
Lorsque Google DeepMind a lancé Nano Banana Pro le 20 novembre 2025, ils ont martelé un message clé : « untouched areas remain pixel-perfect — no generation drift, no quality loss across iterative edits » (les zones intactes restent parfaites au pixel près — aucune dérive de génération, aucune perte de qualité lors des modifications itératives). Si vous prenez cela au pied de la lettre, cela signifie que l'IA a enfin réussi la « modification locale façon Photoshop ». Pourtant, si vous connaissez l'architecture de Gemini 3 Pro Image, vous découvrirez qu'il s'agit fondamentalement d'un redessin complet de l'image par un Transformer autorégressif — le même mécanisme que celui utilisé par les modèles de langage pour prédire le prochain jeton (token).
Comment ces deux réalités peuvent-elles coexister ? Le principe de génération d'images de Nano Banana Pro consiste-t-il à redessiner toute l'image ou à effectuer une véritable modification locale ? Cet article décortique le sujet en quatre niveaux : le moteur d'inférence de Gemini 3, les jetons visuels autorégressifs, les contraintes strictes de masque et le positionnement sémantique par boîte englobante (Bounding Box), afin de fournir aux ingénieurs une compréhension technique concrète.
| Question clé | Réponse intuitive | Réalité |
|---|---|---|
| Est-ce une modification locale PS ? | Oui | Non, le fond reste un redessin complet par tokens |
| Pourquoi est-ce pixel-perfect ? | Le modèle est intelligent | Triple contrainte : Masque + Sémantique + BBox |
| Même origine que GPT-Image-2 ? | Similaire | Tous deux autorégressifs, mais Gemini 3 ajoute l'inférence explicite |
| Dérive-t-il après plusieurs tours ? | Oui | Presque jamais, c'est l'argument de vente de Pro |
En comprenant cette logique sous-jacente, vous serez capable de rédiger des invites (prompts) qui activent réellement l'inférence de Gemini 3, de choisir judicieusement les modes de masque et d'éviter le piège du « redessin déguisé en modification locale ». Nous recommandons aux lecteurs de tester en parallèle sur la plateforme APIYI (apiyi.com) avec l'interface Nano Banana Pro pour faire le lien entre la théorie et le résultat concret.
Principe de génération de Nano Banana Pro : redessin complet ou vraie modification locale ?
Avant de répondre, il faut distinguer deux choses souvent confondues : le mécanisme de génération et l'expérience utilisateur.
Du point de vue du mécanisme, Nano Banana Pro suit la même voie que ses prédécesseurs Nano Banana et GPT-Image-2 d'OpenAI : un redessin complet par tokens via un Transformer autorégressif. En d'autres termes, même si vous demandez à l'IA de changer uniquement la couleur d'une cravate, le modèle compresse l'image entière en jetons visuels, puis prédit à nouveau toute la séquence de jetons du début à la fin avant de décoder le tout en pixels. Il n'existe aucun chemin physique où seuls quelques pixels sont modifiés sans toucher au reste.
Cependant, du point de vue de l'expérience utilisateur, Nano Banana Pro offre une sensation de « quasi-modification locale ». Google affirme clairement que, dans les modes de masque ou de positionnement sémantique, les zones non éditées sont préservées au niveau du pixel, sans dérive de génération ni perte de qualité lors des modifications itératives. Comment cette expérience est-elle extraite d'une architecture de redessin complet ?
