
title: "Claude Opus 4.7 vs GLM-5.1:编程领域巅峰对决"
description: "深度对比 Claude Opus 4.7 与 GLM-5.1 的编程能力,涵盖基准测试、长周期编码及 API 定价,助你做出最佳选择。"
Nota del autor: Análisis profundo de las diferencias en capacidades de programación entre Claude Opus 4.7 y GLM-5.1, cubriendo benchmarks como SWE-Bench y CursorBench, codificación autónoma de ciclo largo y precios de API, para ayudar a los desarrolladores a elegir el modelo de programación más adecuado.

En abril de 2026, el campo de la codificación con IA presenció un enfrentamiento directo entre dos pesos pesados. El 7 de abril, Zhipu AI (Z.ai) lanzó el Modelo de Lenguaje Grande de código abierto GLM-5.1, alcanzando la cima mundial con 58.4 puntos en SWE-Bench Pro. Solo 9 días después, el 16 de abril, Anthropic lanzó Claude Opus 4.7, que elevó su rendimiento en CursorBench del 58% al 70%, y triplicó la cantidad de tareas resueltas en Rakuten-SWE-Bench en comparación con la versión 4.6.
Aunque ambos modelos tienen posicionamientos, arquitecturas y precios muy distintos, compiten directamente en el campo de batalla fundamental de la programación. APIYI (apiyi.com) ya ha integrado ambos modelos, permitiendo a los desarrolladores compararlos rápidamente a través de una interfaz unificada.
Valor central: Al terminar de leer este artículo, tendrás claro cuáles son las ventajas de programación de cada modelo y cuál elegir según el escenario.
Comparativa de parámetros clave: Claude Opus 4.7 vs GLM-5.1
| Dimensión de comparación | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Fecha de lanzamiento | 16.04.2026 | 07.04.2026 |
| Desarrollador | Anthropic | Zhipu AI (Z.ai) |
| Arquitectura | Cerrada | 744B MoE (40B parámetros activos) |
| Licencia | ❌ Cerrada | ✅ Licencia MIT (código abierto) |
| Ventana de contexto | 1M tokens | 200K tokens |
| Salida máxima | 128K tokens | 131K tokens |
| Precio entrada API | $5 / MTok | $1 / MTok |
| Precio salida API | $25 / MTok | $3.2 / MTok |
| Capacidad visual | ✅ 2576px / 3.75MP | ✅ Compatible |
| Modo de razonamiento | Pensamiento adaptativo | Pensamiento multimodal |
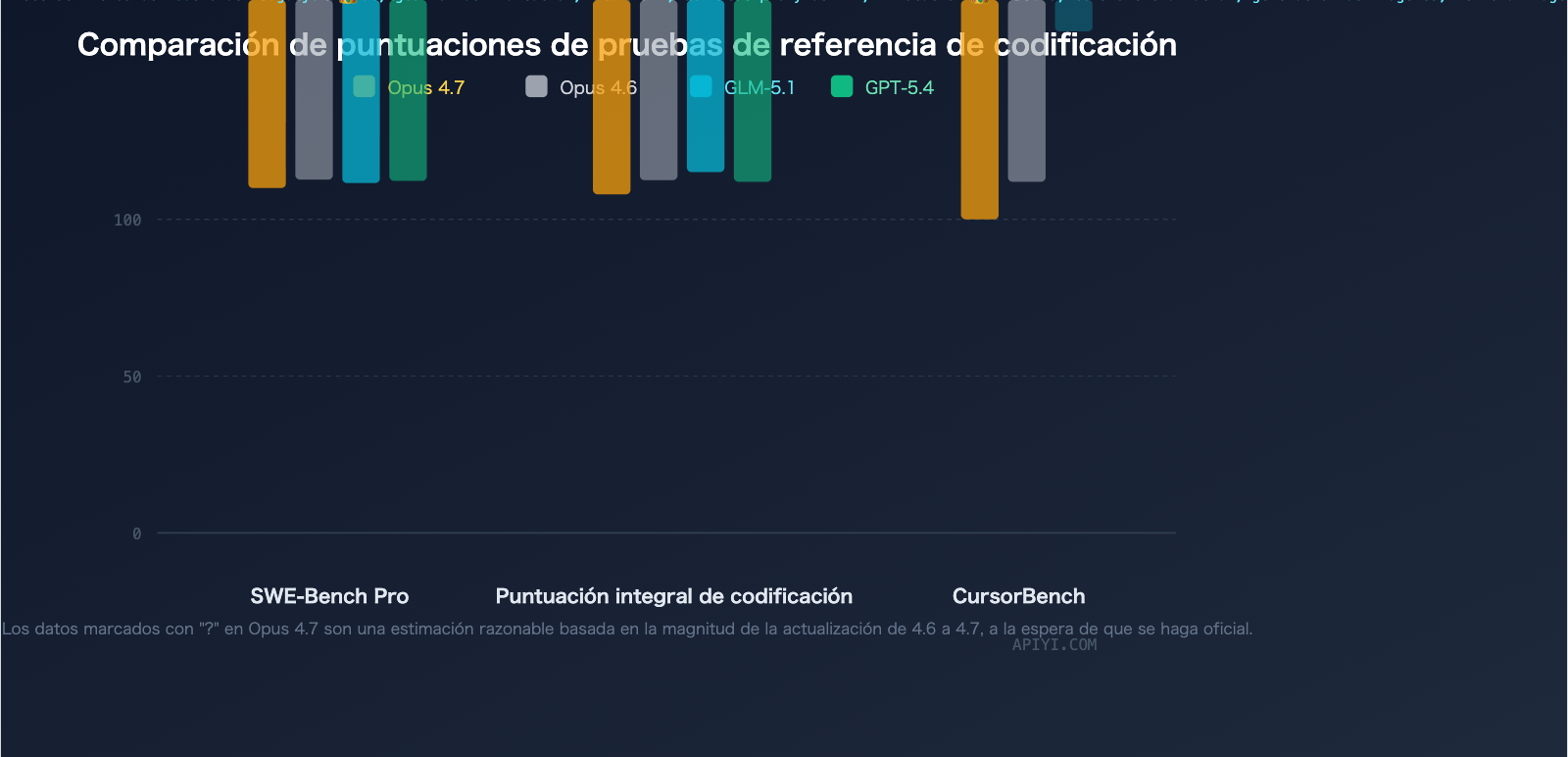
