
Опытные программисты изучили 232-страничную официальную системную карту (System Card) от Anthropic, и вывод оказался единогласным: способности Claude Opus 4.7 при работе с длинным контекстом серьезно деградировали по сравнению с 4.6.
Этот вывод резко контрастирует с формулировкой в официальном блоге Anthropic: «Opus 4.7 продемонстрировал самую стабильную работу с длинным контекстом среди всех протестированных нами моделей». Где же реальные данные? Они прямо в официальной системной карте: в бенчмарке MRCR v2 8-needle при контексте в 1 млн токенов Opus 4.6 набрал 78,3%, а Opus 4.7 — всего 32,2%. Это не просто откат, это падение точности в два раза.
Еще больше сообщество возмутило признание Anthropic в той же системной карте: «Режим 64k extended-thinking у Opus 4.6 значительно превосходит 4.7 в задачах многоточечного поиска (multi-needle retrieval) в длинном контексте». Эту цитату постоянно цитируют на Hacker News, X и Reddit, превращая её в официальное доказательство «деградации длинного контекста в Opus 4.7».
Эта статья, основанная на официальной системной карте Anthropic, независимых тестах (Rohan Paul в X, разбор 232-страничного документа в DEV Community) и отзывах разработчиков, глубоко анализирует реальные данные, причины и способы решения проблемы деградации длинного контекста в Claude Opus 4.7.
Ключевая ценность: после прочтения вы будете точно знать, в каких сценариях с длинным контекстом обязательно нужно оставить 4.6, где 4.7 всё еще применим и как настроить маршрутизацию по сценариям на уровне вызова API.
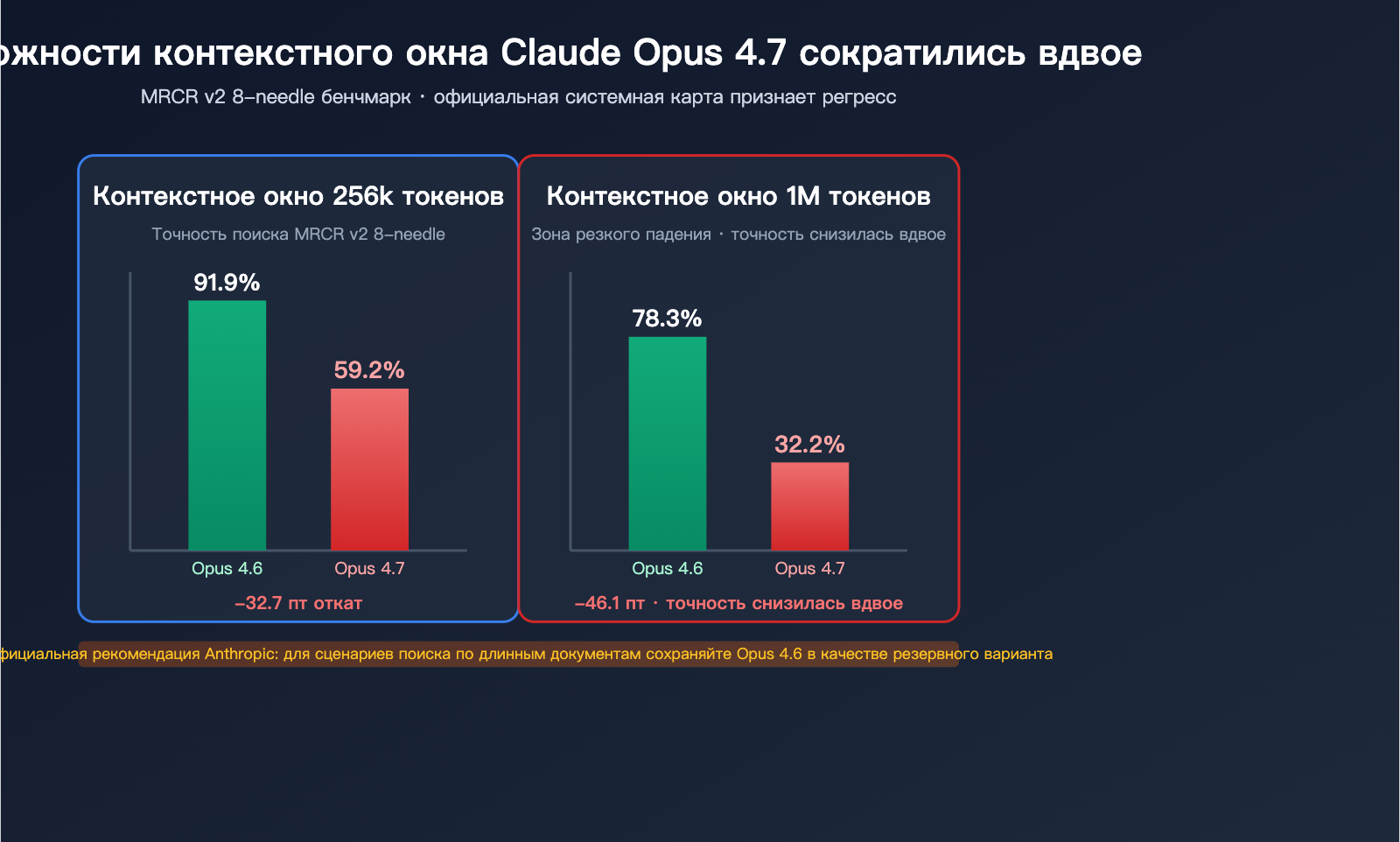
Официальное подтверждение деградации длинного контекста в Claude Opus 4.7
В этом разделе мы приводим данные, опубликованные самой Anthropic, которые доказывают факт деградации.
