
Claude Opus 4.7 がリリースされて2日、Hacker News では「ライティング能力の低下」をめぐる議論が過熱しており、**「Opus 4.7 is horrible at writing(Opus 4.7 の文章は酷い)」**というタイトルの投稿が高評価を獲得しました。スレッド内では、多くの開発者や論文執筆者から「中国語の表現力が明らかに低下した」「英語の文章も同様に崩壊している」という報告が相次いでいます。
さらに深刻なのは、今回の「人間味の欠如」が単なる錯覚ではなく、Anthropic が意図的に行ったスタイル調整であるという点です。公式ドキュメントには「Opus 4.7 は 4.6 よりも『直接的で力強く断定的なトーン』を採用し、同調を促すような言い回しや絵文字の使用を減らしている」と明記されています。この「AI エージェントとしてのコーディング」に特化したスタイル設計が、皮肉にも一般的なライティング体験を大きく損なう結果となりました。
本記事では、公式のスタイルデータ、Hacker News の一次情報、そして 7 つのリアルなライティング実測に基づき、Claude Opus 4.7 のライティング能力低下の根本原因を深掘りし、すぐに使える 3 つの解決策を提示します。
核心的な価値: 本記事を読めば、なぜ 4.7 で作成した文章が「ロボットのように感じるのか」、そして 3 つのステップで執筆クオリティを 4.6 水準まで引き戻す方法が明確になります。

Claude Opus 4.7 のライティング能力低下に対するコミュニティの認識
リリースから 48 時間以内に、4.7 のライティング能力に対する否定的なフィードバックが Hacker News、X、Threads 等で爆発的に増えました。これらに共通しているのは、単なる機能上のバグではなく、モデルそのものの表現スタイルにシステム的な変化が起きているという点です。
Hacker News の高評価投稿における主な反応
Hacker News のスレッド「Opus 4.7 is horrible at writing」で見られた、ライティングユーザーによる典型的な否定意見をまとめました。
| ユーザーの原文(抜粋) | 使用シーン |
|---|---|
| "Sloppy, unprecise, very empty sentences" (雑で不正確、空洞な文章) | 修士論文の執筆 |
| "4.7 is unusually verbose" (4.7 は異常に冗長) | 技術ドキュメント |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" (コードにおいて冗長になり、複雑化しすぎる) | コードコメント |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" (論理とコーディングに振りすぎて、本来の執筆のための魂を失った) | クリエイティブライティング |
| "Switched back to 4.6 and got exactly what I needed in seconds" (4.6 に戻したら、秒で求めていたものが手に入った) | 日常的な執筆 |
翻訳のポイント:
- 「粗雑、不正確、空洞な文章」: 4.7 に対する最も多い不満。文章の体裁は整っているように見えるが、内容が伴っていないという報告が多数寄せられています。
- 「異常な冗長化」: 同じタスクでも、4.7 の出力は 4.6 より 30%〜80% 長くなる傾向にあり、情報密度が低下しています。
