
Google DeepMindが2025年11月20日にNano Banana Proを発表した際、彼らは繰り返しこう強調しました。「untouched areas remain pixel-perfect — no generation drift, no quality loss across iterative edits(未編集領域はピクセル単位で完璧に維持される。生成のズレはなく、反復編集による品質低下も発生しない)」。これを文字通りに受け取れば、AIが「Photoshopのような真の局部修正」を実現したことになります。しかし、Gemini 3 Pro Imageのアーキテクチャを知る者からすれば、それは本質的に「自己回帰型Transformerによる画像全体の再描画」であり、テキストモデルが次のトークンを予測するのと同じメカニズムであることに気づくはずです。
この一見矛盾する二つの事実は、どのようにして両立しているのでしょうか?Nano Banana Proの画像生成原理は、画像を再描画しているのか、それとも真の局部修正を行っているのか。本稿では、Gemini 3の推論バックボーン、視覚トークンの自己回帰、マスクによるハード制約、バウンディングボックスによる意味的特定という4つの側面から深く解剖し、エンジニアが実務で活用できる原理的知見を提供します。

| 核心問題 | 直感的な答え | 真相 |
|---|---|---|
| Photoshopのような局部修正か? | はい | いいえ、基盤は依然として画像全体のトークン再描画 |
| なぜピクセル単位で完璧なのか? | モデルが賢いから | マスク+意味的特定+BBoxの3層ハード制約 |
| GPT-Image-2と同源か? | 類似 | どちらも自己回帰だが、Gemini 3は明示的な推論を追加 |
| 多段階編集で漂移するか? | する | ほぼしない、これがProの核心的な売り |
この基盤ロジックを理解して初めて、Gemini 3の推論を真に活性化させるプロンプトを作成し、適切なマスクモードを選択し、「局部修正に見えて実は再描画」という罠を回避できるようになります。読者の皆様には、APIYI(apiyi.com)プラットフォーム上のNano Banana Proインターフェースで実際に試しながら読み進め、各原理を実際の生成結果と照らし合わせることをお勧めします。
Nano Banana Proの画像生成原理:全画像再描画か、真の局部修正か?
この問いに答える前に、混同しやすい2つの事柄を整理しましょう。それは「生成メカニズム」と「使用体験」です。
生成メカニズムの観点から見ると、Nano Banana Proは、その前身であるNano BananaやOpenAIのGPT-Image-2と同じ路線、すなわち「自己回帰型Transformerによる画像全体のトークン再描画」を採用しています。言い換えれば、たとえAIにネクタイの色を一つ変えるよう指示したとしても、モデル内部では依然として画像全体を視覚トークンに圧縮し、最初から最後までトークンシーケンスを再予測し、最後にピクセルへとデコードしているのです。「一部のピクセルだけを動かし、残りはそのままにする」という物理的なパスは存在しません。
しかし、使用体験の観点で見ると、Nano Banana Proはユーザーに「真の局部修正に近い」感覚を与えます。Googleは公式に、マスクモードや意味的な特定において、未編集領域はほぼピクセルレベルで維持され、生成のズレはなく、反復編集による品質低下も発生しないと明言しています。この体験は、どのようにして「全画像再描画」という基盤アーキテクチャから捻り出されているのでしょうか?
