
Note de l'auteur : Analyse comparative approfondie des capacités de programmation entre Claude Opus 4.7 et GLM-5.1, couvrant les benchmarks tels que SWE-Bench et CursorBench, le codage autonome sur longue période et la tarification API, pour aider les développeurs à choisir le modèle le plus adapté à leurs besoins.

En avril 2026, le domaine du codage par IA a connu une confrontation majeure entre deux poids lourds. Le 7 avril, Zhipu AI (Z.ai) a lancé le modèle open source GLM-5.1, qui a atteint la première place mondiale avec un score de 58,4 sur SWE-Bench Pro. À peine 9 jours plus tard, le 16 avril, Anthropic a dévoilé Claude Opus 4.7, faisant grimper le score CursorBench de 58 % à 70 % et triplant le volume de tâches résolues sur Rakuten-SWE-Bench par rapport à la version 4.6.
Bien que ces deux modèles diffèrent par leur positionnement, leur architecture et leur coût, ils s'affrontent frontalement sur le terrain critique du développement logiciel. APIYI (apiyi.com) a intégré ces deux modèles, permettant aux développeurs de les comparer rapidement via une interface unifiée.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez les atouts en programmation de chaque modèle et saurez lequel choisir selon vos besoins.
Comparaison des paramètres clés : Claude Opus 4.7 vs GLM-5.1
| Dimension de comparaison | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Date de sortie | 16/04/2026 | 07/04/2026 |
| Développeur | Anthropic | Zhipu AI (Z.ai) |
| Architecture | Propriétaire | 744B MoE (40B paramètres actifs) |
| Licence | ❌ Propriétaire | ✅ Licence MIT (Open Source) |
| Fenêtre de contexte | 1M tokens | 200K tokens |
| Sortie maximale | 128K tokens | 131K tokens |
| Prix API (entrée) | 5 $ / MTok | 1 $ / MTok |
| Prix API (sortie) | 25 $ / MTok | 3,2 $ / MTok |
| Capacités visuelles | ✅ 2576px / 3,75MP | ✅ Supporté |
| Mode de réflexion | Adaptive Thinking | Thinking multimodal |
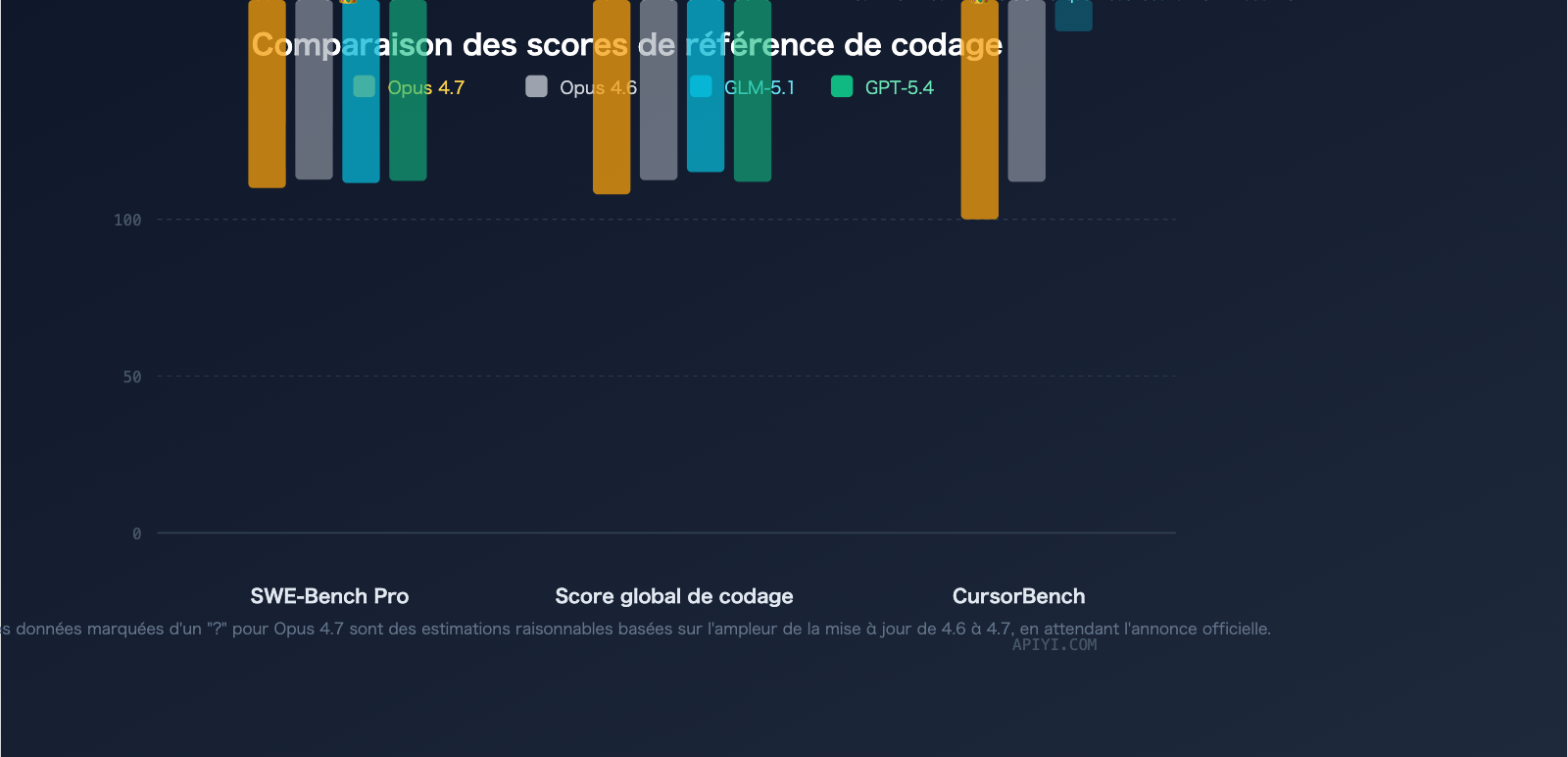
| SWE-Bench Pro | Estimé > 57,3 (score de la 4.6) | 58,4 (actuel leader) |
| CursorBench | 70 % | — |
