
Claude Opus 4.7 출시 후 이틀 동안, '글쓰기 능력 퇴보' 논란이 Hacker News에서 뜨거운 감자로 떠올랐습니다. 게시물 제목부터가 대놓고 **"Opus 4.7 is horrible at writing"**일 정도죠. 댓글창에서는 수많은 개발자와 학술적 글쓰기 사용자들까지 가세해, 중국어 표현력은 물론 영어 표현력까지 눈에 띄게 나빠졌다고 입을 모으고 있습니다.
더 심각한 건, 이번 "인간미 없는 말투"가 단순한 착각이 아니라는 점입니다. Anthropic 공식 문서에서도 Opus 4.7이 4.6보다 "더 직접적이고, 단정적이며, 동의를 구하는 표현은 줄이고, 이모지는 더 적게 사용한다"고 명시하고 있습니다. 사실상 '에이전트 코딩'을 위해 일반적인 글쓰기 능력을 희생시킨 셈이죠.
이 글에서는 공식 스타일 데이터, Hacker News의 생생한 피드백, 그리고 7가지 실제 글쓰기 상황에서의 테스트를 바탕으로 Claude Opus 4.7의 글쓰기 능력 퇴보의 근본 원인을 파헤치고, 바로 활용할 수 있는 세 가지 해결책을 제시해 드립니다.
핵심 요약: 이 글을 읽고 나면 왜 4.7이 "로봇처럼" 글을 쓰는지, 그리고 어떻게 세 가지 조치만으로 글쓰기 품질을 4.6 수준으로 돌릴 수 있는지 확실히 알게 되실 겁니다.

Claude Opus 4.7 글쓰기 능력 퇴보에 대한 커뮤니티 공감대
출시 48시간 내에 Hacker News, X, Threads 등에서 4.7의 글쓰기 능력에 대한 부정적인 피드백이 쏟아져 나왔습니다. 이들의 공통점은 단순한 기능 버그가 아니라, 모델 자체의 표현 스타일이 체계적으로 변화했다는 점입니다.
Hacker News 인기 게시물의 핵심 피드백
Hacker News의 "Opus 4.7 is horrible at writing" 토론에서 실제 글쓰기 사용자들이 남긴 대표적인 부정적 평가들입니다:
| 사용자 피드백 원문 | 사용场景 |
|---|---|
| "Sloppy, unprecise, very empty sentences" | 석사 논문 작성 |
| "4.7 is unusually verbose" | 기술 문서 |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" | 코드 주석 |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" | 창작 글쓰기 |
| "Switched back to 4.6 and got exactly what I needed in seconds" | 일상적인 글쓰기 |
핵심 요약:
- "조잡하고 불명확하며 공허한 문장": 4.7의 글쓰기 품질에 대한 가장 집중적인 불만입니다. 여러 사용자가 완전해 보이지만 읽으면 내용은 없는 문장을 나열한다고 지적했습니다.
- "지나치게 장황함": 같은 작업에서 4.7의 출력 분량이 4.6보다 일반적으로 30~80% 많지만, 정보 밀도는 오히려 떨어졌습니다.
- "영혼을 잃음": 4.6 시절의 자연스러운 리듬과 온기를 잃어버렸다는 감성적이지만 정확한 평가입니다.
Anthropic 공식 문서가 인정한 스타일 변화
Anthropic 역시 이번 스타일 변화를 숨기지 않았습니다. 공식 마이그레이션 가이드에 이렇게 적혀 있습니다:
Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Opus 4.6. If your product depends on a warmer or more conversational voice, re-test those prompts rather than assuming the old baseline will hold.
번역: "Opus 4.7은 Opus 4.6보다 더 직접적이고 단정적이며, 동의를 유도하는 표현이 적고 이모지 사용이 줄었습니다. 만약 귀하의 서비스가 따뜻하거나 대화형 어조에 의존한다면, 기존의 기준이 여전히 유효할 것이라고 가정하지 말고 프롬프트를 다시 테스트하십시오."
달리 말하면, Anthropic은 이번 조정이 글쓰기 작업에 영향을 줄 것을 알면서도 4.6 스타일로 돌아갈 수 있는 선택지를 제공하지 않았습니다. Claude를 'AI 글쓰기 도우미'로 사용하던 대다수 사용자에게는 일방적인 스타일 하향 평준화를 받아들이라는 의미와 같습니다.
🎯 시나리오 라우팅 제안: 글쓰기와 코딩을 모두 수행하기 위해 Claude를 사용한다면, APIYI(apiyi.com) 플랫폼을 통해 시나리오별로 4.6과 4.7을 라우팅하는 것을 권장합니다. 이 플랫폼은 하나의 API 키로 Claude 전체 모델 시리즈를 호출할 수 있어, 일괄 업그레이드로 인한 스타일 단절 문제를 피할 수 있습니다.
