
Vous voulez que l'IA « réfléchisse d'abord, puis réponde » comme un être humain ? Le mode Gemini Thinking est la toute dernière fonctionnalité de raisonnement approfondi lancée par Google, permettant au modèle d'afficher l'intégralité de son cheminement intellectuel avant de fournir une réponse. Cet article vous explique en détail comment configurer correctement le mode Gemini Thinking dans deux clients IA populaires : Cherry Studio et Chatbox.
Valeur ajoutée : En lisant cet article, vous apprendrez à activer le mode de réflexion Gemini dans Cherry Studio et Chatbox, à visualiser le processus de raisonnement du modèle et à optimiser la résolution de tâches complexes.
Points clés du mode Gemini Thinking
Le mode Gemini Thinking est une fonctionnalité de raisonnement profond introduite par Google dans les séries de modèles Gemini 2.5 et 3. Contrairement à une conversation classique, le mode Thinking permet au modèle d'effectuer un raisonnement interne avant de fournir sa réponse finale, ce qui améliore considérablement la précision sur des tâches complexes.
| Point clé | Description | Valeur |
|---|---|---|
| Visualisation de la pensée | Affiche le processus de raisonnement du modèle | Comprendre comment l'IA arrive à sa conclusion |
| Raisonnement boosté | Raisonnement logique en plusieurs étapes | Résoudre des problèmes complexes de maths et de code |
| Profondeur contrôlable | Ajuster le budget de tokens de réflexion | Équilibrer la vitesse et la précision |
| Compatibilité modèles | Séries Gemini 2.5/3 complètes | Choix flexible selon le cas d'usage |
Modèles supportant le mode Gemini Thinking
Voici les modèles Gemini supportant actuellement le mode Thinking :
| Nom du modèle | ID du modèle | Paramètre de réflexion | Comportement par défaut |
