
Les développeurs experts ont épluché les 232 pages de la fiche technique officielle d'Anthropic, et la conclusion est sans appel : les capacités de contexte long de Claude Opus 4.7 ont subi une régression majeure par rapport à la version 4.6.
Ce constat contraste violemment avec la communication d'Anthropic, qui affirmait dans son blog officiel : "Opus 4.7 a offert les performances de contexte long les plus cohérentes de tous les modèles que nous avons testés". Où se cache la vérité ? Dans les données brutes de leur propre fiche technique : sur le benchmark MRCR v2 8-needle avec 1M de tokens de contexte, Opus 4.6 affiche un score de 78,3 %, tandis qu'Opus 4.7 plafonne à 32,2 %. Ce n'est pas une simple baisse, c'est une chute libre.
Plus troublant encore, Anthropic admet dans sa fiche technique : "Le mode 64k extended-thinking d'Opus 4.6 surpasse largement le 4.7 sur les tâches de récupération multi-aiguilles dans des contextes longs." Cette phrase est devenue virale sur Hacker News, X et Reddit, servant de preuve officielle à la communauté pour confirmer cette régression.
Cet article analyse en profondeur les données réelles, les causes profondes et les solutions face à cette régression, en s'appuyant sur la documentation officielle, les tests indépendants (Rohan Paul sur X, analyses de la communauté DEV) et les retours d'expérience des développeurs.
Valeur ajoutée : Vous saurez exactement quels scénarios nécessitent le maintien de la version 4.6, où la version 4.7 reste pertinente, et comment mettre en place un routage par scénario au niveau de vos appels API.
La confirmation officielle de la régression de Claude Opus 4.7
Cette section utilise les données publiées par Anthropic pour prouver cette régression.
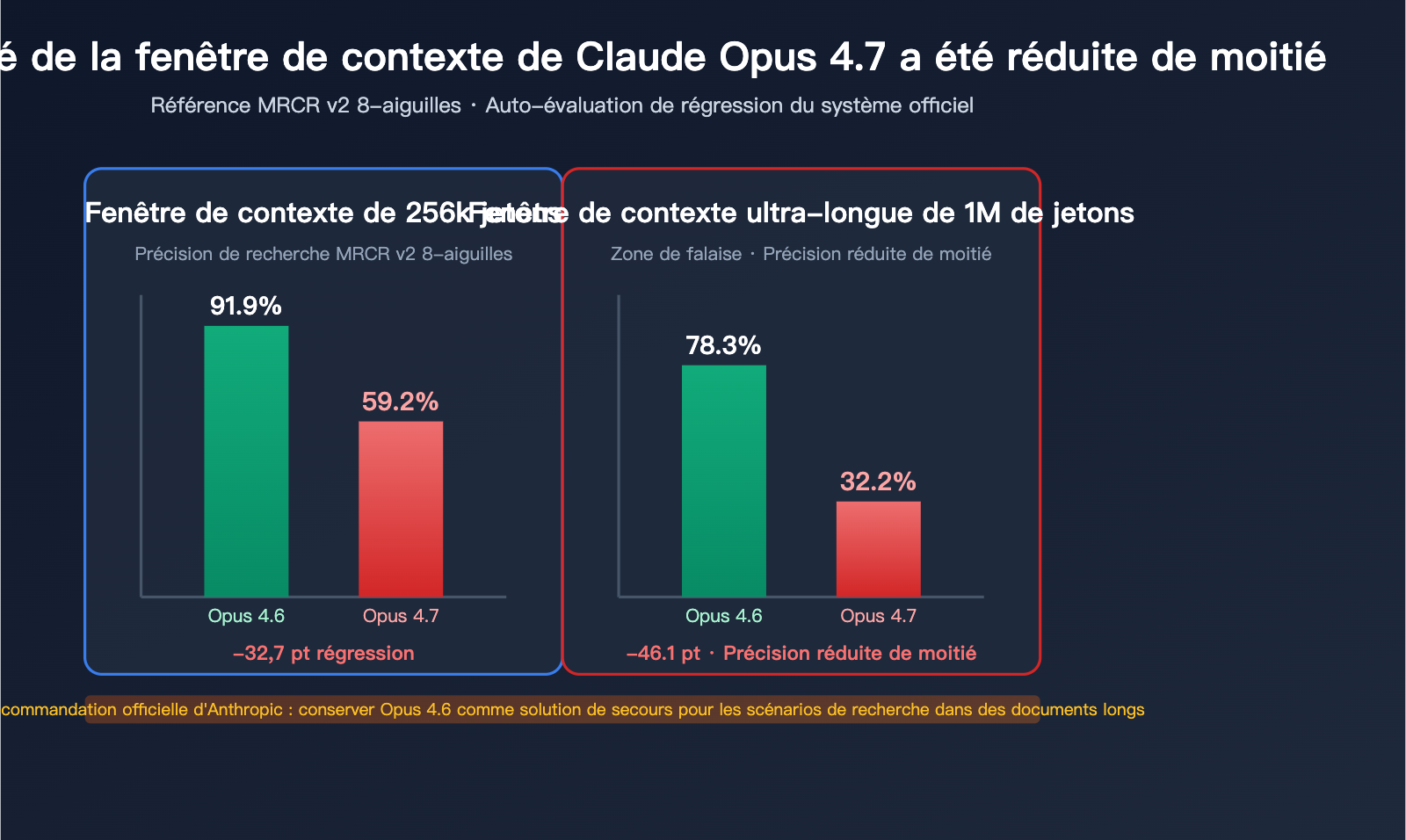
Chute brutale sur le benchmark MRCR v2 8-needle
Le MRCR v2 (Multi-Round Coreference Resolution, version 2) est le standard de l'industrie pour mesurer la capacité de récupération multi-aiguilles dans un contexte long. Test : insérer 8 faits spécifiques dans un texte très long et demander au modèle de les retrouver. Le score représente le taux de correspondance moyen (%).
| Longueur du contexte | Opus 4.6 | Opus 4.7 | Amplitude de baisse |
|---|---|---|---|
| 256k Token | 91,9 % | 59,2 % | -32,7 pt |
| 1M Token | 78,3 % | 32,2 % | -46,1 pt |
Ce que signifient ces chiffres :
- Avec 256k de contexte, la précision de récupération du 4.7 passe d'un score "presque parfait" à un score "insuffisant".
- Avec 1M de contexte, la précision du 4.7 est divisée par plus de deux, atteignant à peine un tiers du score précédent.