| SWE-Bench Pro | Estimado > 57.3 (puntuación de la 4.6) | 58.4 (líder actual) |
| CursorBench | 70% | — |
| Hardware de entrenamiento | Clúster de GPU en EE. UU. | Huawei Ascend 910B |
🎯 Conclusión rápida: Si buscas capacidad de programación extrema + ventana de contexto ultra larga + comprensión visual, elige Opus 4.7. Si buscas relación calidad-precio inigualable + control total (código abierto) + una capacidad de programación muy sólida, elige GLM-5.1. Ambos modelos ya están disponibles en APIYI (apiyi.com).
Comparativa profunda de benchmarks de programación
SWE-Bench Pro: GLM-5.1 lidera actualmente
SWE-Bench Pro es uno de los benchmarks de codificación del mundo real más autorizados, ya que evalúa la capacidad de los modelos para resolver problemas (Issues) reales en GitHub.
| Modelo | SWE-Bench Pro | Clasificación |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | Previsto > 57.3 | Pendiente |
GLM-5.1 encabeza la lista de SWE-Bench Pro con 58.4 puntos, superando a GPT-5.4 (57.7) y Claude Opus 4.6 (57.3). Cabe destacar que Opus 4.7 presenta una mejora significativa en el ámbito de la codificación respecto a la versión 4.6 (+12pp en CursorBench, 3 veces en Rakuten-SWE-Bench), por lo que se espera que su puntuación en SWE-Bench Pro aumente considerablemente, aunque aún no se ha publicado al momento de redactar este artículo.
CursorBench: Opus 4.7 lidera con ventaja
CursorBench evalúa la capacidad de escritura de código de los modelos en un entorno de IDE real (editor Cursor), lo que se asemeja más a los escenarios de desarrollo cotidianos.
| Modelo | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | Sin datos |
Puntuación compuesta de codificación (Coding Composite)
La puntuación compuesta de codificación agrega múltiples dimensiones, incluyendo SWE-Bench Pro, Terminal-Bench 2.0 y NL2Repo:
| Modelo | Puntuación compuesta de codificación |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | Previsto significativamente superior a 4.6 |
En cuanto a la puntuación compuesta de codificación, Claude Opus 4.6 lidera con 57.5 frente a los 54.9 de GLM-5.1. Se espera que la capacidad de codificación compuesta de Opus 4.7 amplíe aún más esta brecha.
