
Nota do autor: Este artigo explica sistematicamente o princípio real da estratificação de imagens no gpt-image-2, os fenômenos de processamento em segundo plano com Python, os métodos de invocação de API e as estratégias de otimização de custos, ajudando os desenvolvedores a não confundirem as capacidades da cadeia de ferramentas com as capacidades nativas do modelo.
Se você tem usado o gpt-image-2 recentemente para criar pôsteres, gráficos científicos, imagens de produtos ou slides, talvez já tenha notado um fenômeno interessante: algumas pessoas afirmam que ele consegue "estratificar imagens" (fazer a separação de camadas) e até mesmo dividir uma imagem em objetos editáveis via Python no backend.
À primeira vista, parece que o modelo aprendeu Photoshop de repente, mas, na verdade, isso se aproxima mais de um fluxo de trabalho com múltiplas ferramentas: o gpt-image-2 é responsável por gerar ou editar imagens de alta qualidade, enquanto scripts Python cuidam do pós-processamento, como OCR, preenchimento de fundo, segmentação de elementos e reconstrução de arquivos SVG/PPTX/PSD.
Este não é mais um artigo introdutório, mas sim uma análise completa sobre o que a estratificação de imagens do gpt-image-2 pode ou não fazer, abordando capacidades de API, princípios de camadas, pós-processamento em Python, cálculo de custos e implementação de engenharia.
Valor central: Ao terminar este artigo, você terá clareza sobre os limites da estratificação de imagens do gpt-image-2, saberá como integrar a API oficial do gpt-image-2 via APIYI (apiyi.com) e como projetar um fluxo de trabalho de "geração de imagem para material editável" pronto para produção.
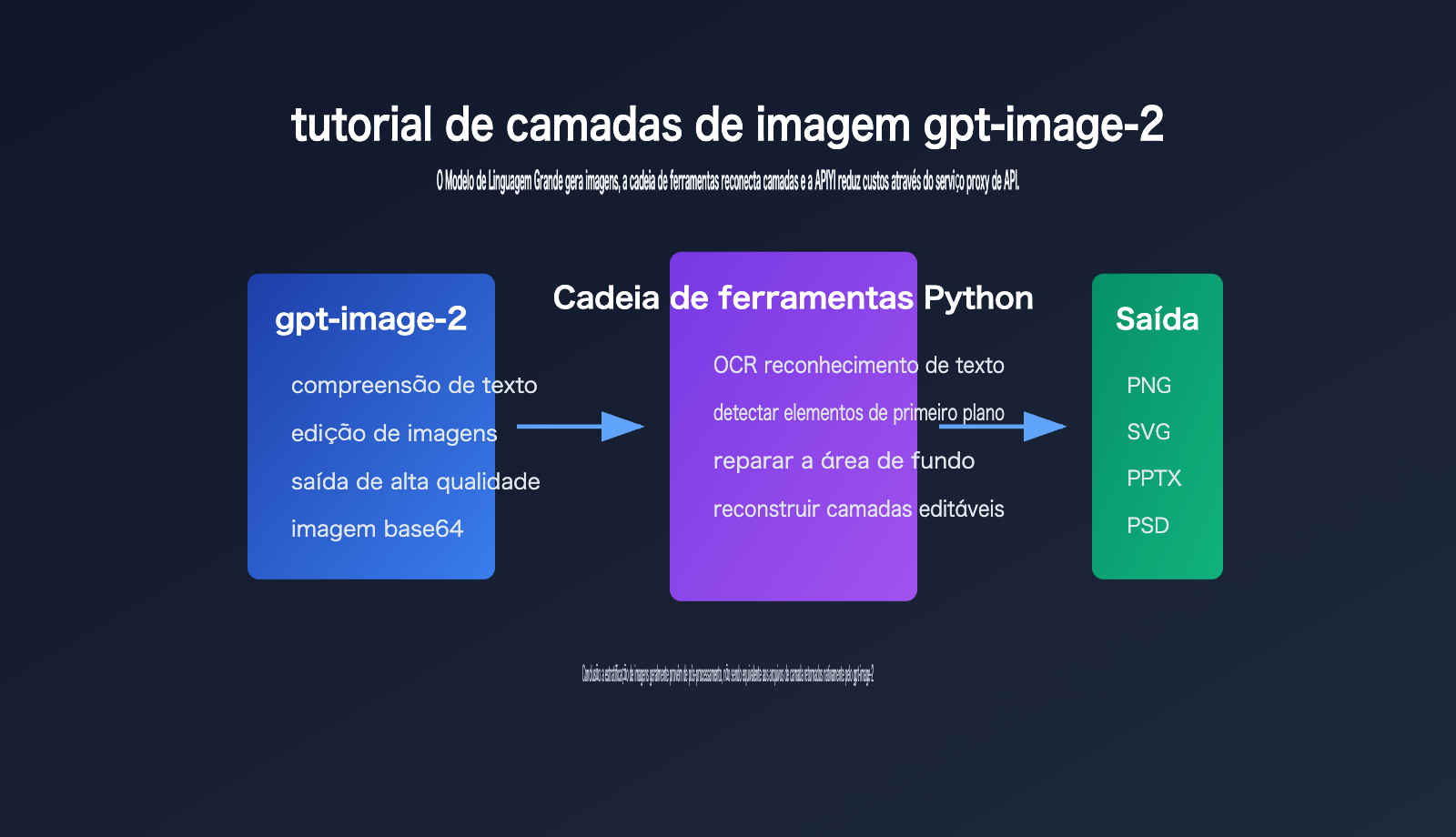
Pontos principais da estratificação de imagens no gpt-image-2
O segredo da estratificação de imagens no gpt-image-2 é distinguir primeiro entre a "saída do modelo" e a "saída do fluxo de trabalho do produto".
