 |
Anthropic 공식 API에는 claude-opus-4-6-thinking이라는 모델 이름이 없습니다. -thinking 접미사는 중계 플랫폼의 명명 규칙으로, 사용자가 모델 이름을 통해 직접 thinking 기능을 활성화할 수 있도록 하며, 수동으로 파라미터를 설정할 필요가 없습니다.
팁: APIYI apiyi.com에서
claude-opus-4-6-thinking모델 이름을 사용하면, 플랫폼이 자동으로 요청에thinking: {"type": "adaptive"}파라미터를 추가합니다. 이렇게 하면 코드를 수정하지 않고도 OpenAI SDK를 통해 바로 thinking 능력을 얻을 수 있습니다.
Claude Thinking 모델 API 자주 발생하는 문제와 해결 방법

자주 묻는 질문
Q1: OpenAI 형식으로 Thinking 모델을 호출하면 사고 능력을 잃나요?
아니요. 모델의 사고(thinking) 과정은 Anthropic 서버 측에서 발생하며, 호출 엔드포인트 형식과는 무관합니다. OpenAI 형식으로 호출할 때도 모델은 여전히 완전한 사고 추론을 수행하며, 단지 사고 과정의 텍스트 요약이 클라이언트에 반환되지 않을 뿐입니다. 최종 답변의 품질과 깊이는 동일합니다. 여러분은 "심사숙고한 답변"을 얻지만, "사고 과정의 텍스트 기록"은 볼 수 없습니다.
Q2: 어떤 상황에서 /v1/messages 네이티브 형식을 꼭 사용해야 하나요?
두 가지 상황에서 네이티브 형식이 필요합니다: 1) 디버깅, 교육 또는 추론 체인을 보여주기 위해 모델의 사고 과정(summarized thinking)을 확인해야 할 때; 2) 비용 절감을 위해 프롬프트 캐싱(prompt caching)을 사용해야 할 때 — 캐싱 기능은 /v1/messages 엔드포인트에서만 사용할 수 있습니다. 이 두 가지 요구사항이 모두 없다면 OpenAI 형식을 사용하는 것이 더 편리합니다. APIYI apiyi.com의 OpenAI 호환 엔드포인트를 통해 호출하는 것이 가장 간단합니다.
Q3: APIYI 관리자 화면에서 채널을 /v1/messages로 설정했을 때 호환성 문제는 어떻게 해결하나요?
두 가지 해결책이 있습니다: 1) 채널을 OpenAI 유형(/v1/chat/completions)으로 전환하여 형식 변환 문제를 근본적으로 피하는 방법; 2) 반드시 /v1/messages 채널을 사용해야 한다면, 중계 계층이 클라이언트의 string content를 list 형식으로 올바르게 변환하고, 다중 턴 대화에서 thinking blocks의 순서와 signature 전달을 올바르게 처리하도록 해야 합니다. 첫 번째 방법이 더 간단하고 안정적입니다.
Q4: adaptive thinking과 구버전 extended thinking의 차이점은 무엇인가요?
Opus 4.6에서는 thinking: {"type": "adaptive"}(적응형 사고)를 사용하는 것을 권장합니다. 이 경우 모델은 문제의 복잡도에 따라 자동으로 사고 여부와 깊이를 결정합니다. 구버전인 thinking: {"type": "enabled", "budget_tokens": N}은 Opus 4.6과 Sonnet 4.6에서 더 이상 사용되지 않습니다. 새 버전에서는 사고 깊이를 제어하는 effort 매개변수(low/medium/high/max)가 추가되었으며, 기본값은 high입니다.
요약
Claude Thinking 모델 API 호환성 문제의 핵심 포인트:
- 에러의 근본 원인은 content 형식 불일치: Anthropic 원본 API는 content를 리스트(list)로 엄격히 요구하지만, OpenAI 형식은 문자열도 허용합니다. 중계 채널이
/v1/messages를 사용하는데 클라이언트가 문자열을 전송하면Input should be a valid list에러가 발생합니다. - OpenAI 형식이 호환성 면에서 더 우수: 자동으로 thinking 블록을 제거하고, signature를 다시 전달할 필요가 없으며, content가 문자열일 수 있어 중계 시나리오에서 최적의 선택입니다.
- -thinking 접미사는 중계 규약일 뿐, 공식 모델명이 아님: 공식 모델명은
claude-opus-4-6이며, thinking은 파라미터를 통해 활성화됩니다.
API 중계를 통해 Claude Thinking 모델을 호출하는 가장 간단한 방법은 OpenAI 호환 형식을 일관되게 사용하는 것입니다.
APIYI apiyi.com을 통해 호출하는 것을 추천합니다. 플랫폼이 Thinking 모델에 대한 형식 호환성을 최적화했으며, 무료 크레딧과 다중 모델 통합 인터페이스를 제공합니다.
📚 참고 자료
-
Claude API Extended Thinking 문서: 사고 모드의 완전한 API 참조
- 링크:
platform.claude.com/docs/en/build-with-claude/extended-thinking - 설명: 적응형 사고(adaptive thinking), effort 파라미터, 콘텐츠 블록 형식에 대한 상세 설명을 포함합니다.
- 링크:
-
Claude API OpenAI SDK 호환성 문서: OpenAI 형식으로 Claude를 호출하는 공식 가이드
- 링크:
platform.claude.com/docs/en/api/openai-sdk - 설명: 호환성 제한 및 지원되지 않는 기능 목록을 포함합니다.
- 링크:
-
Claude API 오류 코드 참조: 모든 API 오류 유형에 대한 설명
- 링크:
platform.claude.com/docs/en/api/errors - 설명: invalid_request_error에 대한 구체적인 문제 해결 방법을 포함합니다.
- 링크:
-
APIYI 문서 센터: OpenAI 호환 인터페이스를 통해 Claude Thinking 모델 호출
- 링크:
docs.apiyi.com - 설명: Thinking 모델에 대한 형식 적응을 완료했으며, thinking 블록 변환을 자동으로 처리합니다.
- 링크:
저자: APIYI 기술 팀
기술 교류: 댓글에서 토론을 환영합니다. 더 많은 자료는 APIYI docs.apiyi.com 문서 센터를 방문하세요.