
海外の熟練プログラマーたちが Anthropic の 232 ページに及ぶ公式システムカードを徹底的に分析した結果、結論は一致しました。それは、Claude Opus 4.7 の長文コンテキスト処理能力が 4.6 と比較して著しく低下しているという事実です。
この結論は、Anthropic の公式ブログにある「Opus 4.7 は、我々がテストしたどのモデルよりも一貫した長文コンテキスト性能を発揮した」という記述と鋭く対立しています。真のデータはどこにあるのでしょうか?それは、彼ら自身が公開したシステムカードの中にあります。MRCR v2 8-needle ベンチマークにおいて、1M コンテキストでの Opus 4.6 のスコアは 78.3% でしたが、Opus 4.7 はわずか 32.2% でした。精度は低下したのではなく、半減したのです。
さらにコミュニティを騒然とさせたのは、Anthropic がシステムカード内で「Opus 4.6 の 64k extended-thinking モードは、長文コンテキストのマルチニードル(多点)検索タスクにおいて 4.7 を圧倒している」と認めたことです。この一文は Hacker News、X、Reddit のベテランプログラマーたちの間で繰り返し引用され、「Opus 4.7 の長文コンテキスト退化」という共通認識を裏付ける公式の証拠となりました。
本記事では、Anthropic の公式システムカード、第三者による独立した横断評価(X の Rohan Paul 氏、DEV Community の 232 ページにわたるシステムカード解説)、およびプログラマーコミュニティからの一次情報を基に、Claude Opus 4.7 の長文コンテキスト能力が低下した理由と、その対策を深く掘り下げます。
核心的価値: 本記事を読めば、どの長文コンテキストシナリオで 4.6 を維持すべきか、どのシナリオなら 4.7 が使えるか、そして API 呼び出しレイヤーでどのようにシナリオ別のルーティングを行うべきかが明確になります。
Claude Opus 4.7 の長文コンテキスト退化に関する公式の裏付け
このセクションでは、Anthropic 自身が公開したデータを用いて、退化の事実を証明します。
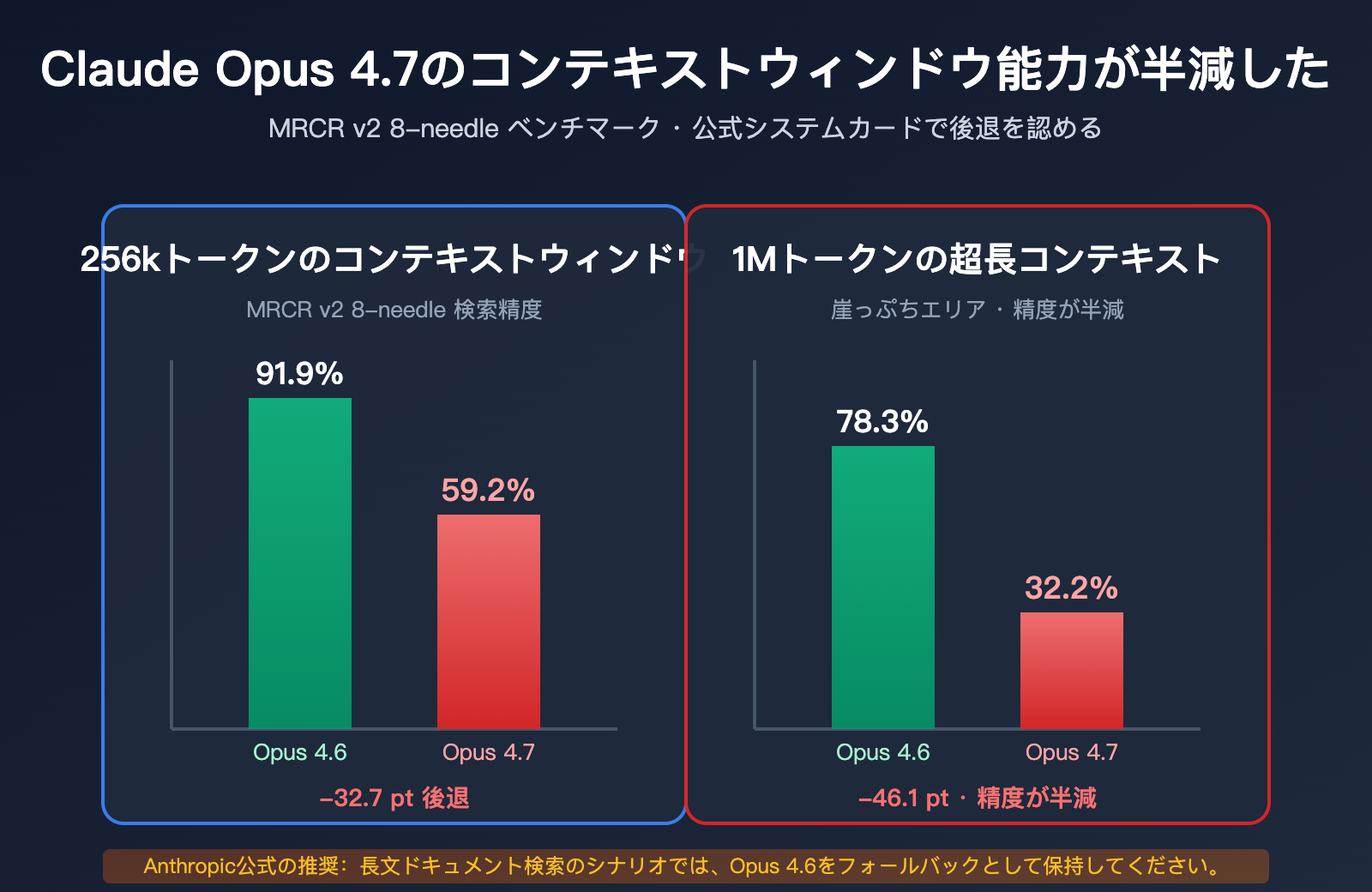
MRCR v2 8-needle ベンチマークにおける急激な低下
MRCR v2 (Multi-Round Coreference Resolution, version 2) は、長文コンテキストにおけるマルチニードル(多点)検索能力を測定するための業界標準ベンチマークです。テスト方法は、非常に長いテキストの中に 8 つの特定の事実を埋め込み、モデルにそれらを検索・再現させるというものです。スコアは平均一致率(%)で示されます。
| コンテキスト長 | Opus 4.6 | Opus 4.7 | 低下幅 |
|---|---|---|---|
| 256k トークン | 91.9% | 59.2% | -32.7pt |
