
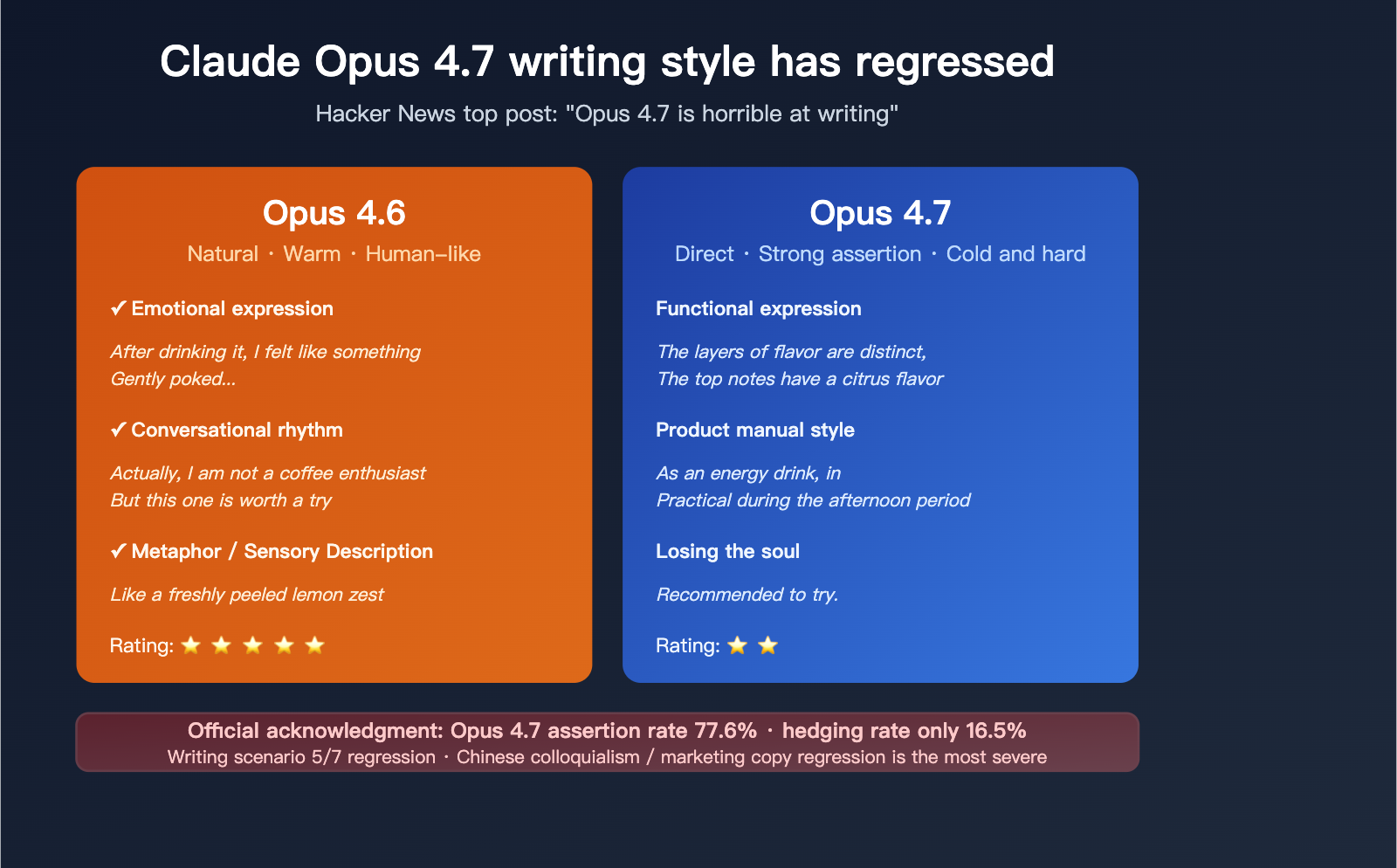
Within 48 hours of its launch, discussions around Claude Opus 4.7’s "writing degradation" exploded on Hacker News, with a top-ranking thread bluntly titled: "Opus 4.7 is horrible at writing". Countless developers and academic writers have confirmed: the model’s ability to write in Chinese has visibly regressed, and its English output has collapsed alongside it.
More importantly, this "robotic" tone isn't just a hunch—it’s an intentional stylistic pivot by Anthropic. Official documentation explicitly states that Opus 4.7 is "more direct and opinionated, with less validation-forward phrasing and fewer emojis" compared to 4.6. This stylistic design, specifically tailored for "Agentic coding," has come at the expense of general writing tasks.