A página oficial do modelo da OpenAI define o gpt-image-2 como um modelo de imagem para geração e edição rápida e de alta qualidade, que suporta entrada de texto, entrada de imagem e saída de imagem, podendo ser usado nos endpoints de geração e edição da API de Imagens.
No entanto, a partir da forma atual da API pública, o resultado principal que os desenvolvedores recebem ainda são dados de imagem, e não arquivos de projeto com múltiplas camadas ao estilo Photoshop.
| Ponto | Descrição | Valor para o desenvolvedor |
|---|---|---|
| Capacidade nativa do modelo | O gpt-image-2 é responsável por entender o comando, a imagem de referência e a intenção de edição, gerando a imagem final | Adequado para gerar pôsteres, imagens de produtos, ilustrações e rascunhos visuais |
| Formato de saída da interface | A documentação oficial gira em torno de campos como b64_json, formato da imagem, dimensões, qualidade, uso de tokens, etc. |
Facilita o salvamento, upload, auditoria e cobrança no lado do servidor |
| Origem da estratificação | A maioria das camadas editáveis provém de pós-processamento como OCR, segmentação, preenchimento, vetorização, gravação em PPTX/PSD | Explica "por que o backend executa Python" |
| Otimização de custos | A API oficial via proxy permite a integração pelo preço original, combinada com bônus de recarga para reduzir o custo real | Adequado para geração em lote, testes e integração em produção |
A estratificação de imagens do gpt-image-2 não é uma saída PSD nativa
Um dos pontos mais mal compreendidos sobre a estratificação de imagens no gpt-image-2 é confundir o "arquivo editável que o usuário final vê" com o "arquivo que o modelo expele diretamente".
Em termos de engenharia, essas duas coisas são completamente diferentes.
O modelo gera diretamente uma imagem, que geralmente é recebida pela aplicação como dados de imagem base64 ou arquivo de imagem.
Se um produto consegue transformá-la em PPTX, SVG ou PSD, isso geralmente significa que o produto adicionou uma camada de sistema de pós-processamento após o modelo.
Essa camada de sistema provavelmente é feita em Python, já que o ecossistema Python é maduro em processamento de imagem, OCR, inferência de aprendizado profundo e geração de documentos de escritório.
Por exemplo, um engenheiro pode primeiro usar OCR para identificar o texto, depois usar inpainting para limpar a área de texto na imagem original e, em seguida, usar python-pptx para reconstruir caixas de texto e camadas de imagem.
Esse tipo de fluxo pode fazer o usuário sentir que a "imagem foi estratificada", mas, na essência, é uma inferência reversa da estrutura editável a partir de uma imagem plana.
Essa inferência reversa nem sempre é perfeita.
Quanto mais claro o texto, mais simples o fundo e mais regular o layout, melhor será o efeito de estratificação.
Se a imagem contiver texturas complexas, sombras semitransparentes, escrita à mão, decorações pequenas ou objetos altamente sobrepostos, o pós-processamento facilmente apresentará detecções incorretas, falhas de detecção e imperfeições nas bordas.
A estratificação de imagens do gpt-image-2 exige atenção aos limites entre o modelo e a cadeia de ferramentas
Ao desenvolver a estratificação de imagens com gpt-image-2, os desenvolvedores devem dividir o sistema em duas partes.
A primeira parte é a fase de geração: fazer com que o gpt-image-2 produza imagens com qualidade visual suficientemente alta, estrutura clara e texto o mais preciso possível.
A segunda parte é a fase de estruturação: usar Python ou outras ferramentas de pós-processamento para converter a imagem plana em objetos editáveis.
Os objetivos das duas partes são diferentes, e os indicadores de avaliação também.
Na fase de geração, o foco está na obediência ao comando, composição, precisão do texto, consistência da imagem e custo de saída.
Na fase de estruturação, o foco está na taxa de editabilidade do texto, precisão da divisão de objetos, naturalidade do preenchimento de fundo, compatibilidade do arquivo exportado e custo de correção manual.
Dica técnica: Se você deseja validar o fluxo de estratificação de imagens do gpt-image-2, recomenda-se integrar primeiro a API oficial do gpt-image-2 via APIYI (apiyi.com) para realizar a geração e edição, e depois adicionar gradualmente os módulos de OCR, segmentação, preenchimento e exportação. Isso permite isolar os problemas do modelo dos problemas de pós-processamento.
Como funciona a estratificação de imagens no gpt-image-2
A estratificação de imagens no gpt-image-2 pode ser entendida como uma engenharia reversa de "imagens planas para materiais estruturados".
Não se trata apenas de um simples recorte, mas de um fluxo completo que combina compreensão visual, processamento de imagem tradicional e geração de documentos.