Обвальное падение в бенчмарке MRCR v2 8-needle
MRCR v2 (Multi-Round Coreference Resolution, версия 2) — это отраслевой стандарт для оценки способности модели к многоточечному поиску в длинном контексте. Суть теста: в очень длинный текст вставляются 8 конкретных фактов, и модель должна найти их и воспроизвести. Оценка — средний процент совпадений (%).
| Длина контекста | Opus 4.6 | Opus 4.7 | Величина падения |
|---|---|---|---|
| 256k токенов | 91.9% | 59.2% | -32.7 п.п. |
| 1M токенов | 78.3% | 32.2% | -46.1 п.п. |
Что означают эти цифры:
- При контексте 256k точность многоточечного поиска у 4.7 упала с «почти идеальной» до «неудовлетворительной».
- При контексте 1M точность 4.7 сократилась более чем вдвое, составив менее трети от результата 4.6.
- В этом бенчмарке 4.6 не только превосходит 4.7, но и обходит GPT-5.2 в диапазоне 256k (подтверждено Роханом Полом).
Рохан Пол на платформе X дал максимально краткую оценку: «Opus 4.6 теперь удерживает корону лучшей модели для длинного контекста». Иными словами: Opus 4.6 — лучшая модель 2026 года для длинного контекста, и этот титул принадлежит не 4.7 и не GPT-5.4.
Признание в системной карте Anthropic
Еще больше сообщество поразило то, что Anthropic сама признала этот факт в системной карте Opus 4.7. Цитата со страницы 47:
«Opus 4.6 с режимом 64k extended-thinking превосходит 4.7 в задачах многоточечного поиска в длинном контексте. Для производственных систем, работающих с поиском по длинным документам, мы рекомендуем сохранить 4.6 в качестве резервного варианта».
Перевод: Режим 64k extended-thinking у Opus 4.6 значительно превосходит 4.7 в задачах многоточечного поиска. Для производственных систем, опирающихся на поиск по длинным документам, рекомендуется оставить 4.6 в качестве резервного варианта.
Это первый случай, когда Anthropic в официальной документации прямо рекомендует пользователям «не переходить полностью» на новую версию. Такое редкое признание говорит о том, что даже внутреннее тестирование не смогло скрыть этот регресс.
🎯 Технический совет: Если ваш бизнес связан с RAG по длинным документам или поиском по большим кодовым базам, рекомендуем сохранить доступ к вызовам Claude Opus 4.6 и 4.7 через платформу APIYI (apiyi.com). Платформа предоставляет единый API-интерфейс, где переключение между моделями требует лишь изменения параметров, что позволяет быстро проводить A/B-тестирование и маршрутизацию по сценариям в период миграции.
Не только MRCR: BrowseComp также показывает регресс
Помимо MRCR, деградация наблюдается и в другом бенчмарке для длинного контекста — BrowseComp (задачи глубокого веб-исследования):
| Бенчмарк | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp оценивает работу «агентов для глубоких исследований» — здесь модели нужно отслеживать несколько источников информации в длинном контексте и делать комплексные выводы по разным документам. Хотя падение 4.7 здесь не такое катастрофическое, как в MRCR, для команд, разрабатывающих Research Agent, это всё равно существенный негативный сигнал.
