
해외의 숙련된 개발자들이 Anthropic의 232페이지 분량 공식 시스템 카드를 샅샅이 분석한 결과, 결론은 하나로 모였습니다. Claude Opus 4.7의 긴 컨텍스트 처리 능력이 4.6 버전에 비해 심각하게 퇴보했다는 것입니다.
이 결론은 "Opus 4.7은 우리가 테스트한 모델 중 가장 일관된 긴 컨텍스트 성능을 보여주었다"는 Anthropic 공식 블로그의 문구와 극명한 대조를 이룹니다. 실제 데이터는 어디에 있을까요? 바로 공식 시스템 카드에 있습니다. MRCR v2 8-needle 벤치마크에서 1M 컨텍스트 기준, Opus 4.6은 78.3%를 기록했지만 Opus 4.7은 32.2%에 그쳤습니다. 정확도가 퇴보한 수준이 아니라 반토막이 난 셈입니다.
더욱 커뮤니티를 놀라게 한 것은 Anthropic이 시스템 카드에서 "Opus 4.6의 64k extended-thinking 모드가 긴 컨텍스트 다중 바늘(multi-needle) 검색 작업에서 4.7을 압도한다"고 인정한 점입니다. 이 문구는 Hacker News, X, Reddit의 베테랑 개발자들 사이에서 "Opus 4.7 긴 컨텍스트 퇴보"를 입증하는 공식 증거로 끊임없이 인용되고 있습니다.
본 글에서는 Anthropic 공식 시스템 카드, 제3자 독립 평가(X의 Rohan Paul, DEV Community의 232페이지 시스템 카드 분석), 그리고 개발자 커뮤니티의 생생한 피드백을 바탕으로 Claude Opus 4.7의 긴 컨텍스트 능력 퇴보에 대한 실제 데이터, 근본 원인, 그리고 대응 방안을 심층 분석합니다.
핵심 가치: 이 글을 읽고 나면 어떤 긴 컨텍스트 시나리오에서 4.6을 유지해야 하는지, 어떤 경우에 4.7을 사용해도 되는지, 그리고 API 호출 단계에서 어떻게 시나리오별 라우팅을 구현할지 명확히 알게 될 것입니다.
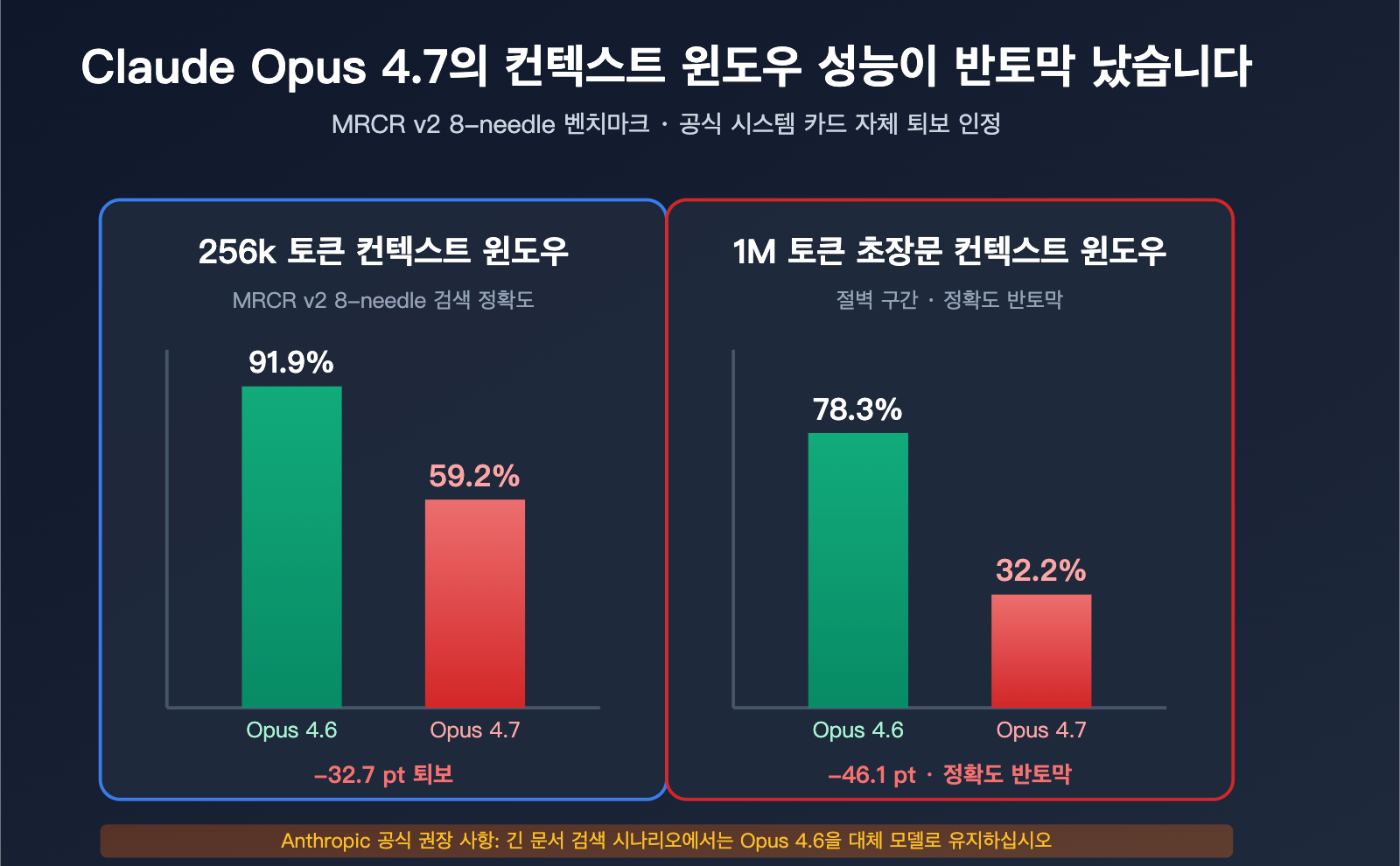
Claude Opus 4.7 긴 컨텍스트 퇴보의 공식적 증거
이 섹션에서는 Anthropic이 직접 공개한 데이터를 통해 퇴보 사실을 증명합니다.
