
لقد قام كبار المبرمجين حول العالم بتمحيص بطاقة النظام الرسمية لشركة Anthropic المكونة من 232 صفحة، وكانت النتيجة موحدة وصادمة: قدرة Claude Opus 4.7 على التعامل مع السياق الطويل تراجعت بشكل حاد مقارنة بإصدار 4.6.
هذا الاستنتاج يتناقض بشكل صارخ مع ما ورد في مدونة Anthropic الرسمية التي زعمت أن "Opus 4.7 قدم أداءً أكثر اتساقاً في السياق الطويل مقارنة بأي نموذج اختبرناه". فأين الحقيقة؟ تكمن الإجابة في البيانات التي نشرتها الشركة نفسها في بطاقة النظام: في معيار MRCR v2 8-needle عند سياق 1 مليون رمز (Token)، حصل Opus 4.6 على 78.3%، بينما لم يحصل Opus 4.7 سوى على 32.2%. هذا ليس مجرد تراجع، بل هو انهيار في الدقة.
وما أثار ضجة أكبر في مجتمع المطورين هو اعتراف Anthropic في بطاقة النظام بأن: "نموذج Opus 4.6 بوضع التفكير الموسع 64k يتفوق تماماً على 4.7 في مهام استرجاع الإبر المتعددة في السياق الطويل". وقد تم تداول هذه العبارة مراراً وتكراراً على منصات Hacker News وX وReddit، لتصبح دليلاً رسمياً على "تراجع Opus 4.7 في السياق الطويل".
يستعرض هذا المقال، استناداً إلى بطاقة نظام Anthropic الرسمية، والتقييمات المستقلة (مثل Rohan Paul على X، وتحليلات مجتمع DEV)، والتعليقات المباشرة من المبرمجين، تحليلاً عميقاً للبيانات الحقيقية وراء تراجع قدرات Claude Opus 4.7 في السياق الطويل، والأسباب الكامنة وراء ذلك، وكيفية التعامل مع هذا الوضع.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف بوضوح: ما هي سيناريوهات السياق الطويل التي يجب أن تظل متمسكاً فيها بـ 4.6، وأيها لا يزال 4.7 صالحاً لها، وكيفية توجيه الطلبات (Routing) حسب السيناريو في طبقة استدعاء الـ API.
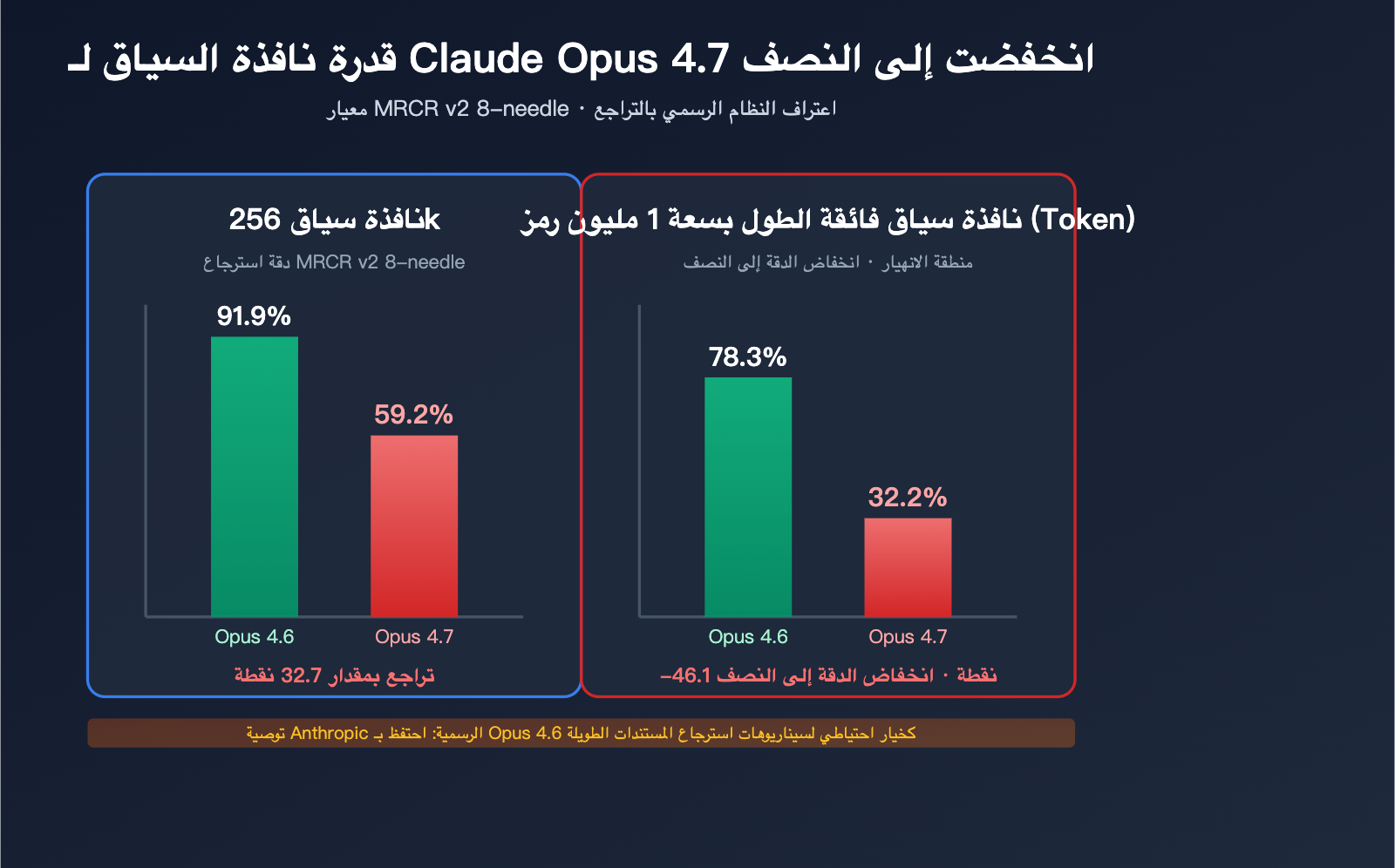
إثبات رسمي لتراجع Claude Opus 4.7 في السياق الطويل
يستخدم هذا القسم البيانات التي نشرتها Anthropic نفسها لإثبات حقيقة التراجع.
