
Erfahrene Entwickler haben die 232-seitige offizielle Systemkarte von Anthropic akribisch durchforstet, und das Fazit ist eindeutig: Die Leistung von Claude Opus 4.7 bei langen Kontexten ist im Vergleich zu 4.6 massiv eingebrochen.
Dieses Ergebnis steht in krassem Widerspruch zur offiziellen Formulierung im Anthropic-Blog, wonach „Opus 4.7 die konsistenteste Leistung bei langen Kontexten aller von uns getesteten Modelle lieferte“. Wo finden sich die echten Daten? Direkt in der offiziellen Systemkarte: Beim MRCR v2 8-Needle-Benchmark mit 1 Mio. Token Kontext erreichte Opus 4.6 noch 78,3 %, während Opus 4.7 nur auf 32,2 % kam. Das ist kein bloßer Rückschritt, das ist eine Halbierung der Genauigkeit.
Was die Community noch mehr aufschreckte, ist das Eingeständnis von Anthropic in der Systemkarte: „Der 64k Extended-Thinking-Modus von Opus 4.6 übertrifft 4.7 bei Multi-Needle-Retrieval-Aufgaben mit langem Kontext bei weitem.“ Dieser Satz wird in Entwicklerkreisen auf Hacker News, X und Reddit ständig zitiert und dient als offizieller Beleg für den Rückschritt von Opus 4.7.
Dieser Artikel analysiert auf Basis der offiziellen Systemkarte, unabhängiger Tests (Rohan Paul auf X, DEV Community-Analysen) und direktem Feedback aus der Entwickler-Community die Daten, Ursachen und Lösungsansätze für den Leistungsabfall von Claude Opus 4.7 bei langen Kontexten.
Kernnutzen: Nach diesem Artikel wissen Sie genau, für welche Szenarien Sie zwingend bei 4.6 bleiben müssen, wo 4.7 dennoch einsetzbar ist und wie Sie auf API-Ebene ein szenariobasiertes Routing implementieren.
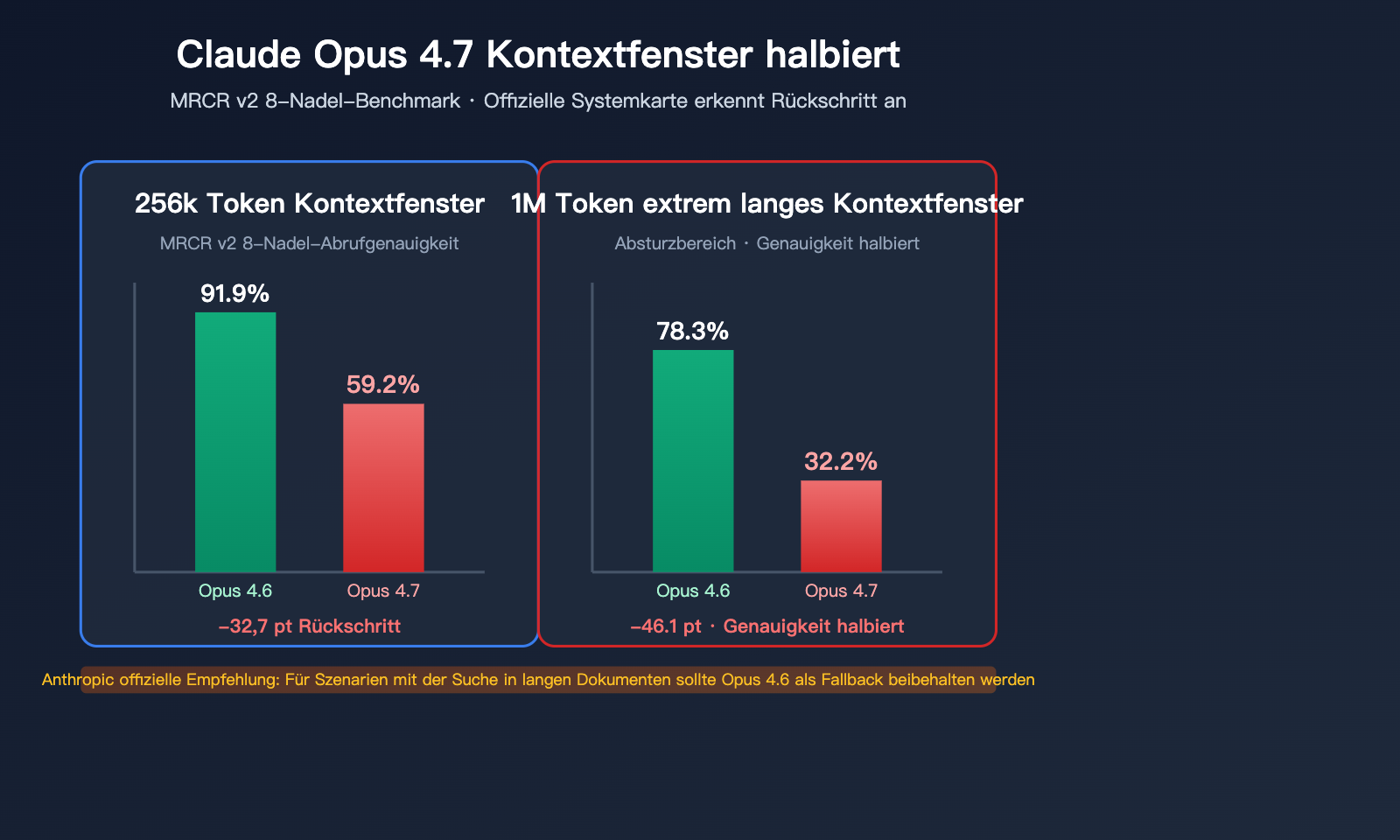
Der offizielle Beweis für den Rückschritt bei Claude Opus 4.7
Dieser Abschnitt belegt den Rückschritt anhand der von Anthropic selbst veröffentlichten Daten.
