
Nota do autor: Análise profunda das diferenças de capacidade na área de programação entre o Claude Opus 4.7 e o GLM-5.1, abrangendo benchmarks como SWE-Bench e CursorBench, codificação autônoma de longo ciclo e precificação de API, para ajudar desenvolvedores a escolher o modelo de codificação mais adequado.
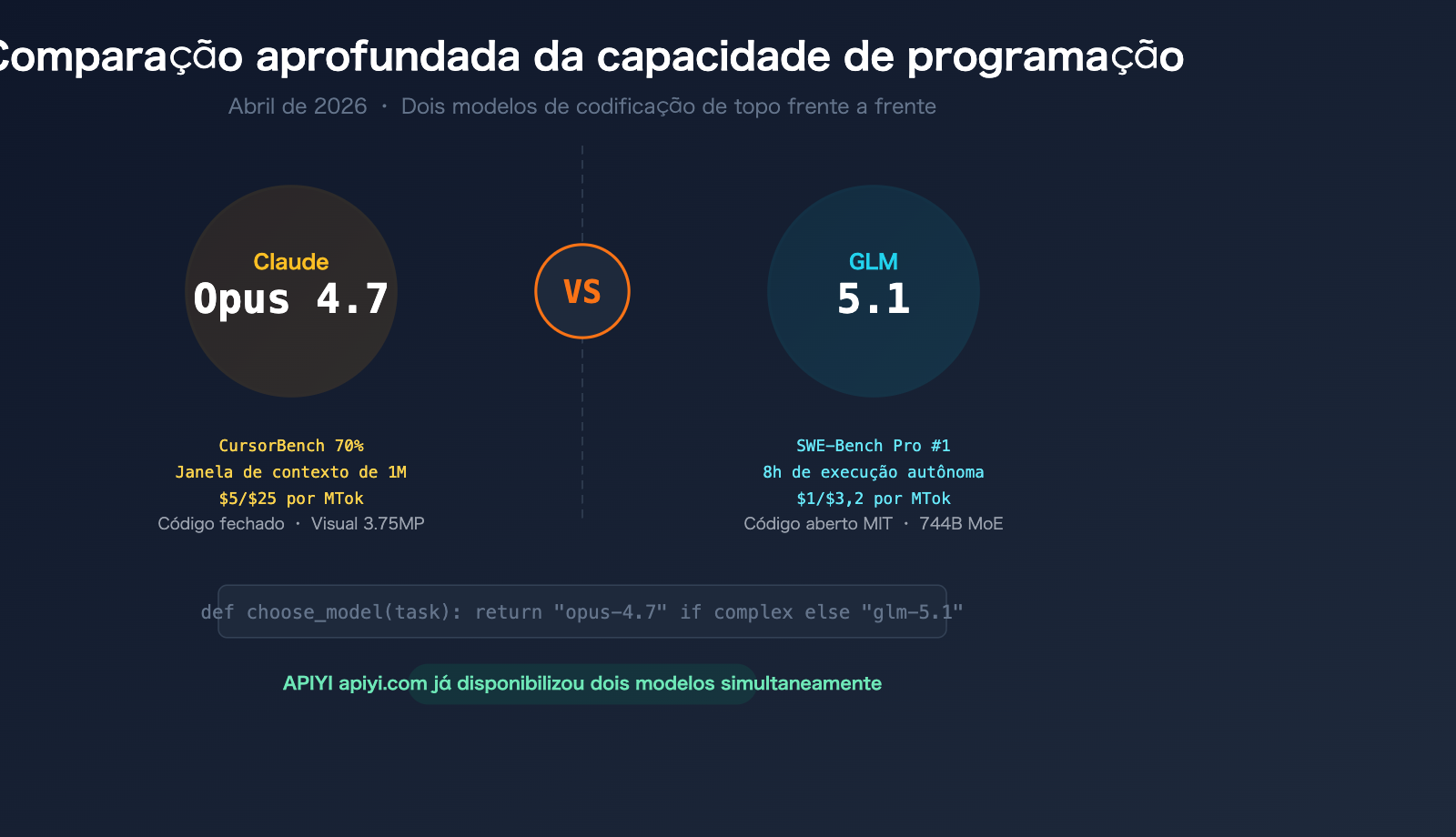
Em abril de 2026, o campo da codificação por IA testemunhou um confronto direto entre dois grandes competidores. No dia 7 de abril, a Zhipu AI (Z.ai) lançou o modelo de código aberto GLM-5.1, que alcançou o topo do ranking global com 58,4 pontos no SWE-Bench Pro; apenas 9 dias depois, em 16 de abril, a Anthropic lançou o Claude Opus 4.7, com o CursorBench saltando de 58% para 70% e a resolução de tarefas no Rakuten-SWE-Bench atingindo o triplo da versão 4.6.
