
老外高手程序員已經翻遍了 Anthropic 的 232 頁官方系統卡,結論非常統一: Claude Opus 4.7 的長上下文能力相比 4.6 出現了嚴重倒退。
這個結論和 Anthropic 官方博客裏 "Opus 4.7 delivered the most consistent long-context performance of any model we tested" 的措辭形成了尖銳反差。真實數據在哪裏?就在官方自己發佈的系統卡里——MRCR v2 8-needle 基準在 1M 上下文下,Opus 4.6 得分 78.3%,Opus 4.7 僅得 32.2%。準確率不是倒退,是腰斬。
更讓社區譁然的是,Anthropic 在系統卡中坦承: "Opus 4.6 的 64k extended-thinking 模式在長上下文多針檢索任務上完勝 4.7。" 這段話被 Hacker News、X、Reddit 的老牌程序員反覆引用,成爲"Opus 4.7 長上下文倒退"這個共識的官方證據。
本文基於 Anthropic 官方系統卡、第三方獨立橫評(Rohan Paul on X、DEV Community 232 頁系統卡解讀)以及程序員社區一手反饋,深度拆解 Claude Opus 4.7 長上下文 能力倒退的真實數據、根本原因和應對方案。
核心價值: 看完本文你會明確知道——哪些長上下文場景必須保留 4.6,哪些場景 4.7 仍可用,以及如何在 API 調用層做分場景路由。
Claude Opus 4.7 長上下文倒退的官方實錘
這一節用 Anthropic 自己公佈的數據證明倒退事實。
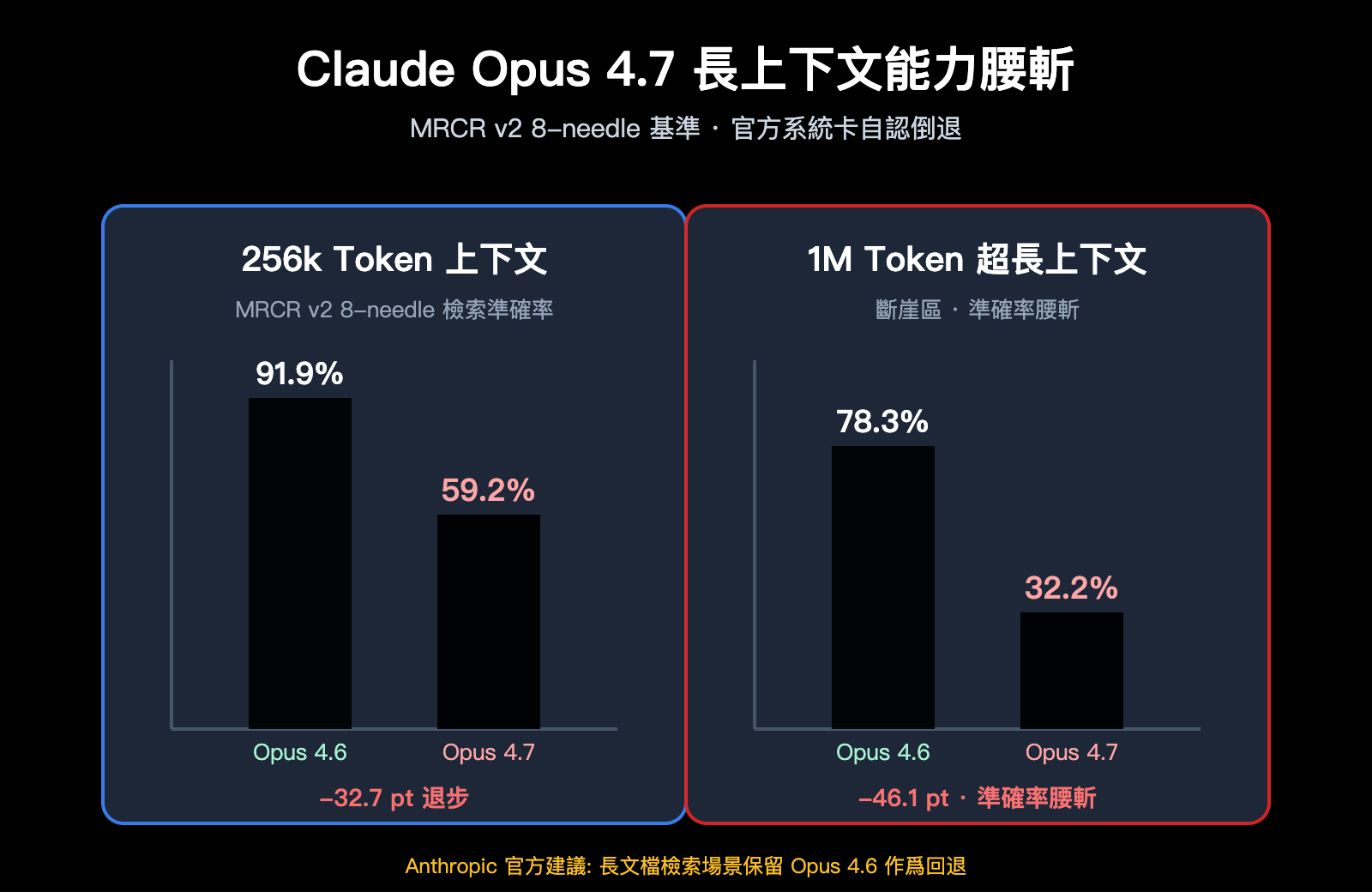
MRCR v2 8-needle 基準的斷崖式下降
MRCR v2 (Multi-Round Coreference Resolution,version 2) 是業界衡量長上下文多針檢索能力的標準基準。測試方式: 在一段非常長的文本中埋入 8 條特定事實,要求模型檢索並復現。得分爲平均匹配率(%)。
| 上下文長度 | Opus 4.6 | Opus 4.7 | 下降幅度 |
|---|---|---|---|
| 256k Token | 91.9% | 59.2% | -32.7pt |
| 1M Token | 78.3% | 32.2% | -46.1pt |
這兩個數字的含義:
- 在 256k 上下文下,4.7 的多針檢索準確率從"接近滿分"掉到"不及格"
- 在 1M 上下文下,4.7 的準確率被直接腰斬,甚至不到三分之一
- 4.6 在這個基準上不僅超越 4.7,還在 256k 範圍戰勝 GPT-5.2(Rohan Paul 官方確認)
Rohan Paul 在 X 平臺給出了最簡潔的判斷: "Opus 4.6 now takes the crown as the best long-context model." 翻譯過來就是: Opus 4.6 是 2026 年當前最好的長上下文模型——這個冠軍不是 4.7,也不是 GPT-5.4。