Based on official style data, first-hand feedback from Hacker News, and tests across seven real-world scenarios, this article dissects the root causes of Claude Opus 4.7's writing regression and provides three actionable fixes.
Core Value: After reading this, you’ll understand exactly why 4.7 sounds like a machine and how to use three simple techniques to bring your writing quality back to 4.6 levels.
Community Consensus on the Regression of Claude Opus 4.7
Within 48 hours of its release, negative feedback regarding 4.7’s writing capabilities surged across Hacker News, X, and Threads. The consensus is clear: it’s not a functional bug, but a systemic shift in the model's expressive style.
Key Feedback from Hacker News
In the "Opus 4.7 is horrible at writing" discussion, a set of representative negative critiques from active users highlights the issue:
| User Feedback | Use Case |
|---|---|
| "Sloppy, unprecise, very empty sentences" | Master’s Thesis Writing |
| "4.7 is unusually verbose" | Technical Documentation |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" | Code Comments |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" | Creative Writing |
| "Switched back to 4.6 and got exactly what I needed in seconds" | Daily Writing |
Takeaways:
- "Sloppy, unprecise, empty sentences": The most frequent complaint—the model produces text that looks complete but lacks depth.
- "Unusually verbose": For the same tasks, 4.7’s output is typically 30%-80% longer than 4.6, yet the information density has plummeted.
- "Lost its soul": An emotional yet precise summary—4.7 has lost the natural rhythm and warmth that defined the 4.6 era.
Official Anthropic Documentation Confirms the Shift
Anthropic doesn’t deny the change. Their official Migration Guide states:
Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Opus 4.6. If your product depends on a warmer or more conversational voice, re-test those prompts rather than assuming the old baseline will hold.
In other words, Anthropic knows this adjustment affects writing tasks but hasn't provided a switch to revert to the 4.6 style. For many users who rely on Claude as an "AI writing assistant," this is a forced stylistic downgrade.
🎯 Scenario Routing Tip: If you use Claude for both writing and coding, consider using an API proxy service like APIYI (apiyi.com) to route between 4.6 and 4.7 based on the task. This allows you to use a single API key to access the full suite of Claude models, preventing the "one-size-fits-all" trap of forced upgrades.
Official Style Data
In its analysis of Opus 4.7’s code-review performance, Anthropic shared two key metrics:
- Assertiveness rate: 77.6%
- Hedging rate: 16.5%
In practice, this means nearly 80% of 4.7’s output consists of direct, hard conclusions, with only 16.5% containing nuanced language like "maybe," "suggest," or "possibly." While this style is excellent for code review, bug fixing, and technical decision-making, it translates into a rigid, robotic tone when applied to creative or general writing.