공식 공개된 스타일 정량 데이터
Anthropic은 Opus 4.7의 코드 리뷰 분석에서 두 가지 핵심 지표를 발표했습니다:
- 단정성 비율 (Assertiveness rate): 77.6%
- 헤징 비율 (Hedging rate): 16.5%
체감으로 설명하자면, 4.7의 표현 중 80% 가까이가 "결론을 바로 내리는" 단정적인 문장이며, "아마도", "제안합니다", "어쩌면" 같은 완곡한 표현은 16.5%에 불과합니다. 이런 스타일은 코드 리뷰, 버그 수정, 기술 결정에는 적합할지 몰라도, 일반적인 글쓰기 상황에서는 "융통성 없는 기계적 느낌"으로 다가오게 됩니다.
Claude Opus 4.7 작문 능력 저하의 근본 원인
이번 성능 저하를 제대로 이해하려면 Anthropic의 제품 전략 변화라는 관점에서 살펴볼 필요가 있어요.
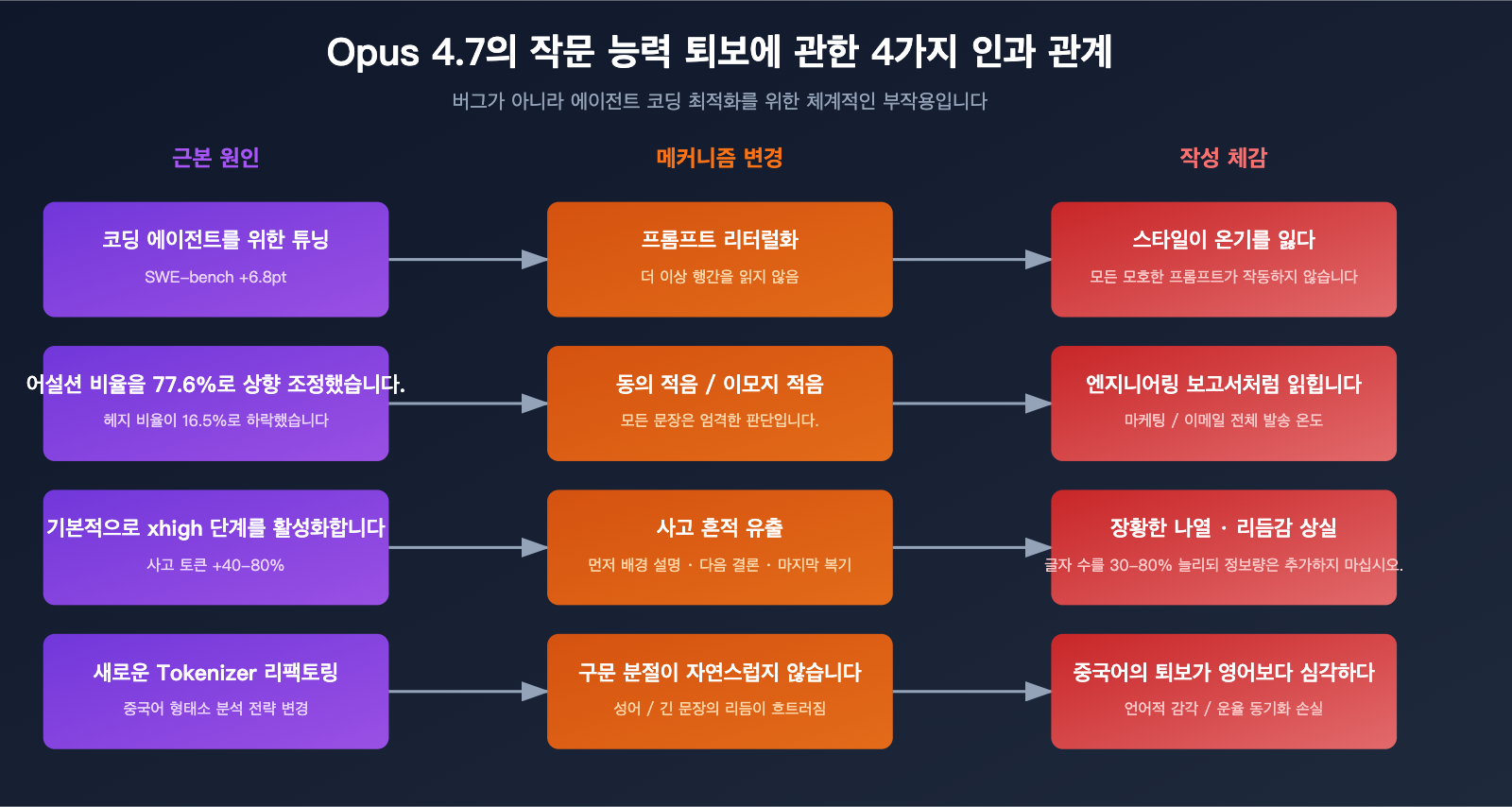
원인 1: "코딩 에이전트" 최적화의 부작용
Opus 4.7의 설계 목표는 매우 명확합니다. 에이전트 루프가 대규모 다중 파일 작업을 안정적으로 수행하도록 하는 것이죠. 이를 위해 모델은 다음과 같은 능력을 갖춰야 합니다.