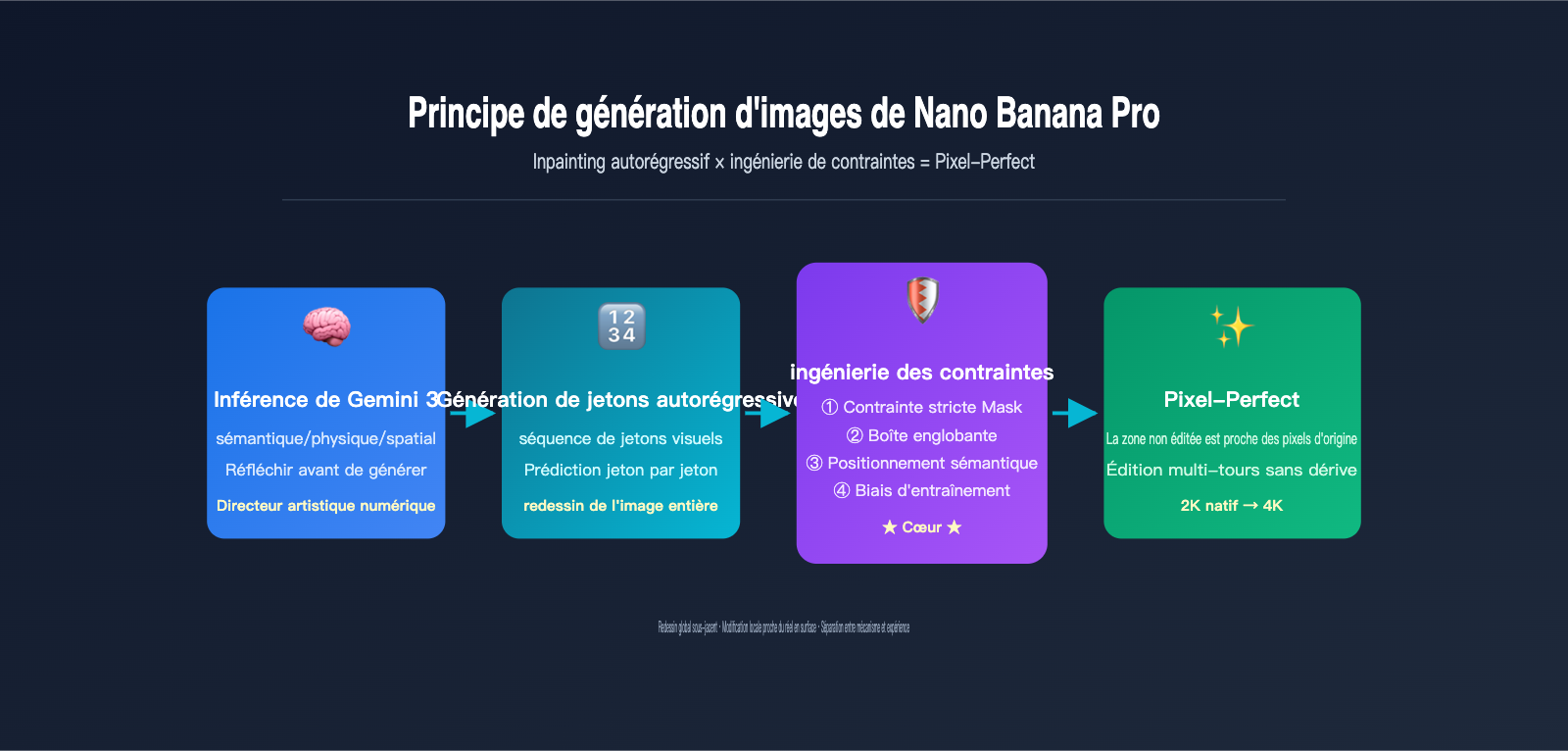
La réponse est : l'ingénierie de contraintes (constraint engineering). Google a superposé trois couches de contraintes strictes sur le flux de génération autorégressif : le verrouillage par jetons de masque, la spécification de zone par boîte englobante (Bounding Box) et la « liste de préservation » sémantique de Gemini 3. Ces trois couches forcent le modèle à « choisir activement » de reproduire les jetons des zones non éditées lors du redessin. C'est là que réside le véritable savoir-faire de l'équipe d'ingénierie de Nano Banana Pro.
Relation entre logique de redessin et expérience de modification locale
| Perspective | Réalité technique | Ressenti utilisateur |
|---|---|---|
| Architecture sous-jacente | Redessin complet par tokens | Ressemble à une modification locale |
| Zones non éditées | Jetons régénérés | Équivalent presque exact aux pixels originaux |
| Limites de modification | Génération autorégressive continue | Transition naturelle sans artefact |
| Instructions d'édition | Transmises via des contraintes | Adaptation automatique à la lumière/perspective |
En comprenant cette séparation entre « mécanisme » et « expérience », vous pourrez expliquer pourquoi, parfois, des zones non éditées présentent des changements infimes après une modification par Nano Banana Pro — c'est le prix inévitable du redessin par tokens, mais Google a réduit ce changement à un niveau quasi imperceptible. Nous vous conseillons d'utiliser l'interface Nano Banana Pro sur APIYI (apiyi.com) pour éditer plusieurs fois la même image et observer l'amplitude de la dérive ; cette comparaison rendra la compréhension du principe beaucoup plus concrète.
Principe de fonctionnement de Nano Banana Pro : l'épine dorsale autorégressive de Gemini 3 Pro Image
Pour bien comprendre le principe de fonctionnement de Nano Banana Pro, il est indispensable de se pencher sur son nom officiel : Gemini 3 Pro Image. Ce nom révèle ses deux lignées fondamentales : l'épine dorsale d'inférence Gemini 3 et le décodeur de génération d'images.