الانخفاض الحاد في معيار MRCR v2 8-needle
يعد معيار MRCR v2 (حل المراجع الأساسية متعدد الجولات، الإصدار الثاني) المعيار الصناعي لقياس قدرة استرجاع "الإبر" المتعددة في السياق الطويل. طريقة الاختبار: يتم زرع 8 حقائق محددة في نص طويل جداً، ويُطلب من النموذج استرجاعها وإعادة إنتاجها. الدرجة هي متوسط معدل المطابقة (%).
| طول السياق | Opus 4.6 | Opus 4.7 | مقدار الانخفاض |
|---|---|---|---|
| 256k Token | 91.9% | 59.2% | -32.7pt |
| 1M Token | 78.3% | 32.2% | -46.1pt |
معنى هذه الأرقام:
- عند سياق 256k، انخفضت دقة استرجاع الإبر المتعددة في 4.7 من "الدرجة الكاملة تقريباً" إلى "غير مقبول".
- عند سياق 1M، انخفضت دقة 4.7 إلى النصف، بل وأقل من الثلث.
- تفوق 4.6 في هذا المعيار ليس فقط على 4.7، بل تفوق أيضاً على GPT-5.2 في نطاق 256k (كما أكد Rohan Paul رسمياً).
قدم Rohan Paul على منصة X الحكم الأكثر اختصاراً: "Opus 4.6 يحمل الآن تاج أفضل نموذج للسياق الطويل." وهذا يعني: أن Opus 4.6 هو أفضل نموذج للسياق الطويل في عام 2026 – هذا اللقب ليس لـ 4.7، ولا لـ GPT-5.4.
اعتراف Anthropic في بطاقة النظام
الأمر الأكثر إثارة للصدمة هو أن Anthropic اعترفت بنفسها بهذا الأمر في بطاقة نظام Opus 4.7. جاء في الصفحة 47 من بطاقة النظام:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
الترجمة: "نموذج Opus 4.6 بوضع التفكير الموسع 64k يتفوق تماماً على 4.7 في مهام استرجاع الإبر المتعددة في السياق الطويل. بالنسبة لأنظمة الإنتاج التي تعتمد على استرجاع المستندات الطويلة، نوصي بالإبقاء على 4.6 كخيار احتياطي."
هذه هي المرة الأولى التي توصي فيها Anthropic صراحةً في وثائقها الرسمية المستخدمين "بعدم الانتقال الكامل" إلى الإصدار الجديد. هذا الاعتراف النادر يوضح أن التقييمات الداخلية لم تستطع إخفاء هذا التراجع.
🎯 نصيحة تقنية: إذا كان عملك يتضمن RAG للمستندات الطويلة أو استرجاع مستودعات برمجية ضخمة، نوصي بالحفاظ على صلاحيات استدعاء كل من Claude Opus 4.6 و4.7 عبر منصة APIYI (apiyi.com). توفر المنصة واجهة API موحدة، ولا يتطلب تبديل النماذج سوى تعديل المعلمات، مما يتيح لك إجراء مقارنات A/B سريعة والتوجيه حسب السيناريو خلال فترة الانتقال.
ليس فقط MRCR: تراجع في BrowseComp أيضاً
بالإضافة إلى MRCR، شهد معيار آخر متعلق بالسياق الطويل وهو BrowseComp (مهام البحث العميق على الويب) تراجعاً أيضاً:
| المعيار | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
يقيس BrowseComp أداء "وكلاء البحث العميق" (Research Agents) – حيث يحتاج النموذج إلى تتبع مصادر معلومات متعددة في سياق طويل وإجراء أحكام شاملة عبر المستندات. على الرغم من أن تراجع 4.7 ليس بنفس حدة MRCR، إلا أنه لا يزال إشارة سلبية جوهرية للفرق التي تعمل على وكلاء البحث.
الأسباب الجذرية لتراجع قدرة Claude Opus 4.7 في التعامل مع السياقات الطويلة
لماذا قد يتراجع نموذج رئيسي جديد صدر في عام 2026 بشكل كبير في التعامل مع السياقات الطويلة؟ من خلال بطاقة النظام الرسمية وتحليلات المجتمع، يمكننا استخلاص ثلاثة أسباب جوهرية.