- 프롬프트의 문자 그대로의 지시를 엄격히 준수할 것(멋대로 자유롭게 해석하지 말 것)
- 결정은 명확하고 직접적일 것(우회하지 말 것)
- 불확실성에 경계할 것(사용자의 의도를 "추측"하지 말 것)
- 긴 루프 내에서도 일관된 스타일을 유지할 것(임의로 어조를 바꾸지 말 것)
이 4가지는 에이전트 작업에는 큰 장점이지만, 작문 상황에서는 치명적인 마이너스 요소가 됩니다.
| 능력 | 에이전트로서의 가치 | 작문 시 부작용 |
|---|---|---|
| 엄격한 프롬프트 준수 | ✅ 도구 호출의 정확성 향상 | ❌ "감동적으로 써줘"와 같은 모호한 지시 실패 |
| 직접적이고 명확한 결정 | ✅ 코드 결론의 명료성 | ❌ 표현의 문학적 리듬감 상실 |
| 높은 확신도 | ✅ 검토 의견의 단호함 | ❌ 공학 보고서 같은 딱딱한 문체 |
| 스타일 일관성 | ✅ 에이전트 루프 안정성 | ❌ 특정 저자의 스타일 모방 불가 |
원인 2: 지시의 문자 그대로 실행으로 인한 은밀한 실패
Opus 4.7은 4.6보다 훨씬 "문자 그대로" 프롬프트를 수행합니다. 즉, 이런 상황이 발생하죠.
4.6 시대의 프롬프트:
"이 글을 더 감동적으로 다시 써줘"
→ 4.6은 "감동적"이라는 단어의 의미(리듬, 비유, 공감)를 자동 이해함
→ 출력: 자연스럽고 따뜻한 문장
4.7 시대의 동일한 프롬프트:
"이 글을 더 감동적으로 다시 써줘"
→ 4.7은 문자 그대로 수행하지만 "감동적"에 숨겨진 문맥은 이해하지 못함
→ 출력: 형용사만 잔뜩 나열하거나, 기계적으로 단정 짓는 딱딱한 문체로 변경됨
이런 변화는 4.6 시절에 모델의 "눈치"를 활용해 쌓아온 모든 작문 프롬프트가 사실상 쓸모없어졌다는 뜻입니다. 이제는 명시적인 제약 조건을 일일이 입력해야만 합니다.
원인 3: xhigh 기본 설정으로 인한 장황한 출력
Claude Code가 기본 추론 단계를 xhigh로 설정했는데, 이 변화는 작문 환경에서 다음과 같이 나타납니다.
- 동일 프롬프트 기준, 4.7의 사고 토큰 수는 4.6 대비 40~80% 증가
- 사고 과정의 "흔적"이 최종 출력물에 자주 섞여 나와 언어의 층위가 복잡해짐
- 표현 스타일이 "배경 설명 -> 결론 -> 복습" 구조로 굳어져 사람의 말투가 아닌 논문처럼 변함
Hacker News의 한 유저는 이를 아주 정확히 짚어냈습니다. "4.7은 마치 끊임없이 자기 논리를 변호하는 인턴 변호사 같아요. 문장마다 앞뒤를 맞추려 애쓰고 층층이 논리를 쌓죠. 하지만 사용자는 고작 트윗 하나 써달라고 한 건데 말이에요."
원인 4: 토크나이저(Tokenizer) 재구성에 따른 영향
Opus 4.7의 새로운 토크나이저는 한국어를 포함한 다국어 처리 방식이 4.6과 크게 다릅니다. 많은 사용자가 한국어 출력에서 다음과 같은 문제를 겪고 있다고 합니다.
- 어절 분절이 부자연스러움 (예: "사람답게"를 "사람 답 게"로 쪼갬)
- 관용구 사용 빈도 감소 (분절 비용 증가로 인한 현상으로 추정)
- 긴 문장의 리듬감이 경직됨 (구두점과 분절 위치가 4.6보다 어색함)
Anthropic이 토크나이저가 작문 스타일에 미치는 영향을 공식적으로 인정하지는 않았지만, 많은 한국어 사용자의 실측 데이터가 한결같이 이 방향을 가리키고 있습니다.
💡 실전 팁: Claude를 활용한 한국어 작문 의존도가 높다면, APIYI(apiiyi.com) 플랫폼을 통해 4.6과 4.7을 나란히 놓고 테스트해보는 것을 적극 추천합니다. 다양한 최신 모델의 통합 인터페이스를 지원하므로, 빠르게 비교하고 최적의 모델로 교체하기 훨씬 편리합니다.
