
Author's Note: This article provides an in-depth comparison of the programming capabilities of Claude Opus 4.7 and GLM-5.1, covering benchmarks like SWE-Bench and CursorBench, long-cycle autonomous coding, and API pricing to help developers choose the best model for their coding needs.

In April 2026, the AI coding landscape saw a major showdown between two heavyweights. On April 7, Zhipu AI (Z.ai) released the open-source model GLM-5.1, which topped the global charts with a score of 58.4 on SWE-Bench Pro. Just nine days later, on April 16, Anthropic launched Claude Opus 4.7, which boosted its CursorBench score from 58% to 70% and tripled the task resolution rate on Rakuten-SWE-Bench compared to version 4.6.
These two models have different positioning, architectures, and price points—but they are competing head-to-head in the core arena of programming. APIYI (apiyi.com) has integrated both models, allowing developers to quickly compare them via a unified interface.
Core Value: After reading this article, you'll clearly understand the coding strengths of each model and which one you should choose for different scenarios.
Claude Opus 4.7 vs GLM-5.1 Core Parameter Comparison
| Comparison Dimension | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Release Date | 2026.04.16 | 2026.04.07 |
| Developer | Anthropic | Zhipu AI (Z.ai) |
| Architecture | Closed-source | 744B MoE (40B active parameters) |
| License | ❌ Closed-source | ✅ MIT License (Fully open) |
| Context Window | 1M tokens | 200K tokens |
| Max Output | 128K tokens | 131K tokens |
| API Input Price | $5 / MTok | $1 / MTok |
| API Output Price | $25 / MTok | $3.2 / MTok |
| Vision Capability | ✅ 2576px / 3.75MP | ✅ Supported |
| Thinking Mode | Adaptive Thinking | Multi-mode Thinking |
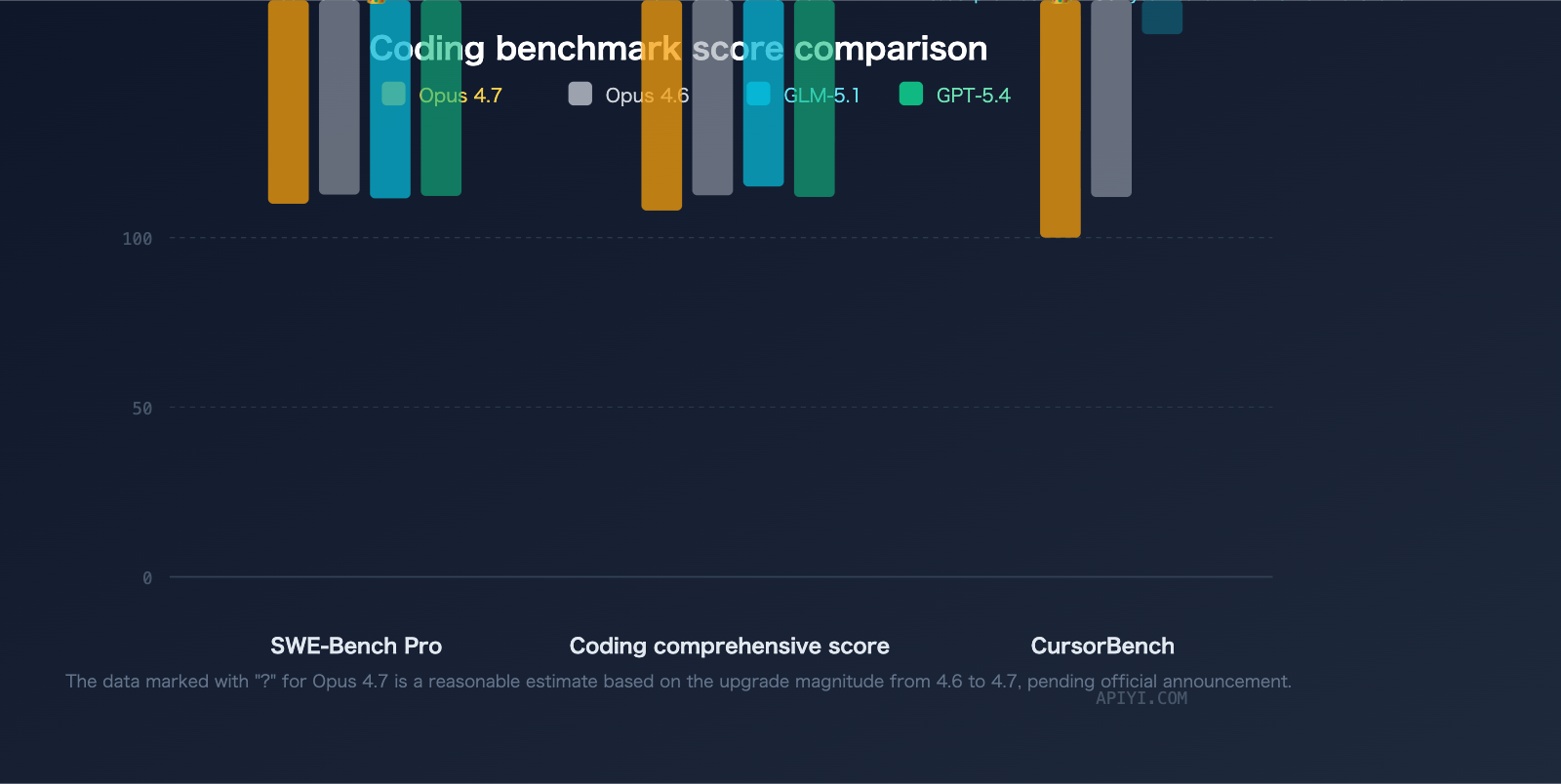
| SWE-Bench Pro | Expected > 57.3 (v4.6 score) | 58.4 (Current leader) |
| CursorBench | 70% | — |
| Training Hardware | US GPU Cluster | Huawei Ascend 910B |
🎯 Quick Conclusion: If you're looking for top-tier coding performance + massive context window + visual understanding, go with Opus 4.7. If you're looking for extreme cost-effectiveness + open-source control + powerful coding capabilities, choose GLM-5.1. Both models are available now on APIYI (apiyi.com).
Deep Dive into Programming Benchmarks
SWE-Bench Pro: GLM-5.1 Currently in the Lead
SWE-Bench Pro is one of the most authoritative real-world coding benchmarks, testing a model's ability to resolve actual GitHub issues.