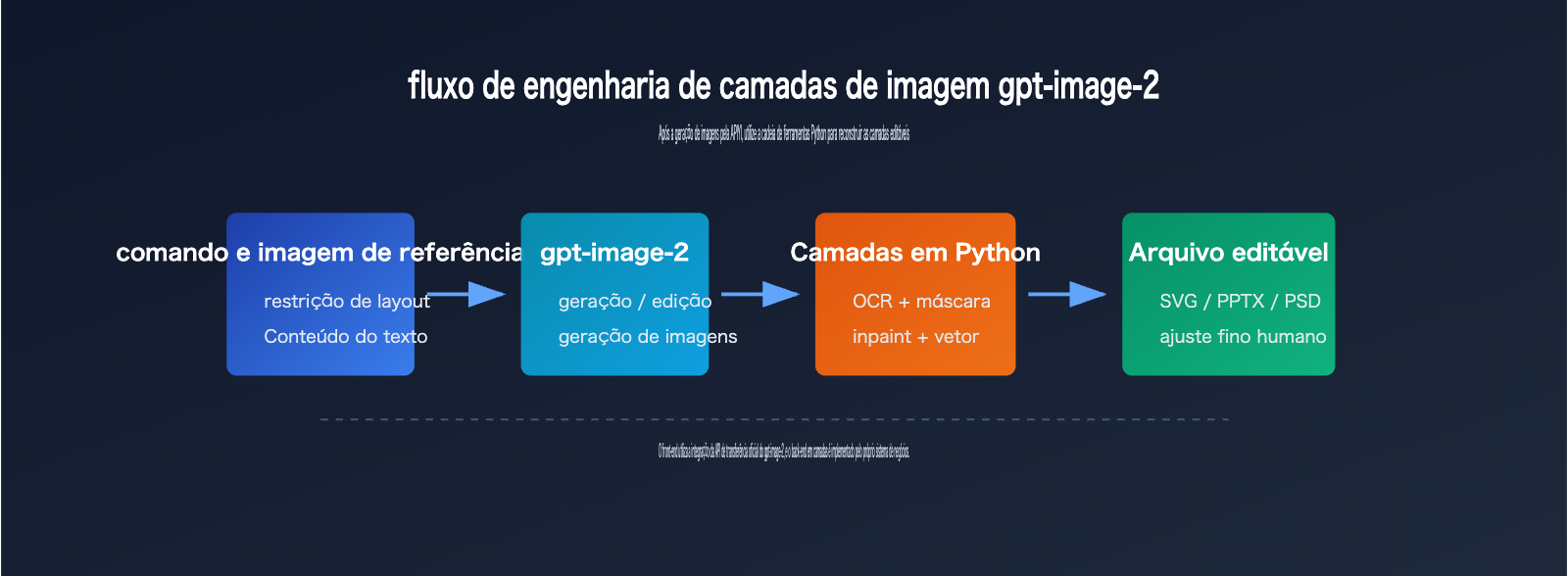
Passo 1 da estratificação do gpt-image-2: Gerar imagens adequadas para estratificação
Para tornar a estratificação de imagens no gpt-image-2 mais estável, a fase de geração deve servir ao pós-processamento.
O comando deve exigir explicitamente um layout claro, limites de elementos bem definidos, áreas de texto independentes e texturas de fundo que não sejam excessivamente complexas.
Se o objetivo for criar PPTX ou SVG, recomenda-se usar design plano, blocos de cores nítidos, poucas sombras e poucos gradientes.
Se o objetivo for criar um PSD, recomenda-se descrever claramente a relação entre o sujeito, o fundo, o texto e os elementos decorativos.
Um erro comum é pedir ao modelo que gere cartazes de filme muito complexos e esperar que as ferramentas de pós-processamento separem automaticamente as camadas perfeitamente.
Isso não é realista nas condições de engenharia atuais.
O efeito de estratificação depende fortemente da capacidade de análise da imagem de entrada.
Passo 2 da estratificação do gpt-image-2: Detecção de texto e objetos
A primeira categoria de tarefas mais comum no backend Python é a detecção.
A detecção de texto geralmente usa modelos de OCR para identificar o conteúdo dos caracteres, posição, tamanho da fonte e limites da caixa de texto.
A detecção ou segmentação de objetos identificará objetos visuais como pessoas, produtos, ícones, linhas, áreas de fundo, etc.
No caso de slides ou infográficos, também é possível identificar títulos, parágrafos, tabelas, setas, eixos de coordenadas e legendas.
Esta camada não é o gpt-image-2 "retornando camadas" por si só, mas sim o modelo de pós-processamento inferindo as camadas a partir dos pixels.
Quanto mais precisa for a inferência, mais o PPTX, SVG ou PSD exportado se parecerá com o design original.
Quando a inferência não é precisa, os problemas mais comuns incluem deslocamento da caixa de texto, fontes inconsistentes, vestígios no reparo do fundo e ícones fragmentados.
Passo 3 da estratificação do gpt-image-2: Reparo de fundo e reconstrução de arquivos
Quando o OCR identifica uma área de texto, para tornar o texto editável, geralmente é necessário apagá-lo da imagem original.
Após apagar o texto, aparecerão buracos no fundo.
Nesse momento, é necessário usar algoritmos de inpainting ou reparo de imagem para preencher o fundo.
Em seguida, o sistema escreve o texto identificado de volta no PPTX, SVG ou PSD como uma caixa de texto independente.
Se você quiser camadas de objetos mais detalhadas, também precisará gerar uma máscara para os elementos do primeiro plano, recortar o objeto e gravá-lo em camadas diferentes.
Esse fluxo parece "o modelo estratifica", mas, sendo preciso, é "modelo gera imagem + Python analisa imagem + biblioteca de documentos reconstrói camadas".
Primeiros passos com a estratificação de imagens no gpt-image-2
Abaixo, apresento o fluxo mínimo de estratificação de imagens no gpt-image-2 para desenvolvedores.
O primeiro passo é obter a imagem via API.
O segundo passo é salvar a imagem como um arquivo local.
O terceiro passo é encaminhá-la para os módulos de OCR, segmentação, reparo e exportação.