Der dramatische Abfall beim MRCR v2 8-Needle-Benchmark
MRCR v2 (Multi-Round Coreference Resolution, Version 2) ist der Industriestandard zur Messung der Fähigkeit, mehrere Informationen in langen Kontexten abzurufen. Testmethode: In einem sehr langen Text werden 8 spezifische Fakten versteckt; das Modell muss diese abrufen und reproduzieren. Die Punktzahl entspricht der durchschnittlichen Trefferquote (%).
| Kontextlänge | Opus 4.6 | Opus 4.7 | Rückgang |
|---|---|---|---|
| 256k Token | 91,9 % | 59,2 % | -32,7 pt |
| 1M Token | 78,3 % | 32,2 % | -46,1 pt |
Die Bedeutung dieser Zahlen:
- Bei 256k Kontext fiel die Genauigkeit von 4.7 beim Multi-Needle-Retrieval von „nahezu perfekt“ auf „ungenügend“.
- Bei 1M Kontext wurde die Genauigkeit von 4.7 halbiert und liegt bei weniger als einem Drittel.
- Opus 4.6 übertrifft in diesem Benchmark nicht nur 4.7, sondern schlug im 256k-Bereich sogar GPT-5.2 (offiziell bestätigt durch Rohan Paul).
Rohan Paul lieferte auf X das prägnanteste Urteil: „Opus 4.6 übernimmt nun die Krone als bestes Modell für lange Kontexte.“ Übersetzt bedeutet das: Opus 4.6 ist das derzeit beste Modell für lange Kontexte im Jahr 2026 – der Champion ist weder 4.7 noch GPT-5.4.
Das Eingeständnis in der Anthropic-Systemkarte
Was die Community noch mehr schockierte, ist, dass Anthropic dies in der Systemkarte zu Opus 4.7 selbst zugibt. Zitat von Seite 47 der Systemkarte:
„Opus 4.6 mit 64k Extended-Thinking-Modus dominiert 4.7 beim Multi-Needle-Retrieval mit langem Kontext. Für Produktionssysteme, die auf dem Abruf aus langen Dokumenten basieren, empfehlen wir, 4.6 als Fallback verfügbar zu halten.“
Übersetzung: Der 64k-Modus von Opus 4.6 übertrifft 4.7 bei der Suche in langen Dokumenten deutlich. Für produktive Systeme wird empfohlen, 4.6 als Ausweichoption beizubehalten.
Dies ist das erste Mal, dass Anthropic in einem offiziellen Dokument explizit davon abrät, vollständig auf eine neue Version zu migrieren. Dieses seltene Eingeständnis zeigt, dass selbst interne Tests diesen Rückschritt nicht verbergen konnten.
🎯 Technische Empfehlung: Wenn Ihr Unternehmen RAG mit langen Dokumenten oder die Analyse großer Codebasen nutzt, sollten Sie über die APIYI-Plattform (apiyi.com) den Zugriff auf Claude Opus 4.6 und 4.7 parallel beibehalten. Die Plattform bietet eine einheitliche API-Schnittstelle, bei der der Modellwechsel nur eine Parameteranpassung erfordert. So können Sie in der Migrationsphase schnell A/B-Tests durchführen und ein szenariobasiertes Routing implementieren.
Nicht nur MRCR: Auch BrowseComp zeigt Schwächen
Neben MRCR zeigte auch der BrowseComp-Benchmark (für tiefgreifende Web-Rechercheaufgaben) einen Rückschritt:
| Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83,7 % | 79,3 % | 89,3 % |
BrowseComp misst die Leistung von „Deep Research Agents“ – das Modell muss über lange Kontexte hinweg mehrere Informationsquellen verfolgen und dokumentübergreifende Schlussfolgerungen ziehen. Obwohl der Rückgang bei 4.7 hier nicht so drastisch ausfällt wie bei MRCR, ist er für Teams, die Research-Agenten entwickeln, dennoch ein deutliches Warnsignal.
Die Grundursachen für den Leistungsabfall bei der langen Kontextverarbeitung von Claude Opus 4.7
Warum zeigt ein neues Flaggschiff-Modell aus dem Jahr 2026 einen derart massiven Rückschritt bei der Verarbeitung langer Kontexte? Aus den offiziellen Systemkarten und Analysen der Community lassen sich drei grundlegende Ursachen ableiten.

