
Lors de la conférence Google I/O 2026, le 19 mai 2026, Google a officiellement lancé la famille de modèles multimodaux Gemini Omni, dont le premier modèle, Gemini Omni Flash, a été déployé auprès des utilisateurs le jour même. Pour ceux qui découvrent ce nom, le terme « Omni » est bien plus important qu'il n'y paraît : il marque une nouvelle direction stratégique où Google fusionne totalement les capacités de raisonnement intelligent de Gemini avec ses outils de génération multimédia. Cet article vous explique en 5 minutes ce qu'est Google Omni, ce qu'il permet de faire, en quoi il diffère de Veo, et comment les développeurs ou créateurs peuvent s'y mettre.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez parfaitement le positionnement, les limites et l'importance industrielle de Google Omni (Gemini Omni), sans vous laisser perdre par les termes techniques des titres d'actualité.
Qu'est-ce que Google Omni : un aperçu rapide
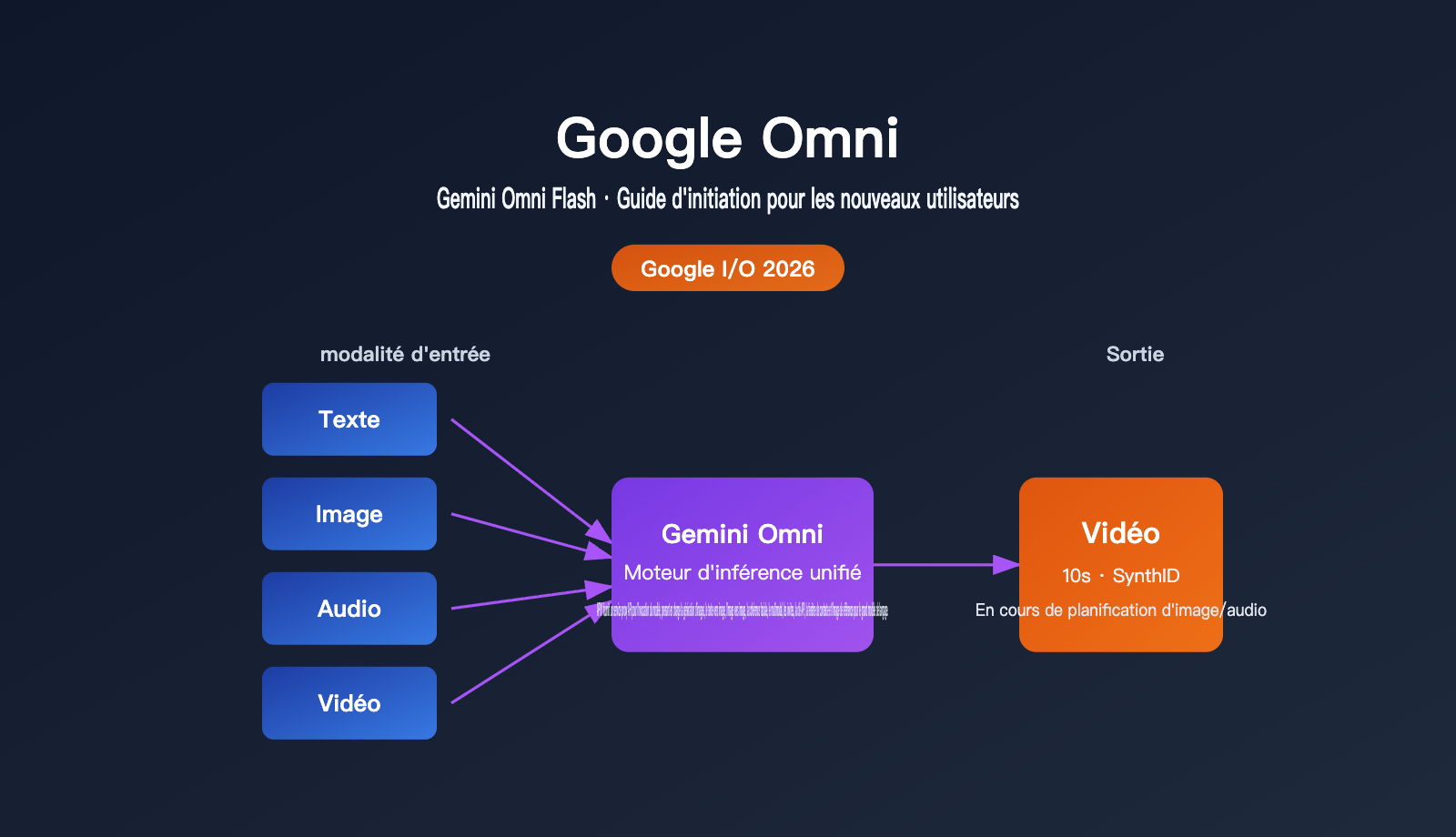
En une phrase : Google Omni est une « famille de modèles de génération multimodaux » lancée par Google, dont le premier modèle est Gemini Omni Flash. Son argument de vente principal n'est pas d'être « un énième IA capable de générer des vidéos », mais sa capacité à prendre n'importe quelle combinaison de texte, d'image, d'audio et de vidéo en entrée, pour produire, après un raisonnement unifié, une vidéo cohérente.