- Sur ce benchmark, le 4.6 ne surpasse pas seulement le 4.7, il bat également GPT-5.2 sur la plage des 256k (confirmé par Rohan Paul).
Rohan Paul a résumé la situation sur X de manière concise : "Opus 4.6 prend désormais la couronne du meilleur modèle pour les contextes longs." En clair : Opus 4.6 est le meilleur modèle de 2026 pour les contextes longs — ce n'est pas le 4.7, et ce n'est pas GPT-5.4.
L'aveu d'Anthropic dans sa fiche technique
Plus surprenant encore, Anthropic admet lui-même ce fait dans la fiche technique d'Opus 4.7. Page 47 :
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
Traduction : Le mode 64k extended-thinking d'Opus 4.6 surpasse largement le 4.7 sur la récupération multi-aiguilles en contexte long. Pour les systèmes de production basés sur la récupération de documents longs, nous recommandons de conserver le 4.6 comme option de secours.
C'est la première fois qu'Anthropic recommande explicitement dans sa documentation officielle de ne pas migrer intégralement vers une nouvelle version. Cet aveu rare montre que leurs tests internes n'ont pas pu masquer cette régression.
🎯 Conseil technique : Si votre activité implique du RAG sur documents longs ou de l'analyse de bases de code massives, nous vous recommandons de conserver l'accès aux deux versions, Claude Opus 4.6 et 4.7, via la plateforme APIYI apiyi.com. Cette plateforme offre une interface API unifiée, permettant de changer de modèle en modifiant simplement un paramètre, ce qui facilite les tests A/B et le routage par scénario durant cette phase de transition.
Pas seulement le MRCR : BrowseComp régresse également
Au-delà du MRCR, un autre benchmark lié aux contextes longs, BrowseComp (tâches de recherche Web approfondie), montre également une baisse :
| Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83,7 % | 79,3 % | 89,3 % |
BrowseComp mesure les performances d'un "Agent de recherche approfondie" — le modèle doit suivre plusieurs sources d'information dans un contexte long et effectuer des synthèses croisées. Bien que la baisse du 4.7 soit moins spectaculaire que sur le MRCR, elle constitue un signal négatif substantiel pour les équipes développant des agents de recherche.
Les causes profondes de la régression des capacités de contexte long de Claude Opus 4.7
Pourquoi un nouveau modèle phare de 2026 présenterait-il une régression aussi marquée sur la gestion des contextes longs ? En analysant les fiches techniques officielles et les retours de la communauté, trois causes fondamentales se dégagent.
