
Expert programmers have combed through the 232-page official Anthropic system card, and the conclusion is unanimous: Claude Opus 4.7’s long-context performance has seen a significant regression compared to 4.6.
This finding stands in sharp contrast to the phrasing in Anthropic’s official blog, which claimed, "Opus 4.7 delivered the most consistent long-context performance of any model we tested." Where is the real data? It’s right there in the official system card: in the MRCR v2 8-needle benchmark at a 1M context window, Opus 4.6 scored 78.3%, while Opus 4.7 managed only 32.2%. This isn't just a regression; it's a total collapse in accuracy.
What has the community even more riled up is that Anthropic admitted in the system card: "Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval." This statement has been cited repeatedly by veteran developers on Hacker News, X, and Reddit, serving as official evidence for the "Opus 4.7 long-context regression" consensus.
This article provides a deep dive into the real data, root causes, and mitigation strategies for the Claude Opus 4.7 long-context regression, based on the official system card, independent third-party reviews (such as Rohan Paul on X and the DEV Community’s breakdown of the 232-page document), and firsthand feedback from the developer community.
Core Value: After reading this, you’ll know exactly which long-context scenarios require keeping 4.6, which ones are still fine for 4.7, and how to implement scenario-based routing at the API invocation layer.
Official Confirmation of Claude Opus 4.7 Long-Context Regression
This section uses data published by Anthropic itself to prove the regression.
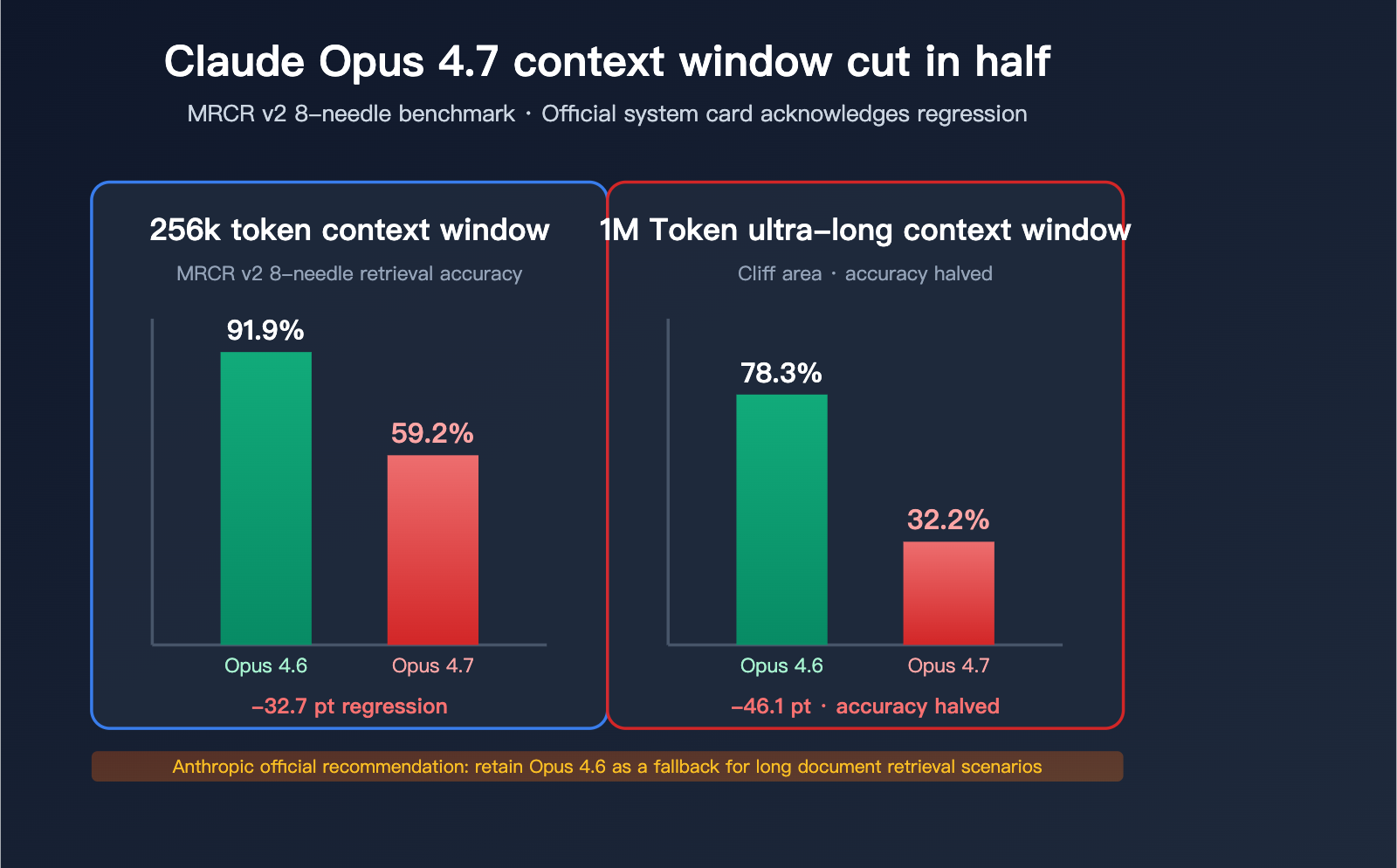
The Cliff-Edge Drop in the MRCR v2 8-Needle Benchmark
MRCR v2 (Multi-Round Coreference Resolution, version 2) is the industry standard for measuring long-context multi-needle retrieval capabilities. The test involves embedding 8 specific facts into a very long text and requiring the model to retrieve and reproduce them. The score represents the average match rate (%).
| Context Length | Opus 4.6 | Opus 4.7 | Drop |
|---|---|---|---|
| 256k Token | 91.9% | 59.2% | -32.7pt |
| 1M Token | 78.3% | 32.2% | -46.1pt |