MRCR v2 8-needle 벤치마크의 급격한 하락
MRCR v2(Multi-Round Coreference Resolution, version 2)는 업계에서 긴 컨텍스트 다중 바늘 검색 능력을 측정하는 표준 벤치마크입니다. 테스트 방식은 매우 긴 텍스트 안에 8개의 특정 사실을 숨겨두고, 모델이 이를 검색하여 재현하도록 하는 것입니다. 점수는 평균 일치율(%)입니다.
| 컨텍스트 길이 | Opus 4.6 | Opus 4.7 | 하락폭 |
|---|---|---|---|
| 256k Token | 91.9% | 59.2% | -32.7pt |
| 1M Token | 78.3% | 32.2% | -46.1pt |
이 수치들의 의미:
- 256k 컨텍스트에서 4.7의 다중 바늘 검색 정확도는 "거의 만점"에서 "낙제점"으로 떨어졌습니다.
- 1M 컨텍스트에서 4.7의 정확도는 반토막이 났으며, 3분의 1 수준에도 미치지 못합니다.
- 4.6은 이 벤치마크에서 4.7을 능가할 뿐만 아니라, 256k 범위에서 GPT-5.2마저 이겼습니다(Rohan Paul 공식 확인).
Rohan Paul은 X 플랫폼에서 가장 간결한 평가를 내렸습니다. "Opus 4.6 now takes the crown as the best long-context model." 즉, Opus 4.6이 2026년 현재 최고의 긴 컨텍스트 모델이라는 뜻입니다. 이 챔피언은 4.7도, GPT-5.4도 아닙니다.
Anthropic 시스템 카드의 자인
더욱 커뮤니티를 충격에 빠뜨린 것은 Anthropic이 Opus 4.7 시스템 카드에서 이 사실을 직접 인정했다는 점입니다. 시스템 카드 47페이지 원문:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
번역: Opus 4.6의 64k 확장 사고 모드가 긴 컨텍스트 다중 바늘 검색에서 4.7을 압도합니다. 긴 문서 검색에 의존하는 프로덕션 시스템의 경우, 4.6을 폴백(fallback) 옵션으로 유지할 것을 권장합니다.
이는 Anthropic이 공식 문서에서 사용자에게 "전면적인 마이그레이션"을 하지 말라고 명시한 첫 사례입니다. 이러한 이례적인 자인은 내부 평가에서도 이번 퇴보를 숨길 수 없었음을 의미합니다.
🎯 기술적 제언: 귀하의 비즈니스가 긴 문서 RAG나 대규모 코드베이스 검색과 관련이 있다면, APIYI(apiyi.com) 플랫폼을 통해 Claude Opus 4.6과 4.7의 호출 권한을 모두 유지하는 것을 권장합니다. 해당 플랫폼은 통합 API 인터페이스를 제공하여 모델 변경 시 파라미터 수정만으로 대응이 가능하며, 마이그레이션 기간 동안 빠른 A/B 테스트와 시나리오별 라우팅을 수행할 수 있습니다.
MRCR뿐만이 아닙니다: BrowseComp도 퇴보
MRCR 외에도 긴 컨텍스트 관련 벤치마크인 BrowseComp(심층 웹 조사 작업) 역시 퇴보를 보였습니다.
| 벤치마크 | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp는 "심층 조사 에이전트"의 성능을 측정합니다. 모델이 긴 컨텍스트 내에서 여러 정보원을 추적하고 교차 문서 종합 판단을 내릴 수 있어야 합니다. 4.7의 퇴보 폭이 MRCR만큼 극단적이지는 않지만, 리서치 에이전트를 운영하는 팀에게는 여전히 실질적인 부정적 신호입니다.