Os dois modelos possuem posicionamentos, arquiteturas e preços muito diferentes, mas competem diretamente no campo de batalha central da programação. O APIYI apiyi.com já disponibilizou ambos os modelos, permitindo que desenvolvedores comparem rapidamente através de uma interface unificada.
Valor principal: Ao terminar este artigo, você entenderá as vantagens de codificação de cada modelo e qual escolher para diferentes cenários.
Comparação dos parâmetros principais: Claude Opus 4.7 vs GLM-5.1
| Dimensão de comparação | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Data de lançamento | 16/04/2026 | 07/04/2026 |
| Desenvolvedor | Anthropic | Zhipu AI (Z.ai) |
| Arquitetura do modelo | Fechada | 744B MoE (40B parâmetros ativos) |
| Licença de código aberto | ❌ Fechado | ✅ Licença MIT (totalmente aberto) |
| Janela de contexto | 1M tokens | 200K tokens |
| Saída máxima | 128K tokens | 131K tokens |
| Preço de entrada da API | $5 / MTok | $1 / MTok |
| Preço de saída da API | $25 / MTok | $3.2 / MTok |
| Capacidade visual | ✅ 2576px / 3.75MP | ✅ Suportado |
| Modo de raciocínio | Raciocínio Adaptativo | Raciocínio multimodal |
| SWE-Bench Pro | Estimado > 57.3 (pontuação da 4.6) | 58.4 (topo do ranking atual) |
| CursorBench | 70% | — |
| Hardware de treinamento | Cluster de GPU nos EUA | Huawei Ascend 910B |
🎯 Conclusão rápida: Se você busca capacidade de codificação extrema + janela de contexto super longa + compreensão visual, escolha o Opus 4.7; se você busca custo-benefício extremo + controle de código aberto + capacidade de codificação robusta, escolha o GLM-5.1. Ambos os modelos já estão disponíveis no APIYI apiyi.com.
Comparativo Profundo de Benchmarks de Programação
SWE-Bench Pro: GLM-5.1 Lidera Atualmente
O SWE-Bench Pro é um dos benchmarks de codificação do mundo real mais respeitados, avaliando a capacidade de um Modelo de Linguagem Grande em resolver problemas reais no GitHub.
| Modelo | SWE-Bench Pro | Ranking |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | Previsto > 57.3 | A atualizar |
O GLM-5.1 assumiu a liderança do SWE-Bench Pro com 58.4 pontos, superando o GPT-5.4 (57.7) e o Claude Opus 4.6 (57.3). Vale notar que o Opus 4.7 apresenta melhorias significativas em relação à versão 4.6 na área de codificação (CursorBench +12pp, Rakuten-SWE-Bench 3x), e espera-se um aumento substancial em sua pontuação no SWE-Bench Pro, embora os dados oficiais ainda não tenham sido divulgados.
CursorBench: Opus 4.7 com Liderança Expressiva
O CursorBench avalia a capacidade de escrita de código do modelo em um ambiente de IDE real (editor Cursor), aproximando-se mais dos cenários de desenvolvimento do dia a dia.
| Modelo | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | Sem dados |
Pontuação Composta de Codificação (Coding Composite)
A pontuação composta de codificação agrega múltiplos indicadores, como SWE-Bench Pro, Terminal-Bench 2.0 e NL2Repo:
| Modelo | Pontuação Composta |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | Previsto significativamente maior que 4.6 |
Na pontuação composta, o Claude Opus 4.6 lidera com 57.5 contra 54.9 do GLM-5.1. Espera-se que a capacidade de codificação composta do Opus 4.7 amplie ainda mais essa vantagem.
