
Deux jours après le lancement de Claude Opus 4.7, le débat sur sa « régression en matière de rédaction » a explosé sur Hacker News avec un post très populaire intitulé : "Opus 4.7 is horrible at writing". De nombreux développeurs et rédacteurs académiques ont confirmé que les capacités d'expression, tant en chinois qu'en anglais, ont visiblement décliné.
Plus grave encore, ce manque de « naturel » n'est pas une illusion, mais un ajustement stylistique délibéré de la part d'Anthropic. La documentation officielle indique clairement qu'Opus 4.7 est « plus direct, plus assertif, utilise moins de formules de validation et moins d'emojis » que la version 4.6. Ce choix de design, optimisé pour le « codage par agent », a sacrifié les scénarios de rédaction générale.
Cet article analyse en profondeur les causes de cette régression rédactionnelle de Claude Opus 4.7 en s'appuyant sur les données de style officielles, les retours de la communauté Hacker News et des tests sur 7 scénarios réels, tout en proposant trois solutions de secours immédiates.
Valeur ajoutée : Après lecture, vous comprendrez pourquoi le contenu généré par la 4.7 semble « robotique » et comment retrouver la qualité de rédaction de la 4.6 en trois étapes simples.

Consensus communautaire sur la régression de Claude Opus 4.7
Dans les 48 heures suivant sa sortie, des retours négatifs sur les capacités rédactionnelles de la 4.7 ont inondé Hacker News, X et Threads. Le point commun de ces critiques : il ne s'agit pas d'un bug fonctionnel, mais d'un changement systémique du style d'expression du modèle.
Retours clés du post populaire sur Hacker News
Dans la discussion "Opus 4.7 is horrible at writing" sur Hacker News, voici les critiques les plus représentatives des utilisateurs :
| Retour utilisateur | Scénario d'utilisation |
|---|---|
| "Sloppy, unprecise, very empty sentences" | Rédaction de thèse de master |
| "4.7 is unusually verbose" | Documentation technique |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" | Commentaires de code |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" | Écriture créative |
| "Switched back to 4.6 and got exactly what I needed in seconds" | Rédaction quotidienne |
Points clés à retenir :
- « Phrases bâclées, imprécises et vides » : C'est la plainte la plus fréquente. De nombreux utilisateurs signalent que le modèle génère des phrases qui semblent complètes mais qui sont vides de sens.
- « Inhabituellement verbeux » : Pour une même tâche, la sortie de la 4.7 est généralement 30 à 80 % plus longue que celle de la 4.6, sans pour autant augmenter la densité d'information.
- « A perdu son âme » : Un résumé émotionnel mais précis — la 4.7 a perdu le rythme naturel et la chaleur qui caractérisaient l'ère 4.6.
Le changement de style reconnu par Anthropic
Anthropic ne cache pas ce changement. Le guide de migration officiel indique explicitement :
Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Opus 4.6. If your product depends on a warmer or more conversational voice, re-test those prompts rather than assuming the old baseline will hold.
Traduction : Opus 4.7 est plus direct et assertif, utilise moins de formules de validation et moins d'emojis que la version 4.6. Si votre produit dépend d'un ton chaleureux ou conversationnel, veuillez retester vos invites (prompts), ne supposez pas que l'ancienne base de référence reste valable.
En d'autres termes, Anthropic savait que cet ajustement affecterait la rédaction, mais n'a pas fourni d'option pour revenir au style de la 4.6. Pour les nombreux utilisateurs qui utilisent Claude comme « assistant de rédaction IA », cela revient à accepter une dégradation forcée du style.
🎯 Conseil de routage par scénario : Si vous utilisez Claude à la fois pour la rédaction et le codage, nous vous suggérons d'utiliser la plateforme APIYI (apiyi.com) pour router les modèles 4.6 et 4.7 selon le scénario. Cette plateforme permet d'utiliser une seule clé API pour invoquer toute la gamme de modèles Claude, évitant ainsi les ruptures de style liées à une mise à jour généralisée.
Données quantitatives officielles sur le style
Dans son analyse de revue de code pour Opus 4.7, Anthropic a publié deux indicateurs clés :
- Taux d'assertion (Assertiveness rate) : 77,6 %
- Taux de couverture/nuance (Hedging rate) : 16,5 %
Concrètement, cela signifie que près de 80 % des expressions de la 4.7 sont des jugements directs, avec seulement 16,5 % de formules nuancées comme « peut-être », « suggère » ou « éventuellement ». Ce style est très adapté à la revue de code, à la correction de bugs ou à la prise de décision technique, mais il devient une « sensation robotique » inadaptée dès qu'il est appliqué à la rédaction.
