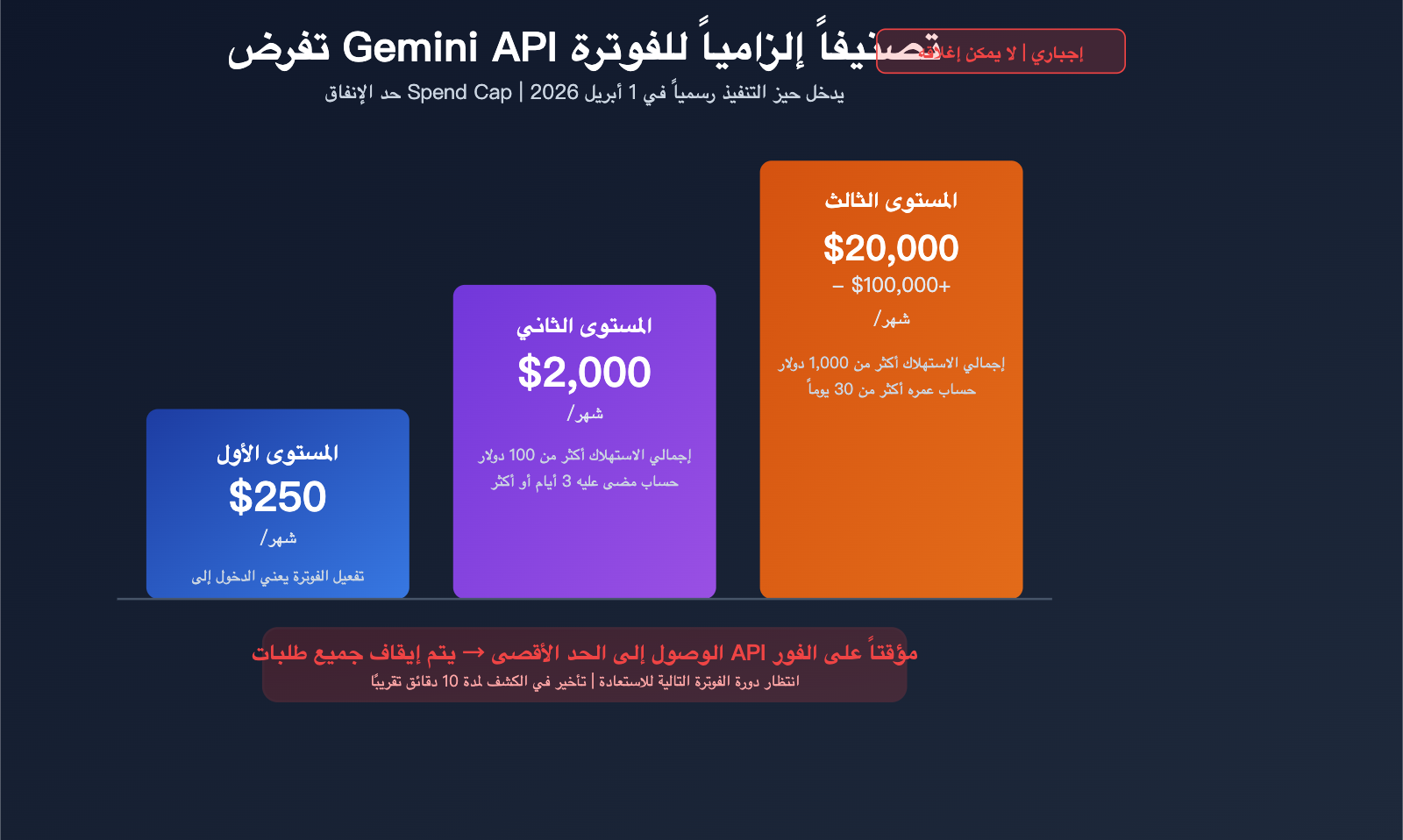
الفرق بين Claude Fable 5 و Mythos 5: نموذجان بتغليف مختلف، 5 اختلافات جوهرية موضحة
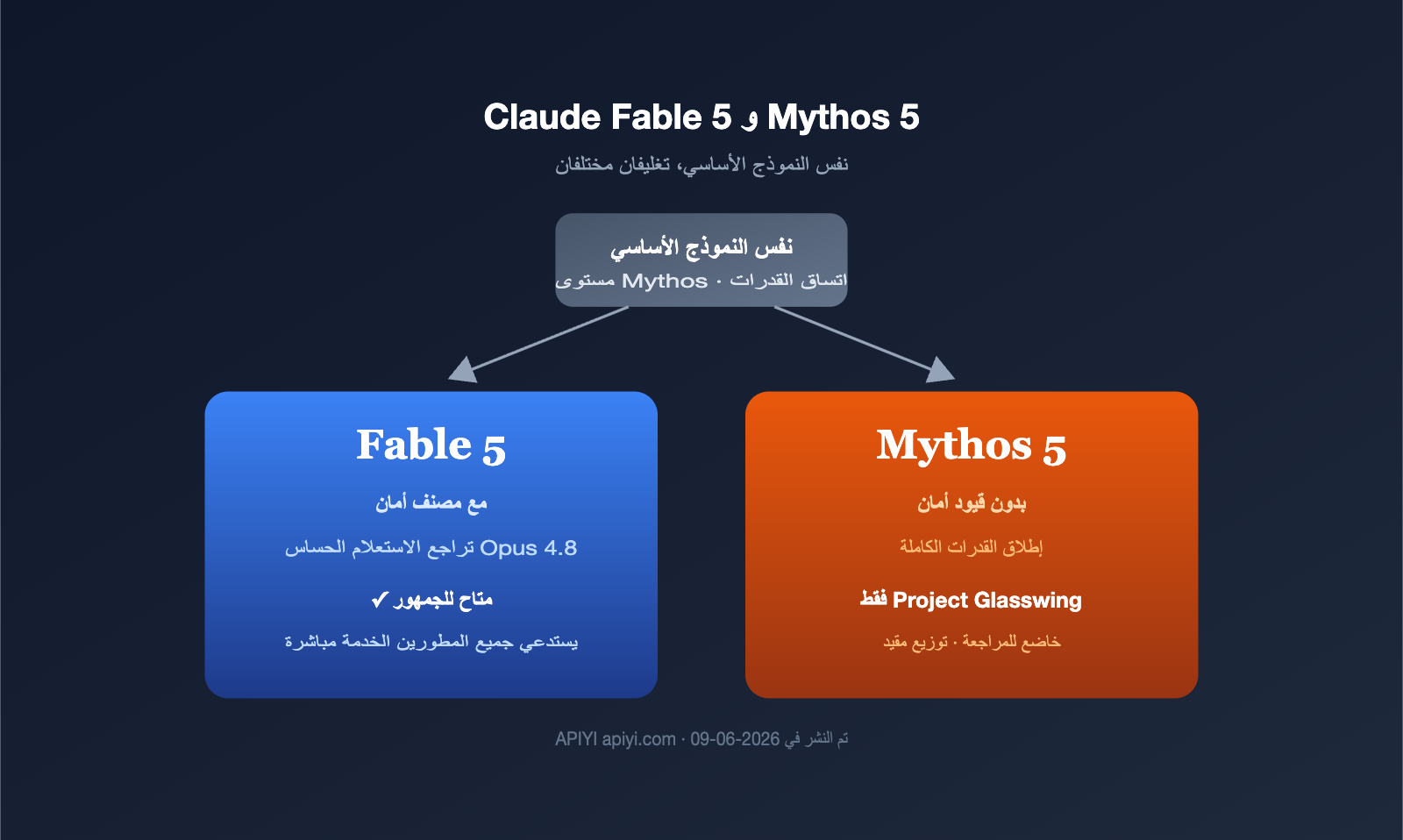
في 9 يونيو 2026، أطلقت شركة Anthropic اسمين دفعة واحدة: Claude Fable 5 وClaude Mythos 5. ظن الكثيرون أنهما نموذجان مختلفان، لكن في الواقع هما تغليفان مختلفان لنفس النموذج الأساسي. ما يميزهما حقاً ليس القدرات، بل سياسات الأمان. تجيب هذه المقالة على سؤال واحد فقط: ما الفرق الحقيقي بين Claude Fable 5 وMythos 5؟ سنشرح … اقرأ المزيد