
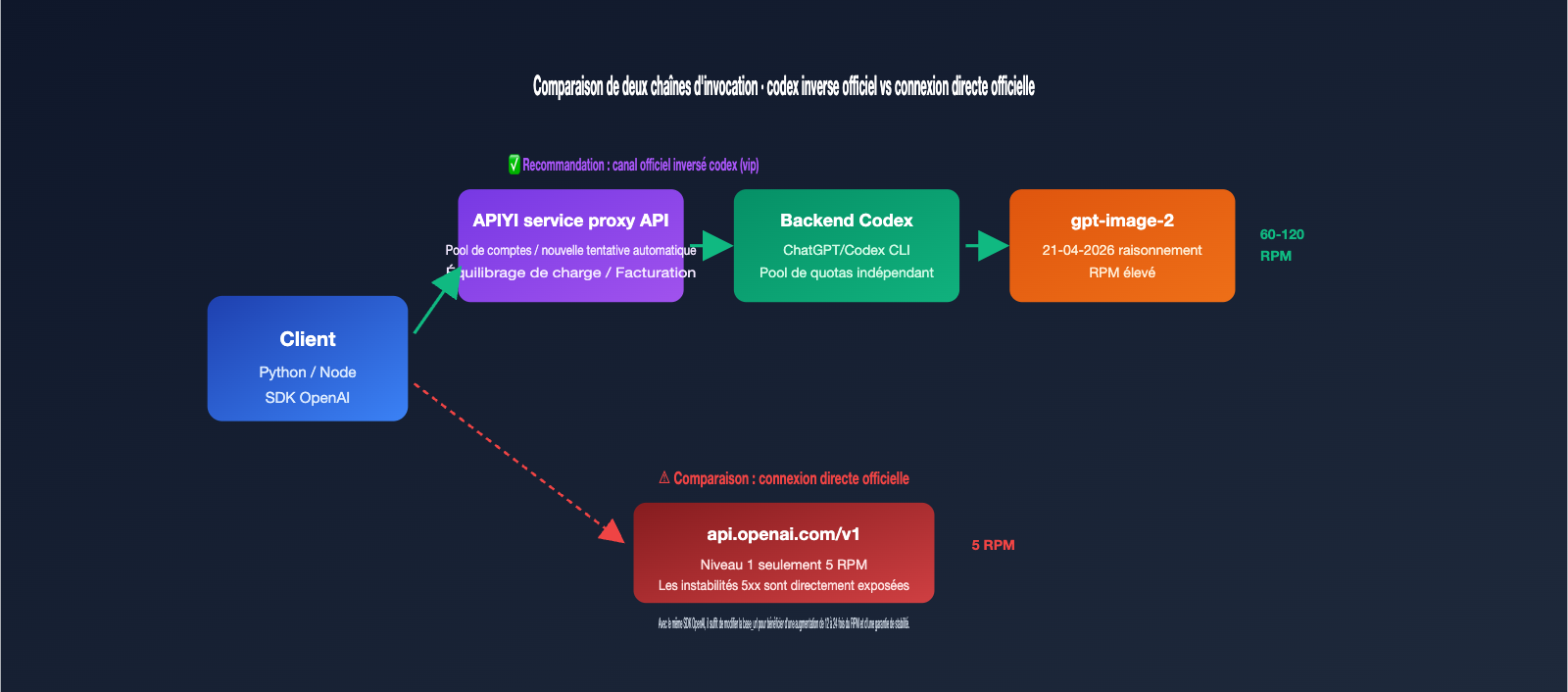
Si vous venez d'intégrer gpt-image-2 dans votre environnement de production, vous avez probablement été confronté à deux obstacles majeurs : les limites de débit et la stabilité. Les limites imposées par OpenAI pour un accès direct à gpt-image-2 sont extrêmement strictes : les comptes Tier 1 sont limités à 5 requêtes par minute, ce qui déclenche rapidement des erreurs 429 dès que vous lancez des traitements par lots. De plus, les instabilités de type 5xx peuvent entraîner plusieurs échecs consécutifs. C'est pourquoi de nombreuses équipes se tournent vers des "canaux inversés officiels" — en exploitant le backend gpt-image-2 intégré à ChatGPT Pro/Codex CLI pour bénéficier de quotas RPM plus élevés et d'une connexion plus robuste.
