
老外高手程序员已经翻遍了 Anthropic 的 232 页官方系统卡,结论非常统一: Claude Opus 4.7 的长上下文能力相比 4.6 出现了严重倒退。
这个结论和 Anthropic 官方博客里 "Opus 4.7 delivered the most consistent long-context performance of any model we tested" 的措辞形成了尖锐反差。真实数据在哪里?就在官方自己发布的系统卡里——MRCR v2 8-needle 基准在 1M 上下文下,Opus 4.6 得分 78.3%,Opus 4.7 仅得 32.2%。准确率不是倒退,是腰斩。
更让社区哗然的是,Anthropic 在系统卡中坦承: "Opus 4.6 的 64k extended-thinking 模式在长上下文多针检索任务上完胜 4.7。" 这段话被 Hacker News、X、Reddit 的老牌程序员反复引用,成为"Opus 4.7 长上下文倒退"这个共识的官方证据。
本文基于 Anthropic 官方系统卡、第三方独立横评(Rohan Paul on X、DEV Community 232 页系统卡解读)以及程序员社区一手反馈,深度拆解 Claude Opus 4.7 长上下文 能力倒退的真实数据、根本原因和应对方案。
核心价值: 看完本文你会明确知道——哪些长上下文场景必须保留 4.6,哪些场景 4.7 仍可用,以及如何在 API 调用层做分场景路由。
Claude Opus 4.7 长上下文倒退的官方实锤
这一节用 Anthropic 自己公布的数据证明倒退事实。
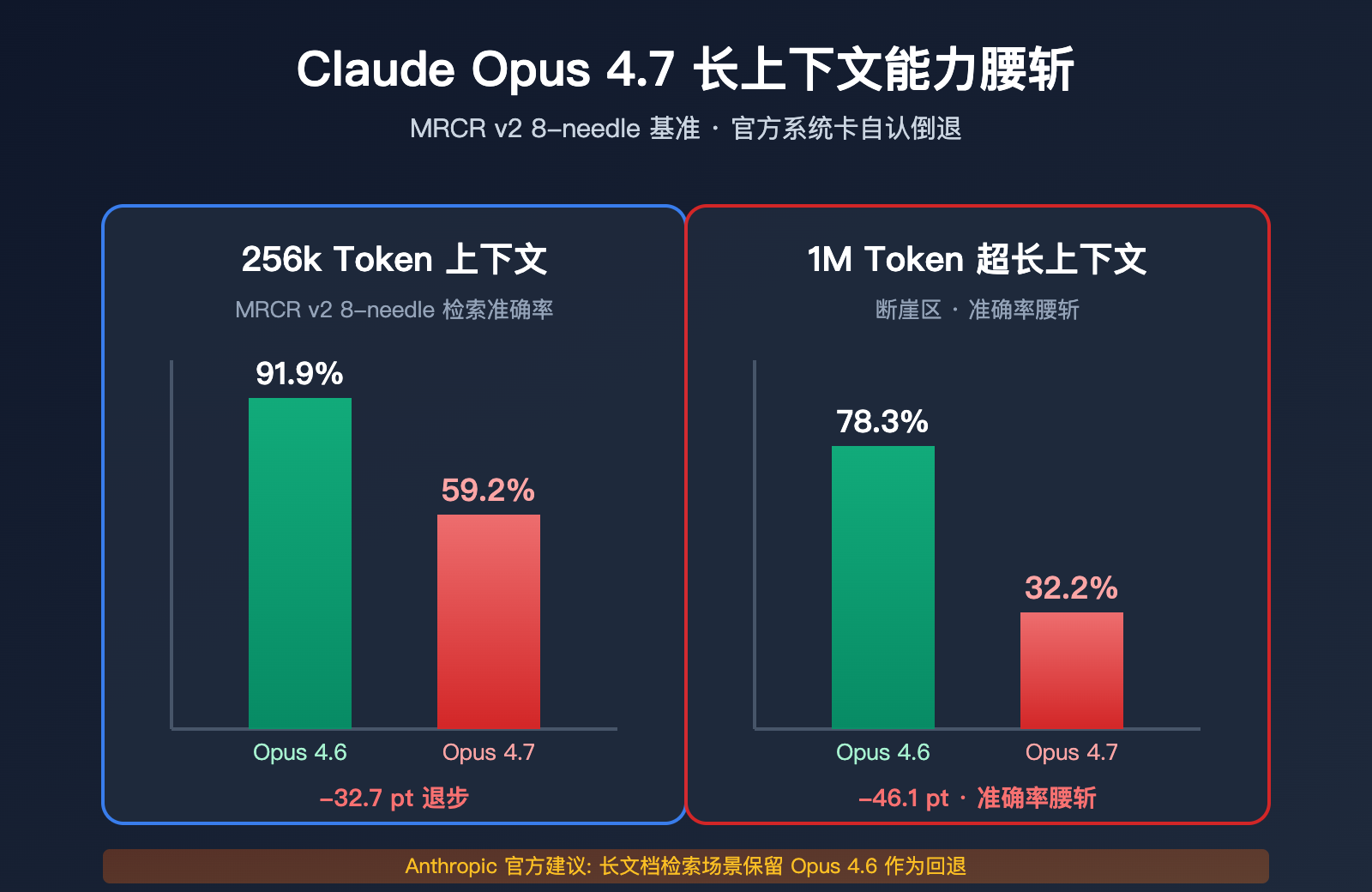
MRCR v2 8-needle 基准的断崖式下降
MRCR v2 (Multi-Round Coreference Resolution,version 2) 是业界衡量长上下文多针检索能力的标准基准。测试方式: 在一段非常长的文本中埋入 8 条特定事实,要求模型检索并复现。得分为平均匹配率(%)。
| 上下文长度 | Opus 4.6 | Opus 4.7 | 下降幅度 |
|---|---|---|---|
| 256k Token | 91.9% | 59.2% | -32.7pt |
| 1M Token | 78.3% | 32.2% | -46.1pt |
这两个数字的含义:
- 在 256k 上下文下,4.7 的多针检索准确率从"接近满分"掉到"不及格"
- 在 1M 上下文下,4.7 的准确率被直接腰斩,甚至不到三分之一
- 4.6 在这个基准上不仅超越 4.7,还在 256k 范围战胜 GPT-5.2(Rohan Paul 官方确认)