Anthropic 系統卡的自認
更讓社區震動的是,Anthropic 在 Opus 4.7 系統卡中自己承認了這件事。系統卡第 47 頁原文:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
翻譯: Opus 4.6 的 64k 擴展思考模式在長上下文多針檢索上完勝 4.7。對依賴長文檔檢索的生產系統,建議保留 4.6 作爲回退選項。
這是 Anthropic 第一次在官方文檔中明確推薦用戶"不要全量遷移"到新版本。這種罕見的自認,說明內部評測也無法掩蓋這次倒退。
🎯 技術建議: 如果你的業務涉及長文檔 RAG 或大型代碼庫檢索,建議通過 API易 apiyi.com 平臺同時保留 Claude Opus 4.6 和 4.7 的調用權限。該平臺提供統一 API 接口,切換模型僅需修改參數,在遷移期可以快速做 A/B 對比和按場景路由。
不只是 MRCR: BrowseComp 也在退步
除 MRCR 外,另一個長上下文相關基準 BrowseComp(深度 Web 研究任務)也出現了倒退:
| 基準 | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp 衡量的是 "深度研究 Agent" 的表現——需要模型在長上下文裏跟蹤多個信息源、做跨文檔綜合判斷。4.7 的退步雖然幅度不如 MRCR 那麼誇張,但對做 Research Agent 的團隊來說仍然是個實質性負面信號。
Claude Opus 4.7 長上下文能力倒退的根本原因
爲什麼一個 2026 年的新旗艦模型會在長上下文上大幅倒退?從官方系統卡和社區分析中可以提煉出三個根本原因。

原因 1: 爲"Agent 編碼"犧牲長距離注意力
Opus 4.7 的核心設計目標是"長時間運行的 Agentic 編碼工作流"——注意,長時間運行 ≠ 長上下文檢索。這兩個概念在 Anthropic 的產品語言裏常常混淆,但在模型能力層面是兩件事:
| 能力維度 | 長時間運行 (Agent Horizon) | 長上下文檢索 (Multi-needle Retrieval) |
|---|---|---|
| 關鍵要求 | 連續決策穩定性 | 精確定位遠距離信息 |
| 典型場景 | Claude Code 多輪循環 | RAG 檢索、長文檔問答 |
| 訓練目標 | 一致性 + 步驟規劃 | 注意力精度 + 細粒度記憶 |
| 4.7 表現 | ✓ 顯著提升 | ✗ 嚴重倒退 |
Opus 4.7 在第一個維度投入了大量優化資源(Task Budgets、xhigh 檔位、更精準的指令遵循),這些優化可能直接或間接地犧牲了長距離注意力精度。
原因 2: "Lost in the Middle" 問題加劇
"Lost in the middle" 是業界公認的長上下文通病: 信息埋在長文本中段時,模型會系統性地忽視或錯誤歸因。Opus 4.6 曾是業界處理這個問題最好的模型之一,4.7 在這一點上出現了明顯退步。
