
ملاحظة من المؤلف: تحليل معمق للفروقات في قدرات البرمجة بين Claude Opus 4.7 و GLM-5.1، يغطي معايير الاختبار مثل SWE-Bench و CursorBench، والبرمجة الذاتية طويلة المدى، وتسعير الـ API، لمساعدة المطورين في اختيار النموذج الأنسب لمهام البرمجة.

في أبريل 2026، شهد مجال البرمجة باستخدام الذكاء الاصطناعي مواجهة قوية بين عملاقين. في 7 أبريل، أطلقت شركة Z.ai نموذجها مفتوح المصدر GLM-5.1، الذي تصدر القائمة العالمية بـ 58.4 نقطة في اختبار SWE-Bench Pro. وبعد 9 أيام فقط، في 16 أبريل، أطلقت Anthropic نموذج Claude Opus 4.7، الذي قفز بأدائه في CursorBench من 58% إلى 70%، وحقق في اختبار Rakuten-SWE-Bench ثلاثة أضعاف المهام المنجزة مقارنة بالإصدار 4.6.
يتمتع النموذجان بتوجهات معمارية مختلفة وفوارق سعرية كبيرة، لكنهما يتنافسان مباشرة في ساحة البرمجة. وقد أتاحت خدمة وكيل API الخاص بـ APIYI (apiyi.com) كلا النموذجين، مما يتيح للمطورين مقارنتهما بسرعة عبر واجهة موحدة.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتضح لك المزايا البرمجية لكل نموذج، ومتى يجب عليك اختيار أحدهما.
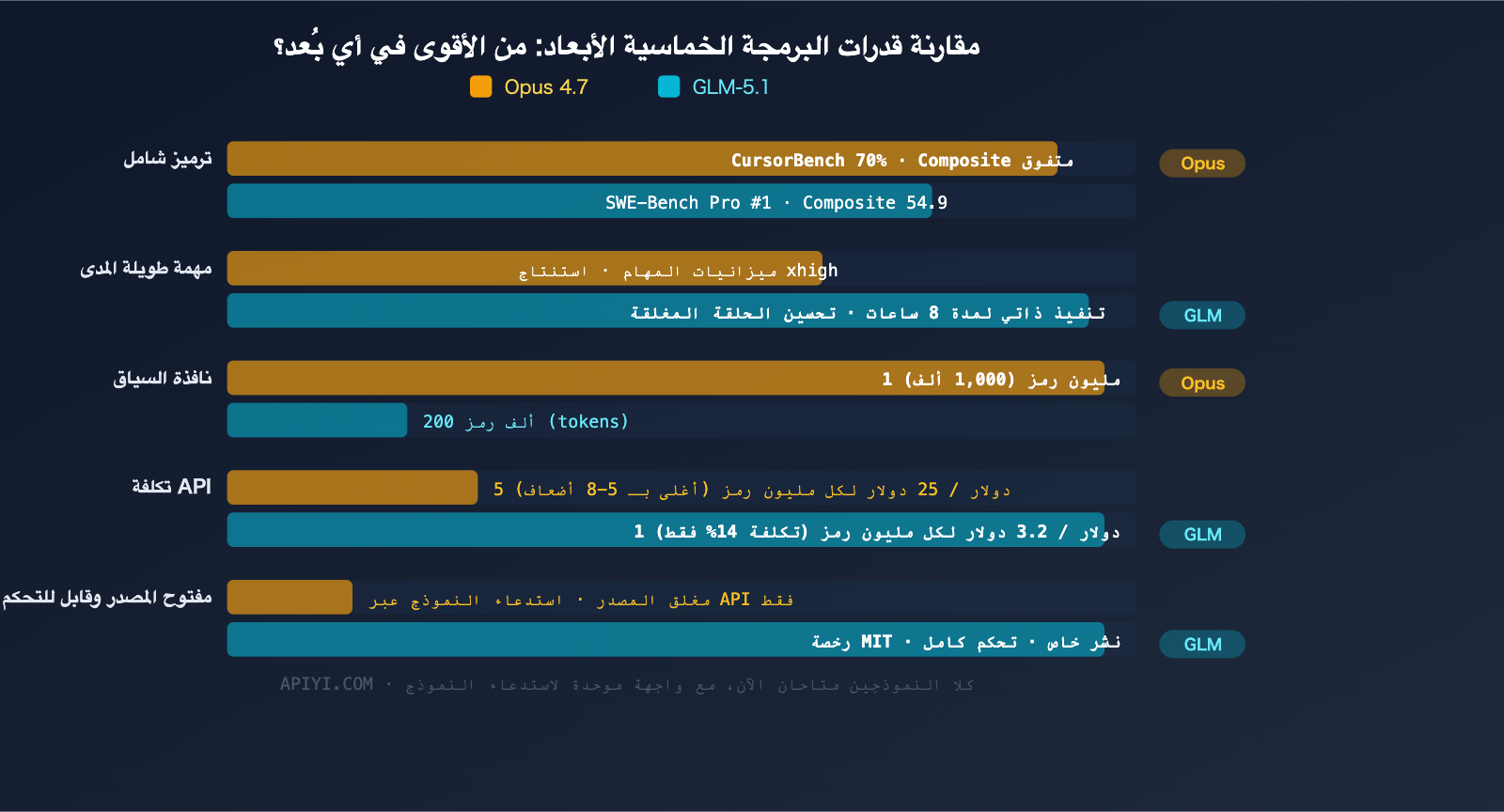
مقارنة الخصائص الجوهرية بين Claude Opus 4.7 و GLM-5.1
| وجه المقارنة | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| تاريخ الإصدار | 2026.04.16 | 2026.04.07 |
| المطور | Anthropic | Z.ai |
| معمارية النموذج | مغلق المصدر | 744B MoE (40B بارامتر نشط) |
| رخصة الاستخدام | ❌ مغلق المصدر | ✅ رخصة MIT (مفتوح بالكامل) |
| نافذة السياق | 1M tokens | 200K tokens |