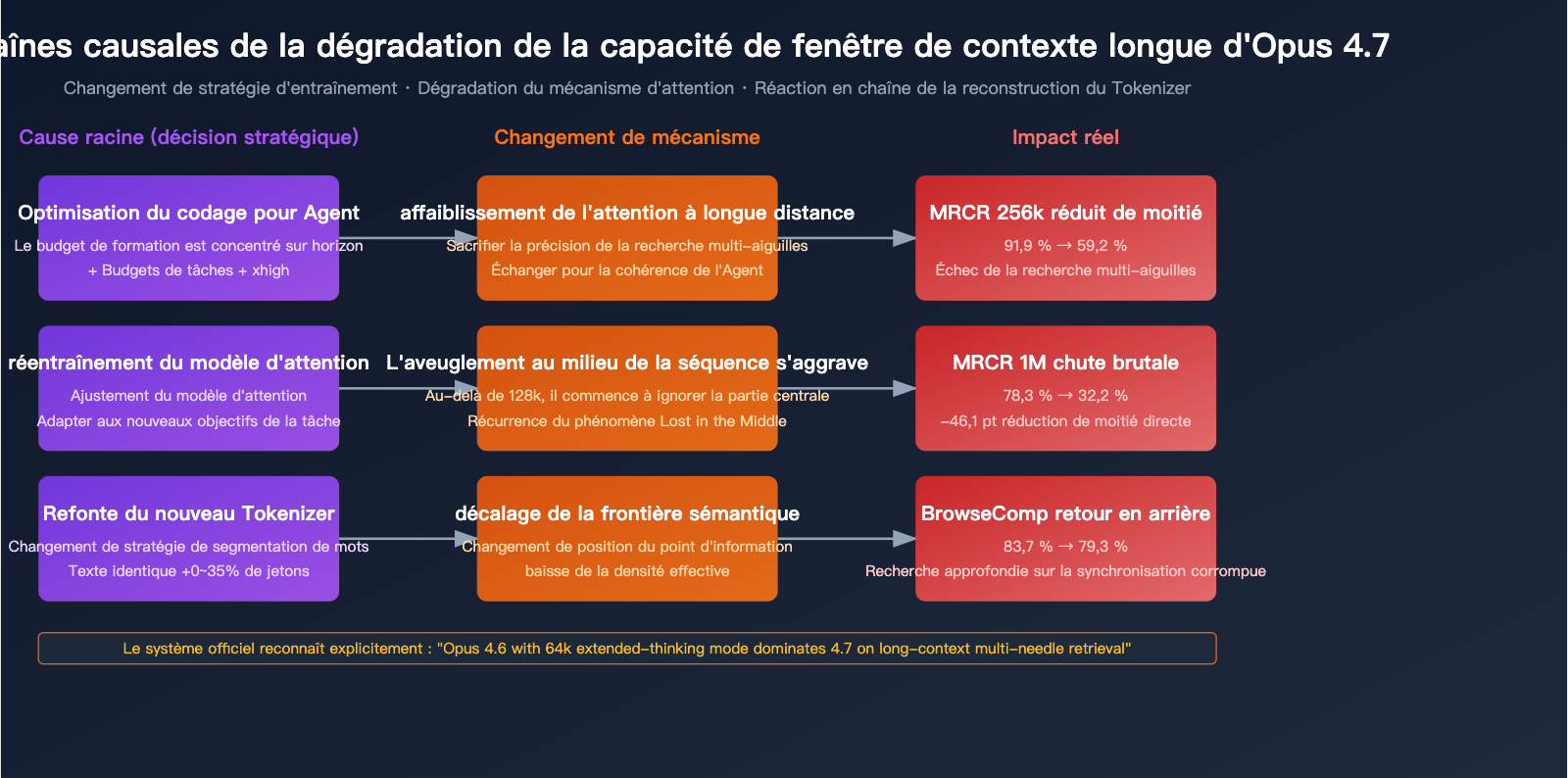
Raison 1 : Sacrifier l'attention longue distance pour le "codage par agent"
L'objectif de conception principal d'Opus 4.7 est le "flux de travail de codage agentique longue durée" — attention, longue durée ≠ récupération sur contexte long. Ces deux concepts sont souvent confondus dans le langage marketing d'Anthropic, mais au niveau des capacités du modèle, ce sont deux choses bien distinctes :
| Dimension de capacité | Exécution longue (Horizon Agent) | Récupération sur contexte long (Multi-needle) |
|---|---|---|
| Exigence clé | Stabilité décisionnelle continue | Localisation précise d'infos distantes |
| Scénarios types | Boucles multiples Claude Code | RAG, Q&A sur longs documents |
| Objectif d'entraînement | Cohérence + planification | Précision de l'attention + mémoire fine |
| Performance 4.7 | ✓ Amélioration notable | ✗ Régression sévère |
Opus 4.7 a investi énormément de ressources d'optimisation dans la première dimension (budgets de tâches, niveaux xhigh, suivi d'instructions plus précis), et ces optimisations ont probablement sacrifié, directement ou indirectement, la précision de l'attention longue distance.
