
Googleは2026年5月19日に開催された「Google I/O 2026」において、Gemini Omni マルチモーダルモデルファミリーを正式に発表しました。初弾モデルとなる「Gemini Omni Flash」は、発表当日からユーザーへの提供が開始されています。この名前を初めて耳にする方にとって、「Omni(オムニ)」という言葉は想像以上に重要です。これは、Geminiの高度な推論能力とメディア生成能力を完全に融合させるという、Googleの全く新しい方向性を示しているからです。本記事では、Google Omniとは一体何なのか、何ができるのか、従来のVeoと何が違うのか、そして開発者やクリエイターがどのように使い始めればよいのかを、5分でわかるようにやさしく解説します。
核心的な価値: 本記事を読めば、Google Omni(Gemini Omni)の立ち位置、能力の境界線、利用チャネル、そして業界における意義が明確になり、ニュースの見出しに並ぶ専門用語に惑わされることはなくなります。
Google Omniとは:核心情報のまとめ
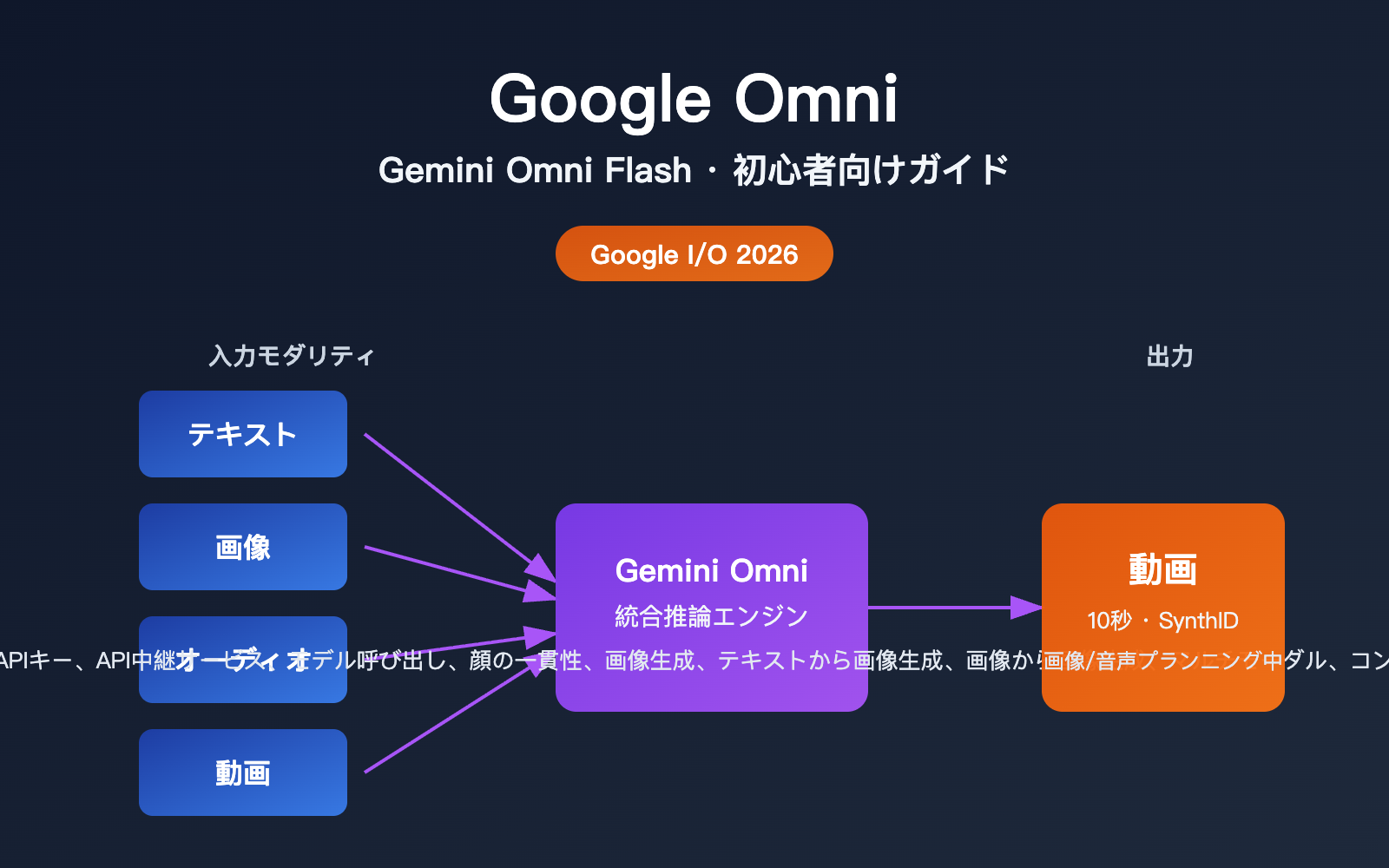
一言でまとめると、Google OmniはGoogleが発表した「マルチモーダル生成モデルファミリー」であり、その最初のモデルがGemini Omni Flashです。最大の売りは「また動画を生成できるAIが登場した」ことではなく、「テキスト、画像、音声、動画を自由な組み合わせで入力し、統合的に推論した上で、一貫性のある動画を出力できる」という点にあります。
GoogleのCEOであるスンダー・ピチャイ氏は、基調講演でその立ち位置を「create anything from any input(あらゆる入力から何でも生成する)」という非常にわかりやすい言葉で表現しました。言い換えれば、これまでは画像生成モデルで画像を作り、別のモデルでそれを動画にする必要がありましたが、Omniは単一のモデルでクロスモーダルな推論と生成を完結させようとしているのです。
| 項目 | 詳細 |
|---|---|
| 発表日 | 2026年5月19日(Google I/O 2026) |
| 発表元 | Google(Google DeepMind & Google Labs) |
| 初弾モデル | Gemini Omni Flash |
| モデルの立ち位置 | マルチモーダル推論 + メディア生成の統合モデルファミリー |
