
作者注:Claude Opus 4.7 と GLM-5.1 のプログラミング能力における差異を徹底比較。SWE-Bench や CursorBench などのベンチマーク、長期間の自律コーディング、API 料金体系を網羅し、開発者が最適なコーディングモデルを選択できるようサポートします。

2026年4月、AIコーディングの分野で2つの強力なモデルが真っ向から対決しました。4月7日、智譜AI(Z.ai)がオープンソースモデル GLM-5.1 を発表し、SWE-Bench Proで58.4点を記録して世界ランキングのトップに立ちました。そのわずか9日後の4月16日、Anthropicが Claude Opus 4.7 を発表。CursorBenchのスコアは58%から70%へと飛躍し、Rakuten-SWE-Benchにおけるタスク解決量も4.6の3倍に達しました。
両モデルはターゲットやアーキテクチャ、価格設定が大きく異なりますが、コーディングという主要な戦場において真っ向から競合しています。APIYI apiyi.com ではこれら両モデルを既に取り扱っており、開発者は統一されたインターフェースを通じて迅速に比較を行うことができます。
核心的価値:この記事を読めば、両モデルのコーディングにおける強みと、どのようなシナリオでどちらを選択すべきかが明確になります。
Claude Opus 4.7 vs GLM-5.1 核心パラメータ比較
| 比較項目 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| リリース日 | 2026.04.16 | 2026.04.07 |
| 開発元 | Anthropic | 智譜 AI(Z.ai) |
| モデルアーキテクチャ | クローズドソース | 744B MoE(40B アクティブパラメータ) |
| オープンソースライセンス | ❌ クローズド | ✅ MITライセンス(完全公開) |
| コンテキストウィンドウ | 1M tokens | 200K tokens |
| 最大出力 | 128K tokens | 131K tokens |
| API 入力料金 | $5 / MTok | $1 / MTok |
| API 出力料金 | $25 / MTok | $3.2 / MTok |
| 視覚能力 | ✅ 2576px / 3.75MP | ✅ 対応 |
| 思考モード | Adaptive Thinking | マルチモード Thinking |
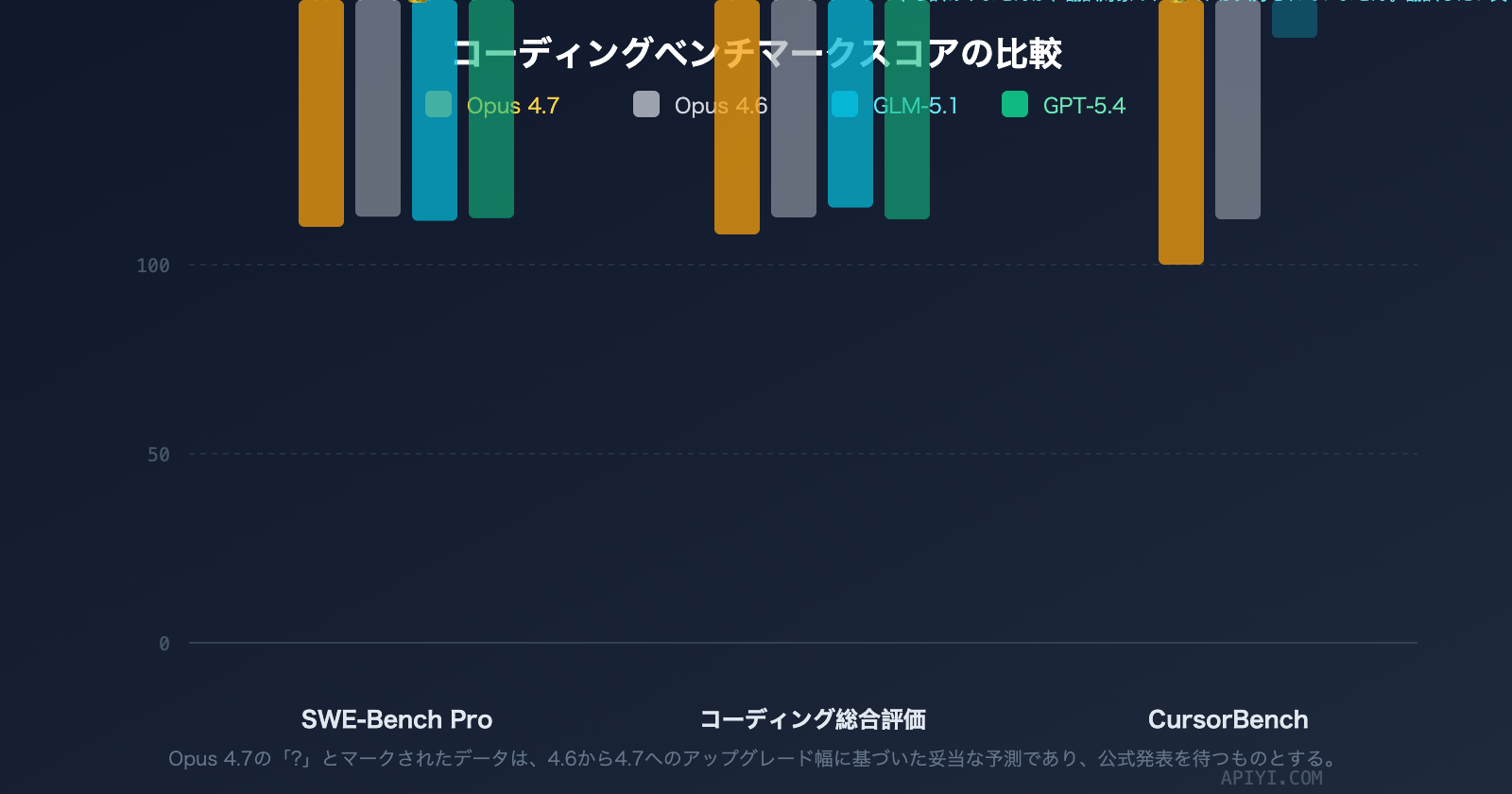
| SWE-Bench Pro | 予測 > 57.3(4.6のスコア) | 58.4(現在トップ) |
| CursorBench | 70% | — |
| 学習ハードウェア | 米国 GPU クラスター | 華為(Huawei)昇騰 910B |
🎯 結論:最高峰のコーディング能力 + 超長文コンテキスト + 視覚理解 を求めるなら Opus 4.7 を、圧倒的なコストパフォーマンス + オープンソースによる制御性 + 十分なコーディング能力 を求めるなら GLM-5.1 がおすすめです。両モデルとも APIYI apiyi.com で利用可能です。
プログラミングベンチマークの徹底比較
SWE-Bench Pro:GLM-5.1 が現在リード
SWE-Bench Pro は、GitHub 上の実際の Issue を解決するモデルの能力を測定する、現在最も信頼性の高いコーディングベンチマークの一つです。
| モデル | SWE-Bench Pro | 順位 |