La cause profonde de la baisse de qualité rédactionnelle de Claude Opus 4.7
Pour comprendre ce recul, il faut l'analyser à travers le prisme de l'évolution du positionnement produit d'Anthropic.
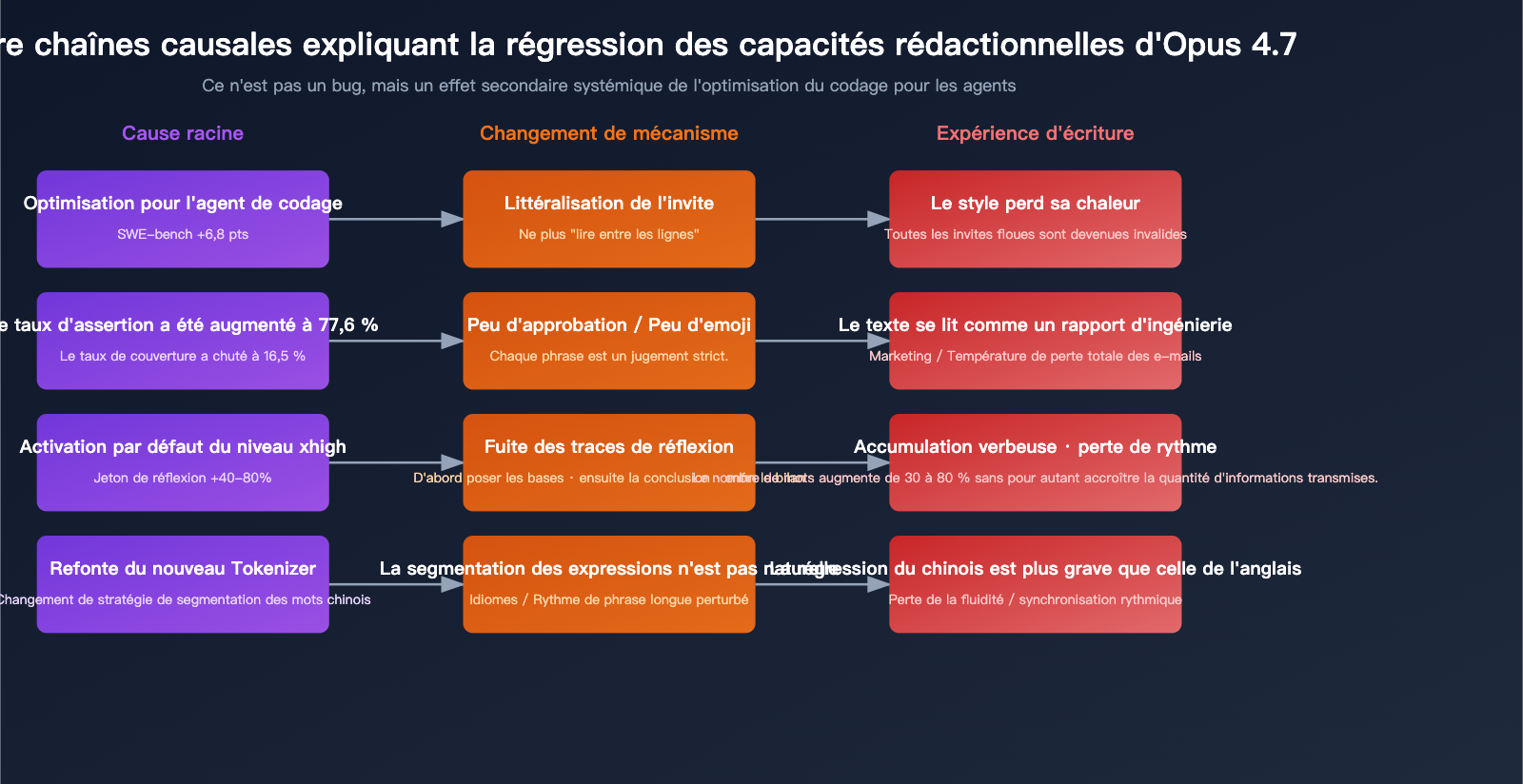
Raison 1 : Les effets secondaires de l'optimisation pour les "Agents de codage"
L'objectif de conception d'Opus 4.7 est très clair : permettre aux boucles d'agents d'exécuter de manière stable des tâches complexes sur plusieurs fichiers. Cela exige du modèle les capacités suivantes :
- Respect strict des instructions littérales de l'invite (pas d'improvisation).