Raison 2 : Aggravation du problème "Lost in the Middle"
Le phénomène "Lost in the middle" (perdu au milieu) est un défaut reconnu des modèles à contexte long : lorsque l'information est enfouie au milieu d'un long texte, le modèle a tendance à l'ignorer systématiquement ou à mal l'interpréter. Opus 4.6 était l'un des meilleurs modèles du marché pour gérer cela, mais la version 4.7 a nettement reculé.
Voici ce que disent les auteurs de l'analyse de 232 pages de la fiche technique :
"Opus 4.6 utilise sa fenêtre de contexte complète de manière fiable. Opus 4.7 montre des signes précoces de cécité au milieu du contexte, surtout au-delà de 128k jetons."
En clair : Opus 4.6 pouvait utiliser sa fenêtre de contexte complète de manière fiable. Opus 4.7 présente des signes évidents de "cécité centrale" au-delà de 128k jetons.
Cela explique pourquoi le 4.7 maintient 59,2 % de précision sur un benchmark de 256k, mais tombe à 32,2 % sur 1M — plus le contexte est long, plus la probabilité que le milieu soit "perdu" augmente.
Raison 3 : La refonte du Tokenizer modifie les frontières sémantiques
Bien que le nouveau Tokenizer d'Opus 4.7 vise principalement à "améliorer l'efficacité du traitement", sa manière de segmenter le texte n'est pas compatible avec celle du 4.6. Cela implique que :
- Les mêmes informations occupent des positions de jetons différentes entre le 4.6 et le 4.7.
- Les "motifs d'attention" optimisés lors de l'entraînement pourraient nécessiter une réadaptation.
- À court terme, le changement de Tokenizer entraîne une perte invisible dans la capacité de récupération héritée du 4.6.
Si l'on ajoute à cela l'augmentation de la taille des jetons (0-35 %), la "densité de jetons effectifs" d'un même long document a en réalité diminué sur le 4.7 — vous pensez avoir fourni 1M de jetons d'information, mais ils ont été fragmentés en davantage de jetons, ce qui a fini par disperser l'attention du modèle.
Panorama des données de test en contexte long de Claude Opus 4.7
Cette section présente une comparaison synthétique des performances de la version 4.7 par rapport à la 4.6 et au GPT-5.4 sur divers benchmarks de contexte long.
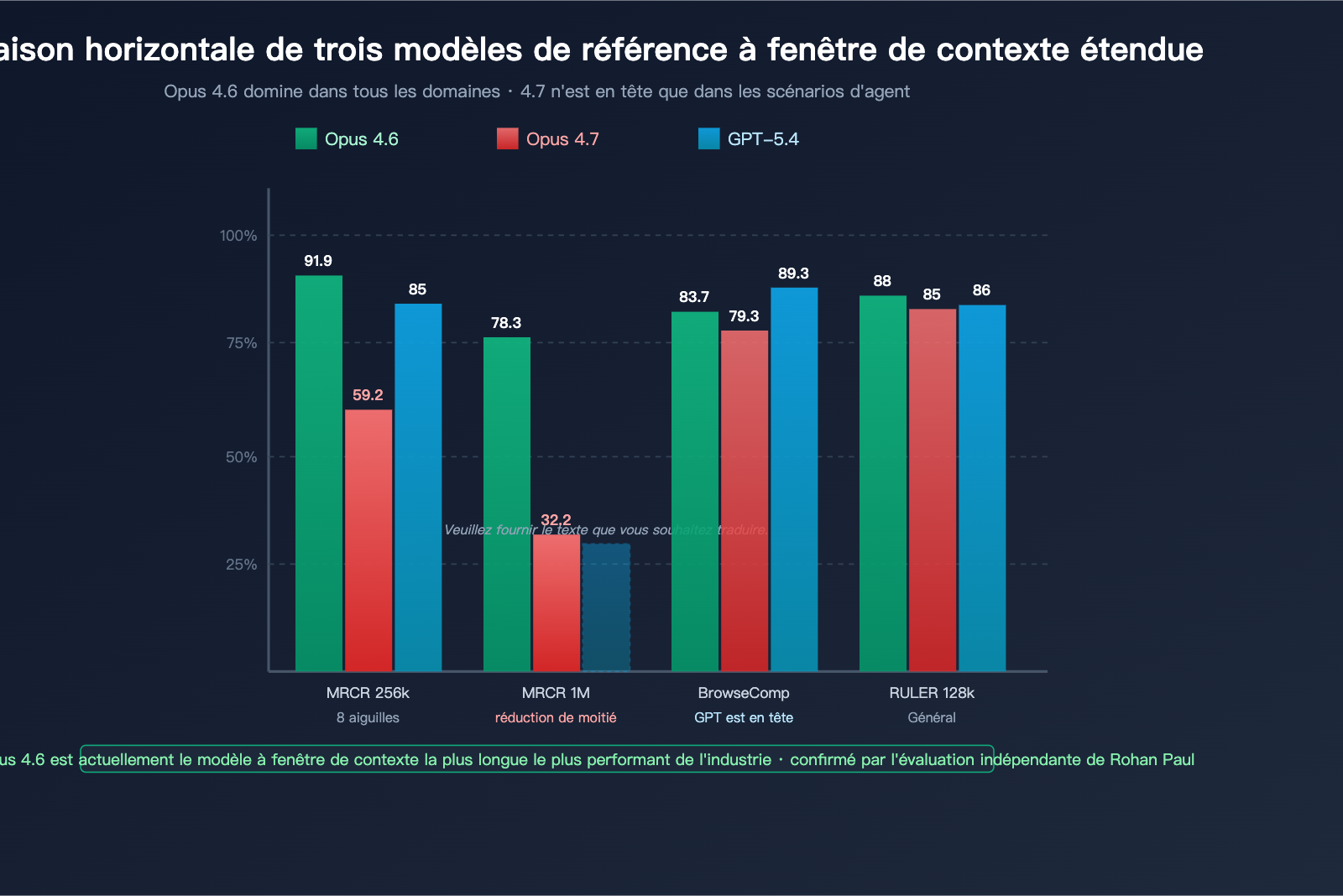
Panorama des benchmarks de contexte long
