
작성자 주: 프로그래밍 분야에서 Claude Opus 4.7과 GLM-5.1의 성능 차이를 심층 분석합니다. SWE-Bench, CursorBench 등 벤치마크 결과부터 장기 자율 코딩, API 가격까지 다루며, 개발자가 최적의 코딩 모델을 선택할 수 있도록 돕습니다.

2026년 4월, AI 코딩 분야에서 두 거물급 모델이 정면으로 맞붙었습니다. 4월 7일, 즈푸 AI(Z.ai)가 오픈소스 모델인 GLM-5.1을 출시하며 SWE-Bench Pro에서 58.4점을 기록해 세계 1위에 올랐습니다. 그로부터 불과 9일 뒤인 4월 16일, Anthropic은 Claude Opus 4.7을 발표했는데, CursorBench 점수가 58%에서 70%로 급상승했고 Rakuten-SWE-Bench 작업 처리량은 4.6 버전 대비 3배나 증가했습니다.
두 모델은 포지셔닝과 아키텍처, 가격 면에서 큰 차이를 보이지만, 코딩이라는 핵심 전장에서 치열하게 경쟁하고 있습니다. APIYI(apiyi.com)는 이미 두 모델을 모두 지원하고 있어, 개발자들은 통합 인터페이스를 통해 빠르게 성능을 비교해 볼 수 있습니다.
핵심 가치: 이 글을 읽고 나면 두 모델의 코딩 강점과 상황별 선택 기준을 명확히 이해하게 될 것입니다.
Claude Opus 4.7 vs GLM-5.1 핵심 사양 비교
| 비교 항목 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 출시일 | 2026.04.16 | 2026.04.07 |
| 개발사 | Anthropic | 즈푸 AI(Z.ai) |
| 모델 아키텍처 | 비공개 | 744B MoE (40B 활성 파라미터) |
| 오픈소스 라이선스 | ❌ 비공개 | ✅ MIT 라이선스 (완전 공개) |
| 컨텍스트 윈도우 | 1M tokens | 200K tokens |
| 최대 출력 | 128K tokens | 131K tokens |
| API 입력 가격 | $5 / MTok | $1 / MTok |
| API 출력 가격 | $25 / MTok | $3.2 / MTok |
| 시각적 능력 | ✅ 2576px / 3.75MP | ✅ 지원 |
| 사고 모드 | Adaptive Thinking | 다중 모드 Thinking |
| SWE-Bench Pro | 예상 > 57.3 (4.6 버전 점수) | 58.4 (현재 1위) |
| CursorBench | 70% | — |
| 학습 하드웨어 | 미국 GPU 클러스터 | 화웨이 Ascend 910B |
🎯 빠른 결론: 최고 수준의 코딩 능력 + 초장기 컨텍스트 + 시각적 이해력이 필요하다면 Opus 4.7을 추천합니다. 극강의 가성비 + 오픈소스 제어권 + 강력한 코딩 성능을 원하신다면 GLM-5.1이 정답입니다. 두 모델 모두 APIYI(apiyi.com)에서 바로 사용하실 수 있습니다.