Ursache 1: Opferung der Langstrecken-Aufmerksamkeit für "Agent-Codierung"
Das zentrale Designziel von Opus 4.7 sind "lang laufende Agenten-Codierungs-Workflows" – beachten Sie: lang laufend ≠ Abruf langer Kontexte. Diese beiden Konzepte werden in der Produktsprache von Anthropic oft vermischt, sind aber auf der Ebene der Modellfähigkeiten zwei verschiedene Dinge:
| Fähigkeitsdimension | Lang laufend (Agent Horizon) | Abruf langer Kontexte (Multi-needle Retrieval) |
|---|---|---|
| Kernanforderung | Stabilität bei kontinuierlichen Entscheidungen | Präzise Lokalisierung weit entfernter Informationen |
| Typische Szenarien | Claude Code Multi-Turn-Schleifen | RAG-Abruf, Beantwortung langer Dokumente |
| Trainingsziel | Konsistenz + Schrittplanung | Aufmerksamkeitsgenauigkeit + feingranulares Gedächtnis |
| 4.7 Leistung | ✓ Deutliche Verbesserung | ✗ Schwerer Rückschritt |
Opus 4.7 hat erhebliche Optimierungsressourcen in die erste Dimension investiert (Task Budgets, xhigh-Modus, präzisere Befolgung von Anweisungen). Diese Optimierungen haben möglicherweise direkt oder indirekt die Genauigkeit der Langstrecken-Aufmerksamkeit geopfert.
Ursache 2: Verschärfung des "Lost in the Middle"-Problems
"Lost in the Middle" ist ein in der Branche bekanntes Problem bei langen Kontexten: Wenn Informationen in der Mitte eines langen Textes eingebettet sind, ignoriert das Modell diese systematisch oder ordnet sie falsch zu. Opus 4.6 war eines der besten Modelle der Branche bei der Bewältigung dieses Problems; 4.7 zeigt hier einen deutlichen Rückschritt.
Der Autor der 232-seitigen Systemkarten-Analyse schreibt dazu:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
Übersetzung: Opus 4.6 nutzt sein vollständiges Kontextfenster zuverlässig. Opus 4.7 zeigt erste Anzeichen von "Blindheit in der Mitte des Kontexts", insbesondere jenseits von 128k Token.
Dies erklärt, warum 4.7 bei einem 256k-Benchmark noch 59,2 % halten konnte, bei 1M Token jedoch nur noch 32,2 % erreichte – je länger der Kontext, desto größer ist die Wahrscheinlichkeit, dass die Mitte "übersehen" wird.
Ursache 3: Tokenizer-Refactoring verändert semantische Grenzen
Obwohl das Hauptziel des neuen Tokenizers von Opus 4.7 die "Verbesserung der Verarbeitungseffizienz" war, ist seine Art der Textsegmentierung nicht mit der von 4.6 kompatibel. Das bedeutet:
- Dieselben Informationspunkte belegen bei 4.6 und 4.7 unterschiedliche Token-Positionen.
- Das während des Trainings optimierte "Aufmerksamkeitsmuster (Attention Pattern)" muss möglicherweise neu angepasst werden.
- Kurzfristig führt die Änderung des Tokenizers zu einem unsichtbaren Verlust bei der Übernahme der Abruffähigkeiten von 4.6.
In Kombination mit der Tatsache der Token-Expansion (0–35 %) ist die "effektive Token-Dichte" eines langen Dokuments bei 4.7 tatsächlich gesunken – man glaubt, 1M Token an Informationen eingespeist zu haben, aber in Wirklichkeit wurden diese in mehr Token zerstückelt, was die Aufmerksamkeit des Modells zerstreut.
title: "Claude Opus 4.7: Panorama der Testergebnisse für lange Kontextfenster"
Claude Opus 4.7: Panorama der Testergebnisse für lange Kontextfenster
Dieser Abschnitt fasst die Vergleichsdaten von 4.7 mit 4.6 und GPT-5.4 über verschiedene Benchmarks für lange Kontextfenster zusammen.