| 1M トークン | 78.3% | 32.2% | -46.1pt |
これらの数値が意味すること:
- 256k コンテキストにおいて、4.7 のマルチニードル検索精度は「ほぼ満点」から「不合格」レベルまで低下しました。
- 1M コンテキストにおいて、4.7 の精度は半分以下にまで落ち込み、3分の1にも満たない結果となりました。
- 4.6 はこのベンチマークにおいて 4.7 を上回るだけでなく、256k の範囲では GPT-5.2 にも勝利しています(Rohan Paul 氏の公式確認による)。
Rohan Paul 氏は X プラットフォームで最も簡潔な判断を下しています:「Opus 4.6 now takes the crown as the best long-context model.(Opus 4.6 が最高の長文コンテキストモデルの座を奪還した)」。つまり、2026 年現在、最高の長文コンテキストモデルは 4.7 でも GPT-5.4 でもなく、Opus 4.6 であるということです。
Anthropic システムカードによる自認
コミュニティをさらに震撼させたのは、Anthropic が Opus 4.7 のシステムカード内で、この件を自ら認めているという点です。システムカードの 47 ページにはこう記されています:
"Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval. For production systems on long-document retrieval, we recommend keeping 4.6 available as a fallback."
翻訳:「64k 拡張思考モードを備えた Opus 4.6 は、長文コンテキストのマルチニードル検索において 4.7 を圧倒している。長文ドキュメント検索に依存する本番システムにおいては、4.6 をフォールバック(代替)として利用可能な状態にしておくことを推奨する。」
Anthropic が公式ドキュメントでユーザーに対し「完全な移行は控えるように」と明言したのはこれが初めてです。このような異例の自認は、内部評価においても今回の退化を隠しきれなかったことを示しています。
🎯 技術的アドバイス: もしあなたのビジネスが長文ドキュメントの RAG や大規模なコードベースの検索に関わるものであれば、APIYI (apiyi.com) プラットフォームを通じて Claude Opus 4.6 と 4.7 の両方の呼び出し権限を保持しておくことを推奨します。同プラットフォームは統一された API インターフェースを提供しており、モデルの切り替えはパラメータを変更するだけで済みます。移行期間中、迅速に A/B テストを行い、シナリオに応じたルーティングが可能です。
MRCR だけではない:BrowseComp も退化
MRCR 以外にも、長文コンテキストに関連する別のベンチマークである BrowseComp(高度な Web リサーチタスク)でも退化が見られます:
| ベンチマーク | Opus 4.6 | Opus 4.7 | GPT-5.4 Pro |