232 頁系統卡分析作者的原話:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
翻譯: Opus 4.6 能可靠地使用完整上下文窗口。Opus 4.7 在 128k Token 之後出現了明顯的"中段失明"跡象。
這解釋了爲什麼 4.7 在 256k 基準下還能維持 59.2%,但在 1M 下只剩 32.2%——上下文越長,中段被"看丟"的概率越大。
原因 3: Tokenizer 重構改變了語義邊界
Opus 4.7 的新 Tokenizer 雖然主要目標是"提升處理效率",但它對文本的切分方式與 4.6 並不兼容。這意味着:
- 同樣的信息點在 4.6 和 4.7 上佔用的 Token 位置不同
- 訓練時優化過的"注意力 attention pattern"可能需要重新適配
- 短期內,Tokenizer 變化讓 4.7 在繼承 4.6 的檢索能力上存在隱形損失
結合 Tokenizer 膨脹(0-35%)這個事實,實際上同一段長文檔在 4.7 上的"有效 Token 密度"反而下降了——你以爲餵了 1M Token 的信息,實際上被切碎成了更多的 Token,分散了模型的注意力。
Claude Opus 4.7 長上下文實測數據全景
這一節把 4.7 與 4.6、GPT-5.4 在長上下文各類基準上的數據彙總對比。
主流長上下文基準全景
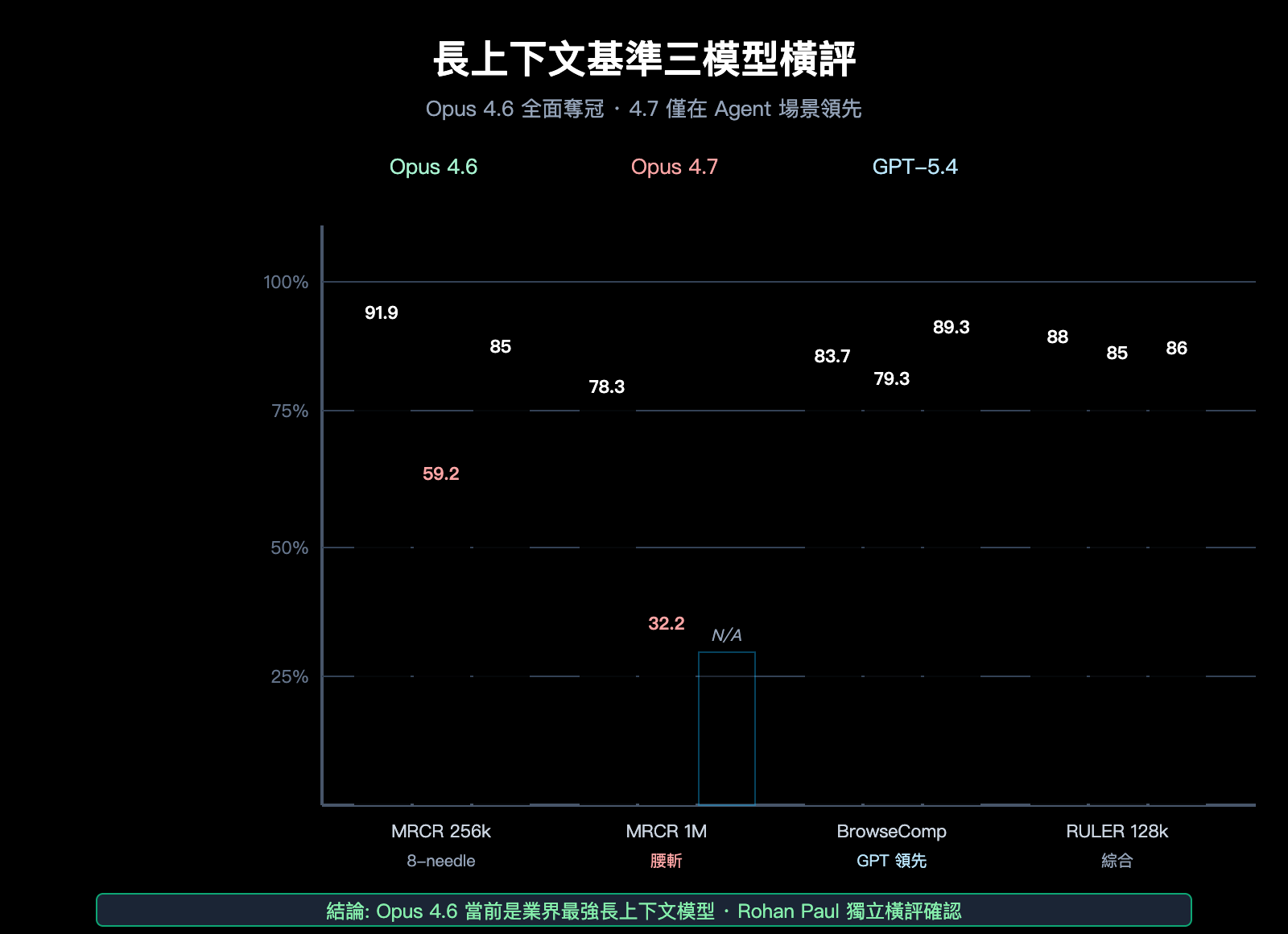
| 基準 | 測量維度 | Opus 4.6 | Opus 4.7 | GPT-5.4 | 冠軍 |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | 多針檢索準確率 | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | 超長上下文檢索 | 78.3% | 32.2% | 未公開 | Opus 4.6 |
| BrowseComp | 深度研究 Agent | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | 綜合長上下文 | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | 長文檔理解 | 高 | 略降 | 持平 | Opus 4.6 |
| Needle-in-haystack @ 1M | 單針檢索 | 99%+ | ~95% | ~97% | 接近平局 |
從這張表裏可以看出:
- 單針檢索(把 1 條信息埋在長文本里)上,三個模型差距不大
- 多針檢索(同時找 8 條信息)上,Opus 4.6 的領先幅度巨大
- 在 1M 級超長上下文下,Opus 4.7 的表現明顯低於 Opus 4.6 和 GPT-5.4
真實場景映射表
把基準數據翻譯成真實業務場景:
| 業務場景 | 主要能力要求 | 推薦模型 | 原因 |
|---|---|---|---|
| 長合同文本解析 | 多針檢索 + 精確定位 | Opus 4.6 | MRCR 領先 |