|---|---|---|---|
| Gemini 3 Pro | gemini-3-pro-preview |
thinking_level | Réflexion dynamique (HIGH) |
| Gemini 3 Flash | gemini-3-flash-preview |
thinking_level | Réflexion dynamique (HIGH) |
| Gemini 2.5 Pro | gemini-2.5-pro |
thinking_budget | Dynamique (8192 tokens) |
| Gemini 2.5 Flash | gemini-2.5-flash |
thinking_budget | Dynamique (-1) |
| Gemini 2.5 Flash-Lite | gemini-2.5-flash-lite |
thinking_budget | Désactivé par défaut (0) |
🎯 Conseil technique : Pour vos projets, nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour appeler les modèles Gemini Thinking. Elle propose une interface compatible avec le format OpenAI, vous évitant de gérer les processus complexes d'authentification de Google API.
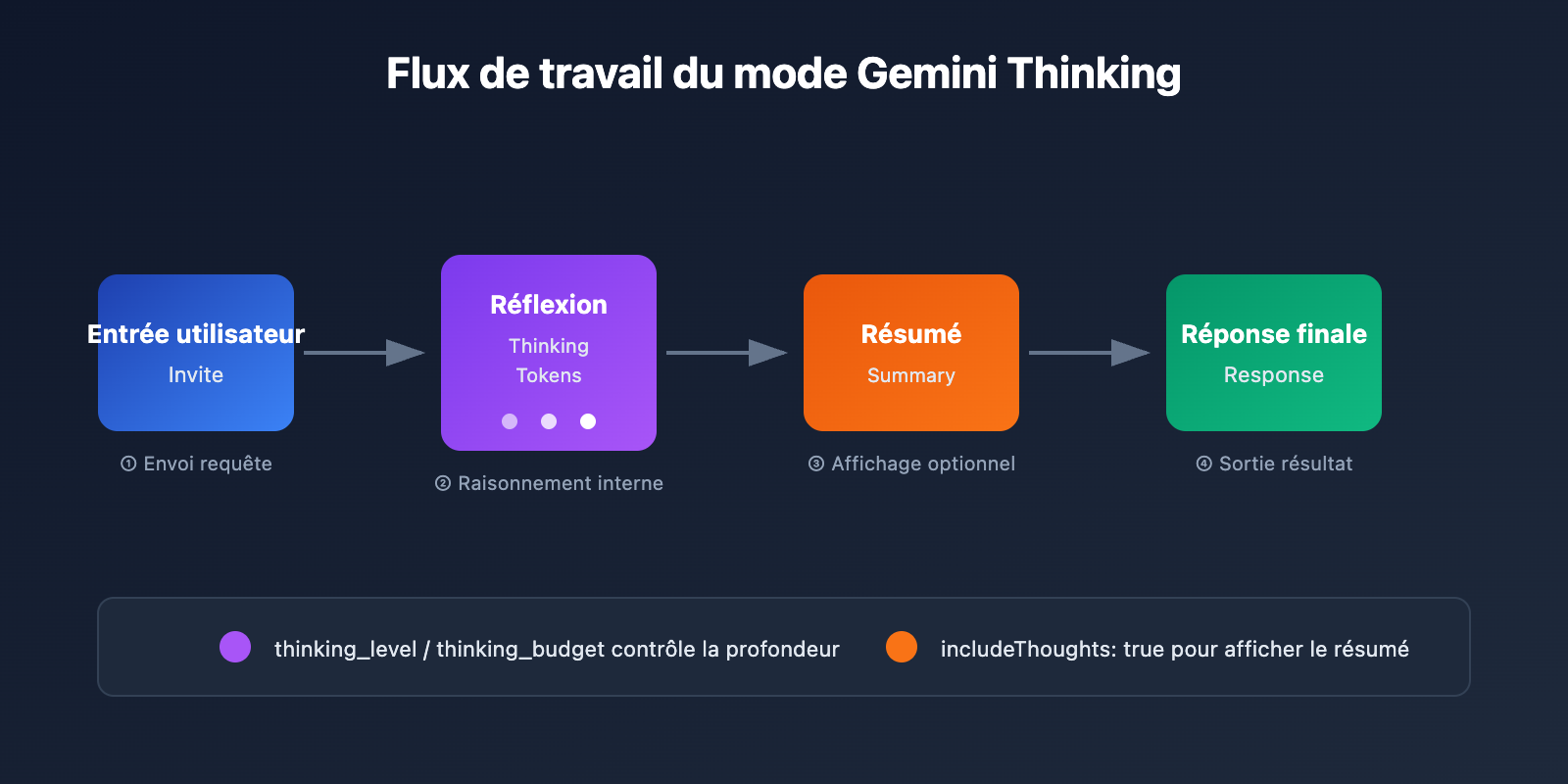
Détails des paramètres API du mode Gemini Thinking
Les différentes versions des modèles Gemini utilisent des paramètres de contrôle de réflexion distincts :
Série Gemini 3 – Paramètre thinking_level
| Niveau | Description | Cas d'utilisation |
|---|---|---|
minimal |
Réflexion minimale | Questions-réponses simples |
low |
Réflexion faible | Conversations quotidiennes |
medium |
Réflexion modérée | Raisonnement général |
high |
Réflexion profonde (par défaut) | Tâches complexes |
Série Gemini 2.5 – Paramètre thinking_budget
| Valeur | Description | Cas d'utilisation |
|---|---|---|
0 |
Désactiver la réflexion | Réponse rapide |
-1 |
Réflexion dynamique (recommandé) | Ajustement automatique |
128-32768 |
Nombre de tokens spécifié | Contrôle précis |
Configuration du mode Gemini Thinking dans Cherry Studio
Cherry Studio est un client IA puissant qui prend en charge plus de 300 modèles et de nombreux fournisseurs d'IA. Voici les étapes détaillées pour configurer le mode Gemini Thinking dans Cherry Studio.
