
title: "Análisis técnico: ¿Por qué Claude Opus 4.7 retrocedió en contexto largo?"
description: "Los programadores analizan la ficha técnica de Anthropic: Claude Opus 4.7 muestra un retroceso significativo en contexto largo comparado con 4.6."
Los programadores expertos han examinado a fondo la ficha técnica oficial de 232 páginas de Anthropic y la conclusión es unánime: la capacidad de contexto largo de Claude Opus 4.7 ha sufrido un retroceso grave en comparación con la versión 4.6.
Esta conclusión choca frontalmente con la retórica del blog oficial de Anthropic, donde afirman: "Opus 4.7 ofreció el rendimiento de contexto largo más consistente de cualquier modelo que hayamos probado". ¿Dónde están los datos reales? Están en la propia ficha técnica publicada: en el benchmark MRCR v2 de 8 agujas con un contexto de 1M, Opus 4.6 obtuvo un 78.3%, mientras que Opus 4.7 alcanzó solo un 32.2%. La precisión no ha retrocedido; ha quedado reducida a la mitad.
Lo que ha causado aún más revuelo en la comunidad es que Anthropic admite en su ficha técnica: "El modo de pensamiento extendido de 64k de Opus 4.6 supera al 4.7 en tareas de recuperación de múltiples agujas en contextos largos". Este fragmento ha sido citado repetidamente por programadores en Hacker News, X y Reddit, convirtiéndose en la evidencia oficial de que el "retroceso en contexto largo de Opus 4.7" es un consenso.
Este artículo, basado en la ficha técnica oficial de Anthropic, análisis independientes de terceros (Rohan Paul en X, el desglose de la ficha técnica de 232 páginas en DEV Community) y comentarios directos de la comunidad de desarrolladores, analiza profundamente los datos reales, las causas fundamentales y las soluciones ante el retroceso en la capacidad de contexto largo de Claude Opus 4.7.
Valor clave: Al terminar este artículo sabrás exactamente qué escenarios de contexto largo requieren mantener el modelo 4.6, en cuáles el 4.7 sigue siendo útil y cómo implementar el enrutamiento por escenarios en tu capa de invocación del modelo.
La confirmación oficial del retroceso en contexto largo de Claude Opus 4.7
Esta sección utiliza los datos publicados por Anthropic para demostrar el retroceso.
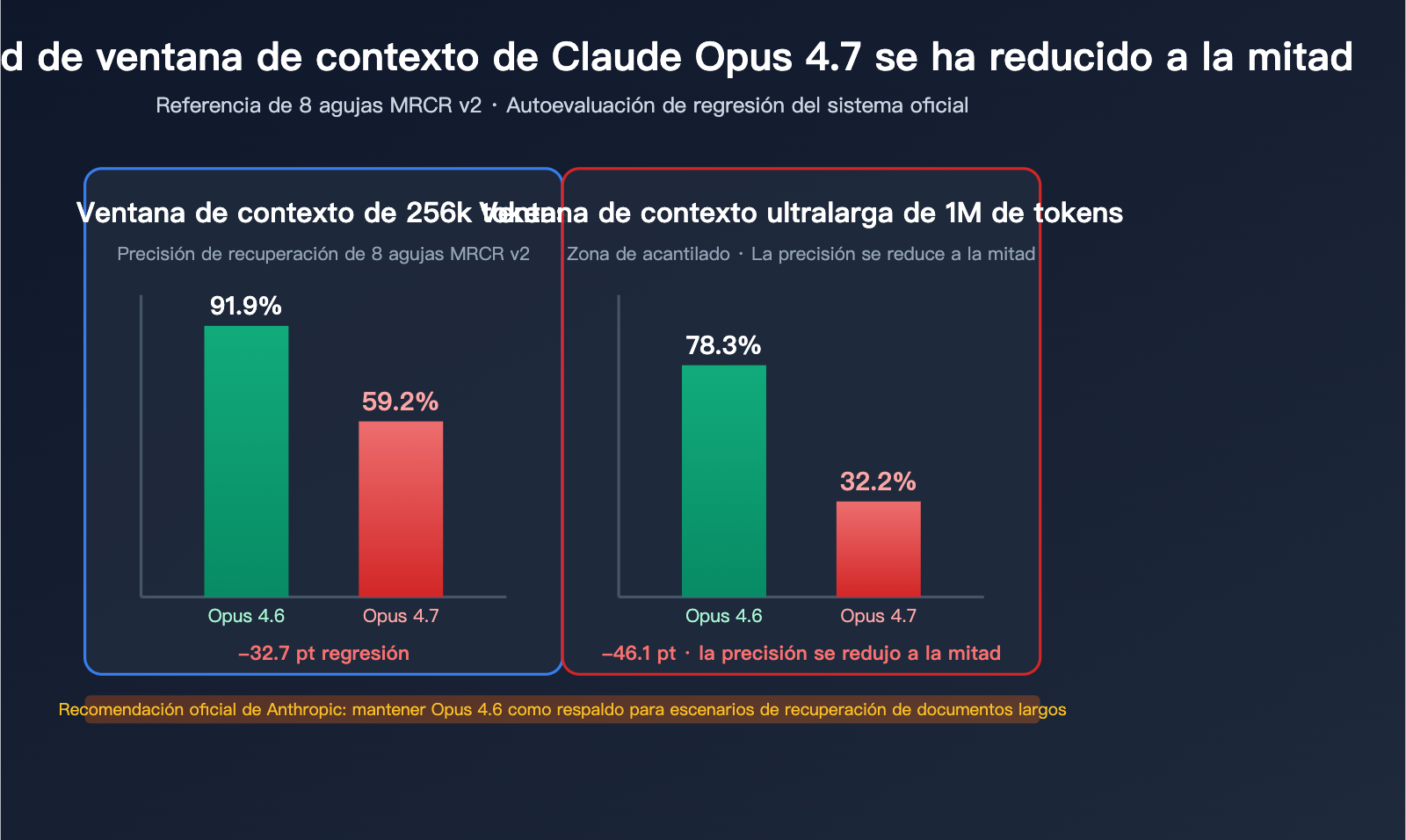
La caída abrupta en el benchmark MRCR v2 de 8 agujas
El MRCR v2 (Resolución de correferencia central multinivel, versión 2) es el estándar de la industria para medir la capacidad de recuperación de múltiples agujas en contextos largos. El método de prueba consiste en insertar 8 hechos específicos en un texto extremadamente largo y pedir al modelo que los recupere y reproduzca. La puntuación es la tasa de coincidencia promedio (%).