|---|---|---|---|
| BrowseComp | 83.7% | 79.3% | 89.3% |
BrowseComp は「高度なリサーチエージェント」の性能を測定するもので、モデルが長文コンテキスト内で複数の情報源を追跡し、ドキュメントを横断して総合的な判断を下す能力が求められます。4.7 の退化幅は MRCR ほど極端ではありませんが、リサーチエージェントを開発するチームにとっては、依然として実質的なマイナスシグナルと言えます。
Claude Opus 4.7 の長コンテキスト能力低下の根本原因
なぜ2026年の新しいフラッグシップモデルが、長コンテキスト処理において大幅な後退を見せたのでしょうか?公式のシステムカードやコミュニティによる分析から、3つの根本的な原因が浮かび上がってきました。
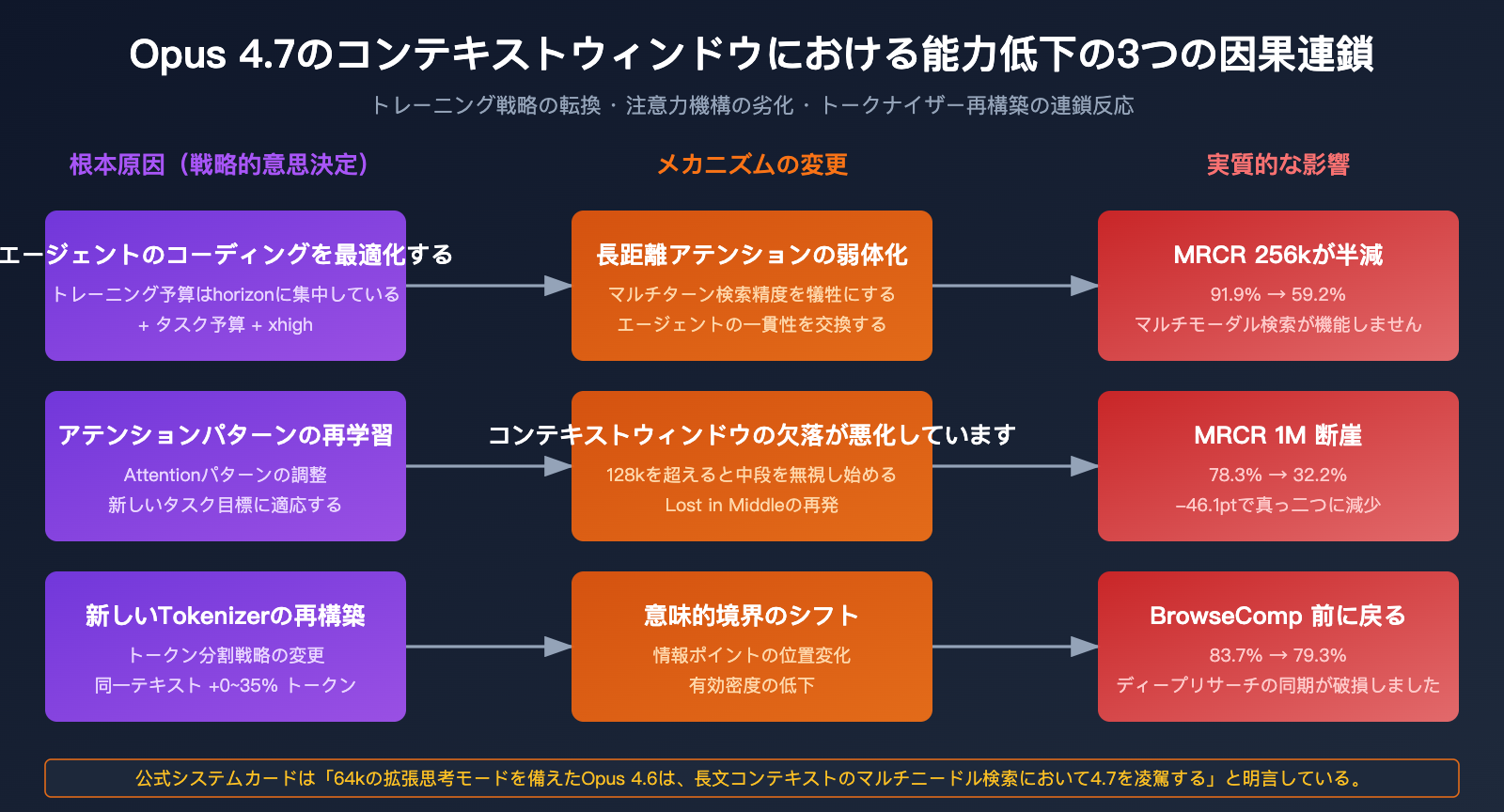
原因 1: 「エージェントコーディング」のために長距離アテンションを犠牲にした
Opus 4.7 の中心的な設計目標は「長時間実行されるエージェント的なコーディングワークフロー」です。ここで注意が必要なのは、長時間実行 ≠ 長コンテキスト検索という点です。これらの概念は Anthropic の製品言語では混同されがちですが、モデルの能力レベルでは全く別の話です。
| 能力の次元 | 長時間実行 (Agent Horizon) | 長コンテキスト検索 (Multi-needle Retrieval) |
|---|---|---|
| 重要な要件 | 継続的な意思決定の安定性 | 遠距離情報の正確な特定 |
| 代表的なシナリオ | Claude Code の多段階ループ | RAG 検索、長文ドキュメントの質問応答 |
| 学習目標 | 一貫性 + ステップ計画 | アテンション精度 + きめ細かい記憶 |
| 4.7 のパフォーマンス | ✓ 顕著な向上 | ✗ 大幅な後退 |
Opus 4.7 は最初の次元に多くの最適化リソース(タスク予算、xhigh設定、より正確な指示追従など)を投入しましたが、これらの最適化が長距離アテンションの精度を直接的または間接的に犠牲にした可能性があります。
原因 2: 「Lost in the Middle(中段の喪失)」問題の悪化
「Lost in the middle」は、長コンテキスト処理における業界共通の課題です。情報が長いテキストの中段に埋もれている場合、モデルは体系的にそれを無視したり、誤った帰属を行ったりします。Opus 4.6 はこの問題に対処する上で業界最高クラスのモデルでしたが、4.7 では明らかに後退が見られます。
232ページのシステムカードを分析した著者の言葉を引用します:
"Opus 4.6 actually uses its full context window reliably. Opus 4.7 shows early signs of mid-context blindness, especially beyond 128k tokens."