Claude Opus 4.7의 긴 컨텍스트 능력 저하에 대한 근본 원인
2026년의 새로운 플래그십 모델이 왜 긴 컨텍스트 처리 능력에서 크게 퇴보했을까요? 공식 시스템 카드와 커뮤니티 분석을 통해 세 가지 근본 원인을 정리해 보았습니다.
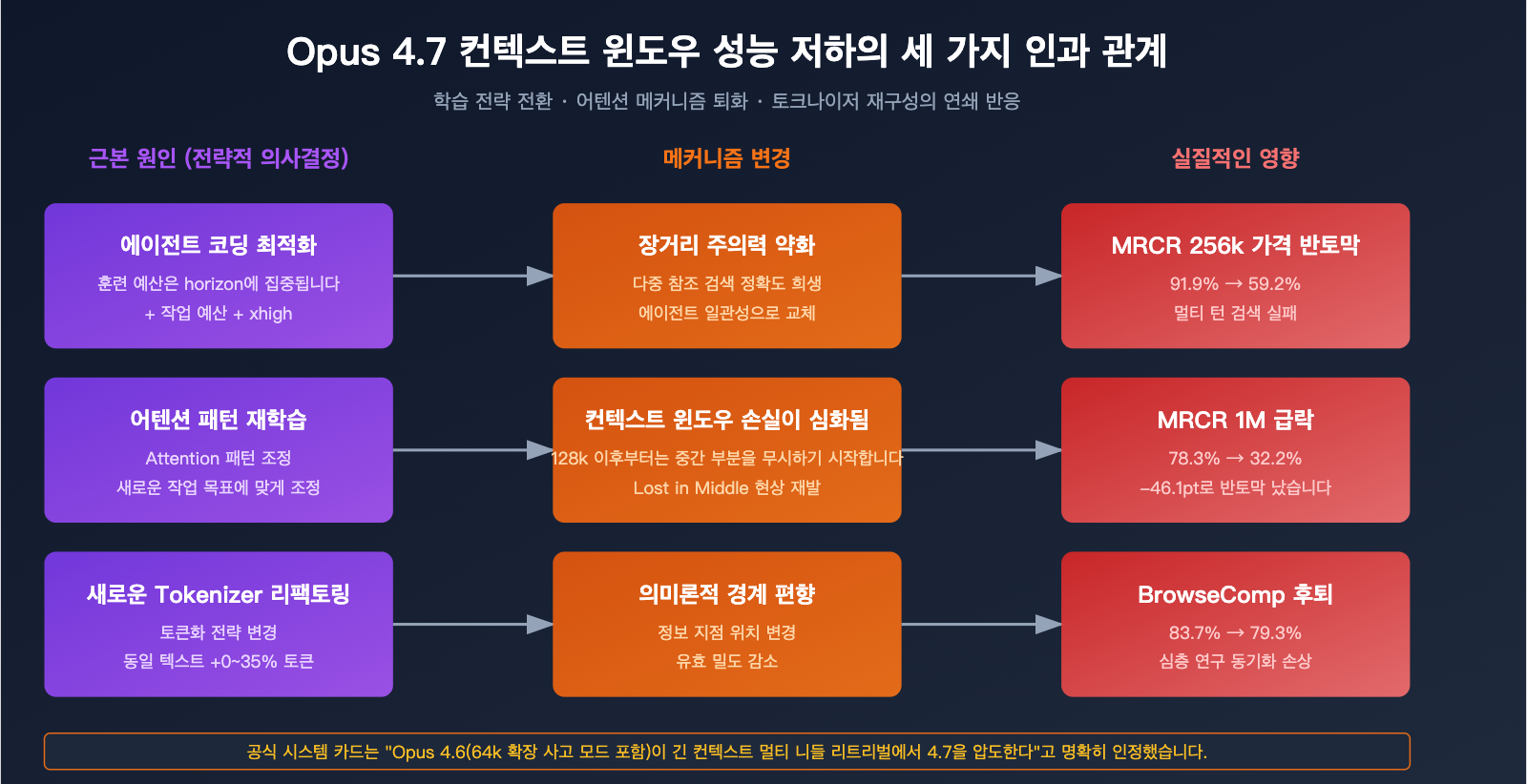
원인 1: '에이전트 코딩'을 위한 장거리 어텐션 희생
Opus 4.7의 핵심 설계 목표는 '장시간 실행되는 에이전트 코딩 워크플로우'입니다. 주의할 점은, 장시간 실행 ≠ 긴 컨텍스트 검색이라는 것입니다. Anthropic의 제품 언어에서 이 두 개념이 자주 혼용되지만, 모델 성능 차원에서는 엄연히 다른 두 가지 작업입니다.
| 능력 차원 | 장시간 실행 (Agent Horizon) | 긴 컨텍스트 검색 (Multi-needle Retrieval) |
|---|---|---|
| 핵심 요구 | 지속적인 의사결정 안정성 | 원거리 정보의 정밀한 위치 파악 |
| 주요 활용 | Claude Code 다중 루프 | RAG 검색, 장문 문서 질의응답 |
| 학습 목표 | 일관성 + 단계별 계획 | 어텐션 정밀도 + 세밀한 기억 |
| 4.7 성능 | ✓ 대폭 개선 | ✗ 심각한 퇴보 |
Opus 4.7은 첫 번째 차원에 많은 최적화 자원(작업 예산, xhigh 레벨, 더 정확한 지시 이행 등)을 투입했으며, 이러한 최적화가 장거리 어텐션 정밀도를 직간접적으로 희생시켰을 가능성이 높습니다.