Exemplo de API minimalista para estratificação no gpt-image-2
O exemplo a seguir demonstra como chamar a API oficial do gpt-image-2 via interface unificada.
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
result = client.images.generate(
model="gpt-image-2",
prompt="Gerar um cartaz de lançamento de produto adequado para estratificação posterior, fundo de cor sólida, áreas de texto claras, limites de elementos definidos",
size="1024x1024",
quality="medium",
output_format="png"
)
image_bytes = base64.b64decode(result.data[0].b64_json)
open("poster.png", "wb").write(image_bytes)
O foco deste código não é "obter um PSD imediatamente", mas sim obter uma imagem clara e adequada para o pós-processamento.
Se você vir o servidor continuando a chamar o Python, geralmente é porque ele entrou na fase de OCR, máscara, inpainting ou exportação.
Estrutura completa de processamento de estratificação no gpt-image-2
Abaixo está uma estrutura de processamento mais próxima de um projeto real.
Ela não está vinculada a um modelo específico de OCR ou segmentação, apenas mostra os limites dos módulos.
from pathlib import Path
def generate_image(prompt: str) -> Path:
"""Chama a API oficial do gpt-image-2 e salva a imagem plana."""
# client = OpenAI(api_key="YOUR_APIYI_KEY", base_url="https://vip.apiyi.com/v1")
# response = client.images.generate(model="gpt-image-2", prompt=prompt)
return Path("poster.png")
def detect_layout(image_path: Path) -> dict:
"""OCR, detecção de objetos, reconhecimento de layout."""
return {"texts": [], "objects": [], "background_regions": []}
def rebuild_editable_file(image_path: Path, layout: dict) -> Path:
"""Repara o fundo e exporta SVG, PPTX ou PSD."""
return Path("poster-editable.pptx")
prompt = "Gerar um cartaz de produto de IA com texto claro, elementos separados e adequado para edição em camadas"
image_path = generate_image(prompt)
layout = detect_layout(image_path)
editable_path = rebuild_editable_file(image_path, layout)
print(editable_path)
Em ambientes de produção, recomenda-se separar generate_image e rebuild_editable_file em tarefas assíncronas.
A geração da imagem em si pode exigir tempo de espera, e o pós-processamento também pode consumir CPU ou GPU.
Para equipes que precisam gerar cartazes, imagens de produtos ou gráficos científicos em lote, é melhor que as chamadas de API e as tarefas de pós-processamento entrem em uma fila, registrando o tempo de execução e a causa de falhas de cada etapa.
Dica para começar rápido: A API oficial do gpt-image-2 da APIYI (apiyi.com) é ideal para validar a fase de geração, permitindo que você conecte seus próprios módulos de estratificação em Python posteriormente. Assim, você mantém a capacidade do modelo oficial enquanto domina a lógica de arquivos editáveis no seu próprio sistema.
Modelo de comando para estratificação de imagens no gpt-image-2
Se o objetivo final é "ser estratificável", o comando deve ser mais contido do que um comando comum de texto para imagem.
| Objetivo | Escrita de comando recomendada | Escrita não recomendada |
|---|---|---|
| Estratificação de cartazes | Fundo de cor sólida ou gradiente de baixa complexidade, título independente, produto com bordas claras | Gerar cartazes complexos de nível cinematográfico, com muitas texturas e fumaça |
| Estratificação de PPT | Estilo de infográfico plano, contendo títulos claros, ícones, setas e três seções de explicação | Gerar visuais abstratos com forte senso artístico |
| Estratificação de imagem de produto | Produto no centro da tela, fundo limpo, projeção suave, limites definidos | Fazer com que o produto se funda fortemente com o fundo |
| Reconstrução SVG | Formas geométricas, linhas, blocos de cor, pouco texto, evitar texturas de fotos reais | Muitas texturas fragmentadas, personagens complexos e materiais transparentes |
Bons comandos reduzem significativamente a dificuldade do pós-processamento.
Do ponto de vista da engenharia, "adequado para geração" e "adequado para estratificação" não são o mesmo objetivo.
Usuários comuns querem impacto visual, sistemas de estratificação querem estrutura clara.
Se você deseja produzir materiais automatizados, deve priorizar a clareza estrutural.
Análise do fenômeno de processamento em Python para camadas de imagem no gpt-image-2
Quando os usuários observam o Python processando camadas de imagem no gpt-image-2 em segundo plano, geralmente existem três possibilidades.
A primeira é o script de encapsulamento da API.
Para reduzir a repetição de código, os desenvolvedores escrevem scripts em Python para chamar o gpt-image-2, salvar imagens automaticamente, registrar parâmetros, tratar erros e realizar novas tentativas.
Esse tipo de script não significa que o modelo seja executado internamente em Python.
A segunda é o script de pós-processamento de imagem.
Por exemplo, enviar a imagem gerada para ferramentas de OCR, modelos de segmentação, modelos de preenchimento de fundo, ferramentas de vetorização ou bibliotecas de geração de PPTX/PSD.
Esses scripts são a principal fonte da "sensação de camadas".
A terceira é o script de fluxo de trabalho de Agente.
Se o usuário invoca a geração de imagens através do ChatGPT, Codex, Claude Code ou outras ferramentas de Agente, o Agente pode selecionar automaticamente uma ferramenta Python para concluir o download, conversão, recorte, montagem ou geração de arquivos.
Isso ainda é uma chamada de ferramenta em nível de produto, não um retorno nativo de múltiplas camadas pela API do gpt-image-2.