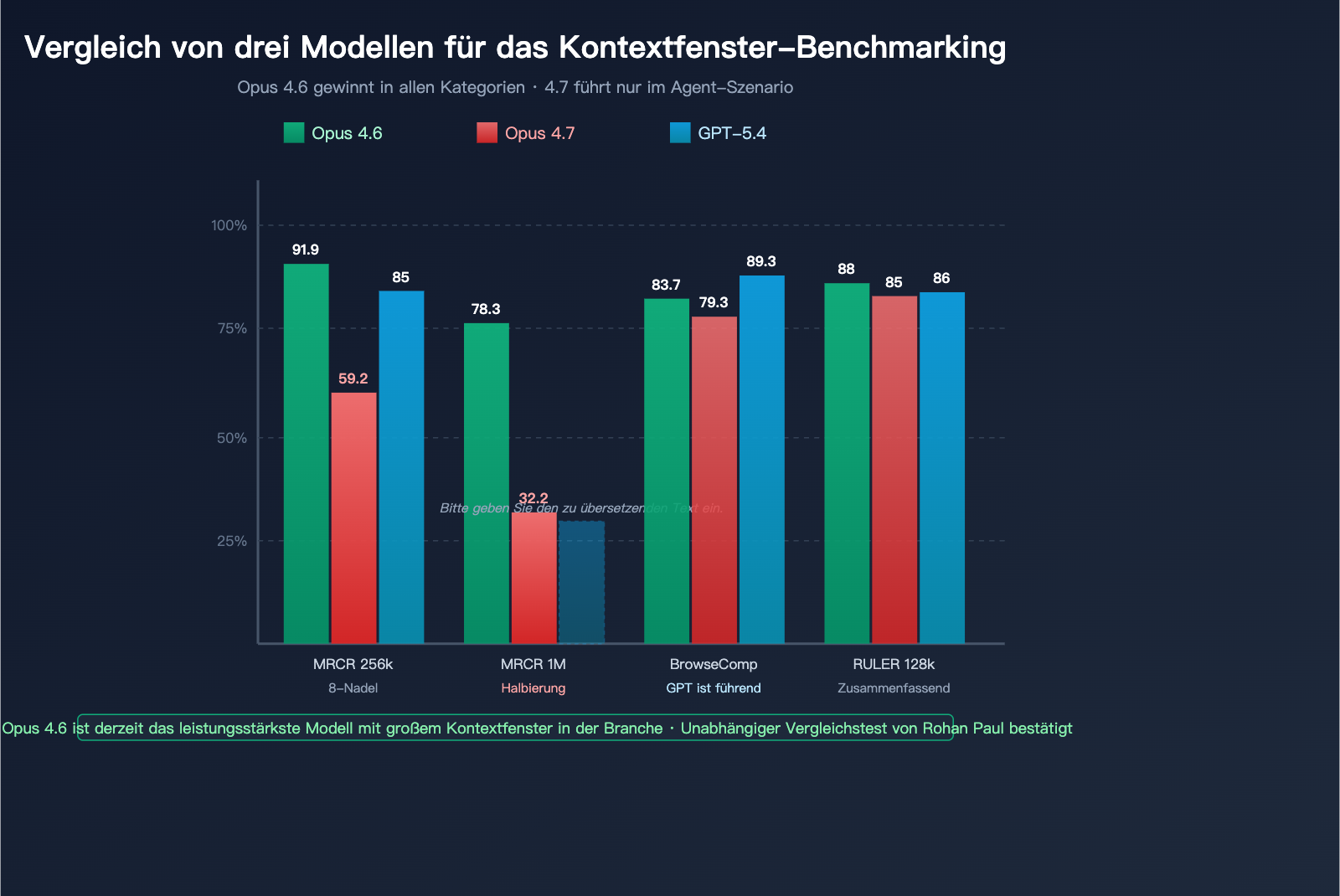
Panorama der gängigen Benchmarks für lange Kontextfenster
| Benchmark | Messdimension | Opus 4.6 | Opus 4.7 | GPT-5.4 | Sieger |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Genauigkeit der Mehrfach-Suche | 91,9 % | 59,2 % | ~85 % | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Suche im extrem langen Kontext | 78,3 % | 32,2 % | nicht publiziert | Opus 4.6 |
| BrowseComp | Deep-Research-Agent | 83,7 % | 79,3 % | 89,3 % | GPT-5.4 Pro |
| RULER @ 128k | Umfassender langer Kontext | ~88 % | ~85 % | ~86 % | Opus 4.6 |
| LongBench v2 | Verständnis langer Dokumente | hoch | leicht gesunken | gleichauf | Opus 4.6 |
| Needle-in-haystack @ 1M | Einzelsuche | 99 %+ | ~95 % | ~97 % | Fast unentschieden |
Aus dieser Tabelle lässt sich Folgendes ableiten:
- Bei der Einzelsuche (Verstecken einer Information in einem langen Text) gibt es kaum Unterschiede zwischen den Modellen.
- Bei der Mehrfach-Suche (gleichzeitiges Finden von 8 Informationen) führt Opus 4.6 mit großem Vorsprung.
- Bei einem extrem langen Kontext von 1M zeigt Opus 4.7 eine deutlich schwächere Leistung als Opus 4.6 und GPT-5.4.