🎯 Análise: O GLM-5.1 provou ser o mais forte no SWE-Bench Pro, mas em termos de capacidade de codificação composta, a família Claude ainda mantém a dianteira. Desenvolvedores podem utilizar o serviço proxy de API da APIYI (apiyi.com) para acessar ambos os modelos e realizar testes A/B em seus projetos reais.
Comparação Profunda de Capacidades em Cenários de Programação
Benchmarks são apenas uma dimensão. Em cenários reais de programação, os dois modelos apresentam vantagens bastante distintas.
Codificação Autônoma de Longo Ciclo
Esta é a funcionalidade matadora do GLM-5.1.
| Capacidade de Longo Ciclo | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Tempo máximo de execução autônoma | Depende do orçamento da tarefa | 8 horas ininterruptas |
| Ciclo autônomo | Suporta agentes de múltiplas etapas | Ciclo completo de "Planejamento → Execução → Teste → Correção → Otimização" |
| Gestão de orçamento de tokens | Orçamentos de tarefa (novo recurso) | Gestão de tarefas longas integrada |
| Auto-correção | Correção automática durante a codificação | Ciclo autônomo de experimento → análise → otimização |
O GLM-5.1 consegue executar tarefas de codificação de forma contínua e autônoma por até 8 horas, formando um ciclo de "experimento → análise → otimização", o que é extremamente vantajoso em cenários como grandes refatorações e migrações entre módulos.
Embora o Opus 4.7 tenha aprimorado suas capacidades para tarefas longas através dos orçamentos de tarefa e do nível de raciocínio xhigh, ele foca mais em "concluir com eficiência dentro do orçamento" do que em "execução ilimitada por longos períodos".
Tarefas de Agente (Agentic Tasks)
| Capacidade de Agente | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Suporte nativo a MCP | ✅ Otimização profunda | ✅ Suportado |
| Eficiência de chamada de ferramenta | Menos chamadas, mais raciocínio | Uso ativo de ferramentas |
| Confiabilidade em múltiplas etapas | Muito alta | Alta |
| Gestão de contexto | Contexto ultralongo de 1M tokens | 200K tokens |
| Gestão de subagentes | Controle refinado (ajustável) | Suportado |
Em tarefas de agente, a janela de contexto de 1M tokens do Opus 4.7 é uma vantagem avassaladora. Ao lidar com grandes bases de código, o Opus 4.7 pode carregar mais contexto de arquivos de uma só vez, reduzindo a perda de informações.
Revisão e Refatoração de Código
| Capacidade de Revisão | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Precisão de comando | Execução mais literal, precisa e sem omissões | Interpretação flexível |
| Capacidade de autoverificação | Verifica antes de gerar (novo) | Suportado |
| Processamento de arquivos grandes | 1M de contexto carrega a base completa | Limite de 200K pode exigir segmentação |
| Revisão visual | Compreensão de capturas de alta resolução | Visual básico |
Codificação Rápida e Desenvolvimento Diário
| Codificação Diária | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Velocidade de resposta | Média | Mais rápida |
| Custo de API | $5/$25 por MTok | $1/$3.2 por MTok |
| Estilo de código | Mais conciso, focado em raciocínio | Comentários detalhados, focado em ferramentas |
| Suporte a idiomas | Excelente | Excelente (comentários em chinês mais naturais) |
Comparação de Preços: Uma diferença de custo de 5 vezes
O preço é um fator que não pode ser ignorado ao escolher um modelo. A diferença de precificação entre ambos é enorme:
| Item de cobrança | Claude Opus 4.7 | GLM-5.1 | Diferença |
|---|---|---|---|
| Preço de entrada | $5 / MTok | $1 / MTok | Opus é 5 vezes mais caro |
| Preço de saída | $25 / MTok | $3.2 / MTok | Opus é 7.8 vezes mais caro |
| Preço de cache | Desconto padrão de cache | $0.26 / MTok | Cache do GLM é extremamente barato |
| Sobretaxa de contexto longo | Nenhuma | Nenhuma | — |
Estimativa de custo em cenários reais
Suponha uma equipe de desenvolvimento de médio porte que consome 500M de tokens por mês (metade entrada, metade saída):
| Modelo utilizado | Custo mensal de entrada | Custo mensal de saída | Total mensal |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| Diferença | — | — | $6,450/mês |
O custo do GLM-5.1 é de apenas cerca de 14% do Opus 4.7. Para equipes sensíveis ao orçamento, essa é uma diferença decisiva.