Por que o Python é comumente usado para camadas de imagem no gpt-image-2
O Python é adequado para o processamento de camadas do gpt-image-2 não por ser misterioso, mas porque seu ecossistema é completo.
| Etapa de processamento | Tarefa comum em Python | Valor típico |
|---|---|---|
| Chamada de API | Chamar a API de Imagens, salvar imagem em base64, registrar parâmetros | Geração estável de imagens |
| OCR | Identificar conteúdo, posição e caixas de texto | Transformar texto da imagem em texto editável |
| Segmentação | Gerar máscara de objeto principal, fundo, ícones, linhas | Separar objetos visuais |
| Preenchimento | Apagar texto ou objetos e preencher o fundo | Criar uma imagem de base limpa |
| Exportação | Gravar em SVG, PPTX, PSD ou outros formatos | Entrega de arquivos editáveis |
A vantagem desse fluxo é a flexibilidade.
Os desenvolvedores podem escolher diferentes modelos de OCR, modelos de segmentação e formatos de exportação de acordo com o cenário de negócio.
A desvantagem é que a estabilidade do resultado não é determinada inteiramente pelo gpt-image-2.
Se o OCR identificar caracteres errados ou o preenchimento de fundo falhar, mesmo que a imagem original tenha alta qualidade, o arquivo editável final apresentará problemas.
As camadas de imagem do gpt-image-2 não são as "layers" das políticas de segurança
Existe outro termo que causa confusão: "layers".
Materiais de segurança da OpenAI mencionam expressões como image input layers, image output layers, multiple layers of protection, etc.
Aqui, layers refere-se a camadas de detecção de segurança, camadas de detecção de entrada/saída ou camadas de proteção, e não a camadas do Photoshop.
Se você vir o termo layers em inglês e traduzi-lo diretamente como "camadas de imagem", é fácil causar uma interpretação errada.
Ao realizar a seleção técnica, recomendo sempre verificar os campos da API e o formato de saída.
Se a interface não retornar uma lista de camadas, lista de máscaras, árvore de objetos ou arquivo PSD, ela não pode ser considerada uma interface nativa de camadas de imagem.
Critérios de confiabilidade para camadas de imagem no gpt-image-2
Para julgar se uma solução de camadas de imagem do gpt-image-2 é confiável, observe quatro indicadores.
Primeiro, veja se ela diferencia claramente a saída da imagem original da saída do pós-processamento.
Segundo, veja se ela consegue exibir a origem de cada camada, como camada de texto OCR, camada de fundo, camada de objeto em primeiro plano.
Terceiro, veja se permite correção manual.
Quarto, veja se consegue reproduzir o resultado de camadas para a mesma imagem.
Se um sistema apenas diz "camadas automáticas por IA", mas não explica a lógica de OCR, máscara, preenchimento e exportação, o desenvolvedor deve avaliar com cautela.
Sugestão de solução: Em projetos reais, você pode obter a capacidade de geração estável do gpt-image-2 através de canais de redirecionamento oficial e transformar a capacidade de camadas em Python em um serviço interno. Assim, você utiliza a capacidade do canal oficial sem prender o pós-processamento a uma única ferramenta "caixa-preta".
Custos da API de camadas de imagem do gpt-image-2 e a referência de 14% de desconto
O custo das camadas de imagem do gpt-image-2 deve ser calculado separadamente.
A geração do modelo é uma parte do custo.
OCR, segmentação, preenchimento, exportação e armazenamento são outra parte.
Se você olhar apenas para "quanto custa gerar um arquivo editável", é fácil julgar mal o orçamento.
Referência de preço oficial das camadas de imagem do gpt-image-2
De acordo com a página de preços da API oficial da OpenAI, os preços públicos do gpt-image-2 incluem entrada de imagem, entrada de imagem em cache, saída de imagem, entrada de texto e entrada de texto em cache.
| Item de cobrança | Preço oficial | Significado nas camadas de imagem |
|---|---|---|
| Image input | US$ 8,00 / 1 milhão de tokens | Gerado ao inserir imagem de referência, edição ou material |
| Cached image input | US$ 2,00 / 1 milhão de tokens | Custo de entrada de imagem em cache reutilizável |
| Image output | US$ 30,00 / 1 milhão de tokens | Custo principal da saída da imagem em si |
| Text input | US$ 5,00 / 1 milhão de tokens | Comandos, instruções de edição, especificações de layout |
| Cached text input | US$ 1,25 / 1 milhão de tokens | Espaço de otimização de custo para comandos em cache |
O preço oficial é a base para o orçamento.
Mas em projetos reais, também é preciso considerar novas tentativas após falhas, filas em lote, poder computacional de pós-processamento, revisão humana e custos de armazenamento.
Se você precisa gerar frequentemente várias versões de cartazes, recomendo controlar os custos através de comandos, dimensões, qualidade e estratégias de nova tentativa.
Custos usando a API de redirecionamento oficial para camadas de imagem do gpt-image-2
A API de redirecionamento oficial do gpt-image-2 da APIYI (apiyi.com) pode ser acessada seguindo os preços originais oficiais, sendo ideal para equipes que desejam manter o canal oficial do modelo enquanto reduzem a complexidade de integração.
A promoção de recarga mencionada pelos usuários é: recarregue US$ 100 e ganhe 10% de saldo extra.
Calculando estritamente como "US$ 100 depositados resultam em US$ 110 de saldo disponível", o custo unitário equivalente é de aproximadamente 90,9% do preço oficial original.