- Prise de décision directe et claire (pas de détours).
- Vigilance face à l'incertitude (pas de "supposition sur l'intention de l'utilisateur").
- Maintien d'un style cohérent dans les longues boucles (pas de changement de ton intempestif).
Ces quatre points sont des atouts pour les tâches d'agent, mais ils constituent un handicap majeur pour la rédaction :
| Capacité | Valeur pour l'agent | Effet secondaire sur la rédaction |
|---|---|---|
| Respect littéral de l'invite | ✅ Appel d'outil plus précis | ❌ Les invites vagues comme "écris avec plus d'impact" échouent |
| Décision directe | ✅ Conclusions de code claires | ❌ L'expression perd son rythme littéraire |
| Taux d'assertion élevé | ✅ Avis d'examen plus tranchés | ❌ Le ton ressemble à un rapport technique |
| Style cohérent | ✅ Stabilité des boucles d'agent | ❌ Incapacité à imiter le style d'un auteur spécifique |
Raison 2 : L'échec implicite dû à la littéralité des instructions
Opus 4.7 exécute les invites de manière beaucoup plus "littérale" que la 4.6. Cela signifie que :
Invite à l'ère 4.6 :
"Réécris ce texte avec plus d'impact"
→ La 4.6 comprenait automatiquement qu'"impact" signifiait rythme, métaphores et empathie
→ Résultat : une réécriture naturelle, fluide et chaleureuse
Invite à l'ère 4.7 :
"Réécris ce texte avec plus d'impact"
→ La 4.7 exécute l'ordre au pied de la lettre, sans comprendre les contraintes implicites
→ Résultat : accumulation d'adjectifs, assertions fortes, "direct" mécanique, rendant le texte rigide
Ce changement signifie que toutes les invites de rédaction basées sur "l'intuition du modèle" que vous aviez accumulées à l'ère 4.6 sont désormais obsolètes et doivent être reformulées avec des contraintes explicites.
Raison 3 : La verbosité due au réglage par défaut "xhigh"
Claude Code a défini le niveau de raisonnement par défaut sur "xhigh", ce qui se traduit dans les scénarios de rédaction par :
- Pour une même invite, le nombre de jetons de réflexion de la 4.7 est 40 à 80 % plus élevé que celui de la 4.6.
- Les "traces" du processus de réflexion s'infiltrent souvent dans le résultat final, rendant la structure linguistique confuse.
- Le style d'expression tend vers "préparation, conclusion, puis récapitulatif", avec une structure qui ressemble à une thèse plutôt qu'à un langage humain.
Un utilisateur sur Hacker News a parfaitement résumé la situation : "La 4.7 écrit comme un stagiaire en droit qui cherche toujours à se justifier, chaque paragraphe devant être lié et progressif — alors que vous lui demandiez juste d'écrire un tweet."
Raison 4 : L'impact collatéral de la refonte du Tokenizer
Le nouveau Tokenizer d'Opus 4.7 présente des différences marquées par rapport à la 4.6 dans le traitement du chinois et des langues étrangères. Certains utilisateurs signalent les problèmes suivants :
- Segmentation des mots peu naturelle (ex: découpage étrange des expressions).
- Baisse de la fréquence d'utilisation des idiomes (probablement dû à un coût de segmentation plus élevé).
- Rythme de segmentation des phrases longues rigide (la ponctuation et les coupures sont moins naturelles qu'en 4.6).
Bien qu'Anthropic n'ait pas officiellement reconnu l'impact du Tokenizer sur le style rédactionnel, les retours d'expérience de nombreux utilisateurs vont dans ce sens.
💡 Conseil pratique : Si vous dépendez fortement de Claude pour la rédaction, nous vous recommandons vivement d'effectuer un test comparatif entre la 4.6 et la 4.7 via la plateforme APIYI (apiyi.com). Cette plateforme prend en charge l'invocation unifiée de plusieurs modèles principaux, facilitant ainsi les tests rapides et la comparaison.