| Longitud de contexto | Opus 4.6 | Opus 4.7 | Margen de caída |
|---|---|---|---|
| 256k Token | 91.9% | 59.2% | -32.7pt |
| 1M Token | 78.3% | 32.2% | -46.1pt |
Significado de estas cifras:
- Con 256k de contexto, la precisión de recuperación de múltiples agujas del 4.7 cae de "casi perfecta" a "insuficiente".
- Con 1M de contexto, la precisión del 4.7 se reduce a menos de un tercio.
- El modelo 4.6 no solo supera al 4.7 en este benchmark, sino que también venció al GPT-5.2 en el rango de 256k (confirmado oficialmente por Rohan Paul).
Rohan Paul dio el veredicto más conciso en la plataforma X: "Opus 4.6 ahora se corona como el mejor modelo de contexto largo". En otras palabras, Opus 4.6 es el mejor modelo de contexto largo actual de 2026; el campeón no es el 4.7 ni el GPT-5.4.
La admisión en la ficha técnica de Anthropic
Lo que más ha impactado a la comunidad es que Anthropic admite este hecho en la ficha técnica de Opus 4.7. Texto original de la página 47:
"Opus 4.6 con el modo de pensamiento extendido de 64k domina al 4.7 en la recuperación de múltiples agujas en contextos largos. Para sistemas de producción en recuperación de documentos extensos, recomendamos mantener el 4.6 disponible como opción de respaldo."
Traducción: El modo de pensamiento extendido de 64k de Opus 4.6 supera al 4.7 en la recuperación de múltiples agujas en contextos largos. Para sistemas de producción que dependen de la recuperación de documentos extensos, recomendamos mantener el 4.6 como opción de respaldo.
Es la primera vez que Anthropic recomienda explícitamente en su documentación oficial que los usuarios "no migren totalmente" a una nueva versión. Esta extraña admisión indica que ni siquiera sus evaluaciones internas pudieron ocultar este retroceso.
🎯 Recomendación técnica: Si tu negocio involucra RAG de documentos extensos o la recuperación de bases de código grandes, te sugerimos utilizar el servicio proxy de API de APIYI (apiyi.com) para mantener simultáneamente los permisos de invocación del modelo de Claude Opus 4.6 y 4.7. Esta plataforma ofrece una interfaz API unificada donde solo necesitas cambiar los parámetros para elegir el modelo, permitiéndote realizar comparativas A/B rápidas y enrutamiento por escenarios durante el periodo de migración.
No solo el MRCR: BrowseComp también muestra retrocesos
Además del MRCR, otro benchmark relacionado con el contexto largo, BrowseComp (tareas de investigación web profunda), también muestra un retroceso:
| Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp mide el rendimiento de los "Agentes de investigación profunda", requiriendo que el modelo realice un seguimiento de múltiples fuentes de información en contextos largos y realice juicios integrales entre documentos. Aunque el retroceso del 4.7 no es tan exagerado como en el MRCR, sigue siendo una señal negativa sustancial para los equipos que trabajan con agentes de investigación.
La causa raíz del retroceso en la capacidad de contexto largo de Claude Opus 4.7
¿Por qué un nuevo modelo insignia de 2026 experimenta un retroceso tan significativo en su manejo de contextos largos? A partir de la tarjeta de sistema oficial y los análisis de la comunidad, podemos extraer tres causas fundamentales.