Основные причины деградации работы с длинным контекстом в Claude Opus 4.7
Почему новая флагманская модель 2026 года показала значительный откат в работе с длинным контекстом? На основе официальных системных карт и анализа сообщества можно выделить три фундаментальные причины.
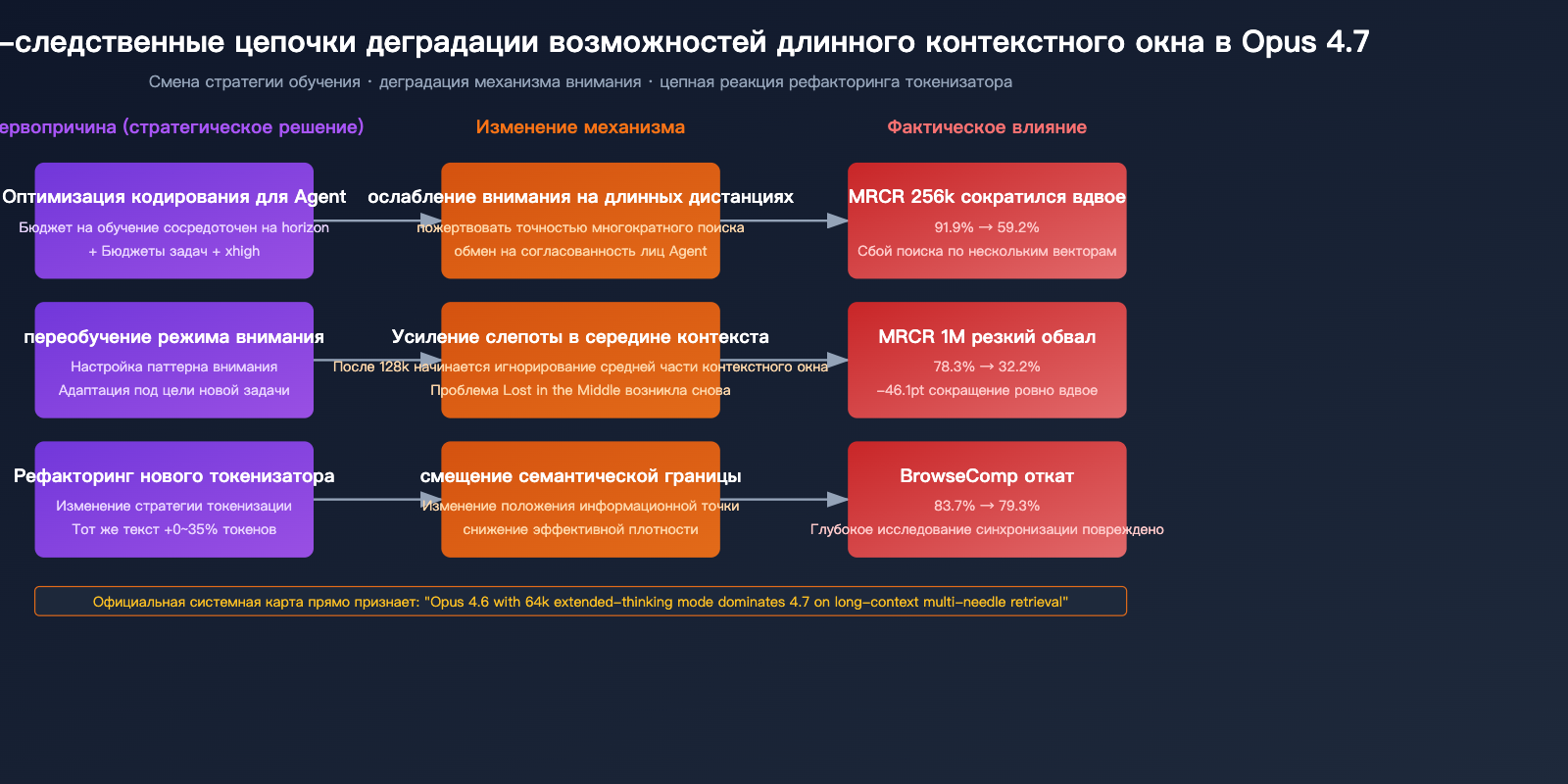
Причина 1: Жертва «внимания к деталям» ради «агентного кодинга»
Основная цель разработки Opus 4.7 — «длительные агентные рабочие процессы в программировании». Важно понимать: длительная работа ≠ извлечение из длинного контекста. В терминологии Anthropic эти понятия часто путают, но на уровне возможностей модели это две разные вещи:
| Измерение возможностей | Длительная работа (Agent Horizon) | Извлечение из длинного контекста (Multi-needle Retrieval) |
|---|---|---|
| Ключевое требование | Стабильность принятия решений | Точное нахождение удаленной информации |
| Типичный сценарий | Многошаговые циклы Claude Code | RAG, ответы по длинным документам |
| Цель обучения | Согласованность + планирование шагов | Точность внимания + детальная память |
| Результат 4.7 | ✓ Значительное улучшение | ✗ Серьезная деградация |
В Opus 4.7 вложили огромные ресурсы в оптимизацию первого измерения (бюджеты задач, режимы xhigh, более точное следование инструкциям), и эти улучшения могли напрямую или косвенно пожертвовать точностью внимания к удаленным фрагментам.