答えは「制約エンジニアリング(constraint engineering)」です。 Googleは自己回帰生成プロセスの上に、マスクトークンのロック、バウンディングボックスによる領域指定、Gemini 3による意味的な「保持リスト」という3層のハード制約を重ねています。これらの制約により、モデルは再描画時に未編集領域のトークンを「意図的に選択して再現」するようになります。これこそが、Nano Banana Proのエンジニアリングチームが成し遂げた真の功績です。
再描画ロジックと局部修正体験の関係
| 視点 | 実態 | ユーザーの体感 |
|---|---|---|
| 基盤アーキテクチャ | 画像全体のトークン再描画 | 局部修正のように見える |
| 未編集領域 | 再生成されたトークン | 原画像とほぼ同じピクセル |
| 編集境界 | 自己回帰による連続生成 | 自然な移行、アーティファクトなし |
| 編集指示 | 制約を通じて入力 | 光影や視点を自動的に適合 |
この「メカニズムと体験」の分離を理解すれば、なぜNano Banana Proで編集した後に、非編集領域に極めてわずかな変化が生じることがあるのかを説明できます。それはトークン再描画の必然的な代償ですが、Googleは制約を駆使することで、その変化を肉眼ではほぼ感知できないレベルまで抑え込んでいます。APIYI(apiyi.com)でNano Banana Proを使い、同一画像を繰り返し編集して詳細のズレを観察してみてください。このような比較こそが、原理への理解を深める鍵となります。
Nano Banana Pro の実装原理:Gemini 3 Pro Image の自己回帰バックボーン
Nano Banana Pro の実装原理を深く理解するには、その正式名称である「Gemini 3 Pro Image」に注目する必要があります。この名称には、Gemini 3 推論バックボーンと画像生成デコーダーという2つの核心的な血統が示されています。
Gemini 3 は、Nano Banana Pro の発表のわずか2日前に Google がリリースしたフラッグシップ級のマルチモーダル大規模言語モデルであり、「推論能力」の高さで知られています。Nano Banana Pro は、Gemini 3 Pro の Transformer バックボーンをそのまま活用し、語彙リストに視覚トークンを追加して、出力側に画像デコーダーを接続したものです。言い換えれば、これは独立した画像モデルではなく、Gemini 3 マルチモーダルファミリーにおける画像生成に特化した形態なのです。
これにより、根本的な変化が生まれました。Nano Banana Pro は、最初のピクセルを描画する前に、まず Gemini 3 を使って「何を描くべきか」を推論します。Google 公式の言葉を借りれば、「従来の拡散モデルのように機能するのではなく、デジタルアートディレクターのように機能する」のです。つまり、プロンプトのセマンティックな論理、物理的な因果関係、空間的な関係性を分析してから、視覚トークンの生成段階へと移行します。