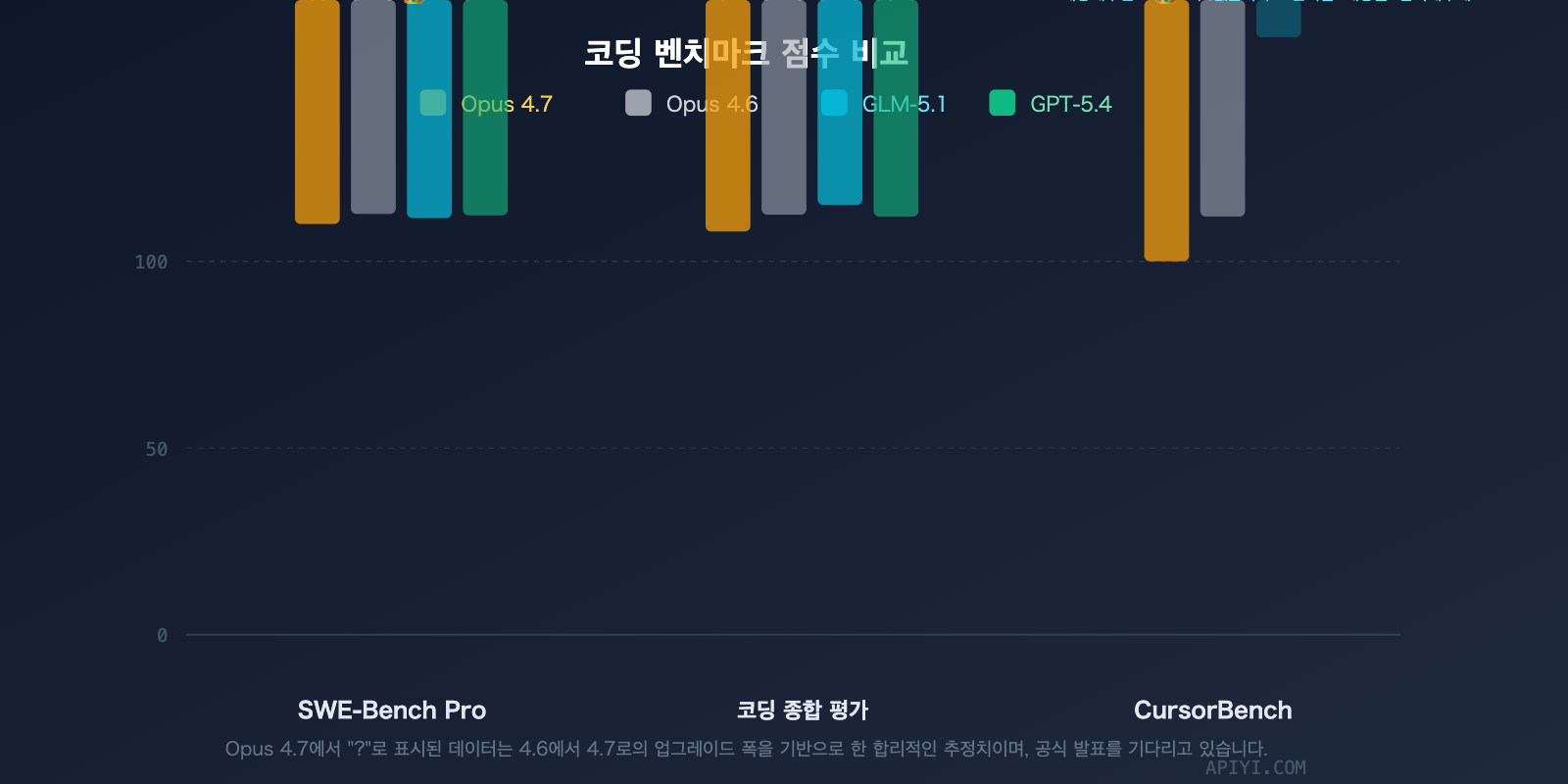
프로그래밍 벤치마크 심층 비교
SWE-Bench Pro: GLM-5.1의 현재 선두
SWE-Bench Pro는 GitHub의 실제 이슈를 해결하는 모델의 능력을 평가하는 가장 권위 있는 실제 코딩 벤치마크 중 하나입니다.
| 모델 | SWE-Bench Pro | 순위 |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | 예상 > 57.3 | 업데이트 예정 |
GLM-5.1은 58.4점으로 SWE-Bench Pro 정상에 오르며 GPT-5.4(57.7)와 Claude Opus 4.6(57.3)을 제쳤습니다. 주목할 점은 Opus 4.7이 4.6 버전에 비해 코딩 분야에서 비약적인 성능 향상(CursorBench +12pp, Rakuten-SWE-Bench 3배)을 보였다는 것입니다. SWE-Bench Pro 점수 또한 실질적으로 상승할 것으로 예상되지만, 아직 공식 발표 전입니다.
CursorBench: Opus 4.7의 압도적 우위
CursorBench는 실제 IDE 환경(Cursor 에디터)에서의 코드 작성 능력을 테스트하며, 일상적인 개발 시나리오에 더욱 가깝습니다.
| 모델 | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | 데이터 없음 |
코딩 종합 점수 (Coding Composite)
코딩 종합 점수는 SWE-Bench Pro, Terminal-Bench 2.0, NL2Repo 등 여러 차원을 종합한 결과입니다.
| 모델 | 코딩 종합 점수 |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | 4.6 대비 대폭 상승 예상 |
종합 코딩 점수에서는 Claude Opus 4.6이 57.5점으로 GLM-5.1(54.9점)을 앞서고 있습니다. Opus 4.7은 종합 코딩 능력에서 격차를 더욱 벌릴 것으로 예상됩니다.