Gemini 3 est le grand modèle de langage multimodal phare lancé par Google seulement deux jours avant la sortie de Nano Banana Pro, et il est réputé pour ses capacités de "raisonnement". Nano Banana Pro réutilise directement l'épine dorsale Transformer de Gemini 3 Pro, en ajoutant simplement des jetons visuels au vocabulaire et en connectant un décodeur d'image en sortie. En d'autres termes, ce n'est pas un modèle d'image indépendant, mais une variante de la famille multimodale Gemini 3 spécialisée dans la génération d'images.
Cela entraîne un changement fondamental : avant même de dessiner le premier pixel, Nano Banana Pro utilise Gemini 3 pour déduire "ce qu'il doit dessiner". Comme le dit Google, il "fonctionne moins comme un modèle de diffusion traditionnel et davantage comme un directeur artistique numérique" : il analyse d'abord la logique sémantique, la causalité physique et les relations spatiales de l'invite, avant d'entamer la phase de génération des jetons visuels.
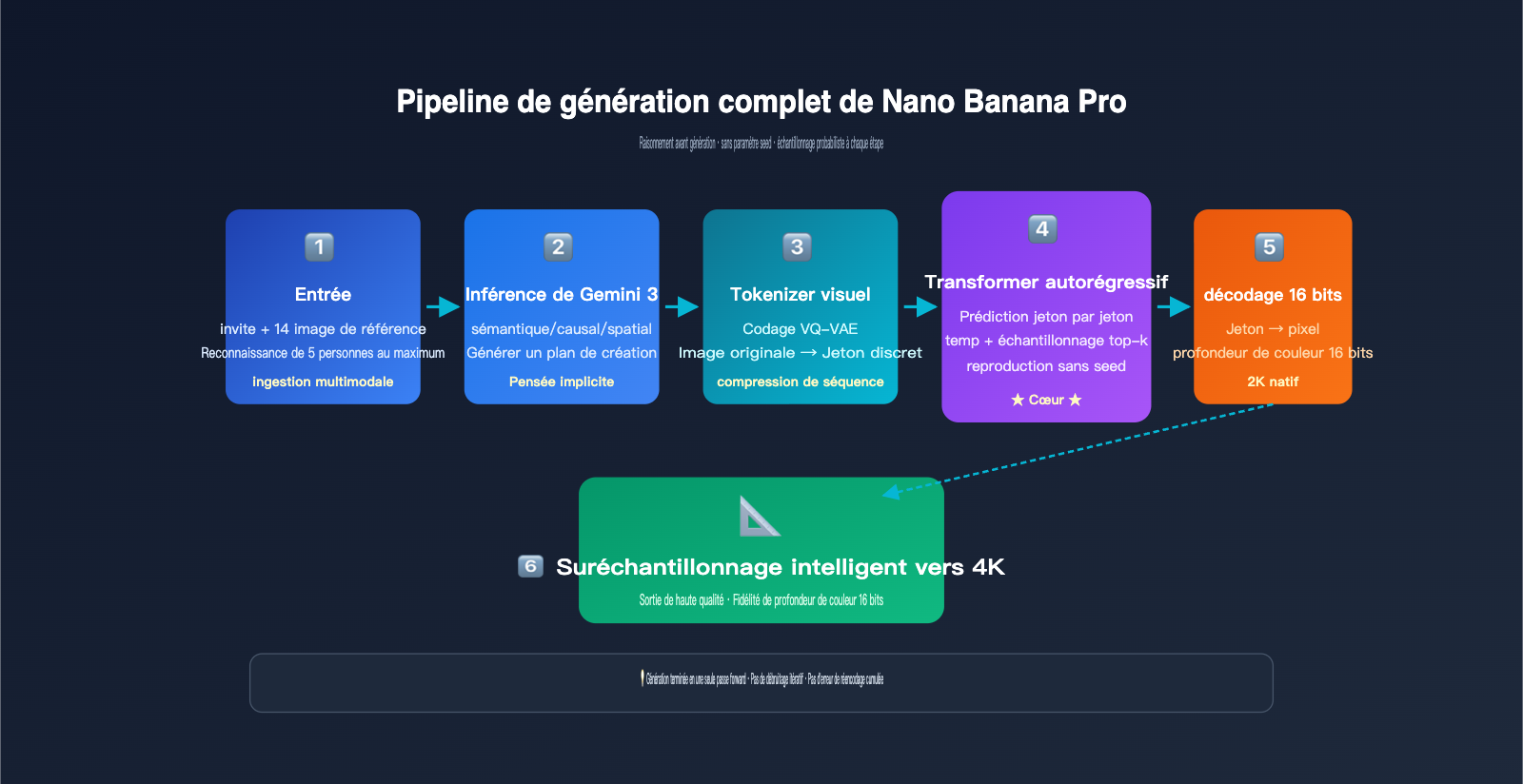
Le flux de travail peut être divisé en cinq étapes :
- Analyse de l'entrée multimodale : L'épine dorsale d'inférence Gemini 3 ingère simultanément l'invite textuelle de l'utilisateur et jusqu'à 14 images de référence pour comprendre le contexte global de la tâche.