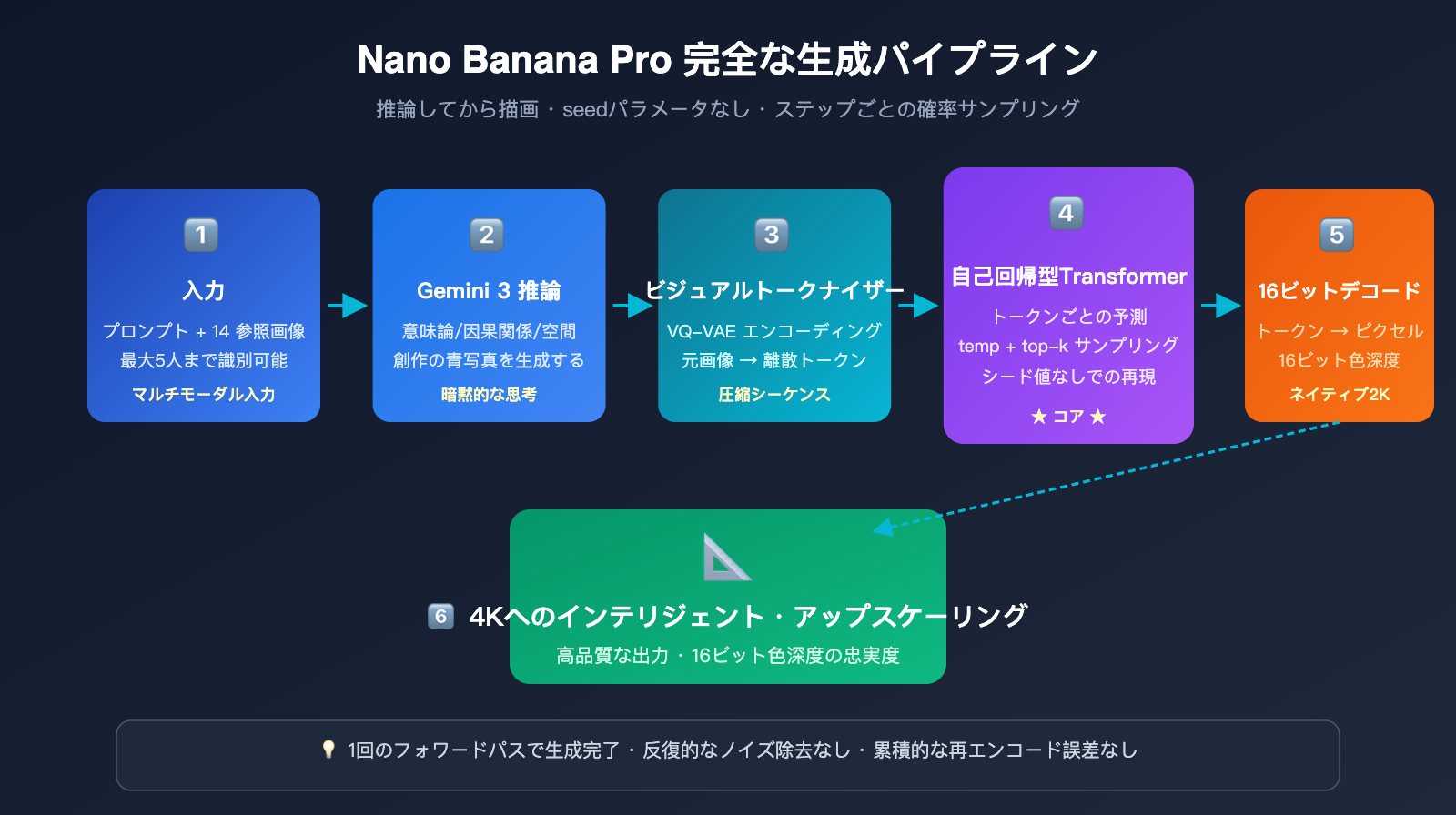
具体的なワークフローは、以下の5つの段階に分けられます。
- マルチモーダル入力解析: Gemini 3 推論バックボーンが、ユーザーのテキストプロンプトと最大14枚の参照画像を同時に取り込み、タスク全体のコンテキストを理解します。
- 構造化推論(内部ブループリント): モデルはまず内部で、画面の空間レイアウト、人物のアイデンティティ、照明設定、保持または修正すべき箇所を「明確に考え」、目に見えない「創作ブループリント」を生成します。
- 参照画像視覚トークンエンコーディング: 参照画像は、VQ-VAE に似た離散化メカニズムを通じて視覚トークンシーケンスに圧縮されます。
- 自己回帰トークン予測: Gemini 3 バックボーンのアテンションメカニズムの下で、モデルは左から右へと出力画像の各視覚トークンを逐次予測します。各ステップで、完全なプロンプトトークンと参照画像トークンを「参照」できます。
- デコードとアップサンプリング: 出力トークンは16ビット色深度のデコーダーを通じてネイティブな2K画像に復元され、さらにインテリジェントに4Kまでアップサンプリングされます。
Gemini 3 推論バックボーンの2つの独自能力
1つ目は**「考えてから描く」**能力です。これは単なる宣伝文句ではありません。Gemini 3 のテキストタスクにおける推論能力が、そのまま画像生成に移行されています。「この人の服を、職業にふさわしい服装に変えて」という複雑な指示を与えた場合、通常の画像モデルは混乱しますが、Nano Banana Pro は「この人は医者に見える → 白衣であるべきだ」と推論してから描画を行います。
2つ目は**「Google 検索によるグラウンディング」**です。Nano Banana Pro は生成プロセス中に Google 検索ツールを呼び出し、事実を確認できます。例えば、「あるブランドの最新製品」を描かせる際、ネット経由で実際の外観を参照できます。これは現在、ネイティブな検索グラウンディングをサポートする唯一の画像生成モデルであり、Nano Banana Pro と GPT-Image-2 の最大の違いの一つです。もし本番環境でグラウンディング能力をテストする必要がある場合は、APIYI (apiyi.com) を通じて Nano Banana Pro にアクセス可能です。このプラットフォームは、Google 公式と一致するインターフェース仕様を提供しています。
特筆すべき点として、Nano Banana Pro は seed パラメータをサポートしていません。自己回帰生成であるため、各ステップのサンプリングは確率分布から行われる(temperature と top-k によって制御される)ため、拡散モデルのように初期ノイズを固定して結果を完全に再現することはできません。この特性は制約でもありますが、モデルの創造性を維持するための設計上の選択でもあります。