🎯 Interpretación: GLM-5.1 ha demostrado ser el más fuerte en la categoría individual de SWE-Bench Pro, pero en capacidad de codificación compuesta, la serie Claude sigue manteniendo el liderazgo. Los desarrolladores pueden acceder a ambos modelos a través de APIYI (apiyi.com) para realizar pruebas A/B en sus propios proyectos reales.
Análisis profundo de capacidades en escenarios de programación
Los benchmarks son solo una dimensión. En escenarios de programación reales, ambos modelos muestran ventajas claramente diferenciadas.
Codificación autónoma de ciclo largo
Esta es la característica estrella de GLM-5.1.
| Capacidad de ciclo largo | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Tiempo máximo de ejecución autónoma | Depende del presupuesto de tarea | 8 horas ininterrumpidas |
| Bucle autónomo | Soporta agentes de múltiples pasos | Ciclo completo «planificación→ejecución→prueba→corrección→optimización» |
| Gestión de presupuesto de tokens | Presupuestos de tarea (nueva función) | Gestión de tareas largas integrada |
| Autocorrección | Corrección automática durante la codificación | Ciclo autónomo de «experimentación→análisis→optimización» |
GLM-5.1 es capaz de ejecutar tareas de codificación de forma autónoma y continua durante hasta 8 horas, formando un ciclo cerrado de «experimentación, análisis y optimización», lo cual resulta extremadamente ventajoso en escenarios como refactorizaciones a gran escala o migraciones entre módulos.
Aunque Opus 4.7 ha mejorado sus capacidades en tareas largas mediante los presupuestos de tarea y el nivel de razonamiento xhigh, se enfoca más en «completar eficientemente dentro del presupuesto» que en «ejecuciones prolongadas e ilimitadas».
Tareas de agentes (Agentic Tasks)
| Capacidad de agente | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Soporte nativo MCP | ✅ Optimización profunda | ✅ Soportado |
| Eficiencia en llamadas a herramientas | Menos llamadas, más razonamiento | Uso activo de herramientas |
| Fiabilidad en múltiples pasos | Muy alta | Alta |
| Gestión de contexto | Ventana de contexto ultra larga de 1M tokens | 200K tokens |
| Gestión de subagentes | Control preciso (ajustable) | Soportado |
En cuanto a tareas de agentes, la ventana de contexto de 1M de tokens de Opus 4.7 representa una ventaja abrumadora. Al trabajar con bases de código extensas, Opus 4.7 puede cargar más contexto de archivos de una sola vez, reduciendo la pérdida de información.
Revisión y refactorización de código
| Capacidad de revisión | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Precisión de instrucciones | Ejecución más literal, sin omisiones | Interpretación flexible |
| Capacidad de autoverificación | Verifica antes de emitir (novedad) | Soportado |
| Procesamiento de archivos grandes | Carga la base de código completa con 1M de contexto | El límite de 200K puede requerir segmentación |
| Revisión visual | Comprensión de capturas de alta resolución | Visión básica |
Codificación rápida y desarrollo diario
| Codificación diaria | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| Velocidad de respuesta | Media | Más rápida |
| Coste de API | $5/$25 por MTok | $1/$3.2 por MTok |
| Estilo de código | Más refinado, orientado al razonamiento | Comentarios detallados, orientado a herramientas |
| Soporte multilingüe | Excelente | Excelente (comentarios en chino más naturales) |
Comparativa de precios: una diferencia de coste de 5 veces
El precio es un factor que no se puede ignorar al elegir un modelo. La diferencia de precio entre ambos es muy significativa:
| Ítem de facturación | Claude Opus 4.7 | GLM-5.1 | Diferencia |
|---|---|---|---|
| Precio de entrada | $5 / MTok | $1 / MTok | Opus es 5 veces más caro |
| Precio de salida | $25 / MTok | $3.2 / MTok | Opus es 7.8 veces más caro |
| Precio de caché | Descuento estándar de caché | $0.26 / MTok | Caché de GLM extremadamente barata |
| Sobrecargo por contexto largo | Ninguno | Ninguno | — |
Estimación de costes en escenarios reales
Supongamos que un equipo de desarrollo mediano consume 500M de tokens al mes (mitad entrada, mitad salida):
| Modelo utilizado | Coste mensual de entrada | Coste mensual de salida | Total mensual |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| Diferencia | — | — | $6,450/mes |
El coste de GLM-5.1 es solo aproximadamente el 14% del de Opus 4.7. Para equipos sensibles al presupuesto, esta es una diferencia decisiva.