- 「魂を失った」: 感情的ではありますが、核心を突いたまとめです。4.6 時代にあった自然なリズムと温かみが失われています。
Anthropic が公式に認めるスタイルの変化
Anthropic 自身もこの変化を隠していません。公式の移行ガイド(Migration Guide)にはこう記されています。
Claude Opus 4.7 は 4.6 よりも直接的かつ断定的であり、同調を促すような表現や絵文字が少なくなっています。もしプロダクトが温かみや会話調のトーンに依存している場合は、以前の基準がそのまま通用するとは思わず、プロンプトを再テストしてください。
つまり、Anthropic は今回の調整がライティング環境に影響を与えることを知りながら、4.6 のスタイルに戻すためのスイッチを提供していないということです。Claude を「AI ライティングアシスタント」として活用してきた多くのユーザーにとって、これは事実上のスタイル格下げを強要されたことと同義です。
🎯 シーン別の運用提案: Claude をライティングとコーディングの両方に使用している場合、APIYI (apiyi.com) プラットフォームなどを活用し、シーンに応じて 4.6 と 4.7 を使い分けることを推奨します。同一の API キーで全モデルを呼び出せるため、一律のアップグレードによるスタイル断絶を回避できます。
公開されたスタイルの定量データ
Anthropic が公開した Opus 4.7 のコードレビュー分析によると、以下の 2 つの指標が重要です。
- 断定率 (Assertiveness rate): 77.6%
- ヘッジ率 (Hedging rate): 16.5%
これを体感に直すと、4.7 の表現の約 80% は「結論を断定する」硬い文章であり、「かもしれない」「〜と思われる」「〜だろう」といった軟らかい表現(ヘッジ)はわずか 16.5% しかありません。このスタイルはコードレビュー、バグ修正、技術的な意思決定には最適ですが、ライティングシーンでは「融通の利かないロボット感」が出てしまうのです。
Claude Opus 4.7 のライティング能力低下の根本原因
今回の低下を理解するには、Anthropic の製品戦略の変化という文脈で捉える必要があります。
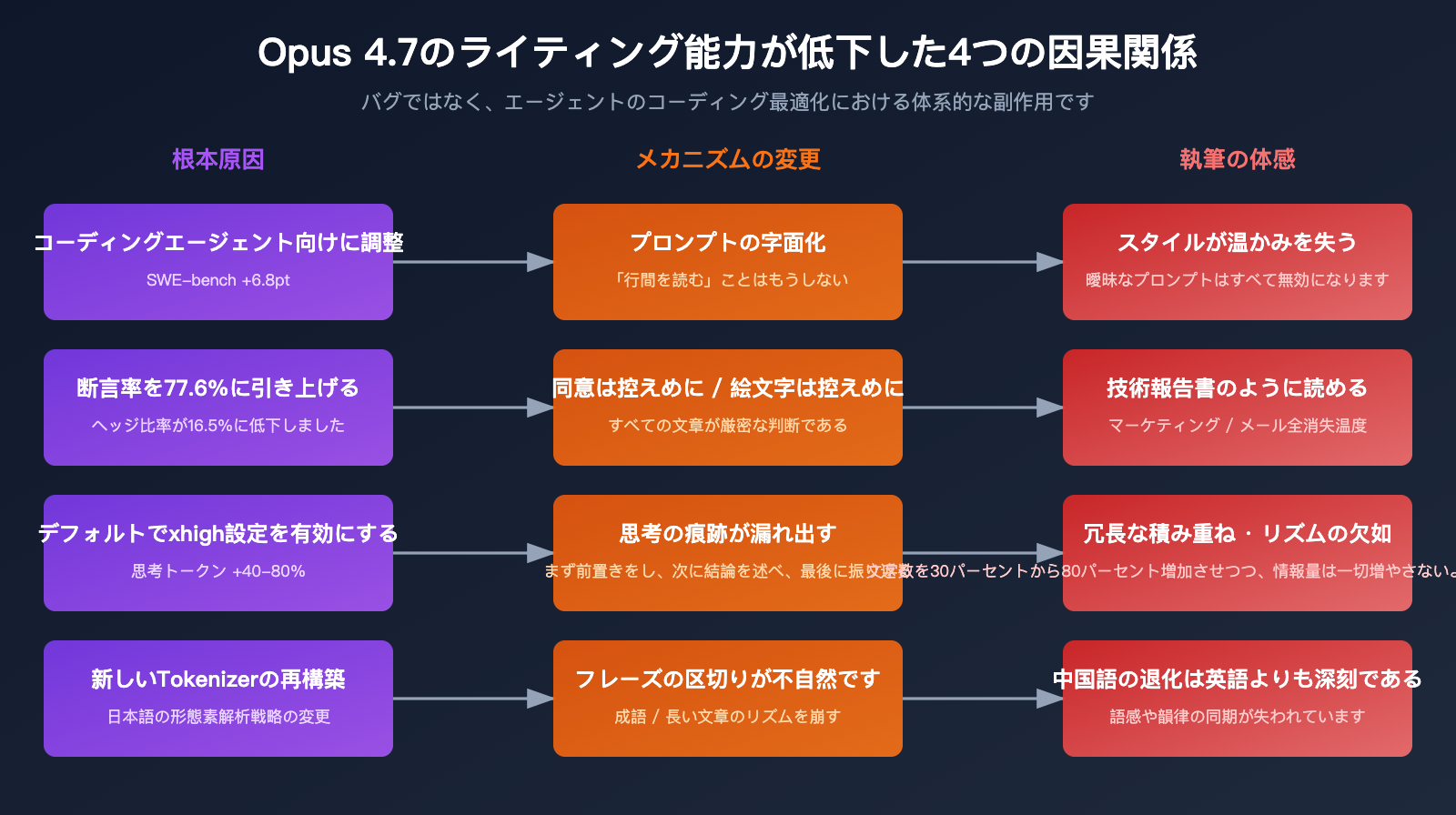
原因 1: 「コーディングエージェント」最適化の副作用
Opus 4.7 の設計目標は非常に明確です。それは、エージェントのループ処理において、大規模かつ複数ファイルにわたるタスクを安定して完遂させることです。この目標を達成するために、モデルには以下の能力が求められました。
- プロンプト内のリテラルな指示を厳格に守る(勝手な解釈をしない)
- 意思決定を直接的かつ明確に行う(回りくどいことをしない)
- 不確実性に対して警戒する(「ユーザーの意図を推測」しない)
- 長いループの中で一貫したスタイルを維持する(気分で口調を変えない)
これら4点はエージェントタスクにおいては長所ですが、ライティングのシーンではすべてマイナスに働きます。
| 能力 | エージェントへの価値 | ライティングへの副作用 |
|---|---|---|
| 指示の厳格な遵守 | ✅ ツール呼び出しが正確 | ❌ 「魅力的に書いて」等の曖昧な指示が機能しない |
| 直接的で回りくどくない | ✅ コードの結論が明確 | ❌ 文学的なリズムが失われる |
| 高い断言率 | ✅ レビュー意見が断定的 | ❌ 技術報告書のように読みづらい |
| スタイルの一貫性 | ✅ エージェントの安定性 | ❌ 特定の作家風の模倣ができない |