AI画像の部分編集における4つの制約メカニズム:Pixel-Perfectはいかにして実現されるか
その根底にあるのが画像全体の再描画であるにもかかわらず、Nano Banana Proはなぜ未編集領域でPixel-Perfect(画素単位の完璧さ)に近い品質を保証できるのでしょうか?その答えは、GoogleがAI画像の部分編集シナリオにおいて、4層の制約メカニズムを重ね合わせている点にあります。これこそが、Pro版がベース版のNano Bananaと比較して最も注目すべきエンジニアリング上の革新です。
第1層:Mask(マスク)によるハード制約。これが最も直接的な手法です。ユーザーが同じサイズの白黒マスク画像を提供すると、白い領域ではAIによる新しいトークンの生成が許可され、黒い領域では出力されるトークンが元の画像の対応する位置のトークンを強制的にコピーするよう求められます。これは、自己回帰生成時にモデルへ「ハードコピー規則」を課すことに相当します。これこそが、Googleが言うところの「pixel-perfect untouched areas(未編集領域の画素単位の完璧さ)」の核心的な技術的根拠です。
第2層:Bounding Box(バウンディングボックス)による領域指定。Nano Banana Proは、座標を0〜1000の範囲で正規化したBounding Boxパラメータをサポートしています。これにより、「(200, 300) から (600, 500) の矩形領域内のみを変更する」といった指示が可能です。システムは自動的にBBoxを内部のマスク制約へと変換するため、手動でマスクを描画するよりもはるかに手軽です。
第3層:Gemini 3によるセマンティック(意味的)な位置特定。これが最も「魔法」のような層です。自然言語で「背景をビーチに変えて」と指示するだけで、Gemini 3の推論バックボーンが画像内のどのトークンが「背景」に該当するかを自動的に識別し、暗黙的なマスクを生成します。このマスク不要の編集モードは、Googleが公式に述べている「ほとんどの編集シナリオ」をカバーしています。
第4層:学習データにおける「言及なきは維持」というバイアス。Googleは膨大な「元画像と編集後画像」のペアデータを使用し、学習過程でモデルに一つの暗黙的なルールを学ばせました。それは「プロンプトで明示的に変更を要求されない限り、他の領域は可能な限りトークン単位で元画像をコピーする」というものです。このバイアスは重みに固定されており、推論時に自動的に適用されます。
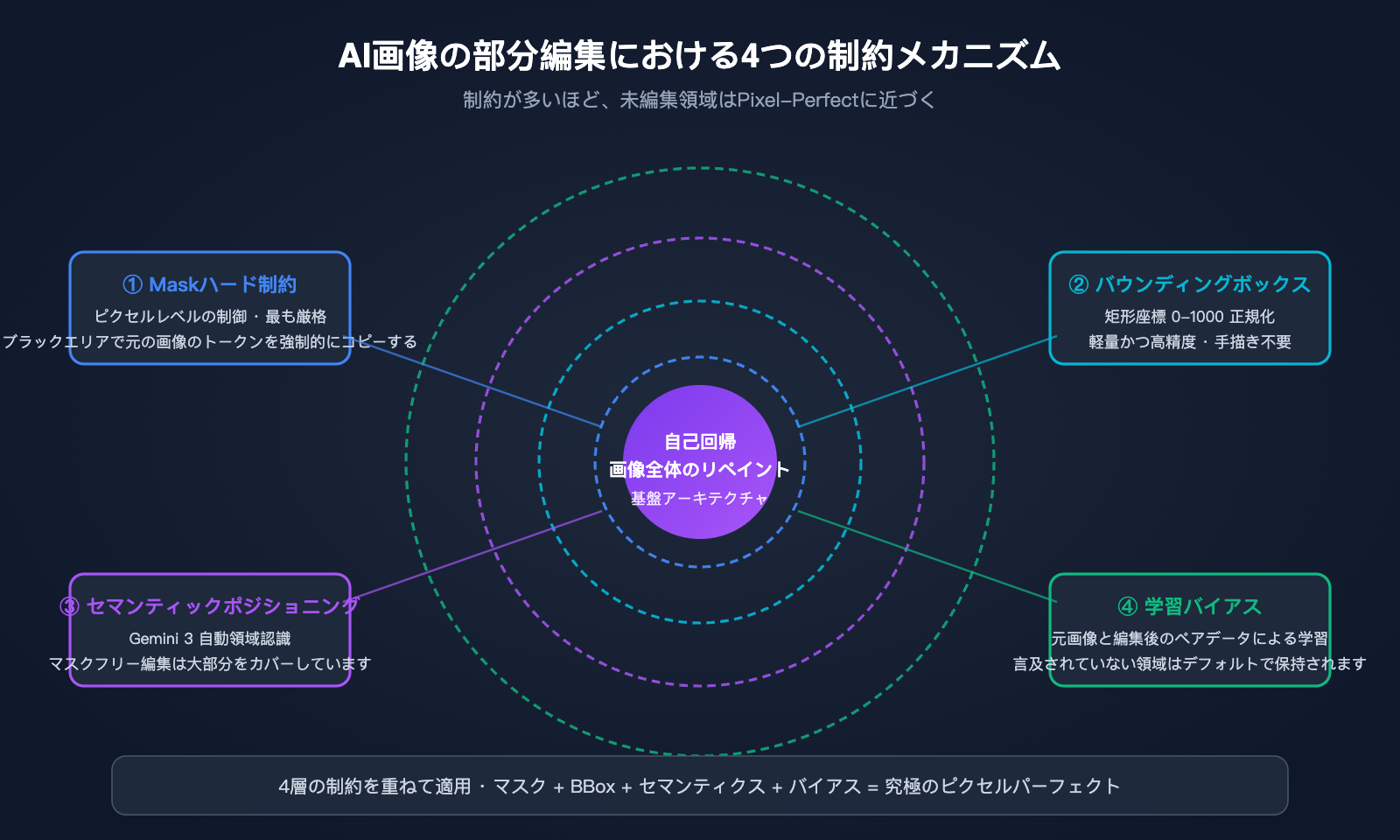
4つの制約メカニズムの比較
| 制約メカニズム | 制御粒度 | ユーザーコスト | 適用シナリオ |
|---|---|---|---|
| Maskハード制約 | 画素レベル | マスク描画が必要 | 精密な修復/切り抜き・置換 |