| Benchmark | Dimension de mesure | Opus 4.6 | Opus 4.7 | GPT-5.4 | Leader |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Précision de recherche multi-aiguilles | 91,9 % | 59,2 % | ~85 % | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Recherche en contexte ultra-long | 78,3 % | 32,2 % | Non divulgué | Opus 4.6 |
| BrowseComp | Agent de recherche approfondie | 83,7 % | 79,3 % | 89,3 % | GPT-5.4 Pro |
| RULER @ 128k | Contexte long global | ~88 % | ~85 % | ~86 % | Opus 4.6 |
| LongBench v2 | Compréhension de documents longs | Élevé | Légère baisse | Stable | Opus 4.6 |
| Needle-in-haystack @ 1M | Recherche mono-aiguille | 99 %+ | ~95 % | ~97 % | Quasi-égalité |
Ce tableau nous apprend que :
- Pour la recherche mono-aiguille (cacher une information dans un texte long), les trois modèles sont très proches.
- Pour la recherche multi-aiguilles (trouver 8 informations simultanément), l'Opus 4.6 conserve une avance considérable.
- Avec un contexte ultra-long de 1M, les performances de l'Opus 4.7 sont nettement inférieures à celles de l'Opus 4.6 et du GPT-5.4.
Tableau de correspondance pour les cas d'usage réels
Traduction des données de benchmark en scénarios métier concrets :
| Cas d'usage | Exigences de capacité | Modèle recommandé | Raison |
|---|---|---|---|
| Analyse de contrats longs | Recherche multi-aiguilles + localisation précise | Opus 4.6 | Avance sur MRCR |
| Q&A sur base de code | Recherche sémantique inter-fichiers | Opus 4.6 | Fiable au-delà de 128k |
| Analyse de rapports financiers | Tableaux multiples + synthèse | Opus 4.6 | Capacité multi-aiguilles |
| Recherche Web approfondie | Jugement synthétique inter-pages | GPT-5.4 Pro | Leader sur BrowseComp |
| Boucles longues Claude Code | Exécution stable de tâches longues | Opus 4.7 | Horizon d'agent robuste |
| Q&A sur documents courts | Réponses rapides et précises | Opus 4.7 / 4.6 | Peu de différence |
| Recherche juridique | Correspondance précise + citations | Opus 4.6 | Nécessite un rappel élevé |
💡 Conseil de sélection : Pour les activités impliquant la recherche dans des documents longs ou des scénarios RAG, nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour router vos requêtes entre Opus 4.6 et 4.7 selon le besoin. La plateforme unifie les interfaces d'invocation du modèle, facilitant ainsi la commutation rapide.