원인 2: 'Lost in the Middle' 문제 심화
'Lost in the middle(중간 정보 유실)'은 긴 컨텍스트 모델에서 업계 공통으로 발생하는 고질병입니다. 정보가 긴 텍스트의 중간에 위치하면 모델이 이를 체계적으로 무시하거나 잘못 해석하는 현상이죠. Opus 4.6은 이 문제를 처리하는 데 업계 최고 수준이었지만, 4.7에서는 확실한 퇴보를 보였습니다.
232페이지 분량의 시스템 카드 분석 작성자의 원문을 확인해 보죠.
"Opus 4.6은 컨텍스트 윈도우를 안정적으로 활용합니다. 반면 Opus 4.7은 특히 128k 토큰을 넘어가면 중간 컨텍스트에 대한 '맹점' 증상이 나타나기 시작합니다."
즉, Opus 4.6은 전체 컨텍스트 윈도우를 신뢰성 있게 활용할 수 있지만, Opus 4.7은 128k 토큰 이후 명백한 '중간 정보 유실' 징후를 보인다는 것입니다.
이것이 4.7이 256k 벤치마크에서는 59.2%를 유지하다가 1M에서는 32.2%까지 떨어지는 이유를 설명해 줍니다. 컨텍스트가 길어질수록 중간 정보가 '누락'될 확률이 커지는 것이죠.
원인 3: 토크나이저(Tokenizer) 재구성이 바꾼 의미적 경계
Opus 4.7의 새로운 토크나이저는 '처리 효율성 개선'을 주 목적으로 하지만, 텍스트를 나누는 방식이 4.6과 호환되지 않습니다. 이는 다음을 의미합니다.
- 동일한 정보 포인트가 4.6과 4.7에서 차지하는 토큰 위치가 다름
- 학습 시 최적화된 '어텐션 패턴'을 다시 조정해야 함
- 단기적으로 토크나이저 변경은 4.7이 4.6의 검색 능력을 계승하는 데 보이지 않는 손실을 초래함
토크나이저 팽창(0~35%) 사실까지 결합해 보면, 동일한 긴 문서라도 4.7에서는 '유효 토큰 밀도'가 오히려 낮아진 셈입니다. 사용자는 1M 토큰의 정보를 입력했다고 생각하지만, 실제로는 더 잘게 쪼개진 토큰들로 인해 모델의 어텐션이 분산되는 결과를 초래합니다.
Claude Opus 4.7 긴 컨텍스트 실측 데이터 파노라마
이번 섹션에서는 4.7 버전과 4.6, 그리고 GPT-5.4의 긴 컨텍스트 관련 각종 벤치마크 데이터를 종합적으로 비교해 보겠습니다.
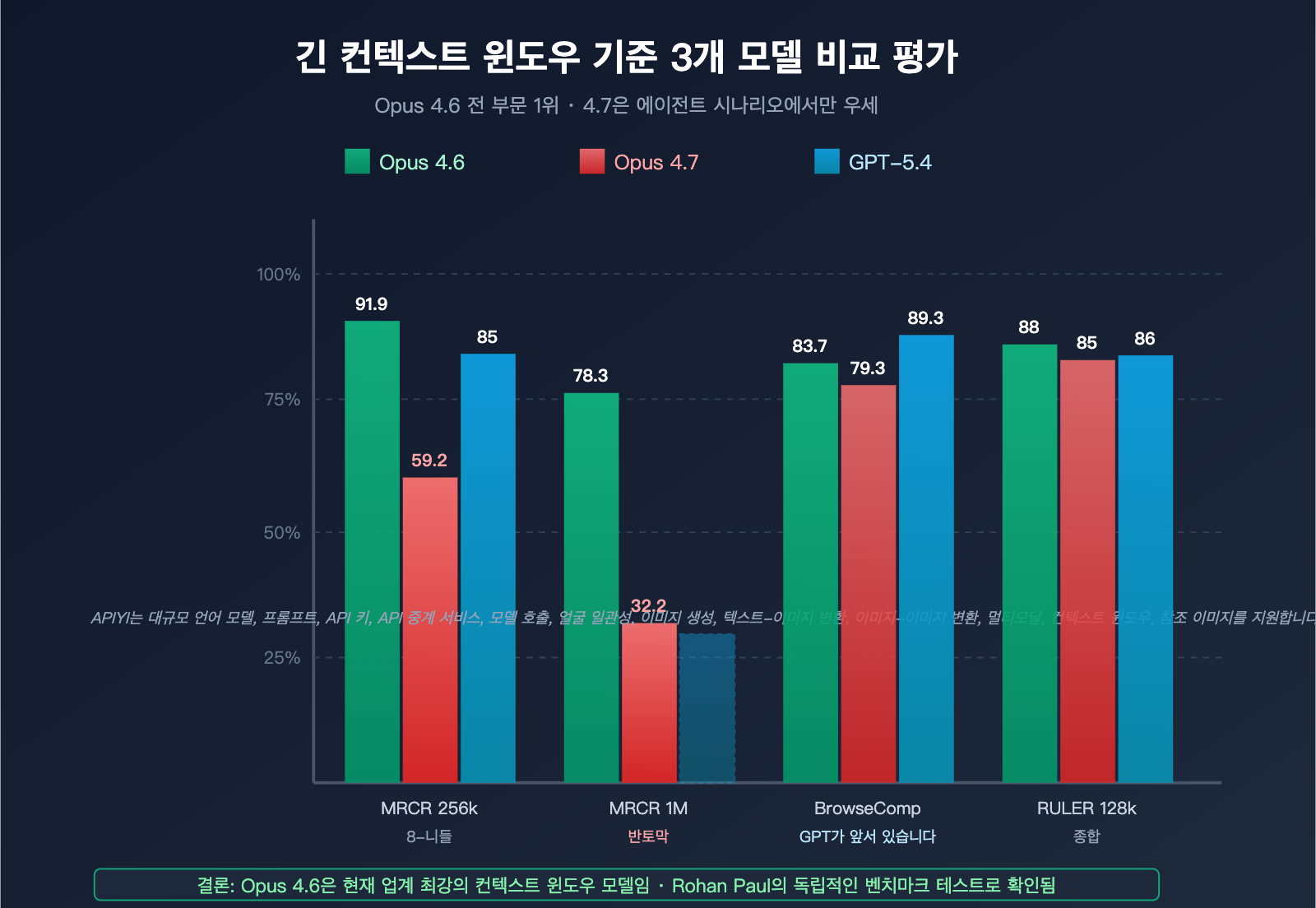
주요 긴 컨텍스트 벤치마크 파노라마
| 벤치마크 | 측정 차원 | Opus 4.6 | Opus 4.7 | GPT-5.4 | 1위 |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | 다중 검색 정확도 | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | 초장문 컨텍스트 검색 | 78.3% | 32.2% | 미공개 | Opus 4.6 |