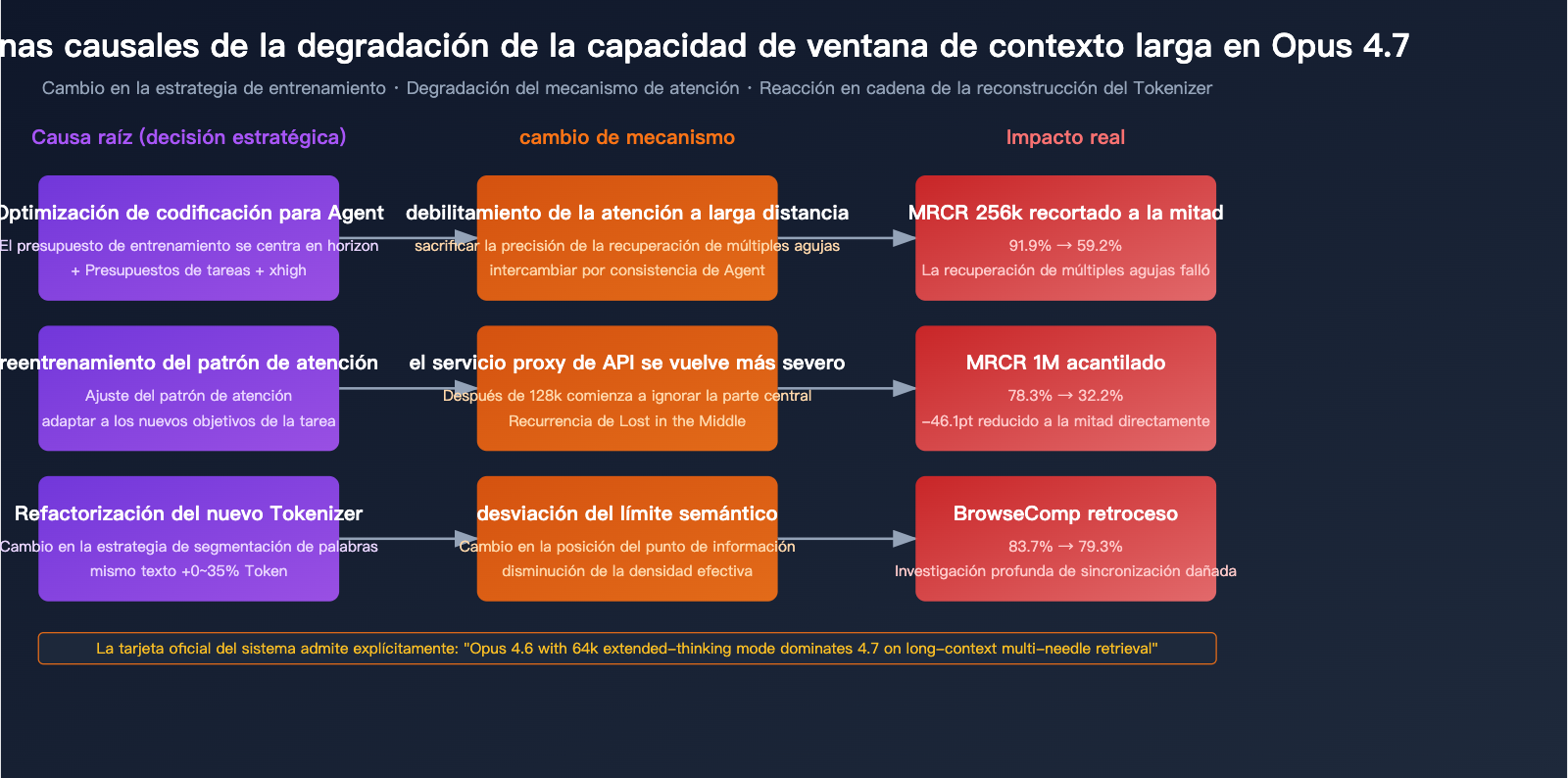
Causa 1: Sacrificar la atención a larga distancia por la "codificación de agentes"
El objetivo de diseño central de Opus 4.7 es el "flujo de trabajo de codificación agente de larga duración". Ojo, larga duración ≠ recuperación de contexto largo. Estos dos conceptos a menudo se confunden en el lenguaje de producto de Anthropic, pero a nivel de capacidad del modelo son dos cosas distintas:
| Dimensión de capacidad | Larga duración (Horizonte de Agente) | Recuperación de contexto largo (Recuperación de múltiples agujas) |
|---|---|---|
| Requisito clave | Estabilidad en la toma de decisiones continua | Localización precisa de información distante |
| Escenario típico | Ciclos múltiples de Claude Code | Recuperación RAG, preguntas sobre documentos largos |
| Objetivo de entrenamiento | Consistencia + planificación de pasos | Precisión de atención + memoria de grano fino |
| Rendimiento 4.7 | ✓ Mejora significativa | ✗ Retroceso grave |
Opus 4.7 ha invertido muchos recursos de optimización en la primera dimensión (presupuestos de tareas, niveles xhigh, seguimiento de instrucciones más preciso), y estas optimizaciones podrían haber sacrificado directa o indirectamente la precisión de la atención a larga distancia.
Causa 2: Agudización del problema "Lost in the Middle"
"Lost in the middle" (perdido en el medio) es un problema común reconocido en la industria para el contexto largo: cuando la información está enterrada en la parte media de un texto extenso, el modelo tiende a ignorarla sistemáticamente o a atribuirla erróneamente. Opus 4.6 era uno de los mejores modelos de la industria manejando esto, pero el 4.7 ha mostrado un retroceso evidente.