| 入力モダリティ | テキスト、画像、動画、音声(任意の組み合わせ) |
| 出力モダリティ | 動画(初弾はこれを主軸に)、画像と音声は順次開放予定 |
| 単一セグメントの長さ | 最大10秒(デプロイ段階の制限、モデルの限界値ではない) |
| コンテンツ識別 | すべての動画にSynthIDの不可視透かしを自動埋め込み |
| 今後の予定 | Gemini Omni Pro(プロ版)、より長い動画生成、音声編集機能 |
💡 初心者向けヒント: Geminiシリーズを含む主要なモデルをいち早く体験したい場合は、APIYI(apiyi.com)を利用することで、統一されたインターフェースから素早くモデル呼び出しが可能です。プラットフォームごとに登録する手間を省くことができます。
Google Omni の重要な能力:なぜ「次世代」と呼ばれるのか
「入力と出力が何か」という点だけで見ると、Omni を Sora、Veo、Runway といった動画生成モデルの同類だと誤解しがちです。しかし、Google のプロダクトディレクターである Nicole Brichtova 氏は、より正確な表現をしています。「これは Gemini の知能とメディアモデルのレンダリング能力を組み合わせた、次のステップである」と。以下の4つの能力こそ、Omni と従来の動画モデルの違いを理解するための鍵となります。
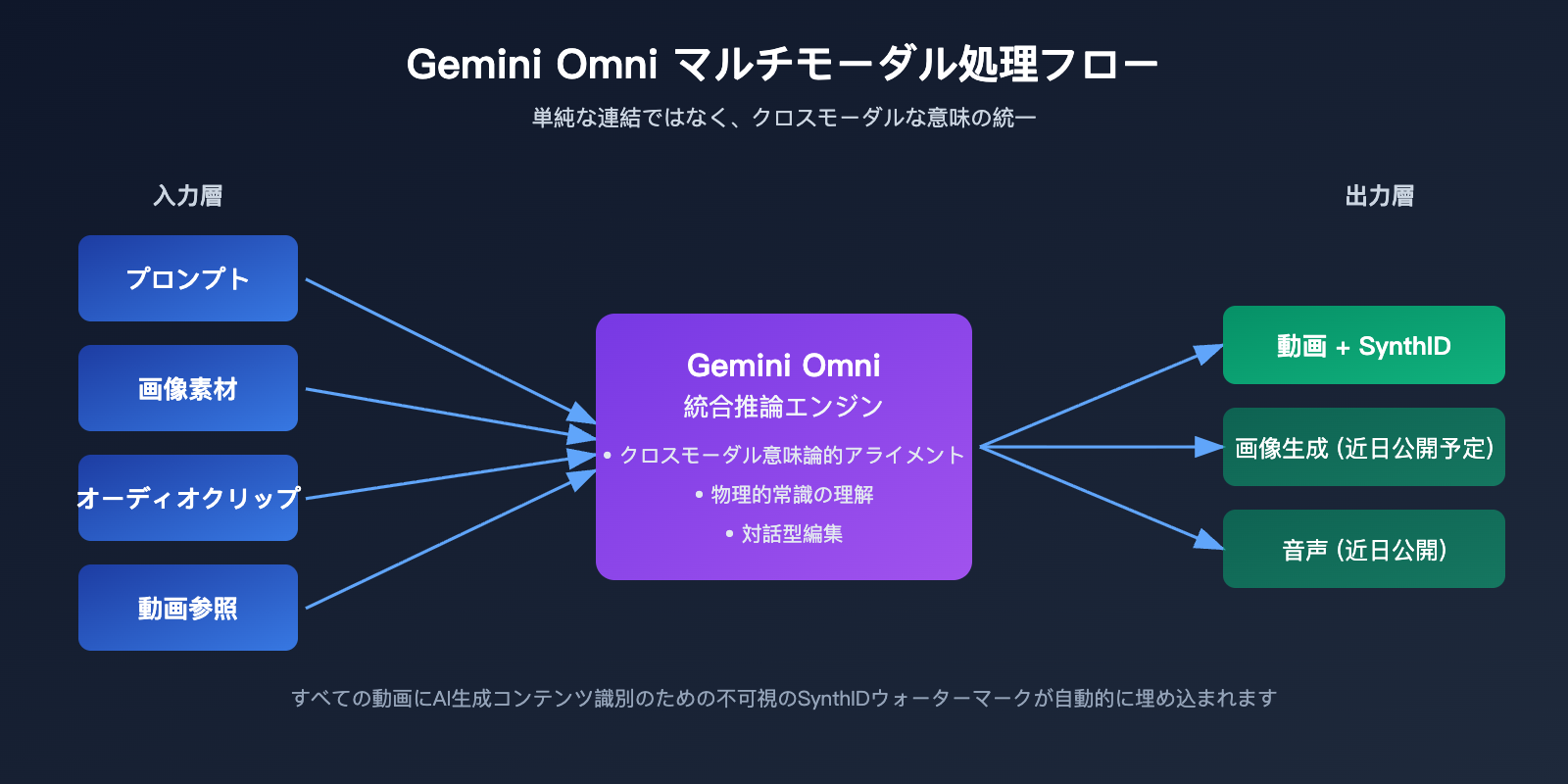
1. 単なる結合ではない、クロスモーダル推論
従来の動画生成は、「テキスト → 動画」や「画像+テキスト → 動画」といった2段階のプロセスが一般的でした。Gemini Omni の手法は、すべての入力を一つのモデルに投げ込み、内部で統一された意味理解を構築した上で、一度に動画をレンダリングします。
例えば、製品写真、背景音楽、広告のセリフを同時に Omni に渡すと、単に音楽を動画に重ねるのではなく、「リズムが変わるタイミングで製品を表示する」「セリフと画面の動きを呼応させる」といった処理を行います。この「理解してから生成する」という能力は、Gemini モデルそのものが持つ推論の遺伝子によるものです。
2. 物理的理解と世界の知識
Google はデモで2つの例を強調しました。一つは瑪瑙(めのう)のボールが転がるシーンで、ボールが着地した際の反発、停止、衝突音が現実の物理法則に従っています。もう一つは、タンパク質の折り畳みを粘土アニメ(クレイメーション)風に解説するアニメーションで、幾何学構造が分子生物学の常識に即しています。これらは一見シンプルですが、背後には単なる画素レベルの適合ではなく、モデルが「現実世界の法則」を理解しているという事実があります。