| Matériel d'entraînement | Cluster GPU US | Huawei Ascend 910B |
🎯 Conclusion rapide : Si vous recherchez une capacité de codage ultime, une fenêtre de contexte étendue et une compréhension visuelle, optez pour Opus 4.7. Si vous privilégiez un rapport qualité-prix imbattable, une solution open source contrôlable et une solide capacité de codage, choisissez GLM-5.1. Les deux modèles sont disponibles sur APIYI (apiyi.com).
Analyse comparative des benchmarks de programmation
SWE-Bench Pro : GLM-5.1 en tête pour le moment
Le SWE-Bench Pro est actuellement l'un des benchmarks de codage réel les plus rigoureux, évaluant la capacité des modèles à résoudre des problèmes (issues) authentiques sur GitHub.
| Modèle | SWE-Bench Pro | Classement |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | Prévu > 57.3 | À venir |
Avec un score de 58,4, GLM-5.1 se hisse en tête du SWE-Bench Pro, dépassant GPT-5.4 (57,7) et Claude Opus 4.6 (57,3). Il est intéressant de noter que l'Opus 4.7 affiche des progrès significatifs en programmation par rapport à la version 4.6 (+12 points de pourcentage sur CursorBench, 3 fois plus sur Rakuten-SWE-Bench). Son score au SWE-Bench Pro devrait donc augmenter sensiblement, bien qu'il n'ait pas encore été officiellement publié au moment de la rédaction.
CursorBench : Large avance pour Opus 4.7
Le CursorBench évalue la capacité de codage des modèles dans un environnement IDE réel (l'éditeur Cursor), ce qui correspond davantage aux scénarios de développement quotidiens.
| Modèle | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | Données indisponibles |
Score de codage composite (Coding Composite)
Le score de codage composite agrège plusieurs dimensions, notamment SWE-Bench Pro, Terminal-Bench 2.0 et NL2Repo :
| Modèle | Score de codage composite |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | Prévu nettement supérieur à 4.6 |
En termes de score de codage global, Claude Opus 4.6 devance GLM-5.1 avec 57,5 contre 54,9. Les capacités de codage globales de l'Opus 4.7 devraient creuser encore davantage cet écart.