Lors de son discours, le PDG de Google, Sundar Pichai, a résumé son positionnement avec une formule simple : « create anything from any input ». En d'autres termes, là où il fallait auparavant utiliser un modèle pour générer une image, puis un autre pour l'animer, Omni tente d'accomplir le raisonnement et la génération inter-modale avec un seul et même modèle.
| Information | Détails |
|---|---|
| Date de lancement | 19 mai 2026 (Google I/O 2026) |
| Éditeur | Google (Google DeepMind & Google Labs) |
| Premier modèle | Gemini Omni Flash |
| Positionnement | Famille de modèles unifiés pour le raisonnement multimodal et la génération multimédia |
| Modalités d'entrée | Texte, image, vidéo, audio (combinaison libre) |
| Modalités de sortie | Vidéo (priorité initiale), images et audio prévus ultérieurement |
| Durée par segment | Jusqu'à 10 secondes (limite de déploiement, pas une limite technique du modèle) |
| Identification du contenu | Filigrane invisible SynthID intégré automatiquement à toutes les vidéos |
| Prochaines étapes | Version Pro, durées plus longues, capacités d'édition audio |
💡 Conseil pour les débutants : Si vous souhaitez tester rapidement les principaux modèles, dont la série Gemini, vous pouvez utiliser le service proxy API APIYI (apiyi.com) pour les appeler via une interface unifiée, évitant ainsi la corvée de vous inscrire sur chaque plateforme.
Analyse des capacités clés de Google Omni : Pourquoi est-ce une « nouvelle génération » ?
Si l'on se contente de regarder « ce qui entre et ce qui sort », il est facile de classer Omni dans la même catégorie que Sora, Veo ou Runway. Mais Nicole Brichtova, directrice produit chez Google, a donné une définition plus précise : « C'est la prochaine étape, combinant l'intelligence de Gemini avec les capacités de rendu des modèles multimédias. » Les quatre capacités suivantes sont essentielles pour comprendre en quoi Omni se distingue des modèles vidéo traditionnels.
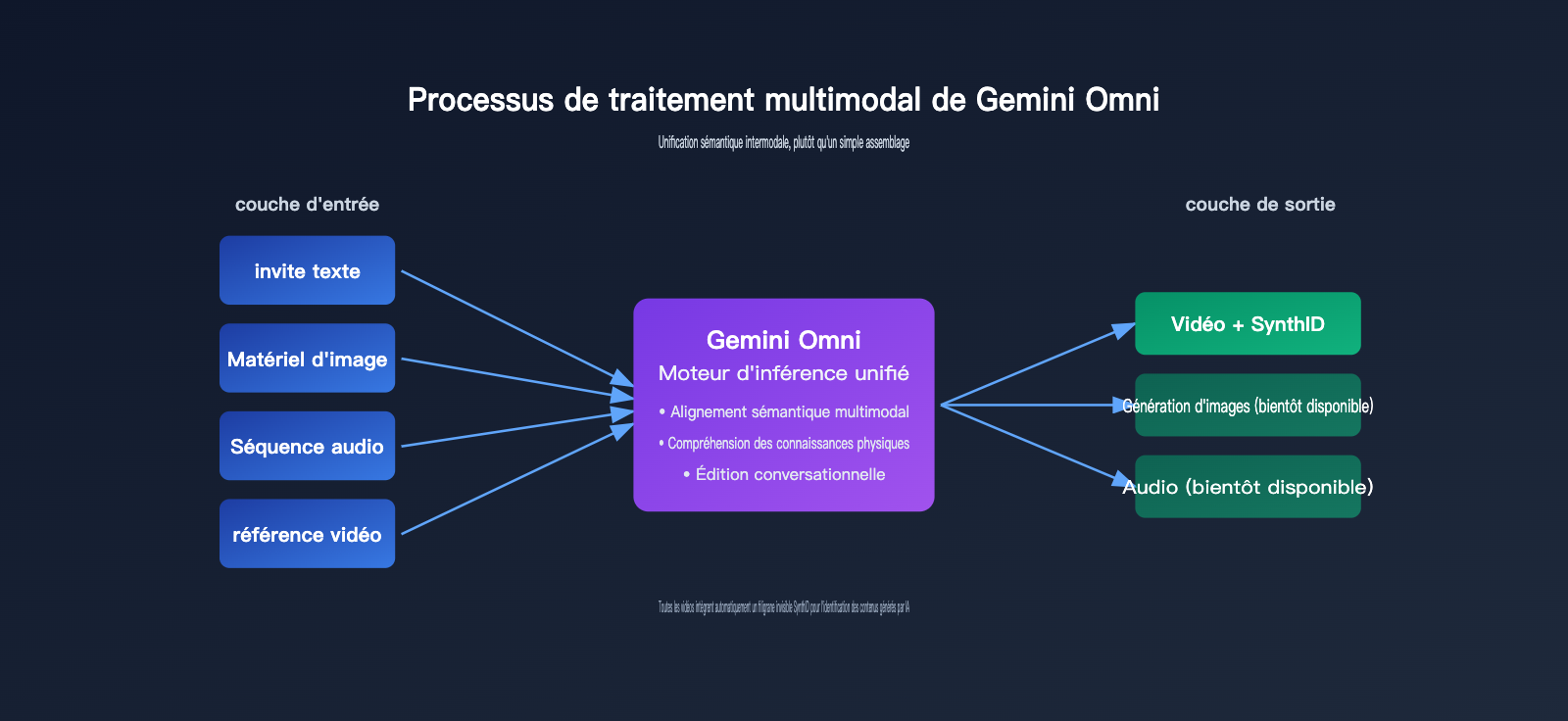
1. Raisonnement multimodal, plutôt qu'un simple assemblage
