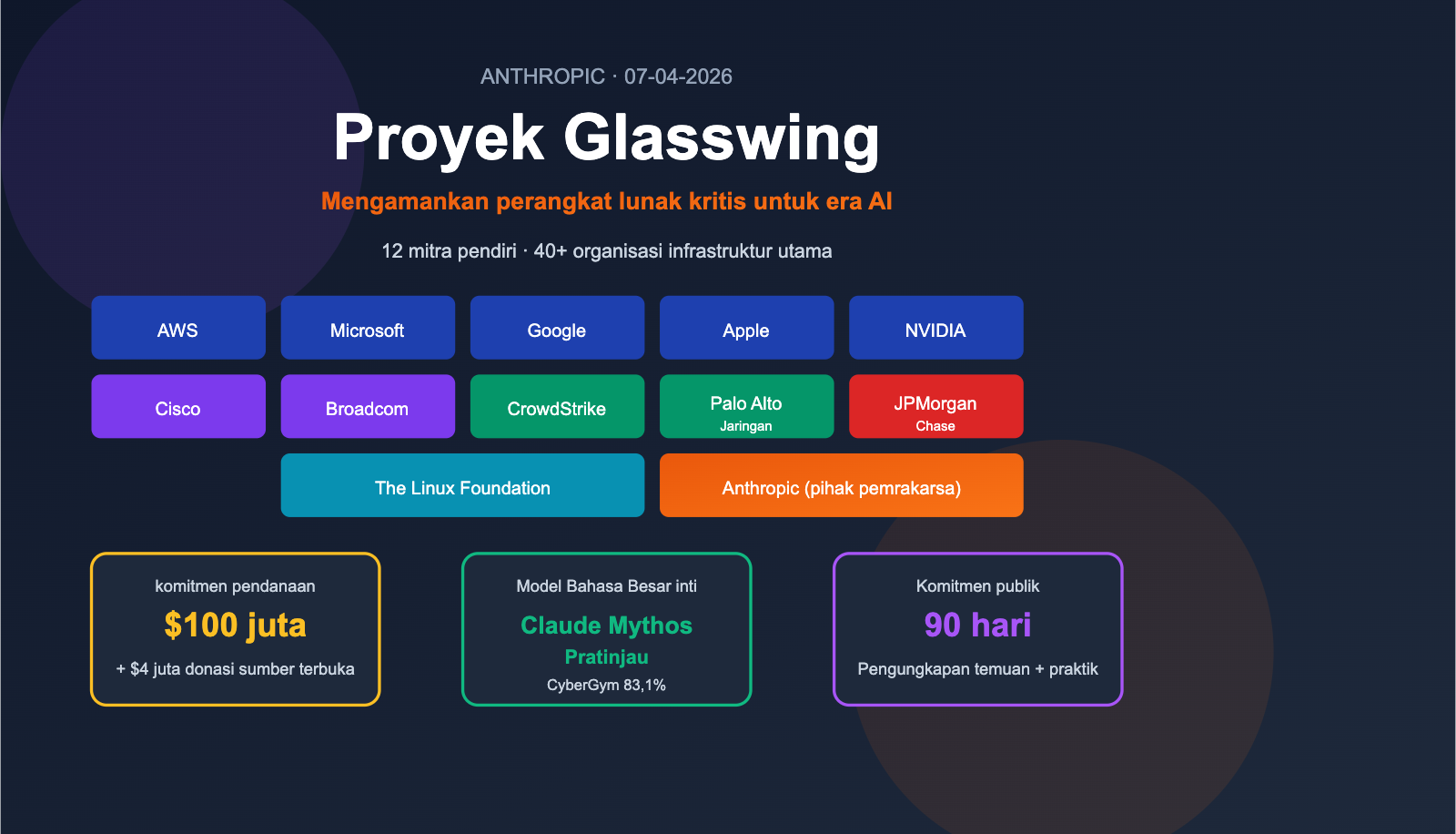
Perbedaan antara Claude Fable 5 dan Mythos 5: Dua kemasan untuk satu Model Bahasa Besar, 5 perbedaan inti dijelaskan
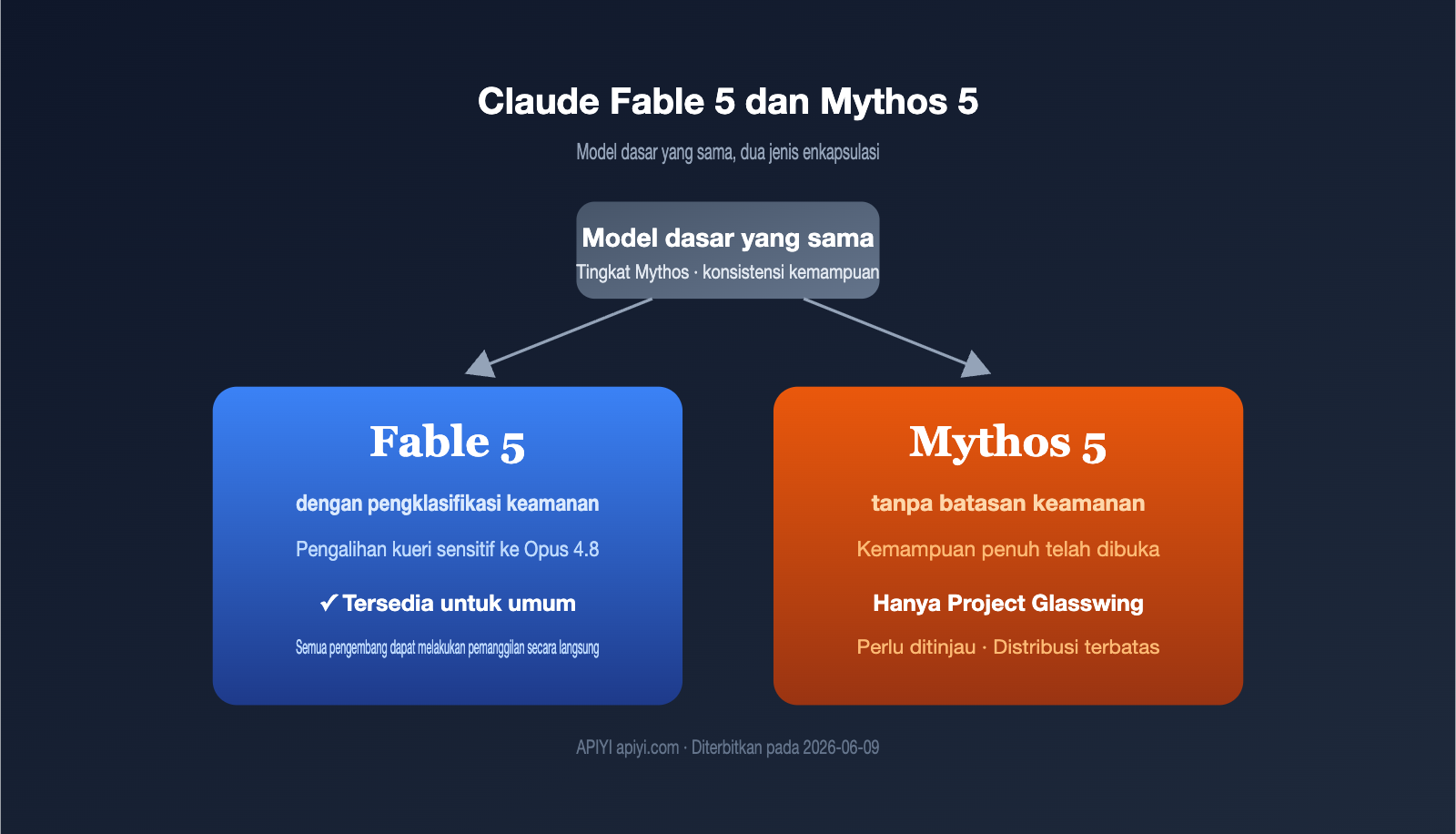
Pada tanggal 9 Juni 2026, Anthropic merilis dua nama sekaligus: Claude Fable 5 dan Claude Mythos 5. Banyak orang mengira ini adalah dua model yang berbeda, padahal keduanya hanyalah dua kemasan dari satu model dasar yang sama. Yang membedakan keduanya bukanlah kemampuan, melainkan kebijakan keamanannya. Artikel ini hanya akan menjawab satu pertanyaan: apa sebenarnya perbedaan … Baca Selengkapnya