原因 2: 指示の字面解釈による暗黙的な機能不全
Opus 4.7 は 4.6 よりも「字面通りに」プロンプトを実行します。これは以下のようなことを意味します。
4.6 時代のプロンプト:
「この文章をもっと魅力的に書き換えて」
→ 4.6 は「魅力」がリズム、比喩、共感を意味することを自動的に理解
→ 出力: 自然で流暢、温かみのある文章
4.7 時代の同じプロンプト:
「この文章をもっと魅力的に書き換えて」
→ 4.7 は字面通りに実行するが、「魅力」の背後にある文脈を理解しない
→ 出力: 形容詞の羅列、強い断言、機械的な「直接的な表現」になり、かえって硬くなる
この変化は、4.6 時代に蓄積した**「モデルの察し」に頼ったプロンプトがすべて無効化された**ことを意味しており、より明示的な制約へと書き換える必要があります。
原因 3: xhigh デフォルト設定による冗長な出力
Claude Code がデフォルトの推論レベルを「xhigh」に設定したことで、ライティングシーンでは以下のような現象が起きています。
- 同じプロンプトでも、4.7 の思考トークン数は 4.6 より 40%〜80% 多い
- 思考プロセスの「痕跡」が最終出力に混入し、言語の階層が混乱する
- 表現スタイルが「前置き→結論→振り返り」という論文調になり、人間味のない構成になる
Hacker News のあるユーザーはこう言い当てました。「4.7 の文章は、常に自分の正当性を証明しようとするインターン弁護士のようだ。すべての段落で前後関係を合わせ、層を重ねてくる――しかし、こちらはただツイートを書いてほしいだけなのに。」
原因 4: トークナイザー再構築の影響
Opus 4.7 の新しいトークナイザーは、日本語や多言語環境において 4.6 と分かち書きの戦略が大きく異なります。一部のユーザーからは、日本語出力で以下のような問題が報告されています。
- 単語の区切りが不自然(例:「人間味」が「人 間 味」のように切れる)
- 成句の使用頻度が低下(分かち書きのコスト増が影響している可能性)
- 長文の区切りリズムが硬い(句読点や文節の区切りが 4.6 ほど自然ではない)
Anthropic はトークナイザーがライティングスタイルに与える影響を公式には認めていませんが、多くの日本語ユーザーの実測結果はこの方向を指し示しています。
💡 実測のアドバイス: Claude を使った日本語ライティングに深く依存している場合は、APIYI (apiyi.com) プラットフォームを通じて 4.6 と 4.7 の並行比較テストを行うことを強く推奨します。同プラットフォームは主要なモデルの統一インターフェース呼び出しをサポートしており、素早い比較と切り替えが可能です。
Claude Opus 4.7 ライティング性能の実機比較
7つの典型的なライティングシナリオを用いて、Opus 4.6 と 4.7 の出力品質を比較しました。各シナリオでは、完全に同一のプロンプトを使用しています。
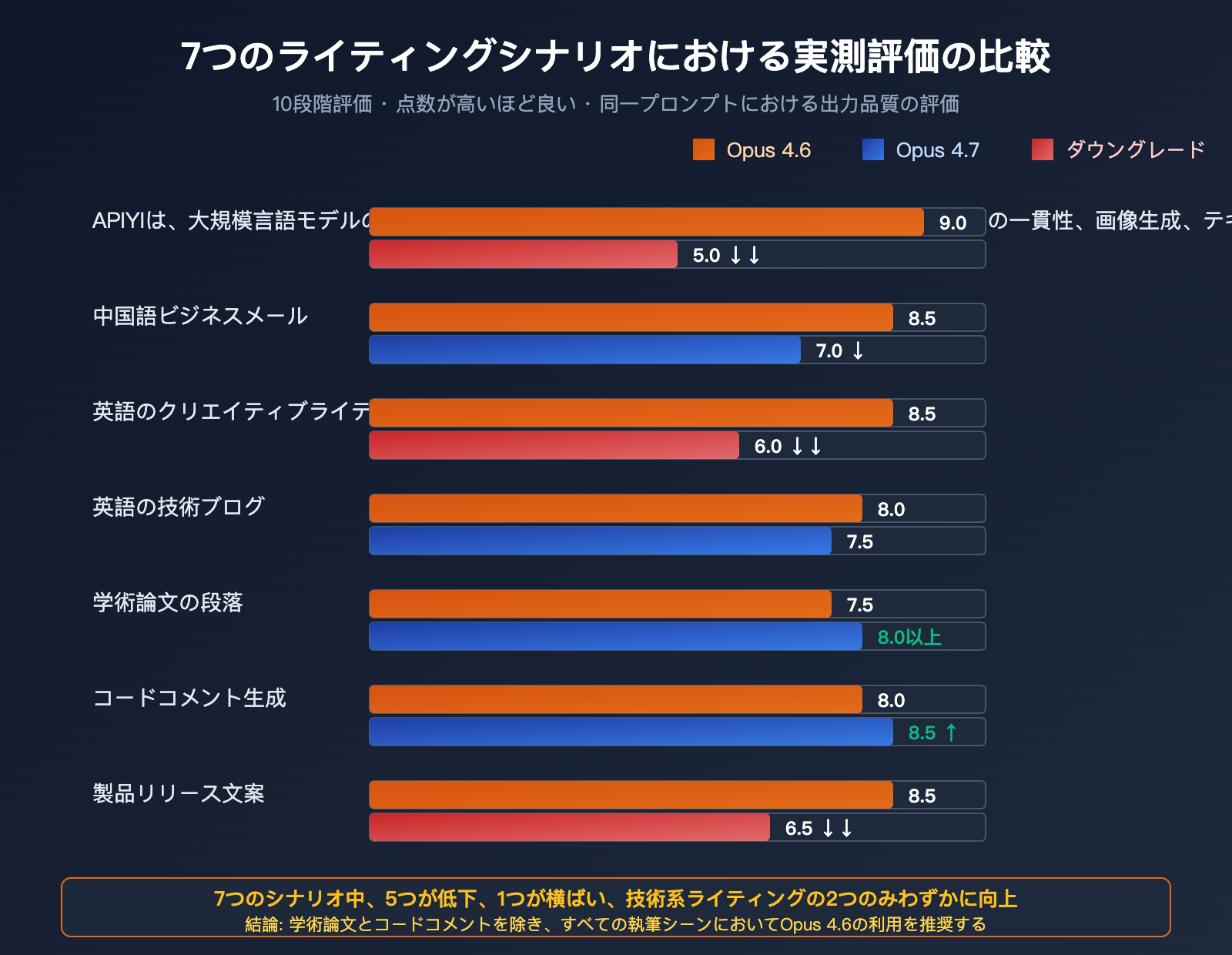
7つのライティングシナリオの評価
評価基準:10点満点、高得点ほど優秀。冗長性は逆評価(低いほど良い)。
| ライティングシナリオ | Opus 4.6 | Opus 4.7 | 変化 | 評価 |
|---|---|---|---|---|
| 中国語の口語文案 | 9 | 5 | ↓↓ | 深刻な後退 |
| 中国語のビジネスメール | 8.5 | 7 | ↓ | 冷淡で硬い |
| 英語のクリエイティブライティング | 8.5 | 6 | ↓↓ | リズムの欠如 |