Zuordnung zu realen Szenarien
Übersetzung der Benchmark-Daten in reale Geschäftsszenarien:
| Geschäftsszenario | Hauptanforderung | Empfohlenes Modell | Grund |
|---|---|---|---|
| Analyse langer Verträge | Mehrfach-Suche + Präzision | Opus 4.6 | Führend bei MRCR |
| Q&A für große Code-Basen | Semantische Suche über Dateien | Opus 4.6 | Zuverlässig ab 128k+ |
| Analyse von Finanzberichten | Mehrere Tabellen + Abschnitte | Opus 4.6 | Starke Mehrfach-Suche |
| Deep Web Research | Übergreifende Beurteilung | GPT-5.4 Pro | Führend bei BrowseComp |
| Claude Code Long Loop | Stabile Ausführung langer Aufgaben | Opus 4.7 | Starker Agent-Horizont |
| Q&A für kurze Dokumente | Präzise und schnelle Antwort | Opus 4.7 / 4.6 | Kaum Unterschiede |
| Suche in Rechtstexten | Präziser Abgleich + Zitate | Opus 4.6 | Hoher Recall erforderlich |
💡 Empfehlung zur Modellauswahl: Für Geschäftsszenarien, die eine Suche in langen Dokumenten oder RAG erfordern, empfiehlt es sich, Opus 4.6 und 4.7 über die Plattform APIYI (apiyi.com) je nach Anwendungsfall zu routen. Die Plattform unterstützt einheitliche Schnittstellen für verschiedene gängige Modelle, was einen schnellen Wechsel je nach Szenario ermöglicht.
Einflusskurve der Kontextlänge
Bei unterschiedlichen Kontextlängen zeigt sich bei 4.7 ein nicht-linearer Rückgang der Leistung:
- Unter 32k: Kaum Unterschiede zwischen 4.7 und 4.6.
- 32k – 128k: 4.7 zeigt erste leichte Einbußen (innerhalb von ~5 Prozentpunkten).
- 128k – 256k: Der Leistungsabfall bei 4.7 verstärkt sich deutlich (-15 bis -30 Prozentpunkte).
- 256k – 1M: 4.7 erreicht einen "Abgrund", die Mehrfach-Suche versagt vollständig.
Diese Kurve dient als direkte Entscheidungshilfe: Wenn der Kontextbedarf unter 128k liegt, ist 4.7 einsatzbereit; bei mehr als 128k wird dringend empfohlen, bei 4.6 zu bleiben.
Drei Strategien zur Bewältigung der Regression bei langen Kontexten in Claude Opus 4.7
Da die Regression eine Tatsache ist, stellt sich bei der Migration nicht die Frage nach dem „Ob“, sondern nach dem „Wie“. Die folgenden drei Strategien sind nach Kosten (von niedrig bis hoch) sortiert und können einzeln oder in Kombination eingesetzt werden.
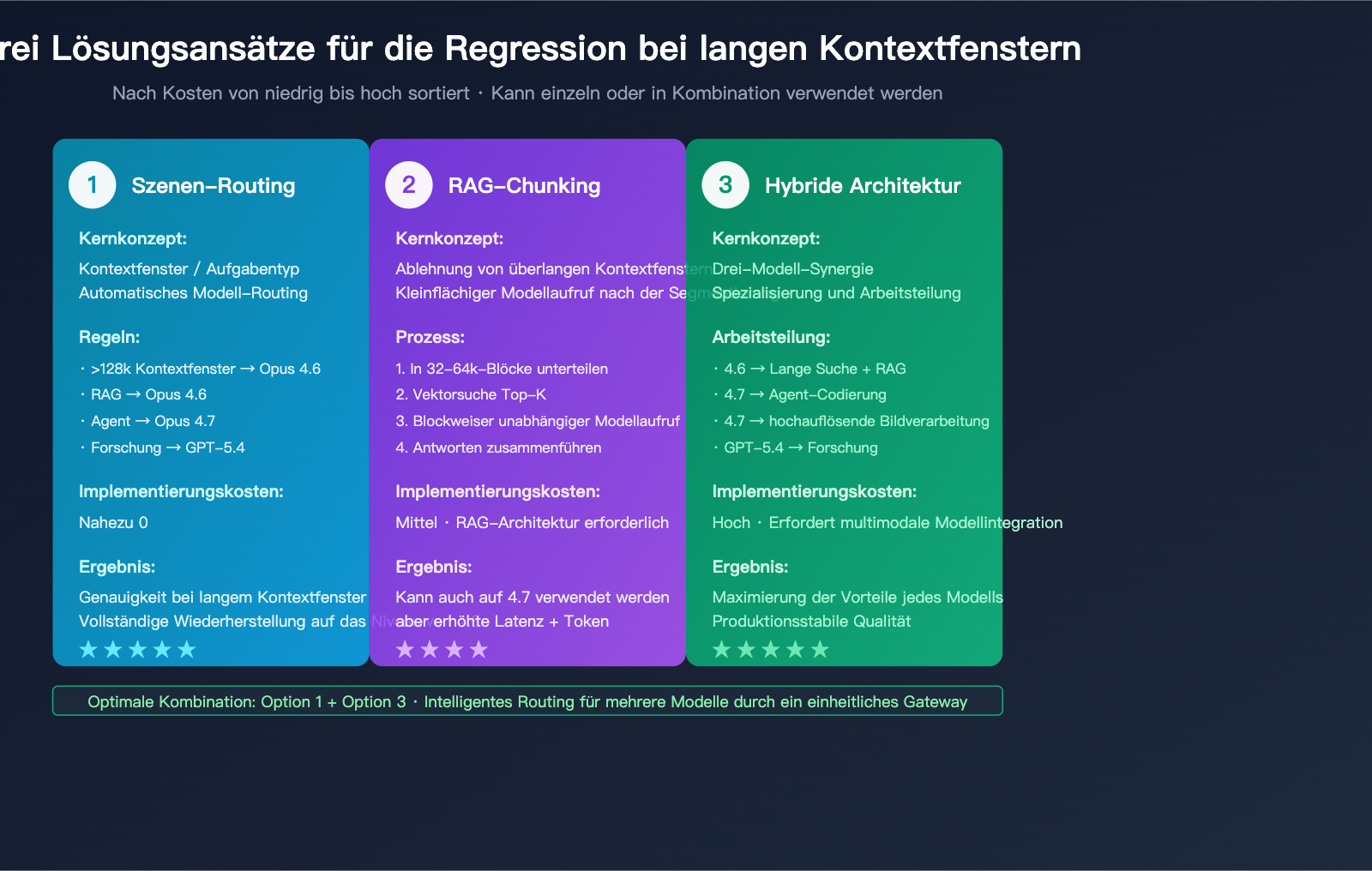
Strategie 1: Routing auf API-Ebene nach Szenario (4.6 vs. 4.7)
Dies ist die kostengünstigste und effektivste Lösung. Das Kernkonzept: Kurze Kontexte / Agent-Coding nutzen 4.7, während lange Kontexte / RAG / Deep Research auf 4.6 zurückgreifen.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Routing des Modells basierend auf Kontextlänge und Aufgabentyp"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
Vollständigen Code für multidimensionale Routing-Strategie anzeigen