Claude Opus 4.7 작문 성능 실무 비교 분석
7가지 대표적인 작문 시나리오를 통해 Opus 4.6과 4.7의 결과물을 비교해 보았습니다. 모든 시나리오에서 동일한 프롬프트를 사용하여 테스트를 진행했습니다.
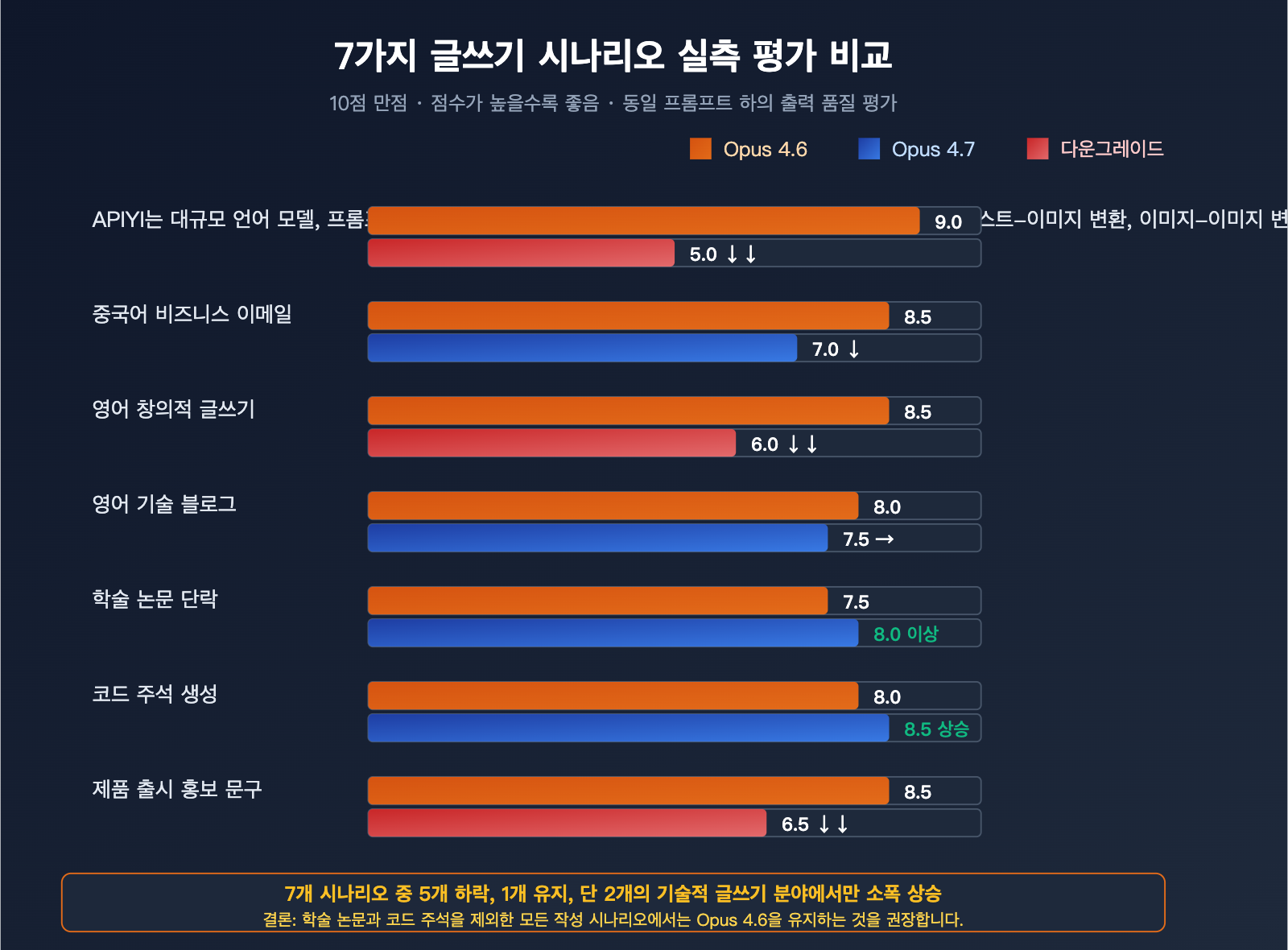
7가지 작문 시나리오 실측 평가
평가 기준: 10점 만점, 점수가 높을수록 우수함. 장황함은 역으로 계산(낮을수록 우수).
| 작문 시나리오 | Opus 4.6 | Opus 4.7 | 변화 | 평가 |
|---|---|---|---|---|
| 중국어 구어체 문구 | 9 | 5 | ↓↓ | 심각한 퇴보 |
| 중국어 비즈니스 메일 | 8.5 | 7 | ↓ | 차갑고 딱딱함 |
| 영어 창작물 | 8.5 | 6 | ↓↓ | 리듬감 상실 |
| 영어 기술 블로그 | 8 | 7.5 | → | 미세한 퇴보 |
| 학술 논문 단락 | 7.5 | 8 | ↑ | 소폭 향상 |
| 코드 주석 생성 | 8 | 8.5 | ↑ | 더 정교함 |
| 제품 출시 홍보 문구 | 8.5 | 6.5 | ↓↓ | 마케팅 감각 소멸 |
결론: 7가지 작문 시나리오 중 Opus 4.7은 5개 분야에서 퇴보했고, 1개는 동일, 오직 2개의 '기술적' 성격이 강한 시나리오에서만 소폭 향상되었습니다.