Le modèle gpt-image-2-vip disponible sur APIYI (apiyi.com) utilise précisément cette voie d'accès inversée. Cet article détaille les 5 caractéristiques clés, les 30 options de dimensions, les 3 points de terminaison compatibles et le code pratique pour maîtriser cette interface et l'intégrer directement en production.
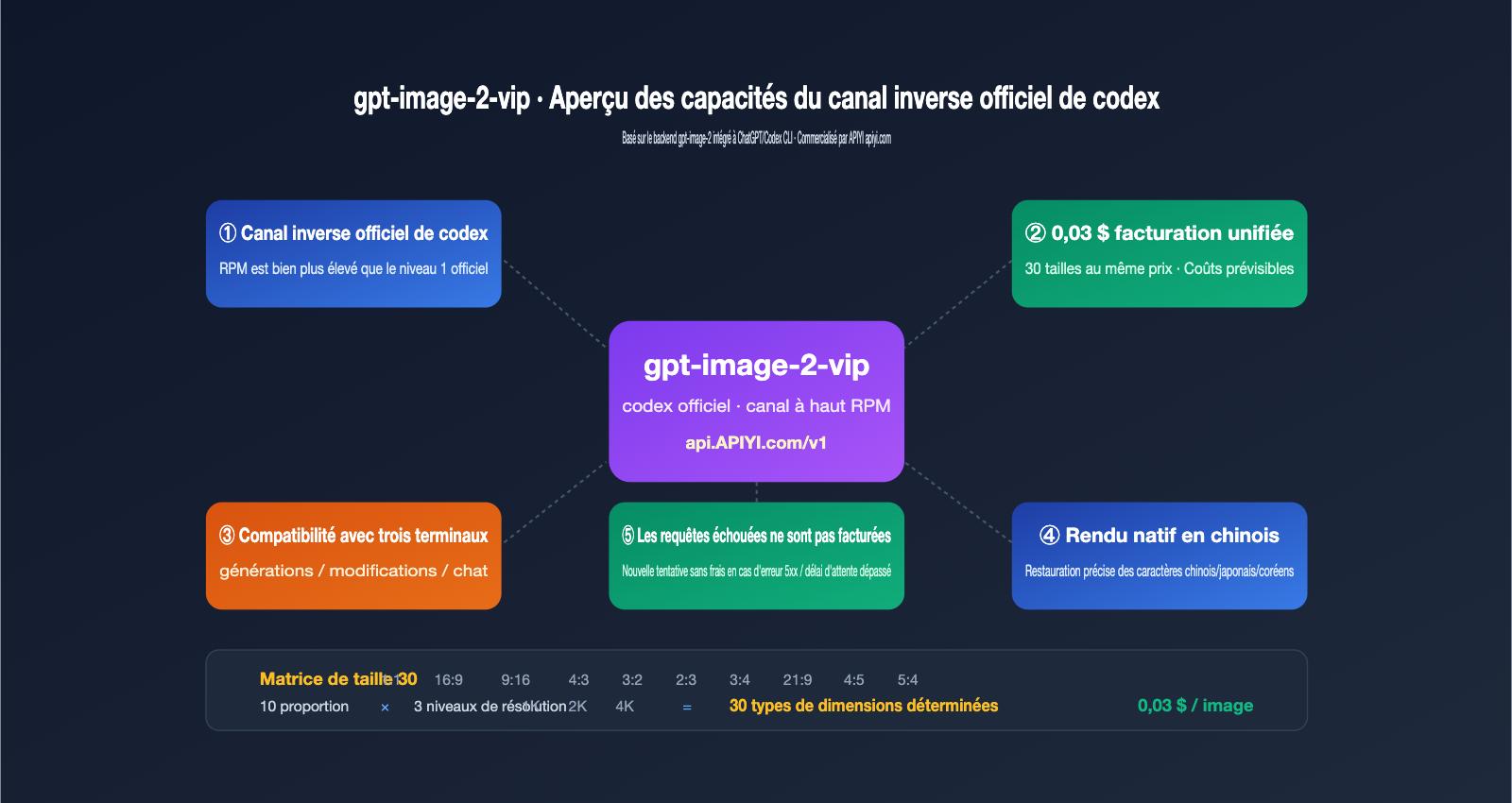
Qu'est-ce que l'API "Codex官逆" : 3 différences fondamentales avec la connexion officielle
Beaucoup de développeurs pensent, en entendant parler de "Codex官逆" (inversion officielle Codex), qu'il s'agit d'une interface illégale. En réalité, ce terme désigne l'ingénierie inverse de la chaîne d'appel gpt-image-2 intégrée nativement dans le CLI Codex et ChatGPT Pro d'OpenAI. Lorsque OpenAI a lancé gpt-image-2 en avril 2026, ils l'ont intégrée simultanément dans le CLI Codex (fonctionnalité $imagegen) et dans le client ChatGPT. Ces deux points d'entrée partagent un pool de quotas de débit indépendant, avec des stratégies de limitation différentes de celles de l'API publique.