| Bounding Box | 矩形領域 | 座標指定のみ | 矩形領域が明確な編集 |
| セマンティック定位 | 意味的対象 | テキスト指示のみ | ほとんどの日常的な編集 |
| 学習バイアス | 全体 | 設定不要 | 全てのシナリオでデフォルト有効 |
これら4層の制約は排他的なものではなく、重ね合わせて機能します。最も厳格な組み合わせは「Mask + Bounding Box + セマンティック指示」であり、これによりNano Banana ProのPixel-Perfectな体験を極限まで高めることができます。APIYI(apiyi.com)でのテストでは、セマンティック定位と学習バイアスのみを使用した場合でも、日常的な編集のほとんどにおいて、肉眼では判別できないほどの一貫性が得られることが確認されました。
多段階編集でも漂流しないエンジニアリングの理由
Nano Banana Proのマーケティング上の重点の一つは「多段階編集でも累積的な品質損失がない」ことです。理由は2つあります。第一に、自己回帰アーキテクチャ自体が拡散モデルのようにVAEによる繰り返しのエンコード・デコードを必要とせず、トークンから画素への変換が一度きりであるため、再エンコードによる誤差が蓄積しません。第二に、Maskによるハード制約が未編集領域でトークン単位のコピーを維持するため、何度反復しても新たなランダム性がほとんど導入されません。
これは、従来のStable Diffusionでインペインティングを繰り返すと画像が「ぼやけて」しまう現象とは対照的です。もしワークフローにおいて、同一のベース画像に対して5〜10回の反復編集が必要な場合、Nano Banana Proは現在、それに耐えうるほぼ唯一のモデルと言えます。
Gemini 3 Pro Image vs GPT-Image-2:2つの路線の違い
多くのチームがGemini 3 Pro Image(Nano Banana Pro)とOpenAIのGPT-Image-2の両方に注目しています。両者とも根底には自己回帰モデルを採用していますが、その位置付けや能力にはそれぞれ特徴があります。
GPT-Image-2は「Thinkingモード」とテキスト描画の正確性(公式で約99%)を強調しており、複数オブジェクトのレイアウトや長文を含むシーンを得意とします。一方、Nano Banana ProはGemini 3の推論バックボーン、4K出力、14枚のマルチ画像融合、5人までの人物の一貫性保持、そして独自の「Google検索によるグラウンディング(根拠付け)」に強みを持っています。
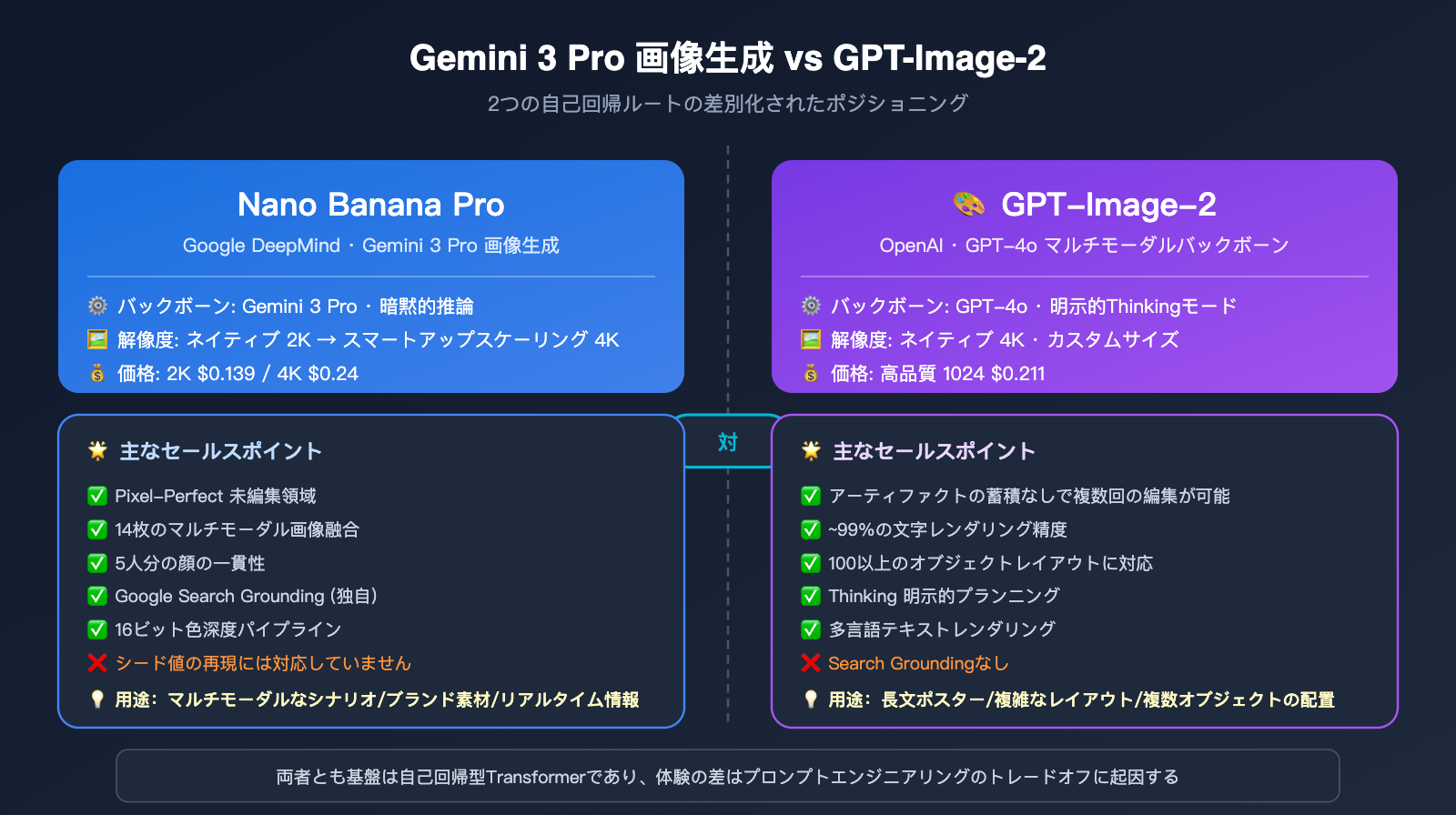
両者のNano Banana Pro画像生成原理とGPT-Image-2の実現経路における重要な違いは、以下の表で確認できます。
| 項目 | Nano Banana Pro | GPT-Image-2 |