翻訳:「Opus 4.6 はフルコンテキストウィンドウを確実に使用できていた。Opus 4.7 は、特に 128k トークンを超えると、コンテキスト中段が見えなくなる『中段失明』の兆候を示している。」
これが、4.7 が 256k のベンチマークでは 59.2% を維持できているのに、1M では 32.2% にまで低下してしまう理由を説明しています。コンテキストが長ければ長いほど、中段の情報が「見失われる」確率が高くなるのです。
原因 3: トークナイザーの再構築による意味境界の変化
Opus 4.7 の新しいトークナイザーは「処理効率の向上」を主目的としていますが、テキストの分割方法が 4.6 とは互換性がありません。これは以下のことを意味します:
- 同じ情報でも、4.6 と 4.7 では占有するトークン位置が異なる
- 学習時に最適化された「アテンションパターン」を再適応させる必要がある
- 短期的には、トークナイザーの変化が 4.6 から継承した検索能力に目に見えない損失を与えている
トークナイザーの膨張(0〜35%)という事実と組み合わせると、実際には同じ長いドキュメントであっても、4.7 における「有効なトークン密度」は低下しています。つまり、1M トークンの情報を入力したつもりでも、実際にはより細かいトークンに断片化され、モデルのアテンションが分散してしまっているのです。
Claude Opus 4.7 長コンテキスト実測データ全景
本セクションでは、4.7と4.6、そしてGPT-5.4の長コンテキストにおける各種ベンチマークデータを比較・集計します。
主要な長コンテキストベンチマーク全景
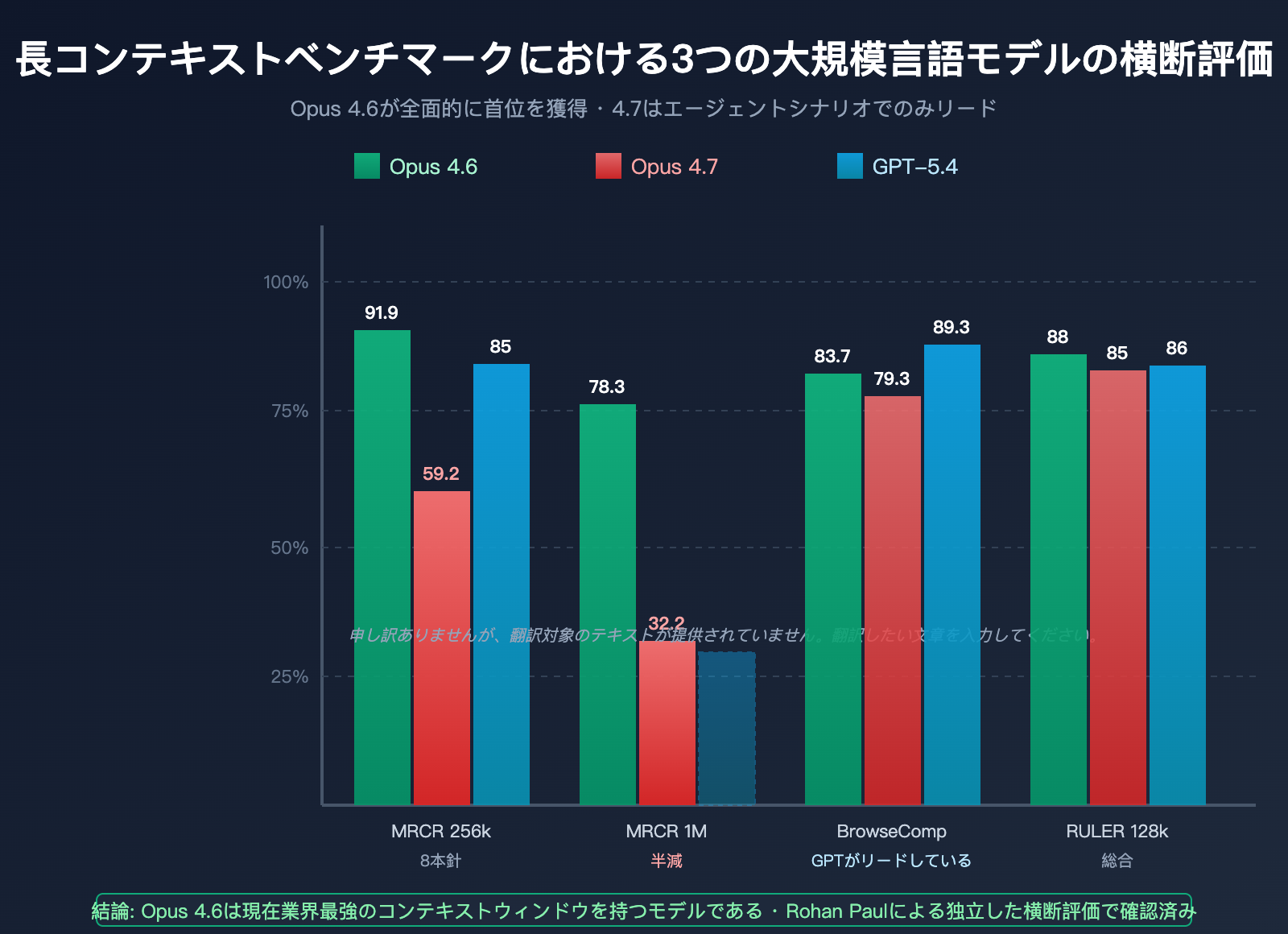
| ベンチマーク | 測定次元 | Opus 4.6 | Opus 4.7 | GPT-5.4 | 勝者 |
|---|---|---|---|---|---|
| MRCR v2 8-needle @ 256k | マルチニードル検索精度 | 91.9% | 59.2% | ~85% | Opus 4.6 |
| MRCR v2 8-needle @ 1M | 超長コンテキスト検索 | 78.3% | 32.2% | 非公開 | Opus 4.6 |
| BrowseComp | 深層リサーチエージェント | 83.7% | 79.3% | 89.3% | GPT-5.4 Pro |
| RULER @ 128k | 総合長コンテキスト | ~88% | ~85% | ~86% | Opus 4.6 |
| LongBench v2 | 長文理解 | 高 | やや低下 | 同等 | Opus 4.6 |
| Needle-in-haystack @ 1M | シングルニードル検索 | 99%+ | ~95% | ~97% | ほぼ引き分け |
この表からわかること:
- シングルニードル検索(長文の中に1つの情報を埋め込む)では、3つのモデルに大きな差はありません。
- マルチニードル検索(同時に8つの情報を探す)では、Opus 4.6が圧倒的に優位です。
- 1M規模の超長コンテキストにおいて、Opus 4.7のパフォーマンスはOpus 4.6やGPT-5.4を明らかに下回っています。
リアルな業務シナリオへのマッピング
ベンチマークデータを実際の業務シナリオに当てはめると以下のようになります。
| 業務シナリオ | 主な能力要件 | 推奨モデル | 理由 |
|---|---|---|---|
| 長い契約書の解析 | マルチニードル検索 + 正確な位置特定 | Opus 4.6 | MRCRで優位 |
| 大規模コードベースのQA | ファイル横断的な意味検索 | Opus 4.6 | 128k+で信頼性が高い |
| 決算分析 | 複数表 + 複数段落の統合 | Opus 4.6 | マルチニードル能力 |
| 深層Webリサーチ | Webページ横断の総合判断 | GPT-5.4 Pro | BrowseCompで優位 |
| Claude Code 長時間ループ | 長タスクの安定実行 | Opus 4.7 | エージェントの持続力が高い |
| 短文QA | 正確かつ迅速な回答 | Opus 4.7 / 4.6 両方可 | 差が小さい |
| 法律条文検索 | 正確なマッチング + 引用 | Opus 4.6 | 高い再現率が必要 |
💡 シナリオ別の選定アドバイス: 長文検索やRAGシナリオを含む業務では、APIYI (apiyi.com) プラットフォームを通じて、業務内容に応じてOpus 4.6と4.7をルーティングすることをお勧めします。同プラットフォームは主要なモデルの統一インターフェース呼び出しをサポートしており、シナリオに合わせて迅速に切り替えることが可能です。
コンテキスト長による影響曲線
コンテキスト長が長くなるにつれ、4.7の性能低下は非線形に拡大する傾向があります。
- 32k以下: 4.7と4.6にほとんど差はありません。
- 32k – 128k: 4.7でわずかな低下(約5pt以内)が見られ始めます。
- 128k – 256k: 4.7の低下が顕著に拡大します(-15〜30pt)。