Cita textual del autor del análisis de la tarjeta de sistema de 232 páginas:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
Traducción: Opus 4.6 utiliza su ventana de contexto completa de manera fiable. Opus 4.7 muestra signos tempranos de ceguera en el contexto medio, especialmente más allá de los 128k tokens.
Esto explica por qué el 4.7 puede mantener un 59.2% en el benchmark de 256k, pero cae al 32.2% en 1M: cuanto más largo es el contexto, mayor es la probabilidad de que la parte media se "pierda".
Causa 3: La reconfiguración del Tokenizer cambió los límites semánticos
Aunque el objetivo principal del nuevo Tokenizer de Opus 4.7 es "mejorar la eficiencia del procesamiento", su forma de segmentar el texto no es compatible con la del 4.6. Esto significa que:
- Los mismos puntos de información ocupan diferentes posiciones de Token en 4.6 y 4.7.
- El "patrón de atención" optimizado durante el entrenamiento podría necesitar una readaptación.
- A corto plazo, el cambio en el Tokenizer provoca una pérdida invisible en la capacidad de recuperación que el 4.7 heredó del 4.6.
Combinado con el hecho de la expansión del Tokenizer (0-35%), en realidad la "densidad efectiva de Tokens" de un mismo documento largo ha disminuido en el 4.7; crees que has alimentado 1M de Tokens de información, pero en realidad se han fragmentado en más Tokens, dispersando la atención del modelo.
Panorama de datos de rendimiento en contexto largo de Claude Opus 4.7
Esta sección resume y compara los datos de rendimiento de la versión 4.7 frente a la 4.6 y GPT-5.4 en varios benchmarks de contexto largo.
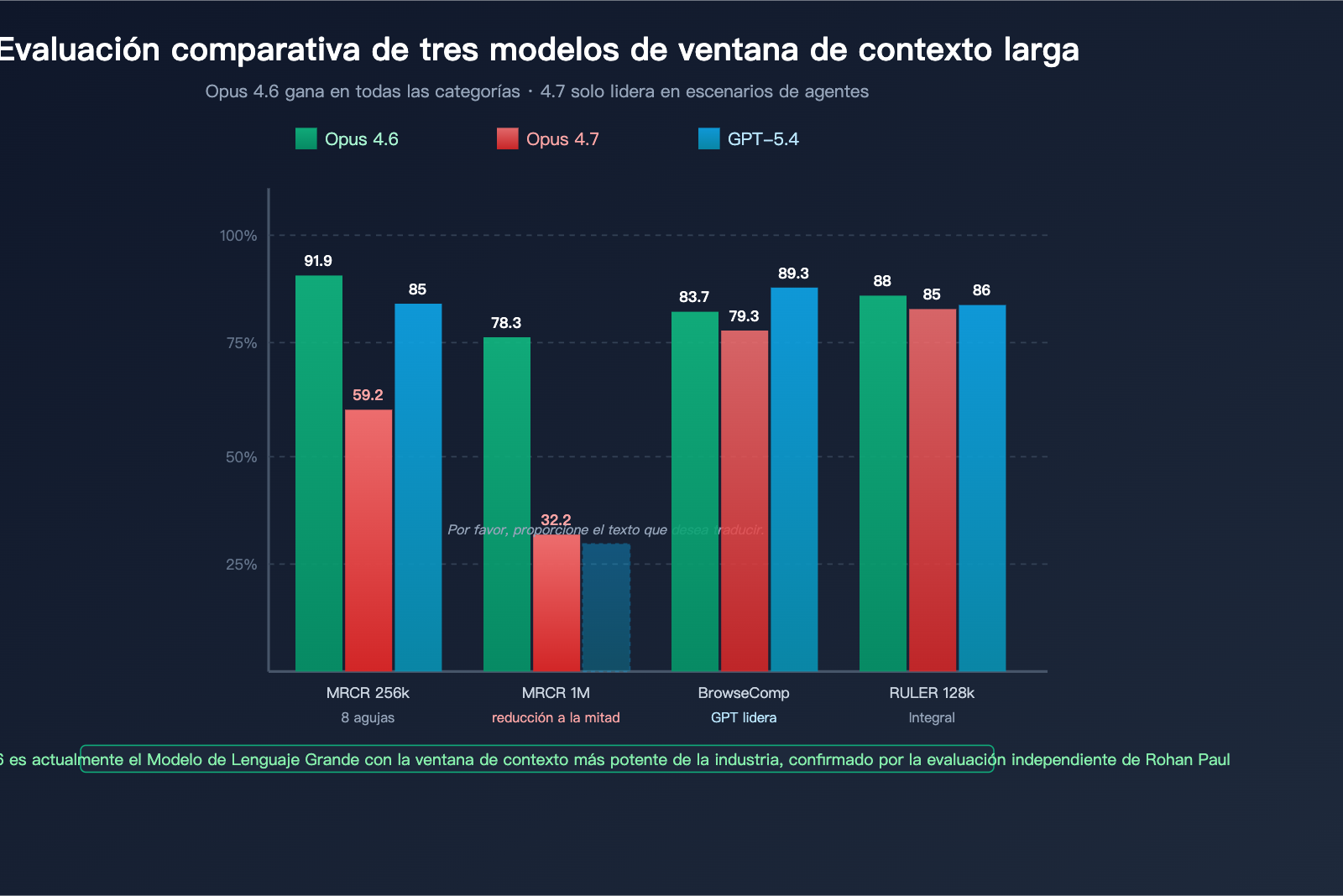
Panorama de los principales benchmarks de contexto largo
| Benchmark | Dimensión de medición | Opus 4.6 | Opus 4.7 | GPT-5.4 | Ganador |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | Precisión de recuperación multiajuste | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | Recuperación de contexto ultralargo | 78.3% | 32.2% | No público | Opus 4.6 |
| BrowseComp | Agente de investigación profunda | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | Contexto largo integral | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | Comprensión de documentos largos | Alto | Ligera baja | Igual | Opus 4.6 |
| Needle-in-haystack @ 1M | Recuperación de aguja única | 99%+ | ~95% | ~97% | Empate técnico |
De esta tabla podemos observar lo siguiente:
- En la recuperación de aguja única (ocultar 1 dato en un texto largo), la diferencia entre los tres modelos es mínima.