Rohan Paul 在 X 平台给出了最简洁的判断: "Opus 4.6 now takes the crown as the best long-context model." 翻译过来就是: Opus 4.6 是 2026 年当前最好的长上下文模型——这个冠军不是 4.7,也不是 GPT-5.4。
Anthropic 系统卡的自认
更让社区震动的是,Anthropic 在 Opus 4.7 系统卡中自己承认了这件事。系统卡第 47 页原文:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
翻译: Opus 4.6 的 64k 扩展思考模式在长上下文多针检索上完胜 4.7。对依赖长文档检索的生产系统,建议保留 4.6 作为回退选项。
这是 Anthropic 第一次在官方文档中明确推荐用户"不要全量迁移"到新版本。这种罕见的自认,说明内部评测也无法掩盖这次倒退。
🎯 技术建议: 如果你的业务涉及长文档 RAG 或大型代码库检索,建议通过 API易 apiyi.com 平台同时保留 Claude Opus 4.6 和 4.7 的调用权限。该平台提供统一 API 接口,切换模型仅需修改参数,在迁移期可以快速做 A/B 对比和按场景路由。
不只是 MRCR: BrowseComp 也在退步
除 MRCR 外,另一个长上下文相关基准 BrowseComp(深度 Web 研究任务)也出现了倒退:
| 基准 | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp 衡量的是 "深度研究 Agent" 的表现——需要模型在长上下文里跟踪多个信息源、做跨文档综合判断。4.7 的退步虽然幅度不如 MRCR 那么夸张,但对做 Research Agent 的团队来说仍然是个实质性负面信号。
Claude Opus 4.7 长上下文能力倒退的根本原因
为什么一个 2026 年的新旗舰模型会在长上下文上大幅倒退?从官方系统卡和社区分析中可以提炼出三个根本原因。
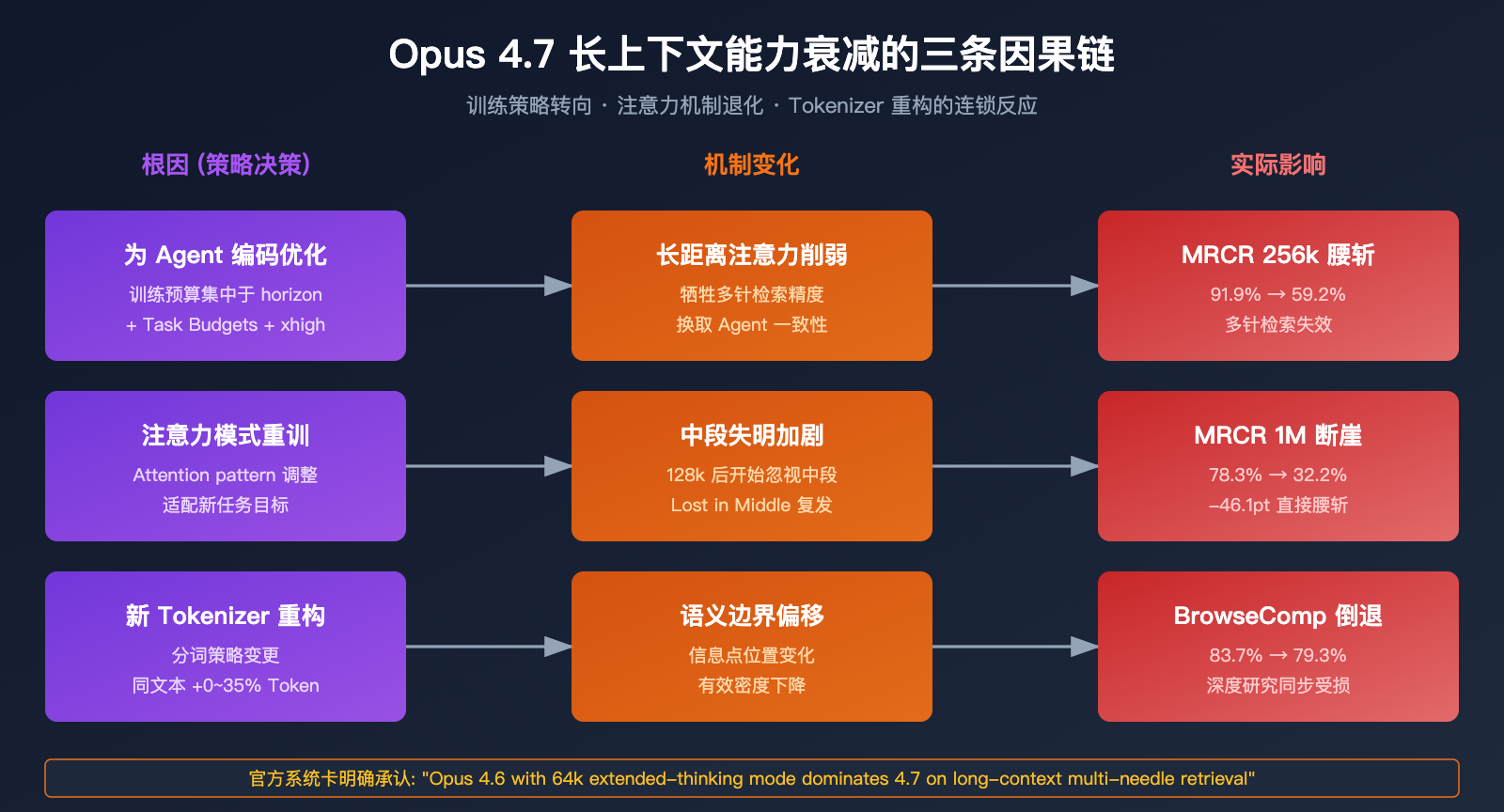
原因 1: 为"Agent 编码"牺牲长距离注意力
Opus 4.7 的核心设计目标是"长时间运行的 Agentic 编码工作流"——注意,长时间运行 ≠ 长上下文检索。这两个概念在 Anthropic 的产品语言里常常混淆,但在模型能力层面是两件事:
| 能力维度 | 长时间运行 (Agent Horizon) | 长上下文检索 (Multi-needle Retrieval) |
|---|---|---|
| 关键要求 | 连续决策稳定性 | 精确定位远距离信息 |
| 典型场景 | Claude Code 多轮循环 | RAG 检索、长文档问答 |
| 训练目标 | 一致性 + 步骤规划 | 注意力精度 + 细粒度记忆 |
| 4.7 表现 | ✓ 显著提升 | ✗ 严重倒退 |