🎯 해설: GLM-5.1은 SWE-Bench Pro 단일 항목에서 최강의 성능을 보여주었지만, 종합적인 코딩 능력 면에서는 여전히 Claude 시리즈가 우위를 점하고 있습니다. 개발자분들은 APIYI(apiyi.com)를 통해 두 모델을 모두 연동하여 실제 프로젝트에서 A/B 테스트를 진행해 보실 수 있습니다.
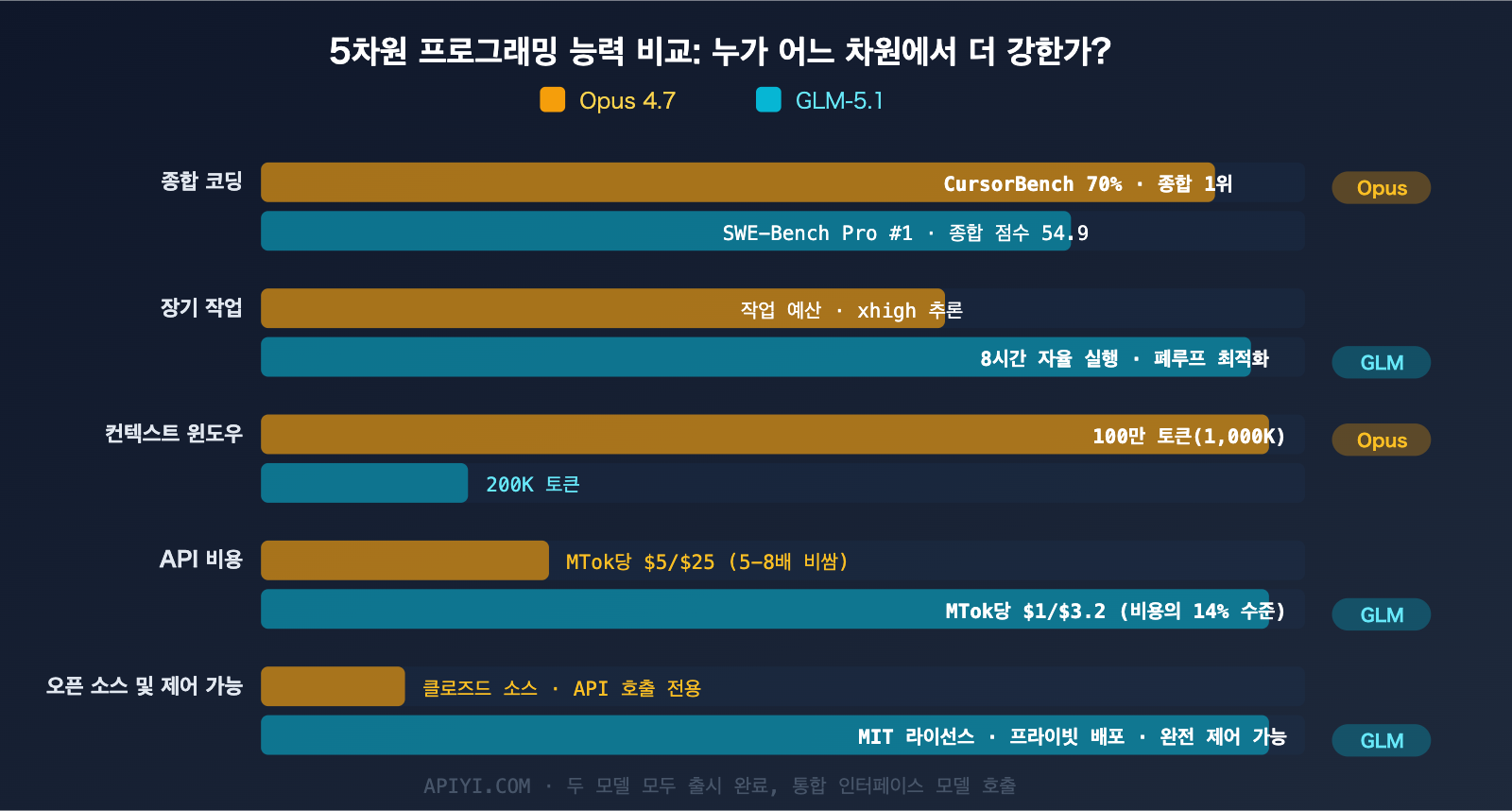
프로그래밍 시나리오별 성능 심층 비교
벤치마크 점수는 하나의 지표일 뿐입니다. 실제 프로그래밍 시나리오에서 두 모델은 확연히 다른 강점을 보여줍니다.