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Multidimensionale Routing-Entscheidung"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Agent-Langzyklus-Szenario, 4.7 Horizon ist stärker",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} Token überschreiten den 4.7 MRCR-Sicherheitsbereich",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="BrowseComp 4.6 ist 4.7 überlegen",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="MRCR-Mehrpunkt-Retrieval: 4.6 mit absolutem Vorteil",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Kurze Kontextaufgaben: 4.7 bietet stärkere Gesamtleistung",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Token-Anzahl schätzen"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Routing-Entscheidung: {decision.model} (Grund: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Praxisergebnis: Unter Beibehaltung der Agent-Fähigkeiten von 4.7 kehrt die Genauigkeit bei langen Kontexten vollständig auf das Niveau von 4.6 zurück; die Migrationskosten sind nahezu null.
🚀 Einheitliches Interface-Routing: Wir empfehlen die Implementierung des Routings für die gesamte Claude-Modellreihe über die Plattform APIYI (apiyi.com). Diese bietet ein zu Claude offiziell kompatibles Interface, macht die Verwaltung mehrerer API-Schlüssel überflüssig und reduziert die architektonische Komplexität beim Modell-Routing.
Strategie 2: RAG-Chunking + Gleitendes Fenster
Wenn Ihr Unternehmen stark von 4.7 abhängig ist (z. B. durch bestehende Claude-Code-Workflows), können Sie das Problem der „Blindheit in der Mitte“ bei 4.7 umgehen, indem Sie die Kontextlänge pro Aufruf reduzieren.
Kernstrategie:
- Unterteilen Sie lange Dokumente in Chunks von 32k-64k (in diesem Bereich arbeitet 4.7 einwandfrei).
- Nutzen Sie Vektor-Retrieval, um nur die relevanten Top-K-Chunks abzurufen.
- Führen Sie unabhängige Aufrufe für jeden Chunk durch und führen Sie die Antworten anschließend zusammen.
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""Optimiertes Chunked-RAG für Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Beantworte die Frage basierend auf dem gegebenen Dokumentenabschnitt."},
{"role": "user", "content": f"Dokument: {chunk}\nFrage: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Beantworte die Frage durch Zusammenfassung der folgenden Antworten: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Anwendungsszenario: Teams, die bereits Claude Code / Cursor nutzen, aber extrem lange Dokumente verarbeiten müssen.
Strategie 3: Hybride Modellarchitektur (Opus 4.6 + Sonnet + GPT-5.4)
Für ausgereifte Produkte ist die sicherste Lösung eine Hybride Architektur aus drei Modellen:
- Opus 4.6: Langkontext-Retrieval, RAG, Analyse langer Verträge.
- Opus 4.7: Agent-Coding, Claude-Code-Schleifen, hochauflösende Bildverarbeitung.
- GPT-5.4 Pro: Tiefgreifende Web-Recherche, BrowseComp-Aufgaben.
Diese Architektur erkennt an, dass „kein einzelnes Modell alles perfekt abdecken kann“, und maximiert die Stärken jedes Modells durch Kombination.
💰 Kosten- und Architekturoptimierung: Voraussetzung für eine hybride Modellarchitektur ist eine einheitliche API-Zugriffsschicht. Über die Plattform APIYI (apiyi.com) können Sie die gesamte Palette an Claude-, GPT- und Gemini-Modellen mit einem einzigen API-Schlüssel aufrufen. Die Plattform bietet detaillierte Aufrufstatistiken und Kostenanalysen und ist die ideale Wahl für die Implementierung von Multi-Modell-Architekturen.