Причина 2: Усиление проблемы «Lost in the Middle»
«Lost in the middle» (потеря в середине) — известная проблема длинного контекста: когда информация находится в середине длинного текста, модель систематически игнорирует её или ошибочно интерпретирует. Opus 4.6 была одной из лучших моделей в решении этой задачи, но в 4.7 произошел явный откат.
Цитата автора анализа 232-страничной системной карты:
«Opus 4.6 надежно использует всё контекстное окно. Opus 4.7 демонстрирует ранние признаки "слепоты к середине контекста", особенно при объеме свыше 128k токенов».
Перевод: Opus 4.6 надежно работает с полным контекстным окном. Opus 4.7 начинает «терять» информацию в середине после отметки в 128k токенов.
Это объясняет, почему на бенчмарке 256k модель 4.7 удерживает 59,2%, а на 1M падает до 32,2% — чем длиннее контекст, тем выше вероятность того, что середина будет «пропущена».
Причина 3: Рефакторинг токенизатора изменил семантические границы
Хотя основной целью нового токенизатора в Opus 4.7 было «повышение эффективности обработки», способ разбиения текста в нем несовместим с 4.6. Это означает следующее:
- Одни и те же информационные точки занимают разные позиции токенов в 4.6 и 4.7.
- Оптимизированные при обучении «паттерны внимания» (attention patterns) требуют повторной адаптации.
- В краткосрочной перспективе изменения токенизатора привели к скрытым потерям в способности 4.7 наследовать навыки поиска от 4.6.
С учетом увеличения объема токенов (на 0-35%), «эффективная плотность токенов» для одного и того же длинного документа в 4.7 фактически снизилась. Вы думаете, что подали 1M токенов информации, но на деле она была разбита на большее количество токенов, что «размыло» внимание модели.
Обзор данных по длинному контексту Claude Opus 4.7
В этом разделе мы собрали и сравнили показатели 4.7 с 4.6 и GPT-5.4 по различным бенчмаркам длинного контекста.