| 大型代碼庫問答 | 跨文件語義檢索 | Opus 4.6 | 128k+ 可靠 |
| 財報分析 | 多表格 + 多段落綜合 | Opus 4.6 | 多針能力 |
| 深度 Web 研究 | 跨網頁綜合判斷 | GPT-5.4 Pro | BrowseComp 領先 |
| Claude Code 長循環 | 長任務穩定執行 | Opus 4.7 | Agent horizon 強 |
| 短文檔問答 | 精確快速回答 | Opus 4.7 / 4.6 都可 | 差距不大 |
| 法律條文檢索 | 精確匹配 + 引用 | Opus 4.6 | 需要高召回 |
💡 場景選型建議: 涉及長文檔檢索或 RAG 場景的業務,建議通過 API易 apiyi.com 平臺按業務路由 Opus 4.6 與 4.7。該平臺支持多種主流模型的統一接口調用,便於根據場景快速切換。
上下文長度影響曲線
在不同上下文長度下,4.7 的倒退幅度呈現非線性放大特徵:
- 32k 以下: 4.7 vs 4.6 幾乎無差異
- 32k – 128k: 4.7 開始出現輕微退步(~5pt 以內)
- 128k – 256k: 4.7 退步明顯放大(-15~30pt)
- 256k – 1M: 4.7 進入"斷崖區",多針檢索徹底失效
這條曲線直接指導你的業務決策: 如果上下文需求低於 128k,4.7 可以用;如果超過 128k,強烈建議保留 4.6。
Claude Opus 4.7 長上下文倒退的三個應對方案
既然倒退是事實,遷移的關鍵不是"要不要",而是"怎麼遷"。以下三個方案按成本由低到高排列,可以單獨使用也可以組合。

方案 1: API 層按場景路由 4.6 與 4.7
這是成本最低、效果最好的方案。核心思路: 讓短上下文 / Agent 編碼走 4.7,長上下文 / RAG / 深度研究走 4.6。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""根據上下文長度和任務類型路由模型"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
查看完整的多維度路由策略代碼
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""多維度路由決策"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Agent 長循環場景,4.7 horizon 更強",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} tokens 超過 4.7 MRCR 安全區",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="BrowseComp 4.6 領先 4.7",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="MRCR 多針檢索 4.6 絕對優勢",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="短上下文任務,4.7 