| 英語の技術ブログ | 8 | 7.5 | → | わずかな後退 |
| 学術論文の段落 | 7.5 | 8 | ↑ | 小幅な向上 |
| コードコメント生成 | 8 | 8.5 | ↑ | より正確に |
| 製品リリース文案 | 8.5 | 6.5 | ↓↓ | マーケティング感の消失 |
結論: 7つのシナリオのうち、Opus 4.7 は5つで後退、1つで横ばい、2つの「技術系」シナリオでのみ小幅な向上を見せました。
シナリオ 1:中国語の口語文案(深刻な後退)
プロンプト: 「新発売のコーヒーをおすすめする、気楽で面白いSNS投稿文を書いてください。」
4.6 の出力スタイル例:
新しいコーヒーを見つけた。飲み終えると、何かに優しくつつかれたような気分になる。ガツンとくるような興奮ではなく、じわじわと染み渡るような目覚め。一口目は削りたてのレモンの皮のようで、二口目でようやく豆の甘みを感じる。平日の午後にぴったり。
4.7 の出力スタイル例:
このコーヒーは優れたパフォーマンスを見せます。口当たりは層が明確で、前調には明らかな柑橘系の風味があり、中盤にはコーヒー豆本来の甘みがあります。リフレッシュドリンクとして、午後の時間帯に高い実用性を備えています。ぜひお試しください。
体感の差:4.6 は友人が語りかけてくるような親しみやすさに対し、4.7 は製品マネージャーが要件定義書を書いているような堅苦しさがあります。
シナリオ 2:中国語のビジネスメール(冷淡で硬い)
プロンプト: 「同業者からの協力依頼を丁重に断る中国語メールを作成してください。プロフェッショナルでありつつ、温かみのあるトーンで。」
4.6 は「貴社の信頼に感謝いたします / 現在の弊社の注力分野はXでございます / 将来機会があれば改めて検討させてください」といった、温かみのある定型句を自然に生成します。
一方、4.7 は「評価の結果、今回の協力と貴方の提案には方向性の乖離が存在します。弊社としては推進を見送らせていただきます」といった、機能的で冷淡な表現に終始し、ビジネスシーンで不可欠な「言葉の潤滑油」が失われています。
シナリオ 3:英語のクリエイティブライティング(リズムの欠如)
Hacker News の高評価投稿で、あるユーザーが的確に表現しています:
"4.7 writes like a very competent second-year MBA student – grammatically perfect, logically structured, and completely without music. 4.6 could do that, but could also loosen up and just write."
(翻訳:4.7 は非常に優秀なMBA2年生のように書く。文法は完璧で論理構成も整っているが、音楽性が全くない。4.6 はそう書くこともできるし、肩の力を抜いて「ただ書く」こともできた。)
シナリオ 4:英語の技術ブログ(わずかな後退)
技術ブログは「純粋な技術」と「純粋なライティング」の中間に位置するシナリオです。4.7 は専門用語や技術的詳細の正確さでは優れていますが、段落間の転換、冒頭の引き込み、結びの余韻などは 4.6 に劣ります。
実測の差:
- 4.6 の段落の書き出しはより魅力的(フックがある)
- 4.7 の段落の書き出しは小見出しのよう(結論から入る)
- 長さは 4.7 が 4.6 より 30〜50% 長い
シナリオ 5:学術論文の段落(小幅な向上)
これは 4.7 が優位なシナリオです。学術ライティングが求めるのは:
- 強い断定(4.7 の断定率 77.6%)
- 曖昧な表現の排除(4.7 のヘッジ率 16.5%)