Courbe d'impact de la longueur du contexte
La dégradation des performances de la version 4.7 suit une courbe non linéaire à mesure que le contexte s'allonge :
- Moins de 32k : Quasi aucune différence entre 4.7 et 4.6.
- 32k – 128k : L'Opus 4.7 commence à montrer un léger recul (moins de 5 points).
- 128k – 256k : Le recul s'accentue nettement (-15 à -30 points).
- 256k – 1M : L'Opus 4.7 entre dans une "zone de décrochage", où la recherche multi-aiguilles devient inopérante.
Cette courbe dicte votre stratégie : si vos besoins en contexte restent inférieurs à 128k, l'Opus 4.7 est utilisable ; au-delà, nous recommandons vivement de conserver l'Opus 4.6.
Trois stratégies pour gérer la régression du contexte long de Claude Opus 4.7
Puisque la régression est une réalité, la question n'est plus de savoir s'il faut migrer, mais comment le faire. Voici trois approches, classées de la moins coûteuse à la plus complexe, utilisables séparément ou combinées.

Solution 1 : Routage par scénario au niveau de l'API (4.6 vs 4.7)
C'est la solution la plus efficace et la moins coûteuse. Le principe : utilisez le 4.7 pour les contextes courts ou le codage Agent, et le 4.6 pour les contextes longs, le RAG ou la recherche approfondie.
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Routage du modèle selon la longueur du contexte et le type de tâche"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
Voir le code complet de la stratégie de routage multidimensionnel
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Décision de routage multidimensionnel"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Scénario Agent en boucle longue, horizon 4.7 plus performant",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} tokens dépassent la zone de sécurité MRCR du 4.7",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="Le 4.6 surpasse le 4.7 sur BrowseComp",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="Avantage absolu du 4.6 pour la recherche multi-aiguilles MRCR",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Tâche à contexte court, capacités globales du 4.7 supérieures",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Estimation du nombre de jetons"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Décision de routage : {decision.model} (Raison : {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Résultats observés : En conservant les capacités Agent du 4.7, la précision sur les scénarios à contexte long revient au niveau du 4.6, avec un coût de migration quasi nul.
🚀 Routage d'interface unifié : Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour réaliser le routage à la demande de toute la gamme Claude. Elle offre une interface totalement compatible avec l'API officielle de Claude, éliminant le besoin de gérer plusieurs clés API et simplifiant l'architecture de routage.
Solution 2 : RAG par blocs + fenêtre glissante
Si votre activité dépend fortement du 4.7 (par exemple, un workflow Claude Code déjà configuré), vous pouvez contourner le problème de "cécité médiane" en réduisant la longueur du contexte par appel.
Stratégie clé :
- Découpez les longs documents en blocs de 32k à 64k jetons (plage où le 4.7 est stable).
- Utilisez une recherche vectorielle pour ne récupérer que les blocs pertinents (Top-K).
- Effectuez un appel indépendant pour chaque bloc, puis fusionnez les réponses.
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""RAG par blocs optimisé pour Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Répondez à la question en vous basant sur l'extrait de document fourni."},
{"role": "user", "content": f"Document : {chunk}\nQuestion : {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Synthétisez les réponses suivantes pour répondre à : {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Cas d'usage : Équipes utilisant déjà Claude Code / Cursor mais devant traiter des documents extrêmement longs.
Solution 3 : Architecture hybride (Opus 4.6 + Sonnet + GPT-5.4)
Pour les produits matures, la solution la plus robuste est l'architecture hybride à trois modèles :
- Opus 4.6 : Recherche sur contexte long, RAG, analyse de contrats longs.
- Opus 4.7 : Codage Agent, boucles Claude Code, vision haute définition.
- GPT-5.4 Pro : Recherche Web approfondie, tâches de type BrowseComp.
Cette architecture reconnaît qu'aucun modèle ne peut tout couvrir parfaitement, et maximise les avantages de chaque modèle par la combinaison.