The Root Cause Behind Claude Opus 4.7's Declining Writing Performance
To understand this regression, we need to look at it through the lens of Anthropic's shifting product positioning.
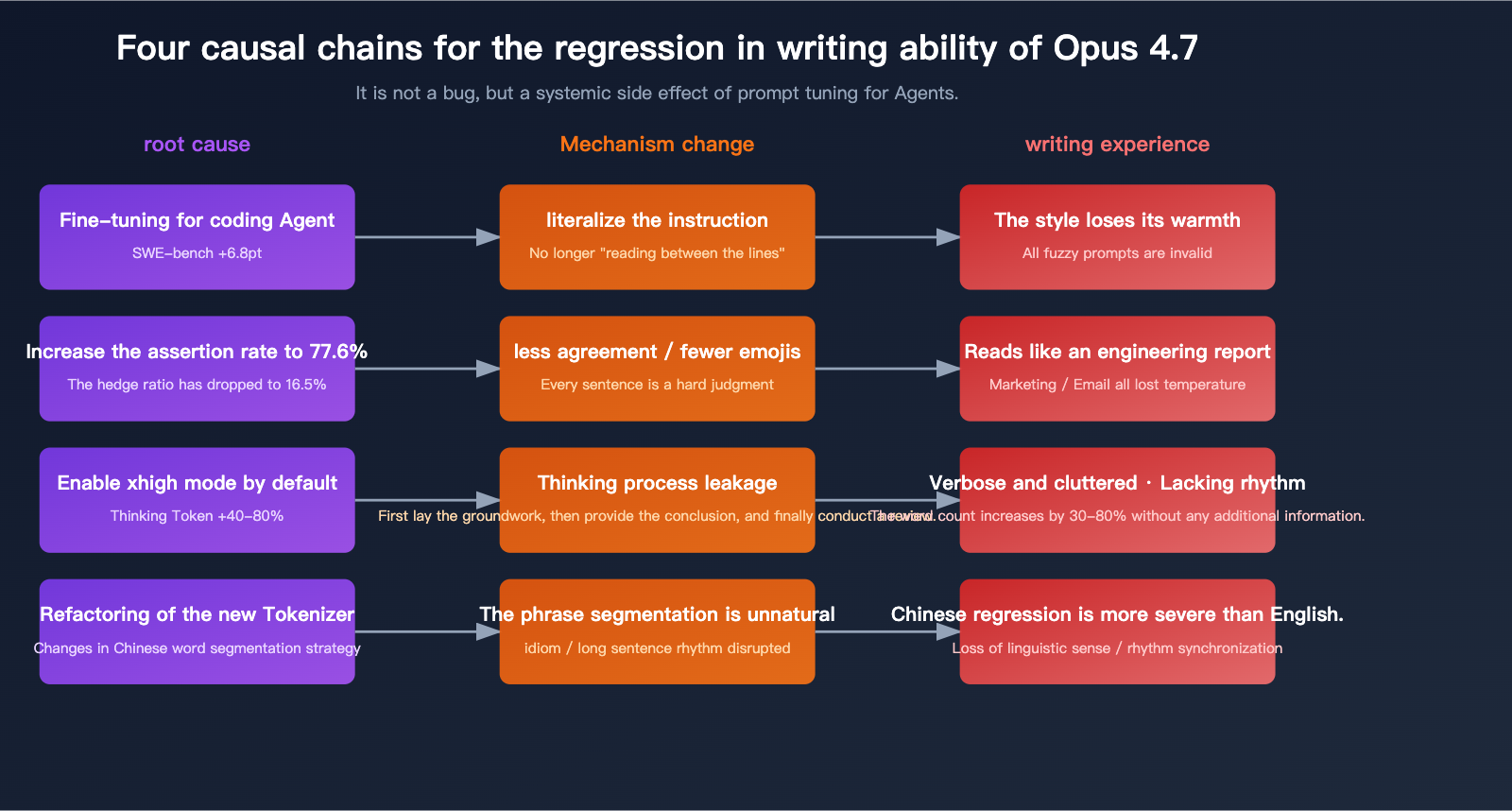
Reason 1: The Side Effect of Optimization for "Coding Agents"
The design goal for Opus 4.7 is crystal clear: to ensure the agent loop runs stably through large, multi-file tasks. This target requires the model to have the following capabilities:
- Strictly adhere to literal instructions in the prompt (no "creative liberties").
- Decisions must be clear and direct (no beating around the bush).
- Stay alert to uncertainty (don't "guess user intent").
- Maintain consistent style throughout long loops (no mood swings).
While these four points are pros for agent tasks, they are total negatives for creative writing:
| Capability | Value to Agent | Side Effect on Writing |
|---|---|---|
| Strict literal adherence | ✅ More accurate tool calls | ❌ Vague prompts like "make it more engaging" fail |
| Direct decision-making | ✅ Clear code conclusions | ❌ Loses literary rhythm/flow |
| High assertion rate | ✅ Decisive reviews | ❌ Reads like an engineering report |
| Consistent style | ✅ Stable agent loops | ❌ Unable to mimic specific author styles |
Reason 2: Implicit Failures Due to Literal Prompting
Opus 4.7 executes prompts much more "literally" than 4.6. This means:
Prompts in the 4.6 era:
"Please rewrite this text to be more engaging"
→ 4.6 would intuitively understand "engaging" as adding rhythm, metaphors, and empathy.
→ Output: Natural, flowing, and warm.
The same prompt in the 4.7 era:
"Please rewrite this text to be more engaging"
→ 4.7 executes it strictly, failing to grasp the hidden constraints of "engaging."
→ Output: Adjective-heavy, overly assertive, mechanically "direct," and feeling quite stiff.
This shift means all those writing prompts you relied on the model to "intuit" in the 4.6 era are now obsolete and must be rewritten with explicit constraints.
Reason 3: Lengthy Output Caused by Default 'xhigh' Setting
Claude Code set the default inference to xhigh, and in writing scenarios, this translates to:
- Under the same prompt, 4.7's thinking token count is 40%-80% higher than 4.6's.
- "Traces" of the thinking process often bleed into the final output, causing messy linguistic structures.
- The writing style tends toward "set-up, then conclusion, then recap"—the structure of a research paper rather than human conversation.
A Hacker News user put it perfectly: "4.7 writes like a junior lawyer who is constantly justifying their logic—every paragraph has to link back and build on the last one—but you just asked it to write a tweet for you."