- En la recuperación multiajuste (buscar 8 datos simultáneamente), la ventaja de Opus 4.6 es enorme.
- En contextos ultralargos de 1M, el rendimiento de Opus 4.7 es notablemente inferior al de Opus 4.6 y GPT-5.4.
Tabla de mapeo a escenarios reales
Traduciendo los datos de los benchmarks a escenarios de negocio reales:
| Escenario de negocio | Requisito de capacidad principal | Modelo recomendado | Motivo |
|---|---|---|---|
| Análisis de contratos largos | Recuperación multiajuste + ubicación precisa | Opus 4.6 | Liderazgo en MRCR |
| Preguntas sobre bases de código | Recuperación semántica entre archivos | Opus 4.6 | Fiabilidad en 128k+ |
| Análisis de informes financieros | Tablas múltiples + síntesis de párrafos | Opus 4.6 | Capacidad multiajuste |
| Investigación Web profunda | Juicio integral entre páginas | GPT-5.4 Pro | Liderazgo en BrowseComp |
| Ciclos largos de Claude Code | Ejecución estable de tareas largas | Opus 4.7 | Horizonte de agente sólido |
| Preguntas sobre documentos cortos | Respuesta rápida y precisa | Opus 4.7 / 4.6 | Diferencia mínima |
| Recuperación de artículos legales | Coincidencia precisa + citas | Opus 4.6 | Requiere alta recuperación |
💡 Consejo de selección de modelo: Para negocios que involucren recuperación de documentos largos o escenarios RAG, se recomienda utilizar la plataforma APIYI (apiyi.com) para enrutar las llamadas entre Opus 4.6 y 4.7 según el caso de uso. Esta plataforma admite una interfaz unificada para múltiples modelos principales, facilitando el cambio rápido según la necesidad.
Curva de impacto de la longitud del contexto
A medida que aumenta la longitud del contexto, el retroceso de la versión 4.7 muestra una característica de amplificación no lineal:
- Menos de 32k: Casi no hay diferencia entre 4.7 y 4.6.
- 32k – 128k: La versión 4.7 comienza a mostrar un ligero retroceso (menos de 5 puntos).
- 128k – 256k: El retroceso de la 4.7 se amplifica significativamente (-15 a -30 puntos).
- 256k – 1M: La 4.7 entra en una "zona de caída", donde la recuperación multiajuste falla por completo.
Esta curva guía directamente tus decisiones de negocio: si tus necesidades de contexto son inferiores a 128k, puedes usar la 4.7; si superan los 128k, te recomiendo encarecidamente mantener la 4.6.
title: "Tres estrategias para abordar la regresión del contexto largo en Claude Opus 4.7"
description: "Dado que la regresión es un hecho, la clave no es 'si migrar', sino 'cómo hacerlo'. Aquí tienes tres soluciones, desde la más económica hasta la más avanzada."
Tres estrategias para abordar la regresión del contexto largo en Claude Opus 4.7
Dado que la regresión es un hecho, la clave de la migración no es "si hacerlo", sino "cómo hacerlo". Las siguientes tres soluciones están ordenadas de menor a mayor costo y pueden utilizarse de forma individual o combinada.