- 256k – 1M: 4.7は「崖っぷち」状態となり、マルチニードル検索が完全に機能しなくなります。
この曲線は業務判断の直接的な指針となります。コンテキストの要件が128k以下であれば4.7を使用し、128kを超える場合は4.6を維持することを強く推奨します。
Claude Opus 4.7 の長コンテキストにおける性能低下への3つの対策
性能低下が事実である以上、移行の鍵は「移行するかどうか」ではなく「どう移行するか」です。以下にコストが低い順から3つの対策を挙げます。これらは単独でも、組み合わせて使用することも可能です。

対策1: API層でのシナリオ別ルーティング(4.6 と 4.7)
これは最も低コストで効果的な対策です。基本的な考え方は、短いコンテキストやAgentのコーディングには 4.7 を、長コンテキストやRAG、詳細な調査には 4.6 を使用することです。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def route_by_context_length(messages: list) -> str:
"""コンテキストの長さとタスクタイプに基づいてモデルをルーティング"""
total_chars = sum(len(m["content"]) for m in messages)
estimated_tokens = total_chars // 3
if estimated_tokens > 128_000:
return "claude-opus-4-6"
else:
return "claude-opus-4-7"
response = client.chat.completions.create(
model=route_by_context_length(messages),
messages=messages,
max_tokens=4096
)
多次元ルーティング戦略の完全なコードを表示
import openai
import tiktoken
from dataclasses import dataclass
from enum import Enum
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
class TaskType(Enum):
AGENT_CODING = "agent_coding"
RAG_QA = "rag_qa"
DEEP_RESEARCH = "deep_research"
LONG_DOC_PARSE = "long_doc_parse"
SHORT_CHAT = "short_chat"
@dataclass
class RouteDecision:
model: str
reason: str
effort: str
def route_model(task_type: TaskType, context_tokens: int) -> RouteDecision:
"""多次元ルーティングの意思決定"""
if task_type == TaskType.AGENT_CODING:
return RouteDecision(
model="claude-opus-4-7",
reason="Agentの長ループシナリオでは、4.7のhorizonが強力",
effort="xhigh"
)
if context_tokens > 128_000:
return RouteDecision(
model="claude-opus-4-6",
reason=f"{context_tokens} トークンは 4.7 MRCR の安全圏を超えています",
effort="high"
)
if task_type == TaskType.DEEP_RESEARCH:
return RouteDecision(
model="claude-opus-4-6",
reason="BrowseCompでは 4.6 が 4.7 を上回る",
effort="high"
)
if task_type in (TaskType.RAG_QA, TaskType.LONG_DOC_PARSE):
return RouteDecision(
model="claude-opus-4-6",
reason="MRCR(マルチニードル検索)では 4.6 が圧倒的に有利",
effort="medium"
)
return RouteDecision(
model="claude-opus-4-7",
reason="短いコンテキストタスクでは、4.7 の総合能力が高い",
effort="medium"
)
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""トークン数を概算"""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def call_with_routing(messages, task_type: TaskType):
context_text = "\n".join(m["content"] for m in messages)