|---|---|---|
| 基盤モデル | Gemini 3 Pro | GPT-4o マルチモーダル |
| 推論強化 | Gemini 3 暗黙的推論 | 明示的なThinkingモード |
| 最高解像度 | 4K (2Kからのアップサンプリング) | 4K ネイティブ |
| マルチ画像入力上限 | 14枚 | 複数枚 (上限非公開) |
| 人物の一貫性 | 最大5人まで同時 | 強力、人数上限非公開 |
| テキスト描画 | 業界トップクラス、多言語対応 | 99%の正確性 |
| リアルタイム情報 | ✅ Google検索グラウンディング | ❌ |
| Seedパラメータ | ❌ 非対応 | 一部制御可能 |
| 部分編集の強み | 未編集領域のPixel-perfect | 多段階でも漂流なし |
| 単一画像価格 | 2K $0.139 / 4K $0.24 | 高品質 1024 $0.211 |
選定のアドバイス:判断基準は主に2点です。ブランド素材、製品画像、複数キャラクターの合成シーンが必要な場合は、Nano Banana Proのマルチ画像融合と人物の一貫性が適しています。一方、長文ポスター、複雑なレイアウト、100以上のオブジェクト配置が中心となる場合は、GPT-Image-2のThinkingモードの方が安定する可能性があります。APIYI(apiyi.com)プラットフォームを通じて両モデルを接続し、実際のシナリオで小規模なA/Bテストを行ってからメインモデルを決定することをお勧めします。
Nano Banana Pro API 実践:マスクからバウンディングボックスまでの全シナリオ
仕組みを理解したところで、Nano Banana Pro のAI画像局部編集能力を実戦で活用する方法を見ていきましょう。以下は、APIYIの互換エンドポイントを通じて Gemini 3 Pro Image を呼び出すための最小構成の Python サンプルです。
from google import genai
from PIL import Image
# APIYIのクライアント設定
client = genai.Client(
api_key="your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1"}
)
original = Image.open("portrait.png")
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"人物のアイデンティティと背景はそのままに、上着を白いTシャツから濃紺のスーツジャケットに変更してください。元の光の当たり方と影の方向を維持してください。",
original
]
)
# 結果を保存
for part in response.candidates[0].content.parts:
if part.inline_data:
with open("edited.png", "wb") as f:
f.write(part.inline_data.data)
プロンプトの書き方に注目してください。「何を変えないか」「何を修正するか」「元の光の当たり方を維持する」と明示することが、Gemini 3 の推論バックボーンのセマンティックな位置特定能力を直接引き出す鍵となります。より精密な領域制御が必要な場合は、バウンディングボックスのプロンプトを追加できます。
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"画像のバウンディングボックス [200, 150, 600, 700] の範囲内で、服装を濃紺のスーツジャケットに置き換えてください。その他の領域は元の画素を維持してください。",
original
]
)
座標は 0〜1000 の正規化範囲を採用しており、実際の処理時に画像サイズに合わせてマッピングされます。さらに厳密な制御が必要な場合は、マスク画像を別途入力として追加することも可能です。
実戦最適化のための5つの経験則
Nano Banana Pro の実装原理をエンジニアリングに落とし込む際、以下の5つのアドバイスをまとめました。
- プロンプトには常に「維持するリスト」を明記する: 「人物、背景、光の当たり方を維持」と書くことが、4層の制約を有効化する鍵です。
- セマンティックな位置特定を優先する: 編集境界にピクセル単位の精度が求められない限り、マスクなしモードの方が効率的です。
- 複数画像の統合は14枚まで: 公式の上限を超えると切り捨てられ、複数画像の一貫性に影響が出ます。
- 2Kと4Kの使い分け: Webやモバイル表示用なら 2K ($0.139) で十分です。印刷や大型ディスプレイ用には 4K ($0.24) を使いましょう。
- シード値での再現は試さない: Nano Banana Pro はシード値をサポートしていません。安定した再現が必要な場合は、プロンプトの重み付けと参照画像の固定で対応してください。
料金とシナリオの適合表
| 設定 | 1枚あたりのコスト | 推奨シナリオ |
|---|---|---|
| 2K 単一画像 | $0.139 | ソーシャルメディア/Web用画像 |
| 4K 単一画像 | $0.24 | 印刷物/大画面展示/マーケティング用メインビジュアル |
| 4K + 14枚統合 | $0.24 + 入力トークン | ブランドの複数キャラクター合成 |
| 4K + Grounding | $0.24 + 検索トークン | リアルな製品/イベント用画像 |
本番環境では、APIYI (apiyi.com) の Batch API を使用してバッチ処理を行うことを推奨します。品質を維持しながらコストを大幅に削減できるため、素材ライブラリの大量生成に適しています。
Nano Banana Pro 画像生成原理 FAQ と意思決定のヒント
Q1: Nano Banana Pro は描画ですか、それとも局部修正ですか?