Étape 1 : Ajouter le fournisseur d'API Gemini
- Ouvrez Cherry Studio, allez dans Paramètres → Fournisseurs
- Trouvez Gemini ou Fournisseur personnalisé
- Entrez les informations de configuration de l'API :
Adresse API : https://api.apiyi.com/v1
Clé API : Votre clé APIYI
💡 Conseil de configuration : En utilisant APIYI (apiyi.com) comme adresse API, vous bénéficiez d'un accès plus stable et d'un format d'interface unifié.
Étape 2 : Ajouter les modèles Gemini Thinking
Cliquez sur le bouton « Gérer » ou « Ajouter » en bas pour ajouter manuellement les modèles suivants :
| Nom du modèle à ajouter | Description |
|---|---|
gemini-3-pro-preview |
Gemini 3 Pro (version Thinking) |
gemini-3-flash-preview |
Gemini 3 Flash (version Thinking) |
gemini-2.5-pro |
Gemini 2.5 Pro (version Thinking) |
gemini-2.5-flash |
Gemini 2.5 Flash (version Thinking) |
Étape 3 : Activer l'interrupteur du mode Thinking
Dans l'interface de discussion :
- Cliquez sur l'icône de paramètres en haut à droite
- Trouvez l'option Thinking Mode
- Basculez l'interrupteur sur ON
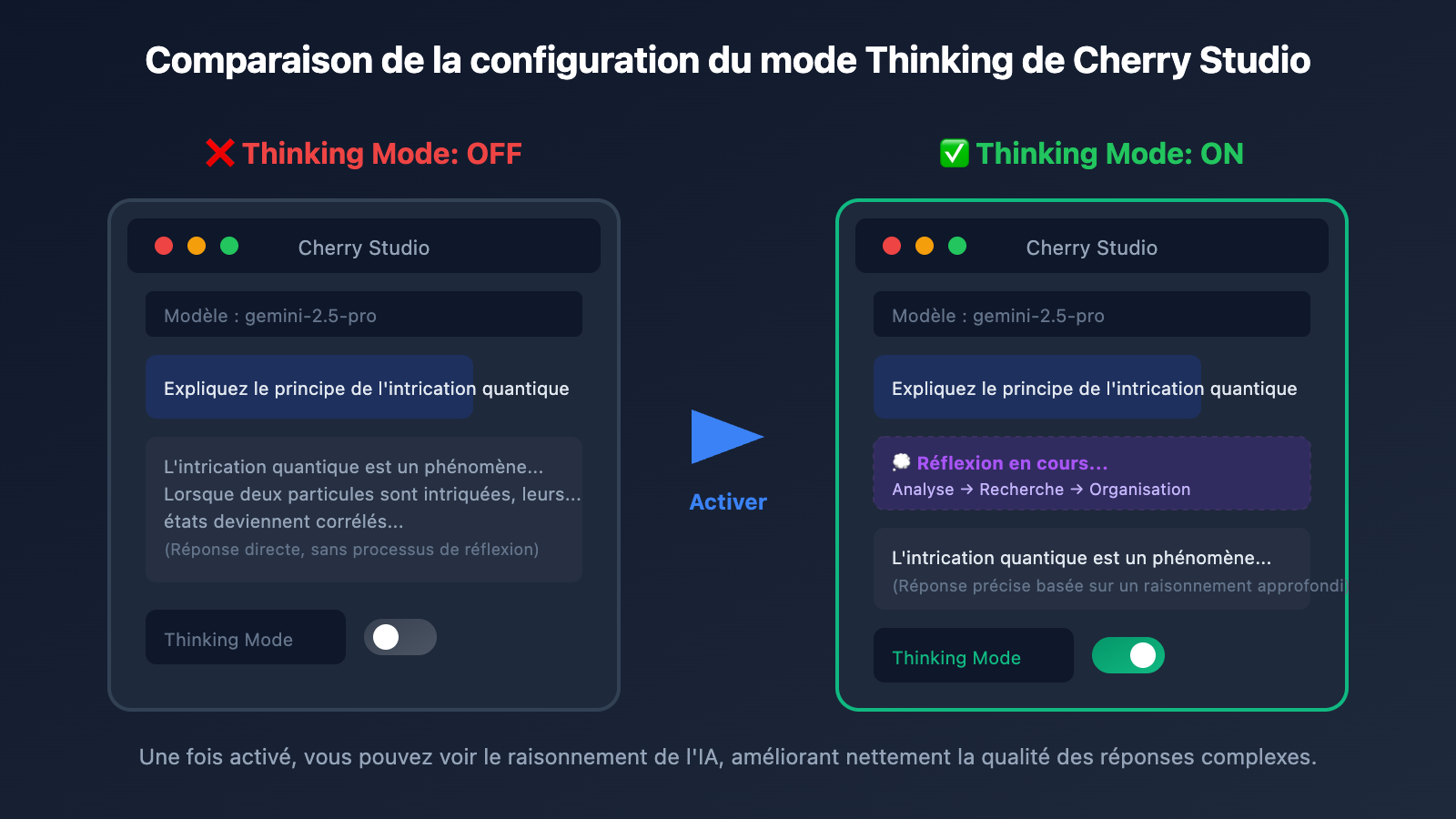
Configuration des paramètres personnalisés dans Cherry Studio
Si l'interrupteur de l'interface utilisateur ne semble pas fonctionner, vous devrez configurer manuellement les paramètres personnalisés :
Pour les modèles Gemini 3 :
{
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Pour les modèles Gemini 2.5 :
{
"generationConfig": {
"thinkingConfig": {
"thinkingBudget": -1,
"includeThoughts": true
}
}
}
Copiez et collez la configuration JSON correspondante dans la section Paramètres personnalisés (Custom Parameters) de Cherry Studio.
Voir les instructions de configuration détaillées de Cherry Studio