장기 연속 코딩
이것은 GLM-5.1의 킬러 기능입니다.
| 장기 작업 능력 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 최대 자율 실행 시간 | 작업 예산(Task Budget)에 따름 | 8시간 중단 없음 |
| 자율 루프 | 다단계 에이전트 지원 | 완벽한 「계획→실행→테스트→수정→최적화」 폐루프 |
| 토큰 예산 관리 | Task Budgets(신기능) | 내장형 장기 작업 관리 |
| 자기 수정 | 코딩 중 자동 수정 | 실험→분석→최적화 자율 루프 |
GLM-5.1은 최대 8시간 동안 지속적으로 코딩 작업을 자율 수행하며 「실험→분석→최적화」의 폐루프를 형성합니다. 대규모 리팩토링이나 모듈 간 마이그레이션 같은 작업에서 압도적인 강점을 보이죠.
반면 Opus 4.7은 Task Budgets와 xhigh 추론 레벨을 통해 장기 작업 능력을 강화했지만, '무한 실행'보다는 '예산 내 효율적 완료'에 더 무게를 두고 있습니다.
에이전트 작업(Agentic Tasks)
| 에이전트 능력 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| MCP 네이티브 지원 | ✅ 심층 최적화 | ✅ 지원 |
| 도구 호출 효율 | 적은 호출, 더 많은 추론 | 적극적인 도구 활용 |
| 다단계 신뢰성 | 매우 높음 | 높음 |
| 컨텍스트 관리 | 1M 토큰 초장기 컨텍스트 | 200K 토큰 |
| 하위 에이전트 관리 | 세밀한 제어(조절 가능) | 지원 |
에이전트 작업 면에서 Opus 4.7의 1M 토큰 컨텍스트 윈도우는 압도적인 이점입니다. 대규모 코드베이스를 다룰 때 Opus 4.7은 더 많은 파일 컨텍스트를 한 번에 불러올 수 있어 정보 손실이 적습니다.
코드 리뷰 및 리팩토링
| 코드 리뷰 능력 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 지시 정확도 | 문자 그대로 실행, 정밀함 | 유연한 해석 |
| 자체 검증 능력 | 출력 전 검증(신규 추가) | 지원 |
| 대용량 파일 처리 | 1M 컨텍스트로 전체 코드베이스 로드 | 200K 제한으로 분할 필요 가능성 |
| 시각적 리뷰 | 고해상도 스크린샷 이해 | 기본 시각 기능 |
빠른 코딩 및 일상 개발
| 일상 코딩 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 응답 속도 | 중간 | 빠름 |
| API 비용 | $5/$25 per MTok | $1/$3.2 per MTok |
| 코드 스타일 | 더 정제됨, 추론 선호 | 상세 주석, 도구 호출 선호 |
| 다국어 지원 | 우수 | 우수(중문 코드 주석이 더 자연스러움) |
가격 비교: 5배의 비용 차이
모델 선택 시 가격은 결코 무시할 수 없는 요소입니다. 두 모델의 가격 차이는 상당히 큽니다.
| 과금 항목 | Claude Opus 4.7 | GLM-5.1 | 차이 |
|---|---|---|---|
| 입력 가격 | $5 / MTok | $1 / MTok | Opus가 5배 비쌈 |
| 출력 가격 | $25 / MTok | $3.2 / MTok | Opus가 7.8배 비쌈 |
| 캐시 가격 | 표준 캐시 할인 | $0.26 / MTok | GLM 캐시가 매우 저렴 |
| 장기 컨텍스트 추가 비용 | 없음 | 없음 | — |
실제 시나리오 비용 추정
중형 개발 팀이 매달 500M 토큰(입력+출력 각 절반)을 소비한다고 가정해 봅시다:
| 사용 모델 | 월 평균 입력 비용 | 월 평균 출력 비용 | 월간 합계 |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| 차액 | — | — | $6,450/월 |
GLM-5.1의 비용은 Opus 4.7의 약 14% 수준입니다. 예산이 민감한 팀에게는 결정적인 차이입니다.