💰 Optimisation des coûts et de l'architecture : La condition préalable à une architecture hybride est une couche d'accès API unifiée. Via la plateforme APIYI (apiyi.com), vous pouvez appeler toute la gamme Claude, GPT et Gemini avec une seule clé API. La plateforme fournit des statistiques d'utilisation détaillées et une analyse des coûts, ce qui en fait le choix idéal pour déployer une architecture multi-modèles.
FAQ sur les capacités de contexte long de Claude Opus 4.7
Q1 : Anthropic affirme que le contexte long de la 4.7 est plus stable, pourquoi les données tierces disent-elles le contraire ?
Il s'agit d'une confusion entre deux concepts : "exécution prolongée" et "récupération en contexte long". La "stabilité" mise en avant par Anthropic concerne la cohérence décisionnelle dans les boucles d'agents — c'est-à-dire que le modèle ne plante pas lors de tâches complexes. Mais la "récupération en contexte long" désigne la capacité à localiser précisément une information à une distance importante, ce qui est une dimension technique totalement différente.
Le benchmark MRCR v2 8-needle mesure directement cette seconde capacité, et c'est précisément là que la fiche système officielle d'Anthropic reconnaît que l'Opus 4.6 surpasse la 4.7. Par conséquent, les deux affirmations ne sont pas contradictoires, elles ne mesurent tout simplement pas la même chose.
Q2 : Dois-je immédiatement revenir à la 4.6 pour mes applications RAG sur documents longs ?
Cela dépend de votre situation :
- Cœur de métier dépendant d'une récupération > 128k : Revenez immédiatement. Une chute de moitié de la précision sur MRCR 1M n'est pas négligeable et impactera directement la qualité de vos réponses.
- Contexte entre 32k et 128k : Je recommande de faire des tests A/B. Si la qualité est acceptable, vous pouvez continuer avec la 4.7, sinon repassez à la 4.6.
- Contexte inférieur à 32k : L'écart entre les deux modèles est minime, choisissez en fonction d'autres critères (coût, latence).
Il est recommandé d'effectuer des tests A/B via la plateforme APIYI apiyi.com, qui permet l'invocation du modèle en parallèle pour comparer les versions 4.6 et 4.7.
Q3 : Pourquoi Anthropic a-t-il permis une telle régression ?
D'après les informations révélées dans la fiche système officielle, Anthropic a fait un arbitrage conscient : concentrer le budget d'entraînement sur le codage par agent et la compréhension visuelle, au détriment d'une partie de la précision de récupération en contexte long.
Cette stratégie correspond aux priorités commerciales actuelles d'Anthropic — Claude Code et les flux de travail d'agents en entreprise sont leurs sources de revenus les plus importantes. Mais pour les utilisateurs de documents longs, de RAG ou d'agents de recherche, ce changement de cap signifie une dégradation.
En suggérant directement dans sa fiche système de "garder la 4.6 comme solution de repli", Anthropic indique implicitement : ce n'est pas un bug, c'est une stratégie, adaptez-vous.
Q4 : À quel point la chute du benchmark MRCR est-elle grave pour les activités réelles ?
C'est très grave. Le test MRCR 8-needle simule des scénarios réels où il faut "trouver plusieurs faits clés dans un document volumineux", par exemple :
- Examen de contrats : identifier toutes les clauses restrictives + dates limites + clauses de résiliation.
- Analyse financière : localiser plusieurs indicateurs financiers dans un rapport de 100 pages.
- Questions sur une base de code : suivre les définitions de variables + chaînes d'appels + dépendances à travers plusieurs fichiers.
Le passage de 78,3 % à 32,2 % sur le MRCR signifie que, pour ce type de tâche, la 4.7 manquera en moyenne 2/3 des informations clés. Pour les entreprises dépendantes de la précision, c'est une régression catastrophique.
Q5 : Dans les scénarios à contexte court (< 32k), quelles sont les différences réelles entre la 4.7 et la 4.6 ?
En dessous de 32k, les capacités de contexte long de la 4.7 et de la 4.6 sont quasiment identiques. Cependant, la 4.7 se distingue sur les points suivants :
- Capacités de codage supérieures : +6,8 points sur SWE-bench Verified.
- Compréhension visuelle renforcée : haute résolution 3,75 MP.
- Appel d'outils plus précis : en tête sur MCP-Atlas.
- Coût plus élevé : augmentation du nombre de jetons de 0 à 35 %.
Ainsi, pour les contextes courts, le choix dépend principalement du type de tâche. Choisissez la 4.7 pour le codage et la 4.6 pour la rédaction, c'est le critère le plus simple à retenir.
Q6 : Existe-t-il un moyen pour que la 4.7 égale la 4.6 sur le contexte long ?