Détails des étapes de configuration :
- Ouvrir les paramètres du modèle : Cliquez sur le nom du modèle en haut de la fenêtre de discussion.
- Accéder aux paramètres avancés : Faites défiler jusqu'à la zone « Paramètres personnalisés ».
- Coller le JSON : Copiez la configuration JSON du modèle correspondant ci-dessus.
- Enregistrer et tester : Envoyez un message pour vérifier si le processus de réflexion s'affiche.
Dépannage courant :
- Assurez-vous que le format JSON est correct (attention aux virgules en trop).
- Confirmez que le nom du modèle correspond bien à votre configuration.
- Vérifiez que votre clé API est toujours valide.
🚀 Démarrage rapide : Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour obtenir vos clés API. Elle prend en charge toute la gamme des modèles Gemini et simplifie grandement la configuration.
Configuration du mode Gemini Thinking dans Chatbox
Chatbox est un autre client de bureau pour IA très populaire, apprécié pour son interface épurée et sa compatibilité multiplateforme. Voici comment configurer le mode Gemini Thinking dans Chatbox.
Étape 1 : Configurer le fournisseur d'API (API Provider)
- Ouvrez Chatbox, cliquez sur Paramètres en bas à gauche.
- Choisissez Fournisseur de modèle → Personnalisé (Custom).
- Configurez les informations de l'API :
Nom : Gemini Thinking
Type d'API : OpenAI Compatible
Hôte de l'API : https://api.apiyi.com
Clé API : sk-votre-cle-apiyi
Étape 2 : Sélectionner le modèle Thinking
Dans le sélecteur de modèle, saisissez ou sélectionnez :
gemini-3-pro-preview– Capacité de raisonnement maximale.gemini-2.5-pro– Équilibre entre performance et coût.gemini-2.5-flash– Réponse rapide.