La génération vidéo traditionnelle suit souvent un processus en deux étapes : « texte → vidéo » ou « image + texte → vidéo ». L'approche de Gemini Omni consiste à injecter toutes les entrées dans un seul et même modèle, lui permettant d'établir une compréhension sémantique unifiée en interne, puis de générer la vidéo en une seule fois.
Par exemple, si vous fournissez simultanément à Omni une photo de produit, un morceau de musique de fond et un script publicitaire, il comprendra que « le produit doit apparaître au moment du changement de rythme » et que « le texte doit correspondre aux mouvements à l'écran », au lieu de simplement superposer la musique sur la vidéo. Cette capacité de « comprendre avant de générer » est ancrée dans l'ADN de raisonnement du modèle Gemini lui-même.
2. Compréhension physique et connaissances du monde
Dans ses démonstrations, Google a mis en avant deux exemples : une séquence avec une bille d'agate qui roule, où le rebond, l'arrêt et le bruit de collision au sol respectent les lois de la physique réelle ; et une animation éducative style pâte à modeler (claymation) sur le repliement des protéines, dont la structure géométrique est conforme aux bases de la biologie moléculaire. Ces démos semblent simples, mais elles témoignent de la compréhension des « lois du monde réel » par le modèle, et non d'une simple adaptation au niveau des pixels.
Pour les débutants, cela signifie que les vidéos générées par Omni sont moins sujettes aux défauts classiques des vidéos IA, comme les « objets qui se téléportent », les « éclairages incohérents » ou les « mains à plusieurs doigts ».
3. Édition itérative par conversation
Omni prend en charge l'édition « générer d'abord, modifier ensuite en langage naturel ». Une fois qu'une vidéo est générée, vous pouvez dire au modèle : « change l'arrière-plan pour un coucher de soleil » ou « ralentis la caméra ». Le modèle effectuera des ajustements locaux tout en conservant la cohérence des personnages, des scènes et des actions.