- Raisonnement structuré (plan interne) : Le modèle "réfléchit" d'abord en interne à la disposition spatiale, à l'identité des personnages, à l'éclairage et aux éléments à conserver ou à modifier, générant un "plan de création" invisible.
- Encodage des jetons visuels de l'image source : Les images de référence sont compressées en une séquence de jetons visuels via un mécanisme de discrétisation similaire au VQ-VAE.
- Prédiction autorégressive des jetons : Grâce au mécanisme d'attention de l'épine dorsale Gemini 3, le modèle prédit un par un, de gauche à droite, chaque jeton visuel de l'image de sortie, en "voyant" à chaque étape l'intégralité des jetons de l'invite et de l'image source.
- Décodage et suréchantillonnage : Les jetons de sortie sont restaurés en une image native 2K via un décodeur 16 bits, puis intelligemment suréchantillonnés en 4K.
Les deux capacités uniques de l'épine dorsale d'inférence Gemini 3
La première est "réfléchir avant de dessiner". Ce n'est pas qu'un argument marketing : la capacité de raisonnement de Gemini 3 sur les tâches textuelles est directement transférée à la génération d'images. Si vous lui donnez une instruction complexe comme "change les vêtements de cette personne pour qu'ils correspondent à sa profession", un modèle d'image classique serait perdu, tandis que Nano Banana Pro déduira d'abord : "cette personne ressemble à un médecin → il devrait porter une blouse blanche", avant de commencer à dessiner.
La seconde est le Grounding avec Google Search. Nano Banana Pro peut appeler les outils de recherche Google pendant le processus de génération pour vérifier des faits. Par exemple, si vous lui demandez de dessiner "le dernier produit lancé par telle marque", il peut se connecter au web pour obtenir une référence visuelle réelle. Il s'agit du seul modèle de génération d'images prenant en charge le grounding par recherche native, ce qui constitue l'une des différences majeures entre Nano Banana Pro et GPT-Image-2. Si vous avez besoin de tester les capacités de Grounding dans un environnement de production, vous pouvez accéder à Nano Banana Pro via APIYI (apiyi.com), qui propose des spécifications d'interface identiques à celles de Google.
Il est important de noter que Nano Banana Pro ne prend pas en charge le paramètre seed. Comme il s'agit d'une génération autorégressive, chaque échantillonnage est tiré d'une distribution de probabilité (contrôlée par la température et le top-k), contrairement aux modèles de diffusion qui permettent de reproduire exactement les résultats en fixant le bruit initial. Cette caractéristique est à la fois une contrainte et un choix de conception, permettant au modèle de conserver sa créativité.