| أقصى مخرجات | 128K tokens | 131K tokens |
| سعر إدخال API | $5 / MTok | $1 / MTok |
| سعر إخراج API | $25 / MTok | $3.2 / MTok |
| القدرات البصرية | ✅ 2576px / 3.75MP | ✅ مدعومة |
| نمط التفكير | تفكير تكيفي | تفكير متعدد الأنماط |
| SWE-Bench Pro | متوقع > 57.3 (أداء الإصدار 4.6) | 58.4 (الأول حالياً) |
| CursorBench | 70% | — |
| عتاد التدريب | مجموعات GPU أمريكية | Huawei Ascend 910B |
🎯 الخلاصة السريعة: إذا كنت تبحث عن أقصى قدرات برمجية + نافذة سياق ضخمة + فهم بصري، اختر Opus 4.7؛ أما إذا كنت تبحث عن أفضل قيمة مقابل سعر + تحكم كامل (مفتوح المصدر) + قدرات برمجية قوية جداً، فاختر GLM-5.1. كلا النموذجين متاحان الآن عبر APIYI (apiyi.com).
مقارنة عميقة لمعايير البرمجة
SWE-Bench Pro: نموذج GLM-5.1 يتصدر حالياً
يُعد SWE-Bench Pro أحد أكثر معايير البرمجة موثوقية في العالم الحقيقي، حيث يختبر قدرة النماذج على حل مشكلات (Issues) حقيقية على GitHub.
| النموذج | SWE-Bench Pro | الترتيب |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | متوقع > 57.3 | بانتظار التحديث |
تصدر نموذج GLM-5.1 اختبار SWE-Bench Pro برصيد 58.4 نقطة، متفوقاً على GPT-5.4 (57.7) وClaude Opus 4.6 (57.3). ومن الجدير بالذكر أن Opus 4.7 شهد تحسناً ملحوظاً في مجال البرمجة مقارنة بـ 4.6 (زيادة 12 نقطة مئوية في CursorBench، وثلاثة أضعاف في Rakuten-SWE-Bench)، ومن المتوقع أن يرتفع رصيده في SWE-Bench Pro بشكل جوهري، لكن النتائج لم تُعلن رسمياً حتى وقت كتابة هذا التقرير.