🎯 비용 최적화 전략: APIYI(apiyi.com) 플랫폼을 사용하면 두 모델을 유연하게 배분할 수 있습니다. 복잡한 아키텍처 설계와 코드 리뷰는 Opus 4.7에 맡기고, 대량의 일상적인 코드 생성 및 배치 작업은 GLM-5.1을 활용하세요. 플랫폼의 통합 인터페이스를 통해 다중 모델 전략을 매우 저렴하게 구현할 수 있습니다.
상황별 선택 가이드
Claude Opus 4.7을 선택해야 할 때
- 초대형 코드베이스 처리: 수십 개의 파일을 한 번에 로드하여 컨텍스트를 파악해야 할 때 (1M vs 200K)
- 코드 리뷰 및 보안 감사: 매우 높은 정확도와 자체 검증 능력이 필요할 때
- 멀티모달 개발: UI 스크린샷, 디자인 시안, 문서 이미지 등을 이해해야 할 때 (3.75MP 고해상도 비전)
- 엔터프라이즈급 신뢰성 요구: 안정적인 폐쇄형 상용 지원이 필요할 때
- 복잡한 추론 중심 코딩: 수학적 계산, 알고리즘 설계 등 깊이 있는 추론이 필요한 작업
GLM-5.1을 선택해야 할 때
- 장기 자율 개발: 대규모 리팩토링을 위해 모델이 수 시간 동안 지속적으로 작업해야 할 때
- 비용 효율적인 배치 작업: CI/CD 통합, 대량 코드 생성, 자동화 테스트
- 프라이빗 배포: 자체 서버에서 모델을 실행해야 할 때 (MIT 라이선스, 완전 오픈)
- 중국어 개발 환경: 중국어 코드 주석 및 문서 생성이 더 자연스럽고 매끄러움
- SWE-Bench 유형 작업: GitHub 이슈 해결, 버그 수정 등 실제 코딩 작업
베스트 프랙티스: 듀얼 모델 전략
| 작업 유형 | 추천 모델 | 이유 |
|---|---|---|
| 아키텍처 설계 및 기술 제안 | Opus 4.7 | 심층 추론 + 초장기 컨텍스트 |
| 일상적인 코드 작성 | GLM-5.1 | 낮은 비용, 충분한 품질 |
| 코드 리뷰 | Opus 4.7 | 정확도 + 자체 검증 |
| 대량 코드 생성 | GLM-5.1 | 비용이 14% 수준 |
| 버그 수정 (GitHub Issue) | GLM-5.1 | SWE-Bench Pro 1위 |
| 다중 파일 리팩토링 | Opus 4.7 | 1M 컨텍스트의 강점 |
| 장시간 자율 작업 | GLM-5.1 | 8시간 자율 실행 |
| UI/스크린샷 관련 개발 | Opus 4.7 | 3.75MP 고해상도 비전 |
🎯 통합 관리 제안: APIYI(apiyi.com)는 Claude Opus 4.7과 GLM-5.1을 모두 지원합니다. 개발자는 하나의 API 키와 통합된 OpenAI 호환 인터페이스를 통해 두 모델을 자유롭게 호출할 수 있으며, 작업 유형에 따라 유연하게 전환하여 코딩 효율성과 비용 최적화를 동시에 달성할 수 있습니다.
자주 묻는 질문 (FAQ)
Q1: GLM-5.1이 정말 Claude Opus보다 강력한가요?
어떤 측면을 보느냐에 따라 다릅니다. SWE-Bench Pro 단일 항목에서는 GLM-5.1(58.4)이 Opus 4.6(57.3)을 앞섰지만, 코딩 종합 점수에서는 Opus 4.6(57.5)이 GLM-5.1(54.9)보다 앞서 있습니다. Opus 4.7은 4.6의 대규모 업그레이드 버전인 만큼 종합적인 코딩 능력 격차는 더욱 벌어질 것으로 예상됩니다. 전반적으로는 Opus 4.7이 더 강력하지만, 특정 시나리오(장기 작업, SWE-Bench 유형 작업)에서는 GLM-5.1이 독보적인 강점을 가집니다.