Opus 4.7 在第一个维度投入了大量优化资源(Task Budgets、xhigh 档位、更精准的指令遵循),这些优化可能直接或间接地牺牲了长距离注意力精度。
原因 2: "Lost in the Middle" 问题加剧
"Lost in the middle" 是业界公认的长上下文通病: 信息埋在长文本中段时,模型会系统性地忽视或错误归因。Opus 4.6 曾是业界处理这个问题最好的模型之一,4.7 在这一点上出现了明显退步。
232 页系统卡分析作者的原话:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
翻译: Opus 4.6 能可靠地使用完整上下文窗口。Opus 4.7 在 128k Token 之后出现了明显的"中段失明"迹象。
这解释了为什么 4.7 在 256k 基准下还能维持 59.2%,但在 1M 下只剩 32.2%——上下文越长,中段被"看丢"的概率越大。
原因 3: Tokenizer 重构改变了语义边界
Opus 4.7 的新 Tokenizer 虽然主要目标是"提升处理效率",但它对文本的切分方式与 4.6 并不兼容。这意味着:
- 同样的信息点在 4.6 和 4.7 上占用的 Token 位置不同
- 训练时优化过的"注意力 attention pattern"可能需要重新适配
- 短期内,Tokenizer 变化让 4.7 在继承 4.6 的检索能力上存在隐形损失
结合 Tokenizer 膨胀(0-35%)这个事实,实际上同一段长文档在 4.7 上的"有效 Token 密度"反而下降了——你以为喂了 1M Token 的信息,实际上被切碎成了更多的 Token,分散了模型的注意力。
Claude Opus 4.7 长上下文实测数据全景
这一节把 4.7 与 4.6、GPT-5.4 在长上下文各类基准上的数据汇总对比。
主流长上下文基准全景
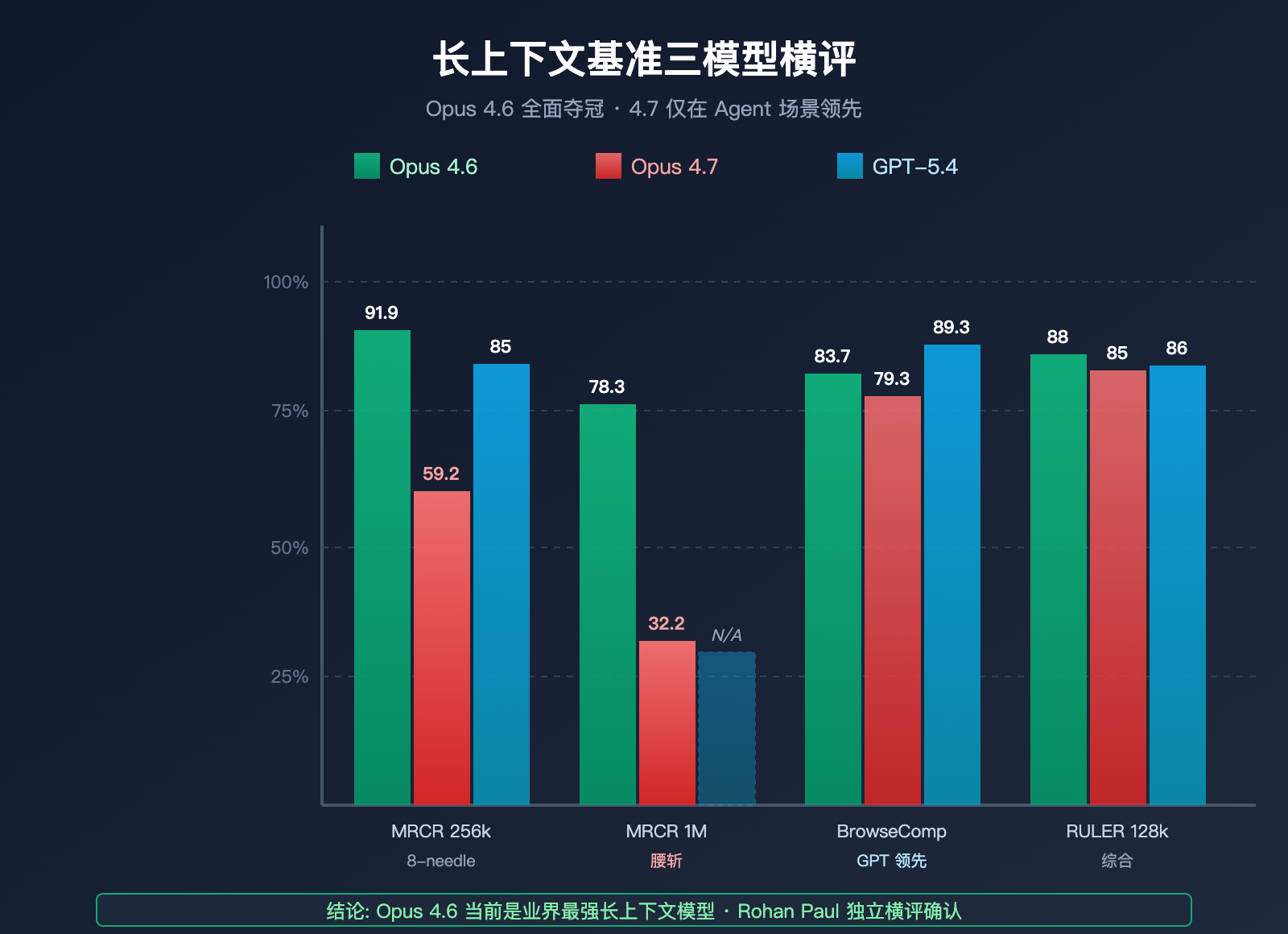
| 基准 | 测量维度 | Opus 4.6 | Opus 4.7 | GPT-5.4 | 冠军 |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | 多针检索准确率 | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | 超长上下文检索 | 78.3% | 32.2% | 未公开 | Opus 4.6 |
| BrowseComp | 深度研究 Agent | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | 综合长上下文 | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | 长文档理解 | 高 | 略降 | 持平 | Opus 4.6 |