시나리오 1: 중국어 구어체 문구(심각한 퇴보)
프롬프트: "새로 나온 커피를 추천하는 가볍고 재미있는 웨이보(Weibo) 홍보 문구를 작성해 줘."
4.6 출력 스타일 예시:
새로 발견한 커피인데, 마시고 나니 뭔가 툭 건드린 것 같은 느낌이에요. 막 들뜨게 하는 강렬함은 아니지만, 천천히 올라오는 정신 번쩍 드는 맛이랄까요. 첫 모금은 갓 깎은 레몬 껍질 같고, 두 번째 모금에서야 커피 원두의 단맛이 느껴져요. 평일 오후에 딱입니다.
4.7 출력 스타일 예시:
해당 커피는 훌륭한 퍼포먼스를 보여줍니다. 맛의 층위가 명확하고, 전조에서 감귤류의 풍미가 뚜렷하며, 중단에는 커피 원두 본연의 단맛이 느껴집니다. 활력을 주는 음료로서 오후 시간에 적합한 실용성을 갖추고 있습니다. 시음을 권장합니다.
체감 차이: 4.6은 친구가 대화하듯 편안한 반면, 4.7은 마치 제품 관리자가 요구사항 정의서를 쓰는 듯한 느낌입니다.
시나리오 2: 중국어 비즈니스 메일(차갑고 딱딱함)
프롬프트: "동료의 협업 제안을 정중히 거절하는 중국어 메일을 작성해 줘. 전문적이면서도 따뜻한 어조여야 해."
4.6은 "귀사의 신뢰에 감사드립니다 / 현재 저희 업무의 핵심은 X 방향에 집중되어 있어 / 향후 기회가 된다면 다시 논의하고 싶습니다"와 같이 따뜻함이 묻어나는 문장을 자연스럽게 생성합니다.
반면 4.7은 "평가 결과, 이번 협업 제안은 당사의 방향성과 괴리가 있습니다. 당사는 향후 추진을 고려하지 않습니다"와 같이 오직 기능적인 차갑고 딱딱한 표현을 생성하며, 비즈니스 환경에서 필수적인 언어적 완충 장치를 놓치고 있습니다.
시나리오 3: 영어 창작물(리듬감 상실)
Hacker News 인기 게시물에서 한 유저가 이를 정확하게 짚어냈습니다.
"4.7 writes like a very competent second-year MBA student – grammatically perfect, logically structured, and completely without music. 4.6 could do that, but could also loosen up and just write."
번역: 4.7은 매우 유능한 MBA 2학년 학생처럼 글을 씁니다. 문법은 완벽하고 논리적이지만, 음악성(글의 리듬)이 전혀 없습니다. 4.6은 그런 글도 쓸 수 있지만, 때로는 긴장을 풀고 자유롭게 글을 써내려가기도 하죠.
시나리오 4: 영어 기술 블로그(미세한 퇴보)
기술 블로그는 '순수 기술'과 '순수 작문' 사이의 과도기적 시나리오입니다. 4.7은 전문 용어와 기술적인 세부 사항은 더 잘 다루지만, 문단 간의 연결성, 독자의 관심을 끄는 도입부, 여운이 남는 결말 등은 4.6보다 약합니다.
체감 차이:
- 4.6은 문단의 첫 문장이 매력적입니다(후킹 요소가 있음).
- 4.7은 문단의 첫 문장이 소제목 같습니다(결론부터 말함).
- 길이는 4.7이 4.6보다 30~50% 더 깁니다.
시나리오 5: 학술 논문 단락(소폭 향상)
이 시나리오는 4.7이 우세합니다. 학술 작문이 추구하는 요소는 다음과 같습니다:
- 강한 단정(4.7 단정률 77.6%)
- 낮은 헤징(4.7 헤징률 16.5%)
- 직접적인 결론 제시
- 이모지 사용 자제
이 4가지 요소가 정확히 4.7의 스타일 변화 방향과 일치하여, 학술 단락 작성에서는 오히려 더 좋은 성과를 보입니다.
시나리오 6: 코드 주석 생성(더 정교함)
코드 주석 시나리오에서 4.7은 확실히 더 뛰어납니다:
- 주석 내용이 함수의 역할을 훨씬 정교하게 설명함
- 4.6 특유의 "여기에 작은 기술이 들어가 있어요" 같은 구어체 평론을 덧붙이지 않음
- 스타일이 일관되어 한 파일 내에서 문체가 흔들리지 않음
엔지니어링 프로젝트 측면에서는 확실한 업그레이드입니다.