Étape 3 : Configurer les paramètres de réflexion
Chatbox permet de configurer le mode réflexion via les Paramètres supplémentaires (Extra Parameters) :
{
"thinking_config": {
"thinking_level": "high"
}
}
Ou en utilisant thinking_budget :
{
"thinking_config": {
"thinking_budget": 8192
}
}
Paramètres d'affichage du processus de réflexion dans Chatbox
Par défaut, Chatbox réduit l'affichage du processus de réflexion. Vous pouvez ajuster cela :
| Option de réglage | Rôle | Valeur recommandée |
|---|---|---|
| Afficher le processus de réflexion | Déplier/Replier le contenu de réflexion | Activé |
| Style du processus | Bloc indépendant / Affichage en ligne | Bloc indépendant |
| Repli automatique | Réduit automatiquement les réflexions longues | Activé |
Voir l’exemple de code de configuration pour Chatbox
# 使用 OpenAI SDK 配置 Gemini Thinking
import openai
client = openai.OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[
{"role": "user", "content": "请解释为什么 1+1=2"}
],
extra_body={
"thinking_config": {
"thinking_budget": 8192,
"include_thoughts": True
}
}
)
# 输出思考过程和答案
print(response.choices[0].message.content)
Meilleures pratiques pour le mode Gemini Thinking
Configuration de la profondeur de réflexion selon les scénarios
| Scénario d'utilisation | Modèle recommandé | Configuration de réflexion | Explication |
|---|---|---|---|
| Preuve mathématique | gemini-3-pro-preview | thinking_level: high | Nécessite un raisonnement rigoureux |
| Débogage de code | gemini-2.5-pro | thinking_budget: 16384 | Analyse logique complexe |
| Questions-réponses | gemini-2.5-flash | thinking_budget: -1 | Auto-adaptation dynamique |
| Réponse rapide | gemini-2.5-flash-lite | thinking_budget: 0 | Désactiver la réflexion |