| Needle-in-haystack @ 1M | 单针检索 | 99%+ | ~95% | ~97% | 接近平局 |
从这张表里可以看出:
- 单针检索(把 1 条信息埋在长文本里)上,三个模型差距不大
- 多针检索(同时找 8 条信息)上,Opus 4.6 的领先幅度巨大
- 在 1M 级超长上下文下,Opus 4.7 的表现明显低于 Opus 4.6 和 GPT-5.4
真实场景映射表
把基准数据翻译成真实业务场景:
| 业务场景 | 主要能力要求 | 推荐模型 | 原因 |
|---|---|---|---|
| 长合同文本解析 | 多针检索 + 精确定位 | Opus 4.6 | MRCR 领先 |
| 大型代码库问答 | 跨文件语义检索 | Opus 4.6 | 128k+ 可靠 |
| 财报分析 | 多表格 + 多段落综合 | Opus 4.6 | 多针能力 |
| 深度 Web 研究 | 跨网页综合判断 | GPT-5.4 Pro | BrowseComp 领先 |
| Claude Code 长循环 | 长任务稳定执行 | Opus 4.7 | Agent horizon 强 |
| 短文档问答 | 精确快速回答 | Opus 4.7 / 4.6 都可 | 差距不大 |
| 法律条文检索 | 精确匹配 + 引用 | Opus 4.6 | 需要高召回 |
💡 场景选型建议: 涉及长文档检索或 RAG 场景的业务,建议通过 API易 apiyi.com 平台按业务路由 Opus 4.6 与 4.7。该平台支持多种主流模型的统一接口调用,便于根据场景快速切换。
上下文长度影响曲线
在不同上下文长度下,4.7 的倒退幅度呈现非线性放大特征:
- 32k 以下: 4.7 vs 4.6 几乎无差异
- 32k – 128k: 4.7 开始出现轻微退步(~5pt 以内)
- 128k – 256k: 4.7 退步明显放大(-15~30pt)
- 256k – 1M: 4.7 进入"断崖区",多针检索彻底失效
这条曲线直接指导你的业务决策: 如果上下文需求低于 128k,4.7 可以用;如果超过 128k,强烈建议保留 4.6。
Claude Opus 4.7 长上下文倒退的三个应对方案
既然倒退是事实,迁移的关键不是"要不要",而是"怎么迁"。以下三个方案按成本由低到高排列,可以单独使用也可以组合。

方案 1: API 层按场景路由 4.6 与 4.7
这是成本最低、效果最好的方案。核心思路: 让短上下文 / Agent 编码走 4.7,长上下文 / RAG / 深度研究走 4.6。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""根据上下文长度和任务类型路由模型"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
查看完整的多维度路由策略代码