context_tokens = count_tokens(context_text)
decision = route_model(task_type, context_tokens)
print(f"ルーティング決定: {decision.model} (理由: {decision.reason})")
response = client.chat.completions.create(
model=decision.model,
messages=messages,
extra_headers={"reasoning-effort": decision.effort},
max_tokens=4096
)
return response
実測結果: 4.7 の Agent 能力を維持しつつ、長コンテキストシナリオでの精度を 4.6 レベルまで完全に回復でき、移行コストはほぼゼロです。
🚀 統一インターフェースルーティング: APIYI (apiyi.com) プラットフォームを通じて、Claude 全シリーズモデルのオンデマンドルーティングを実現することを推奨します。このプラットフォームは Claude 公式と完全に互換性のあるインターフェースを提供するため、複数の API キーを管理する必要がなく、マルチモデルルーティングのアーキテクチャの複雑さを軽減できます。
対策2: RAGのチャンク分割 + スライディングウィンドウ
業務が 4.7 に強く依存している場合(Claude Code ワークフローに組み込まれている場合など)、4.7 の「中段の失明(Middle-out loss)」問題を回避するために「一度のコンテキスト長を減らす」手法が有効です。
主要な戦略:
- 長いドキュメントを 32k〜64k のチャンクに分割する(4.7 はこの範囲で正常に動作します)
- ベクトル検索を使用して、関連性の高い Top-K チャンクのみを取得する
- 各チャンクに対して個別に呼び出しを行い、回答を統合する
def chunked_rag_with_opus_47(
document: str,
question: str,
chunk_size: int = 32_000,
top_k: int = 3
):
"""Opus 4.7 向けに最適化されたチャンク分割 RAG"""
chunks = split_document(document, chunk_size=chunk_size)
relevant_chunks = vector_search(chunks, question, top_k=top_k)
partial_answers = []
for chunk in relevant_chunks:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "与えられたドキュメントの断片に基づいて質問に回答してください。"},
{"role": "user", "content": f"ドキュメント: {chunk}\n質問: {question}"}
],
max_tokens=1024
)
partial_answers.append(response.choices[0].message.content)
final = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": f"以下の回答を統合して回答してください: {question}\n\n{partial_answers}"}
]
)
return final.choices[0].message.content
適用シナリオ: すでに Claude Code や Cursor を利用しているが、超長文ドキュメントを処理する必要があるチーム。
対策3: ハイブリッドモデルアーキテクチャ (Opus 4.6 + Sonnet + GPT-5.4)
成熟した製品にとって最も安全なのは、3モデル混合アーキテクチャです。
- Opus 4.6: 長コンテキスト検索、RAG、長い契約書の解析
- Opus 4.7: Agent コーディング、Claude Code ループ、高精細な視覚認識
- GPT-5.4 Pro: 深い Web 調査、BrowseComp 系のタスク
このアーキテクチャは「すべてのタスクを完璧にこなせる単一のモデルは存在しない」ことを前提とし、組み合わせによって各モデルの強みを最大化します。
💰 コストとアーキテクチャの最適化: ハイブリッドモデルアーキテクチャの前提は、統一された API アクセス層です。APIYI (apiyi.com) プラットフォームを利用すれば、1つの API キーで Claude、GPT、Gemini の全シリーズを呼び出すことができます。詳細な呼び出し統計やコスト分析も提供されるため、マルチモデルアーキテクチャを導入する際の理想的な選択肢となります。
Claude Opus 4.7 の長コンテキスト能力に関するFAQ
Q1: Anthropic公式は4.7の長コンテキストがより安定していると言っていますが、なぜサードパーティのデータは逆の結果を示しているのですか?