綜合能力更強",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""估算 Token 數"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"路由決策: {decision.model} (原因: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
實測效果: 在保留 4.7 Agent 能力的前提下,長上下文場景的準確率完全恢復到 4.6 水平,遷移成本幾乎爲零。
🚀 統一接口路由: 推薦通過 API易 apiyi.com 平臺實現 Claude 全系列模型的按需路由。該平臺提供與 Claude 官方完全兼容的接口,無需維護多套 API Key,降低多模型路由的架構複雜度。
方案 2: RAG 分塊 + 滑動窗口
如果業務強依賴 4.7(比如已經綁定 Claude Code 工作流),可以通過"減少單次上下文長度"來規避 4.7 的中段失明問題。
核心策略:
- 把長文檔切成 32k-64k 的分塊(4.7 在此區間表現正常)
- 使用向量檢索只取相關 Top-K 塊
- 在每個分塊上獨立調用,再做答案合併
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""針對 Opus 4.7 優化的分塊 RAG"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "基於給定文檔片段回答問題。"},
{"role": "user", "content": f"文檔: {chunk}\n問題: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"綜合以下答案回答: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
適用場景: 已有 Claude Code / Cursor 綁定,但需要處理超長文檔的團隊。
方案 3: 混合模型架構 (Opus 4.6 + Sonnet + GPT-5.4)
對成熟產品,最穩妥的方案是三模型混合架構:
- Opus 4.6: 長上下文檢索、RAG、長合同解析
- Opus 4.7: Agent 編碼、Claude Code 循環、高清視覺
- GPT-5.4 Pro: 深度 Web 研究、BrowseComp 類任務
這種架構承認"沒有一個模型能全面覆蓋",用組合方式把每個模型的優勢最大化。
💰 成本與架構優化: 混合模型架構的前提是統一的 API 接入層。通過 API易 apiyi.com 平臺可以用一套 API Key 調用 Claude、GPT、Gemini 全系列模型,該平臺提供精細的調用統計和成本分析,是多模型架構落地的理想選擇。
Claude Opus 4.7 長上下文能力 FAQ
Q1: Anthropic 官方說 4.7 長上下文更穩定,爲什麼第三方數據相反?