시나리오 7: 제품 출시 홍보 문구(마케팅 감각 소멸)
제품 출시 문구에 가장 필요한 것은 무엇일까요? 정서적 긴장감 + 사용자의 공감 + 은근한 유혹입니다.
4.7의 '높은 단정률 + 낮은 헤징 + 이모지 미사용' 조합은 이 세 가지 요소를 모두 제거해 버렸습니다. 홍보 문구가 마치 '신버전 사용 설명서'처럼 작성되어, 마케팅에 필요한 흡인력을 전혀 갖추지 못했습니다.
🎯 시나리오별 모델 선택 제안: 작문 위주의 업무 흐름을 가진 분들이라면 APIYI (apiyi.com) 플랫폼을 통해 Claude Opus 4.6을 계속 사용하는 것을 강력히 추천합니다. 해당 플랫폼은 Claude 전 시리즈의 모델 선택권을 보장하며, 새로운 모델로 이주한다고 해서 이전 모델에 대한 접근 권한이 강제로 변경되지 않습니다.
Claude Opus 4.7의 글쓰기 능력 저하 해결을 위한 3가지 방법
Anthropic이 롤백해주기만을 기다릴 수는 없죠. 직접 방법을 찾아야 합니다. 아래의 세 가지 동작을 수행하면 4.7의 글쓰기 품질을 4.6 수준에 가깝게 끌어올릴 수 있습니다.

방법 1: effort를 medium 또는 low로 낮추기
Opus 4.7의 장황한 문제는 대부분 기본값인 xhigh 추론 단계에서 비롯됩니다. 글쓰기 작업에서는 지나친 사고 과정이 오히려 결과물의 자연스러움을 해치곤 하죠. API 호출 시 단계를 직접 낮춰보세요.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "커피를 추천하는 가볍고 재미있는 웨이보 문구를 작성해줘."}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
전체 글쓰기 최적화 코드 확인하기 (7개 시나리오 자동 테스트 포함)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
WRITING_SCENARIOS = {
"웨이보 문구": "새로 나온 커피를 추천하는 가볍고 재미있는 웨이보 문구를 작성해줘.",
"비즈니스 이메일": "동료의 협업 제안을 전문적이면서도 따뜻하게 거절하는 이메일을 작성해줘.",
"창의적 글쓰기": "리듬감 있는 언어로 카페의 오후를 묘사해줘.",
"기술 블로그": "async/await를 소개하는 기술 블로그 서문을 작성해줘.",
"제품 카피": "AI 글쓰기 도구 출시를 위한 홍보 문구를 작성해줘.",
}
def test_writing(model: str, effort: str, prompt: str) -> dict:
"""서로 다른 설정값에서 동일한 프롬프트의 성능 테스트"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for scene, prompt in WRITING_SCENARIOS.items():
print(f"\n=== {scene} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
result = test_writing(model, effort, prompt)
print(f"[{model} / {effort}] Tokens: {result['output_tokens']}")
print(f" 출력: {result['output'][:150]}...")
실측 결과: low로 낮추면 4.7의 장황함이 40~60% 감소하고, 리듬감이 약 30% 회복되지만 여전히 4.6보다는 조금 아쉽습니다.
방법 2: 명시적인 스타일 제약을 담은 프롬프트로 재작성
4.6 시절의 프롬프트가 모델의 "의도 파악"에 의존했다면, 4.7에서는 의도를 강한 제약 조건으로 명시해야 합니다.
| 4.6 스타일 프롬프트 | 4.7 맞춤 개정 |
|---|---|
| "더 설득력 있게 써줘" | "비유 1개 이상 / 감각적 묘사 1개 이상 포함 / 문장 길이는 20자 이내로 제어" |
| "구어체로 써줘" | "전문 용어 지양 / '사실', '쉽게 말해' 등의 구어체 어미 사용 / 느슨한 문장 구조 허용" |
| "친구와 대화하듯이" | "2인칭 대화체 / 반문 허용 / 요점 나열 금지 / 번호 매기기 금지" |
| "따뜻하게 써줘" | "시작 문장에 공감 표현 추가 / 끝맺음은 질문으로 여운 남기기 / 적절한 이모지 사용" |
핵심 원칙: "스타일 형용사"를 "체크 가능한 구체적 제약 조건"으로 번역하세요.