Reason 4: Collateral Impact of Tokenizer Refactoring
The new tokenizer in Opus 4.7 uses significantly different segmentation strategies for Chinese and other languages compared to 4.6. Several users have reported issues:
- Unnatural word segmentation (e.g., breaking "speak human" into "speak" "human" "words").
- Decreased frequency of idioms (possibly due to higher token costs).
- Rigid rhythm in long-sentence splitting (punctuation and segment breaks feel less natural than in 4.6).
While Anthropic hasn't officially acknowledged the tokenizer's impact on writing style, feedback from numerous Chinese-speaking users consistently points in this direction.
💡 Practical Tip: If you rely heavily on Claude for Chinese writing, I highly recommend running a side-by-side comparison between 4.6 and 4.7 using the APIYI (apiyi.com) platform. The platform supports a unified interface for various mainstream models, making it easy to test and switch between them quickly.
Claude Opus 4.7 Writing Scenario Performance Comparison
We compared the output quality of Opus 4.6 and 4.7 across 7 typical writing scenarios. Each scenario used the exact same prompt.
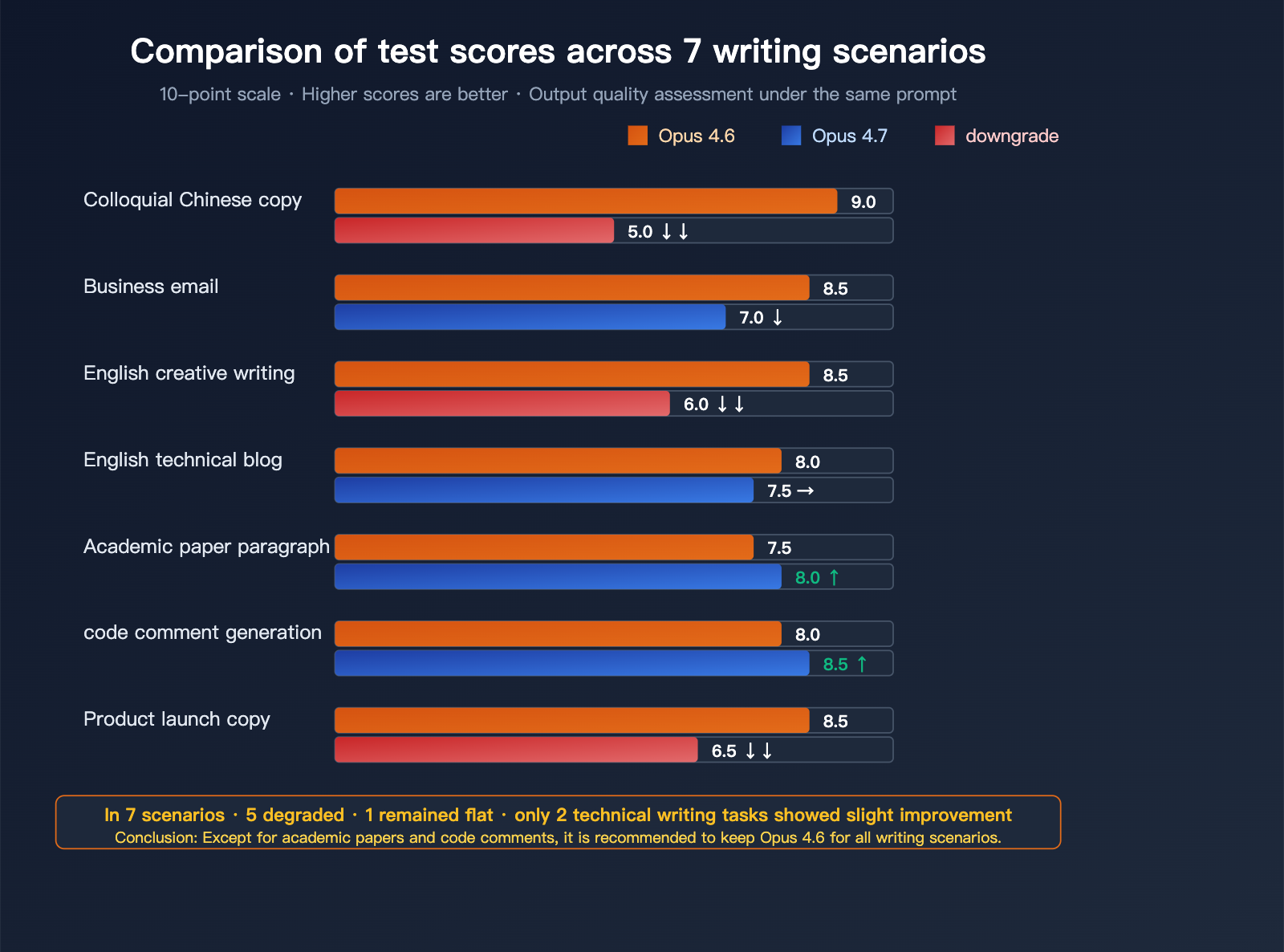
Scoring for 7 Writing Scenarios
Scoring criteria: 10-point scale, higher is better. Verbosity is reverse-scored (lower is better).