Cette interaction ressemble davantage à une conversation avec un monteur vidéo qu'à la rédaction d'une longue invite unique. C'est particulièrement intuitif pour ceux qui n'ont pas d'expérience en ingénierie d'invites.
4. Avatar numérique personnalisé
Omni permet aux utilisateurs de créer leur propre avatar numérique via une authentification biométrique, puis de l'intégrer dans les vidéos générées. Google souligne que cette étape doit être effectuée par la personne elle-même, afin de réduire les risques d'abus liés à l'usurpation d'identité (deepfake).
🎯 Résumé des capacités : Le point fort d'Omni n'est pas une « résolution plus élevée » ou une « durée plus longue », mais le trio « raisonnement multimodal + connaissances physiques + édition conversationnelle ». Pour intégrer ces capacités dans vos propres produits, nous vous suggérons de tester les effets de différentes combinaisons de modèles via un service proxy API comme APIYI (apiyi.com), avant de décider de votre solution principale.
Gemini Omni et Veo : Quelle différence ? Les deux noms qui sèment la confusion chez les débutants
Beaucoup de nouveaux utilisateurs demandent : « Google n'a-t-il pas déjà Veo ? À quoi sert Omni ? » C'est une question très légitime, car ils peuvent tous deux « générer de la vidéo », mais leur positionnement est totalement différent. Le tableau ci-dessous est le moyen le plus rapide pour comprendre la relation entre les deux.
| Dimension de comparaison | Veo | Gemini Omni |
|---|---|---|
| Type de modèle | Modèle média spécialisé | Modèle unifié (raisonnement multimodal + génération) |
| Entrées supportées | Texte, image | Texte + image + audio + vidéo (combinaison libre) |
| Profondeur de raisonnement | Principalement au niveau du rendu | Utilise le raisonnement Gemini, sémantique multimodale unifiée |
| Méthode d'édition | Principalement par régénération | Supporte l'édition incrémentale conversationnelle |
| Compréhension physique | Moyenne | Significativement améliorée (point fort des démos officielles) |
| Public cible | Créateurs vidéo professionnels | Créateurs + grand public + développeurs |
| Positionnement actuel | Outil de génération vidéo haute qualité | Modèle de base multimodal « créer tout » |
Analogie simple : Veo est comme une imprimante haute fidélité ; vous lui donnez une image, elle produit un résultat magnifique. Omni ressemble davantage à un assistant complet capable de comprendre vos intentions : vous lui fournissez quelques éléments et une demande en une phrase, et il produit le résultat final. Les deux coexisteront probablement à l'avenir, mais Omni représente la voie de « l'unification multimodale » sur laquelle Google mise tout.

🧭 Conseil pour les débutants : Si vous voulez simplement générer de courts clips magnifiques, Veo suffit encore largement. Si vous développez des scénarios d'application avec des entrées mixtes (texte, image, audio, vidéo), Omni est la direction la plus pertinente. Pour comparer rapidement les performances réelles de ces deux types de modèles, nous vous recommandons d'utiliser une interface comme APIYI (apiyi.com) qui permet de basculer entre plusieurs modèles, afin de changer de modèle sans modifier votre flux de travail.
Comment utiliser Gemini Omni Flash : guide pour les débutants
Lors de son lancement, Gemini Omni Flash a été rendu accessible à différents publics, mais via des canaux disparates. Le tableau comparatif ci-dessous aidera les nouveaux utilisateurs à déterminer rapidement par où commencer.
| Type d'utilisateur | Point d'entrée recommandé | Payant ? | Remarques |
|---|---|---|---|
| Grand public | Application Gemini | Abonnement Google AI Plus/Pro/Ultra requis | Création personnelle, montage vidéo court |
| Créateurs de contenu | Google Flow | Abonnement Google AI requis | Flux de travail créatifs professionnels |
| Utilisateurs de vidéos courtes | YouTube Shorts, YouTube Create App | Gratuit | Accès gratuit limité, idéal pour débuter |
| Développeurs / Entreprises | Google API (bientôt disponible) | Prix non encore annoncé | Ouverture dans quelques semaines, surveillez les annonces |
| Évaluateurs de modèles | Plateformes API tierces | Selon la tarification de la plateforme | Idéal pour les équipes R&D comparant plusieurs modèles |
Le chemin le plus simple pour débuter
- Si vous n'utilisez aucun outil d'IA payant, je vous recommande de commencer par YouTube Shorts ou l'application YouTube Create pour tester la génération vidéo gratuite d'Omni. C'est la porte d'entrée la plus accessible.