| BrowseComp | 심층 연구 에이전트 | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | 종합 긴 컨텍스트 | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | 긴 문서 이해 | 높음 | 소폭 하락 | 동일 | Opus 4.6 |
| Needle-in-haystack @ 1M | 단일 검색 | 99%+ | ~95% | ~97% | 사실상 동점 |
표를 통해 알 수 있는 점:
- 단일 검색(긴 텍스트 속에 정보 1개를 숨기는 작업)에서는 세 모델 간의 격차가 크지 않습니다.
- 다중 검색(8개의 정보를 동시에 찾는 작업)에서는 Opus 4.6이 압도적인 우위를 점하고 있습니다.
- 1M급 초장문 컨텍스트 환경에서 Opus 4.7의 성능은 Opus 4.6 및 GPT-5.4보다 현저히 낮습니다.
실제 비즈니스 시나리오 매핑
벤치마크 데이터를 실제 업무 시나리오로 변환하면 다음과 같습니다.
| 비즈니스 시나리오 | 주요 능력 요구사항 | 추천 모델 | 이유 |
|---|---|---|---|
| 긴 계약서 텍스트 분석 | 다중 검색 + 정확한 위치 파악 | Opus 4.6 | MRCR 성능 우위 |
| 대규모 코드베이스 질의응답 | 파일 간 의미론적 검색 | Opus 4.6 | 128k+ 안정성 |
| 재무제표 분석 | 다중 표 + 다중 문단 종합 | Opus 4.6 | 다중 검색 능력 |
| 심층 웹 연구 | 웹 페이지 간 종합 판단 | GPT-5.4 Pro | BrowseComp 우위 |
| Claude Code 긴 루프 | 긴 작업의 안정적 수행 | Opus 4.7 | 에이전트 호라이즌 강점 |
| 짧은 문서 질의응답 | 정확하고 빠른 답변 | Opus 4.7 / 4.6 | 격차 미미 |
| 법률 조항 검색 | 정확한 매칭 + 인용 | Opus 4.6 | 높은 재현율 필요 |
💡 시나리오별 선택 가이드: 긴 문서 검색이나 RAG(검색 증강 생성) 시나리오가 포함된 업무라면, APIYI(apiyi.com) 플랫폼을 통해 업무에 맞춰 Opus 4.6과 4.7을 라우팅하는 것을 권장합니다. 해당 플랫폼은 주요 모델들의 통합 인터페이스 호출을 지원하여 시나리오에 따라 빠르게 모델을 전환할 수 있습니다.
컨텍스트 길이에 따른 영향 곡선
컨텍스트 길이가 길어짐에 따라 4.7 버전의 성능 저하 폭은 비선형적으로 확대되는 특징을 보입니다.