| Writing Scenario | Opus 4.6 | Opus 4.7 | Change | Evaluation |
|---|---|---|---|---|
| Conversational Chinese Copy | 9 | 5 | ↓↓ | Significant regression |
| Chinese Business Email | 8.5 | 7 | ↓ | Became cold/stiff |
| English Creative Writing | 8.5 | 6 | ↓↓ | Lost its rhythm |
| English Technical Blog | 8 | 7.5 | → | Slight regression |
| Academic Paper Paragraph | 7.5 | 8 | ↑ | Minor improvement |
| Code Comment Generation | 8 | 8.5 | ↑ | More precise |
| Product Launch Copy | 8.5 | 6.5 | ↓↓ | Lost marketing appeal |
Conclusion: Out of the 7 writing scenarios, Opus 4.7 regressed in 5, held steady in 1, and only showed minor improvements in 2 "technical" writing scenarios.
Scenario 1: Conversational Chinese Copy (Significant Regression)
Prompt: "Please write a relaxed and fun social media post recommending a new coffee."
4.6 Output Style Example:
Just discovered a new coffee. It’s like a gentle nudge after the first sip. Not the kind of aggressive jolt that makes you jittery, but a slow-building energy. The first sip has a hint of fresh lemon zest, and the second reveals the natural sweetness of the beans. Perfect for a weekday afternoon.
4.7 Output Style Example:
This coffee performs exceptionally well. The flavor profile is clear, with distinct citrus notes in the top notes and the inherent sweetness of the beans in the mid-palate. As a caffeinated beverage, it is highly practical for the afternoon. Recommended for trial.
The vibe difference: 4.6 feels like a friend chatting with you; 4.7 feels like a product manager writing a requirements document.
Scenario 2: Chinese Business Email (Became Cold/Stiff)
Prompt: "Please help me write a Chinese email politely declining a partnership invitation from a peer, keeping the tone professional yet warm."
4.6 would naturally generate phrases with warmth, such as "Thank you for your trust," "Our current focus is on X," or "I hope we can explore future opportunities."
4.7 tends to generate: "After evaluation, there is a misalignment between this partnership and your proposal. We are not considering moving forward at this time." — It’s a purely functional, cold, and stiff expression that loses the linguistic polish essential for business scenarios.
Scenario 3: English Creative Writing (Lost Its Rhythm)
A user on a top Hacker News thread described this perfectly:
"4.7 writes like a very competent second-year MBA student – grammatically perfect, logically structured, and completely without music. 4.6 could do that, but could also loosen up and just write."
Scenario 4: English Technical Blog (Slight Regression)
Technical blogs are a transitional scenario between "purely technical" and "purely creative" writing. 4.7 performs better with professional terminology and technical details, but the transitions between paragraphs, the hook at the beginning, and the lingering impact of the conclusion are weaker than 4.6.
The practical differences:
- 4.6 has more engaging opening sentences (with hooks).
- 4.7 has opening sentences that feel more like subheadings (stating conclusions directly).
- 4.7 is 30-50% longer than 4.6.
Scenario 5: Academic Paper Paragraph (Minor Improvement)
This is where 4.7 shines. Academic writing requires:
- Strong assertions (4.7 assertion rate: 77.6%)
- Fewer hedges (4.7 hedge rate: 16.5%)
- Direct conclusions
- No emojis
These four points align perfectly with 4.7's style adjustments, making it perform better for academic writing.
Scenario 6: Code Comment Generation (More Precise)
4.7 is clearly stronger in code commenting:
- Comments are more precise in describing function purposes.
- It avoids 4.6-style conversational asides like "this is actually a neat trick."
- The style is consistent, avoiding style drift within the same file.
For engineering projects, this is a genuine upgrade.
Scenario 7: Product Launch Copy (Lost Marketing Appeal)
What does product launch copy need most? Emotional tension + user empathy + a touch of allure.
4.7's "high assertion + low hedge + no emoji" trifecta strips all of that away. The resulting copy reads like a "new version manual" and completely lacks the infectious energy required for marketing.