- Si vous êtes déjà abonné à Google AI Plus ou supérieur, ouvrez directement l'application Gemini ; vous trouverez l'option de génération vidéo Omni dans le panneau de création.
- Si vous êtes développeur, la stratégie la plus pragmatique consiste à tester les résultats côté utilisateur en attendant l'ouverture de l'API officielle. En parallèle, utilisez APIYI (apiyi.com) pour invoquer d'autres modèles de la gamme Gemini déjà disponibles, afin de préparer dès maintenant vos pipelines d'invocation multimodale.
Un exemple d'invocation minimaliste (en attendant l'API officielle)
Bien que l'API officielle pour les développeurs soit annoncée pour "dans quelques semaines", nous pouvons concevoir la structure d'appel dès maintenant pour une intégration immédiate le moment venu.
# Exemple d'invocation agrégée (structure indicative, remplacez le modèle une fois l'API officielle disponible)
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Accès unifié aux modèles via APIYI
)
# Appel actuel des modèles de la gamme Gemini déjà disponibles
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "Expliquez en une phrase la valeur fondamentale des modèles multimodaux"}]
)
print(response.choices[0].message.content)
💡 Conseil pour bien démarrer : Pas besoin d'attendre l'ouverture de toutes les API officielles. Utilisez APIYI (apiyi.com) pour configurer vos flux avec les autres modèles Gemini. Une fois l'API Omni disponible, il vous suffira de remplacer le nom du modèle, pour un coût de migration quasi nul.
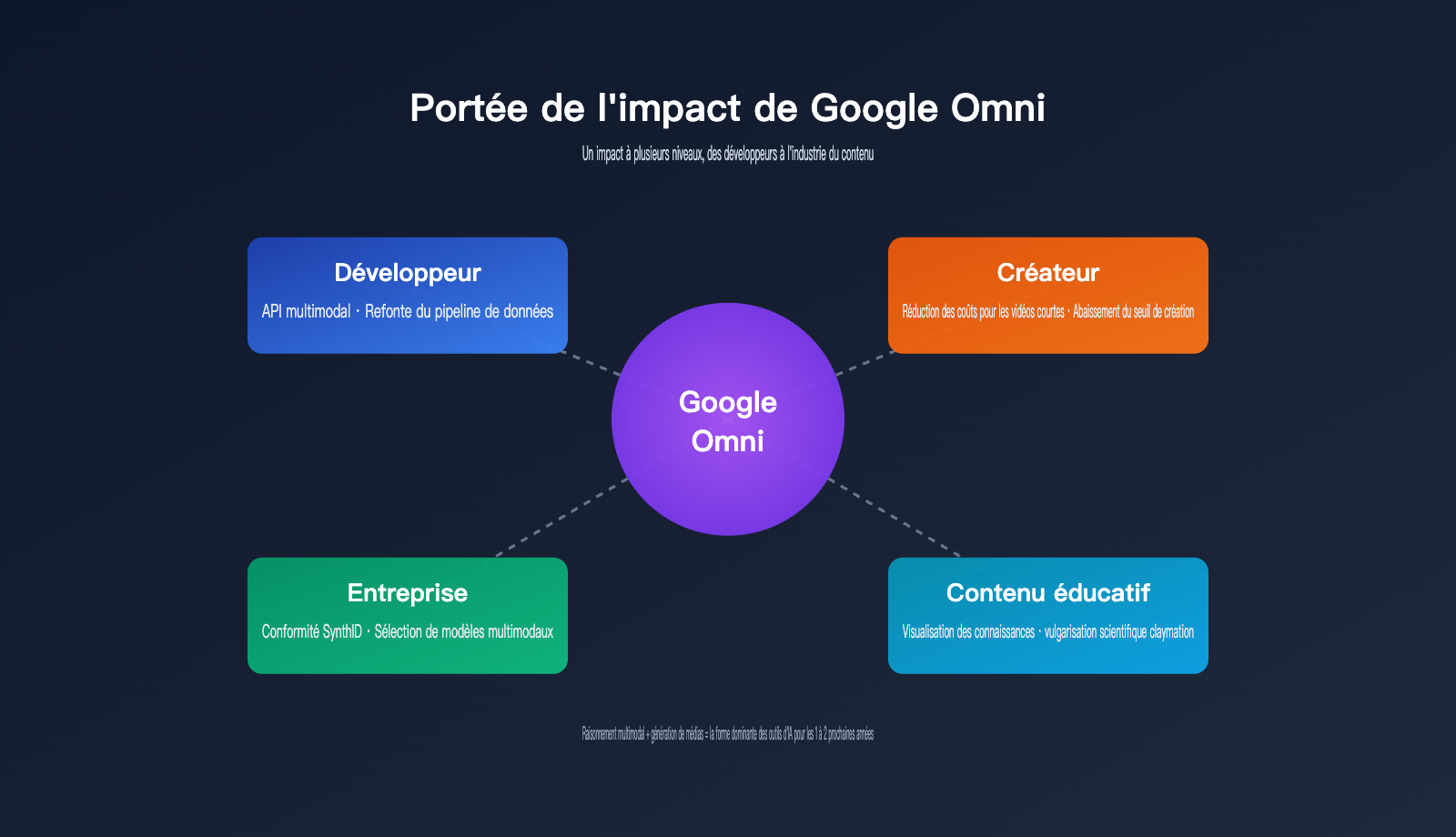
L'impact de Google Omni sur les développeurs et l'industrie
Beaucoup se demandent : qu'est-ce que ce nouveau modèle change pour moi ? La réponse varie selon que vous soyez développeur, créateur ou entreprise.
Impact sur les développeurs
| Direction de l'impact | Manifestation concrète |
|---|---|
| Méthode d'invocation | La conception d'invites multimodales remplace les pipelines "texte vers image puis image vers vidéo" |
| Chaîne d'outils | Le SDK doit s'adapter aux "flux d'entrée vidéo/audio" plutôt qu'au texte pur |
| Conformité du contenu | Le filigrane SynthID devient la norme, nécessite une planification pour la détection et l'affichage |