CursorBench: تفوق كبير لـ Opus 4.7
يقيس CursorBench قدرة النماذج على كتابة الكود داخل بيئة تطوير متكاملة (IDE) حقيقية (محرر Cursor)، وهو ما يحاكي سيناريوهات التطوير اليومية بشكل أدق.
| النموذج | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | لا توجد بيانات |
التقييم البرمجي الشامل (Coding Composite)
يجمع التقييم البرمجي الشامل بين عدة أبعاد مثل SWE-Bench Pro، وTerminal-Bench 2.0، وNL2Repo:
| النموذج | التقييم البرمجي الشامل |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | متوقع أعلى بكثير من 4.6 |
في التقييم البرمجي الشامل، يتصدر Claude Opus 4.6 برصيد 57.5 مقابل 54.9 لـ GLM-5.1. ومن المتوقع أن يوسع Opus 4.7 الفجوة في القدرات البرمجية الشاملة.
🎯 تحليل: بينما أثبت GLM-5.1 قوته في اختبار SWE-Bench Pro كنموذج منفرد، لا تزال سلسلة Claude تحتفظ بالصدارة في القدرات البرمجية الشاملة. يمكن للمطورين استخدام خدمة وكيل API من APIYI (apiyi.com) للوصول إلى كلا النموذجين وإجراء اختبارات A/B في مشاريعهم الفعلية.

تحليل معمق لقدرات سيناريوهات البرمجة
لا تعد الاختبارات المعيارية سوى بُعد واحد للتقييم. في سيناريوهات البرمجة الفعلية، يظهر كل نموذج مزايا مختلفة تماماً.
البرمجة الذاتية طويلة الأمد
تعد هذه الميزة القاتلة لنموذج GLM-5.1.
| القدرة طويلة الأمد | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| أقصى وقت تنفيذ ذاتي | يعتمد على ميزانية المهمة | 8 ساعات متواصلة |
| الحلقة الذاتية | يدعم الوكلاء متعددي الخطوات | حلقة مغلقة كاملة «تخطيط ← تنفيذ ← اختبار ← إصلاح ← تحسين» |
| إدارة ميزانية الرموز | ميزانيات المهام (ميزة جديدة) | إدارة مدمجة للمهام الطويلة |
| الإصلاح الذاتي | إصلاح تلقائي أثناء البرمجة | حلقة ذاتية من «تجربة ← تحليل ← تحسين» |
يستطيع GLM-5.1 تنفيذ مهام البرمجة ذاتياً وبشكل مستمر لمدة تصل إلى 8 ساعات، مشكلاً حلقة مغلقة من «التجربة والتحليل والتحسين»، وهو ما يمنحه ميزة كبيرة في سيناريوهات إعادة الهيكلة الضخمة أو نقل البيانات بين الوحدات البرمجية.
على الرغم من أن Opus 4.7 عزز قدراته في المهام الطويلة عبر ميزانيات المهام (Task Budgets) ومستوى الاستدلال xhigh، إلا أنه يركز أكثر على «الإنجاز الفعال ضمن الميزانية» بدلاً من «التنفيذ غير المحدود لفترات طويلة».
مهام الوكلاء (Agentic Tasks)
| قدرات الوكلاء | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| دعم MCP الأصلي | ✅ تحسين عميق | ✅ مدعوم |
| كفاءة استدعاء الأدوات | استدعاءات أقل، استدلال أكثر | استخدام نشط للأدوات |
| موثوقية الخطوات المتعددة | عالية جداً | عالية |
| إدارة السياق | نافذة سياق 1M رمز | 200K رمز |
| إدارة الوكلاء الفرعيين | تحكم دقيق (قابل للتعديل) | مدعوم |
فيما يخص مهام الوكلاء، تتفوق نافذة السياق البالغة 1M رمز في Opus 4.7 بشكل ساحق. عند التعامل مع قواعد بيانات برمجية ضخمة، يمكن لـ Opus 4.7 تحميل المزيد من سياق الملفات دفعة واحدة، مما يقلل من فقدان المعلومات.