🎯 Analyse : Si GLM-5.1 s'impose comme le plus performant sur le test spécifique SWE-Bench Pro, la famille Claude conserve une longueur d'avance sur les capacités de codage globales. Les développeurs peuvent utiliser le service proxy API APIYI (apiyi.com) pour accéder aux deux modèles et effectuer des tests A/B sur leurs propres projets.
Analyse approfondie des capacités en programmation
Les benchmarks ne sont qu'une dimension. Dans des scénarios de programmation réels, les deux modèles révèlent des avantages très distincts.
Codage autonome sur longue période
C'est la fonctionnalité phare de GLM-5.1.
| Capacité long terme | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Temps d'exécution autonome max. | Selon le budget de tâche | 8 heures en continu |
| Boucle autonome | Supporte les agents multi-étapes | Cycle complet « Planification→Exécution→Test→Correction→Optimisation » |
| Gestion du budget de jetons | Budgets de tâches (nouvelle fonction) | Gestion intégrée des tâches longues |
| Auto-correction | Correction automatique lors du codage | Cycle autonome : Expérimentation→Analyse→Optimisation |
GLM-5.1 est capable d'exécuter des tâches de codage de manière autonome pendant jusqu'à 8 heures, formant une boucle « Expérimentation→Analyse→Optimisation », ce qui est extrêmement avantageux pour les refactorisations majeures ou les migrations inter-modules.
Bien qu'Opus 4.7 ait renforcé ses capacités sur les tâches longues via les budgets de tâches et le niveau de raisonnement xhigh, il se concentre davantage sur « l'achèvement efficace dans le respect du budget » plutôt que sur une exécution prolongée illimitée.
Tâches d'agent (Agentic Tasks)
| Capacité d'agent | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Support natif MCP | ✅ Optimisation poussée | ✅ Supporté |
| Efficacité d'appel d'outils | Moins d'appels, plus de raisonnement | Utilisation active des outils |
| Fiabilité multi-étapes | Très élevée | Élevée |
| Gestion du contexte | Contexte ultra-long de 1M de jetons | 200K jetons |
| Gestion des sous-agents | Contrôle précis (ajustable) | Supporté |
Pour les tâches d'agent, la fenêtre de contexte de 1M de jetons d'Opus 4.7 constitue un avantage écrasant. Lors du traitement de bases de code volumineuses, Opus 4.7 peut charger davantage de contexte de fichiers en une seule fois, réduisant ainsi la perte d'informations.
Revue de code et refactorisation
| Capacité de revue | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Précision des instructions | Exécution littérale, sans omission | Interprétation flexible |
| Capacité d'auto-vérification | Vérification avant sortie (nouveau) | Supporté |
| Traitement de gros fichiers | Contexte de 1M pour charger toute la base | Limite de 200K nécessitant un découpage |
| Revue visuelle | Compréhension de captures haute résolution | Vision basique |
Codage rapide et développement quotidien
| Codage quotidien | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Vitesse de réponse | Moyenne | Plus rapide |
| Coût API | 5 $ / 25 $ par MTok | 1 $ / 3,2 $ par MTok |
| Style de code | Plus concis, axé sur le raisonnement | Commentaires détaillés, axé sur les outils |
| Support multilingue | Excellent | Excellent (commentaires en chinois plus naturels) |
Comparaison des prix : un écart de coût de 5 fois
Le prix est un facteur incontournable lors du choix d'un modèle. L'écart tarifaire entre les deux est très important :
| Élément de facturation | Claude Opus 4.7 | GLM-5.1 | Écart |
|---|---|---|---|
| Prix d'entrée | 5 $ / MTok | 1 $ / MTok | Opus est 5 fois plus cher |
| Prix de sortie | 25 $ / MTok | 3,2 $ / MTok | Opus est 7,8 fois plus cher |
| Prix du cache | Remise standard | 0,26 $ / MTok | Cache GLM très bon marché |
| Prime contexte long | Aucune | Aucune | — |
Estimation des coûts en situation réelle
Imaginons une équipe de développement de taille moyenne consommant 500M de jetons par mois (moitié entrée, moitié sortie) :
| Modèle utilisé | Coût mensuel entrée | Coût mensuel sortie | Total mensuel |
|---|---|---|---|
| Opus 4.7 | 1 250 $ | 6 250 $ | 7 500 $ |
| GLM-5.1 | 250 $ | 800 $ | 1 050 $ |
| Différence | — | — | 6 450 $/mois |
Le coût de GLM-5.1 ne représente qu'environ 14 % de celui d'Opus 4.7. Pour les équipes sensibles au budget, c'est une différence décisive.