Claude Opus 4.7 FAQ zur Langkontext-Fähigkeit
Q1: Anthropic behauptet offiziell, 4.7 sei bei langem Kontext stabiler. Warum zeigen Drittanbieter-Daten das Gegenteil?
Hier liegt eine Verwechslung zwischen „Langzeitbetrieb“ und „Langkontext-Abruf“ vor. Die von Anthropic betonte „Stabilität“ bezieht sich auf die Entscheidungskonsistenz in Agenten-Schleifen – das Modell stürzt bei langen Aufgaben nicht vorzeitig ab. „Langkontext-Abruf“ hingegen beschreibt die Fähigkeit, Informationen an weit entfernten Stellen präzise zu finden. Das sind zwei völlig unterschiedliche Leistungsdimensionen.
Der MRCR v2 8-Needle-Benchmark misst direkt die zweite Fähigkeit, und genau hier räumt das offizielle System-Card von Anthropic ein, dass Opus 4.6 dem 4.7 überlegen ist. Die beiden Aussagen widersprechen sich also nicht, sie messen lediglich unterschiedliche Dinge.
Q2: Sollte meine RAG-Anwendung für lange Dokumente sofort auf 4.6 zurückgestuft werden?
Das kommt auf den Einzelfall an:
- Kernanwendung benötigt > 128k Kontext-Abruf: Sofort zurückstufen. Ein Einbruch der MRCR 1M-Genauigkeit um die Hälfte ist kein kleines Problem und beeinträchtigt die Antwortqualität direkt.
- Kontext zwischen 32k und 128k: Wir empfehlen A/B-Tests. Wenn die Qualität akzeptabel ist, kann 4.7 weiterverwendet werden, andernfalls zurück zu 4.6.
- Kontext unter 32k: Die Unterschiede zwischen den Modellen sind gering; entscheiden Sie nach anderen Kriterien (Kosten, Latenz).
Wir empfehlen, A/B-Tests über die Plattform APIYI (apiyi.com) durchzuführen, da diese den parallelen Modellaufruf von Opus 4.6 und 4.7 unterstützt.
Q3: Warum lässt Anthropic einen solchen Rückschritt zu?
Den Informationen aus dem offiziellen System-Card zufolge hat Anthropic eine bewusste Abwägung getroffen: Das Trainingsbudget wurde auf Agenten-Programmierung und visuelles Verständnis konzentriert, wobei die Genauigkeit beim Langkontext-Abruf teilweise geopfert wurde.
Diese Strategie entspricht dem aktuellen geschäftlichen Fokus von Anthropic – Claude Code und Unternehmens-Agenten-Workflows sind die wichtigsten Einnahmequellen. Für Nutzer von langen Dokumenten, RAG und forschungsorientierten Agenten bedeutet dieser Strategiewechsel jedoch eine Verschlechterung.
Dass Anthropic im System-Card direkt empfiehlt, „4.6 als Fallback beizubehalten“, ist ein Hinweis an die Nutzer: Das ist kein Bug, sondern Strategie – bitte passen Sie sich entsprechend an.
Q4: Wie schwerwiegend ist der Einbruch im MRCR-Benchmark für die Praxis?
Sehr schwerwiegend. Der MRCR 8-Needle-Benchmark simuliert reale Szenarien, in denen „mehrere Schlüsselfakten in einem großen Dokument gefunden werden müssen“, wie zum Beispiel:
- Vertragsprüfung: Auffinden aller Klauselbeschränkungen + Fristen + Kündigungsklauseln.
- Analyse von Finanzberichten: Lokalisierung mehrerer Finanzkennzahlen in 100-seitigen Berichten.
- Code-Basis-Q&A: Verfolgung von Variablendefinitionen + Aufrufketten + Abhängigkeiten über mehrere Dateien hinweg.
Dass MRCR von 78,3 % auf 32,2 % fällt, bedeutet: Bei solchen Aufgaben übersieht 4.7 im Durchschnitt 2/3 der kritischen Informationen. Für geschäftskritische Anwendungen ist das ein katastrophaler Rückschritt.
Q5: Welche praktischen Unterschiede gibt es bei kurzem Kontext (< 32k) zwischen 4.7 und 4.6?
Bei kurzem Kontext unter 32k sind kaum Unterschiede in der Langkontext-Fähigkeit feststellbar. 4.7 ist jedoch in folgenden Bereichen überlegen:
- Stärkere Programmierfähigkeiten: SWE-bench Verified +6,8 pt.
- Stärkeres visuelles Verständnis: 3,75 MP hohe Auflösung.
- Präzisere Werkzeugaufrufe: Führend bei MCP-Atlas.
- Höhere Kosten: Tokenizer-Expansion um 0–35 %.
Bei kurzem Kontext ist die Wahl also primär aufgabenabhängig und nicht mehr von der Langkontext-Fähigkeit bestimmt. Programmierung: 4.7; Schreiben: 4.6 – das ist aktuell die einfachste Entscheidungshilfe.