What these numbers mean:
- At 256k context, 4.7’s multi-needle retrieval accuracy dropped from "near perfect" to "failing."
- At 1M context, 4.7’s accuracy was cut in half, falling to less than one-third of its predecessor.
- On this benchmark, 4.6 not only outperforms 4.7 but also beat GPT-5.2 in the 256k range (officially confirmed by Rohan Paul).
Rohan Paul provided the most concise assessment on X: "Opus 4.6 now takes the crown as the best long-context model." In other words, Opus 4.6 is currently the best long-context model of 2026—the champion is neither 4.7 nor GPT-5.4.
Anthropic’s Admission in the System Card
What shocked the community even more is that Anthropic admitted this in the Opus 4.7 system card. Page 47 of the document states:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
This is the first time Anthropic has explicitly recommended that users "not fully migrate" to a new version in their official documentation. This rare admission indicates that internal evaluations couldn't hide this regression.
🎯 Technical Advice: If your business involves long-document RAG or large codebase retrieval, we recommend using the APIYI (apiyi.com) platform to maintain access to both Claude Opus 4.6 and 4.7. The platform provides a unified API interface, allowing you to switch models by simply changing parameters. This makes it easy to perform A/B testing and scenario-based routing during the transition period.
It’s Not Just MRCR: BrowseComp Is Also Regressing
Beyond MRCR, another long-context benchmark, BrowseComp (for deep web research tasks), has also shown a decline:
| Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp measures the performance of "Deep Research Agents"—tasks requiring the model to track multiple information sources within a long context and make cross-document judgments. While the regression in 4.7 isn't as dramatic as in MRCR, it remains a substantial negative signal for teams building Research Agents.
The Root Causes of the Long-Context Regression in Claude Opus 4.7
Why would a new flagship model from 2026 take such a significant step backward in long-context performance? By distilling official system cards and community analysis, we can identify three fundamental reasons.