- 32k 이하: 4.7과 4.6 간의 차이가 거의 없음
- 32k – 128k: 4.7에서 미세한 성능 저하 시작(~5pt 이내)
- 128k – 256k: 4.7의 성능 저하가 눈에 띄게 확대(-15~30pt)
- 256k – 1M: 4.7은 "절벽 구간"에 진입하며, 다중 검색 기능이 사실상 무력화됨
이 곡선은 비즈니스 의사결정에 직접적인 지표가 됩니다. 컨텍스트 요구사항이 128k 미만이라면 4.7을 사용해도 무방하지만, 128k를 초과한다면 4.6을 유지하는 것을 강력히 권장합니다.
Claude Opus 4.7 긴 컨텍스트 성능 저하에 대한 3가지 대응 방안
성능 저하가 사실이라면, 마이그레이션의 핵심은 "할 것인가 말 것인가"가 아니라 "어떻게 할 것인가"입니다. 다음 세 가지 방안은 비용이 낮은 순서대로 나열되었으며, 단독으로 사용하거나 조합하여 활용할 수 있습니다.

방안 1: API 계층에서의 시나리오별 4.6 및 4.7 라우팅
가장 비용이 저렴하고 효과적인 방법입니다. 핵심 아이디어는 짧은 컨텍스트나 에이전트 코딩은 4.7을, 긴 컨텍스트/RAG/심층 연구는 4.6을 사용하도록 하는 것입니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""컨텍스트 길이와 작업 유형에 따라 모델 라우팅"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
다차원 라우팅 전략 코드 전체 보기
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""다차원 라우팅 결정"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="에이전트 장기 루프 시나리오, 4.7 horizon이 더 강력함",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} 토큰은 4.7 MRCR 안전 구역을 초과함",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="BrowseComp에서 4.6이 4.7보다 앞섬",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="MRCR 다중 지점 검색에서 4.6이 절대적 우위",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="짧은 컨텍스트 작업, 4.7의 종합 능력이 더 뛰어남",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""토큰 수 추정"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"라우팅 결정: {decision.model} (이유: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
실측 결과: 4.7의 에이전트 능력을 유지하면서도, 긴 컨텍스트 시나리오에서의 정확도가 4.6 수준으로 완전히 회복되었으며 마이그레이션 비용은 거의 제로에 가깝습니다.
🚀 통합 인터페이스 라우팅: APIYI(apiyi.com) 플랫폼을 통해 Claude 전 시리즈 모델의 온디맨드 라우팅을 구현하는 것을 추천합니다. 이 플랫폼은 Claude 공식 인터페이스와 완벽하게 호환되며, 여러 API 키를 관리할 필요 없이 다중 모델 라우팅의 아키텍처 복잡성을 낮춰줍니다.
방안 2: RAG 청킹 + 슬라이딩 윈도우
비즈니스가 4.7에 크게 의존하고 있다면(이미 Claude Code 워크플로우에 결합된 경우 등), "단일 컨텍스트 길이를 줄여" 4.7의 중간 부분 인식 문제를 회피할 수 있습니다.
핵심 전략:
- 긴 문서를 32k-64k 단위로 분할(4.7은 이 구간에서 정상적으로 작동)
- 벡터 검색을 사용하여 관련 Top-K 청크만 추출
- 각 청크에 대해 독립적으로 호출한 후 답변 병합
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""Opus 4.7에 최적화된 청킹 RAG"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "제공된 문서 조각을 바탕으로 질문에 답변하세요."},
{"role": "user", "content": f"문서: {chunk}\n질문: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"다음 답변들을 종합하여 답변하세요: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
적용 시나리오: 이미 Claude Code/Cursor가 결합되어 있으나 초장문 문서를 처리해야 하는 팀.
방안 3: 하이브리드 모델 아키텍처 (Opus 4.6 + Sonnet + GPT-5.4)
성숙한 제품의 경우 가장 안전한 방법은 3가지 모델 하이브리드 아키텍처입니다.
- Opus 4.6: 긴 컨텍스트 검색, RAG, 긴 계약서 분석
- Opus 4.7: 에이전트 코딩, Claude Code 루프, 고해상도 시각 처리
- GPT-5.4 Pro: 심층 웹 연구, BrowseComp 유형 작업
이 아키텍처는 "모든 것을 완벽하게 커버하는 모델은 없다"는 점을 인정하고, 조합을 통해 각 모델의 강점을 극대화합니다.
💰 비용 및 아키텍처 최적화: 하이브리드 모델 아키텍처의 전제 조건은 통합 API 액세스 계층입니다. APIYI(apiyi.com) 플랫폼을 사용하면 하나의 API 키로 Claude, GPT, Gemini 전 시리즈 모델을 호출할 수 있습니다. 이 플랫폼은 세밀한 호출 통계와 비용 분석을 제공하므로 다중 모델 아키텍처 도입에 이상적인 선택입니다.
Claude Opus 4.7 긴 컨텍스트 성능 FAQ
Q1: Anthropic 공식 발표에서는 4.7의 긴 컨텍스트가 더 안정적이라고 했는데, 왜 서드파티 데이터는 반대인가요?