A: 根本的には「自己回帰による全画像トークンの再描画」、つまり「描画」です。しかし、マスクのハード制約、バウンディングボックス、Gemini 3 のセマンティックな位置特定、学習バイアスという4層の制約により、使用感として「真の局部修正」に近い効果を実現しています。アーキテクチャは再描画、エンジニアリングはロックという関係性です。
Q2: なぜ公式は未編集領域が「ピクセルパーフェクト」だと言っているのですか?
A: マスクモードでは、黒い領域の出力トークンは元の画像の対応する位置のトークンと等しくなるよう強制されます。デコード後の画素はほぼ同じになりますが、厳密には VQ-VAE のエンコード・デコードで微小な損失が発生するため、数学的に完全に同一ではなく「極めて近い」状態です。日常的な使用において肉眼で判別することは不可能です。
Q3: なぜ Nano Banana Pro はシード値をサポートしていないのですか?
A: 自己回帰生成はステップごとに確率分布からサンプリングを行うため、拡散モデルの初期ノイズを固定する仕組みとは全く異なります。Google はシード値パラメータを公開せず、モデルの創造性と多様性を維持する方針をとっています。結果を安定させたい場合は、詳細なプロンプトと参照画像の組み合わせを使用してください。APIYI (apiyi.com) で異なるプロンプトテンプレートの出力安定性をテストし、ワークフローに適した「準確定的な」組み合わせを見つけることをお勧めします。
Q4: Nano Banana Pro と GPT-Image-2 はどう使い分けるべきですか?
A: 複数キャラクターのシナリオ、ブランド素材、リアルタイム情報 (Grounding) が必要な場合は Nano Banana Pro を選んでください。複雑なレイアウト、長文のポスター、100以上のオブジェクト配置が必要な場合は GPT-Image-2 が適しています。どちらも自己回帰型ですが、体験の差は Google と OpenAI の異なる制約エンジニアリングの選択によるものです。
Q5: マスクなしで編集領域を正確に指定できますか?
A: 可能です。2つの方法があります。1つはバウンディングボックスパラメータ(0-1000の正規化座標)を使用すること。もう1つは Gemini 3 の推論バックボーンのセマンティックな位置特定に頼ることで、プロンプトに「画像右下の赤い物体を修正して」と書くだけで済みます。後者はほとんどのシナリオをカバーし、前者は矩形領域を明確にしたい場合に使用します。
Q6: Grounding with Google Search は実際どう使うのですか?
A: プロンプト内で事実確認が必要な要素を明確にします。例えば「月面にいるテスラの2025年最新型サイバートラックの画像を描いて」と指示すると、モデルが自動的に Google 検索を呼び出して実際の外観を参照し、生成プロセスに入ります。これは Nano Banana Pro 独自の能力であり、GPT-Image-2 には現在対応する機能がありません。
まとめ:制約エンジニアリングを理解し、Nano Banana Pro を使いこなす
Nano Banana Pro は、エンジニアリングの観点から非常に精巧な製品です。新しい画像生成パラダイムを発明したわけではなく、Gemini 3 の自己回帰バックボーンの上に、4層の制約エンジニアリングを重ねることで、「全画像再描画」という基礎アーキテクチャを「真の局部修正に近い」製品体験へと昇華させています。
この「メカニズムと体験の分離」という認識を持つことで、4層の制約を有効化するプロンプトを正確に記述し、適切な編集モードを選択し、多段階の反復ワークフローを計画できるようになります。Nano Banana Pro の画像生成原理の核心は、特定のブラックテクノロジーではなく、制約エンジニアリングのフルスタックな連携にあります。
APIYI (apiyi.com) プラットフォームを通じて実戦的なテストと比較を行うことを推奨します。同プラットフォームは Nano Banana Pro、GPT-Image-2、Stable Diffusion など複数の主要モデルの統一インターフェース呼び出しをサポートしており、本記事で紹介した原理や最適化テクニックを迅速に検証し、本番環境に最適なモデル選定を行うのに役立ちます。
本記事は APIYI チームが Google DeepMind、Vertex AI などの公式資料および現場での実測に基づき作成しました。本番環境で Gemini 3 Pro Image (Nano Banana Pro) を呼び出す必要がある場合は、APIYI 公式サイト (apiyi.com) にアクセスして接続ドキュメントをご確認ください。