Le canal "Codex官逆" consiste à exposer ce flux de données interne de Codex sous forme d'interface REST, vous permettant d'utiliser gpt-image-2 comme n'importe quelle API OpenAI classique, tout en passant par le backend de ChatGPT. Le modèle gpt-image-2-vip est une implémentation de ce type. Voici 3 différences fondamentales par rapport à la connexion officielle :
| Dimension | Connexion officielle OpenAI | Canal Codex官逆 (gpt-image-2-vip) |
|---|---|---|
| Limitation de débit | Tier 1 : 5 RPM, nécessite une recharge | Pool partagé Codex, bien supérieur au Tier 1 |
| Modèle de facturation | Basé sur la taille/qualité de l'image | Tarif unique de 0,03 $/image, 30 tailles au même prix |
| Stabilité | Impactée par les fluctuations 5xx officielles | Pool multi-comptes + réessai auto, masque les instabilités |
Paramètre quality |
Supporte low/medium/high/auto | Non supporté (utilise la stratégie interne Codex) |
Paramètre n (lot) |
Supporte 1 à 4 images | Non supporté, retourne 1 image par appel |
| Validité de l'URL | 60 minutes | ~24 heures |
🎯 À retenir : L'inversion officielle n'est pas un "piratage", c'est l'exposition de la chaîne d'appel interne d'un produit OpenAI (Codex CLI) en une interface REST. APIYI (apiyi.com) transforme ce canal en un produit commercial. Sa valeur ajoutée n'est pas de contourner OpenAI, mais de mettre à disposition des utilisateurs de l'API les quotas de débit plus stables du côté de Codex.
Les 5 caractéristiques clés de gpt-image-2-vip
Une fois les différences de canal comprises, les spécificités deviennent plus claires. Voici les 5 points qui distinguent gpt-image-2-vip des modèles gpt-image-2-all et gpt-image-2 officiel, des détails souvent éparpillés dans la documentation et qu'il est important de souligner.
Caractéristique 1 : 30 tailles verrouillables, facturation unique à 0,03 $
La plus grande valeur technique de gpt-image-2-vip est de traiter la "taille" comme un paramètre de premier ordre. Le modèle supporte 10 ratios d'aspect × 3 niveaux de résolution = 30 tailles fixes. Il suffit de les spécifier dans le paramètre size, sans avoir à manipuler inutilement l'invite. La facturation est simplifiée : les 30 tailles sont facturées uniformément à 0,03 $/image, éliminant les coûts cachés liés aux grandes dimensions. C'est un gain majeur en prédictibilité des coûts pour les équipes travaillant sur la génération de modèles ou de miniatures en masse.
| Niveau de résolution | Pixels côté court | Pixels côté long (max) | Scénarios d'usage |
|---|---|---|---|
| 1K | ~1024 | ~1820 | Miniatures, couvertures de flux, réseaux sociaux |
| 2K | ~2048 | ~3640 | Affiches, images e-commerce, cartes de contenu |
| 4K | ~2880 | ~3840 | Impression HD, ressources vidéo, supports imprimés |
Les 10 ratios couvrent les besoins courants (1:1, 16:9, 9:16, 4:3, 3:2, 21:9, etc.), évitant souvent le recadrage post-production. L'autre avantage de la tarification unique est la flexibilité : vous pouvez changer de résolution selon vos besoins métier sans impacter votre modèle financier. Par exemple, lors d'un test A/B, comparer une image 1K et 4K avec la même invite a un coût parfaitement prévisible.
Caractéristique 2 : Compatibilité totale avec les trois points de terminaison
gpt-image-2-vip supporte les trois points de terminaison d'image standards d'OpenAI : /v1/images/generations (texte vers image), /v1/images/edits (image vers image et édition), et /v1/chat/completions (génération via interface de chat). C'est crucial : vous n'avez pas besoin de réécrire votre code SDK. Il suffit de remplacer model par gpt-image-2-vip et de pointer base_url vers le service proxy API.