Il n'existe actuellement aucune solution au niveau de la configuration. Même en poussant le reasoning-effort au maximum, les scores MRCR de la 4.7 restent nettement inférieurs à ceux de la 4.6.
Deux solutions indirectes sont envisageables :
- Découpage RAG : diviser le contexte long en blocs de 32k-64k pour permettre à la 4.7 de travailler dans sa "zone de sécurité".
- Chaînage de modèles : utiliser la 4.6 pour la récupération en contexte long, puis transmettre les résultats à la 4.7 pour le raisonnement global.
La seconde solution peut être facilement mise en œuvre via l'interface multi-modèles de la plateforme APIYI apiyi.com, qui supporte l'invocation du modèle de manière unifiée pour plusieurs modèles majeurs.
Résumé de la régression du contexte long de Claude Opus 4.7
La régression des capacités de contexte long de Claude Opus 4.7 est un problème réel, étayé par des données officielles, vérifié par la communauté et ayant un impact clairement défini. Conclusion :
- Reconnaissance officielle : Le score MRCR v2 8-needle est divisé par deux sur 256k et 1M, et la fiche système d'Anthropic recommande explicitement de garder la 4.6 en secours.
- Cause profonde, un arbitrage stratégique : Anthropic a sacrifié la précision de l'attention à longue distance au profit du codage par agent et de la compréhension visuelle.
- Impact concentré sur les scénarios 128k+ : La 4.7 reste utilisable en contexte court, mais la régression devient non linéaire au-delà de 128k.
- Opus 4.6 reste le meilleur modèle pour le contexte long : Un constat partagé par des observateurs reconnus comme Rohan Paul, surpassant même le GPT-5.2.
- La meilleure réponse est le routage par scénario : Utilisez la 4.6 pour les documents longs, la 4.7 pour le codage, et envisagez GPT-5.4 Pro pour la recherche approfondie.
Pour les utilisateurs, la bonne attitude n'est pas d'attendre une "correction" d'Anthropic — cet ajustement est stratégique et ne sera pas annulé à court terme — mais de préparer immédiatement un routage multi-modèles au niveau de l'invocation. Faites de la 4.6 votre choix par défaut pour les scénarios de contexte long et réservez la 4.7 pour ses tâches de prédilection : le codage par agent.
Cela s'inscrit dans la nouvelle tendance de l'industrie de l'IA en 2026 : l'ère du modèle unique couvrant tous les scénarios est terminée, chaque modèle évolue vers une spécialisation. L'exigence pour les utilisateurs passe du choix du "meilleur modèle" à la "conception d'un routage multi-modèles optimal".
Nous recommandons d'utiliser la plateforme APIYI apiyi.com pour gérer de manière unifiée vos invocations de modèles de la gamme Claude. La plateforme propose des comparaisons de benchmarks en temps réel, un routage intelligent multi-modèles et une interface API entièrement compatible avec l'officielle, constituant un outil pragmatique pour faire face à la régression du contexte long de l'Opus 4.7.
Références
-
Fiche technique Anthropic Opus 4.7 : Fiche système officielle de 232 pages
- Lien :
anthropic.com/news/claude-opus-4-7 - Description : Contient les données complètes du benchmark MRCR v2 et des recommandations de migration.
- Lien :
-
Analyse approfondie de la fiche système Opus 4.7 : Analyse de la communauté DEV
- Lien :
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Description : Résumé de la fiche système de 232 pages du point de vue d'un développeur.
- Lien :
-
Guide de migration Anthropic : Guide de migration vers Opus 4.7
- Lien :
platform.claude.com/docs/en/about-claude/models/migration-guide - Description : Conseils officiels de migration et points d'attention concernant la fenêtre de contexte étendue.
- Lien :
-
Classement des benchmarks de contexte long : Classement des benchmarks de contexte long
- Lien :
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Description : Comparaison transversale entre MRCR, RULER et LongBench v2.
- Lien :
-
Commentaire de Rohan Paul sur X : Analyse d'Opus 4.6, champion du contexte long
- Lien :
x.com/rohanpaul_ai/status/2019545018051240059 - Description : Évaluation par un observateur indépendant des avantages d'Opus 4.6 en matière de contexte long.
- Lien :
Auteur : Équipe technique APIYI
Date de publication : 18/04/2026
Modèles applicables : Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Échanges techniques : N'hésitez pas à obtenir des crédits de test pour différents modèles via APIYI (apiyi.com) pour tester vous-même les différences de précision de récupération selon les longueurs de fenêtre de contexte.