Les 4 mécanismes de contrainte pour l'édition locale d'images par IA : comment atteindre le "Pixel-Perfect"
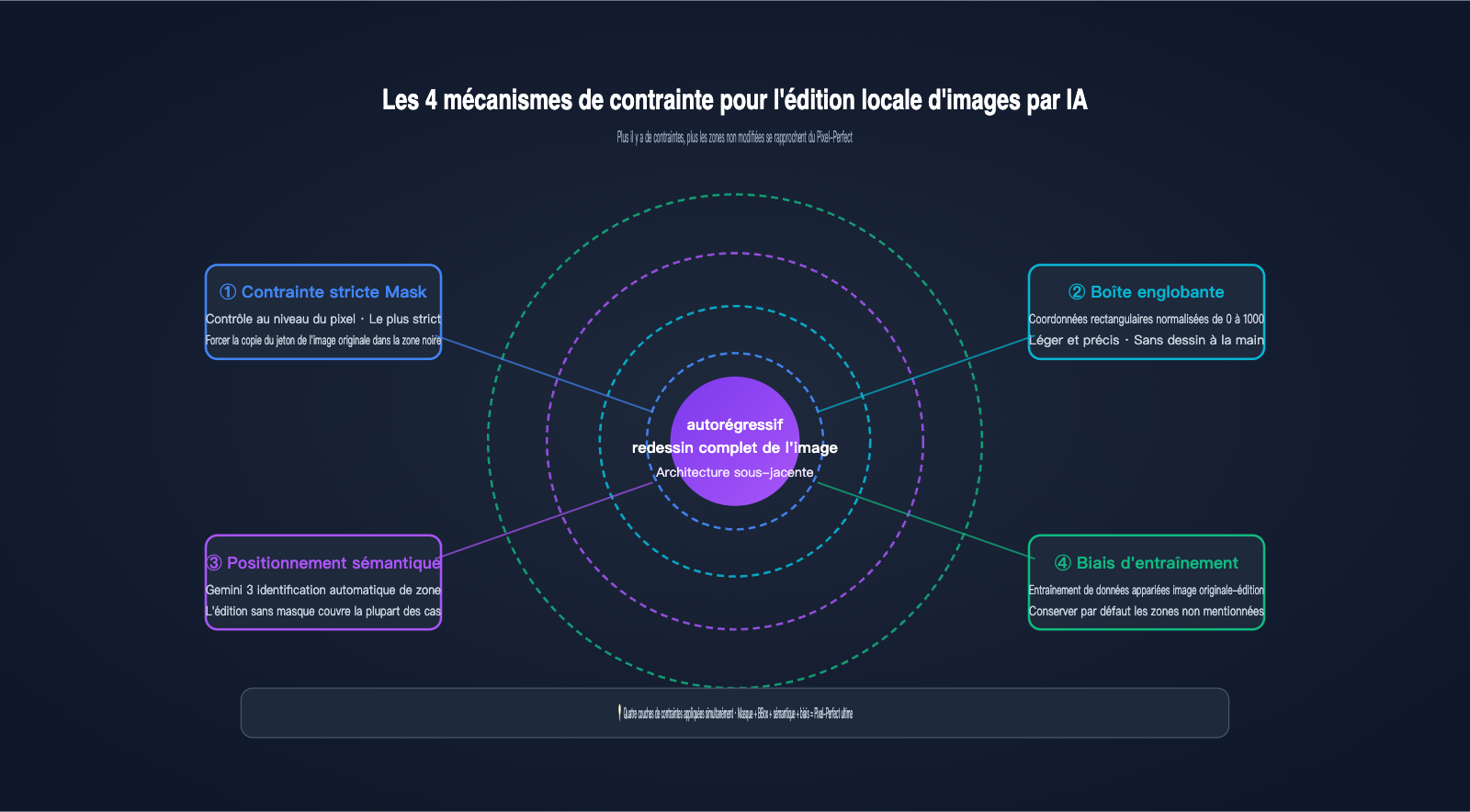
Puisque le processus sous-jacent repose sur un redessin complet de l'image, comment Nano Banana Pro parvient-il à garantir que les zones non modifiées restent "pixel-perfect" ? La réponse réside dans quatre couches de mécanismes de contrainte superposées par Google pour l'édition locale d'images par IA. C'est l'innovation technique la plus remarquable de la version Pro par rapport à la version Nano Banana standard.
Première couche : Contrainte matérielle par masque (Mask). C'est la méthode la plus directe : l'utilisateur fournit un masque noir et blanc de même dimension. Les zones blanches autorisent l'IA à générer de nouveaux jetons (tokens), tandis que les zones noires imposent au modèle de copier les jetons correspondants de l'image originale. Cela équivaut à ajouter une "règle de copie stricte" lors de la génération autorégressive. C'est la source technologique fondamentale de ce que Google appelle les "zones intactes pixel-perfect".
Deuxième couche : Positionnement par zone (Bounding Box). Nano Banana Pro prend en charge des paramètres de boîte englobante (bounding box) avec des coordonnées normalisées de 0 à 1000. Vous pouvez indiquer au modèle de "modifier uniquement dans ce rectangle de (200, 300) à (600, 500)". Le système convertit automatiquement la BBox en une contrainte de masque interne, ce qui est bien plus pratique que le dessin manuel.
Troisième couche : Positionnement sémantique par Gemini 3. C'est la couche la plus "magique". Il suffit d'utiliser un langage naturel comme "remplace l'arrière-plan par une plage", et le moteur de raisonnement de Gemini 3 identifie automatiquement quels jetons correspondent à "l'arrière-plan" pour générer un masque implicite. Ce mode d'édition sans masque couvre la "majorité des scénarios d'édition" mentionnés par Google.