初心者にとってこれは、Omni が生成する動画において「物体の瞬間移動」「光と影の不整合」「人物の指の数がおかしい」といった典型的な AI 動画の欠陥が発生しにくいことを意味します。
3. 対話形式の反復編集
Omni は「生成した後に自然言語で修正する」ことをサポートしています。モデルが動画を生成した後、「背景を夕暮れにして」「カメラワークを少しゆっくりにして」と指示すれば、人物、シーン、動作の一貫性を保ったまま部分的な調整を行ってくれます。
このインタラクションは、一度きりの長いプロンプトを書くよりも、編集者と会話する感覚に近いです。プロンプトエンジニアリングの経験がない初心者には特に親しみやすい設計です。
4. カスタムデジタルアバター
Omni では、ユーザーが生体認証を通じて自身のデジタルアバターを作成し、生成された動画に組み込むことができます。Google は、このステップには必ず本人による生体認証が必要であることを強調しており、なりすましによる悪用リスクを低減することを目的としています。
🎯 能力のまとめ: Omni の鍵は「高解像度」や「長尺」ではなく、「クロスモーダル推論 + 物理常識 + 対話編集」の3点セットです。これらの能力を自社プロダクトに組み込むには、APIYI (apiyi.com) のような集約型インターフェースを通じて、さまざまなモデルの組み合わせの効果をテストし、主力プランを決定することをお勧めします。
Gemini Omni と Veo の違い:初心者が最も混同しやすい二つの名前
多くの初心者が「Google にはすでに Veo があるのに、Omni は何のためにあるのか?」と質問します。これは非常に真っ当な疑問です。どちらも「動画を生成できる」ためですが、その位置付けは全く異なります。以下の表は、両者の関係を理解するための最短ルートです。
| 比較項目 | Veo | Gemini Omni |
|---|---|---|
| モデルタイプ | 専用メディアモデル | マルチモーダル推論 + メディア生成統合モデル |
| 入力サポート | テキスト、画像 | テキスト + 画像 + 音声 + 動画 (任意組み合わせ) |
| 推論の深さ | レンダリング層がメイン | Gemini 推論による、クロスモーダルな意味の統合 |
| 編集方法 | 再生成がメイン | 対話形式の増分編集をサポート |