| Model | SWE-Bench Pro | Rank |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | Expected > 57.3 | TBD |
GLM-5.1 has taken the top spot on SWE-Bench Pro with a score of 58.4, edging out GPT-5.4 (57.7) and Claude Opus 4.6 (57.3). It's worth noting that Opus 4.7 shows significant improvements in coding over 4.6 (CursorBench +12pp, Rakuten-SWE-Bench 3x), and its SWE-Bench Pro score is expected to see a substantial boost, though it hasn't been officially released as of this writing.
CursorBench: Opus 4.7 Takes a Commanding Lead
CursorBench evaluates a model's coding proficiency within a real IDE environment (the Cursor editor), making it much more representative of day-to-day development workflows.
| Model | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | No data |
Coding Composite Score
The Coding Composite score aggregates multiple dimensions, including SWE-Bench Pro, Terminal-Bench 2.0, and NL2Repo:
| Model | Coding Composite Score |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | Expected significantly higher than 4.6 |
In terms of the composite coding score, Claude Opus 4.6 leads with 57.5 compared to GLM-5.1's 54.9. Opus 4.7's composite coding capabilities are expected to widen this gap even further.
🎯 Takeaway: While GLM-5.1 is the current leader in the SWE-Bench Pro category, the Claude series maintains its edge in overall coding capabilities. Developers can use APIYI (apiyi.com) to access both models simultaneously and run A/B tests on their own real-world projects.
Deep Dive: Programming Capability Comparison
Benchmarks are just one piece of the puzzle. When you look at real-world programming scenarios, these two models show distinct strengths.
Long-Running Autonomous Coding
This is the killer feature of GLM-5.1.
| Long-Cycle Capability | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Max Autonomous Runtime | Depends on Task Budget | 8 hours non-stop |
| Autonomous Loop | Supports multi-step agents | Full "Plan→Execute→Test→Fix→Optimize" loop |
| Token Budget Management | Task Budgets (New feature) | Built-in long-task management |
| Self-Healing | Auto-fix during coding | Experiment→Analyze→Optimize autonomous loop |
GLM-5.1 can continuously execute coding tasks autonomously for up to 8 hours, creating a closed loop of "experimentation, analysis, and optimization." This is a massive advantage for large-scale refactoring or cross-module migrations.