Quatrième couche : Biais d'entraînement "non mentionné, donc conservé". Google a utilisé une quantité massive de données appariées "image originale – image éditée", permettant au modèle d'apprendre une règle implicite lors de l'entraînement : sauf si l'invite demande explicitement une modification, les autres zones doivent être copiées jeton par jeton depuis l'original. Ce biais est ancré dans les poids du modèle et s'applique automatiquement lors de l'inférence.
Comparaison des 4 mécanismes de contrainte
| Mécanisme de contrainte | Granularité du contrôle | Coût utilisateur | Scénarios d'application |
|---|---|---|---|
| Contrainte matérielle (Mask) | Niveau pixel | Dessin du masque requis | Restauration précise / détourage |
| Bounding Box | Zone rectangulaire | Coordonnées uniquement | Édition de zones rectangulaires connues |
| Positionnement sémantique | Objet sémantique | Instructions textuelles | La plupart des éditions courantes |
| Biais d'entraînement | Global | Aucune configuration | Activé par défaut pour tous les cas |
Ces quatre couches ne sont pas mutuellement exclusives, elles se superposent. La combinaison la plus stricte est "Masque + Bounding Box + Instruction sémantique", ce qui pousse l'expérience pixel-perfect de Nano Banana Pro à son paroxysme. Nos tests sur APIYI (apiyi.com) montrent que même avec la simple combinaison positionnement sémantique + biais d'entraînement, on obtient une cohérence visuelle quasi indiscernable pour la plupart des tâches quotidiennes.
Raisons techniques de l'absence de dérive lors d'éditions multiples
L'un des arguments marketing de Nano Banana Pro est "l'absence de perte de qualité cumulative lors d'éditions multiples". Il y a deux raisons à cela. Premièrement, l'architecture autorégressive ne nécessite pas de codage/décodage VAE répété comme les modèles de diffusion ; il n'y a qu'une seule conversion jeton-pixel, ce qui évite l'accumulation d'erreurs de réencodage. Deuxièmement, la contrainte matérielle du masque force la copie des jetons originaux pour les zones non modifiées, ce qui n'introduit quasiment aucune nouvelle stochasticité, même après plusieurs itérations.
Cela contraste fortement avec les modèles Stable Diffusion traditionnels, dont les inpaintings répétés finissent par rendre l'image "floue". Si votre flux de travail nécessite 5 à 10 itérations d'édition sur une même image de base, Nano Banana Pro est pratiquement le seul modèle capable de tenir la distance.
Gemini 3 Pro Image vs GPT-Image-2 : Différences stratégiques
De nombreuses équipes s'intéressent simultanément à Gemini 3 Pro Image (Nano Banana Pro) et au GPT-Image-2 d'OpenAI. Bien que les deux reposent sur une architecture autorégressive, leur positionnement et leurs capacités diffèrent.
GPT-Image-2 met l'accent sur le « mode réflexion » (Thinking mode) et la précision du rendu textuel (environ 99 % selon les données officielles), ce qui le rend excellent pour les mises en page multi-objets et les scènes avec beaucoup de texte. Nano Banana Pro, quant à lui, mise sur l'épine dorsale de raisonnement de Gemini 3, la sortie 4K, la fusion de 14 images, la conservation de l'identité de 5 personnes, ainsi que sa fonctionnalité exclusive de Grounding avec la recherche Google.

Les différences clés entre les principes de génération d'images de Nano Banana Pro et le chemin d'implémentation de GPT-Image-2 sont résumées dans ce tableau :
| Dimension | Nano Banana Pro | GPT-Image-2 |
|---|---|---|
| Modèle sous-jacent | Gemini 3 Pro | GPT-4o multimodal |
| Amélioration du raisonnement | Raisonnement implicite Gemini 3 | Mode réflexion explicite |
| Résolution max | 4K (upscaling depuis 2K) | 4K natif |
| Limite d'entrée multi-images | 14 images | Plusieurs (limite non publique) |
| Cohérence faciale | Jusqu'à 5 personnes | Forte, limite non publique |
| Rendu textuel | Leader du secteur, multilingue | 99 % de précision |
| Informations en temps réel | ✅ Grounding avec Google Search | ❌ |
| Paramètre Seed | ❌ Non supporté | Partiellement contrôlé |
| Édition locale | Pixel-perfect (zones non éditées) | Multi-tours sans dérive |
| Prix par image | 2K 0,139 $ / 4K 0,24 $ | Haute qualité 1024 0,211 $ |
Conseils de sélection : Tout dépend de vos besoins. Si vous travaillez sur des supports de marque, des photos de produits ou des compositions multi-personnages, la fusion d'images et la cohérence faciale de Nano Banana Pro seront plus adaptées. Si votre scénario principal concerne des affiches avec de longs textes, des mises en page complexes ou plus de 100 objets, le mode réflexion de GPT-Image-2 sera probablement plus stable. Nous vous recommandons d'accéder aux deux modèles via la plateforme APIYI (apiyi.com) pour effectuer des tests A/B à petite échelle sur vos cas d'usage réels avant de choisir votre modèle principal.