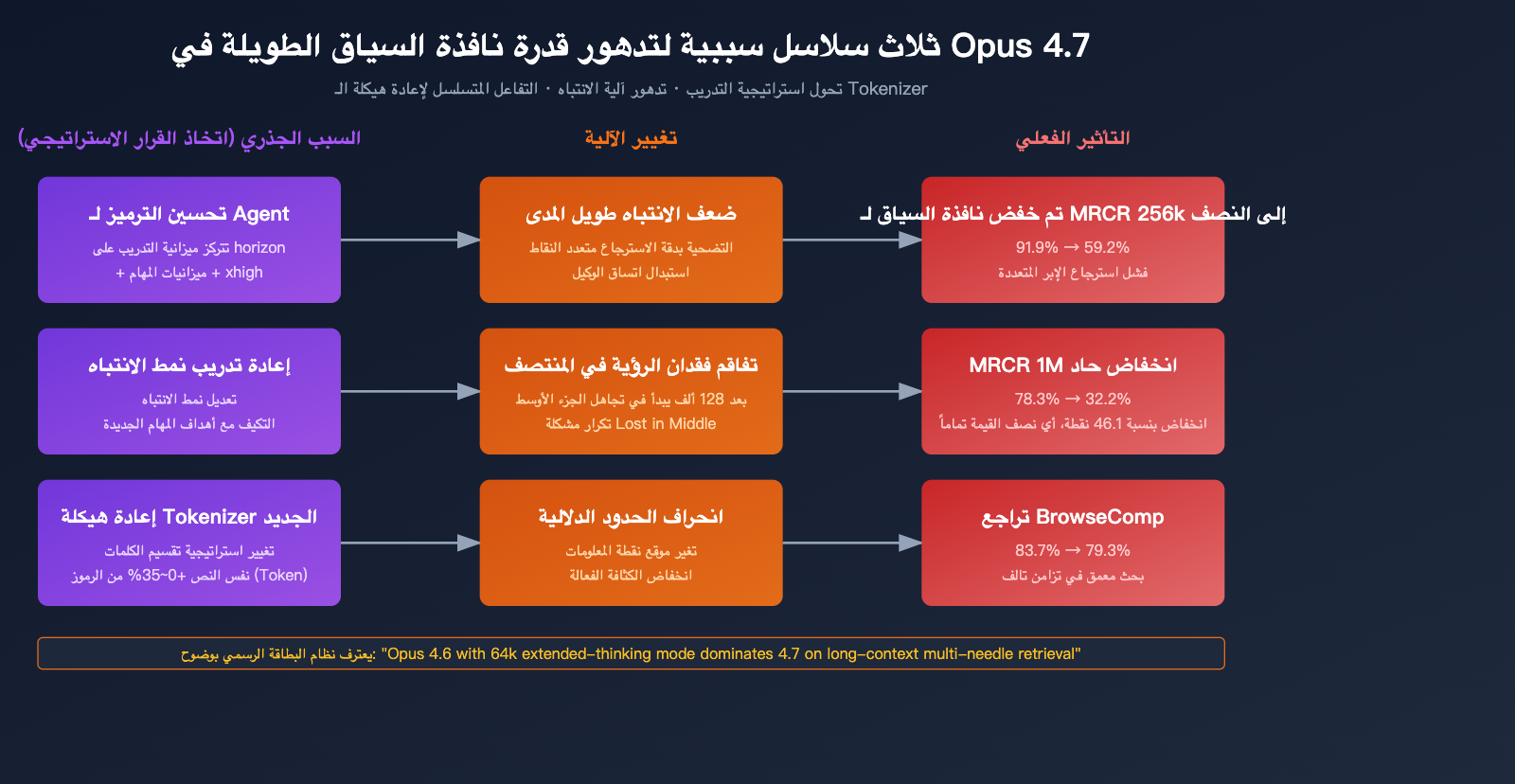
السبب 1: التضحية بالانتباه للمسافات الطويلة من أجل "ترميز الوكيل" (Agent Coding)
الهدف التصميمي الأساسي لنموذج Opus 4.7 هو "سير عمل الترميز الوكلي طويل الأمد" — لاحظ، التشغيل طويل الأمد لا يساوي استرجاع السياق الطويل. غالبًا ما يتم الخلط بين هذين المفهومين في لغة منتجات Anthropic، لكنهما أمران مختلفان على مستوى قدرات النموذج:
| بُعد القدرة | التشغيل طويل الأمد (أفق الوكيل) | استرجاع السياق الطويل (استرجاع إبر متعددة) |
|---|---|---|
| المتطلبات الأساسية | استقرار اتخاذ القرار المستمر | تحديد دقيق للمعلومات بعيدة المدى |
| السيناريوهات النموذجية | حلقات Claude Code المتعددة | استرجاع RAG، الإجابة على الأسئلة الطويلة |
| هدف التدريب | الاتساق + تخطيط الخطوات | دقة الانتباه + ذاكرة دقيقة |
| أداء 4.7 | ✓ تحسن ملحوظ | ✗ تراجع حاد |
لقد استثمر Opus 4.7 الكثير من موارد التحسين في البُعد الأول (ميزانيات المهام، مستويات xhigh، واتباع التعليمات بدقة أكبر)، وهذه التحسينات ربما أدت بشكل مباشر أو غير مباشر إلى التضحية بدقة الانتباه للمسافات الطويلة.