While Opus 4.7 has improved its long-task capabilities through Task Budgets and xhigh inference tiers, it's more focused on "completing tasks efficiently within a budget" rather than "unlimited long-duration execution."
Agentic Tasks
| Agentic Capability | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Native MCP Support | ✅ Deeply optimized | ✅ Supported |
| Tool Use Efficiency | Fewer calls, more reasoning | Proactive tool usage |
| Multi-step Reliability | Very high | High |
| Context Management | 1M tokens ultra-long context | 200K tokens |
| Sub-agent Management | Fine-grained control (adjustable) | Supported |
For agentic tasks, the 1M token context window of Opus 4.7 is a game-changer. When handling massive codebases, Opus 4.7 can load more file context at once, significantly reducing information loss.
Code Review and Refactoring
| Code Review Capability | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Instruction Precision | Literal execution, highly precise | Flexible interpretation |
| Self-Verification | Verify before output (New) | Supported |
| Large File Handling | 1M context loads full codebase | 200K limit may require chunking |
| Visual Review | High-res screenshot understanding | Basic vision |
Rapid Coding and Daily Development
| Daily Coding | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Response Speed | Moderate | Faster |
| API Cost | $5/$25 per MTok | $1/$3.2 per MTok |
| Code Style | More concise, reasoning-heavy | Detailed comments, tool-heavy |
| Multi-language Support | Excellent | Excellent (Chinese comments feel more natural) |
Price Comparison: A 5x Cost Gap
Price is a factor you can't ignore when choosing a model. The pricing gap between the two is substantial:
| Billing Item | Claude Opus 4.7 | GLM-5.1 | Gap |
|---|---|---|---|
| Input Price | $5 / MTok | $1 / MTok | Opus is 5x more expensive |
| Output Price | $25 / MTok | $3.2 / MTok | Opus is 7.8x more expensive |
| Cache Price | Standard Cache discount | $0.26 / MTok | GLM caching is extremely cheap |
| Long Context Premium | None | None | — |
Real-World Cost Estimation
Assuming a mid-sized development team consumes 500M tokens per month (split evenly between input and output):
| Model Used | Monthly Input Cost | Monthly Output Cost | Monthly Total |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| Difference | — | — | $6,450/month |
GLM-5.1's cost is only about 14% of Opus 4.7's. For budget-sensitive teams, this is a decisive difference.
🎯 Cost Optimization Strategy: Through the APIYI (apiyi.com) platform, you can flexibly deploy both models—assign complex architectural design and code reviews to Opus 4.7, and handle high-volume daily code generation and batch processing tasks with GLM-5.1. The platform's unified interface makes implementing a multi-model strategy extremely cost-effective.

Recommendations for Different Scenarios
When to Choose Claude Opus 4.7
- Large Codebase Handling: When you need to load the context of dozens of files at once (1M vs 200K).
- Code Review & Security Auditing: When you need extremely high precision and self-verification capabilities.
- Multimodal Development: When you need to interpret UI screenshots, design drafts, or document images (3.75MP high-resolution vision).
- Enterprise-Grade Reliability: When you require stable, closed-source commercial support.
- Complex Reasoning-Intensive Coding: Scenarios requiring deep reasoning, such as mathematical calculations or algorithm design.
When to Choose GLM-5.1
- Long-Cycle Autonomous Development: When you need the model to work continuously for hours to complete large-scale refactoring.
- Cost-Sensitive Batch Tasks: CI/CD integration, batch code generation, and automated testing.
- Private Deployment: When you need to run the model on your own servers (MIT license, fully open).
- Chinese Development Environments: More natural and fluent generation of Chinese code comments and documentation.
- SWE-Bench Style Tasks: Real-world coding tasks like resolving GitHub issues or fixing bugs.