Caractéristique 3 : Fusion multi-images et image vers image
Via le point de terminaison /v1/images/edits, vous pouvez télécharger 1 à N images et, en combinant avec une invite descriptive, le modèle effectuera des transferts de style, de la fusion de contenu ou du réagencement de mise en page. Par exemple, fusionner une "photo de produit + photo de mannequin + image de fond" en une seule image e-commerce. Il est conseillé de compresser chaque image en dessous de 1,5 Mo pour éviter une consommation excessive de jetons d'entrée.
Caractéristique 4 : Compréhension native du chinois
gpt-image-2-vip partage le même backend d'inférence que le gpt-image-2 officiel, héritant de sa capacité de rendu de texte multilingue (chinois, japonais, coréen, hindi, bengali). Les invites en chinois n'ont pas besoin d'être traduites en anglais ; les titres et textes sur les affiches sont restitués avec précision, une prouesse que Midjourney ou Stable Diffusion ne maîtrisent pas aussi bien.
Caractéristique 5 : Pas de facturation en cas d'échec
C'est un détail financier important pour la production à grande échelle. Aucune requête retournant une erreur 5xx, un timeout ou bloquée par la politique de sécurité n'est facturée ; seuls les appels réussis sont comptabilisés. Cela vous permet de mettre en place des réessais avec backoff exponentiel sans craindre d'exploser votre facture. Avec le tarif unique de 0,03 $/image, l'estimation des coûts devient extrêmement simple : pour 10 000 images, comptez environ 300 $, sans calcul complexe par taille ou qualité.
Flux de travail et exemple de code : commencez avec 5 lignes de Python
La logique d'intégration est très directe et identique au SDK officiel d'OpenAI ; il suffit de modifier le base_url et le model. Voici un exemple minimal fonctionnel pour la génération d'images, où le base_url pointe vers le service proxy API unifié d'APIYI (apiyi.com).
from openai import OpenAI
import base64
client = OpenAI(
api_key="votre-cle-apiyi",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2-vip",
prompt="Visuel principal pour une conférence technologique sombre, titre néon central 『APIYI · gpt-image-2 est en ligne』, petit texte en bas à gauche 2026",
size="2048x1152"
)
img_b64 = resp.data[0].b64_json
with open("poster_2k.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Si vous souhaitez effectuer une opération d'image vers image ou une fusion d'images, remplacez simplement client.images.generate par client.images.edit et ajoutez image=[open("a.png","rb"), open("b.png","rb")]. Le format du corps de la requête pour les trois points de terminaison suit les spécifications officielles d'OpenAI.
🎯 Conseil pour démarrer rapidement : Pour tester ce flux en 30 secondes, nous vous recommandons de créer une clé API sur APIYI (apiyi.com), puis d'utiliser
gpt-image-2-vipavec n'importe quelle taille pour générer une image de test. Les requêtes échouées ne sont pas facturées, vous pouvez donc ajuster vos paramètres en toute sérénité.
Comment choisir parmi 30 formats : guide rapide par scénario
Face aux 30 options de taille disponibles, la première réaction est souvent de se demander laquelle choisir. Voici une classification par scénario métier. Une chose importante à retenir : toutes les tailles ont le même prix. Choisissez donc en fonction de vos besoins réels sans craindre de sacrifier la qualité pour faire des économies.
| Scénario métier | Ratio recommandé | Résolution recommandée | Taille typique |
|---|---|---|---|
| Couverture d'article / Image à la une | 16:9 / 3:2 | 2K | 2048×1152 |
| Format vertical (réseaux sociaux) | 9:16 / 4:5 | 2K | 1152×2048 |
| Image produit e-commerce | 1:1 | 2K ou 4K | 2048×2048 ou 2880×2880 |
| Image Hero de site web | 21:9 / 16:9 | 4K | 3840×1640 ou 3840×2160 |
| Illustration PPT | 16:9 | 1K ou 2K | 1820×1024 |
| Impression / Affiche | 3:4 / 2:3 | 4K | 2880×3840 |
| Miniature de flux d'actualités | 1:1 | 1K | 1024×1024 |
| Bannière horizontale | 21:9 | 1K | 1820×780 |
🎯 Conseil pour le choix de la taille : Pour un environnement de production, nous recommandons en priorité le format 2K, avec un poids d'image d'environ 1 à 3 Mo, offrant le meilleur équilibre entre vitesse de chargement et rendu visuel. Réservez le 4K uniquement pour l'impression ou les grands écrans, et utilisez le 1K pour les miniatures ou les petits formats.