السبب 2: تفاقم مشكلة "الضياع في المنتصف" (Lost in the Middle)
تعد مشكلة "الضياع في المنتصف" عيبًا شائعًا ومعترفًا به في الصناعة عند التعامل مع سياقات طويلة: عندما تُدفن المعلومات في منتصف النص الطويل، يتجاهلها النموذج بشكل منهجي أو يخطئ في نسبتها. كان Opus 4.6 أحد أفضل النماذج في معالجة هذه المشكلة، لكن 4.7 شهد تراجعًا واضحًا في هذه النقطة.
جاء في نص تحليل بطاقة النظام المكون من 232 صفحة:
"Opus 4.6 يستخدم نافذة سياقه الكاملة بشكل موثوق. بينما يظهر Opus 4.7 علامات مبكرة على "العمى في منتصف السياق"، خاصة بعد تجاوز 128 ألف رمز (Token)."
بمعنى: كان Opus 4.6 قادرًا على استخدام نافذة السياق بالكامل بشكل موثوق. أما Opus 4.7 فيظهر علامات "عمى منتصف السياق" واضحة بعد تجاوز حاجز 128 ألف رمز.
وهذا يفسر سبب تمكن 4.7 من الحفاظ على 59.2% في معيار 256 ألف رمز، بينما انخفضت النسبة إلى 32.2% عند 1 مليون رمز — فكلما زاد طول السياق، زاد احتمال "ضياع" المعلومات الموجودة في المنتصف.
السبب 3: إعادة هيكلة المرمز (Tokenizer) غيرت الحدود الدلالية
على الرغم من أن الهدف الرئيسي للمرمز الجديد في Opus 4.7 هو "تحسين كفاءة المعالجة"، إلا أن طريقة تقطيعه للنصوص ليست متوافقة مع إصدار 4.6. وهذا يعني:
- نفس نقاط المعلومات تشغل مواقع رموز (Tokens) مختلفة في 4.6 و 4.7.
- "نمط الانتباه" (Attention pattern) الذي تم تحسينه أثناء التدريب قد يحتاج إلى إعادة تكييف.
- على المدى القصير، تسببت تغييرات المرمز في خسارة غير مرئية في قدرة 4.7 على وراثة قدرات الاسترجاع الخاصة بـ 4.6.
بإضافة حقيقة تضخم الرموز (بنسبة 0-35%)، نجد أن "كثافة الرموز الفعالة" لنفس المستند الطويل قد انخفضت فعليًا في 4.7 — فأنت تظن أنك أدخلت معلومات بحجم 1 مليون رمز، لكنها في الواقع قُطعت إلى عدد أكبر من الرموز، مما أدى إلى تشتيت انتباه النموذج.
نظرة شاملة على بيانات الأداء للسياق الطويل لنموذج Claude Opus 4.7
يستعرض هذا القسم مقارنة شاملة لبيانات الأداء بين الإصدارين 4.7 و4.6 من Claude، ونموذج GPT-5.4 عبر مختلف معايير قياس السياق الطويل.
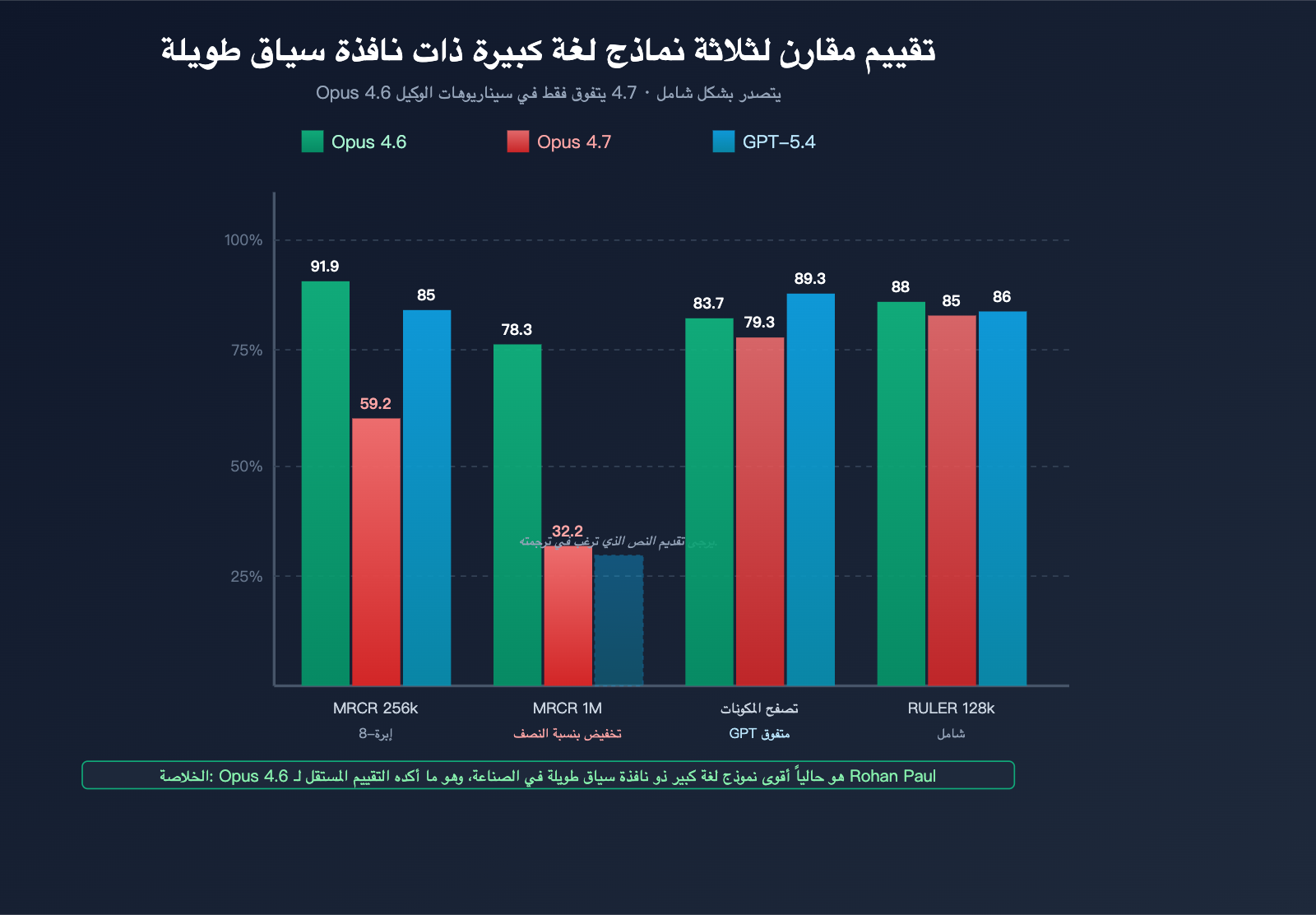
نظرة شاملة على معايير السياق الطويل السائدة
| المعيار | بُعد القياس | Opus 4.6 | Opus 4.7 | GPT-5.4 | المتصدر |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | دقة استرجاع متعدد النقاط | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | استرجاع سياق طويل جداً | 78.3% | 32.2% | غير معلن | Opus 4.6 |