Se convertido com base na exibição da promoção da plataforma e no desconto consolidado, pode ser entendido externamente como uma faixa de desconto próxima de 14% em relação ao site oficial, sujeito às regras reais de recarga e liquidação da plataforma.
| Forma de acesso | Base de preço | Vantagens | Observações |
|---|---|---|---|
| API oficial da OpenAI | Preço oficial | Canal nativo, documentação completa | Requer gerenciamento próprio de conta, pagamento, limites e risco |
| API de redirecionamento oficial | Preço oficial | Acesso rápido, interface unificada, fácil gestão | Requer recarga e liquidação conforme regras da plataforma |
| Promoção de recarga | Recarregue US$ 100 ganhe 10% | Pode reduzir o custo unitário real | O desconto depende do valor efetivamente creditado |
| Solução reversa própria | Variável | Alta flexibilidade | Maior custo de conformidade, estabilidade e manutenção |
Sugestão de custo: Se você for realizar testes de produto para camadas de imagem do gpt-image-2, recomendo usar primeiro a API de redirecionamento oficial da APIYI (apiyi.com) para processar de 50 a 100 amostras, registrar o custo de geração de cada imagem, a taxa de sucesso das camadas e o tempo de correção manual, antes de decidir se deve ampliar as chamadas em lote.
Lista de verificação para otimização de custos em camadas de imagem do gpt-image-2
Não foque apenas no preço unitário para otimizar custos.
O mais importante é reduzir gerações inválidas.
Primeiro, use comandos estruturados para reduzir novas tentativas causadas por composições pouco claras.
Segundo, use qualidade média para validar o layout antes de aumentar a qualidade para a versão final.
Terceiro, armazene em cache os comandos de modelo para reduzir o custo de entrada de texto repetitivo.
Quarto, use imagens de referência e especificações de layout unificadas para o mesmo produto, reduzindo a dificuldade do pós-processamento.
Quinto, classifique as amostras com falha para distinguir se a falha ocorreu na geração do modelo ou no processamento de camadas em Python.
Sexto, priorize o estilo de infográfico plano para cenários que exigem entrega editável.
Essas práticas costumam ser mais eficazes do que simplesmente buscar um preço unitário menor.
Comparativo de soluções de camadas de imagem para gpt-image-2
Diferentes equipes possuem requisitos distintos para a separação de camadas em imagens geradas pelo gpt-image-2.
Alguns usuários apenas querem alterar o título, outros precisam exportar para PPTX, há quem deseje um arquivo PSD completo e outros que buscam apenas gerar um SVG com estrutura clara.
O comparativo abaixo ajudará você a escolher o caminho ideal.
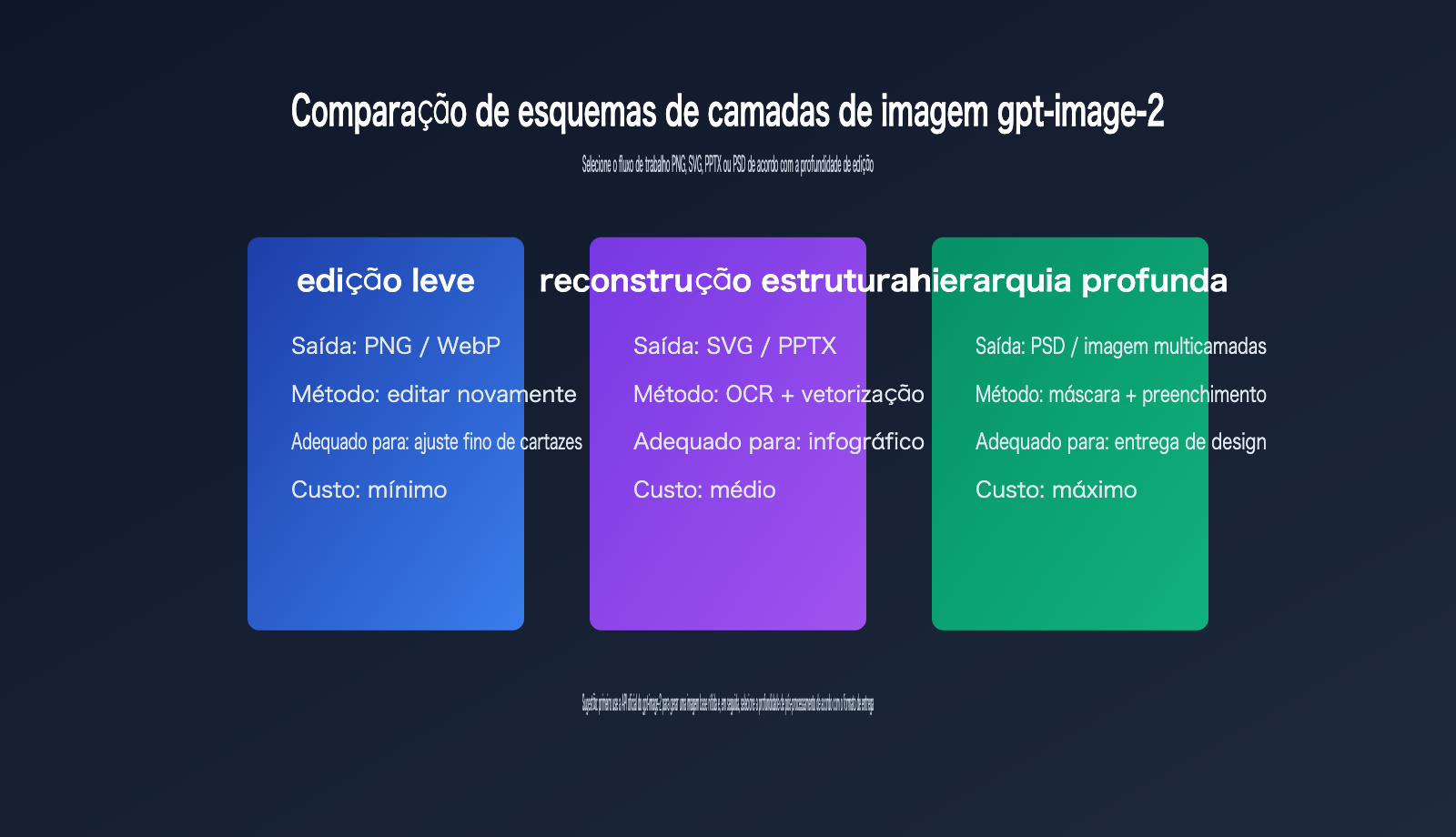
Rota 1 de camadas do gpt-image-2: continuar com a edição de imagem
Se você precisa apenas alterar uma parte do conteúdo, a maneira mais simples não é separar em camadas, mas continuar editando com o gpt-image-2.