| 物理的理解 | 一般的 | 顕著に強化 (公式デモで重点的に強調) |
| 対象ユーザー | プロの動画クリエイター | クリエイター + 一般消費者 + 開発者 |
| 現在の立ち位置 | 高品質動画生成ツール | クロスモーダル「何でも生成」基礎モデル |
簡単な例え:Veo は高精細なプリンターのようなもので、画像を渡せば美しい完成品を印刷してくれます。一方、Omni はあなたの意図を理解できる万能アシスタントのようなもので、素材と一言の要望を投げれば、完成した動画を生成してくれます。両者は将来的に共存する可能性が高いですが、Omni は Google が賭けている「統一マルチモーダル」路線を象徴しています。

🧭 初心者への選択アドバイス: 美しい短編動画を生成したいだけであれば、Veo で十分です。しかし、「画像・テキスト・音声・動画を混合入力する」という応用シーンを作りたいのであれば、Omni がより適した方向性です。これら2種類のモデルの実際のパフォーマンスを素早く比較するには、APIYI (apiyi.com) のような複数モデルの切り替えをサポートするインターフェースを利用して A/B テストを行うことをお勧めします。これにより、同じコード体系でプロセスを変えずにモデルを入れ替えることが可能です。
Gemini Omni Flash の使い方:初心者向けガイド
Gemini Omni Flash はリリース当初から様々な層に向けて公開されていますが、利用チャネルは多岐にわたります。以下のチャネル比較表を参考に、初心者の方は「どこから始めるべきか」を素早く判断してください。
| ユーザータイプ | 推奨入口 | 有料/無料 | 備考 |
|---|---|---|---|
| 一般消費者 | Gemini アプリ | Google AI Plus/Pro/Ultra への登録が必要 | 個人のクリエイティブ、ショート動画制作 |
| コンテンツクリエイター | Google Flow | Google AI プランへの登録が必要 | プロ向けのクリエイティブワークフロー |
| ショート動画ユーザー | YouTube Shorts、YouTube Create アプリ | 無料 | 期間限定の無料体験、最初の入り口として最適 |
| 開発者 / 企業 | Google API (近日公開) | 価格未定 | 数週間以内に公開予定、続報に注目 |