| Structure des coûts | Le coût de génération unitaire peut être plus élevé que l'invocation textuelle, nécessite une gestion fine |
Pour les ingénieurs qui construisent des applications IA, Omni envoie un signal clair : les interfaces IA de demain ne seront plus "entrée texte, sortie texte", mais "entrée multimodale, sortie multimodale". Reconstruire vos pipelines de données dès maintenant et gérer vos ressources par modalité vous donnera un avantage compétitif lors du lancement de l'API Omni.
Impact sur l'industrie du contenu
Les plateformes de vidéos courtes, les agences de publicité et les producteurs de contenu éducatif seront les premiers bénéficiaires. Une vidéo de haute qualité de 10 secondes, qui nécessitait auparavant des heures de montage, peut désormais être produite en quelques minutes par Omni Flash. Pour les créateurs, le seuil de passage "d'une image à une vidéo finale" est considérablement abaissé.
Attention toutefois : l'intégration forcée du filigrane SynthID signifie que la nature "générée par IA" sera de plus en plus transparente. Les plateformes, les marques et les régulateurs pourraient ajuster leurs politiques de modération et d'étiquetage en fonction de ce filigrane.
Impact sur les entreprises
Les entreprises se concentrent sur deux points : la conformité/sécurité de la marque, et le coût à grande échelle. Le filigrane SynthID résout une partie du premier problème, tandis que le second dépendra de la tarification API que Google annoncera. Pour les équipes sensibles au budget, la stratégie la plus prudente consiste à utiliser des plateformes d'agrégation comme APIYI (apiyi.com) pour évaluer simultanément les capacités vidéo ou multimodales de plusieurs fournisseurs (Gemini, GPT, Claude), puis de choisir en fonction du rapport coût/qualité.
Foire aux questions (FAQ)
Q1 : Google Omni et Gemini Omni sont-ils la même chose ?
Oui. Google Omni est une abréviation non officielle ; le nom complet utilisé par Google est « Gemini Omni », qui appartient à la branche multimodale de la famille de modèles Gemini. Gemini Omni Flash est le premier modèle de cette famille. Les deux noms désignent la même technologie.
Q2 : Les nouveaux utilisateurs peuvent-ils tester Gemini Omni gratuitement dès maintenant ?