🎯 Estratégia de otimização de custos: Através da plataforma APIYI apiyi.com, você pode alternar de forma flexível entre os dois modelos — delegue o design de arquitetura complexa e a revisão de código ao Opus 4.7, e deixe a geração massiva de código diário e tarefas de processamento em lote para o GLM-5.1. A interface unificada da plataforma torna o custo de implementação de uma estratégia multimodelo extremamente baixo.

Sugestões de escolha para diferentes cenários
Cenários para escolher o Claude Opus 4.7
- Processamento de bases de código gigantescas: Quando você precisa carregar o contexto de dezenas de arquivos de uma só vez (1M vs 200K).
- Revisão de código e auditoria de segurança: Quando é necessária uma precisão extremamente alta e capacidade de autoverificação.
- Desenvolvimento multimodal: Quando você precisa entender capturas de tela de UI, esboços de design e imagens de documentos (visão de alta resolução de 3,75 MP).
- Requisitos de confiabilidade de nível empresarial: Quando você precisa de suporte comercial estável e de código fechado.
- Codificação complexa com uso intensivo de raciocínio: Cenários que exigem raciocínio profundo, como cálculos matemáticos e design de algoritmos.
Cenários para escolher o GLM-5.1
- Desenvolvimento autônomo de longo ciclo: Quando o modelo precisa trabalhar continuamente por várias horas para concluir grandes refatorações.
- Tarefas em lote sensíveis a custos: Integração CI/CD, geração de código em lote e testes automatizados.
- Implantação privada: Quando você precisa executar o modelo em seu próprio servidor (licença MIT, totalmente aberto).
- Ambiente de desenvolvimento em chinês: Geração de comentários de código e documentação em chinês de forma mais natural e fluida.
- Tarefas do tipo SWE-Bench: Resolução de problemas do GitHub, correção de bugs e outras tarefas de codificação do mundo real.
Melhores práticas: Estratégia de modelo duplo
| Tipo de tarefa | Modelo recomendado | Motivo |
|---|---|---|
| Design de arquitetura e soluções técnicas | Opus 4.7 | Raciocínio profundo + contexto ultralongo |
| Escrita de código diária | GLM-5.1 | Baixo custo, qualidade suficiente |
| Revisão de código | Opus 4.7 | Precisão + autoverificação |
| Geração de código em grande escala | GLM-5.1 | Custo de apenas 14% |
| Correção de bugs (GitHub Issue) | GLM-5.1 | Líder no ranking SWE-Bench Pro |
| Refatoração de múltiplos arquivos | Opus 4.7 | Vantagem de 1M de contexto |
| Tarefas autônomas de longa duração | GLM-5.1 | 8 horas de execução autônoma |
| Desenvolvimento relacionado a UI/capturas de tela | Opus 4.7 | Visão de alta resolução de 3,75 MP |
🎯 Sugestão de gerenciamento unificado: A APIYI (apiyi.com) disponibilizou tanto o Claude Opus 4.7 quanto o GLM-5.1. Os desenvolvedores podem realizar a invocação do modelo usando a mesma chave API e uma interface unificada compatível com OpenAI, alternando de forma flexível de acordo com o tipo de tarefa para alcançar o equilíbrio ideal entre eficiência de codificação e custo.
Perguntas frequentes
Q1: O GLM-5.1 é realmente melhor que o Claude Opus?