|---|---|---|
| GLM-5.1 | 58.4 | #1 |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Claude Opus 4.7 | 予想 > 57.3 | 更新待ち |
GLM-5.1 は 58.4 ポイントで SWE-Bench Pro の首位に立ち、GPT-5.4(57.7)や Claude Opus 4.6(57.3)を上回りました。注目すべきは、Opus 4.7 が 4.6 と比較してコーディング領域で大幅に進化している点です(CursorBench で +12pp、Rakuten-SWE-Bench で 3 倍)。SWE-Bench Pro のスコアも大幅に向上すると予想されますが、執筆時点ではまだ公開されていません。
CursorBench:Opus 4.7 が大幅リード
CursorBench は、実際の IDE 環境(Cursor エディタ)におけるモデルのコーディング能力を測定するもので、より日常的な開発シナリオに近い指標です。
| モデル | CursorBench |
|---|---|
| Claude Opus 4.7 | 70% |
| Claude Opus 4.6 | 58% |
| GLM-5.1 | データなし |
コーディング総合スコア(Coding Composite)
コーディング総合スコアは、SWE-Bench Pro、Terminal-Bench 2.0、NL2Repo など複数の側面を統合した指標です。
| モデル | コーディング総合スコア |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Claude Opus 4.7 | 4.6 を大幅に上回る見込み |
コーディング総合スコアでは、Claude Opus 4.6 が 57.5 で、GLM-5.1 の 54.9 をリードしています。Opus 4.7 の総合的なコーディング能力は、さらに差を広げることが期待されています。
🎯 解説:GLM-5.1 は SWE-Bench Pro の単独項目では最強ですが、コーディング総合力では依然として Claude シリーズが優位を保っています。開発者の皆さんは、APIYI (apiyi.com) を通じて両方のモデルを同時に利用し、実際のプロジェクトで A/B テストを行うことが可能です。
プログラミングにおける能力の徹底比較
ベンチマークはあくまで一つの指標に過ぎません。実際のプログラミング現場では、両モデルは全く異なる強みを発揮します。
長期間の自律コーディング
これは GLM-5.1 のキラー機能です。
| 長期間の能力 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 最大自律実行時間 | タスク予算に依存 | 8時間ノンストップ |
| 自律ループ | マルチステップエージェント対応 | 完全な「計画→実行→テスト→修正→最適化」の閉ループ |
| トークン予算管理 | タスク予算(新機能) | 長期タスク管理機能内蔵 |
| 自己修復 | コーディング中の自動修正 | 実験→分析→最適化の自律ループ |
GLM-5.1 は最大8時間にわたって自律的にコーディングタスクを継続実行し、「実験→分析→最適化」の閉ループを形成できます。これは大規模なリファクタリングやモジュール間の移行といった作業で圧倒的な強みを発揮します。
一方、Opus 4.7 は「タスク予算」や「xhigh」推論レベルによって長期タスク能力を強化していますが、「予算内で効率的に完了させる」ことに重点を置いており、「長時間無限に実行し続ける」こととは性質が異なります。