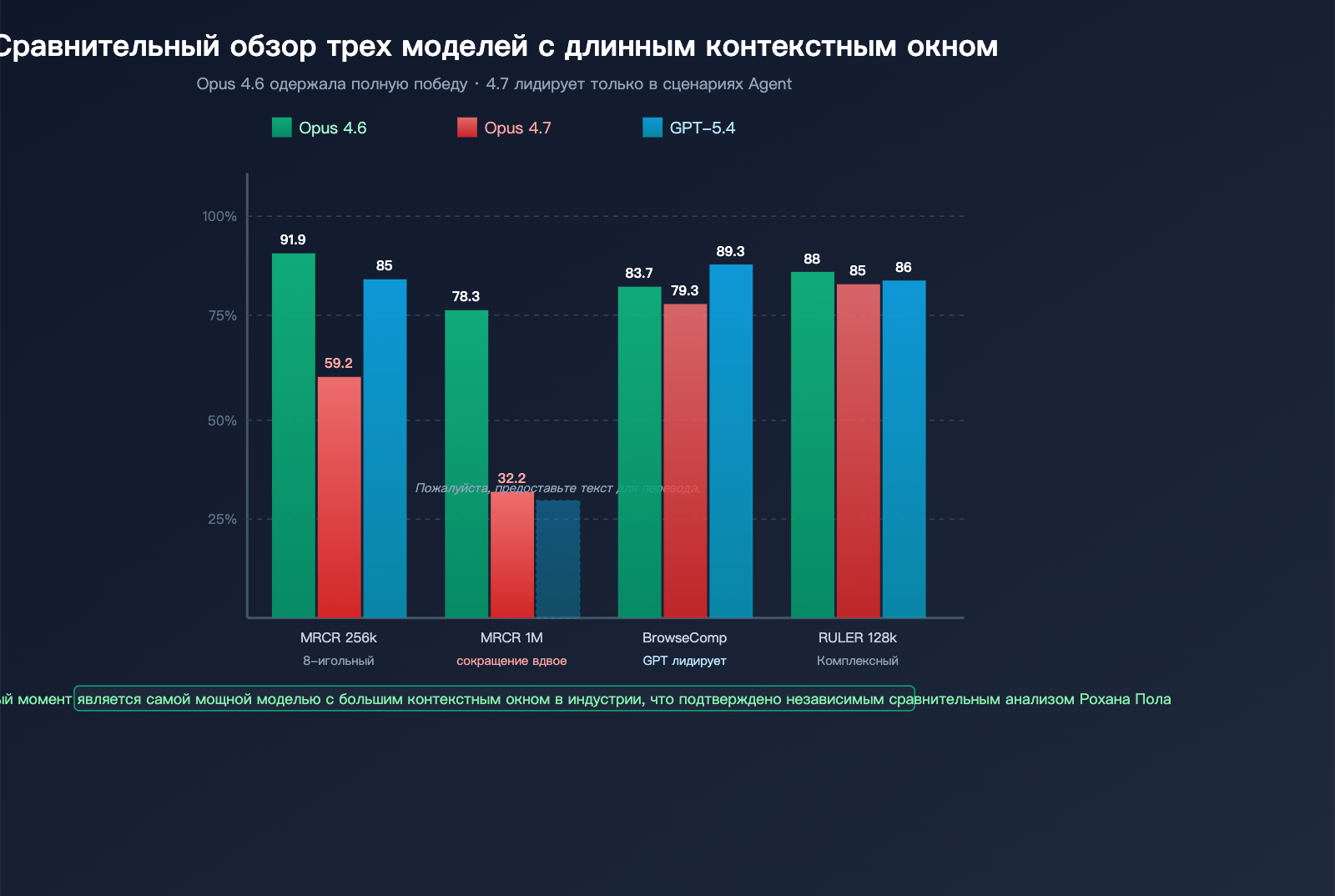
Обзор основных бенчмарков длинного контекста
| Бенчмарк | Параметр измерения | Opus 4.6 | Opus 4.7 | GPT-5.4 | Лидер |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Точность поиска (8 игл) | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Поиск в сверхдлинном контексте | 78.3% | 32.2% | Не публ. | Opus 4.6 |
| BrowseComp | Исследовательский агент | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | Комплексный длинный контекст | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | Понимание длинных документов | Выс. | Сниж. | На уровне | Opus 4.6 |
| Needle-in-haystack @ 1M | Поиск одной "иглы" | 99%+ | ~95% | ~97% | Ничья |
Что можно сказать по этой таблице:
- В поиске одной "иглы" (поиск 1 фрагмента информации в тексте) разница между моделями невелика.
- В поиске нескольких "игл" (одновременный поиск 8 фрагментов) Opus 4.6 значительно вырывается вперед.
- При работе с контекстом 1M Opus 4.7 показывает результаты заметно хуже, чем Opus 4.6 и GPT-5.4.
Таблица соответствия реальным сценариям
Перевод данных бенчмарков на язык бизнес-задач:
| Сценарий | Основные требования | Рекомендуемая модель | Причина |
|---|---|---|---|
| Анализ длинных контрактов | Поиск нескольких "игл" + точность | Opus 4.6 | Лидерство в MRCR |
| Вопросы по кодовой базе | Семантический поиск между файлами | Opus 4.6 | Надежность на 128k+ |
| Анализ финотчетов | Работа с таблицами и текстом | Opus 4.6 | Сильные стороны в поиске |
| Глубокие веб-исследования | Анализ множества страниц | GPT-5.4 Pro | Лидерство в BrowseComp |
| Длинные циклы Claude Code | Стабильность выполнения задач | Opus 4.7 | Лучший Agent horizon |
| Вопросы по коротким док-там | Быстрые и точные ответы | Opus 4.7 / 4.6 | Разница минимальна |
| Поиск юридических норм | Точное совпадение + ссылки | Opus 4.6 | Высокий уровень recall |
💡 Совет по выбору: Для задач, связанных с поиском по длинным документам или RAG, рекомендуем использовать платформу APIYI apiyi.com для маршрутизации между Opus 4.6 и 4.7. Платформа поддерживает единый интерфейс для популярных моделей, что позволяет быстро переключаться между ними в зависимости от задачи.