مراجعة الكود وإعادة الهيكلة
| قدرات مراجعة الكود | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| دقة التعليمات | تنفيذ حرفي أكثر، دقة عالية دون إغفال | تفسير مرن |
| قدرة التحقق الذاتي | التحقق قبل المخرجات (جديد) | مدعوم |
| معالجة الملفات الكبيرة | تحميل كامل لقاعدة الكود (1M سياق) | قيود 200K قد تتطلب التقسيم |
| المراجعة البصرية | فهم لقطات الشاشة عالية الدقة | رؤية أساسية |
البرمجة السريعة والتطوير اليومي
| البرمجة اليومية | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| سرعة الاستجابة | متوسطة | أسرع |
| تكلفة API | $5/$25 لكل مليون رمز | $1/$3.2 لكل مليون رمز |
| نمط الكود | أكثر إيجازاً، يميل للاستدلال | تعليقات مفصلة، يميل لاستدعاء الأدوات |
| دعم اللغات | ممتاز | ممتاز (تعليقات الكود بالعربية أكثر طبيعية) |
مقارنة الأسعار: فجوة تكلفة تصل إلى 5 أضعاف
السعر عامل لا يمكن تجاهله عند اختيار النموذج. الفجوة في التسعير بين الاثنين كبيرة جداً:
| بند الفوترة | Claude Opus 4.7 | GLM-5.1 | الفارق |
|---|---|---|---|
| سعر الإدخال | $5 / مليون رمز | $1 / مليون رمز | Opus أغلى 5 أضعاف |
| سعر الإخراج | $25 / مليون رمز | $3.2 / مليون رمز | Opus أغلى 7.8 ضعف |
| سعر التخزين المؤقت | خصم قياسي | $0.26 / مليون رمز | تخزين GLM رخيص جداً |
| علاوة السياق الطويل | لا يوجد | لا يوجد | — |
تقدير التكلفة في سيناريوهات واقعية
بافتراض أن فريق تطوير متوسط الحجم يستهلك 500 مليون رمز شهرياً (نصفها إدخال ونصفها إخراج):
| النموذج المستخدم | تكلفة الإدخال الشهرية | تكلفة الإخراج الشهرية | الإجمالي الشهري |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| فارق التكلفة | — | — | $6,450/شهر |
تبلغ تكلفة GLM-5.1 حوالي 14% فقط من تكلفة Opus 4.7. بالنسبة للفرق الحساسة للميزانية، يعد هذا فرقاً حاسماً.
🎯 استراتيجية تحسين التكلفة: من خلال منصة APIYI (apiyi.com)، يمكنك التبديل بمرونة بين النموذجين؛ حيث يمكنك إسناد تصميم البنية المعقدة ومراجعة الكود إلى Opus 4.7، بينما تترك مهام توليد الكود اليومية الضخمة ومعالجة الدفعات لنموذج GLM-5.1. الواجهة الموحدة للمنصة تجعل تنفيذ استراتيجية النماذج المتعددة منخفض التكلفة للغاية.
توصيات الاختيار حسب سيناريوهات الاستخدام
سيناريوهات اختيار نموذج Claude Opus 4.7
- معالجة قواعد الأكواد الضخمة: عندما تحتاج إلى تحميل سياق عشرات الملفات دفعة واحدة (1 مليون مقابل 200 ألف رمز).
- مراجعة الأكواد والتدقيق الأمني: عندما تتطلب المهمة دقة عالية للغاية وقدرة على التحقق الذاتي.
- التطوير متعدد الوسائط: عندما تحتاج إلى فهم لقطات شاشة واجهات المستخدم، مسودات التصميم، وصور المستندات (رؤية بدقة عالية تصل إلى 3.75 ميجابكسل).
- متطلبات الموثوقية على مستوى المؤسسات: الحاجة إلى دعم تجاري مغلق المصدر ومستقر.