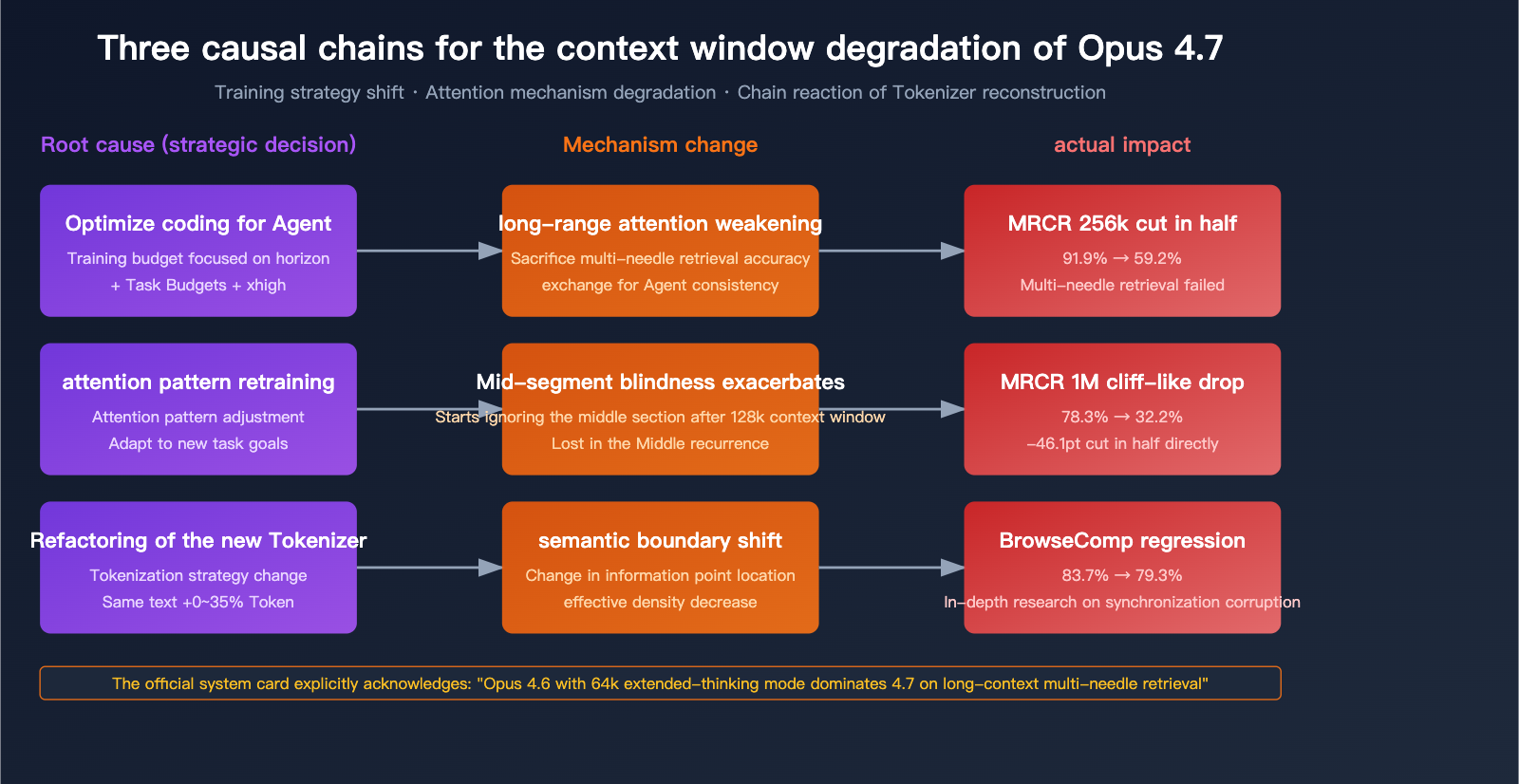
Reason 1: Sacrificing Long-Range Attention for "Agentic Coding"
The core design goal for Opus 4.7 is "long-running agentic coding workflows"—note that long-running does not equal long-context retrieval. While these concepts are often conflated in Anthropic's marketing, they are two distinct things at the model capability level:
| Capability Dimension | Long-Running (Agent Horizon) | Long-Context Retrieval (Multi-needle Retrieval) |
|---|---|---|
| Key Requirement | Continuous decision stability | Precise location of distant information |
| Typical Scenario | Claude Code multi-turn loops | RAG retrieval, long-document Q&A |
| Training Goal | Consistency + step planning | Attention precision + fine-grained memory |
| 4.7 Performance | ✓ Significant improvement | ✗ Severe regression |
Opus 4.7 invested massive optimization resources into the first dimension (Task Budgets, xhigh tiers, and more precise instruction following). These optimizations may have directly or indirectly sacrificed long-range attention precision.
Reason 2: Exacerbation of the "Lost in the Middle" Problem
"Lost in the middle" is a well-known industry-wide issue with long contexts: when information is buried in the middle of a long text, the model systematically ignores or misattributes it. Opus 4.6 was one of the best models in the industry at handling this, but 4.7 has clearly regressed here.
According to the authors of the 232-page system card:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
In other words: Opus 4.6 could reliably use its full context window. Opus 4.7 shows clear signs of "mid-context blindness" after 128k tokens.