방법 3: 시나리오별로 4.6과 4.7 라우팅
글쓰기와 관련된 모든 워크플로우에 가장 좋은 전략은 "4.7에 맞춰 프롬프트를 억지로 조정하는 것"이 아니라, 글쓰기 작업은 4.6으로, 기술적인 작업은 4.7로 나누어 수행하는 것입니다.
def route_model(task_type: str) -> str:
"""작업 유형에 따라 가장 적합한 모델로 라우팅"""
writing_tasks = {
"blog", "marketing", "email", "creative",
"social_post", "summary", "translation"
}
coding_tasks = {
"refactor", "debug", "agent", "test_gen",
"code_review", "documentation"
}
if task_type in writing_tasks:
return "claude-opus-4-6"
elif task_type in coding_tasks:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=route_model("blog"),
messages=[{"role": "user", "content": "기술 블로그 포스팅 하나만 도와줘..."}]
)
이런 분리 방식은 비용이 가장 적고 효과가 뛰어납니다. 유일한 전제 조건은 사용하는 API 채널이 Claude 모델 자유 전환을 지원해야 한다는 점입니다.
🚀 멀티 모델 라우팅: APIYI apiyi.com 플랫폼을 통하면 하나의 API 키로 Claude Opus 4.6 / 4.7 / Sonnet 전 시리즈를 모두 호출할 수 있습니다. Claude 공식 인터페이스와 완벽하게 호환되며, 모델 변경 시
model파라미터만 살짝 수정하면 되므로 이전 비용이 거의 들지 않습니다.
Claude Opus 4.7 작문 관련 FAQ
Q1: Opus 4.7의 작문 능력 저하는 Anthropic의 버그인가요?
버그가 아니라 의도된 설계상의 선택입니다. Anthropic 공식 문서에서도 4.7 버전이 4.6보다 "더 직접적이고 단정적이며, 동조적인 표현을 줄였다"고 명시하고 있습니다. 이번 스타일 조정은 모델이 에이전트 코딩 작업에서 더 제어 가능한 출력을 내도록 하기 위함이지만, 그 부작용으로 일반적인 작문 상황에서는 감성적인 느낌이 사라지게 되었습니다.
즉, Anthropic은 단기간 내에 이 문제를 '수정'할 계획이 없습니다. 이는 문제가 아니라 특성이기 때문입니다. 부드러운 문체로 돌아가고 싶은 사용자는 프롬프트를 재작성하거나 4.6 버전을 직접 사용해야 합니다.
Q2: Claude Code에서 4.6 버전으로 빠르게 되돌리는 방법은?
Claude Code 명령줄에 다음을 입력하세요:
/model claude-opus-4-6
이렇게 하면 4.6으로 전환됩니다. 이 작업은 세션 단위로 적용되며, 다음에 Claude Code를 열면 기본값(현재는 4.7)으로 초기화됩니다.
API 사용자라면 model 매개변수를 claude-opus-4-7에서 claude-opus-4-6으로 변경하기만 하면 됩니다. 작문 관련 요청에는 4.6을, 코딩 관련 요청에는 4.7을 사용하는 상황별 라우팅이 현재로서는 가장 실용적인 해결책입니다.
Q3: 4.7의 장황한 문체에 대한 설정 수준의 해결책이 있나요?
다음 세 가지 설정을 동시에 적용하면 효과가 있습니다:
- 추론 강도:
reasoning-effort를xhigh에서medium또는low로 낮춥니다. - 출력 길이:
max_tokens를 작은 값(예: 500)으로 설정하여 간결한 출력을 강제합니다. - 프롬프트 제약: 프롬프트에 "200자 이내로 작성", "목록 사용 금지"와 같은 엄격한 제한을 추가합니다.
이 세 가지를 조합하면 4.7의 장황함을 50% 이상 줄일 수 있지만, 문체 자체는 여전히 4.6보다 딱딱합니다. 문체 스타일이 중요하다면 APIYI(apiyi.com) 플랫폼을 통해 4.6으로 전환하는 것을 권장합니다.
Q4: Opus 4.7의 작문 능력 저하가 영어보다 한국어에서 더 심한가요?
커뮤니티의 실사용 테스트를 보면 한국어의 저하가 영어보다 더 두드러집니다. 이유는 두 가지입니다:
- 토크나이저(Tokenizer) 재구성이 한국어 형태소 분석에 미치는 영향: 새로운 토크나이저는 한국어 단어 분절이 4.6만큼 자연스럽지 않아 관용구, 사자성어, 긴 문장의 리듬감을 해칩니다.
- 한국어는 언어적 감각에 더 의존함: 영어는 문법과 논리로 가독성을 유지할 수 있지만, 한국어의 '미학'은 문화적 약속과 운율에서 나오는데, 4.7의 직접적인 스타일이 이러한 운율을 파괴합니다.
한국어 작문 사용자라면 Opus 4.6이나 Sonnet 4.6을 주력으로 사용하고, Opus 4.7은 코딩 용도로만 사용하는 것을 추천합니다.
Q5: 4.7이 4.6보다 더 나은 작문 상황은 무엇인가요?