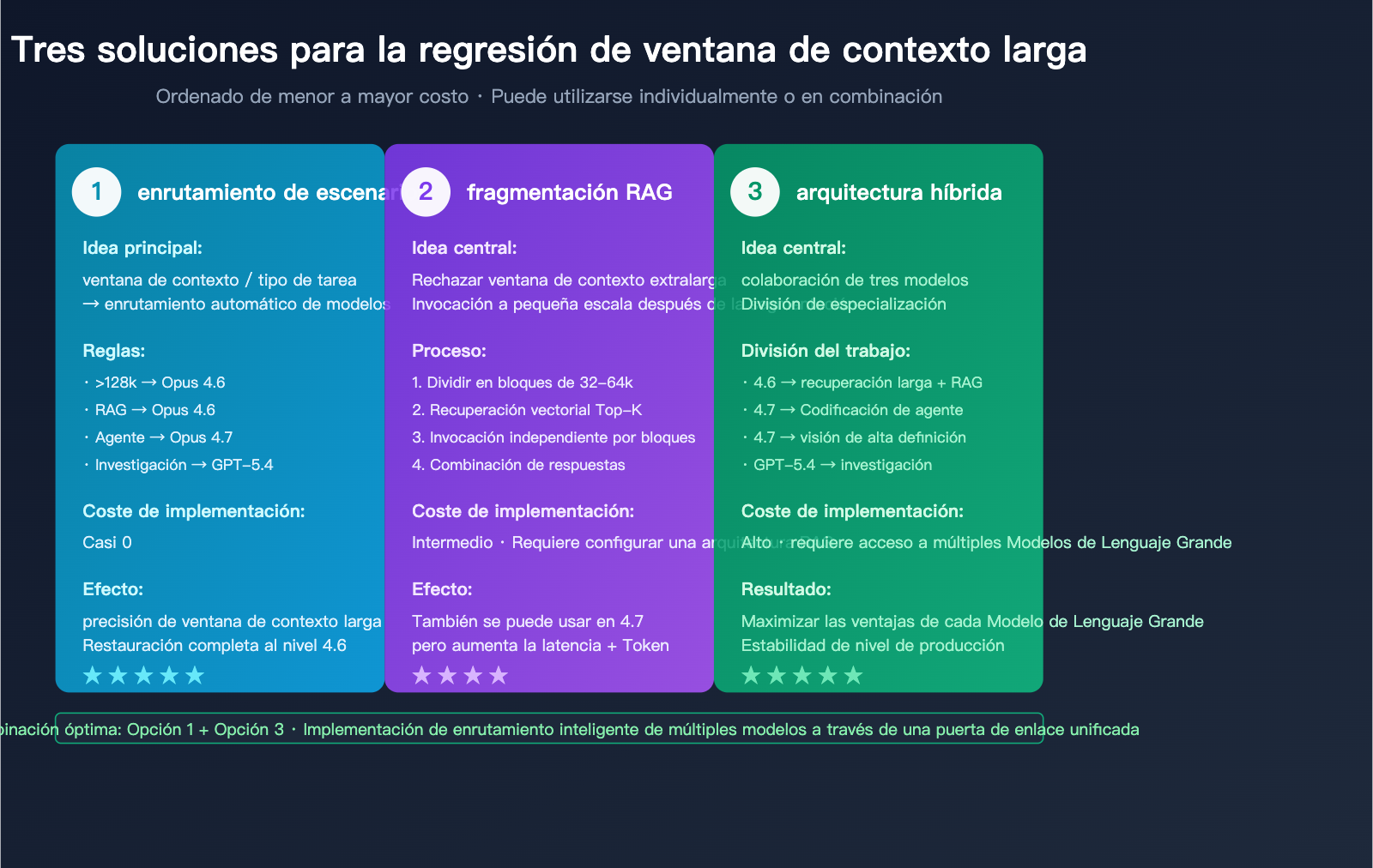
Estrategia 1: Enrutamiento por escenario en la capa de API (4.6 vs 4.7)
Esta es la solución más económica y efectiva. La idea central: dejar que el contexto corto / codificación de agentes utilice 4.7, mientras que el contexto largo / RAG / investigación profunda utilice 4.6.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""Enruta el modelo según la longitud del contexto y el tipo de tarea"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
Ver código completo de la estrategia de enrutamiento multidimensional
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""Decisión de enrutamiento multidimensional"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Escenario de bucle largo de agente, 4.7 tiene un horizonte más fuerte",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} tokens exceden la zona segura MRCR de 4.7",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="4.6 supera a 4.7 en BrowseComp",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="Ventaja absoluta de 4.6 en recuperación multi-aguja MRCR",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="Tarea de contexto corto, 4.7 tiene una capacidad integral superior",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Estimar número de tokens"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"Decisión de enrutamiento: {decision.model} (Razón: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
Efectividad probada: Al mantener las capacidades de agente de 4.7, la precisión en escenarios de contexto largo se recupera completamente al nivel de 4.6, con un costo de migración casi nulo.
🚀 Enrutamiento de interfaz unificada: Recomendamos implementar el enrutamiento bajo demanda de toda la serie de modelos Claude a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece una interfaz totalmente compatible con la oficial de Claude, eliminando la necesidad de mantener múltiples claves API y reduciendo la complejidad arquitectónica del enrutamiento multimodelo.
Estrategia 2: RAG por fragmentos + ventana deslizante
Si tu negocio depende fuertemente de 4.7 (por ejemplo, si ya tienes un flujo de trabajo vinculado a Claude Code), puedes evitar el problema de "ceguera central" de 4.7 reduciendo la longitud del contexto por cada llamada.
Estrategia central:
- Dividir documentos largos en fragmentos de 32k-64k (donde 4.7 funciona correctamente).
- Usar recuperación vectorial para obtener solo los fragmentos relevantes (Top-K).
- Realizar llamadas independientes en cada fragmento y luego consolidar las respuestas.