| Rédaction d'articles | gemini-3-flash-preview | thinking_level: medium | Équilibre créativité et efficacité |
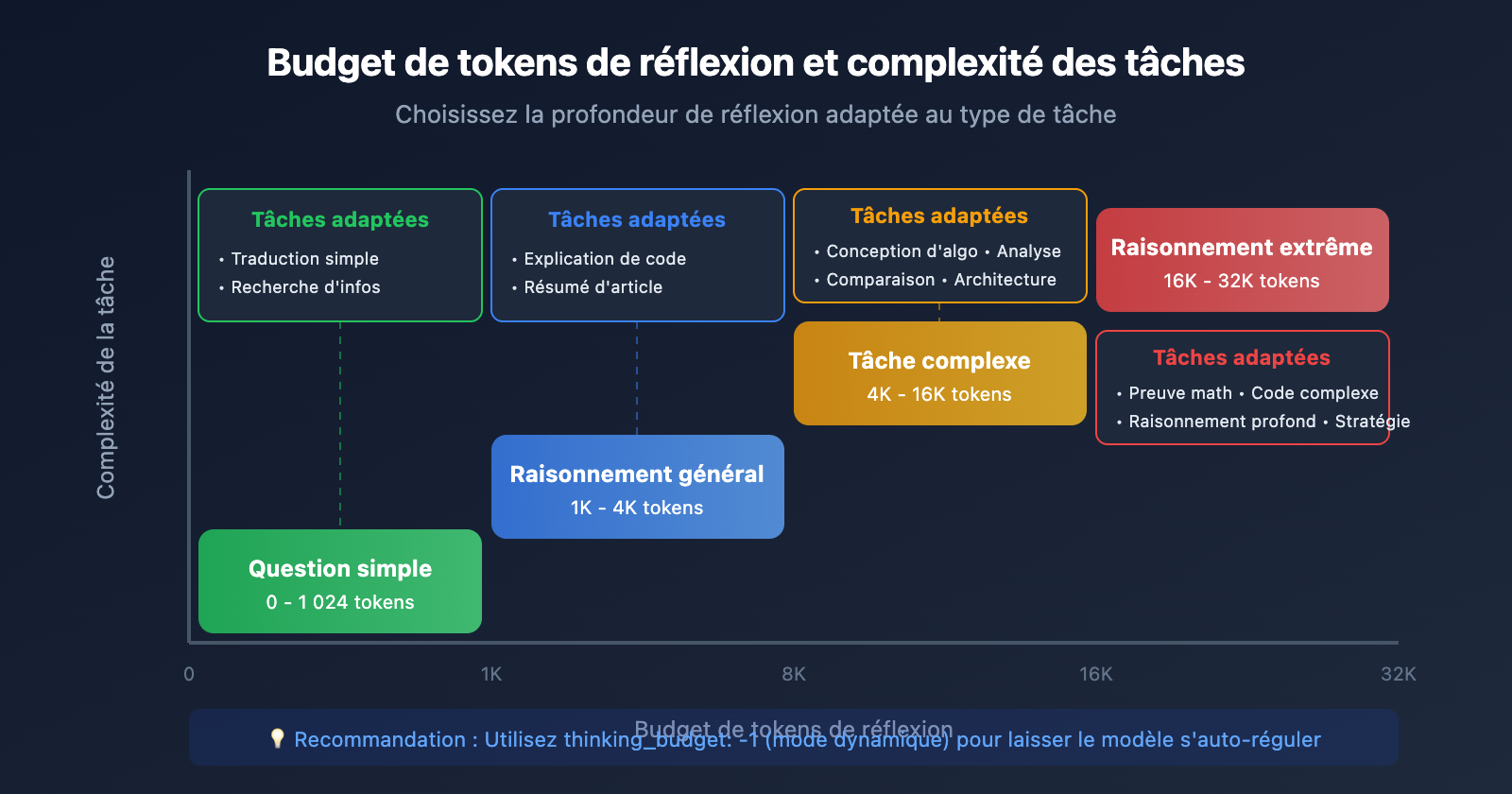
Suggestions de budget de tokens de réflexion
Questions simples : 0 - 1024 tokens
Raisonnement général : 1024 - 4096 tokens
Tâches complexes : 4096 - 16384 tokens
Raisonnement extrême : 16384 - 32768 tokens
💡 Conseil : Le choix de la profondeur de réflexion dépend principalement de la complexité de la tâche. Nous vous recommandons d'effectuer des tests réels sur la plateforme APIYI (apiyi.com) pour trouver la configuration la mieux adaptée à vos besoins. La plateforme supporte tous les modèles Gemini Thinking, ce qui facilite la comparaison rapide des résultats.
Comparaison : Mode Classique vs Mode Thinking
| Dimension | Mode Classique | Mode Thinking |
|---|---|---|
| Vitesse de réponse | Rapide (1-3s) | Plus lente (3-10s) |
| Profondeur de raisonnement | Superficielle | Profonde et multi-étapes |
| Consommation de tokens | Faible | Moyenne à Élevée |
| Précision (tâches complexes) | 60-70% | 85-95% |
| Interprétabilité | Faible | Élevée (réflexion visible) |
| Cas d'utilisation | Questions simples | Tâches de raisonnement complexes |
Questions Fréquentes
Q1 : Cherry Studio n’affiche pas le processus de réflexion après avoir activé l’interrupteur Thinking Mode ?
C'est un problème connu. L'interrupteur de l'interface de certains fournisseurs peut ne pas fonctionner. Vous devez ajouter manuellement la configuration JSON dans les « Paramètres personnalisés » :
{
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Assurez-vous que includeThoughts est réglé sur true, car c'est le paramètre clé pour afficher le processus de réflexion. Lors des appels via la plateforme APIYI apiyi.com, le retour du résumé de réflexion est activé par défaut.