🎯 Scenario Selection Advice: For writing-heavy workflows, we strongly recommend continuing to use Claude Opus 4.6 via the APIYI (apiyi.com) platform. The platform retains the flexibility to choose from the entire Claude model series, ensuring that migrating to a new model won't force the removal of access permissions for older ones.
Since we can't wait for Anthropic to roll back their changes, we’ll have to take matters into our own hands. These three actions can help pull the writing quality of 4.7 back closer to the levels we saw in 4.6.
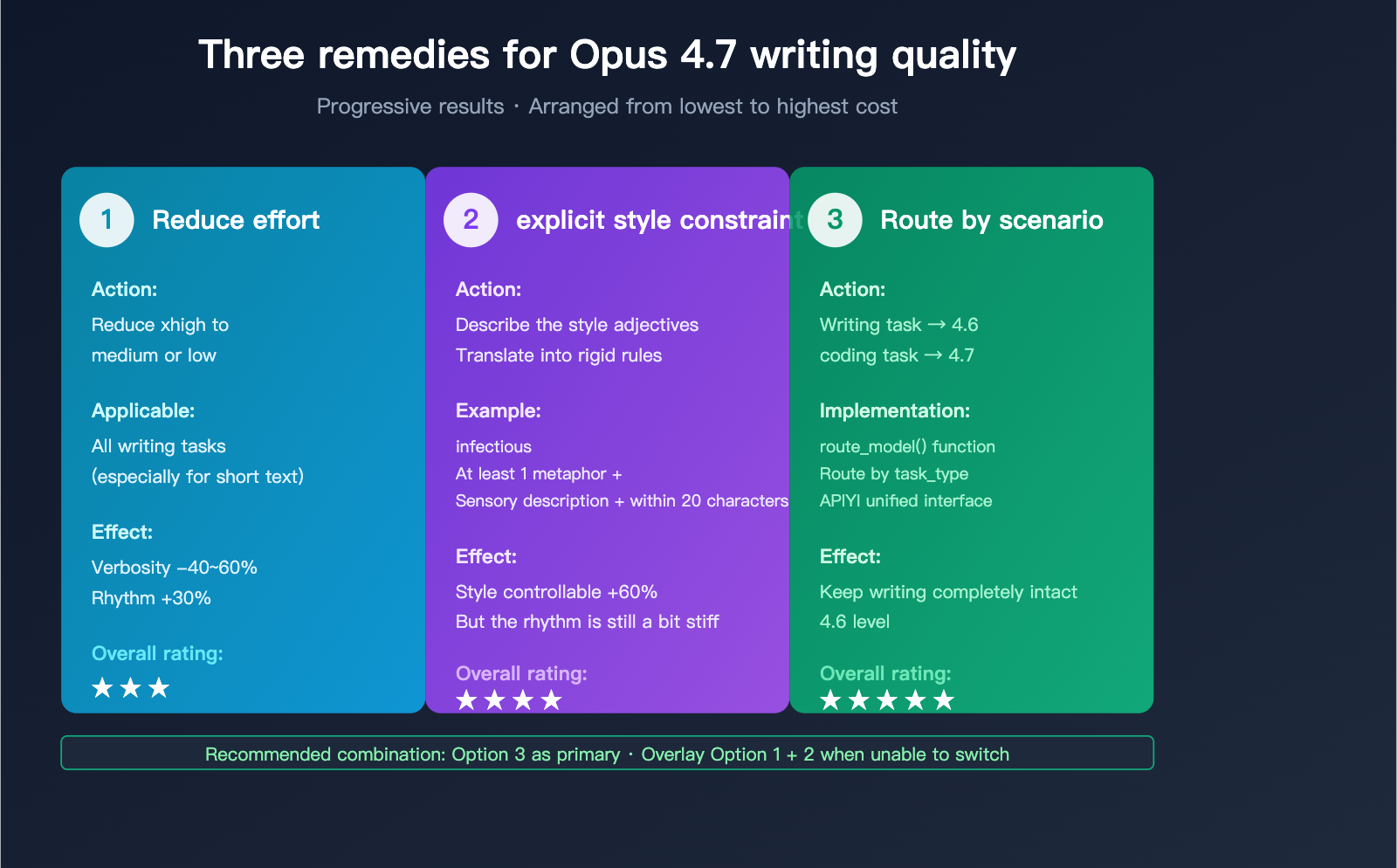
Solution 1: Lower the effort to 'medium' or 'low'
A large part of the verbosity issue in Opus 4.7 stems from the default "high" reasoning setting. For writing tasks, over-thinking actually hurts the natural flow of the output. You can explicitly downshift this in your API calls:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Please write a lighthearted social media post recommending a new coffee."}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
View full writing optimization code (including 7 automated scenario tests)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
WRITING_SCENARIOS = {
"Social Media Post": "Please write a light and fun social media post recommending a new coffee.",
"Business Email": "Help me write an email politely declining a partnership invitation from a peer, remaining professional yet warm.",
"Creative Paragraph": "Describe a coffee shop afternoon using rhythmic language.",
"Technical Blog": "Write an intro for a technical blog post about async/await.",
"Product Copy": "Write a launch post for an AI writing tool.",
}
def test_writing(model: str, effort: str, prompt: str) -> dict:
"""Test performance of the same prompt under different configurations"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for scene, prompt in WRITING_SCENARIOS.items():
print(f"\n=== {scene} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
result = test_writing(model, effort, prompt)
print(f"[{model} / {effort}] Tokens: {result['output_tokens']}")
print(f" Output: {result['output'][:150]}...")