This explains why 4.7 can maintain 59.2% on a 256k benchmark but drops to only 32.2% at 1M—the longer the context, the higher the probability that the middle section gets "lost."
Reason 3: Tokenizer Refactoring Altered Semantic Boundaries
While the primary goal of the new tokenizer in Opus 4.7 was to "improve processing efficiency," its method of segmenting text is incompatible with 4.6. This means:
- The same information points occupy different token positions in 4.6 versus 4.7.
- The "attention patterns" optimized during training may need to be re-adapted.
- In the short term, the tokenizer changes have caused a hidden loss in 4.7's ability to inherit the retrieval capabilities of 4.6.
Combined with the fact that token inflation has increased (by 0-35%), the "effective token density" of the same long document has actually decreased on 4.7. You might think you're feeding it 1M tokens of information, but it's actually being chopped into more tokens, which dilutes the model's attention.
Claude Opus 4.7 Long Context Performance Overview
This section summarizes and compares the performance data of 4.7, 4.6, and GPT-5.4 across various long-context benchmarks.
Mainstream Long-Context Benchmark Overview
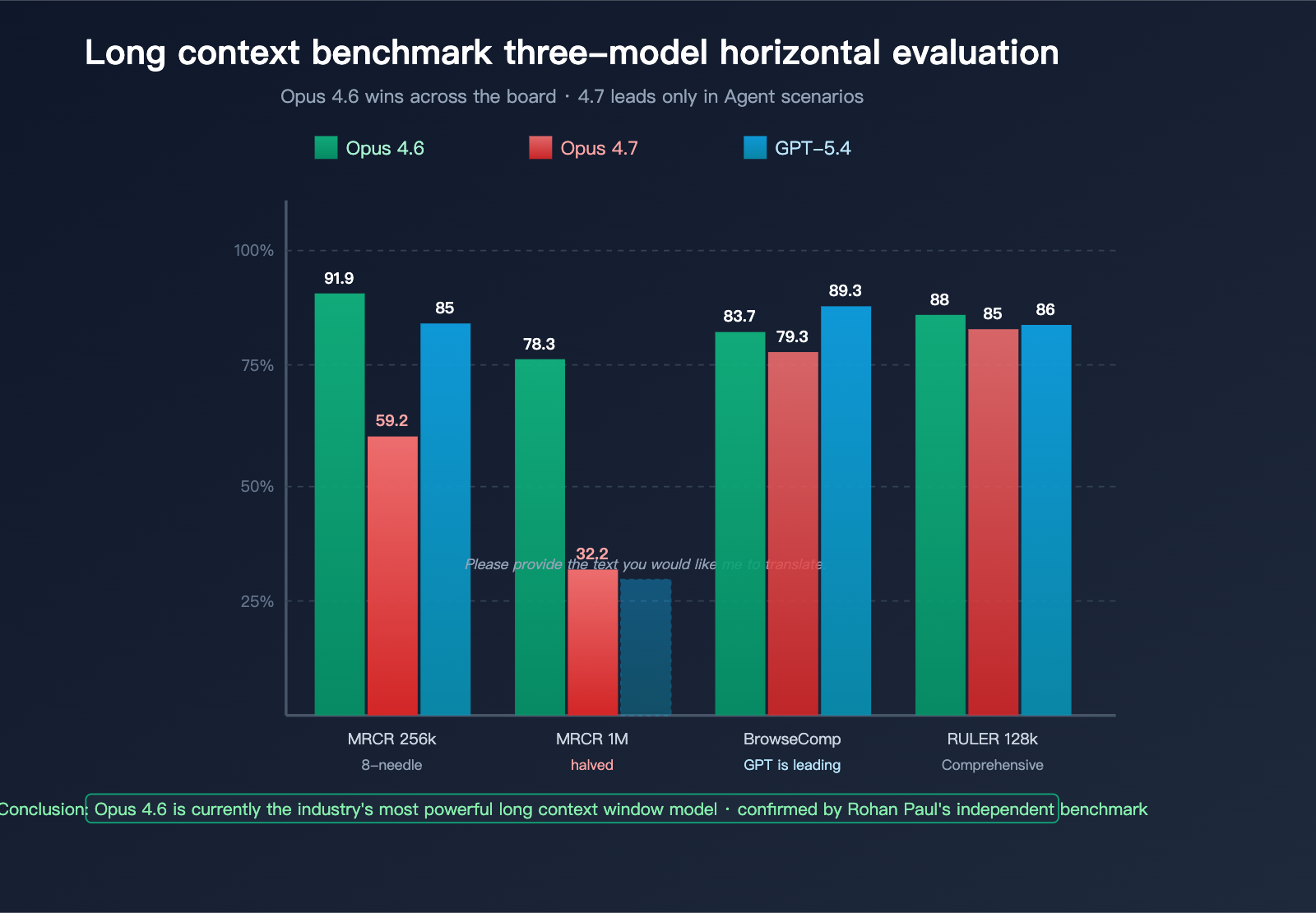
| Benchmark | Measurement Dimension | Opus 4.6 | Opus 4.7 | GPT-5.4 | Winner |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Multi-needle retrieval accuracy | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Ultra-long context retrieval | 78.3% | 32.2% | Undisclosed | Opus 4.6 |
| BrowseComp | Deep research Agent | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | Comprehensive long context | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | Long document understanding | High | Slight drop | On par | Opus 4.6 |
| Needle-in-haystack @ 1M | Single-needle retrieval | 99%+ | ~95% | ~97% | Near tie |
Key takeaways from this table:
- For single-needle retrieval (hiding one piece of information in a long text), the performance gap between the three models is minimal.
- For multi-needle retrieval (finding 8 pieces of information simultaneously), Opus 4.6 holds a significant lead.
- In the 1M ultra-long context range, Opus 4.7's performance is noticeably lower than both Opus 4.6 and GPT-5.4.
Real-World Scenario Mapping
Translating benchmark data into real-world business scenarios:
| Business Scenario | Primary Capability Requirement | Recommended Model | Reason |
|---|---|---|---|
| Long contract parsing | Multi-needle retrieval + precise location | Opus 4.6 | MRCR lead |
| Large codebase Q&A | Cross-file semantic retrieval | Opus 4.6 | Reliable at 128k+ |
| Financial report analysis | Multi-table + multi-paragraph synthesis | Opus 4.6 | Multi-needle capability |
| Deep Web research | Cross-webpage comprehensive judgment | GPT-5.4 Pro | BrowseComp lead |