Por exemplo, alterar o título, mudar cores, trocar o fundo, substituir a imagem do produto ou adicionar pequenos ícones pode ser feito via interface de edição de imagem.
Esta rota tem o menor custo e a menor complexidade de sistema.
A desvantagem é que cada edição exige a regeneração parcial ou total da imagem, não sendo possível selecionar camadas individuais como em softwares de design.
É ideal para gestão de conteúdo, imagens para redes sociais e pôsteres rápidos.
Rota 2 de camadas do gpt-image-2: exportar para SVG ou PPTX
Se a imagem for um gráfico, fluxograma, pôster científico ou infográfico, a reconstrução em SVG/PPTX costuma ser mais prática que o PSD.
Isso ocorre porque os elementos dessas imagens geralmente são textos, ícones, linhas, retângulos, setas e algumas decorações.
O OCR pode identificar o texto, a vetorização pode reconstruir linhas e blocos de cor, e bibliotecas de PPTX podem criar caixas de texto editáveis.
Esta rota é adequada para bases de conhecimento corporativas, apresentações científicas, materiais de vendas e slides de treinamento.
O objetivo não é a restauração de 100% dos pixels, mas sim a "editabilidade" e a fidelidade visual.
Rota 3 de camadas do gpt-image-2: gerar PSD ou pacote de ativos multicamadas
A separação em PSD é a mais complexa.
Para separar pessoas, produtos, fundo, texto, sombras e decorações em camadas distintas, o sistema precisa de capacidades avançadas de segmentação e preenchimento.
Para imagens com estilo fotográfico complexo, um PSD automático dificilmente atingirá o nível de um designer profissional.
Uma estratégia mais realista é gerar um "PSD semiautomático": o sistema separa o fundo, o objeto principal, o texto e alguns objetos-chave, e o designer faz o ajuste manual posteriormente.
Esta rota é ideal para design de marca, imagens principais de e-commerce, criações publicitárias e ativos de alto valor que precisam ser reutilizados a longo prazo.
Perguntas frequentes sobre camadas no gpt-image-2
O gpt-image-2 pode exportar PSD diretamente?
Pelo estado atual da API pública, não se deve entendê-lo como um "exportador direto de arquivos PSD com camadas".
A documentação oficial foca em geração de imagens, edição, dados de imagem em base64, formatos de saída, dimensões, qualidade e consumo de tokens.
Se um produto permite exportar para PSD, geralmente é porque ele integra adicionalmente o Photoshop, bibliotecas de escrita PSD ou módulos de pós-processamento próprios.
O Python mencionado nas camadas do gpt-image-2 é o código interno do modelo?
Geralmente, não.
O Python que os usuários veem é, provavelmente, um script de fluxo de trabalho externo.
Ele pode ser responsável por chamar a API, salvar imagens, executar OCR, gerar máscaras, preencher fundos, vetorizar gráficos ou escrever arquivos PPTX/PSD. Esses scripts pertencem à camada de aplicação, não ao modelo em si.
Por que as camadas do gpt-image-2 parecem tão reais?
Porque o sistema de pós-processamento pode reconstruir a estrutura a partir dos pixels.
Por exemplo, após o reconhecimento de texto, ele pode se tornar uma caixa de texto editável. O objeto principal pode se tornar uma camada de imagem independente através de uma máscara, e o fundo pode se tornar uma base limpa após o preenchimento.
Quando sobrepostas, essas camadas parecem arquivos de projeto exportados de um software de design.
A separação de camadas do gpt-image-2 é adequada para todas as imagens?
Não.
As imagens adequadas para separação geralmente possuem layout claro, bordas definidas, pouco texto, fundo simples e elementos que não se sobrepõem excessivamente.
Imagens não adequadas incluem fotografias complexas, ilustrações com texturas densas, materiais transparentes, muitos detalhes pequenos e composições altamente artísticas.
Como aumentar a taxa de sucesso na separação de camadas?
Comece otimizando o comando.
Peça ao modelo para gerar uma estrutura clara, com bordas definidas, áreas de texto independentes e fundo de baixa complexidade.
Em seguida, limite o tamanho e o estilo da imagem para evitar que o sistema de pós-processamento lide com detalhes excessivos.
Por fim, use conjuntos de amostras para avaliar a precisão do OCR, a precisão da separação de objetos e o tempo de correção manual.