這是"長時間運行"和"長上下文檢索"兩個概念的混淆。Anthropic 強調的"穩定"指的是 Agent 循環中的決策一致性——即長任務下不會中途崩潰。但"長上下文檢索"指的是 在遠距離位置精確找到信息 的能力,這兩者是截然不同的能力維度。
MRCR v2 8-needle 基準直接測量第二種能力,而這恰恰是 Anthropic 官方系統卡承認 Opus 4.6 優於 4.7 的地方。所以兩種說法不矛盾,只是測量的不是同一件事。
Q2: 我的長文檔 RAG 應用應該立刻回退到 4.6 嗎?
分情況:
- 核心業務依賴 > 128k 上下文檢索: 立刻回退。MRCR 1M 準確率腰斬不是小事,會直接影響答案質量。
- 上下文在 32k-128k 之間: 建議 A/B 測試,如果質量可接受可以繼續用 4.7,否則切回 4.6。
- 上下文在 32k 以內: 兩個模型差距不大,按其他維度(成本、延遲)決定即可。
推薦通過 API易 apiyi.com 平臺做 A/B 測試,該平臺支持 Opus 4.6 和 4.7 的並行調用對比。
Q3: 爲什麼 Anthropic 會允許這種倒退發生?
從官方系統卡披露的信息看,Anthropic 做了一個有意識的能力權衡: 把訓練預算集中在 Agent 編碼和視覺理解上,犧牲了部分長上下文檢索精度。
這種策略符合 Anthropic 當前的商業重心——Claude Code、企業 Agent 工作流纔是它最重要的收入來源。但對於長文檔、RAG、研究型 Agent 的用戶來說,這次策略轉向就意味着降級。
Anthropic 在系統卡里直接建議"保留 4.6 作爲回退",某種程度上也是在告訴用戶: 這不是 bug,是策略,請自行適配。
Q4: MRCR 基準的腰斬在實際業務中有多嚴重?
非常嚴重。MRCR 8-needle 模擬的就是"在一個大文檔裏找到多個關鍵事實"的真實場景,比如:
- 合同審查: 找出所有條款限制 + 截止日期 + 違約條款
- 財報分析: 從 100 頁財報中定位多個財務指標
- 代碼庫問答: 在多個文件裏追蹤變量定義 + 調用鏈 + 依賴關係
MRCR 從 78.3% 掉到 32.2% 意味着: 這類任務下, 4.7 平均會漏掉 2/3 的關鍵信息。對依賴精確性的業務,這是災難級回退。
Q5: 短上下文場景(< 32k)下,4.7 和 4.6 有什麼實際差異?
在 32k 以下的短上下文場景,4.7 和 4.6 的長上下文能力幾乎看不出差異。但 4.7 在以下維度仍然明顯:
- 編碼能力更強: SWE-bench Verified +6.8pt
- 視覺理解更強: 3.75MP 高分辨率
- 工具調用更準: MCP-Atlas 領先
- 成本更高: Tokenizer 膨脹 0-35%
所以短上下文場景下,選擇依據主要是任務類型,不再是長上下文能力。編碼選 4.7,寫作選 4.6,這是目前最簡單的判斷。
Q6: 有沒有辦法讓 4.7 在長上下文上追平 4.6?