- البرمجة المعقدة كثيفة الاستنتاج: سيناريوهات تتطلب تفكيراً عميقاً مثل الحسابات الرياضية وتصميم الخوارزميات.
سيناريوهات اختيار نموذج GLM-5.1
- التطوير الذاتي طويل الأمد: الحاجة إلى عمل النموذج بشكل مستمر لساعات لإتمام عمليات إعادة هيكلة (Refactoring) كبيرة.
- المهام الجماعية الحساسة للتكلفة: تكامل CI/CD، توليد الأكواد بالجملة، والاختبارات المؤتمتة.
- النشر الخاص (Private Deployment): الحاجة لتشغيل النموذج على خوادمك الخاصة (ترخيص MIT، مفتوح بالكامل).
- بيئة التطوير باللغة الصينية: توليد تعليقات الأكواد والوثائق باللغة الصينية بشكل أكثر طبيعية وسلاسة.
- مهام فئة SWE-Bench: حل مشكلات GitHub، إصلاح الأخطاء (Bugs)، وغيرها من مهام البرمجة الواقعية.
أفضل الممارسات: استراتيجية النموذج المزدوج
| نوع المهمة | النموذج الموصى به | السبب |
|---|---|---|
| تصميم البنية والحلول التقنية | Opus 4.7 | استنتاج عميق + نافذة سياق طويلة جداً |
| كتابة الأكواد اليومية | GLM-5.1 | تكلفة منخفضة وجودة كافية |
| مراجعة الأكواد | Opus 4.7 | دقة عالية + تحقق ذاتي |
| توليد الأكواد بكميات كبيرة | GLM-5.1 | تكلفة تعادل 14% فقط |
| إصلاح الأخطاء (GitHub Issue) | GLM-5.1 | يتصدر قائمة SWE-Bench Pro |
| إعادة هيكلة ملفات متعددة | Opus 4.7 | ميزة نافذة السياق 1M |
| المهام الذاتية طويلة الأمد | GLM-5.1 | تنفيذ ذاتي لمدة 8 ساعات |
| التطوير المتعلق بـ UI/لقطات الشاشة | Opus 4.7 | رؤية بدقة عالية 3.75MP |
🎯 نصيحة للإدارة الموحدة: توفر منصة APIYI (apiyi.com) كلاً من Claude Opus 4.7 و GLM-5.1، حيث يمكن للمطورين استدعاء كلا النموذجين عبر مفتاح API واحد وواجهة متوافقة مع OpenAI، مما يتيح التبديل المرن حسب نوع المهمة لتحقيق أفضل توازن بين كفاءة البرمجة والتكلفة.
الأسئلة الشائعة
س1: هل GLM-5.1 أقوى حقاً من Claude Opus؟
يعتمد ذلك على المعيار المحدد. في اختبار SWE-Bench Pro، تفوق GLM-5.1 (58.4) بالفعل على Opus 4.6 (57.3)، ولكن في التقييم الشامل للبرمجة، لا يزال Opus 4.6 (57.5) متقدماً على GLM-5.1 (54.9). ومع إصدار Opus 4.7 كترقية كبيرة لـ 4.6، من المتوقع أن تتسع الفجوة في القدرات البرمجية الشاملة. بشكل عام، يتفوق Opus 4.7 في الأداء العام، بينما يتمتع GLM-5.1 بمزايا فريدة في سيناريوهات معينة (المهام طويلة الأمد ومهام SWE-Bench).
س2: GLM-5.1 أرخص بكثير، هل جودته كافية؟
بالنسبة لمعظم مهام البرمجة، نعم كافية. أثبت أداء GLM-5.1 في اختبار SWE-Bench Pro أنه يمتلك قدرات برمجية من الطراز الأول. تشير بيانات التقييم إلى أنه وصل إلى 94.6% من قدرات البرمجة لنموذج Claude Opus 4.6، لكن بتكلفة تتراوح بين 1/5 إلى 1/8 فقط. الطريقة الأكثر أماناً هي إجراء مقارنة فعلية عبر APIYI (apiyi.com) قبل اتخاذ القرار.