Comparaison des trois canaux de la série gpt-image-2 : vip / all / officiel
APIYI (apiyi.com) propose en réalité trois modèles liés à gpt-image-2. Il est très facile de se tromper, alors voici une explication claire de leurs différences pour éviter de devoir retravailler votre intégration.
gpt-image-2 (connexion officielle directe) utilise l'API publique d'OpenAI, prend en charge les paramètres quality et n, mais vous oblige à gérer vous-même la limite de débit réduite de 5 RPM. gpt-image-2-all est un canal agrégé qui prend en charge tous les paramètres, mais le contrôle des dimensions repose sur l'invite (prompt) et manque de précision. gpt-image-2-vip est la star de cet article : il utilise l'ingénierie inverse officielle (codex) et ses points forts sont le verrouillage précis de la size + une tarification unifiée + un RPM élevé.
| ID du modèle | Type de canal | Débit | Contrôle de la taille | Paramètre quality | Nombre d'images | Scénarios recommandés |
|---|---|---|---|---|---|---|
gpt-image-2 |
Connexion directe | Limite Tier | Taille précise | ✅ | 1-4 | Sensible à la qualité, appels basse fréquence |
gpt-image-2-all |
Canal agrégé | Moyen | Via description prompt | ✅ | 1-4 | Migration de code, besoin du paramètre quality |
gpt-image-2-vip |
Inversion officielle | RPM élevé | Taille précise | ❌ | 1 | Production de masse, taille fixe, priorité stabilité |

Décision simple : Si vous avez besoin d'une production de masse stable, de dimensions fixes et d'une facturation prévisible, choisissez gpt-image-2-vip ; si vous devez absolument utiliser quality=high pour une haute fidélité, choisissez gpt-image-2-all ; ne considérez gpt-image-2 que si vous avez peu d'appels et que vous avez besoin de l'ensemble complet des paramètres.
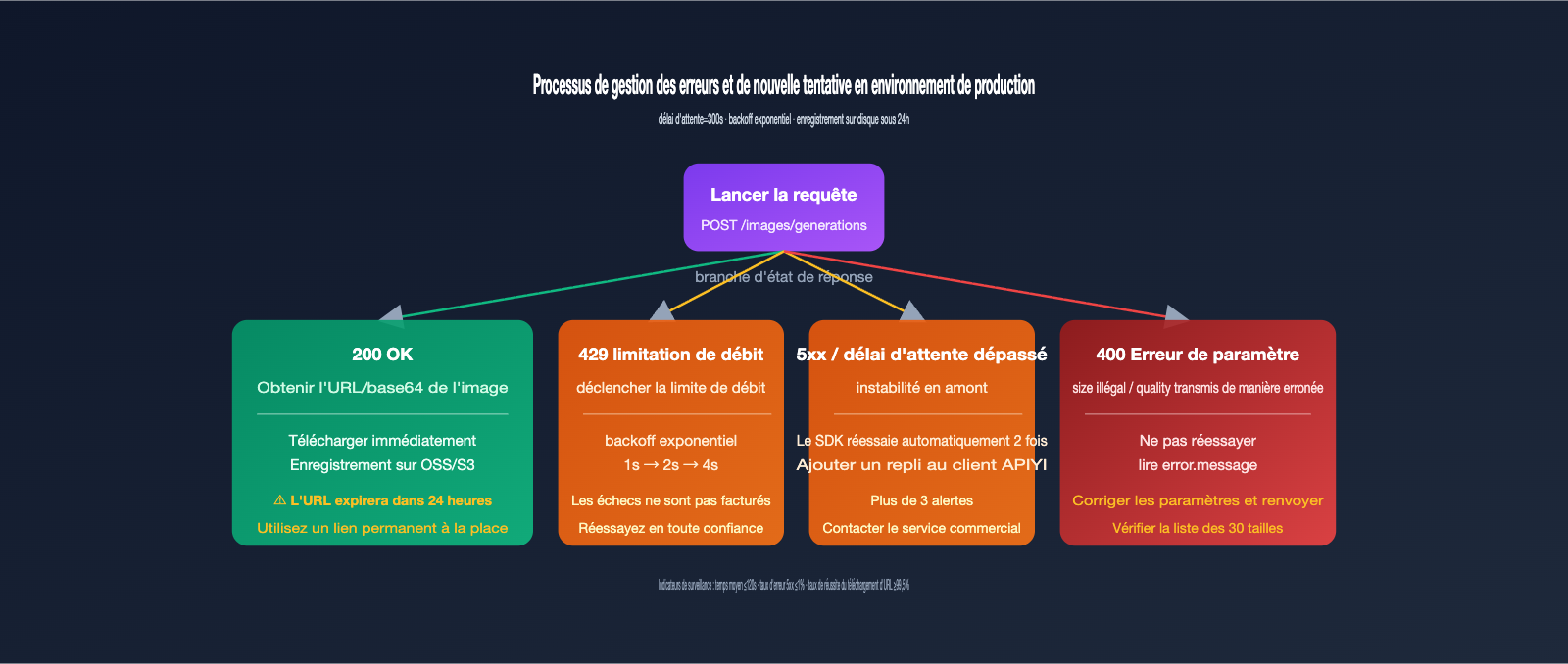
Meilleures pratiques pour la stabilité : timeouts, tentatives et validité des URL
Le débit de gpt-image-2-vip est plus élevé que celui de l'officiel, mais le temps de génération est plus long : l'inférence officielle prend environ 30 à 60 secondes, tandis que le canal VIP, en raison d'une couche de proxy et de tentatives supplémentaires, prend généralement entre 90 et 150 secondes. Votre code de production doit être configuré en fonction de cette durée, sinon vous subirez de nombreux échecs par timeout.
Pratique 1 : Réglez le timeout sur 300 secondes