Depende da métrica. No item individual SWE-Bench Pro, o GLM-5.1 (58,4) supera de fato o Opus 4.6 (57,3), mas na pontuação geral de codificação, o Opus 4.6 (57,5) lidera sobre o GLM-5.1 (54,9). Como uma atualização significativa do 4.6, espera-se que o Opus 4.7 amplie ainda mais a diferença na capacidade geral de codificação. No geral, o Opus 4.7 é mais completo, mas o GLM-5.1 tem vantagens únicas em cenários específicos (tarefas de longo ciclo, tarefas do tipo SWE-Bench).
Q2: O GLM-5.1 é muito mais barato, a qualidade é suficiente?
Para a maioria das tarefas de codificação, sim. O desempenho do GLM-5.1 no SWE-Bench Pro prova que ele possui capacidade de codificação de alto nível. Dados de avaliação mostram que ele atingiu 94,6% da capacidade de codificação do Claude Opus 4.6, mas custa apenas 1/5 a 1/8 do valor. Fazer uma comparação real através da APIYI (apiyi.com) antes de tomar uma decisão é a maneira mais segura.
Q3: Os dois modelos podem ser chamados pela mesma interface?
Sim. A APIYI (apiyi.com) fornece uma interface unificada compatível com OpenAI. Basta alterar o ID do modelo para alternar entre o Claude Opus 4.7 e o GLM-5.1, sem a necessidade de modificar o framework de código ou gerenciar várias chaves API.
Resumo
Conclusões principais do comparativo de programação entre Claude Opus 4.7 e GLM-5.1:
- SWE-Bench Pro: O GLM-5.1 (58,4) lidera atualmente, mas a pontuação do Opus 4.7 ainda não foi divulgada.
- Capacidade de codificação abrangente: A série Opus lidera no geral; os 70% no CursorBench e o aumento de 3x no Rakuten-SWE-Bench do 4.7 são impressionantes.
- Codificação autônoma de longo prazo: A execução autônoma de 8 horas do GLM-5.1 é um diferencial único.
- Janela de contexto: A janela de 1M do Opus 4.7 é 5 vezes maior que a do GLM-5.1, oferecendo uma vantagem clara no processamento de grandes bases de código.
- Diferença de preço: O custo do GLM-5.1 é de apenas cerca de 14% do Opus 4.7.
- Vantagem do código aberto: O GLM-5.1 utiliza licença MIT, permitindo implantação privada e personalização livre.
A melhor estratégia não é escolher apenas um, mas combinar ambos os modelos — use o Opus 4.7 para tarefas de alto valor e o GLM-5.1 para tarefas frequentes em lote. A APIYI (apiyi.com) já disponibilizou ambos os modelos; os desenvolvedores podem realizar invocações de modelos de forma flexível através de uma interface unificada, alcançando o equilíbrio ideal entre eficiência de codificação e custo.
📚 Referências
-
VentureBeat – Relatório de lançamento do GLM-5.1 open source: Relatório detalhado sobre o GLM-5.1 liderando o SWE-Bench Pro.
- Link:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - Descrição: Relatório de lançamento de uma mídia de tecnologia autorizada, contendo dados de testes de benchmark.
- Link:
-
MarkTechPost – Análise técnica do GLM-5.1: Análise técnica do modelo de agente de 754B.
- Link:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - Descrição: Inclui detalhes da arquitetura e análise da capacidade de execução autônoma de 8 horas.
- Link:
-
Anthropic Oficial – Lançamento do Claude Opus 4.7: Notas completas de atualização.
- Link:
anthropic.com/news/claude-opus-4-7 - Descrição: Anúncio oficial e dados de benchmark do Opus 4.7.
- Link:
-
Página do modelo GLM-5.1 no HuggingFace: Download do modelo open source e documentação.
- Link:
huggingface.co/zai-org/GLM-5.1 - Descrição: Pesos do modelo sob licença MIT e guia de implantação.
- Link:
-
Documentação da API Claude – Visão geral do modelo: Especificações técnicas de todos os modelos Claude.
- Link:
platform.claude.com/docs/en/about-claude/models/overview - Descrição: Parâmetros oficiais do modelo, preços e comparação de funcionalidades.
- Link:
Autor: Equipe Técnica APIYI
Troca técnica: Sinta-se à vontade para discutir na seção de comentários. Para mais informações, acesse o centro de documentação da APIYI em docs.apiyi.com