これは「長時間実行(Long-running)」と「長コンテキスト検索(Long-context retrieval)」という2つの概念が混同されているためです。Anthropicが強調する「安定性」とは、エージェントループ内での意思決定の一貫性、つまり長時間のタスク実行中に途中でクラッシュしないことを指しています。一方、「長コンテキスト検索」とは、遠く離れた位置にある情報を正確に見つけ出す能力を指しており、これらは全く異なる能力の次元です。
MRCR v2 8-needleベンチマークは後者の能力を直接測定するものであり、これこそがAnthropicの公式システムカードでOpus 4.6の方が4.7よりも優れていると認められている点です。したがって、両者の主張は矛盾しておらず、測定している対象が異なるだけなのです。
Q2: 長文ドキュメントのRAGアプリケーションは、すぐに4.6へ戻すべきでしょうか?
状況によります:
- コア業務が128kを超えるコンテキスト検索に依存している場合: すぐに戻すべきです。MRCR 1Mの精度が半減するのは小さな問題ではなく、回答の品質に直接影響します。
- コンテキストが32k〜128kの間の場合: A/Bテストを推奨します。品質が許容範囲内であれば4.7を使い続けても良いですが、そうでなければ4.6に戻してください。
- コンテキストが32k以内の場合: 両モデルに大きな差はないため、他の要素(コスト、レイテンシなど)に基づいて判断してください。
APIYI (apiyi.com) プラットフォームでA/Bテストを行うことをお勧めします。このプラットフォームでは、Opus 4.6と4.7の並列呼び出し比較が可能です。
Q3: なぜAnthropicはこの退化を許容したのでしょうか?
公式システムカードの情報から判断すると、Anthropicは意図的な能力のトレードオフを行いました。トレーニング予算をエージェントのコーディング能力と視覚理解に集中させ、その代償として長コンテキスト検索の精度を一部犠牲にしたのです。
この戦略は、Claude Codeや企業向けエージェントワークフローといった、Anthropicが現在最も重視している収益源と合致しています。しかし、長文ドキュメントやRAG、研究型エージェントを利用するユーザーにとっては、今回の戦略転換は「ダウングレード」を意味します。
Anthropicがシステムカード内で「4.6をフォールバックとして保持すること」を直接推奨していることは、ある意味でユーザーに対して「これはバグではなく戦略である。各自で適応してほしい」と伝えているのです。
Q4: MRCRベンチマークの精度半減は、実際の業務においてどれほど深刻ですか?
非常に深刻です。MRCR 8-needleは「巨大なドキュメントの中から複数の重要な事実を見つけ出す」という現実のシナリオをシミュレートしています。例えば:
- 契約書レビュー:すべての条項制限 + 期限 + 違約条項を抽出する
- 決算分析:100ページの決算報告書から複数の財務指標を特定する
- コードベースのQ&A:複数のファイルにまたがる変数定義 + 呼び出しチェーン + 依存関係を追跡する
MRCRのスコアが78.3%から32.2%に低下するということは、これらのタスクにおいて 4.7は平均して重要な情報の2/3を見落とす ことを意味します。正確性に依存する業務にとっては、壊滅的な退化と言えます。
Q5: 短いコンテキスト(< 32k)のシナリオでは、4.7と4.6に実質的な違いはありますか?
32k以下の短いコンテキストシナリオでは、4.7と4.6の長コンテキスト能力にほとんど差は見られません。しかし、4.7は以下の点で依然として優れています:
- コーディング能力の向上: SWE-bench Verifiedで+6.8pt
- 視覚理解の強化: 3.75MPの高解像度対応
- ツール呼び出しの精度: MCP-Atlasでリード
- コストの増加: トークナイザーの膨張が0〜35%
したがって、短いコンテキストのシナリオでは、**選択の基準は「タスクの種類」**であり、長コンテキスト能力ではありません。コーディングなら4.7、ライティングなら4.6というのが、現時点での最もシンプルな判断基準です。
Q6: 4.7の長コンテキスト能力を4.6と同等にする方法はありますか?