Best Practice: The Dual-Model Strategy
| Task Type | Recommended Model | Reason |
|---|---|---|
| Architecture Design & Technical Proposals | Opus 4.7 | Deep reasoning + ultra-long context |
| Daily Coding | GLM-5.1 | Low cost, sufficient quality |
| Code Review | Opus 4.7 | Precision + self-verification |
| Large-Scale Code Generation | GLM-5.1 | Only 14% of the cost |
| Bug Fixing (GitHub Issues) | GLM-5.1 | Top of the SWE-Bench Pro leaderboard |
| Multi-file Refactoring | Opus 4.7 | 1M context advantage |
| Long-term Autonomous Tasks | GLM-5.1 | 8-hour autonomous execution |
| UI/Screenshot-related Development | Opus 4.7 | 3.75MP high-resolution vision |
🎯 Unified Management Tip: APIYI (apiyi.com) has launched both Claude Opus 4.7 and GLM-5.1. Developers can use a single API key and a unified OpenAI-compatible interface to call both models, allowing you to switch flexibly based on the task type for the best balance of coding efficiency and cost.
FAQ
Q1: Is GLM-5.1 actually better than Claude Opus?
It depends on the metric. In the SWE-Bench Pro benchmark, GLM-5.1 (58.4) does outperform Opus 4.6 (57.3), but in overall coding scores, Opus 4.6 (57.5) leads GLM-5.1 (54.9). As a major upgrade to 4.6, Opus 4.7 is expected to widen the gap in comprehensive coding capabilities. Overall, Opus 4.7 is stronger, but GLM-5.1 has unique advantages in specific scenarios (long-cycle tasks, SWE-Bench style tasks).
Q2: GLM-5.1 is so much cheaper—is the quality good enough?
For most coding tasks, yes. GLM-5.1's performance on SWE-Bench Pro proves it has top-tier coding capabilities. Evaluation data shows it reaches 94.6% of Claude Opus 4.6's coding ability, but at only 1/5 to 1/8 of the price. The safest way to decide is to compare them directly via APIYI (apiyi.com).
Q3: Can both models be called through the same interface?
Yes. APIYI (apiyi.com) provides a unified OpenAI-compatible interface. You can switch between Claude Opus 4.7 and GLM-5.1 simply by changing the model ID, without needing to modify your code framework or manage multiple API keys.
Summary
The core takeaways from our programming comparison between Claude Opus 4.7 and GLM-5.1:
- SWE-Bench Pro Performance: GLM-5.1 is currently in the lead with a score of 58.4, though official scores for Opus 4.7 have yet to be released.
- Overall Coding Capability: The Opus series maintains an overall lead, with the 4.7 version showing impressive gains, including 70% on CursorBench and a 3x improvement on Rakuten-SWE-Bench.
- Long-Cycle Autonomous Coding: GLM-5.1’s ability to handle 8-hour autonomous execution is a unique selling point.
- Context Window: Opus 4.7’s 1M context window is 5x larger than that of GLM-5.1, providing a clear advantage when working with massive codebases.
- Price Gap: GLM-5.1 costs only about 14% of what you'd pay for Opus 4.7.
- Open Source Advantage: GLM-5.1 is released under the MIT license, making it perfect for private deployment and custom modifications.
The best strategy isn't choosing one over the other—it's using both models in tandem. Use Opus 4.7 for high-value tasks and GLM-5.1 for high-frequency, batch-oriented work. APIYI (apiyi.com) has launched both models, allowing developers to switch between them via a unified interface to strike the perfect balance between coding efficiency and cost.
📚 References
-
VentureBeat – GLM-5.1 Open Source Release Report: Detailed coverage of GLM-5.1 topping the SWE-Bench Pro leaderboard.
- Link:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - Note: Coverage from a leading tech outlet, including benchmark data.
- Link:
-
MarkTechPost – GLM-5.1 Technical Analysis: A deep dive into the 754B agent model.
- Link:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - Note: Includes architectural details and an analysis of its 8-hour autonomous execution capability.
- Link:
-
Anthropic Official – Claude Opus 4.7 Release: Full upgrade notes.
- Link:
anthropic.com/news/claude-opus-4-7 - Note: Official announcement and benchmark data for Opus 4.7.
- Link:
-
GLM-5.1 HuggingFace Model Page: Open source model downloads and documentation.
- Link:
huggingface.co/zai-org/GLM-5.1 - Note: Model weights and deployment guides under the MIT license.
- Link:
-
Claude API Documentation – Model Overview: Technical specifications for all Claude models.
- Link:
platform.claude.com/docs/en/about-claude/models/overview - Note: Official model parameters, pricing, and feature comparisons.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to join the discussion in the comments. For more resources, visit the APIYI documentation center at docs.apiyi.com.