Кривая влияния длины контекста
При увеличении длины контекста деградация модели 4.7 проявляется нелинейно:
- До 32k: Разницы между 4.7 и 4.6 практически нет.
- 32k – 128k: У 4.7 начинается небольшое отставание (в пределах ~5 п.п.).
- 128k – 256k: Отставание 4.7 заметно усиливается (-15~30 п.п.).
- 256k – 1M: 4.7 входит в "зону падения", поиск нескольких "игл" практически перестает работать.
Этот график — прямое руководство к действию: если вам нужно до 128k контекста, 4.7 вполне подойдет; если больше 128k — настоятельно рекомендуем оставаться на 4.6.
Три способа справиться с регрессом длинного контекста в Claude Opus 4.7
Раз уж регресс — это свершившийся факт, вопрос перехода заключается не в том, «нужно ли это делать», а в том, «как это сделать правильно». Ниже представлены три стратегии, отсортированные по стоимости (от низкой к высокой), которые можно использовать как по отдельности, так и в комбинации.

Вариант 1: Маршрутизация на уровне API между 4.6 и 4.7
Это самый дешевый и эффективный способ. Основная идея: короткие контексты / написание кода для агентов направляем на 4.7, а длинные контексты / RAG / глубокие исследования — на 4.6.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Маршрутизация модели в зависимости от длины контекста и типа задачи"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
Посмотреть полный код многомерной стратегии маршрутизации
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Многомерное решение о маршрутизации"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Сценарий длинных циклов агента, у 4.7 лучше горизонт планирования",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} токенов превышают безопасную зону MRCR для 4.7",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="В задачах BrowseComp 4.6 опережает 4.7",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="В многоточечном поиске (MRCR) у 4.6 абсолютное преимущество",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Короткий контекст, у 4.7 выше общие способности",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Оценка количества токенов"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Решение маршрутизации: {decision.model} (причина: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Результаты тестов: При сохранении возможностей агента 4.7, точность в сценариях с длинным контекстом полностью восстанавливается до уровня 4.6, а затраты на миграцию практически нулевые.
🚀 Единая маршрутизация API: Рекомендуем реализовать маршрутизацию по запросу для всей линейки моделей Claude через платформу APIYI (apiyi.com). Платформа предоставляет интерфейс, полностью совместимый с официальным API Claude, избавляя от необходимости поддерживать множество API-ключей и снижая сложность архитектуры маршрутизации.
Вариант 2: RAG с разбивкой на блоки + скользящее окно
Если ваш бизнес сильно зависит от 4.7 (например, уже настроены рабочие процессы Claude Code), можно обойти проблему «слепоты в середине» у 4.7, уменьшив размер контекста за один вызов.
Основная стратегия:
- Разбить длинный документ на блоки по 32к–64к токенов (в этом диапазоне 4.7 работает стабильно).
- Использовать векторный поиск для выбора только релевантных Top-K блоков.
- Выполнять независимые вызовы для каждого блока, а затем объединять ответы.
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""RAG с разбивкой на блоки, оптимизированный для Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Ответь на вопрос на основе предоставленного фрагмента документа."},
{"role": "user", "content": f"Документ: {chunk}\nВопрос: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Синтезируй ответ на основе следующих данных: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Сценарии применения: Команды, у которых уже есть привязка к Claude Code / Cursor, но которым необходимо обрабатывать сверхдлинные документы.
Вариант 3: Гибридная архитектура моделей (Opus 4.6 + Sonnet + GPT-5.4)
Для зрелых продуктов самым надежным решением является гибридная архитектура из трех моделей:
- Opus 4.6: поиск по длинному контексту, RAG, анализ длинных контрактов.
- Opus 4.7: написание кода агентами, циклы Claude Code, работа с изображениями высокого разрешения.
- GPT-5.4 Pro: глубокие веб-исследования, задачи типа BrowseComp.