🎯 Estrategia de optimización de costes: A través de la plataforma APIYI (apiyi.com), puedes gestionar de forma flexible ambos modelos: delega el diseño de arquitectura complejo y la revisión de código a Opus 4.7, y asigna la generación masiva de código diario y tareas de procesamiento por lotes a GLM-5.1. La interfaz unificada de la plataforma hace que la implementación de una estrategia multimodelo sea extremadamente económica.

Recomendaciones de selección según el escenario
Escenarios para elegir Claude Opus 4.7
- Procesamiento de bases de código masivas: Cuando necesitas cargar el contexto de decenas de archivos de una sola vez (1M frente a 200K).
- Revisión de código y auditoría de seguridad: Requiere una precisión extremadamente alta y capacidad de autoverificación.
- Desarrollo multimodal: Necesitas comprender capturas de pantalla de UI, borradores de diseño e imágenes de documentos (visión de alta resolución de 3.75 MP).
- Requisitos de fiabilidad de nivel empresarial: Necesitas soporte comercial estable de código cerrado.
- Programación compleja intensiva en razonamiento: Escenarios que requieren razonamiento profundo, como cálculos matemáticos o diseño de algoritmos.
Escenarios para elegir GLM-5.1
- Desarrollo autónomo de ciclo largo: Necesitas que el modelo trabaje continuamente durante horas para completar grandes refactorizaciones.
- Tareas por lotes sensibles a los costos: Integración CI/CD, generación masiva de código y pruebas automatizadas.
- Despliegue privado: Necesitas ejecutar el modelo en tus propios servidores (licencia MIT, completamente abierto).
- Entorno de desarrollo en chino: Los comentarios de código y la generación de documentación en chino son más naturales y fluidos.
- Tareas tipo SWE-Bench: Resolver problemas de GitHub, corregir errores y otras tareas de programación del mundo real.
Mejores prácticas: Estrategia de doble modelo
| Tipo de tarea | Modelo recomendado | Motivo |
|---|---|---|
| Diseño de arquitectura y soluciones técnicas | Opus 4.7 | Razonamiento profundo + contexto ultralargo |
| Programación diaria | GLM-5.1 | Bajo costo, calidad suficiente |
| Revisión de código | Opus 4.7 | Precisión + autoverificación |
| Generación masiva de código | GLM-5.1 | Costo de solo el 14% |
| Corrección de errores (GitHub Issue) | GLM-5.1 | Líder en SWE-Bench Pro |
| Refactorización de múltiples archivos | Opus 4.7 | Ventaja de contexto de 1M |
| Tareas autónomas de larga duración | GLM-5.1 | 8 horas de ejecución autónoma |
| Desarrollo relacionado con UI/capturas de pantalla | Opus 4.7 | Visión de alta resolución de 3.75 MP |
🎯 Sugerencia de gestión unificada: APIYI (apiyi.com) ya ha integrado tanto Claude Opus 4.7 como GLM-5.1. Los desarrolladores pueden invocar ambos modelos a través de una única clave API y una interfaz unificada compatible con OpenAI, lo que permite cambiar de forma flexible según el tipo de tarea para lograr la máxima eficiencia de programación y equilibrio de costos.
Preguntas frecuentes
Q1: ¿Es GLM-5.1 realmente mejor que Claude Opus?