| マルチモデル評価者 | サードパーティ API 統合プラットフォーム | プラットフォームの価格設定に準ずる | 複数のモデルを比較したい開発チーム向け |
初心者向けの最もシンプルなステップ
- 有料の AI ツールをまだ使っていない場合は、まず YouTube Shorts または YouTube Create アプリで無料の Omni 動画生成を体験することをお勧めします。これが最もハードルの低い入り口です。
- すでに Google AI Plus 以上のサブスクリプションを利用している場合は、Gemini アプリを開き、作成パネルから Omni 動画生成の入り口にアクセスできます。
- 開発者の方は、現時点では消費者向けサービスで効果を体験しつつ、公式 API の公開を待つのが最も現実的です。同時に、APIYI (apiyi.com) を通じて Gemini シリーズの既存モデルを呼び出し、自身のマルチモーダル呼び出しフローをあらかじめ構築しておくことをお勧めします。
最短の呼び出しコード例(公式 API 公開後)
Omni の公式開発者向け API はまだ「数週間以内にリリース」という段階ですが、呼び出し構造を事前に設計しておけば、インターフェース公開後すぐに接続可能です。
# マルチモデル統合呼び出しの例 (概念的な構造、Omni 公式 API 公開後に model を置き換えてください)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI を通じて複数のモデルを統合的に呼び出し
)
# 現在、Gemini シリーズの公開済みモデルを即座に呼び出し可能
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "マルチモーダルモデルの核心的価値を一言で説明してください"}]
)
print(response.choices[0].message.content)
💡 クイックスタートのヒント: すべての公式 API が公開されるのを待つ必要はありません。APIYI (apiyi.com) を活用して Gemini シリーズの他のモデルでフローを構築しておけば、Omni API が正式リリースされた際にモデル名を書き換えるだけで済み、移行コストをほぼゼロに抑えられます。
Google Omni が開発者と業界に与える影響
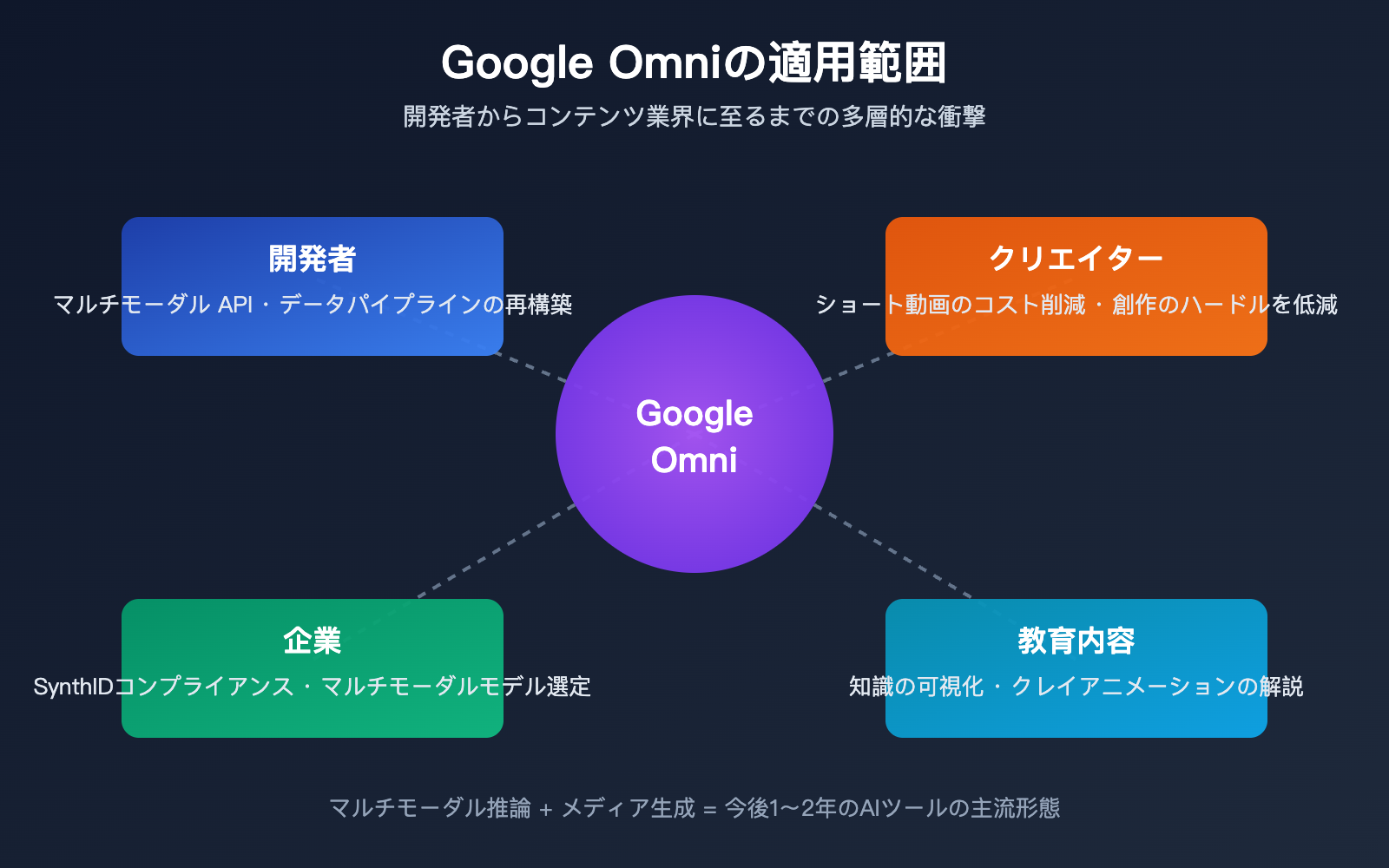
多くの初心者が「この新しいモデルは自分にとって何を意味するのか?」という疑問を抱いています。この問いに対する答えは、開発者、クリエイター、企業という 3 つの層で異なります。