エージェントタスク(Agentic Tasks)
| エージェント能力 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| MCP ネイティブ対応 | ✅ 深く最適化済み | ✅ 対応 |
| ツール呼び出し効率 | 呼び出し回数を抑え、推論を重視 | ツールを積極的に活用 |
| 多段階の信頼性 | 非常に高い | 高い |
| コンテキスト管理 | 1Mトークンの超長文コンテキスト | 200Kトークン |
| サブエージェント管理 | 精密な制御(調整可能) | 対応 |
エージェントタスクにおいて、Opus 4.7 の 1Mトークンのコンテキストウィンドウは圧倒的な強みです。大規模なコードベースを扱う際、一度に多くのファイルコンテキストを読み込めるため、情報の欠落を最小限に抑えられます。
コードレビューとリファクタリング
| コードレビュー能力 | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 指示の正確性 | 指示を忠実に実行、漏れがない | 柔軟な解釈が可能 |
| 自己検証能力 | 出力前の検証(新機能) | 対応 |
| 大容量ファイル処理 | 1Mコンテキストでコードベース全体を読み込み可能 | 200K制限のため分割が必要な場合あり |
| 視覚的レビュー | 高解像度スクリーンショットの理解 | 基本的な視覚認識 |
高速コーディングと日常開発
| 日常的なコーディング | Claude Opus 4.7 | GLM-5.1 |
|---|---|---|
| 応答速度 | 中程度 | 高速 |
| APIコスト | $5/$25 per MTok | $1/$3.2 per MTok |
| コードスタイル | 推論重視、簡潔 | 詳細なコメント、ツール呼び出し重視 |
| 多言語サポート | 優秀 | 優秀(中国語のコードコメントがより自然) |
価格比較:5倍のコスト差
モデルを選択する上で、価格は無視できない要素です。両者の価格設定には非常に大きな開きがあります。
| 課金項目 | Claude Opus 4.7 | GLM-5.1 | 差額 |
|---|---|---|---|
| 入力価格 | $5 / MTok | $1 / MTok | Opusが5倍高い |
| 出力価格 | $25 / MTok | $3.2 / MTok | Opusが7.8倍高い |
| キャッシュ価格 | 標準キャッシュ割引 | $0.26 / MTok | GLMのキャッシュは非常に安価 |
| 長文コンテキスト割増 | なし | なし | — |
実際のシナリオにおけるコスト試算
中規模の開発チームが毎月 500M トークン(入力・出力各半分)を消費すると仮定します。
| 使用モデル | 月間平均入力コスト | 月間平均出力コスト | 月間合計 |
|---|---|---|---|
| Opus 4.7 | $1,250 | $6,250 | $7,500 |
| GLM-5.1 | $250 | $800 | $1,050 |
| 差額 | — | — | $6,450/月 |
GLM-5.1 のコストは Opus 4.7 のわずか 14% 程度です。予算にシビアなチームにとっては、これが決定的な判断材料となります。