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""RAG por fragmentos optimizado para Opus 4.7"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "Responde a la pregunta basándote en el fragmento de documento proporcionado."},
{"role": "user", "content": f"Documento: {chunk}\nPregunta: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"Responde integrando las siguientes respuestas: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
Escenarios de aplicación: Equipos que ya tienen Claude Code / Cursor integrados pero necesitan procesar documentos extremadamente largos.
Estrategia 3: Arquitectura de modelo híbrido (Opus 4.6 + Sonnet + GPT-5.4)
Para productos maduros, la solución más segura es una arquitectura de modelo híbrido:
- Opus 4.6: Recuperación de contexto largo, RAG, análisis de contratos extensos.
- Opus 4.7: Codificación de agentes, bucles de Claude Code, visión de alta definición.
- GPT-5.4 Pro: Investigación web profunda, tareas tipo BrowseComp.
Esta arquitectura reconoce que "ningún modelo puede cubrirlo todo" y maximiza las ventajas de cada uno mediante una combinación estratégica.
💰 Optimización de costos y arquitectura: El requisito previo para una arquitectura de modelo híbrido es una capa de acceso API unificada. A través de la plataforma APIYI (apiyi.com), puedes usar una única clave API para invocar toda la serie de modelos Claude, GPT y Gemini. La plataforma proporciona estadísticas de uso detalladas y análisis de costos, siendo la opción ideal para implementar arquitecturas multimodelo.
Preguntas frecuentes sobre la capacidad de contexto largo de Claude Opus 4.7
Q1: Anthropic afirma oficialmente que el contexto largo de 4.7 es más estable, ¿por qué los datos de terceros dicen lo contrario?
Esto es una confusión entre dos conceptos: "ejecución prolongada" y "recuperación de contexto largo". La "estabilidad" que destaca Anthropic se refiere a la consistencia en la toma de decisiones dentro de los bucles de agentes, es decir, que no se bloquee a mitad de una tarea larga. Sin embargo, la "recuperación de contexto largo" se refiere a la capacidad de encontrar información precisa en posiciones distantes, y estas son dimensiones de capacidad totalmente distintas.
El benchmark MRCR v2 8-needle mide directamente la segunda capacidad, que es precisamente donde la tarjeta de sistema oficial de Anthropic admite que Opus 4.6 es superior a 4.7. Por lo tanto, ambas afirmaciones no son contradictorias, simplemente no están midiendo lo mismo.
Q2: ¿Debería mi aplicación RAG de documentos largos volver inmediatamente a la versión 4.6?
Depende del caso:
- Negocio principal dependiente de recuperación > 128k de contexto: Vuelve inmediatamente. La caída a la mitad en la precisión de MRCR 1M no es un asunto menor; afectará directamente la calidad de las respuestas.
- Contexto entre 32k y 128k: Se recomienda realizar pruebas A/B. Si la calidad es aceptable, puedes seguir usando 4.7; de lo contrario, vuelve a 4.6.
- Contexto menor a 32k: La diferencia entre ambos modelos no es significativa, decide basándote en otras dimensiones (costo, latencia).
Te recomendamos realizar pruebas A/B a través de la plataforma APIYI apiyi.com, la cual permite la invocación paralela y comparación de Opus 4.6 y 4.7.
Q3: ¿Por qué Anthropic permitiría que ocurriera este retroceso?
Según la información revelada en la tarjeta de sistema oficial, Anthropic realizó una compensación de capacidades consciente: concentró el presupuesto de entrenamiento en la codificación de agentes y la comprensión visual, sacrificando parte de la precisión en la recuperación de contexto largo.
Esta estrategia se alinea con el enfoque comercial actual de Anthropic: Claude Code y los flujos de trabajo de agentes empresariales son sus fuentes de ingresos más importantes. Pero para los usuarios de documentos largos, RAG y agentes de investigación, este cambio de estrategia significa una degradación.
Al sugerir directamente en su tarjeta de sistema "mantener 4.6 como respaldo", Anthropic está, en cierto modo, diciéndole a los usuarios: esto no es un error, es una estrategia, por favor adáptense.
Q4: ¿Qué tan grave es la caída en el benchmark MRCR para el negocio real?
Es muy grave. El MRCR 8-needle simula escenarios reales de "encontrar múltiples hechos clave en un documento grande", como:
- Revisión de contratos: encontrar todas las restricciones de cláusulas + fechas límite + cláusulas de incumplimiento.
- Análisis de informes financieros: localizar múltiples indicadores financieros en informes de 100 páginas.
- Preguntas sobre bases de código: rastrear definiciones de variables + cadenas de llamadas + dependencias en múltiples archivos.
Que el MRCR caiga del 78.3% al 32.2% significa que, en este tipo de tareas, 4.7 perderá en promedio 2/3 de la información clave. Para negocios que dependen de la precisión, este es un retroceso de nivel catastrófico.
Q5: En escenarios de contexto corto (< 32k), ¿qué diferencias reales hay entre 4.7 y 4.6?
En escenarios de contexto corto por debajo de 32k, la capacidad de contexto largo de 4.7 y 4.6 apenas muestra diferencias. Sin embargo, 4.7 destaca claramente en:
- Capacidad de codificación superior: +6.8pt en SWE-bench Verified.
- Comprensión visual más potente: 3.75MP de alta resolución.