Na camada de invocação da API, recomenda-se gerenciar de forma centralizada as solicitações via serviço proxy de API do gpt-image-2 para facilitar o registro de custos e amostras com falha.
É obrigatório usar a API para separar camadas no gpt-image-2?
Se você gera imagens apenas ocasionalmente, pode usar a interface gráfica.
Se você precisa de geração em lote, auditoria automática, armazenamento de ativos, exportação de arquivos editáveis ou colaboração em equipe, deve usar a API.
A API torna cada etapa rastreável, repetível e faturável, além de facilitar a integração com serviços de pós-processamento em Python.
Como entender o desconto de 14% (86% do valor) no gpt-image-2?
A referência mencionada pelos usuários é através do serviço proxy de API do gpt-image-2, que cobra pelo preço oficial, mas oferece 10% de bônus em recargas de 100 dólares.
Matematicamente, 100 dólares geram 110 dólares de saldo, o que equivale a um custo unitário de aproximadamente 90,9%.
Se a plataforma exibir um "desconto de 14% sobre o preço oficial" em promoções ou canais específicos, considere sempre o valor efetivamente creditado, o faturamento no painel e as regras da promoção.
Ao montar sua planilha orçamentária, recomendo manter três colunas: "Preço oficial", "Custo após bônus de recarga" e "Desconto promocional da plataforma", para evitar confusão financeira.
Principais conclusões sobre a segmentação de imagens no gpt-image-2
- O ponto central da segmentação de imagens no gpt-image-2 é: o modelo geralmente gera imagens planas, e as camadas (layers) provêm, na verdade, de cadeias de ferramentas de pós-processamento.
- O processamento em Python no backend não tem mistério; ele é frequentemente usado para invocação do modelo, OCR, máscaras, inpainting, vetorização e exportação de arquivos.
- Se a interface não retornar arquivos PSD, árvores de objetos, listas de camadas ou listas de máscaras, isso não deve ser anunciado como uma capacidade nativa de segmentação do modelo.
- Para aumentar a taxa de sucesso da segmentação, o comando deve ser otimizado para o pós-processamento, garantindo que a estrutura da imagem seja clara e os limites dos elementos bem definidos.
- Edições leves podem continuar usando o gpt-image-2, mas entregas estruturadas são mais adequadas para SVG/PPTX, enquanto projetos de design profundo devem considerar o formato PSD.
- A API oficial do gpt-image-2 é ideal para a integração da geração, enquanto o serviço de segmentação em Python é mais adequado para ser controlado pelo próprio sistema de negócio.
- O cálculo de custos deve levar em conta o preço oficial do modelo, bônus de recarga, poder computacional de pós-processamento, tentativas de falha e tempo de correção manual.
Referências sobre a segmentação de imagens no gpt-image-2
Este artigo foi escrito com base em materiais da internet em inglês e cruzado com a documentação pública da API.
- Página do modelo OpenAI GPT Image 2: developers.openai.com/api/docs/models/gpt-image-2
- Documentação de Imagens e Visão da OpenAI: developers.openai.com/api/docs/guides/images-vision
- Referência da API de Imagens da OpenAI: developers.openai.com/api/reference/resources/images
- Preços da API da OpenAI: openai.com/api/pricing
- Discussão no Reddit sobre habilidades em Python com GPT Image 2: reddit.com/r/ClaudeCode/comments/1stokpq
- Discussão no Reddit sobre GPT Image 2 para slides editáveis: reddit.com/r/ChatGPT/comments/1suwjp8
Esses materiais apontam para uma conclusão comum: as capacidades de geração e edição do gpt-image-2 são muito fortes, mas as camadas editáveis são, geralmente, o resultado de fluxos de trabalho na camada de aplicação.
Resumo sobre a estratificação de imagens no gpt-image-2
O ponto mais importante sobre a estratificação de imagens no gpt-image-2 não é buscar uma resposta única sobre "se ele gera um PSD nativo", mas sim estabelecer os limites corretos do sistema.
No lado da geração, o gpt-image-2 é responsável por transformar o comando e a imagem de referência em imagens de alta qualidade.
No lado da engenharia, a cadeia de ferramentas em Python é responsável por analisar a imagem plana e convertê-la em texto, objetos, plano de fundo e arquivos editáveis.
Ao separar claramente essas duas etapas, os desenvolvedores conseguem avaliar com mais precisão os resultados, os custos e a manutenibilidade.
Se o seu objetivo é criar pôsteres em lote, gráficos para PPT, visuais de produtos ou automação de materiais de design, recomendo usar primeiro o gpt-image-2 para gerar uma imagem base com estrutura clara e, em seguida, escolher o pós-processamento em SVG, PPTX ou PSD, dependendo do formato de entrega desejado.
Na camada de acesso, você pode priorizar a API oficial do gpt-image-2 via APIYI (apiyi.com), realizando a invocação do modelo pelo preço oficial e aproveitando a promoção de recarga onde 100 dólares garantem 10% de bônus, reduzindo assim o custo real de uso.
Quando você gerencia separadamente a "capacidade do modelo", a "capacidade de pós-processamento", o "formato de entrega" e o "modelo de custos", a estratificação de imagens no gpt-image-2 deixa de ser uma funcionalidade misteriosa e passa a ser um fluxo de produção visual verificável, escalável e pronto para implementação.
Para trocas técnicas e testes de integração de modelos, acompanhe a APIYI (apiyi.com), ideal para equipes de desenvolvedores que precisam de uma chamada unificada para o gpt-image-2, a série GPT e APIs de outros modelos.