| BrowseComp | وكيل البحث المتعمق | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | سياق طويل شامل | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | فهم المستندات الطويلة | مرتفع | انخفاض طفيف | متكافئ | Opus 4.6 |
| Needle-in-haystack @ 1M | استرجاع نقطة واحدة | 99%+ | ~95% | ~97% | تعادل تقريباً |
من هذا الجدول يمكننا ملاحظة ما يلي:
- في استرجاع نقطة واحدة (إخفاء معلومة واحدة في نص طويل)، لا توجد فجوة كبيرة بين النماذج الثلاثة.
- في استرجاع متعدد النقاط (البحث عن 8 معلومات في وقت واحد)، يتفوق Opus 4.6 بفارق كبير.
- في سياق طويل جداً بمستوى 1M، يكون أداء Opus 4.7 أقل بشكل ملحوظ من Opus 4.6 وGPT-5.4.
جدول مواءمة سيناريوهات العمل الواقعية
ترجمة بيانات المعايير إلى سيناريوهات عمل واقعية:
| سيناريو العمل | متطلبات القدرة الرئيسية | النموذج الموصى به | السبب |
|---|---|---|---|
| تحليل نصوص العقود الطويلة | استرجاع متعدد النقاط + تحديد دقيق | Opus 4.6 | يتصدر في MRCR |
| الأسئلة والأجوبة حول الأكواد البرمجية | استرجاع دلالي عبر الملفات | Opus 4.6 | موثوقية عند 128k+ |
| تحليل التقارير المالية | جداول متعددة + فقرات متعددة | Opus 4.6 | قدرات متعددة النقاط |
| بحث الويب المتعمق | حكم شامل عبر صفحات الويب | GPT-5.4 Pro | يتصدر في BrowseComp |
| دورات Claude Code الطويلة | تنفيذ مهام طويلة ومستقرة | Opus 4.7 | أفق وكيل (Agent) قوي |
| الأسئلة والأجوبة للمستندات القصيرة | إجابات دقيقة وسريعة | Opus 4.7 / 4.6 | لا توجد فجوة كبيرة |
| استرجاع النصوص القانونية | مطابقة دقيقة + اقتباس | Opus 4.6 | يتطلب استرجاعاً عالياً |
💡 نصيحة اختيار النموذج: بالنسبة للأعمال التي تتضمن استرجاع مستندات طويلة أو سيناريوهات RAG، نوصي باستخدام منصة APIYI (apiyi.com) لتوجيه الطلبات بين Opus 4.6 و4.7 حسب طبيعة العمل. تدعم المنصة واجهة موحدة لاستدعاء النماذج السائدة، مما يسهل التبديل السريع بينها بناءً على السيناريو.
منحنى تأثير طول السياق
عند أطوال سياق مختلفة، يظهر تراجع أداء 4.7 سمات تضخم غير خطية:
- أقل من 32k: لا يوجد فرق تقريباً بين 4.7 و4.6.
- 32k – 128k: يبدأ 4.7 في إظهار تراجع طفيف (ضمن 5 نقاط تقريباً).
- 128k – 256k: يتضخم تراجع 4.7 بشكل ملحوظ (-15 إلى -30 نقطة).