Le timeout par défaut du SDK OpenAI est de 60 secondes, ce qui est largement insuffisant pour gpt-image-2-vip. Je vous suggère de transmettre explicitement timeout=300 au client. De très rares invites complexes peuvent approcher les 200 secondes, donc une marge de 300 secondes est plus sûre.
client = OpenAI(
api_key="votre-clé-apiyi",
base_url="https://api.apiyi.com/v1",
timeout=300,
max_retries=2
)
Pratique 2 : Utilisez une stratégie de backoff exponentiel pour les erreurs 5xx
Bien que la couche de proxy gère déjà une tentative, ajouter une couche de backoff exponentiel côté client (1s → 2s → 4s) peut encore améliorer le taux de réussite. Les requêtes échouées ne sont pas facturées, ce qui rend les tentatives sans coût supplémentaire.
Pratique 3 : Téléchargez l'URL renvoyée dans les 24 heures
L'URL de l'image renvoyée par gpt-image-2-vip est valide pendant environ 24 heures, après quoi elle renverra une erreur 404. Par conséquent, une fois l'URL obtenue, téléchargez-la immédiatement vers votre propre stockage OSS/S3 ; ne stockez pas directement cette URL dans votre base de données pour une référence à long terme. Pour les tâches par lots, il est conseillé de terminer le téléchargement dans les 5 minutes suivant la génération.
Pratique 4 : Compressez l'image d'entrée en dessous de 1,5 Mo
L'entrée de l'interface /v1/images/edits traite l'image avec une haute fidélité, et les jetons (tokens) d'entrée sont directement liés au nombre de pixels de l'image. La consommation de jetons entre une image de référence 4K et une image 1024px peut varier d'un facteur 4. Redimensionnez l'image côté client sur le côté le plus long entre 1024 et 2048 pixels avant l'envoi, cela permet d'économiser de l'argent et d'accélérer l'inférence.
Pratique 5 : Ne bloquez pas avec des appels synchrones, utilisez des files d'attente asynchrones
Étant donné qu'une génération prend entre 90 et 150 secondes, n'utilisez surtout pas de boucles synchrones pour des appels séquentiels, sinon 100 images prendraient deux à trois heures. L'approche recommandée consiste à envoyer les requêtes de génération dans une file d'attente de tâches asynchrones (Celery/asyncio). Le thread métier renvoie immédiatement un ID de tâche, et le front-end récupère le résultat final via polling ou WebSocket. Cela permet d'exploiter pleinement le débit de 60 RPM et de tirer parti de la haute concurrence du canal VIP.