Q2: GLM-5.1이 훨씬 저렴한데, 품질은 쓸만한가요?
대부분의 코딩 작업에는 충분합니다. GLM-5.1의 SWE-Bench Pro 성능은 이 모델이 최상급 코딩 능력을 갖췄음을 증명합니다. 평가 데이터에 따르면 Claude Opus 4.6 코딩 능력의 94.6% 수준에 도달했지만, 가격은 1/5에서 1/8 수준에 불과합니다. APIYI(apiyi.com)를 통해 직접 비교해 보고 결정하는 것이 가장 확실한 방법입니다.
Q3: 두 모델을 동일한 인터페이스로 호출할 수 있나요?
네, 가능합니다. APIYI(apiyi.com)는 통합된 OpenAI 호환 인터페이스를 제공하므로, 코드 프레임워크를 수정하거나 여러 API 키를 관리할 필요 없이 모델 ID만 변경하여 Claude Opus 4.7과 GLM-5.1 사이를 자유롭게 전환할 수 있습니다.
요약
Claude Opus 4.7과 GLM-5.1의 프로그래밍 성능 비교 핵심 결론입니다:
- SWE-Bench Pro 단일 항목: GLM-5.1(58.4)이 현재 앞서고 있으나, Opus 4.7의 점수는 아직 발표되지 않았습니다.
- 종합 코딩 능력: Opus 시리즈가 전반적으로 우세하며, 4.7 버전의 CursorBench 70% 달성 및 Rakuten-SWE-Bench 3배 성능 향상은 매우 인상적입니다.
- 장기 자율 코딩: GLM-5.1의 8시간 자율 실행 능력은 독보적인 강점입니다.
- 컨텍스트 윈도우: Opus 4.7의 1M 컨텍스트는 GLM-5.1보다 5배 커서 대규모 코드베이스 처리에 확실한 우위를 점합니다.
- 가격 차이: GLM-5.1의 비용은 Opus 4.7의 약 14% 수준입니다.
- 오픈소스 장점: GLM-5.1은 MIT 라이선스를 채택하여 프라이빗 배포 및 자유로운 커스터마이징이 가능합니다.
최적의 전략은 둘 중 하나를 선택하는 것이 아니라 두 모델을 병행하는 것입니다. 고가치 작업에는 Opus 4.7을, 고빈도 반복 작업에는 GLM-5.1을 활용하세요. APIYI(apiyi.com)는 두 모델을 모두 지원하며, 개발자는 통합 인터페이스를 통해 유연하게 모델을 호출하여 코딩 효율성과 비용의 최적 균형을 찾을 수 있습니다.
📚 참고 자료
-
VentureBeat – GLM-5.1 오픈소스 출시 보도: GLM-5.1의 SWE-Bench Pro 1위 등극 상세 보도
- 링크:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - 설명: 벤치마크 데이터를 포함한 권위 있는 기술 매체의 출시 보도
- 링크:
-
MarkTechPost – GLM-5.1 기술 분석: 754B 에이전트 모델 기술 분석
- 링크:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - 설명: 아키텍처 상세 정보 및 8시간 자율 실행 능력 분석 포함
- 링크:
-
Anthropic 공식 – Claude Opus 4.7 출시: 전체 업그레이드 내용
- 링크:
anthropic.com/news/claude-opus-4-7 - 설명: Opus 4.7 공식 발표 및 벤치마크 데이터
- 링크:
-
GLM-5.1 HuggingFace 모델 페이지: 오픈소스 모델 다운로드 및 문서
- 링크:
huggingface.co/zai-org/GLM-5.1 - 설명: MIT 라이선스 기반 모델 가중치 및 배포 가이드
- 링크:
-
Claude API 문서 – 모델 개요: 모든 Claude 모델 기술 사양
- 링크:
platform.claude.com/docs/en/about-claude/models/overview - 설명: 공식 모델 파라미터, 가격 및 기능 비교
- 링크:
작성자: APIYI 기술팀
기술 교류: 댓글로 자유롭게 토론해 주세요. 더 많은 자료는 APIYI 문서 센터(docs.apiyi.com)에서 확인하실 수 있습니다.