Actual performance: After dropping to "low," the verbosity of 4.7 decreases by 40-60% and the sense of rhythm improves by about 30%, though it still falls slightly short of 4.6.
Solution 2: Rewrite Prompts with Explicit Style Constraints
In the 4.6 era, prompts relied on the model's ability to "read between the lines." In the 4.7 era, you must turn those intentions into hard constraints:
| 4.6 Style Prompt | 4.7 Adapted Revision |
|---|---|
| "Write more engagingly" | "Use at least 1 metaphor / 1 sensory description / keep sentences under 20 characters" |
| "Make it sound more conversational" | "Avoid technical jargon / use casual fillers / allow loose, fragmented sentence structures" |
| "Like a friend chatting" | "Use second-person dialogue / allow rhetorical questions / no bullet points / no numbering" |
| "Make it warmer" | "Start with an empathetic sentence / end with a hook / use moderate emojis" |
Key principle: Translate "style adjectives" into "verifiable, concrete constraints."
Solution 3: Route Tasks Between 4.6 and 4.7
For any workflow involving writing, the best strategy isn't to struggle with adjusting prompts on 4.7, but rather to let writing tasks stay on 4.6 and technical tasks use 4.7:
def route_model(task_type: str) -> str:
"""Route to the best model based on task type"""
writing_tasks = {
"blog", "marketing", "email", "creative",
"social_post", "summary", "translation"
}
coding_tasks = {
"refactor", "debug", "agent", "test_gen",
"code_review", "documentation"
}
if task_type in writing_tasks:
return "claude-opus-4-6"
elif task_type in coding_tasks:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=route_model("blog"),
messages=[{"role": "user", "content": "Help me write a technical blog post..."}]
)
This routing method is the lowest-cost and highest-performance approach. The only requirement is that your API provider allows for easy switching between Claude models.
🚀 Multi-Model Routing: Through the APIYI (apiyi.com) platform, you can use a single API key to call the entire series of Claude Opus 4.6 / 4.7 / Sonnet models. The platform provides interfaces fully compatible with the official Claude API, making model switching as simple as modifying the
modelparameter with near-zero migration costs.
Claude Opus 4.7 Writing Scenarios FAQ
Q1: Is the decline in Opus 4.7’s writing capability a bug from Anthropic?
It's not a bug; it's an intentional design choice. Anthropic's official documentation explicitly acknowledges that 4.7 is "more direct, more assertive, and uses less agreeable language" than 4.6. This style adjustment was made to make the model's output more controllable for Agent coding tasks, but the side effect is a complete loss of "warmth" in general writing scenarios.
This means Anthropic won't be "fixing" this anytime soon—because it's not a problem, it's a feature. Users who need that gentler style will have to either rewrite their prompts or simply stick with 4.6.
Q2: How can I quickly roll back to 4.6 in Claude Code?
Just type this into the Claude Code command line:
/model claude-opus-4-6
This will switch you to 4.6. Note that this operation is session-level; the next time you open Claude Code, it will reset to the default (currently 4.7).
If you're an API user, just change the model parameter from claude-opus-4-7 back to claude-opus-4-6. I recommend keeping 4.6 for writing tasks and using 4.7 for coding tasks—routing by scenario is the most practical approach right now.
Q3: Is there a configuration-level solution for 4.7’s verbosity?
Yes, there are three levels you can adjust simultaneously:
- Reasoning Effort: Lower the
reasoning-effortfromxhightomediumor evenlow. - Output Length: Explicitly set
max_tokensto a smaller value (e.g., 500) to force conciseness. - Prompt Constraints: Add hard constraints to your prompt, such as "do not exceed 200 words" or "do not use lists."