Q6: Gibt es eine Möglichkeit, 4.7 bei langem Kontext auf das Niveau von 4.6 zu bringen?
Derzeit gibt es keine Lösung auf Konfigurationsebene. Selbst wenn man reasoning-effort auf „max“ stellt, bleibt der MRCR-Wert von 4.7 deutlich unter dem von 4.6.
Zwei indirekte Ansätze sind möglich:
- RAG-Chunking: Den langen Kontext in 32k–64k Blöcke unterteilen, damit 4.7 in der „Sicherheitszone“ arbeitet.
- Multi-Modell-Kaskadierung: 4.6 für den Langkontext-Abruf nutzen und die Ergebnisse zur kombinierten Schlussfolgerung an 4.7 weitergeben.
Die zweite Lösung lässt sich schnell über die Multi-Modell-Schnittstelle der Plattform APIYI (apiyi.com) umsetzen, die eine einheitliche Schnittstelle für verschiedene gängige Modelle bietet.
Zusammenfassung des Rückschritts bei Claude Opus 4.7
Der Rückschritt bei der Langkontext-Fähigkeit von Claude Opus 4.7 ist ein reales Problem, das durch offizielle Daten belegt, aus der Community bestätigt und in seinem Einflussbereich klar definiert ist. Die Kernpunkte:
- Offiziell bestätigt: MRCR v2 8-Needle-Werte bei 256k und 1M haben sich halbiert; Anthropic empfiehlt explizit, 4.6 als Fallback zu behalten.
- Strategische Abwägung als Ursache: Anthropic opferte die Präzision der Langstrecken-Aufmerksamkeit zugunsten von Agenten-Programmierung und visuellem Verständnis.
- Fokus auf 128k+ Szenarien: Bei kurzem Kontext bleibt 4.7 nutzbar, aber ab 128k verstärkt sich der Rückschritt nicht-linear.
- Opus 4.6 ist das derzeit stärkste Langkontext-Modell: Ein von Experten wie Rohan Paul bestätigtes Fazit, das sogar GPT-5.2 übertrifft.
- Beste Strategie ist szenariobasiertes Routing: Lange Dokumente über 4.6, Programmierung über 4.7, für tiefgehende Forschung ggf. GPT-5.4 Pro.
Für Nutzer ist die richtige Haltung nicht das „Warten auf einen Fix“ – die Anpassung ist strategisch und wird kurzfristig nicht zurückgenommen –, sondern die sofortige Vorbereitung auf Multi-Modell-Routing auf Anwendungsebene. Nutzen Sie 4.6 als Standard für Langkontext-Szenarien und 4.7 für die Aufgaben, in denen es wirklich glänzt: Agenten-Programmierung.
Dies entspricht auch dem neuen Trend der KI-Industrie 2026: Die Ära, in der ein einziges Modell alle Szenarien abdeckt, ist vorbei. Jedes Modell entwickelt sich in Richtung einer „Spezialisierung“. Die Anforderung an Nutzer verschiebt sich von der „Wahl des stärksten Modells“ hin zum „Entwurf eines intelligenten Multi-Modell-Routings“.
Wir empfehlen die Plattform APIYI (apiyi.com) zur zentralen Verwaltung Ihrer Claude-Modellaufrufe. Sie bietet Echtzeit-Benchmark-Vergleiche, intelligentes Multi-Modell-Routing und eine vollständig kompatible API – ein pragmatisches Werkzeug, um dem Rückschritt bei Opus 4.7 zu begegnen.
Referenzmaterialien
-
Anthropic Opus 4.7 System Card: Offizielle 232-seitige Systemkarte
- Link:
anthropic.com/news/claude-opus-4-7 - Beschreibung: Enthält vollständige MRCR v2-Benchmark-Daten und Migrationsvorschläge.
- Link:
-
Detaillierte Analyse der Opus 4.7 System Card: Analyse der DEV Community
- Link:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Beschreibung: Zusammenfassung der 232-seitigen Systemkarte aus der Perspektive eines Programmierers.
- Link:
-
Anthropic Migrationsleitfaden: Opus 4.7 Migrationsanleitung
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Beschreibung: Offizielle Migrationshinweise und wichtige Informationen zum Kontextfenster.
- Link:
-
Long-Context Benchmarks Leaderboard: Bestenliste für Benchmarks mit langem Kontext
- Link:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Beschreibung: Horizontaler Vergleich von MRCR, RULER und LongBench v2.
- Link:
-
Rohan Paul X Kommentar: Analyse des Long-Context-Champions Opus 4.6
- Link:
x.com/rohanpaul_ai/status/2019545018051240059 - Beschreibung: Bewertung der Vorteile des langen Kontexts von Opus 4.6 durch einen unabhängigen Beobachter.
- Link:
Autor: APIYI Technik-Team
Veröffentlichungsdatum: 18.04.2026
Geeignete Modelle: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Technischer Austausch: Besuchen Sie APIYI unter apiyi.com, um Testguthaben für verschiedene Modelle zu erhalten und die Unterschiede in der Abrufgenauigkeit bei verschiedenen Kontextfenstern selbst zu testen.