Trois scénarios d'intégration concrets
Maintenant que nous avons abordé la théorie, voyons comment utiliser gpt-image-2-vip dans des cas d'usage réels. Les trois scénarios suivants sont les plus fréquemment abordés dans nos groupes de support, et les structures de code sont très légères.
Scénario 1 : Génération en masse d'images de produits e-commerce
Entrée : une image de produit sur fond blanc + un texte descriptif. Sortie : 30 images de produits avec des styles différents. Le processus utilise un modèle d'invite fixe, en remplaçant simplement l'espace réservé "style", et en exécutant par lots 30 fois /v1/images/edits. La taille de chaque image est fixée à 2048x2048 (format standard pour l'e-commerce). Le coût pour 30 images est de 0,9 $, pour une durée totale d'environ 2 minutes (60 RPM en concurrence).
Scénario 2 : Localisation d'affiches multilingues
Entrée : une affiche de base en anglais + le texte dans la langue cible. Sortie : trois versions de l'affiche (chinois, japonais, coréen). En tirant parti des capacités de rendu de texte multilingue de gpt-image-2-vip, l'invite indique simplement : "Change le titre en 'Nouveauté', utilise la police Source Han Sans, et garde la mise en page originale". Une seule invocation suffit pour obtenir la version localisée, sans passer par une édition PSD.
Scénario 3 : Pipeline d'illustrations pour diapositives PPT
Entrée : descriptions de chapitres générées par un LLM. Sortie : une illustration par page. C'est le cœur des outils de "PPT en un clic" populaires sur TikTok. Toutes les illustrations sont uniformisées au format 1820x1024 (ratio standard 16:9 pour PPT), avec une qualité verrouillée sur le niveau supérieur via le canal VIP. Le coût par page est de 0,03 $, soit seulement 0,6 $ pour les illustrations d'une présentation de 20 pages. En ajoutant le coût du texte généré par le LLM, une présentation complète coûte moins de 1 $.
La structure technique commune à ces trois scénarios est la suivante : l'ordonnancement est géré par une file d'attente de tâches en externe, l'invocation du modèle gpt-image-2-vip se fait en interne, et une fois l'image générée, elle est immédiatement enregistrée sur OSS. Le front-end utilise les liens permanents de l'OSS, plutôt que les URL temporaires de 24 heures renvoyées par le modèle.
Erreurs courantes et dépannage
Le tableau ci-dessous répertorie les types d'erreurs les plus fréquemment signalés dans notre groupe de support. Une simple vérification vous permettra de résoudre 90 % des problèmes d'intégration.
| Symptôme d'erreur | Cause racine | Solution |
|---|---|---|
| 408 / 504 Timeout | Timeout trop court | Augmentez le timeout à 300 secondes |
| 400 invalid size | Taille non conforme | Utilisez les tailles standard listées dans la documentation |
| 400 unsupported_parameter | Paramètre quality ou n>1 utilisé |
Le canal VIP ne les supporte pas, supprimez ces champs |
| URL d'image 404 | URL expirée après 24h | Téléchargez l'image sur votre propre stockage immédiatement après génération |
| Texte chinois illisible ou carrés | Caractères rares dans l'invite | Utilisez des caractères courants ou précisez dans l'invite "utiliser la police Source Han Sans" |
| input_tokens trop élevés | Image de référence trop lourde | Compressez l'image côté client en dessous de 1,5 Mo |
FAQ – Questions fréquentes
Q1 : La qualité d'image de gpt-image-2-vip diffère-t-elle de l'officielle ?
Le modèle sous-jacent est strictement identique, il s'agit du snapshot gpt-image-2-2026-04-21. La seule différence réside dans la chaîne de routage : l'officiel utilise le pool de quotas API, tandis que le VIP utilise le pool de quotas Codex. Il n'y a aucune différence de qualité visuelle ; lors de tests en aveugle, il est impossible de les distinguer.
Q2 : Pourquoi le paramètre quality n'est-il pas supporté ?
L'appel interne via Codex CLI utilise une stratégie fixe quality=high. Le canal VIP réutilise ce chemin, il n'est donc pas possible d'exposer l'option quality à l'utilisateur. Si votre activité nécessite des options "low" ou "medium" pour réduire les coûts, utilisez plutôt gpt-image-2-all.
Q3 : Les requêtes échouées sont-elles vraiment gratuites ?