Oui. Le moyen le plus direct est d'utiliser la fonctionnalité de génération vidéo Omni dans YouTube Shorts ou l'application YouTube Create, actuellement ouverte gratuitement aux créateurs. Si vous souhaitez l'utiliser dans l'application Gemini, vous aurez besoin d'un abonnement Google AI Plus, Pro ou Ultra.
Q3 : Pourquoi les vidéos générées par Gemini Omni sont-elles limitées à 10 secondes ?
Il s'agit d'une limitation liée à la phase de déploiement, et non d'une limite technique du modèle lui-même. L'explication officielle est la suivante : « En période de forte demande de puissance de calcul, nous privilégions l'accès au plus grand nombre d'utilisateurs ». Les futurs modèles, comme Omni Pro, permettront progressivement d'allonger la durée des vidéos.
Q4 : Le filigrane SynthID affecte-t-il la qualité vidéo ou l’usage commercial ?
Non. SynthID est un filigrane invisible, imperceptible à l'œil nu, qui n'altère pas la qualité de l'image. Son rôle est de permettre aux plateformes et aux outils d'identifier que « cette vidéo a été générée par une IA » lors de sa diffusion. L'utilisation commerciale doit respecter les conditions d'utilisation de Google.
Q5 : Que doivent préparer les développeurs dès maintenant ?
Premièrement, familiarisez-vous avec la logique de conception des invites multimodales, plutôt que de vous limiter aux invites textuelles. Deuxièmement, organisez votre bibliothèque de ressources en les classant par modalité. Troisièmement, testez dès maintenant vos flux d'invocation du modèle. Nous vous recommandons d'utiliser APIYI (apiyi.com) pour appeler les modèles de la série Gemini via une interface unifiée, afin de basculer en toute transparence dès que l'API Omni sera officiellement lancée.
Q6 : Gemini Omni va-t-il remplacer Veo ?
À court terme, non. Veo reste la référence pour la génération vidéo spécialisée de haute qualité, tandis qu'Omni représente une approche unifiée combinant « raisonnement multimodal et génération de médias ». Il est plus probable que les deux coexistent selon les cas d'usage.
En résumé : trois points clés pour les débutants
Premièrement, l'essence de Gemini Omni réside dans son modèle unifié de « raisonnement transmodal et génération de médias », et non dans une simple « énième IA vidéo ». Sa capacité différenciatrice se manifeste dans la compréhension physique, l'édition conversationnelle et le raisonnement multimodal.
Deuxièmement, le chemin le plus rapide pour tester l'outil est l'accès gratuit via YouTube Shorts ou l'application YouTube Create, suivi des options d'abonnement dans l'application Gemini. L'API pour les développeurs sera lancée « dans les prochaines semaines », vous pouvez donc commencer à planifier votre architecture.
Troisièmement, Omni ne remplacera pas immédiatement vos outils habituels, mais il représente la forme dominante de l'IA multimodale pour les 1 à 2 prochaines années. Comprendre dès maintenant ses méthodes d'entrée/sortie, les exigences de conformité liées à SynthID et la différence de positionnement avec Veo vous évitera bien des détours lors de la prochaine mise à jour de vos outils IA. Si vous souhaitez invoquer Gemini, GPT, Claude et d'autres modèles majeurs via une interface unique, APIYI (apiyi.com) est la solution la plus simple, vous permettant d'intégrer Gemini Omni dès son ouverture officielle.
Références
-
Blog officiel de Google – Annonce de Gemini Omni
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - Description : Présentation officielle faisant autorité sur le positionnement et les capacités de Gemini Omni par Google.
- Lien :
-
TechCrunch – Rapport approfondi sur Gemini Omni
- Lien :
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - Description : Analyse citant les déclarations clés de Sundar Pichai et Nicole Brichtova.
- Lien :
-
9to5Google – Retour d'expérience sur Gemini Omni Flash
- Lien :
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - Description : Inclut une description des démonstrations officielles et des informations sur la disponibilité des canaux d'accès.
- Lien :
Équipe APIYI | Pour suivre davantage d'actualités sur les grands modèles de langage et consulter nos guides pratiques, rendez-vous sur APIYI (apiyi.com). Profitez de crédits de test gratuits pour expérimenter une interface unifiée regroupant plusieurs modèles majeurs, dont la série Gemini.