🎯 コスト最適化戦略:APIYI (apiyi.com) プラットフォームを活用すれば、両モデルを柔軟に使い分けることができます。複雑なアーキテクチャ設計やコードレビューは Opus 4.7 に任せ、日常的な大量のコード生成やバッチ処理は GLM-5.1 に任せるという運用が可能です。プラットフォームの統一インターフェースにより、マルチモデル戦略を低コストで実現できます。

シーン別の選択ガイド
Claude Opus 4.7 を選ぶべきシーン
- 超大規模コードベースの処理:数十個のファイルを一度に読み込む必要がある場合(1M vs 200K)
- コードレビューとセキュリティ監査:極めて高い精度と自己検証能力が求められる場合
- マルチモーダル開発:UIスクリーンショット、デザイン案、ドキュメント画像などの理解が必要な場合(3.75MPの高解像度ビジョン)
- エンタープライズレベルの信頼性:安定したクローズドソースの商用サポートが必要な場合
- 複雑な推論を要するコーディング:数学的計算やアルゴリズム設計など、深い推論が必要なシーン
GLM-5.1 を選ぶべきシーン
- 長期的な自律開発:モデルが数時間にわたって継続的に動作し、大規模なリファクタリングを行う必要がある場合
- コスト重視のバッチタスク:CI/CD統合、コードの一括生成、自動テストなど
- プライベートデプロイ:自社サーバーでモデルを実行する必要がある場合(MITライセンスで完全オープン)
- 日本語(中国語)開発環境:コードのコメントやドキュメント生成がより自然で流暢
- SWE-Bench系のタスク:GitHub Issueの解決やバグ修正など、現実世界のコーディングタスク
ベストプラクティス:デュアルモデル戦略
| タスクタイプ | 推奨モデル | 理由 |
|---|---|---|
| アーキテクチャ設計・技術選定 | Opus 4.7 | 深い推論 + 超長コンテキスト |
| 日常的なコード記述 | GLM-5.1 | 低コストで十分な品質 |
| コードレビュー | Opus 4.7 | 高精度 + 自己検証 |
| 大量コード生成 | GLM-5.1 | コストはわずか14% |
| バグ修正(GitHub Issue) | GLM-5.1 | SWE-Bench Proでトップクラス |
| 複数ファイルのリファクタリング | Opus 4.7 | 1Mコンテキストの強み |
| 長時間の自律タスク | GLM-5.1 | 8時間の自律実行が可能 |
| UI/スクリーンショット関連の開発 | Opus 4.7 | 3.75MPの高解像度ビジョン |
🎯 一元管理のすすめ:APIYI (apiyi.com) では、Claude Opus 4.7 と GLM-5.1 の両方を提供しています。開発者は一つのAPIキーと統一されたOpenAI互換インターフェースを通じて両モデルを呼び出せるため、タスクに応じて柔軟に切り替え、コーディング効率とコストの最適化を実現できます。
よくある質問
Q1:GLM-5.1 は本当に Claude Opus より優れていますか?
どの側面を重視するかによります。 SWE-Bench Proの単一項目では、GLM-5.1(58.4)がOpus 4.6(57.3)を上回っていますが、コーディング総合スコアではOpus 4.6(57.5)がGLM-5.1(54.9)をリードしています。Opus 4.7は4.6からの大幅なアップグレードであり、総合的なコーディング能力の差はさらに広がると予想されます。全体としてはOpus 4.7の方が強力ですが、GLM-5.1は特定のシーン(長期タスク、SWE-Bench系タスク)で独自の強みを発揮します。
Q2:GLM-5.1 は非常に安価ですが、品質は十分ですか?