- 256k – 1M: يدخل 4.7 في "منطقة الانهيار"، حيث يفشل الاسترجاع متعدد النقاط تماماً.
هذا المنحنى يوجه قرارات عملك مباشرة: إذا كانت متطلبات السياق أقل من 128k، يمكنك استخدام 4.7؛ أما إذا تجاوزت 128k، فننصح بشدة بالاحتفاظ بـ 4.6.
ثلاثة حلول للتعامل مع تراجع الأداء في السياق الطويل لنموذج Claude Opus 4.7
بما أن تراجع الأداء أصبح حقيقة واقعة، فإن مفتاح الانتقال ليس في "هل يجب علينا الانتقال؟" بل في "كيف ننتقل؟". فيما يلي ثلاثة حلول مرتبة حسب التكلفة من الأقل إلى الأعلى، ويمكن استخدامها بشكل منفصل أو مدمج.

الحل 1: التوجيه حسب السيناريو في طبقة الـ API بين 4.6 و 4.7
هذا هو الحل الأقل تكلفة والأكثر فعالية. الفكرة الأساسية: توجيه المهام ذات السياق القصير أو مهام الوكيل (Agent) إلى 4.7، وتوجيه مهام السياق الطويل / RAG / البحث العميق إلى 4.6.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""توجيه النموذج بناءً على طول السياق ونوع المهمة"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
عرض كود استراتيجية التوجيه متعدد الأبعاد بالكامل
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""اتخاذ قرار التوجيه متعدد الأبعاد"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="سيناريو الوكيل (Agent) طويل الدورة، 4.7 لديه أفق أقوى",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} توكن تتجاوز منطقة الأمان لـ 4.7",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="نموذج 4.6 يتفوق على 4.7 في مهام البحث المتصفح",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="نموذج 4.6 يتفوق بوضوح في استرجاع الإبرة المتعددة (MRCR)",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="مهام السياق القصير، 4.7 يتمتع بقدرات شاملة أفضل",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""تقدير عدد التوكن"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"قرار التوجيه: {decision.model} (السبب: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
النتائج الفعلية: مع الحفاظ على قدرات الوكيل (Agent) في 4.7، تعود دقة سيناريوهات السياق الطويل تماماً إلى مستوى 4.6، وتكلفة الانتقال تكاد تكون صفراً.
🚀 توجيه الواجهة الموحد: نوصي بتنفيذ التوجيه عند الطلب لجميع نماذج Claude عبر منصة APIYI (apiyi.com). توفر المنصة واجهة متوافقة تماماً مع Claude الرسمي، مما يلغي الحاجة إلى صيانة مفاتيح API متعددة ويقلل من تعقيد بنية التوجيه لنماذج متعددة.
الحل 2: تقسيم RAG + نافذة منزلقة
إذا كان عملك يعتمد بشكل كبير على 4.7 (مثل سير عمل Claude Code المرتبط به بالفعل)، يمكنك تجنب مشكلة "العمى في المنتصف" في 4.7 عن طريق "تقليل طول السياق الفردي".
الاستراتيجية الأساسية:
- تقسيم المستندات الطويلة إلى أجزاء بحجم 32k-64k (حيث يعمل 4.7 بشكل طبيعي في هذا النطاق).
- استخدام استرجاع المتجهات للحصول فقط على الأجزاء ذات الصلة (Top-K).
- إجراء استدعاء مستقل لكل جزء، ثم دمج الإجابات.
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""تقسيم RAG مُحسّن لـ Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "أجب على السؤال بناءً على جزء المستند المقدم."},
{"role": "user", "content": f"المستند: {chunk}\nالسؤال: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"أجب من خلال دمج الإجابات التالية: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
سيناريوهات الاستخدام: الفرق التي لديها بالفعل روابط Claude Code / Cursor، ولكنها تحتاج إلى معالجة مستندات طويلة جداً.
الحل 3: بنية النماذج الهجينة (Opus 4.6 + Sonnet + GPT-5.4)
بالنسبة للمنتجات الناضجة، الحل الأكثر أماناً هو بنية النماذج الثلاثية:
- Opus 4.6: استرجاع السياق الطويل، RAG، تحليل العقود الطويلة.
- Opus 4.7: برمجة الوكيل (Agent)، دورات Claude Code، الرؤية عالية الدقة.
- GPT-5.4 Pro: البحث العميق على الويب، مهام من نوع BrowseComp.
هذه البنية تعترف بأنه "لا يوجد نموذج واحد يمكنه تغطية كل شيء"، وتستخدم أسلوب الدمج لتعظيم مزايا كل نموذج.
💰 تحسين التكلفة والبنية: شرط بنية النماذج الهجينة هو طبقة وصول موحدة لـ API. من خلال منصة APIYI (apiyi.com)، يمكنك استخدام مفتاح API واحد لاستدعاء جميع نماذج Claude وGPT وGemini. توفر المنصة إحصائيات استدعاء دقيقة وتحليلاً للتكاليف، مما يجعلها خياراً مثالياً لتنفيذ بنية النماذج المتعددة.