| Claude Code long loops | Stable long-task execution | Opus 4.7 | Strong Agent horizon |
| Short document Q&A | Precise and fast answers | Opus 4.7 / 4.6 | Minimal difference |
| Legal clause retrieval | Precise matching + citation | Opus 4.6 | High recall required |
💡 Scenario Selection Advice: For business cases involving long document retrieval or RAG, we recommend using the APIYI (apiyi.com) platform to route between Opus 4.6 and 4.7 based on your specific needs. The platform supports unified API calls for various mainstream models, making it easy to switch quickly based on the scenario.
Context Length Impact Curve
As context length increases, the performance regression in 4.7 exhibits non-linear amplification:
- Below 32k: Almost no difference between 4.7 and 4.6.
- 32k – 128k: 4.7 begins to show a slight regression (within ~5pt).
- 128k – 256k: The regression in 4.7 becomes significantly amplified (-15~30pt).
- 256k – 1M: 4.7 enters a "cliff zone," where multi-needle retrieval effectively fails.
This curve directly informs your business decisions: If your context requirements are below 128k, 4.7 is fine; if you exceed 128k, we strongly recommend sticking with 4.6.
3 Strategies for Addressing Claude Opus 4.7 Long Context Regression
Since the regression is a fact, the key to migration isn't "whether" to do it, but "how." Here are three strategies, listed from lowest to highest cost, which can be used individually or in combination.

Strategy 1: API-Layer Routing by Scenario (4.6 vs. 4.7)
This is the lowest-cost and most effective strategy. The core idea: use 4.7 for short contexts or Agent coding, and 4.6 for long context, RAG, or deep research tasks.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Route the model based on context length and task type"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
View full multi-dimensional routing strategy code
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Multi-dimensional routing decision"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Agent long-loop scenario, 4.7 horizon is stronger",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} tokens exceed 4.7 MRCR safe zone",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="BrowseComp 4.6 outperforms 4.7",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="MRCR multi-needle retrieval 4.6 has absolute advantage",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Short-context task, 4.7 has better comprehensive capabilities",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Estimate token count"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Routing decision: {decision.model} (Reason: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Performance: While retaining 4.7's Agent capabilities, accuracy in long-context scenarios is fully restored to 4.6 levels, with almost zero migration cost.