Depende de la dimensión específica. En la categoría individual de SWE-Bench Pro, GLM-5.1 (58.4) supera a Opus 4.6 (57.3), pero en la puntuación integral de programación, Opus 4.6 (57.5) lidera sobre GLM-5.1 (54.9). Como una actualización importante de la versión 4.6, se espera que Opus 4.7 amplíe aún más la brecha en la capacidad de programación integral. En general, Opus 4.7 es más completo, pero GLM-5.1 tiene ventajas únicas en escenarios específicos (tareas de ciclo largo, tareas tipo SWE-Bench).
Q2: GLM-5.1 es mucho más barato, ¿es suficiente su calidad?
Para la mayoría de las tareas de programación, es suficiente. El rendimiento de GLM-5.1 en SWE-Bench Pro demuestra que posee capacidades de programación de primer nivel. Los datos de evaluación muestran que alcanza el 94.6% de la capacidad de programación de Claude Opus 4.6, pero a un precio de solo 1/5 a 1/8. Realizar una comparación práctica a través de APIYI (apiyi.com) es la forma más segura de tomar una decisión.
Q3: ¿Se pueden invocar ambos modelos a través de la misma interfaz?
Sí. APIYI (apiyi.com) proporciona una interfaz unificada compatible con OpenAI; solo necesitas cambiar el ID del modelo para alternar entre Claude Opus 4.7 y GLM-5.1, sin necesidad de modificar el marco de código o gestionar múltiples claves API.
Resumen
Conclusiones clave de la comparativa de programación entre Claude Opus 4.7 y GLM-5.1:
- SWE-Bench Pro: GLM-5.1 (58.4) lidera actualmente, aunque la puntuación de Opus 4.7 aún no se ha publicado.
- Capacidad de codificación integral: La serie Opus mantiene el liderazgo general; el 70% en CursorBench y la mejora de 3 veces en Rakuten-SWE-Bench de la versión 4.7 son impresionantes.
- Codificación autónoma de ciclo largo: La ejecución autónoma de 8 horas de GLM-5.1 es un punto de venta único.
- Ventana de contexto: El 1M de Opus 4.7 es 5 veces mayor que el de GLM-5.1, lo que ofrece una ventaja clara al procesar bases de código extensas.
- Diferencia de precio: El coste de GLM-5.1 es solo aproximadamente el 14% del de Opus 4.7.
- Ventaja del código abierto: GLM-5.1 utiliza la licencia MIT, lo que permite el despliegue privado y la personalización libre.
La estrategia óptima no es elegir uno u otro, sino combinar ambos modelos: utilice Opus 4.7 para tareas de alto valor y GLM-5.1 para tareas frecuentes por lotes. APIYI (apiyi.com) ya ha integrado ambos modelos, permitiendo a los desarrolladores invocarlos de forma flexible a través de una interfaz unificada para lograr el mejor equilibrio entre eficiencia de codificación y costes.
📚 Referencias
-
VentureBeat – Informe sobre el lanzamiento de código abierto de GLM-5.1: Informe detallado sobre el liderazgo de GLM-5.1 en SWE-Bench Pro.
- Enlace:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - Descripción: Informe de un medio tecnológico autorizado que incluye datos de pruebas comparativas.
- Enlace:
-
MarkTechPost – Análisis técnico de GLM-5.1: Análisis técnico del modelo agente de 754B.
- Enlace:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - Descripción: Incluye detalles de la arquitectura y análisis de la capacidad de ejecución autónoma de 8 horas.
- Enlace:
-
Anthropic – Lanzamiento de Claude Opus 4.7: Notas completas de la actualización.
- Enlace:
anthropic.com/news/claude-opus-4-7 - Descripción: Anuncio oficial y datos de pruebas comparativas de Opus 4.7.
- Enlace:
-
Página del modelo GLM-5.1 en HuggingFace: Descarga del modelo de código abierto y documentación.
- Enlace:
huggingface.co/zai-org/GLM-5.1 - Descripción: Pesos del modelo bajo licencia MIT y guía de despliegue.
- Enlace:
-
Documentación de la API de Claude – Resumen de modelos: Especificaciones técnicas de todos los modelos Claude.
- Enlace:
platform.claude.com/docs/en/about-claude/models/overview - Descripción: Parámetros oficiales del modelo, precios y comparativa de funciones.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Le invitamos a debatir en la sección de comentarios. Para más información, visite el centro de documentación de APIYI en docs.apiyi.com.