이는 '장시간 실행(Long-running)'과 '긴 컨텍스트 검색(Long-context retrieval)'이라는 두 개념이 혼동되었기 때문입니다. Anthropic이 강조한 '안정성'은 에이전트 루프 내에서의 의사결정 일관성을 의미합니다. 즉, 긴 작업 도중 모델이 멈추거나 붕괴하지 않는다는 뜻이죠. 반면 '긴 컨텍스트 검색'은 먼 위치에 있는 정보를 정확히 찾아내는 능력을 말하며, 이 둘은 완전히 다른 차원의 능력입니다.
MRCR v2 8-needle 벤치마크는 후자의 능력을 직접 측정하는데, 이는 Anthropic 공식 시스템 카드에서도 Opus 4.6이 4.7보다 우수하다고 인정한 부분입니다. 따라서 두 주장은 모순되는 것이 아니라, 서로 다른 대상을 측정하고 있는 것입니다.
Q2: 제 긴 문서 RAG 애플리케이션을 즉시 4.6으로 롤백해야 할까요?
상황에 따라 다릅니다:
- 핵심 비즈니스가 128k 이상의 컨텍스트 검색에 의존하는 경우: 즉시 롤백하세요. MRCR 1M 정확도가 반토막 나는 것은 가벼운 문제가 아니며, 답변 품질에 직접적인 영향을 미칩니다.
- 컨텍스트가 32k~128k 사이인 경우: A/B 테스트를 권장합니다. 품질이 허용 가능한 수준이라면 4.7을 계속 사용해도 좋지만, 그렇지 않다면 4.6으로 전환하세요.
- 컨텍스트가 32k 이내인 경우: 두 모델 간의 차이가 크지 않으므로 비용, 지연 시간 등 다른 요소를 기준으로 결정하면 됩니다.
APIYI(apiyi.com) 플랫폼을 통해 A/B 테스트를 진행하는 것을 추천합니다. 해당 플랫폼은 Opus 4.6과 4.7의 병렬 호출 비교를 지원합니다.
Q3: Anthropic은 왜 이런 성능 저하를 허용했을까요?
공식 시스템 카드에서 공개된 정보를 보면, Anthropic은 **의도적인 능력 트레이드오프(Trade-off)**를 선택했습니다. 학습 예산을 에이전트 코딩과 시각적 이해에 집중하면서, 긴 컨텍스트 검색 정확도의 일부를 희생한 것입니다.
이러한 전략은 Anthropic의 현재 비즈니스 중심인 Claude Code와 기업용 에이전트 워크플로우를 강화하기 위한 것입니다. 하지만 긴 문서, RAG, 연구용 에이전트를 사용하는 사용자에게 이번 전략적 전환은 성능 저하를 의미합니다.
Anthropic이 시스템 카드에서 "4.6을 롤백용으로 유지하라"고 직접 권장한 것은, 어느 정도 **"이것은 버그가 아니라 전략이니, 사용자가 알아서 대응하라"**는 메시지로 해석할 수 있습니다.
Q4: MRCR 벤치마크의 성능 반토막이 실제 비즈니스에서 얼마나 심각한가요?
매우 심각합니다. MRCR 8-needle은 "방대한 문서에서 여러 핵심 사실을 찾아내는" 실제 상황을 시뮬레이션합니다. 예를 들면 다음과 같습니다:
- 계약서 검토: 모든 조항 제한 + 마감일 + 위반 조항 찾아내기
- 재무 보고서 분석: 100페이지 분량의 보고서에서 여러 재무 지표 위치 파악
- 코드베이스 질의응답: 여러 파일에 걸친 변수 정의 + 호출 체인 + 의존성 추적
MRCR 점수가 78.3%에서 32.2%로 떨어졌다는 것은, 이러한 작업에서 4.7이 평균적으로 핵심 정보의 2/3를 놓친다는 것을 의미합니다. 정확도가 중요한 비즈니스에서는 치명적인 퇴보입니다.
Q5: 짧은 컨텍스트 시나리오(< 32k)에서 4.7과 4.6의 실제 차이는 무엇인가요?
32k 이하의 짧은 컨텍스트 시나리오에서는 두 모델의 긴 컨텍스트 능력 차이를 거의 느낄 수 없습니다. 하지만 4.7은 다음과 같은 차원에서 여전히 우위에 있습니다:
- 더 강력한 코딩 능력: SWE-bench Verified +6.8pt
- 더 뛰어난 시각적 이해: 3.75MP 고해상도
- 더 정확한 도구 호출: MCP-Atlas 선도
- 더 높은 비용: 토크나이저 팽창 0~35%
따라서 짧은 컨텍스트 시나리오에서는 작업 유형에 따라 선택하면 됩니다. 코딩은 4.7, 글쓰기는 4.6을 선택하는 것이 가장 간단한 기준입니다.
Q6: 4.7의 긴 컨텍스트 성능을 4.6 수준으로 끌어올릴 방법이 있을까요?
현재 설정 수준에서 해결할 방법은 없습니다. reasoning-effort를 max로 설정해도 4.7의 MRCR 점수는 여전히 4.6보다 낮습니다.