Oui, la politique de facturation d'APIYI (apiyi.com) est basée sur le "paiement à la réponse réussie". Les erreurs de paramètres 4xx, les erreurs de service 5xx et les timeouts ne sont pas comptabilisés. Vous pouvez vérifier cela point par point dans votre facture.
Q4 : Est-il possible d'appeler l'API directement depuis des serveurs en Chine ?
Oui. Le domaine api.apiyi.com utilise un routage conforme aux réglementations locales, sans avoir besoin de VPN. C'est d'ailleurs l'une des raisons principales pour lesquelles de nombreuses équipes choisissent notre service proxy API.
Q5 : Quel est le plafond de RPM pour le canal VIP ?
Il n'y a pas de limite stricte publique, cela dépend du niveau de charge du pool de comptes. En général, les tests montrent une stabilité entre 60 et 120 RPM, ce qui est bien supérieur aux 5 RPM du Tier 1 officiel. Pour des besoins de concurrence plus élevés, veuillez contacter notre équipe commerciale pour une mise sur liste blanche.
Q6 : L'API ne renvoie qu'une image à la fois, comment gérer le traitement par lots ?
Il suffit d'utiliser des appels concurrents côté client. Avec asyncio.gather en Python ou concurrent.futures.ThreadPoolExecutor, vous pouvez facilement atteindre 60 RPM. Comme le canal VIP effectue l'inférence de manière asynchrone, la soumission concurrente n'est pas limitée par le CPU, le goulot d'étranglement se situe uniquement au niveau du RPM du service proxy API.
Q7 : Le résultat est-il identique si j'utilise la même invite plusieurs fois ?
Non, ce ne sera pas strictement identique. gpt-image-2-vip utilise la stratégie interne de Codex et n'expose pas le paramètre seed, il y a donc une part d'aléatoire à chaque génération. Si vous avez besoin de résultats reproductibles, soyez très précis dans votre invite (ex: codes couleur fixes, description détaillée de la composition) ou utilisez l'image qui vous satisfait comme image de référence via le point de terminaison /v1/images/edits pour un ajustement fin.
Q8 : Comment surveiller la stabilité en environnement de production ?
Nous vous conseillons de suivre trois indicateurs via votre client : temps de génération moyen, taux d'erreur 5xx et taux de succès du téléchargement des URL. Dans des conditions normales, le temps moyen doit être inférieur à 120 secondes, le taux d'erreur 5xx < 1 % et le taux de succès de téléchargement > 99,5 %. Toute anomalie sur l'un de ces points indique une saturation du pool de comptes et nécessite de contacter notre équipe commerciale pour ajuster les ressources.
Résumé
gpt-image-2-vip est une solution commerciale de génération d'images basée sur le canal inverse officiel de codex. Ses 5 caractéristiques principales permettent de résoudre un par un les points de douleur d'une connexion directe officielle : 30 formats disponibles + facturation unifiée à 0,03 $ + compatibilité avec trois points de terminaison + support natif du chinois + pas de facturation en cas d'échec. Pour les équipes travaillant sur la production de contenu, les supports e-commerce, l'automatisation de PPT ou la génération de posters en masse, il s'agit actuellement de l'une des solutions d'intégration gpt-image-2 offrant le meilleur rapport qualité-prix.
L'intégration ne nécessite que la modification de base_url et de model, le code SDK réutilisant entièrement la syntaxe officielle d'OpenAI. Pour un environnement de production, nous recommandons de régler le timeout sur 300 secondes, d'appliquer un backoff exponentiel sur les erreurs 5xx et de sauvegarder les URL d'images localement dans les 24 heures. En évitant ces trois pièges, vous pourrez assurer une montée en charge stable. Si vous évaluez actuellement des solutions d'intégration en production pour gpt-image-2, vous pouvez vous rendre sur APIYI (apiyi.com) pour créer un compte et tester le canal VIP avec vos données métier réelles avant de prendre une décision.
À propos de l'auteur : L'équipe APIYI se concentre sur l'intégration agrégée de modèles multiples et sur l'infrastructure d'inférence à haute concurrence. Nous traitons quotidiennement de nombreuses demandes concernant l'intégration d'API de génération d'images. Cet article est basé sur des données de production réelles. Pour plus de détails sur les paramètres de gpt-image-2-vip, veuillez consulter docs.apiyi.com.