الأسئلة الشائعة حول قدرات السياق الطويل في Claude Opus 4.7
س1: تقول Anthropic رسميًا إن 4.7 أكثر استقرارًا في السياق الطويل، فلماذا تشير بيانات الطرف الثالث إلى عكس ذلك؟
هذا ناتج عن خلط بين مفهومي "التشغيل طويل الأمد" و"استرجاع السياق الطويل". الاستقرار الذي تؤكد عليه Anthropic يشير إلى اتساق اتخاذ القرار في دورات الوكيل (Agent)، أي أن المهمة الطويلة لن تنهار في منتصف الطريق. أما "استرجاع السياق الطويل" فيشير إلى القدرة على العثور بدقة على المعلومات في مواقع متباعدة، وهما بعدان مختلفان تمامًا للقدرة.
يقيس معيار MRCR v2 8-needle القدرة الثانية مباشرة، وهو ما تعترف فيه بطاقة النظام الرسمية لشركة Anthropic بأن Opus 4.6 يتفوق على 4.7. لذا، لا يوجد تناقض بين الرأيين، فهما يقيسان أشياء مختلفة.
س2: هل يجب على تطبيق RAG الخاص بي الذي يعتمد على مستندات طويلة العودة فورًا إلى 4.6؟
يعتمد الأمر على الحالة:
- إذا كانت أعمالك الأساسية تعتمد على استرجاع سياق > 128k: عُد فورًا. انخفاض دقة MRCR 1M إلى النصف ليس أمرًا بسيطًا، وسيؤثر مباشرة على جودة الإجابات.
- إذا كان السياق بين 32k و128k: نوصي بإجراء اختبار A/B، إذا كانت الجودة مقبولة يمكنك الاستمرار في استخدام 4.7، وإلا فعد إلى 4.6.
- إذا كان السياق أقل من 32k: لا يوجد فرق كبير بين النموذجين، اتخذ قرارك بناءً على أبعاد أخرى (التكلفة، زمن الاستجابة).
نوصي بإجراء اختبار A/B عبر منصة APIYI (apiyi.com)، حيث تدعم المنصة الاستدعاء المتوازي للمقارنة بين Opus 4.6 و4.7.
س3: لماذا سمحت Anthropic بحدوث هذا التراجع؟
بناءً على المعلومات التي كشفت عنها بطاقة النظام الرسمية، قامت Anthropic بموازنة متعمدة للقدرات: حيث ركزت ميزانية التدريب على برمجة الوكيل (Agent) والفهم البصري، على حساب دقة استرجاع السياق الطويل.
تتوافق هذه الاستراتيجية مع التركيز التجاري الحالي لشركة Anthropic؛ إذ أن Claude Code وسير عمل الوكيل للمؤسسات هما أهم مصادر دخلها. ولكن بالنسبة لمستخدمي المستندات الطويلة، وRAG، ووكلاء البحث، فإن هذا التحول الاستراتيجي يعني تراجعًا في الأداء.
اقتراح Anthropic في بطاقة النظام "بالاحتفاظ بـ 4.6 كخيار للرجوع إليه" هو اعتراف ضمني للمستخدمين بأن: هذا ليس خطأً برمجياً (Bug)، بل استراتيجية، يرجى التكيف معها.
س4: ما مدى خطورة انخفاض معيار MRCR في الأعمال الفعلية؟
خطير للغاية. يحاكي معيار MRCR 8-needle سيناريوهات واقعية مثل "العثور على حقائق رئيسية متعددة في مستند ضخم"، على سبيل المثال:
- مراجعة العقود: استخراج جميع قيود البنود + المواعيد النهائية + بنود الإخلال بالعقد.
- تحليل التقارير المالية: تحديد مؤشرات مالية متعددة من تقرير مكون من 100 صفحة.
- الأسئلة والأجوبة حول قواعد الأكواد: تتبع تعريف المتغيرات + سلسلة الاستدعاءات + علاقات التبعية عبر ملفات متعددة.
انخفاض MRCR من 78.3% إلى 32.2% يعني أن 4.7 سيفقد في المتوسط ثلثي المعلومات الأساسية في مثل هذه المهام. بالنسبة للأعمال التي تعتمد على الدقة، يعد هذا تراجعًا كارثيًا.
س5: في سيناريوهات السياق القصير (< 32k)، ما الفرق الفعلي بين 4.7 و4.6؟
في سيناريوهات السياق القصير التي تقل عن 32k، لا يكاد يظهر أي فرق في قدرات السياق الطويل. لكن 4.7 لا يزال يتفوق بوضوح في الأبعاد التالية:
- قدرة برمجة أقوى: تحسن بمقدار +6.8pt في SWE-bench Verified.
- فهم بصري أقوى: دقة عالية تصل إلى 3.75MP.
- استدعاء أدوات أدق: ريادة في MCP-Atlas.
- تكلفة أعلى: تضخم في الـ Tokenizer بنسبة 0-35%.
لذا، في سيناريوهات السياق القصير، يعتمد الاختيار بشكل أساسي على نوع المهمة، وليس على قدرة السياق الطويل. اختر 4.7 للبرمجة، و4.6 للكتابة، هذا هو المعيار الأبسط حاليًا.
س6: هل هناك طريقة لجعل 4.7 يضاهي 4.6 في السياق الطويل؟
لا يوجد حاليًا حل على مستوى الإعدادات. حتى مع رفع reasoning-effort إلى الحد الأقصى، تظل درجات MRCR لـ 4.7 أقل بوضوح من 4.6.