🎯 Stratégie d'optimisation des coûts : via la plateforme APIYI apiyi.com, vous pouvez jongler entre les deux modèles : confiez la conception d'architecture complexe et la revue de code à Opus 4.7, et déléguez la génération de code quotidienne massive ainsi que les tâches par lots à GLM-5.1. L'interface unifiée de la plateforme rend la mise en œuvre d'une stratégie multi-modèles extrêmement peu coûteuse.

Conseils de sélection selon les scénarios
Scénarios pour choisir Claude Opus 4.7
- Traitement de bases de code volumineuses : lorsque vous devez charger le contexte de dizaines de fichiers en une seule fois (1M vs 200K).
- Revue de code et audit de sécurité : nécessite une précision extrême et des capacités d'auto-vérification.
- Développement multimodal : besoin de comprendre des captures d'écran d'UI, des maquettes de design ou des images de documents (vision haute résolution 3,75 MP).
- Exigences de fiabilité en entreprise : nécessite un support commercial propriétaire stable.
- Codage complexe à forte intensité de raisonnement : calculs mathématiques, conception d'algorithmes et autres scénarios exigeant une réflexion approfondie.
Scénarios pour choisir GLM-5.1
- Développement autonome sur longue période : nécessite que le modèle travaille en continu pendant plusieurs heures pour effectuer des refactorisations majeures.
- Tâches par lots sensibles aux coûts : intégration CI/CD, génération de code en masse, tests automatisés.
- Déploiement privé : besoin d'exécuter le modèle sur vos propres serveurs (licence MIT, entièrement ouvert).
- Environnement de développement en chinois : les commentaires de code et la génération de documentation en chinois sont plus naturels et fluides.
- Tâches de type SWE-Bench : résolution d'issues GitHub, correction de bugs et autres tâches de codage du monde réel.
Meilleures pratiques : la stratégie du double modèle
| Type de tâche | Modèle recommandé | Raison |
|---|---|---|
| Conception d'architecture et solutions techniques | Opus 4.7 | Raisonnement approfondi + contexte ultra-long |
| Écriture de code quotidienne | GLM-5.1 | Faible coût, qualité suffisante |
| Revue de code | Opus 4.7 | Précision + auto-vérification |
| Génération de code en masse | GLM-5.1 | Coût réduit à 14 % |
| Correction de bugs (GitHub Issue) | GLM-5.1 | En tête du classement SWE-Bench Pro |
| Refactorisation multi-fichiers | Opus 4.7 | Avantage du contexte 1M |
| Tâches autonomes de longue durée | GLM-5.1 | 8 heures d'exécution autonome |
| Développement lié à l'UI/captures d'écran | Opus 4.7 | Vision haute résolution 3,75 MP |
🎯 Conseil de gestion unifiée : APIYI (apiyi.com) propose désormais Claude Opus 4.7 et GLM-5.1. Les développeurs peuvent invoquer les deux modèles via une seule clé API et une interface compatible OpenAI unifiée, permettant de basculer de manière flexible selon le type de tâche pour optimiser l'efficacité du codage et le rapport coût-performance.
Foire aux questions (FAQ)
Q1 : GLM-5.1 est-il vraiment plus performant que Claude Opus ?
Cela dépend du critère. Sur l'épreuve unique SWE-Bench Pro, GLM-5.1 (58,4) surpasse effectivement Opus 4.6 (57,3), mais en termes de score global de codage, Opus 4.6 (57,5) devance GLM-5.1 (54,9). Opus 4.7, en tant que mise à jour majeure de la version 4.6, devrait creuser l'écart en termes de capacités de codage globales. Dans l'ensemble, Opus 4.7 est plus complet, mais GLM-5.1 possède des avantages uniques dans des scénarios spécifiques (tâches de longue durée, type SWE-Bench).