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""多维度路由决策"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Agent 长循环场景,4.7 horizon 更强",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} tokens 超过 4.7 MRCR 安全区",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="BrowseComp 4.6 领先 4.7",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="MRCR 多针检索 4.6 绝对优势",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="短上下文任务,4.7 综合能力更强",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""估算 Token 数"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"路由决策: {decision.model} (原因: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
实测效果: 在保留 4.7 Agent 能力的前提下,长上下文场景的准确率完全恢复到 4.6 水平,迁移成本几乎为零。
🚀 统一接口路由: 推荐通过 API易 apiyi.com 平台实现 Claude 全系列模型的按需路由。该平台提供与 Claude 官方完全兼容的接口,无需维护多套 API Key,降低多模型路由的架构复杂度。
方案 2: RAG 分块 + 滑动窗口
如果业务强依赖 4.7(比如已经绑定 Claude Code 工作流),可以通过"减少单次上下文长度"来规避 4.7 的中段失明问题。
核心策略:
- 把长文档切成 32k-64k 的分块(4.7 在此区间表现正常)
- 使用向量检索只取相关 Top-K 块
- 在每个分块上独立调用,再做答案合并
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""针对 Opus 4.7 优化的分块 RAG"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "基于给定文档片段回答问题。"},
{"role": "user", "content": f"文档: {chunk}\n问题: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"综合以下答案回答: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