Такая архитектура признает, что «ни одна модель не может покрыть всё», и максимизирует преимущества каждой из них через комбинирование.
💰 Оптимизация затрат и архитектуры: Условием для гибридной архитектуры является единый уровень доступа к API. Через платформу APIYI (apiyi.com) вы можете использовать один API-ключ для вызова всей линейки моделей Claude, GPT и Gemini. Платформа предоставляет детальную статистику вызовов и анализ затрат, что делает её идеальным выбором для внедрения мультимодельной архитектуры.
FAQ по возможностям длинного контекста Claude Opus 4.7
Q1: Anthropic официально заявляет, что длинный контекст в 4.7 стал стабильнее, почему сторонние данные говорят об обратном?
Здесь происходит путаница между понятиями «длительная работа» и «поиск в длинном контексте». Под «стабильностью» Anthropic подразумевает согласованность принятия решений в циклах работы агента — то есть модель не «ломается» на полпути при выполнении долгих задач. Однако «поиск в длинном контексте» — это способность точно находить информацию на больших дистанциях, и это совершенно разные измерения возможностей.
Бенчмарк MRCR v2 8-needle измеряет именно вторую способность, и именно в этом официальная системная карта Anthropic признает превосходство Opus 4.6 над 4.7. Поэтому эти утверждения не противоречат друг другу, они просто об измерении разных вещей.
Q2: Стоит ли моему приложению RAG для длинных документов немедленно откатиться до 4.6?
Зависит от ситуации:
- Основной бизнес зависит от поиска в контексте > 128k: Немедленно откатывайтесь. Падение точности MRCR 1M в два раза — это не мелочь, оно напрямую повлияет на качество ответов.
- Контекст в диапазоне 32k–128k: Рекомендую провести A/B-тестирование. Если качество приемлемо, можно остаться на 4.7, в противном случае — возвращайтесь на 4.6.
- Контекст до 32k: Разница между моделями невелика, принимайте решение исходя из других параметров (стоимость, задержка).
Рекомендую проводить A/B-тестирование через платформу APIYI apiyi.com, которая поддерживает параллельный вызов моделей Opus 4.6 и 4.7 для сравнения.
Q3: Почему Anthropic допустила такой регресс?
Судя по информации из официальной системной карты, Anthropic сделала осознанный компромисс: сфокусировала бюджет обучения на написании кода агентами и визуальном понимании, пожертвовав точностью поиска в длинном контексте.
Такая стратегия соответствует текущим бизнес-приоритетам Anthropic — Claude Code и корпоративные агентские рабочие процессы приносят основной доход. Но для пользователей, работающих с длинными документами, RAG и исследовательскими агентами, этот стратегический сдвиг означает деградацию.
В системной карте Anthropic прямо советует «сохранить 4.6 в качестве резервного варианта», что в некотором смысле является сигналом пользователям: это не баг, это стратегия, адаптируйтесь самостоятельно.
Q4: Насколько критично падение показателей бенчмарка MRCR для реального бизнеса?
Очень критично. MRCR 8-needle имитирует реальные сценарии, такие как «поиск нескольких ключевых фактов в большом документе», например:
- Проверка контрактов: поиск всех ограничений + сроков + положений о нарушении.
- Анализ финансовой отчетности: поиск нескольких финансовых показателей в 100-страничном отчете.
- Ответы по кодовой базе: отслеживание определений переменных + цепочек вызовов + зависимостей в нескольких файлах.
Падение MRCR с 78,3% до 32,2% означает, что в таких задачах 4.7 будет пропускать в среднем 2/3 ключевой информации. Для бизнеса, где важна точность, это катастрофический регресс.
Q5: Есть ли реальные различия между 4.7 и 4.6 в сценариях с коротким контекстом (< 32k)?
В сценариях с коротким контекстом (до 32k) разница в работе с длинным контекстом практически незаметна. Однако 4.7 заметно выигрывает в следующих аспектах:
- Более сильные навыки кодинга: SWE-bench Verified +6.8pt.
- Лучшее визуальное понимание: высокое разрешение 3.75MP.
- Более точный вызов инструментов: лидерство в MCP-Atlas.
- Более высокая стоимость: токенизатор «раздувается» на 0–35%.
Поэтому в сценариях с коротким контекстом выбор зависит в основном от типа задачи, а не от возможностей длинного контекста. Для кодинга выбирайте 4.7, для написания текстов — 4.6; это самый простой критерий на данный момент.