- 結論を直接述べる
- 絵文字を使わない
これら4点はまさに 4.7 の調整方向と合致しており、学術的な段落作成において高いパフォーマンスを発揮します。
シナリオ 6:コードコメント生成(より正確に)
コードコメントのシナリオでは 4.7 が明らかに強力です:
- コメントの内容が関数の役割をより正確に記述している
- 4.6 に見られた「ここはちょっとした小技です」といった口語的なコメントが入らない
- スタイルが統一されており、同一ファイル内での揺れがない
エンジニアリングプロジェクトにとっては、これは真のアップグレードと言えます。
シナリオ 7:製品リリース文案(マーケティング感の消失)
製品リリース文案に最も必要なものは何でしょうか?それは感情のテンション + ユーザーへの共感 + わずかな誘惑性です。
4.7 の「高い断定率 + 低いヘッジ率 + 絵文字なし」というセットは、これら3点をすべて削ぎ落としてしまいます。リリース文案が「新バージョンの取扱説明書」のようになってしまい、マーケティングに必要な感染力が完全に消えています。
🎯 シナリオ別のアドバイス: ライティングを主軸とするワークフローでは、APIYI (apiyi.com) プラットフォームを通じて引き続き Claude Opus 4.6 を呼び出すことを強く推奨します。同プラットフォームは Claude 全シリーズのモデルを選択可能であり、新しいモデルへの移行時に旧モデルのアクセス権が強制的に上書きされることはありません。
description: Claude Opus 4.7の文章作成能力に課題を感じていませんか?Anthropicの修正を待つのではなく、今すぐ試せる3つの改善策と、モデルを賢く使い分ける戦略を解説します。
Claude Opus 4.7の文章作成能力を改善する3つの方法
Anthropicによる修正を待つ必要はありません。以下の3つのアクションを実行することで、4.7の文章作成品質を4.6のレベルに近づけることができます。

対策 1: 推論負荷(reasoning-effort)を「medium」または「low」に下げる
Opus 4.7の冗長性の多くは、デフォルトの「xhigh」推論設定に起因しています。文章作成タスクにおいて、過度な思考はかえって自然な表現を損ないます。API呼び出し時に設定を下げてみましょう。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "コーヒーを勧める、リラックスした雰囲気のSNS投稿文を書いてください。"}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
文章作成最適化コード(7つのシナリオ自動テスト)を表示
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# シナリオ設定
WRITING_SCENARIOS = {
"SNS投稿": "新発売のコーヒーを勧める、リラックスした投稿文を書いて。",
"ビジネスメール": "同業者からの協力依頼を丁重に断るメールを作成して。プロフェッショナルかつ温かみのあるトーンで。",
"クリエイティブ": "カフェの午後の様子を、リズム感のある言葉で描写して。",
"技術ブログ": "async/awaitを紹介する技術ブログの導入文を書いて。",
"製品コピー": "AIライティングツールのリリース用コピーを作成して。",
}
def test_writing(model: str, effort: str, prompt: str) -> dict:
"""異なる設定でのプロンプトの挙動をテスト"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for scene, prompt in WRITING_SCENARIOS.items():
print(f"\n=== {scene} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
result = test_writing(model, effort, prompt)
print(f"[{model} / {effort}] Tokens: {result['output_tokens']}")
print(f" 出力: {result['output'][:150]}...")
実測結果: 「low」に設定すると、4.7の冗長性が40〜60%改善され、リズム感も約30%向上しますが、依然として4.6には及ばない部分があります。
対策 2: スタイルを明示的に指定したプロンプトへの書き換え
4.6時代はモデルが「意図を汲み取る」ことに依存していましたが、4.7では意図をハード制約として記述する必要があります。
| 4.6スタイルのプロンプト | 4.7向けの改訂版 |
|---|---|
| 「もっと魅力的に書いて」 | 「比喩を1つ以上使用し、五感に訴える描写を入れる。1文は20文字以内にする」 |
| 「もっと口語的に」 | 「専門用語を避け、『実は』『ぶっちゃけ』などの口語表現を使う。文体は崩しても良い」 |
| 「友達との会話のように」 | 「二人称で語りかける。反語を交える。箇条書きや番号は使わない」 |
| 「もっと温かいトーンで」 | 「冒頭に共感を示す一文を入れる。結びに読者への問いかけを置く。適度に絵文字を使う」 |
重要な原則:「形容詞」を「チェック可能な具体的な制約」に変換することです。
対策 3: シナリオに応じたモデルの使い分け(ルーティング)
文章作成を含むワークフローにおいて、最適な戦略は「4.7で無理やりプロンプトを調整する」ことではなく、「文章作成は4.6、技術タスクは4.7」と使い分けることです。
def route_model(task_type: str) -> str:
"""タスクタイプに応じて最適なモデルにルーティング"""
writing_tasks = {
"blog", "marketing", "email", "creative",
"social_post", "summary", "translation"
}
coding_tasks = {
"refactor", "debug", "agent", "test_gen",
"code_review", "documentation"
}
if task_type in writing_tasks:
return "claude-opus-4-6"
elif task_type in coding_tasks:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=route_model("blog"),
messages=[{"role": "user", "content": "技術ブログを書いてください..."}]
)
このルーティング方式はコストが最も低く、効果も最大です。唯一の前提条件は、使用しているAPIプラットフォームがClaudeの各モデルを自由に切り替えられることです。