開発者への影響
| 影響の方向性 | 具体的な変化 |
|---|---|
| 呼び出し方式 | 「t2i から i2v」というパイプラインに代わり、マルチモーダルなプロンプト設計が主流に |
| ツールチェーン | テキストだけでなく「動画/音声入力ストリーム」への適応が必要 |
| コンテンツコンプライアンス | SynthID ウォーターマークがデフォルト要件となるため、検出と表示の計画が必要 |
| コスト構造 | 単一の生成コストが純粋なテキスト呼び出しよりも高くなる可能性があり、精緻な管理が必要 |
AI アプリを構築しているエンジニアにとって、Omni は明確なシグナルを発しています。それは「未来の AI インターフェースは『テキスト入力・テキスト出力』ではなく、『マルチモーダル入力・マルチモーダル出力』になる」ということです。データパイプラインを再構築し、素材をモーダルごとに分類管理しておくことで、Omni API が正式に公開された際に先行者利益を得ることができるでしょう。
コンテンツ業界への影響
ショート動画プラットフォーム、広告代理店、教育コンテンツ制作者が真っ先に恩恵を受けるでしょう。高品質な 10 秒の動画を作るには本来数時間の編集が必要でしたが、Omni Flash なら数分で実用的な初稿を作成できます。ロングテールなクリエイターにとっても、「1 枚の画像から 1 本の完成動画へ」というハードルが大幅に下がります。
ただし、SynthID ウォーターマークの強制的な埋め込みは、「AI 生成」という事実がますます透明化することを意味します。プラットフォーム、ブランド、規制当局は、このウォーターマークを基にコンテンツのラベリングや審査戦略を調整する可能性があります。
企業ユーザーへの影響
企業ユーザーが最も懸念するのは、「コンプライアンスとブランドの安全性」そして「スケール化のコスト」の 2 点です。SynthID ウォーターマークは前者の課題を半分解決しますが、後者は Google が今後発表する API 価格に依存します。予算に敏感なチームであれば、APIYI (apiyi.com) のような統合プラットフォームを通じて Gemini、GPT、Claude など各社の動画・マルチモーダル能力を事前に評価し、コストと品質に基づいて選定を行うのが最も賢明な戦略です。
よくある質問
Q1: Google Omni と Gemini Omni は同じものですか?