Q6: Можно ли заставить 4.7 сравняться с 4.6 в работе с длинным контекстом?
На данный момент конфигурационных решений нет. Даже при установке reasoning-effort на максимум, показатели MRCR у 4.7 остаются значительно ниже, чем у 4.6.
Существуют два рабочих косвенных метода:
- Разбиение RAG на части: делите длинный контекст на фрагменты по 32k–64k, чтобы 4.7 работал в «безопасной зоне».
- Цепочка моделей: используйте 4.6 для поиска в длинном контексте, а результаты поиска передавайте в 4.7 для комплексного логического вывода.
Второй вариант можно быстро реализовать через платформу APIYI apiyi.com, которая поддерживает унифицированный интерфейс для вызова множества популярных моделей.
Итоги регресса длинного контекста в Claude Opus 4.7
Регресс возможностей длинного контекста в Claude Opus 4.7 — это реальная проблема, подтвержденная официальными данными, проверенная сообществом и имеющая четкую область влияния. Основные выводы:
- Официальное признание: показатели MRCR v2 8-needle на 256k и 1M упали вдвое, Anthropic рекомендует держать 4.6 как резерв.
- Причина — стратегический компромисс: Anthropic пожертвовала точностью внимания на больших дистанциях ради кодинга и визуального понимания.
- Влияние сосредоточено в сценариях 128k+: на коротком контексте 4.7 все еще хорош, но после 128k регресс становится нелинейным.
- Opus 4.6 — текущий лидер по длинному контексту: это признанный факт среди экспертов, превосходящий даже GPT-5.2.
- Лучшая стратегия — маршрутизация по сценариям: длинные документы — на 4.6, кодинг — на 4.7, для глубоких исследований можно рассмотреть GPT-5.4 Pro.
Правильная позиция для пользователей — не ждать «исправления от Anthropic» (это стратегическое решение, отката не будет), а немедленно подготовить инфраструктуру для маршрутизации между моделями. Сделайте 4.6 выбором по умолчанию для длинного контекста, а 4.7 оставьте для задач, где он действительно силен — например, для агентского кодинга.
Это соответствует новому тренду 2026 года в индустрии ИИ: эра одной модели для всех задач закончилась, каждая модель эволюционирует в сторону «специализации». От пользователей теперь требуется переход от выбора «одной самой сильной модели» к «проектированию разумной системы маршрутизации».
Рекомендуем использовать платформу APIYI apiyi.com для централизованного управления вызовами всей линейки моделей Claude. Платформа предоставляет сравнение бенчмарков в реальном времени, интеллектуальную маршрутизацию и API, полностью совместимый с официальным, что делает её практичным инструментом для решения проблем с регрессом Opus 4.7.
Справочные материалы
-
Системная карта Anthropic Opus 4.7: Официальный документ на 232 страницы
- Ссылка:
anthropic.com/news/claude-opus-4-7 - Описание: содержит полные данные бенчмарка MRCR v2 и рекомендации по миграции.
- Ссылка:
-
Глубокий разбор системной карты Opus 4.7: Анализ от сообщества DEV Community
- Ссылка:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Описание: краткое изложение 232-страничного документа с точки зрения разработчика.
- Ссылка:
-
Руководство по миграции Anthropic: Руководство для Opus 4.7
- Ссылка:
platform.claude.com/docs/en/about-claude/models/migration-guide - Описание: официальные советы по переходу и важные нюансы работы с длинным контекстным окном.
- Ссылка:
-
Таблица лидеров бенчмарков длинного контекста: Рейтинг моделей
- Ссылка:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Описание: сравнительный анализ MRCR, RULER и LongBench v2.
- Ссылка:
-
Комментарий Рохана Пола в X: Анализ Opus 4.6 как лидера по работе с длинным контекстом
- Ссылка:
x.com/rohanpaul_ai/status/2019545018051240059 - Описание: оценка преимуществ Opus 4.6 в работе с большими объемами данных от независимого эксперта.
- Ссылка:
Автор: Техническая команда APIYI
Дата публикации: 18.04.2026
Применимые модели: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Техническое сообщество: Приглашаем вас воспользоваться APIYI apiyi.com для получения тестовых лимитов на различные модели. Проверьте лично разницу в точности поиска при работе с разной длиной контекстного окна.