س3: هل يمكن استدعاء النموذجين عبر نفس الواجهة؟
نعم. توفر منصة APIYI (apiyi.com) واجهة موحدة متوافقة مع OpenAI، ما عليك سوى تغيير معرف النموذج (Model ID) للتبديل بين Claude Opus 4.7 و GLM-5.1، دون الحاجة إلى تعديل إطار عمل الكود أو إدارة مفاتيح API متعددة.
ملخص
النتائج الجوهرية للمقارنة البرمجية بين Claude Opus 4.7 و GLM-5.1:
- معيار SWE-Bench Pro: يتصدر GLM-5.1 حالياً (58.4)، بينما لم يتم الإعلان عن نتائج Opus 4.7 بعد.
- قدرات البرمجة الشاملة: تتفوق سلسلة Opus بشكل عام، حيث حقق إصدار 4.7 نسبة 70% في CursorBench وتحسناً بمقدار 3 أضعاف في Rakuten-SWE-Bench، وهي نتائج مبهرة.
- البرمجة الذاتية طويلة المدى: يتميز GLM-5.1 بقدرته الفريدة على التنفيذ الذاتي لمدة 8 ساعات.
- نافذة السياق: تبلغ نافذة Opus 4.7 مليون رمز (1M)، وهي أكبر بـ 5 أضعاف من GLM-5.1، مما يمنحه ميزة واضحة في التعامل مع قواعد الأكواد البرمجية الضخمة.
- فارق السعر: تكلفة GLM-5.1 تعادل حوالي 14% فقط من تكلفة Opus 4.7.
- ميزة المصدر المفتوح: يعتمد GLM-5.1 على رخصة MIT، مما يدعم النشر الخاص والتخصيص الحر.
الاستراتيجية المثلى ليست الاختيار بينهما، بل الجمع بين النموذجين؛ استخدم Opus 4.7 للمهام عالية القيمة، و GLM-5.1 للمهام المتكررة ذات الحجم الكبير. لقد أتاحت منصة APIYI (apiyi.com) النموذجين معاً، حيث يمكن للمطورين استدعاء النماذج بمرونة عبر واجهة موحدة، لتحقيق أفضل توازن بين كفاءة البرمجة والتكلفة.
📚 المراجع
-
VentureBeat – تقرير إطلاق GLM-5.1 مفتوح المصدر: تقرير مفصل حول تصدر GLM-5.1 لاختبار SWE-Bench Pro.
- الرابط:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - ملاحظة: تقرير من وسيلة إعلام تقنية موثوقة يتضمن بيانات اختبارات الأداء.
- الرابط:
-
MarkTechPost – تحليل تقني لـ GLM-5.1: تحليل تقني لنموذج الوكيل الذكي بحجم 754B.
- الرابط:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - ملاحظة: يتضمن تفاصيل البنية المعمارية وتحليل لقدرة التنفيذ الذاتي لمدة 8 ساعات.
- الرابط:
-
Anthropic – إطلاق Claude Opus 4.7: ملاحظات التحديث الكاملة.
- الرابط:
anthropic.com/news/claude-opus-4-7 - ملاحظة: الإعلان الرسمي عن Opus 4.7 وبيانات اختبارات الأداء.
- الرابط:
-
صفحة نموذج GLM-5.1 على HuggingFace: تحميل النموذج مفتوح المصدر والوثائق.
- الرابط:
huggingface.co/zai-org/GLM-5.1 - ملاحظة: أوزان النموذج ودليل النشر تحت رخصة MIT.
- الرابط:
-
وثائق Claude API – نظرة عامة على النماذج: المواصفات التقنية لجميع نماذج Claude.
- الرابط:
platform.claude.com/docs/en/about-claude/models/overview - ملاحظة: معايير النماذج الرسمية، التسعير، ومقارنة الوظائف.
- الرابط:
الكاتب: فريق APIYI التقني
للتواصل التقني: نرحب بمناقشاتكم في قسم التعليقات، ولمزيد من المعلومات يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com