Pratique de l'API Nano Banana Pro : du masque à la bounding box
Maintenant que vous comprenez les principes, voyons comment exploiter la capacité d'édition locale d'images par IA de Nano Banana Pro. Voici un exemple Python minimal pour appeler Gemini 3 Pro Image via les points de terminaison compatibles APIYI :
from google import genai
from PIL import Image
client = genai.Client(
api_key="votre-clé-apiyi",
http_options={"base_url": "https://vip.apiyi.com/v1"}
)
original = Image.open("portrait.png")
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Conserve l'identité du personnage et l'arrière-plan, change uniquement le t-shirt blanc par une veste de costume bleu marine, en conservant la direction de la lumière et des ombres d'origine.",
original
]
)
for part in response.candidates[0].content.parts:
if part.inline_data:
with open("edited.png", "wb") as f:
f.write(part.inline_data.data)
Notez la rédaction de l'invite (prompt) : déclarez explicitement ce qui doit rester inchangé, ce qui doit être modifié et demandez de conserver l'éclairage d'origine. Cela active directement la capacité de localisation sémantique de l'épine dorsale de raisonnement de Gemini 3. Si vous avez besoin d'un contrôle de zone plus précis, vous pouvez ajouter une bounding box :
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Dans la bounding box [200, 150, 600, 700] de l'image, remplace le vêtement par une veste de costume bleu marine. Les autres zones doivent rester inchangées au niveau des pixels.",
original
]
)
Les coordonnées utilisent une plage normalisée de 0 à 1000, mappée selon les dimensions de l'image. Pour un contrôle plus strict, vous pouvez ajouter une image de masque en entrée.
5 conseils pour optimiser vos résultats
Pour une mise en œuvre efficace de Nano Banana Pro en ingénierie, voici 5 recommandations :
- Listez toujours ce qui doit être conservé dans l'invite : « Conserver l'identité, l'arrière-plan et l'éclairage » est la clé pour activer les contraintes de haut niveau.
- Privilégiez la localisation sémantique : À moins qu'une précision au pixel près ne soit requise, le mode sans masque (mask-free) est plus efficace.
- Ne dépassez pas 14 images pour la fusion : Au-delà de la limite officielle, les données seront tronquées, ce qui nuira à la cohérence.
- Choisissez entre 2K et 4K selon l'usage : Le 2K (0,139 $) suffit pour le web/mobile ; réservez le 4K (0,24 $) pour l'impression ou les grands écrans.
- N'essayez pas d'utiliser un seed pour la reproduction : Nano Banana Pro ne supporte pas les seeds. Pour une reproduction stable, utilisez plutôt la pondération des invites et une image de référence fixe.
Tarification et scénarios
| Configuration | Coût par image | Scénario recommandé |
|---|---|---|
| Image 2K | 0,139 $ | Réseaux sociaux / Illustrations web |
| Image 4K | 0,24 $ | Impression / Grands écrans / Visuels marketing |
| 4K + fusion 14 images | 0,24 $ + jetons d'entrée | Composition de scènes multi-personnages |
| 4K + Grounding | 0,24 $ + jetons de recherche | Illustration de produits réels / événements |
Pour les environnements de production, nous vous conseillons d'utiliser l'API Batch d'APIYI (apiyi.com) pour traiter vos tâches en masse. Cela permet de réduire considérablement les coûts tout en maintenant la qualité, ce qui est idéal pour la création de bibliothèques de ressources.
FAQ et conseils de décision sur le principe de génération d'images de Nano Banana Pro
Q1 : Nano Banana Pro effectue-t-il un dessin complet ou une modification locale ?
R : Le mécanisme sous-jacent est le « redessinage de jetons (tokens) d'image entière par autorégression », c'est-à-dire du « dessin ». Cependant, grâce à quatre niveaux de contraintes — masquage strict (Mask), boîte englobante (Bounding Box), positionnement sémantique via Gemini 3 et biais d'entraînement — il offre une expérience utilisateur proche d'une « véritable modification locale ». Les deux aspects ne sont pas contradictoires : l'architecture repose sur le redessinage, tandis que l'ingénierie assure le verrouillage.