🚀 Unified Interface Routing: We recommend using the APIYI (apiyi.com) platform for on-demand routing of the full Claude model series. It provides an interface fully compatible with official Claude APIs, eliminating the need to maintain multiple API keys and reducing the architectural complexity of multi-model routing.
Strategy 2: RAG Chunking + Sliding Window
If your business strongly relies on 4.7 (e.g., you're already locked into a Claude Code workflow), you can mitigate 4.7's mid-context blindness by reducing the "single-pass context length."
Core Strategy:
- Divide long documents into 32k-64k chunks (4.7 performs well in this range).
- Use vector retrieval to fetch only the relevant Top-K chunks.
- Perform independent model invocations on each chunk, then synthesize the answers.
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""Chunked RAG optimized for Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Answer the question based on the provided document snippet."},
{"role": "user", "content": f"Document: {chunk}\nQuestion: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Synthesize the following answers to address: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Suitable for: Teams already using Claude Code/Cursor who still need to process ultra-long documents.
Strategy 3: Hybrid Model Architecture (Opus 4.6 + Sonnet + GPT-5.4)
For mature products, the safest bet is a three-model hybrid architecture:
- Opus 4.6: Long context retrieval, RAG, long contract parsing.
- Opus 4.7: Agent coding, Claude Code loops, high-definition vision.
- GPT-5.4 Pro: Deep Web research, BrowseComp-style tasks.
This architecture acknowledges that "no single model covers everything" and maximizes the strengths of each model through a combined approach.
💰 Cost and Architectural Optimization: The prerequisite for a hybrid model architecture is a unified API access layer. Using the APIYI (apiyi.com) platform, you can call the entire series of Claude, GPT, and Gemini models with a single API key. The platform provides granular usage statistics and cost analysis, making it an ideal choice for implementing multi-model architectures.
Claude Opus 4.7 Long Context Capability FAQ
Q1: Anthropic claims 4.7 has more stable long context, so why do third-party benchmarks show the opposite?
This is a confusion between two concepts: "long-running stability" and "long-context retrieval." The "stability" Anthropic emphasizes refers to decision consistency within Agent loops—meaning it won't crash midway through long tasks. However, "long-context retrieval" refers to the ability to precisely locate information at distant positions, which is a completely different capability dimension.
The MRCR v2 8-needle benchmark directly measures the latter, which is exactly where the official Anthropic system card admits Opus 4.6 outperforms 4.7. So, the two claims aren't contradictory; they're just measuring different things.
Q2: Should my long-document RAG application immediately roll back to 4.6?
It depends:
- Core business relies on > 128k context retrieval: Roll back immediately. A 50% drop in MRCR 1M accuracy is a big deal and will directly impact answer quality.
- Context between 32k-128k: I recommend A/B testing. If the quality is acceptable, you can keep using 4.7; otherwise, switch back to 4.6.
- Context under 32k: There's little difference between the two models, so decide based on other factors like cost or latency.
We recommend using the APIYI (apiyi.com) platform for A/B testing, as it supports parallel model invocation for both Opus 4.6 and 4.7.
Q3: Why would Anthropic allow this regression to happen?
Based on information disclosed in the official system card, Anthropic made a conscious capability trade-off: they focused their training budget on Agent coding and visual understanding, sacrificing some long-context retrieval precision.
This strategy aligns with Anthropic's current business focus—Claude Code and enterprise Agent workflows are their most important revenue sources. But for users focused on long documents, RAG, and research-oriented Agents, this strategic shift means a downgrade.
By explicitly suggesting in the system card that users "keep 4.6 as a fallback," Anthropic is essentially telling users: This isn't a bug; it's a strategy. Please adapt accordingly.
Q4: How severe is the MRCR benchmark drop in real-world business scenarios?
It's very severe. The MRCR 8-needle test simulates real-world scenarios where you need to find multiple key facts within a massive document, such as:
- Contract Review: Identifying all clause restrictions, deadlines, and breach terms.
- Financial Analysis: Locating multiple financial metrics across a 100-page report.
- Codebase Q&A: Tracking variable definitions, call chains, and dependencies across multiple files.