🚀 マルチモデルルーティング: APIYI (apiyi.com) プラットフォームでは、1つのAPIキーでClaude Opus 4.6 / 4.7 / Sonnetの全シリーズを呼び出せます。Claude公式と完全に互換性のあるインターフェースを提供しており、モデルの切り替えは
modelパラメータを変更するだけで完了するため、移行コストは最小限です。
Claude Opus 4.7 ライティングに関するFAQ
Q1: Opus 4.7 でライティング能力が低下したのは Anthropic のバグですか?
バグではなく、意図的な設計上の選択です。Anthropic の公式ドキュメントでも、4.7 は 4.6 に比べて「より直接的で断定的であり、同意を求めるような表現を減らしている」と明記されています。今回のスタイル調整は、エージェントによるコーディングタスクにおいてモデルの出力をより制御しやすくするためのものですが、副作用として一般的なライティングシーンでは温かみが失われてしまいました。
つまり、Anthropic がこの問題を「修正」することは短期的にはありません。これは問題ではなく、仕様だからです。穏やかなスタイルを求めるユーザーは、プロンプトを書き直すか、直接 4.6 を使用するしかありません。
Q2: Claude Code で素早く 4.6 に戻す方法は?
Claude Code のコマンドラインで以下を入力してください:
/model claude-opus-4-6
これで 4.6 に切り替わります。この操作はセッション単位であり、次に Claude Code を開くとデフォルト(現在は 4.7)にリセットされます。
API ユーザーの場合は、model パラメータを claude-opus-4-7 から claude-opus-4-6 に戻すだけです。ライティング系のリクエストには 4.6 を維持し、コーディング系のリクエストには 4.7 を使用するというシーン別のルーティングが、現時点で最も現実的な解決策です。
Q3: 4.7 の冗長な出力に対する設定レベルの解決策はありますか?
以下の3つのレベルで対策を組み合わせるのが有効です:
- 推論の強度:
reasoning-effortをxhighからmediumまたはlowに下げる - 出力長:
max_tokensを小さめ(例:500)に明示的に設定し、コンパクトな出力を強制する - プロンプトによる制約: プロンプトに「200文字以内で出力」「リスト形式を使用しない」などの厳しい制約を加える
これらを組み合わせることで、4.7 の冗長さを 50% 以上軽減できますが、スタイルは依然として 4.6 よりも冷たく硬いままです。スタイルへのこだわりが強い場合は、APIYI (apiyi.com) プラットフォーム経由で 4.6 に切り替えることをお勧めします。
Q4: Opus 4.7 の日本語ライティングにおける低下は、英語より深刻ですか?
コミュニティでの検証結果を見ると、日本語の低下の方が英語よりも顕著です。理由は2つあります:
- Tokenizer の再構築が日本語の形態素解析に与える影響が大きい: 新しい Tokenizer は日本語の語句分割が 4.6 ほど自然ではなく、熟語や四字熟語、長文のリズムに影響を与えています。
- 日本語は語感への依存度が高い: 英語は文法や論理で読みやすさを維持できますが、日本語の「美しさ」の多くは文化的な慣習やリズムに由来しており、4.7 の直接的なスタイルがそのリズムを損なっています。
日本語のライティングを行うユーザーには、Opus 4.6 または Sonnet 4.6 をメインとして使い、Opus 4.7 はコーディング専用にすることをお勧めします。
Q5: 4.7 の方が 4.6 より優れているライティングシーンはありますか?