Q2 : Pourquoi est-il indiqué que les zones non éditées sont « pixel-perfect » ?
R : En mode masque, les jetons de sortie dans les zones noires sont forcés d'être identiques aux jetons de l'image originale à la même position, ce qui rend les pixels quasi identiques après décodage. Techniquement, il existe une perte infime due au codage/décodage VQ-VAE, donc c'est une perfection « proche » du pixel, et non une identité mathématique absolue. À l'œil nu, la différence est imperceptible lors d'une utilisation quotidienne.
Q3 : Pourquoi Nano Banana Pro ne prend-il pas en charge les graines (seed) ?
R : La génération autorégressive échantillonne à chaque étape à partir d'une distribution de probabilité, ce qui diffère totalement du mécanisme des modèles de diffusion qui fixent le bruit initial. Google a choisi de ne pas exposer le paramètre de graine pour préserver la diversité créative du modèle. Si vous avez besoin de résultats reproductibles, utilisez une combinaison d'invites détaillées et d'une image de référence. Nous vous conseillons de tester la stabilité de différents modèles d'invites sur APIYI (apiyi.com) afin de trouver la combinaison « quasi déterministe » adaptée à votre flux de travail.
Q4 : Comment choisir entre Nano Banana Pro et GPT-Image-2 ?
R : Pour des scénarios multi-personnages, des supports de marque ou lorsque des informations en temps réel (Grounding) sont nécessaires → choisissez Nano Banana Pro. Pour des mises en page complexes, des affiches avec beaucoup de texte ou des compositions comportant plus de 100 objets → choisissez GPT-Image-2. Les deux reposent sur l'autorégression, mais les différences d'expérience proviennent des choix d'ingénierie des contraintes respectifs de Google et d'OpenAI.
Q5 : Puis-je localiser précisément la zone d'édition sans utiliser de masque ?
R : Oui, de deux manières. Premièrement, en utilisant le paramètre Bounding Box (coordonnées normalisées de 0 à 1000) ; deuxièmement, en s'appuyant sur le positionnement sémantique du moteur d'inférence Gemini 3, en précisant simplement dans l'invite : « Modifie l'objet rouge en bas à droite de l'image ». Cette dernière méthode couvre la plupart des cas, tandis que la première est réservée aux zones rectangulaires précises.
Q6 : Comment utiliser concrètement le « Grounding with Google Search » ?
R : Précisez dans votre invite les éléments nécessitant une vérification factuelle, par exemple : « Génère une image du dernier Cybertruck 2025 de Tesla sur la surface de la Lune ». Le modèle appellera automatiquement la recherche Google pour obtenir une référence visuelle réelle avant de passer à la phase de génération. Il s'agit d'une capacité exclusive à Nano Banana Pro, non disponible actuellement sur GPT-Image-2.
Conclusion : Maîtriser l'ingénierie des contraintes pour bien utiliser Nano Banana Pro
Nano Banana Pro est un produit d'une grande finesse technique. Il n'invente pas un nouveau paradigme de génération d'images, mais s'appuie sur le moteur autorégressif de Gemini 3 pour transformer une architecture de « redessinage d'image entière » en une expérience de « modification locale quasi réelle » grâce à quatre niveaux de contraintes : masquage strict, boîte englobante, positionnement sémantique et biais d'entraînement.
Comprendre cette distinction entre « mécanisme et expérience » est essentiel pour rédiger des invites capables d'activer ces quatre niveaux de contraintes, choisir le mode d'édition approprié et planifier des flux de travail itératifs. Le cœur du principe de génération d'images de Nano Banana Pro ne réside pas dans une technologie miracle, mais dans la synergie globale de l'ingénierie des contraintes.
Nous vous recommandons d'effectuer vos tests et comparaisons via la plateforme APIYI (apiyi.com). Celle-ci propose une interface unifiée pour invoquer divers modèles majeurs tels que Nano Banana Pro, GPT-Image-2 et Stable Diffusion, facilitant ainsi la vérification rapide des principes et astuces d'optimisation évoqués ici pour trouver la solution optimale à vos besoins de production.
Cet article a été rédigé par l'équipe APIYI, sur la base de documents officiels de Google DeepMind, Vertex AI et de tests sur le terrain. Pour toute invocation de Gemini 3 Pro Image (Nano Banana Pro) en environnement de production, veuillez consulter le site officiel d'APIYI : apiyi.com pour accéder à la documentation.