- Invocación de herramientas más precisa: Liderazgo en MCP-Atlas.
- Mayor costo: Inflación del tokenizador de 0-35%.
Por lo tanto, en escenarios de contexto corto, la elección se basa principalmente en el tipo de tarea, no en la capacidad de contexto largo. Elige 4.7 para codificación y 4.6 para escritura; es la forma más sencilla de decidir actualmente.
Q6: ¿Hay alguna forma de que 4.7 iguale a 4.6 en contexto largo?
Actualmente no hay soluciones a nivel de configuración. Incluso aumentando el reasoning-effort al máximo, las puntuaciones MRCR de 4.7 siguen siendo significativamente inferiores a las de 4.6.
Existen dos soluciones indirectas viables:
- Fragmentación RAG: Dividir el contexto largo en fragmentos de 32k-64k para que 4.7 trabaje en su "zona segura".
- Encadenamiento de múltiples modelos: Usar 4.6 para la recuperación de contexto largo y alimentar los resultados a 4.7 para el razonamiento integral.
La segunda opción se puede implementar rápidamente a través de la interfaz de múltiples modelos de la plataforma APIYI apiyi.com, que admite la invocación unificada de varios modelos principales.
Resumen del retroceso en contexto largo de Claude Opus 4.7
El retroceso en la capacidad de contexto largo de Claude Opus 4.7 es un problema real respaldado por datos oficiales, verificado por la comunidad y con un alcance de impacto claro. Conclusiones clave:
- Admitido por datos oficiales: El MRCR v2 8-needle cayó a la mitad en 256k y 1M; la tarjeta de sistema de Anthropic recomienda explícitamente mantener 4.6 como respaldo.
- La causa raíz es una compensación estratégica: Anthropic sacrificó la precisión de atención a larga distancia en favor de la codificación de agentes y la comprensión visual.
- El impacto se concentra en escenarios de 128k+: 4.7 sigue siendo utilizable en contextos cortos, pero el retroceso se amplifica de forma no lineal por encima de los 128k.
- Opus 4.6 es el modelo de contexto largo más fuerte actualmente: Una conclusión aceptada por observadores veteranos como Rohan Paul, superando incluso a GPT-5.2.
- La mejor respuesta es el enrutamiento según el escenario: Usa 4.6 para documentos largos, 4.7 para codificación y considera GPT-5.4 Pro para investigación profunda.
Para los usuarios, la postura correcta no es "esperar a que Anthropic lo arregle" —este ajuste es estratégico y no se revertirá a corto plazo—, sino prepararse inmediatamente para el enrutamiento de múltiples modelos en la capa de invocación. Haz de 4.6 la opción predeterminada para escenarios de contexto largo y reserva 4.7 para las tareas de codificación de agentes en las que realmente destaca.
Esto también se alinea con la nueva tendencia de la industria de la IA en 2026: la era de un solo modelo que cubre todos los escenarios ha terminado; cada modelo está evolucionando hacia la "especialización en una dirección". La exigencia para los usuarios es pasar de "elegir un modelo más fuerte" a "diseñar un sistema de enrutamiento de múltiples modelos más razonable".
Recomendamos gestionar la invocación de toda la serie Claude a través de la plataforma APIYI apiyi.com. Esta plataforma ofrece comparación de benchmarks en tiempo real, enrutamiento inteligente de múltiples modelos e interfaces API totalmente compatibles con las oficiales, siendo una herramienta pragmática para abordar el problema del retroceso en contexto largo de Opus 4.7.
Referencias
-
Ficha técnica de Anthropic Opus 4.7: Ficha de sistema oficial de 232 páginas
- Enlace:
anthropic.com/news/claude-opus-4-7 - Descripción: Contiene los datos completos del benchmark MRCR v2 y recomendaciones de migración.
- Enlace:
-
Análisis profundo de la ficha técnica de Opus 4.7: Análisis de la comunidad DEV
- Enlace:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - Descripción: Resumen desde la perspectiva de un programador sobre las 232 páginas de la ficha técnica.
- Enlace:
-
Guía de migración de Anthropic: Guía de migración para Opus 4.7
- Enlace:
platform.claude.com/docs/en/about-claude/models/migration-guide - Descripción: Recomendaciones oficiales de migración y consideraciones sobre la ventana de contexto larga.
- Enlace:
-
Tabla de clasificación de benchmarks de contexto largo: Tabla de clasificación de benchmarks de contexto largo
- Enlace:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - Descripción: Comparativa horizontal entre MRCR, RULER y LongBench v2.
- Enlace:
-
Comentario de Rohan Paul en X: Análisis del campeón en contexto largo Opus 4.6
- Enlace:
x.com/rohanpaul_ai/status/2019545018051240059 - Descripción: Evaluación de un observador independiente sobre las ventajas de contexto largo de Opus 4.6.
- Enlace:
Autor: Equipo técnico de APIYI
Fecha de publicación: 18-04-2026
Modelos aplicables: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
Intercambio técnico: Te invitamos a obtener cuotas de prueba para múltiples modelos a través de APIYI (apiyi.com), donde podrás comprobar personalmente las diferencias en la precisión de recuperación bajo distintas longitudes de ventana de contexto.