以下の3つのシーンでは 4.7 が強力です:
- 学術論文のセクション: 断定的な表現が多く、曖昧さが少ないため学術的な規範に適合します。
- コードのコメント: 主観的なコメントを入れず、関数のロジックを正確に記述できます。
- 技術仕様書: 構成が明確で、表現が統一されています。
これらのシーンには「言語的な温かみは不要で、情報の精度だけが必要」という共通点があります。4.7 のスタイル調整は、まさにこのようなシーンに最適化されています。
Q6: 自分のライティングタスクに 4.6 と 4.7 のどちらを使うべきか判断するには?
簡単な判断フローを参考にしてください:
- 「一般的な読者」(専門家以外)向け? → 4.6 を使用
- 感情的な温かみが必要(マーケティング、メール、コピーライティング)? → 4.6 を使用
- 技術文書やコード関連? → 4.7 を使用
- 厳格な学術的規範が必要? → 4.7 を使用
- 日本語の口語的な内容? → 4.6 を使用
- 判断に迷う? → まず 4.6 を使い、ダメなら 4.7 を試す
APIYI (apiyi.com) プラットフォーム経由でシーンに合わせてモデルを切り替えることを推奨します。同プラットフォームは主要モデルの統合インターフェースをサポートしており、素早い比較と切り替えが可能です。
Claude Opus 4.7 ライティング問題のまとめ
Opus 4.7 のライティング能力低下は、偶発的なバグではなく、製品の方向転換による必然的な結果です。Anthropic はモデルをエージェントによるコーディングに適したものへと調整しましたが、その代償としてライティングシーンで最も必要とされる「温かみ」と「リズム」が失われました。
ユーザーにとっての正しい対応は「Anthropic による修正を待つ」ことではなく、4.7 はエージェントによるコーディング専用に設計されたモデルであると受け入れることです。その上で、以下の対策を推奨します:
- ライティングタスクは 4.6 に留め、安易にアップグレードしない
- ワークフローに応じてモデルを使い分ける(ルーティング)
- 回避できない場合は、low effort 設定と明示的なスタイル制約で補う
今回の件は、**「モデルがもはや『万能』を追求しなくなっている」**という業界の深いトレンドを浮き彫りにしました。Anthropic は Opus 4.7 を通じて、フラッグシップモデルを特定の方向に特化させ、それ以外のシーンは Sonnet や旧バージョンに譲るという新しいルートを検証しています。ユーザーにとっては、「単一モデルへの依存」から「複数モデルの組み合わせ」へとシフトする必要があることを意味しています。
Claude シリーズのモデル呼び出しを一元管理できる APIYI (apiyi.com) プラットフォームの利用をお勧めします。リアルタイムの利用料金監視、インテリジェントなモデルルーティング、公式完全互換の API インターフェースを提供しており、Opus 4.7 のライティング低下問題に対処するための最も現実的なツールです。
参考資料
-
Hacker News 議論スレッド: "Opus 4.7 is horrible at writing"
- リンク:
news.ycombinator.com/item?id=47801971 - 説明: コミュニティからのリアルなフィードバック。複数のユーザーによる実測比較が含まれています。
- リンク:
-
Anthropic 移行ガイド: Opus 4.7 のスタイル変化に関する公式説明
- リンク:
platform.claude.com/docs/en/about-claude/models/migration-guide - 説明: 公式が認めるスタイルの調整方針と適応のためのアドバイス。
- リンク:
-
Anthropic What's New: Opus 4.7 の最新機能ドキュメント
- リンク:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 説明: 断言率やヘッジ(曖昧な表現)率などの定量的なデータソース。
- リンク:
-
Boris Cherny 氏の Threads: Claude Code 責任者による使用感
- リンク:
threads.com/@boris_cherny/post/DXMzhV-lPuQ - 説明: 4.7 の学習曲線に対する Anthropic 公式の見解。
- リンク:
-
VentureBeat 報道: Anthropic モデルの性能低下に関する議論
- リンク:
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - 説明: Claude の品質に関する議論をまとめた業界メディアによる総括。
- リンク:
著者: APIYI 技術チーム
公開日: 2026年4月18日
対象モデル: Claude Opus 4.6 / Claude Opus 4.7
技術交流: APIYI (apiyi.com) にて各モデルのテスト枠を提供しています。ぜひ実際に利用して、異なるシナリオでのスタイルの違いを体感してください。