Q2 : GLM-5.1 est beaucoup moins cher, la qualité est-elle suffisante ?
Pour la plupart des tâches de codage, oui. Les performances de GLM-5.1 sur SWE-Bench Pro prouvent qu'il possède des capacités de codage de premier plan. Certaines évaluations montrent qu'il atteint 94,6 % des capacités de codage de Claude Opus 4.6, pour un prix représentant seulement 1/5 à 1/8 du coût. Effectuer une comparaison réelle via APIYI (apiyi.com) reste la méthode la plus prudente avant de prendre une décision.
Q3 : Les deux modèles peuvent-ils être appelés via la même interface ?
Oui. APIYI (apiyi.com) fournit une interface unifiée compatible avec OpenAI. Il suffit de modifier l'ID du modèle pour basculer entre Claude Opus 4.7 et GLM-5.1, sans avoir à modifier votre architecture de code ou à gérer plusieurs clés API.
Résumé
Voici les conclusions clés du comparatif de programmation entre Claude Opus 4.7 et GLM-5.1 :
- SWE-Bench Pro : GLM-5.1 (58,4) est actuellement en tête, bien que le score d'Opus 4.7 n'ait pas encore été publié.
- Capacités de codage globales : La série Opus reste globalement en tête, avec des performances impressionnantes pour la version 4.7 : 70 % sur CursorBench et une amélioration par 3 sur Rakuten-SWE-Bench.
- Codage autonome longue durée : La capacité d'exécution autonome de 8 heures de GLM-5.1 constitue un argument de vente unique.
- Fenêtre de contexte : Avec 1M de jetons, Opus 4.7 offre une fenêtre 5 fois plus grande que celle de GLM-5.1, ce qui lui donne un avantage net pour traiter de vastes bases de code.
- Différence de prix : Le coût de GLM-5.1 ne représente qu'environ 14 % de celui d'Opus 4.7.
- Avantage de l'open source : GLM-5.1 est sous licence MIT, ce qui permet un déploiement privé et une personnalisation libre.
La stratégie optimale n'est pas de choisir l'un ou l'autre, mais de combiner les deux modèles : utilisez Opus 4.7 pour les tâches à haute valeur ajoutée et GLM-5.1 pour les tâches répétitives à haut volume. APIYI (apiyi.com) a intégré les deux modèles ; les développeurs peuvent ainsi les invoquer de manière flexible via une interface unifiée pour atteindre le meilleur équilibre entre efficacité de codage et maîtrise des coûts.
📚 Références
-
VentureBeat – Rapport sur la sortie open source de GLM-5.1 : Rapport détaillé sur la première place de GLM-5.1 au SWE-Bench Pro.
- Lien :
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - Note : Rapport d'un média technologique faisant autorité, incluant les données de benchmarks.
- Lien :
-
MarkTechPost – Analyse technique de GLM-5.1 : Analyse technique du modèle agentique de 754B.
- Lien :
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - Note : Inclut des détails sur l'architecture et l'analyse de la capacité d'exécution autonome de 8 heures.
- Lien :
-
Anthropic – Lancement de Claude Opus 4.7 : Notes de mise à jour complètes.
- Lien :
anthropic.com/news/claude-opus-4-7 - Note : Annonce officielle et données de benchmarks pour Opus 4.7.
- Lien :
-
Page HuggingFace de GLM-5.1 : Téléchargement du modèle open source et documentation.
- Lien :
huggingface.co/zai-org/GLM-5.1 - Note : Poids du modèle sous licence MIT et guide de déploiement.
- Lien :
-
Documentation API Claude – Aperçu des modèles : Spécifications techniques de tous les modèles Claude.
- Lien :
platform.claude.com/docs/en/about-claude/models/overview - Note : Paramètres officiels du modèle, tarification et comparaison des fonctionnalités.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans les commentaires. Pour plus d'informations, consultez le centre de documentation APIYI sur docs.apiyi.com.