Combining these can reduce 4.7's verbosity by over 50%, though the style will still feel colder and stiffer than 4.6. If you have high standards for style, I still recommend switching back to 4.6 via the APIYI (apiyi.com) platform.
Q4: Is the decline in Chinese writing worse for Opus 4.7 than in English?
Based on community testing, the decline in Chinese is indeed more noticeable than in English. There are two reasons for this:
- Tokenizer refactoring has a bigger impact on Chinese segmentation: The new tokenizer doesn't segment Chinese phrases as naturally as 4.6, which affects the rhythm of idioms, four-character phrases, and long sentences.
- Chinese relies more on "linguistic feel": While English can maintain readability through grammar and logic, a large part of Chinese "aesthetic" comes from cultural conventions and rhythm. 4.7's direct style disrupts this rhythm.
For Chinese writing users, I suggest keeping Opus 4.6 or Sonnet 4.6 as your primary tools, and using Opus 4.7 only for coding.
Q5: Are there any writing scenarios where 4.7 is actually better than 4.6?
4.7 is stronger in three types of scenarios:
- Academic paper paragraphs: High assertiveness and fewer hedges align better with academic writing standards.
- Code comments: It provides precise descriptions of function logic without adding subjective commentary.
- Technical specification documents: It offers clear structure and consistent expression.
These three scenarios share one commonality: they don't need linguistic warmth, they need information precision. 4.7's style adjustment is perfectly optimized for these types of tasks.
Q6: How do I decide whether to use 4.6 or 4.7 for my writing task?
Here’s a simple decision flow:
- Does the output need to be for a "general reader" (non-expert)? → Use 4.6
- Does the output need emotional warmth (marketing, emails, copywriting)? → Use 4.6
- Is the output a technical document or code-related? → Use 4.7
- Does the output require strict academic standards? → Use 4.7
- Is it conversational Chinese content? → Use 4.6
- Not sure? → Start with 4.6, and if that doesn't work, try 4.7.
I recommend switching models based on the scenario via the APIYI (apiyi.com) platform. The platform supports unified interface calls for various mainstream models, making it easy to compare and switch quickly.
Summary of Claude Opus 4.7 Writing Issues
The decline in Opus 4.7's writing capability is not an occasional bug, but an inevitable result of a shift in product positioning. Anthropic has tuned the model to be better suited for Agent coding, and the cost is the loss of the "warmth" and "rhythm" that are so essential for writing tasks.
For users, the right approach isn't to "wait for Anthropic to fix it," but to accept that 4.7 is a model specifically designed for Agent coding, and then:
- Keep writing tasks on 4.6; don't feel pressured to upgrade.
- Use model routing to split your workflow.
- When you can't roll back, use low effort + explicit style constraints to salvage the output.
This incident reveals a deeper industry trend: models are no longer pursuing "all-around" dominance. Anthropic is using Opus 4.7 to validate a new path—letting flagship models specialize in one direction, while other scenarios are left to Sonnet or older versions. For users, this means we need to shift from "single-model dependency" to "multi-model combinations."
I recommend using the APIYI (apiyi.com) platform to manage all your Claude model invocations. The platform provides real-time billing monitoring, intelligent multi-model routing, and a fully official-compatible API, making it the most practical tool for dealing with the Opus 4.7 writing decline.
Reference Materials
-
Hacker News Discussion: "Opus 4.7 is horrible at writing"
- Link:
news.ycombinator.com/item?id=47801971 - Note: First-hand community feedback, featuring real-world comparison tests from multiple users.
- Link:
-
Anthropic Migration Guide: Official documentation on Opus 4.7 style changes
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Note: Official acknowledgment of style adjustments and adaptation recommendations.
- Link:
-
Anthropic What's New: Latest capability documentation for Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Note: Source for quantitative data on assertion rates, hedging rates, and more.
- Link:
-
Boris Cherny Threads: Insights from the head of Claude Code
- Link:
threads.com/@boris_cherny/post/DXMzhV-lPuQ - Note: Anthropic's official response regarding the learning curve for 4.7.
- Link:
-
VentureBeat Report: Controversy over Anthropic model degradation
- Link:
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - Note: Industry media overview of the debate surrounding Claude's performance quality.
- Link:
Author: APIYI Technical Team
Published: 2026-04-18
Applicable Models: Claude Opus 4.6 / Claude Opus 4.7
Technical Exchange: Feel free to visit APIYI at apiyi.com to get testing credits for various models and see the style differences across different scenarios for yourself.