실행 가능한 간접적인 대안은 두 가지입니다:
- RAG 청킹(Chunking): 긴 컨텍스트를 32k~64k 단위로 잘라 4.7이 '안전 구역'에서 작업하도록 합니다.
- 다중 모델 연결: 4.6으로 긴 컨텍스트를 검색하고, 검색 결과를 4.7에 전달하여 종합적인 추론을 수행하게 합니다.
두 번째 방법은 APIYI(apiyi.com) 플랫폼의 다중 모델 인터페이스를 통해 빠르게 구현할 수 있습니다. 이 플랫폼은 다양한 주류 모델의 통합 인터페이스 호출을 지원합니다.
Claude Opus 4.7 긴 컨텍스트 성능 저하 요약
Claude Opus 4.7의 긴 컨텍스트 성능 저하는 공식 데이터로 뒷받침되고, 커뮤니티에서 검증되었으며, 영향 범위가 명확한 실제 문제입니다. 핵심 결론은 다음과 같습니다:
- 공식 데이터 인정: MRCR v2 8-needle 성능이 256k 및 1M에서 각각 반토막 났으며, Anthropic은 4.6을 롤백용으로 유지할 것을 권장합니다.
- 근본 원인은 전략적 트레이드오프: 에이전트 코딩과 시각적 이해를 위해 긴 거리의 어텐션 정확도를 희생했습니다.
- 128k+ 시나리오에 집중된 영향: 짧은 컨텍스트에서는 4.7을 여전히 사용할 수 있지만, 128k를 넘어가면 성능 저하가 비선형적으로 증폭됩니다.
- Opus 4.6이 현재 가장 강력한 긴 컨텍스트 모델: Rohan Paul 등 주요 전문가들이 공통적으로 인정하는 결론이며, 심지어 GPT-5.2보다도 우수합니다.
- 최선의 대응은 시나리오별 라우팅: 긴 문서는 4.6, 코딩은 4.7, 심층 연구는 GPT-5.4 Pro를 고려하는 방식입니다.
사용자에게 필요한 올바른 태도는 "Anthropic이 수정해주길 기다리는 것"이 아닙니다. 이번 조정은 전략적인 결정이므로 단기간에 롤백되지 않을 것입니다. 대신 즉시 호출 계층에서 다중 모델 라우팅을 준비해야 합니다. 4.6을 긴 컨텍스트 시나리오의 기본 선택지로, 4.7을 본연의 강점인 에이전트 코딩 작업에 할당하세요.
이는 2026년 AI 산업의 새로운 트렌드와도 일치합니다. 단일 모델이 모든 시나리오를 커버하는 시대는 끝났습니다. 각 모델은 '특정 분야 전문화'를 향해 진화하고 있습니다. 사용자에게는 '가장 강력한 모델 하나를 선택하는 것'에서 '가장 합리적인 다중 모델 라우팅 시스템을 설계하는 것'으로의 전환이 요구됩니다.
APIYI(apiyi.com) 플랫폼을 통해 Claude 전체 시리즈 모델 호출을 통합 관리하는 것을 추천합니다. 이 플랫폼은 실시간 벤치마크 비교, 다중 모델 지능형 라우팅, 공식 API와 완벽하게 호환되는 인터페이스를 제공하여 Opus 4.7의 성능 저하 문제를 해결하는 실용적인 도구가 될 것입니다.
참고 자료
-
Anthropic Opus 4.7 시스템 카드: 공식 232페이지 분량의 시스템 카드
- 링크:
anthropic.com/news/claude-opus-4-7 - 설명: MRCR v2 전체 벤치마크 데이터 및 마이그레이션 제안 포함
- 링크:
-
Opus 4.7 시스템 카드 심층 분석: DEV Community 커뮤니티 분석
- 링크:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - 설명: 232페이지 분량의 시스템 카드를 개발자 관점에서 요약
- 링크:
-
Anthropic 마이그레이션 가이드: Opus 4.7 마이그레이션 가이드
- 링크:
platform.claude.com/docs/en/about-claude/models/migration-guide - 설명: 공식 마이그레이션 제안 및 긴 컨텍스트 윈도우 사용 시 주의사항
- 링크:
-
긴 컨텍스트 벤치마크 리더보드: 긴 컨텍스트 벤치마크 순위표
- 링크:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - 설명: MRCR, RULER, LongBench v2 비교 분석
- 링크:
-
Rohan Paul X 리뷰: Opus 4.6 긴 컨텍스트 챔피언 분석
- 링크:
x.com/rohanpaul_ai/status/2019545018051240059 - 설명: 독립적인 관찰자가 평가한 Opus 4.6의 긴 컨텍스트 강점
- 링크:
작성자: APIYI 기술팀
게시일: 2026-04-18
적용 모델: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
기술 교류: APIYI(apiyi.com)를 통해 다양한 모델의 테스트 크레딧을 받아보세요. 여러 컨텍스트 길이에 따른 검색 정확도 차이를 직접 확인하실 수 있습니다.