A drop in MRCR from 78.3% to 32.2% means that for these tasks, 4.7 will miss 2/3 of the key information on average. For businesses relying on precision, this is a catastrophic regression.
Q5: In short-context scenarios (< 32k), what are the actual differences between 4.7 and 4.6?
In short-context scenarios under 32k, there's almost no discernible difference in long-context capability. However, 4.7 still excels in the following dimensions:
- Stronger coding ability: SWE-bench Verified +6.8pt.
- Stronger visual understanding: 3.75MP high resolution.
- More accurate tool calling: Leading in MCP-Atlas.
- Higher cost: Tokenizer expansion of 0-35%.
So, in short-context scenarios, your choice should be based on the task type, not long-context capability. Choose 4.7 for coding and 4.6 for writing—that's the simplest rule of thumb right now.
Q6: Is there any way to make 4.7 match 4.6 in long-context performance?
There are currently no configuration-level solutions. Even if you increase reasoning-effort to max, 4.7's MRCR scores remain significantly lower than 4.6's.
Two viable indirect approaches exist:
- RAG Chunking: Break long contexts into 32k-64k chunks to keep 4.7 working within its "safe zone."
- Multi-model Chaining: Use 4.6 for long-context retrieval, then feed the retrieved results into 4.7 for comprehensive reasoning.
The second approach can be quickly implemented via the multi-model interface on the APIYI (apiyi.com) platform, which supports unified API calls for various mainstream models.
Summary of Claude Opus 4.7 Long Context Regression
The long-context regression in Claude Opus 4.7 is a real issue supported by official data, verified by the community, and with a clear scope of impact. Key takeaways:
- Official data confirms it: MRCR v2 8-needle scores were cut in half at 256k and 1M, and the Anthropic system card explicitly recommends keeping 4.6 as a fallback.
- The root cause is a strategic trade-off: Anthropic sacrificed long-distance attention precision for the sake of Agent coding and visual understanding.
- Impact is concentrated in 128k+ scenarios: 4.7 is still usable for short contexts, but the regression amplifies non-linearly beyond 128k.
- Opus 4.6 remains the strongest long-context model: A conclusion widely accepted by veteran observers like Rohan Paul, even outperforming GPT-5.2 in this regard.
- The best response is scenario-based routing: Use 4.6 for long documents, 4.7 for coding, and consider GPT-5.4 Pro for deep research.
For users, the right approach isn't to "wait for Anthropic to fix it"—this adjustment is strategic and won't be rolled back in the short term—but to immediately prepare for multi-model routing at the application layer. Make 4.6 your default for long-context scenarios and reserve 4.7 for the Agent coding tasks where it truly shines.
This also aligns with the new 2026 AI industry trend: The era of a single model covering all scenarios is over. Each model is evolving toward "specialization." The requirement for users is shifting from "choosing the strongest model" to "designing a rational multi-model routing strategy."
We recommend using the APIYI (apiyi.com) platform to centrally manage your Claude model invocations. The platform provides real-time benchmark comparisons, intelligent multi-model routing, and fully compatible APIs, making it a pragmatic tool for navigating the Opus 4.7 long-context regression.
References
-
Anthropic Opus 4.7 System Card: Official 232-page system card
- Link:
anthropic.com/news/claude-opus-4-7 - Description: Contains full MRCR v2 benchmark data and migration recommendations.
- Link:
-
Opus 4.7 System Card Deep Dive: DEV Community analysis
- Link:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Description: A developer-focused summary of the 232-page system card.
- Link:
-
Anthropic Migration Guide: Opus 4.7 migration guide
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Description: Official migration advice and considerations for long context windows.
- Link:
-
Long-Context Benchmarks Leaderboard: Long-context benchmark leaderboard
- Link:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Description: Horizontal comparison of MRCR, RULER, and LongBench v2.
- Link:
-
Rohan Paul X Commentary: Analysis of Opus 4.6 as the long-context champion
- Link:
x.com/rohanpaul_ai/status/2019545018051240059 - Description: Independent observer's evaluation of Opus 4.6's long-context advantages.
- Link:
Author: APIYI Technical Team
Release Date: 2026-04-18
Applicable Models: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Technical Exchange: Feel free to visit APIYI at apiyi.com to get testing credits for various models and personally test the differences in retrieval accuracy across different context window lengths.