目前沒有配置級的解決方案。即使調高 reasoning-effort 到 max,4.7 的 MRCR 分數仍然明顯低於 4.6。
可行的間接方案有兩個:
- RAG 分塊: 把長上下文切成 32k-64k 的分塊,讓 4.7 在"安全區"工作
- 多模型串聯: 用 4.6 做長上下文檢索,把檢索結果再餵給 4.7 做綜合推理
第二種方案可以通過 API易 apiyi.com 平臺的多模型接口快速實現,該平臺支持多種主流模型的統一接口調用。
Claude Opus 4.7 長上下文倒退總結
Claude Opus 4.7 的長上下文能力倒退是一個有官方數據支撐、有社區一手驗證、有明確影響範圍的真實問題。核心結論:
- 官方數據已承認: MRCR v2 8-needle 在 256k 和 1M 上分別腰斬,Anthropic 系統卡明確推薦保留 4.6 作爲回退
- 根因是策略性權衡: Anthropic 爲了 Agent 編碼和視覺理解,犧牲了長距離注意力精度
- 影響範圍集中在 128k+ 場景: 短上下文下 4.7 仍然可用,但超過 128k 後倒退呈非線性放大
- Opus 4.6 是當前最強長上下文模型: Rohan Paul 等老牌觀察者公認的結論,甚至超過 GPT-5.2
- 最佳應對是按場景路由: 長文檔走 4.6,編碼走 4.7,深度研究可以考慮 GPT-5.4 Pro
對用戶來說,正確的姿態不是"等 Anthropic 修復"——這次調整是策略性的,短期內不會回滾——而是立即在調用層做好多模型路由準備。把 4.6 作爲長上下文場景的默認選擇,把 4.7 留給它真正擅長的 Agent 編碼任務。
這也符合 2026 年 AI 產業的新趨勢: 單一模型覆蓋全場景的時代結束了,每個模型都在朝"專精某個方向"演化。對用戶的要求,是從"選一個最強模型"轉向"設計一套最合理的多模型路由"。
推薦通過 API易 apiyi.com 平臺統一管理 Claude 全系列模型調用,該平臺提供實時基準對比、多模型智能路由、與官方完全兼容的 API 接口,是應對 Opus 4.7 長上下文倒退問題的務實工具。
參考資料
-
Anthropic Opus 4.7 System Card: 官方 232 頁系統卡
- 鏈接:
anthropic.com/news/claude-opus-4-7 - 說明: 包含 MRCR v2 完整基準數據和遷移建議
- 鏈接:
-
Opus 4.7 System Card 深度解讀: DEV Community 社區分析
- 鏈接:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - 說明: 232 頁系統卡的程序員視角總結
- 鏈接:
-
Anthropic Migration Guide: Opus 4.7 遷移指南
- 鏈接:
platform.claude.com/docs/en/about-claude/models/migration-guide - 說明: 官方遷移建議與長上下文注意事項
- 鏈接:
-
Long-Context Benchmarks Leaderboard: 長上下文基準排行榜
- 鏈接:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - 說明: MRCR、RULER、LongBench v2 橫向對比
- 鏈接:
-
Rohan Paul X 評論: Opus 4.6 長上下文冠軍分析
- 鏈接:
x.com/rohanpaul_ai/status/2019545018051240059 - 說明: 獨立觀察者對 Opus 4.6 長上下文優勢的評價
- 鏈接:
作者: APIYI 技術團隊
發佈日期: 2026-04-18
適用模型: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
技術交流: 歡迎通過 API易 apiyi.com 獲取多模型測試額度,親測不同上下文長度下的檢索精度差異