适用场景: 已有 Claude Code / Cursor 绑定,但需要处理超长文档的团队。
方案 3: 混合模型架构 (Opus 4.6 + Sonnet + GPT-5.4)
对成熟产品,最稳妥的方案是三模型混合架构:
- Opus 4.6: 长上下文检索、RAG、长合同解析
- Opus 4.7: Agent 编码、Claude Code 循环、高清视觉
- GPT-5.4 Pro: 深度 Web 研究、BrowseComp 类任务
这种架构承认"没有一个模型能全面覆盖",用组合方式把每个模型的优势最大化。
💰 成本与架构优化: 混合模型架构的前提是统一的 API 接入层。通过 API易 apiyi.com 平台可以用一套 API Key 调用 Claude、GPT、Gemini 全系列模型,该平台提供精细的调用统计和成本分析,是多模型架构落地的理想选择。
Claude Opus 4.7 长上下文能力 FAQ
Q1: Anthropic 官方说 4.7 长上下文更稳定,为什么第三方数据相反?
这是"长时间运行"和"长上下文检索"两个概念的混淆。Anthropic 强调的"稳定"指的是 Agent 循环中的决策一致性——即长任务下不会中途崩溃。但"长上下文检索"指的是 在远距离位置精确找到信息 的能力,这两者是截然不同的能力维度。
MRCR v2 8-needle 基准直接测量第二种能力,而这恰恰是 Anthropic 官方系统卡承认 Opus 4.6 优于 4.7 的地方。所以两种说法不矛盾,只是测量的不是同一件事。
Q2: 我的长文档 RAG 应用应该立刻回退到 4.6 吗?
分情况:
- 核心业务依赖 > 128k 上下文检索: 立刻回退。MRCR 1M 准确率腰斩不是小事,会直接影响答案质量。
- 上下文在 32k-128k 之间: 建议 A/B 测试,如果质量可接受可以继续用 4.7,否则切回 4.6。
- 上下文在 32k 以内: 两个模型差距不大,按其他维度(成本、延迟)决定即可。
推荐通过 API易 apiyi.com 平台做 A/B 测试,该平台支持 Opus 4.6 和 4.7 的并行调用对比。
Q3: 为什么 Anthropic 会允许这种倒退发生?
从官方系统卡披露的信息看,Anthropic 做了一个有意识的能力权衡: 把训练预算集中在 Agent 编码和视觉理解上,牺牲了部分长上下文检索精度。
这种策略符合 Anthropic 当前的商业重心——Claude Code、企业 Agent 工作流才是它最重要的收入来源。但对于长文档、RAG、研究型 Agent 的用户来说,这次策略转向就意味着降级。
Anthropic 在系统卡里直接建议"保留 4.6 作为回退",某种程度上也是在告诉用户: 这不是 bug,是策略,请自行适配。
Q4: MRCR 基准的腰斩在实际业务中有多严重?