هناك حلان غير مباشرين ممكنان:
- تقسيم RAG: تقسيم السياق الطويل إلى أجزاء من 32k-64k، للسماح لـ 4.7 بالعمل في "المنطقة الآمنة".
- سلسلة النماذج المتعددة: استخدام 4.6 لاسترجاع السياق الطويل، ثم تغذية نتائج الاسترجاع إلى 4.7 لإجراء الاستنتاج الشامل.
يمكن تنفيذ الحل الثاني بسرعة من خلال واجهة النماذج المتعددة في منصة APIYI (apiyi.com)، والتي تدعم الاستدعاء الموحد لمجموعة متنوعة من النماذج الرئيسية.
ملخص تراجع السياق الطويل في Claude Opus 4.7
يعد تراجع قدرات السياق الطويل في Claude Opus 4.7 مشكلة حقيقية مدعومة ببيانات رسمية، وتحققت منها المجتمعات التقنية، ولها نطاق تأثير واضح. الاستنتاجات الجوهرية هي:
- اعتراف البيانات الرسمية: انخفض أداء MRCR v2 8-needle إلى النصف عند 256k و1M، وتوصي بطاقة نظام Anthropic بوضوح بالاحتفاظ بـ 4.6 كخيار للرجوع إليه.
- السبب الجذري هو الموازنة الاستراتيجية: ضحت Anthropic بدقة الانتباه للمسافات الطويلة من أجل برمجة الوكيل والفهم البصري.
- نطاق التأثير يتركز في سيناريوهات 128k+: لا يزال 4.7 قابلاً للاستخدام في السياق القصير، لكن التراجع يتفاقم بشكل غير خطي بعد تجاوز 128k.
- Opus 4.6 هو أقوى نموذج للسياق الطويل حاليًا: استنتاج متفق عليه من قبل مراقبين مخضرمين مثل Rohan Paul، متفوقًا حتى على GPT-5.2.
- أفضل استجابة هي التوجيه حسب السيناريو: استخدم 4.6 للمستندات الطويلة، و4.7 للبرمجة، وللبحث العميق يمكن التفكير في GPT-5.4 Pro.
بالنسبة للمستخدمين، الموقف الصحيح ليس "انتظار إصلاح من Anthropic" – فهذا التعديل استراتيجي ولن يتم التراجع عنه على المدى القصير – بل هو الاستعداد الفوري للتوجيه بين نماذج متعددة على مستوى الاستدعاء. اجعل 4.6 الخيار الافتراضي لسيناريوهات السياق الطويل، واترك 4.7 لمهام برمجة الوكيل التي يتفوق فيها حقًا.
وهذا يتوافق مع اتجاهات صناعة الذكاء الاصطناعي لعام 2026: انتهى عصر النموذج الواحد الذي يغطي جميع السيناريوهات، حيث يتطور كل نموذج نحو "التخصص في اتجاه معين". المتطلب من المستخدمين هو التحول من "اختيار أقوى نموذج" إلى "تصميم مجموعة منطقية من التوجيه بين النماذج المتعددة".
نوصي بإدارة استدعاءات سلسلة Claude بالكامل عبر منصة APIYI (apiyi.com)، حيث توفر المنصة مقارنات معيارية في الوقت الفعلي، وتوجيهًا ذكيًا بين النماذج المتعددة، وواجهة API متوافقة تمامًا مع الواجهة الرسمية، مما يجعلها أداة عملية للتعامل مع مشكلة تراجع السياق الطويل في Opus 4.7.
المراجع
-
بطاقة نظام Anthropic Opus 4.7: بطاقة النظام الرسمية المكونة من 232 صفحة
- الرابط:
anthropic.com/news/claude-opus-4-7 - الوصف: تحتوي على بيانات معيارية كاملة لـ MRCR v2 وتوصيات الترحيل.
- الرابط:
-
تحليل معمق لبطاقة نظام Opus 4.7: تحليل مجتمع DEV Community
- الرابط:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - الوصف: ملخص لبطاقة النظام المكونة من 232 صفحة من منظور المبرمجين.
- الرابط:
-
دليل ترحيل Anthropic: دليل ترحيل Opus 4.7
- الرابط:
platform.claude.com/docs/en/about-claude/models/migration-guide - الوصف: توصيات الترحيل الرسمية وملاحظات حول نافذة السياق الطويلة.
- الرابط:
-
لوحة صدارة معايير السياق الطويل: لوحة صدارة معايير السياق الطويل
- الرابط:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - الوصف: مقارنة أفقية بين MRCR وRULER وLongBench v2.
- الرابط:
-
تعليق Rohan Paul على منصة X: تحليل بطل السياق الطويل Opus 4.6
- الرابط:
x.com/rohanpaul_ai/status/2019545018051240059 - الوصف: تقييم مراقب مستقل لمزايا السياق الطويل في Opus 4.6.
- الرابط:
المؤلف: فريق APIYI التقني
تاريخ النشر: 2026-04-18
النماذج المطبقة: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
التواصل التقني: نرحب بكم للحصول على أرصدة اختبار النماذج المتعددة عبر APIYI (apiyi.com)، حيث يمكنك اختبار فروق دقة الاسترجاع بنفسك عبر أطوال سياق مختلفة.