Q2 : Quelle est la différence entre les paramètres de Gemini 2.5 et Gemini 3 ?
Les deux séries utilisent des paramètres différents pour contrôler le mode Thinking :
- Série Gemini 3 : utilise le paramètre
thinkingLevel, avec les valeurs minimal/low/medium/high. - Série Gemini 2.5 : utilise le paramètre
thinkingBudget, avec une valeur numérique comprise entre 0 et 32768.
Il ne faut pas mélanger ces paramètres, sinon l'API renverra une erreur. Il est recommandé de passer par l'interface unifiée de APIYI apiyi.com, car la plateforme gère automatiquement la compatibilité des paramètres.
Q3 : Combien de tokens supplémentaires le mode Thinking consomme-t-il ?
Les tokens de réflexion font l'objet d'une facturation supplémentaire. Prenons l'exemple de Gemini 2.5 Pro :
- Budget de réflexion par défaut : 8192 tokens.
- Budget de réflexion maximum : 32768 tokens.
La consommation réelle dépend de la complexité de la tâche. Pour des questions simples, le modèle peut n'utiliser que quelques centaines de tokens de réflexion ; pour des problèmes complexes, il peut épuiser tout son budget. Régler thinkingBudget: -1 permet au modèle de s'ajuster automatiquement, ce qui constitue le choix le plus rentable.
Q4 : Comment obtenir uniquement le résumé de la réflexion plutôt que le processus complet ?
En réglant includeThoughts: true lors de l'appel API, vous recevrez un résumé de la réflexion plutôt que l'intégralité des tokens de réflexion internes. Le résumé est plus concis et mieux adapté à un affichage dans une interface utilisateur. Le processus de réflexion complet n'est actuellement pas ouvert au public.
Q5 : Quelles tâches sont les plus adaptées au mode Thinking ?
Le mode Thinking est particulièrement adapté aux tâches nécessitant un raisonnement par étapes :
- Démonstrations mathématiques et calculs.
- Débogage de code et conception d'algorithmes.
- Raisonnement logique et analyse de problèmes.
- Planification stratégique et analyse décisionnelle.
Pour les tâches simples comme la recherche d'informations, la traduction ou le résumé de texte, il n'est pas nécessaire d'activer le mode Thinking, car cela augmenterait inutilement la latence et les coûts.
Conclusion
Le mode Gemini Thinking est une fonctionnalité puissante pour booster les capacités de raisonnement de l'IA. Grâce à ce tutoriel de configuration, vous avez appris à :
- Comprendre le principe du mode Thinking : Maîtriser la différence entre les paramètres
thinking_leveletthinking_budget. - Configurer Cherry Studio : Activer le mode réflexion via l'interface ou par des paramètres JSON personnalisés.
- Configurer Chatbox : Utiliser les "Extra Parameters" pour paramétrer la réflexion.
- Appliquer les meilleures pratiques : Choisir la profondeur de réflexion adaptée à la complexité de la tâche.
Nous vous recommandons d'utiliser APIYI apiyi.com pour tester rapidement l'efficacité du mode Gemini Thinking. La plateforme propose une interface compatible OpenAI, prend en charge tous les modèles des séries Gemini 2.5 et 3, avec une configuration simplifiée et un accès plus stable.
Ressources complémentaires
-
Documentation officielle de Google Gemini Thinking : description complète des paramètres de l'API
- Lien :
ai.google.dev/gemini-api/docs/thinking
- Lien :
-
Documentation officielle de Cherry Studio : guide de configuration du client
- Lien :
docs.cherry-ai.com
- Lien :
-
Liste des modèles Gemini : liste des modèles prenant en charge le mode Thinking
- Lien :
ai.google.dev/gemini-api/docs/models
- Lien :
Auteur : Équipe APIYI
Support technique : Pour obtenir une API Gemini ou pour toute consultation technique, n'hésitez pas à visiter APIYI sur apiyi.com