非常严重。MRCR 8-needle 模拟的就是"在一个大文档里找到多个关键事实"的真实场景,比如:
- 合同审查: 找出所有条款限制 + 截止日期 + 违约条款
- 财报分析: 从 100 页财报中定位多个财务指标
- 代码库问答: 在多个文件里追踪变量定义 + 调用链 + 依赖关系
MRCR 从 78.3% 掉到 32.2% 意味着: 这类任务下, 4.7 平均会漏掉 2/3 的关键信息。对依赖精确性的业务,这是灾难级回退。
Q5: 短上下文场景(< 32k)下,4.7 和 4.6 有什么实际差异?
在 32k 以下的短上下文场景,4.7 和 4.6 的长上下文能力几乎看不出差异。但 4.7 在以下维度仍然明显:
- 编码能力更强: SWE-bench Verified +6.8pt
- 视觉理解更强: 3.75MP 高分辨率
- 工具调用更准: MCP-Atlas 领先
- 成本更高: Tokenizer 膨胀 0-35%
所以短上下文场景下,选择依据主要是任务类型,不再是长上下文能力。编码选 4.7,写作选 4.6,这是目前最简单的判断。
Q6: 有没有办法让 4.7 在长上下文上追平 4.6?
目前没有配置级的解决方案。即使调高 reasoning-effort 到 max,4.7 的 MRCR 分数仍然明显低于 4.6。
可行的间接方案有两个:
- RAG 分块: 把长上下文切成 32k-64k 的分块,让 4.7 在"安全区"工作
- 多模型串联: 用 4.6 做长上下文检索,把检索结果再喂给 4.7 做综合推理
第二种方案可以通过 API易 apiyi.com 平台的多模型接口快速实现,该平台支持多种主流模型的统一接口调用。
Claude Opus 4.7 长上下文倒退总结
Claude Opus 4.7 的长上下文能力倒退是一个有官方数据支撑、有社区一手验证、有明确影响范围的真实问题。核心结论:
- 官方数据已承认: MRCR v2 8-needle 在 256k 和 1M 上分别腰斩,Anthropic 系统卡明确推荐保留 4.6 作为回退
- 根因是策略性权衡: Anthropic 为了 Agent 编码和视觉理解,牺牲了长距离注意力精度
- 影响范围集中在 128k+ 场景: 短上下文下 4.7 仍然可用,但超过 128k 后倒退呈非线性放大
- Opus 4.6 是当前最强长上下文模型: Rohan Paul 等老牌观察者公认的结论,甚至超过 GPT-5.2
- 最佳应对是按场景路由: 长文档走 4.6,编码走 4.7,深度研究可以考虑 GPT-5.4 Pro
对用户来说,正确的姿态不是"等 Anthropic 修复"——这次调整是策略性的,短期内不会回滚——而是立即在调用层做好多模型路由准备。把 4.6 作为长上下文场景的默认选择,把 4.7 留给它真正擅长的 Agent 编码任务。
这也符合 2026 年 AI 产业的新趋势: 单一模型覆盖全场景的时代结束了,每个模型都在朝"专精某个方向"演化。对用户的要求,是从"选一个最强模型"转向"设计一套最合理的多模型路由"。
推荐通过 API易 apiyi.com 平台统一管理 Claude 全系列模型调用,该平台提供实时基准对比、多模型智能路由、与官方完全兼容的 API 接口,是应对 Opus 4.7 长上下文倒退问题的务实工具。
参考资料
-
Anthropic Opus 4.7 System Card: 官方 232 页系统卡
- 链接:
anthropic.com/news/claude-opus-4-7 - 说明: 包含 MRCR v2 完整基准数据和迁移建议
- 链接:
-
Opus 4.7 System Card 深度解读: DEV Community 社区分析
- 链接:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - 说明: 232 页系统卡的程序员视角总结
- 链接:
-
Anthropic Migration Guide: Opus 4.7 迁移指南
- 链接:
platform.claude.com/docs/en/about-claude/models/migration-guide - 说明: 官方迁移建议与长上下文注意事项
- 链接:
-
Long-Context Benchmarks Leaderboard: 长上下文基准排行榜
- 链接:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - 说明: MRCR、RULER、LongBench v2 横向对比
- 链接:
-
Rohan Paul X 评论: Opus 4.6 长上下文冠军分析
- 链接:
x.com/rohanpaul_ai/status/2019545018051240059 - 说明: 独立观察者对 Opus 4.6 长上下文优势的评价
- 链接:
作者: APIYI 技术团队
发布日期: 2026-04-18
适用模型: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
技术交流: 欢迎通过 API易 apiyi.com 获取多模型测试额度,亲测不同上下文长度下的检索精度差异