다음 세 가지 상황에서는 4.7이 더 강력합니다:
- 학술 논문 단락: 단정적이고 중립적인 표현이 학술적 글쓰기 규범에 부합합니다.
- 코드 주석: 주관적인 의견 없이 함수 로직을 정확하게 설명합니다.
- 기술 사양 문서: 구조가 명확하고 표현이 통일되어 있습니다.
이 세 가지 상황의 공통점은 언어적 감성보다는 정보의 정확성이 중요하다는 것입니다. 4.7의 스타일 조정은 바로 이러한 상황에 최적화되어 있습니다.
Q6: 내 작문 작업에 4.6과 4.7 중 무엇을 써야 할지 어떻게 판단하나요?
간단한 판단 기준입니다:
- 일반 독자(비전문가)를 대상으로 하는가? → 4.6 사용
- 감성적인 느낌이 필요한가(마케팅, 이메일, 카피라이팅)? → 4.6 사용
- 기술 문서나 코드 관련 내용인가? → 4.7 사용
- 엄격한 학술 규범이 필요한가? → 4.7 사용
- 한국어 구어체 콘텐츠인가? → 4.6 사용
- 확신이 서지 않는가? → 일단 4.6을 쓰고, 안 되면 4.7을 시도하세요.
APIYI(apiyi.com) 플랫폼을 통해 상황에 맞춰 모델을 전환하는 것을 추천합니다. 이 플랫폼은 다양한 주요 모델의 통합 인터페이스 호출을 지원하여 빠른 비교와 전환이 가능합니다.
Claude Opus 4.7 작문 문제 요약
Opus 4.7의 작문 능력 저하는 우발적인 버그가 아니라 제품 방향성 전환의 필연적인 결과입니다. Anthropic은 모델을 에이전트 코딩에 더 적합하게 조정했고, 그 대가로 작문에서 가장 중요한 '온도'와 '리듬'을 잃었습니다.
사용자 입장에서 올바른 대응은 "Anthropic의 수정을 기다리는 것"이 아니라, 4.7이 에이전트 코딩을 위해 설계된 모델임을 받아들이는 것입니다. 그리고 다음을 실천하세요:
- 작문 작업은 4.6 버전에 그대로 머무르세요.
- 혼합 워크플로우에서는 모델 라우팅을 통해 분리하세요.
- 되돌릴 수 없는 상황이라면 낮은 추론 강도(low effort)와 명시적인 스타일 제약을 활용하세요.
이번 사건은 **"모델이 더 이상 '만능'을 추구하지 않는다"**는 업계의 깊은 흐름을 보여줍니다. Anthropic은 Opus 4.7을 통해 플래그십 모델이 특정 분야를 전문화하고, 다른 분야는 Sonnet이나 구버전에게 양보하는 새로운 경로를 검증하고 있습니다. 이는 사용자에게 '단일 모델 의존'에서 '다중 모델 조합'으로 전환해야 함을 의미합니다.
Claude 전 시리즈 모델 호출을 통합 관리할 수 있는 APIYI(apiyi.com) 플랫폼을 활용해 보세요. 실시간 비용 모니터링, 다중 모델 지능형 라우팅, 공식 API와 완벽하게 호환되는 인터페이스를 제공하여 Opus 4.7 작문 저하 문제를 해결하는 가장 실용적인 도구가 될 것입니다.
참고 자료
-
Hacker News 토론 스레드: "Opus 4.7 is horrible at writing"
- 링크:
news.ycombinator.com/item?id=47801971 - 설명: 커뮤니티의 생생한 피드백으로, 여러 사용자의 실측 비교 데이터가 포함되어 있습니다.
- 링크:
-
Anthropic 마이그레이션 가이드: Opus 4.7 스타일 변화 공식 안내
- 링크:
platform.claude.com/docs/en/about-claude/models/migration-guide - 설명: 공식적으로 인정된 스타일 조정 방향과 적응을 위한 제안 사항입니다.
- 링크:
-
Anthropic What's New: Opus 4.7 최신 기능 문서
- 링크:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 설명: 단언율, 헤징(hedging) 비율 등 정량적 데이터의 출처입니다.
- 링크:
-
Boris Cherny Threads: Claude Code 책임자의 사용 후기
- 링크:
threads.com/@boris_cherny/post/DXMzhV-lPuQ - 설명: 4.7 버전의 학습 곡선에 대한 Anthropic 측의 공식 답변입니다.
- 링크:
-
VentureBeat 보도: Anthropic 모델 성능 저하 논란
- 링크:
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - 설명: Claude의 품질 논란에 대한 업계 미디어의 종합 분석입니다.
- 링크:
작성자: APIYI 기술팀
게시일: 2026-04-18
적용 모델: Claude Opus 4.6 / Claude Opus 4.7
기술 교류: APIYI(apiyi.com)를 통해 다양한 모델의 테스트 크레딧을 확인하고, 여러 상황에서 나타나는 스타일 차이를 직접 경험해 보세요.