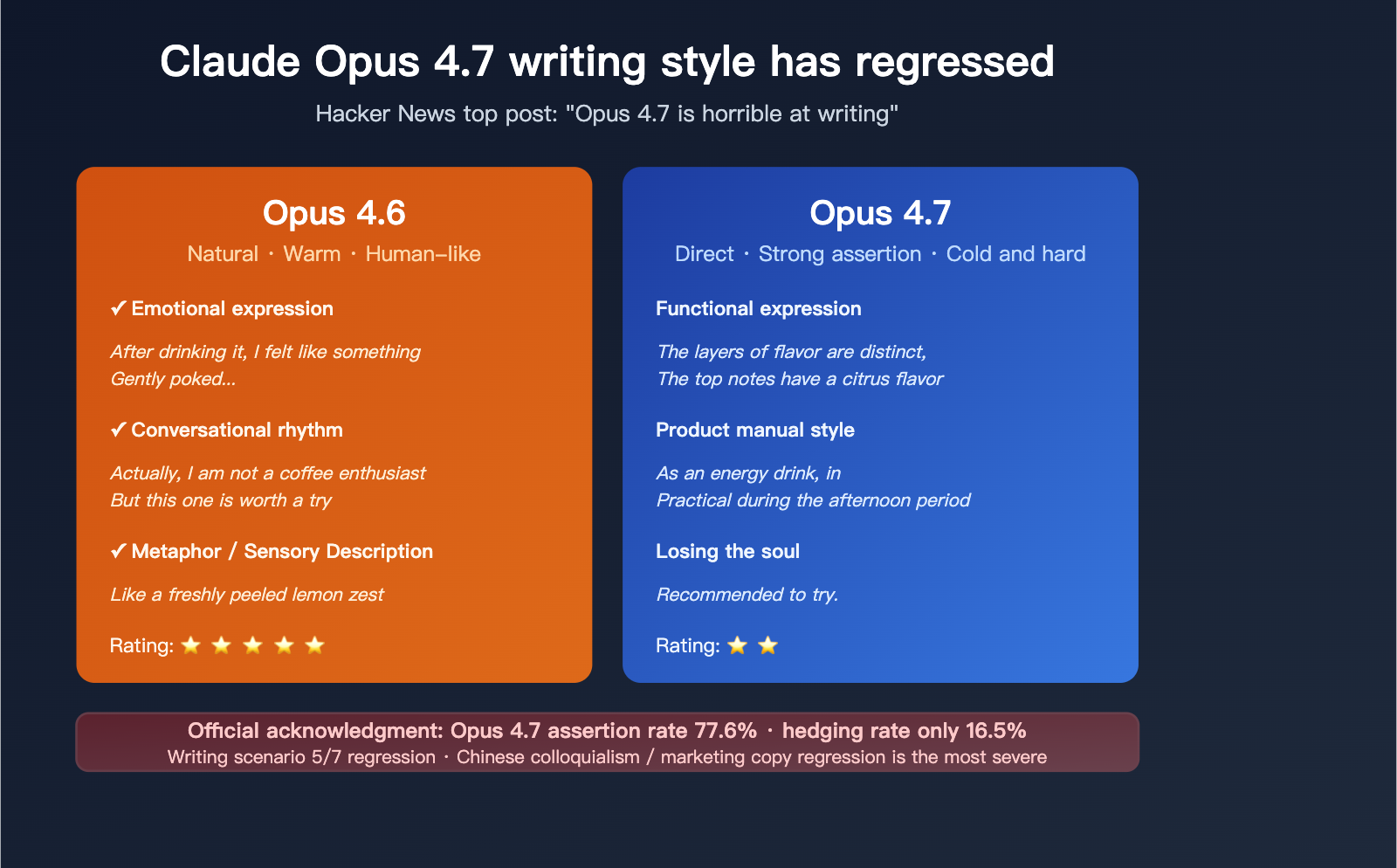
Differences between Claude Fable 5 and Mythos 5: Two packages of the same Large Language Model, 5 core differences explained
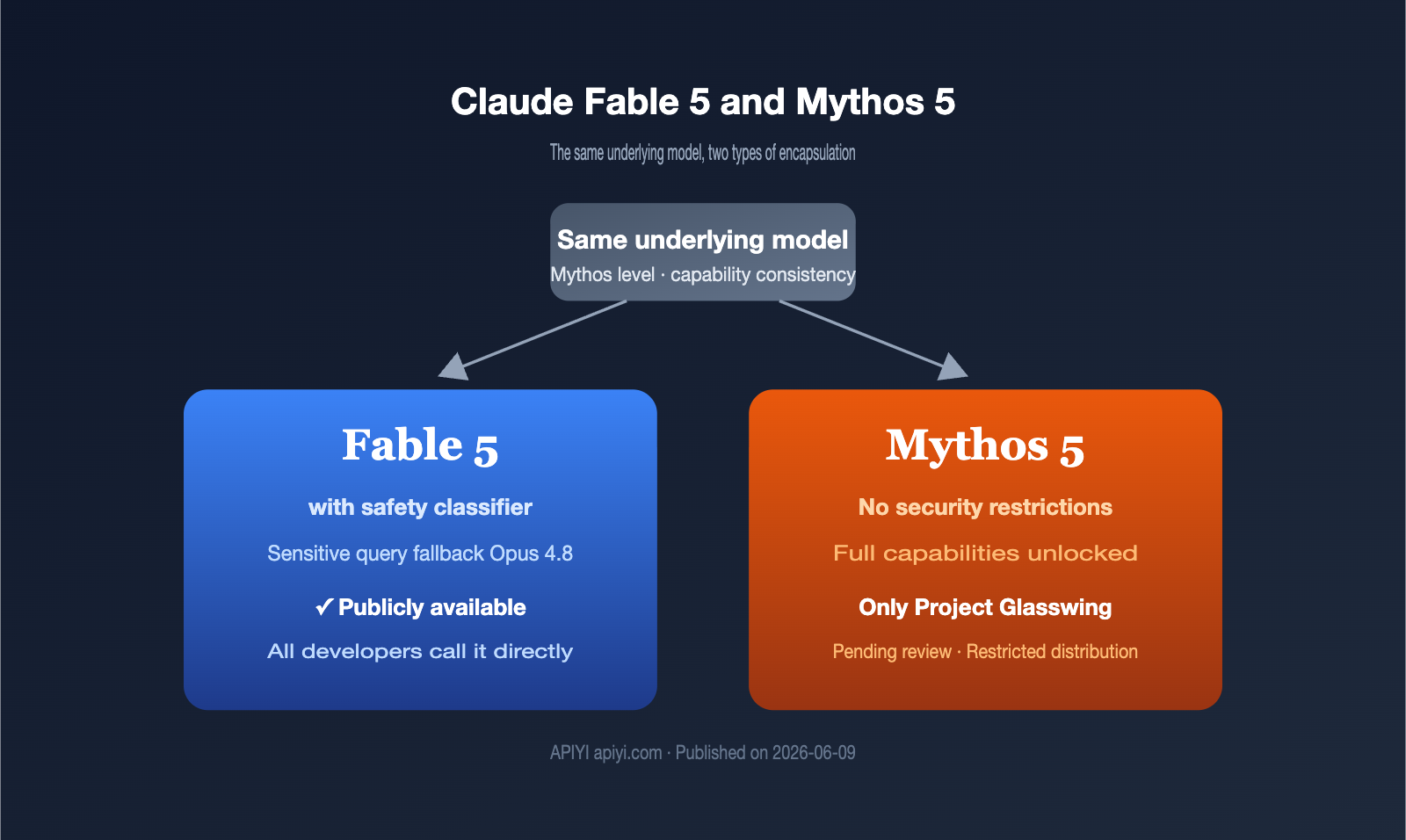
On June 9, 2026, Anthropic dropped two names at once: Claude Fable 5 and Claude Mythos 5. Many assumed these were two distinct models, but in reality, they are two different wrappers for the same underlying model. What truly separates them isn't their capability, but their safety policy. This article answers one question: What is … Read more