はい、同じものです。「Google Omni」は非公式な略称であり、Googleが公式に使用している正式名称は「Gemini Omni」です。これはGeminiモデルファミリーにおけるマルチモーダル部門に属しています。Gemini Omni Flashは、このファミリーの最初のモデルです。どちらの名前も同じ技術を指しています。
Q2: 初心者は今、Gemini Omniを無料で体験できますか?
はい、可能です。最も直接的な方法は、YouTube ShortsまたはYouTube CreateアプリでOmni動画生成機能を使用することです。現在はクリエイター向けに無料で開放されています。Geminiアプリ内で使用したい場合は、Google AI Plus、Pro、またはUltraのサブスクリプションが必要です。
Q3: Gemini Omniで生成できる動画が1セグメントあたり10秒しかないのはなぜですか?
これはモデル自体の能力の上限ではなく、デプロイ段階における制限です。公式の説明によると、「計算リソースが逼迫している段階では、より多くのユーザーに能力を開放することを優先している」とのことです。今後、Omni Proなどのモデルで動画の長さは段階的に延長される予定です。
Q4: SynthIDの透かし(ウォーターマーク)は、動画の画質や商用に影響しますか?
いいえ、影響しません。SynthIDは目に見えない透かしであり、人間の目では認識できず、画質にも影響を与えません。その目的は、プラットフォームやツールがコンテンツの流通過程で「この動画はAIによって生成された」ことを識別できるようにすることです。商用利用については、Googleの利用規約に従う必要があります。
Q5: 開発者は今、どのような準備をすべきですか?
第一に、テキストのみのプロンプトを書くのではなく、マルチモーダルなプロンプトの設計ロジックを習得することです。第二に、自身の素材ライブラリを整理し、モーダルごとに分類しておくことです。第三に、モデル呼び出しのフローを事前に構築しておくことです。APIYI (apiyi.com) を通じて統一インターフェースで既存のGeminiシリーズを呼び出し、Omni APIが正式にリリースされた後にシームレスに切り替えることをお勧めします。
Q6: Gemini OmniはVeoに取って代わりますか?
短期的にはありません。Veoは依然として高品質な動画生成に特化したモデルの代表格であり、Omniは「マルチモーダル推論 + メディア生成」という統合された方向性を表しています。両者は今後、異なるシナリオで共存していく可能性が高いでしょう。
まとめ:初心者が覚えておくべき3つのこと
第一に、Gemini Omniの本質は単なる「新しい動画AI」ではなく、「クロスモーダル推論 + メディア生成」の統合モデルであるということです。その差別化された能力は、物理的な理解、対話型の編集、そしてクロスモーダル推論という3つの次元に現れています。
第二に、初心者が最も早く体験できるルートはYouTube ShortsまたはYouTube Createアプリの無料入り口であり、Geminiアプリのサブスクリプションはその次です。開発者向けのAPIは「数週間以内にリリース」される予定ですので、まずはアーキテクチャの計画を立てておきましょう。
第三に、Omniは使い慣れたツールをすぐに置き換えるものではありませんが、今後1〜2年間のマルチモーダルAIの主流となる形態を象徴しています。その入力・出力方式、SynthIDのコンプライアンス要件、そしてVeoとの位置付けの違いを事前に理解しておくことで、次世代のAIツールへの移行をスムーズに進めることができます。Gemini、GPT、Claudeなどの主要モデルを一つのインターフェースで呼び出したい場合、APIYI (apiyi.com) は現在最も手間のかからないソリューションです。Gemini Omni APIが正式に公開された後も、すぐに接続することが可能です。
参考資料
-
Google 公式ブログ – Gemini Omni リリース発表
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - 説明: Google 公式による Gemini Omni の位置付けと能力に関する権威ある紹介
- リンク:
-
TechCrunch – Gemini Omni 詳細レポート
- リンク:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - 説明: Sundar Pichai 氏と Nicole Brichtova 氏の重要な発言を引用したレポート
- リンク:
-
9to5Google – Gemini Omni Flash 体験レポート
- リンク:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - 説明: 公式デモの解説および提供状況に関するレポート
- リンク:
APIYI Team | AI大規模言語モデルの最新動向や実践ガイドに関心がある方は、APIYI (apiyi.com) にアクセスしてください。無料のテスト枠を提供しており、Geminiシリーズを含む多様な主要モデルの統一インターフェースを体験いただけます。