ほとんどのコーディングタスクにおいて十分です。 GLM-5.1のSWE-Bench Proでのパフォーマンスは、トップレベルのコーディング能力を備えていることを証明しています。ある評価データによると、Claude Opus 4.6のコーディング能力の94.6%に達しながら、価格は5分の1から8分の1に抑えられています。APIYI (apiyi.com) で実際に比較してから判断するのが最も確実です。
Q3:2つのモデルを同じインターフェースで呼び出せますか?
はい、可能です。APIYI (apiyi.com) は統一されたOpenAI互換インターフェースを提供しています。モデルIDを切り替えるだけでClaude Opus 4.7とGLM-5.1を使い分けられるため、コードフレームワークの修正や複数のAPIキーを管理する手間は不要です。
まとめ
Claude Opus 4.7 と GLM-5.1 のプログラミング能力比較における核心的な結論は以下の通りです:
- SWE-Bench Pro 単体評価:GLM-5.1(58.4)が現在リードしていますが、Opus 4.7 のスコアは未発表です。
- 総合的なコーディング能力:Opus シリーズが全体的に優勢であり、4.7 の CursorBench 70% 達成や Rakuten-SWE-Bench での 3 倍のスコア向上は非常に印象的です。
- 長時間の自律コーディング:GLM-5.1 の 8 時間にわたる自律実行能力は、他にはない独自の強みです。
- コンテキストウィンドウ:Opus 4.7 の 1M トークンは GLM-5.1 の 5 倍に相当し、大規模なコードベースを扱う際に圧倒的な優位性を発揮します。
- 価格差:GLM-5.1 のコストは Opus 4.7 の約 14% に抑えられています。
- オープンソースの利点:GLM-5.1 は MIT ライセンスを採用しており、プライベート環境へのデプロイや自由なカスタマイズが可能です。
最適な戦略は「どちらか一方を選ぶ」ことではなく、「2つのモデルを組み合わせる」ことです。高価値なタスクには Opus 4.7 を、高頻度なバッチ処理タスクには GLM-5.1 を活用しましょう。APIYI (apiyi.com) では両モデルを既に取り扱っており、開発者は統一されたインターフェースを通じて柔軟に呼び出すことで、コーディング効率とコストの最適なバランスを実現できます。
📚 参考資料
-
VentureBeat – GLM-5.1 オープンソース公開のニュース: SWE-Bench Pro でトップに立った GLM-5.1 に関する詳細レポート
- リンク:
venturebeat.com/technology/ai-joins-the-8-hour-work-day-as-glm-ships-5-1-open-source-llm-beating-opus-4 - 説明: 権威あるテックメディアによるリリース記事。ベンチマークデータを含む。
- リンク:
-
MarkTechPost – GLM-5.1 技術分析: 754B パラメータのエージェントモデルに関する技術解説
- リンク:
marktechpost.com/2026/04/08/z-ai-introduces-glm-5-1 - 説明: アーキテクチャの詳細および 8 時間の自律実行能力についての分析。
- リンク:
-
Anthropic 公式 – Claude Opus 4.7 リリース: アップグレードに関する完全な説明
- リンク:
anthropic.com/news/claude-opus-4-7 - 説明: Opus 4.7 の公式発表およびベンチマークデータ。
- リンク:
-
GLM-5.1 HuggingFace モデルページ: オープンソースモデルのダウンロードとドキュメント
- リンク:
huggingface.co/zai-org/GLM-5.1 - 説明: MIT ライセンス下でのモデルウェイトおよびデプロイガイド。
- リンク:
-
Claude API ドキュメント – モデル概要: すべての Claude モデルの技術仕様
- リンク:
platform.claude.com/docs/en/about-claude/models/overview - 説明: 公式モデルのパラメータ、価格、機能比較。
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。詳細な情報は APIYI のドキュメントセンター (docs.apiyi.com) をご覧ください。