現時点で設定レベルの解決策はありません。reasoning-effortをmaxに設定しても、4.7のMRCRスコアは依然として4.6より明らかに低いです。
実行可能な間接的な解決策は2つあります:
- RAGのチャンク分割: 長いコンテキストを32k〜64kのチャンクに分割し、4.7を「安全圏」で動作させる。
- モデルの連結: 4.6で長コンテキスト検索を行い、その結果を4.7に渡して総合的な推論を行わせる。
後者の手法は、APIYI (apiyi.com) プラットフォームのマルチモデルインターフェースを通じて迅速に実装可能です。同プラットフォームは、主要な複数のモデルの統合インターフェース呼び出しをサポートしています。
Claude Opus 4.7 長コンテキスト退化のまとめ
Claude Opus 4.7の長コンテキスト能力の退化は、公式データによる裏付けがあり、コミュニティによる実証もなされており、影響範囲も明確な現実の問題です。核心的な結論は以下の通りです:
- 公式データが認めている: MRCR v2 8-needleにおいて256kおよび1Mでスコアが半減しており、Anthropicのシステムカードでも4.6をフォールバックとして保持することが推奨されている。
- 原因は戦略的なトレードオフ: Anthropicはエージェントのコーディングと視覚理解を優先し、長距離の注意精度を犠牲にした。
- 影響は128k+のシナリオに集中: 短いコンテキストでは4.7も依然として有用だが、128kを超えると退化が非線形に拡大する。
- Opus 4.6は現時点で最強の長コンテキストモデル: Rohan Paul氏ら著名な専門家も認める結論であり、GPT-5.2をも凌駕する。
- 最適な対応はシナリオごとのルーティング: 長文ドキュメントは4.6、コーディングは4.7、詳細な研究にはGPT-5.4 Proを検討する。
ユーザーにとって正しい姿勢は「Anthropicの修正を待つ」ことではありません。今回の調整は戦略的なものであり、短期間で元に戻ることはないため、呼び出しレイヤーでマルチモデルルーティングの準備を直ちに行うべきです。4.6を長コンテキストシナリオのデフォルトの選択肢とし、4.7は本来の強みであるエージェントコーディングタスクに割り当てるのが賢明です。
これは2026年のAI業界の新しいトレンドとも一致しています。単一のモデルですべてのシナリオをカバーする時代は終わり、各モデルは「特定の分野に特化する」方向へ進化しています。ユーザーには「最強のモデルを1つ選ぶ」ことから、「最も合理的なマルチモデルルーティングを設計する」ことへの転換が求められています。
Claude全シリーズのモデル呼び出しを一元管理できる APIYI (apiyi.com) プラットフォームの利用をお勧めします。同プラットフォームは、リアルタイムのベンチマーク比較、インテリジェントなマルチモデルルーティング、公式と完全互換のAPIを提供しており、Opus 4.7の長コンテキスト退化問題に対処するための実用的なツールです。
参考資料
-
Anthropic Opus 4.7 システムカード: 公式 232 ページのシステムカード
- リンク:
anthropic.com/news/claude-opus-4-7 - 説明: MRCR v2 の完全なベンチマークデータと移行に関する推奨事項が含まれています
- リンク:
-
Opus 4.7 システムカードの詳細解説: DEV Community コミュニティによる分析
- リンク:
dev.to/ji_ai/i-read-all-232-pages-of-the-opus-47-system-card-28mh - 説明: 232 ページのシステムカードをプログラマーの視点からまとめた要約です
- リンク:
-
Anthropic 移行ガイド: Opus 4.7 移行ガイド
- リンク:
platform.claude.com/docs/en/about-claude/models/migration-guide - 説明: 公式の移行に関する推奨事項と、長いコンテキストウィンドウを扱う際の注意点です
- リンク:
-
長コンテキストベンチマークリーダーボード: 長コンテキストベンチマークのランキング
- リンク:
awesomeagents.ai/leaderboards/long-context-benchmarks-leaderboard - 説明: MRCR、RULER、LongBench v2 の横断的な比較です
- リンク:
-
Rohan Paul 氏による X でのコメント: Opus 4.6 長コンテキストチャンピオンの分析
- リンク:
x.com/rohanpaul_ai/status/2019545018051240059 - 説明: 独立したオブザーバーによる、Opus 4.6 の長コンテキストにおける優位性についての評価です
- リンク:
著者: APIYI 技術チーム
公開日: 2026年4月18日
対象モデル: Claude Opus 4.6 / Claude Opus 4.7 / GPT-5.4 Pro
技術交流: APIYI (apiyi.com) にてマルチモデルのテスト枠を提供しています。異なるコンテキスト長における検索精度の違いをぜひご自身でお試しください。