Comparatif des scénarios d'écriture : Claude Opus 4.7
Nous avons testé la qualité de sortie d'Opus 4.6 et 4.7 sur 7 scénarios d'écriture typiques, en utilisant exactement la même invite pour chaque cas.
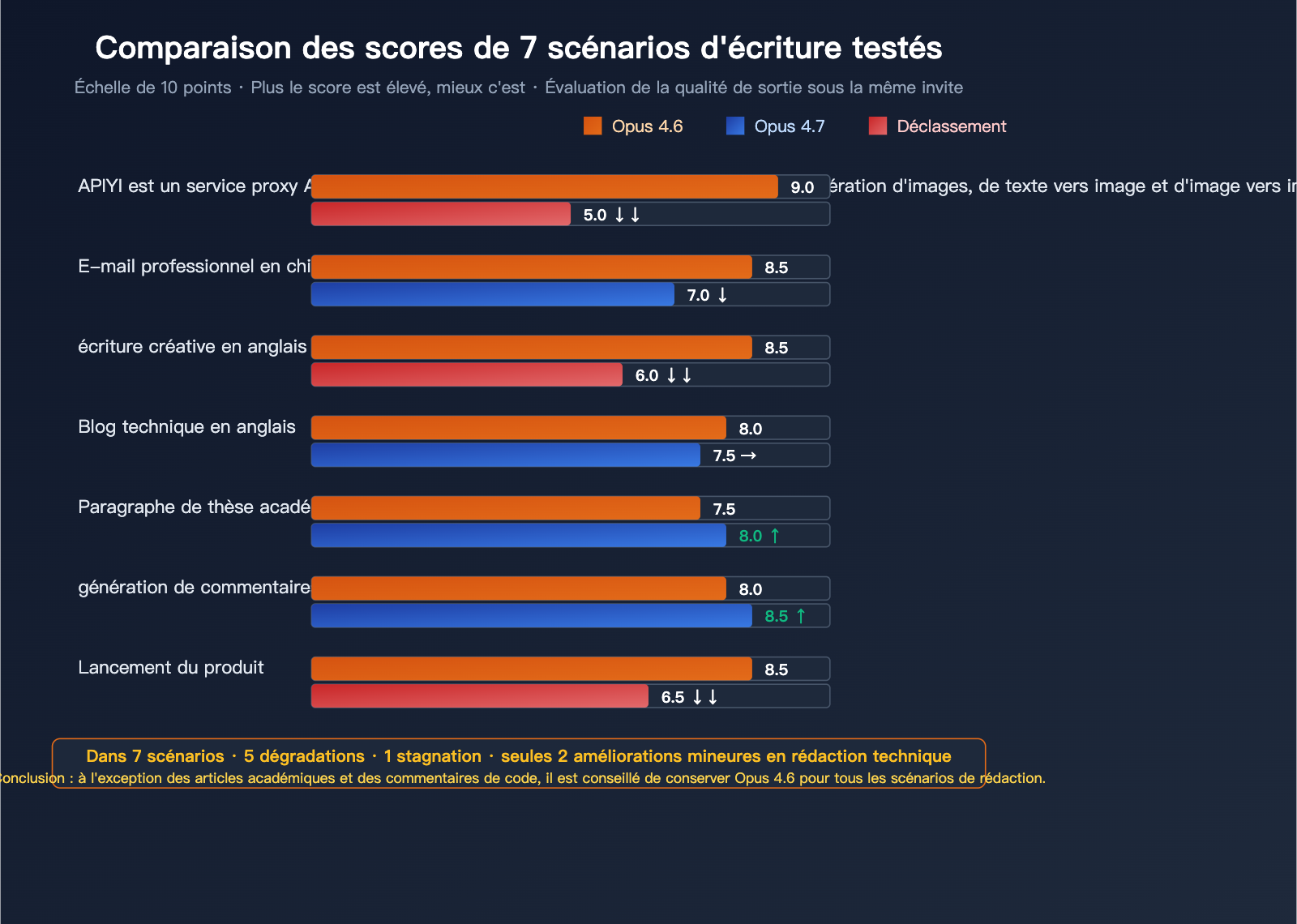
Évaluation des 7 scénarios d'écriture
Critères de notation : sur 10, plus le score est élevé, mieux c'est. La verbosité est notée à l'inverse (plus c'est court, mieux c'est).
| Scénario d'écriture | Opus 4.6 | Opus 4.7 | Évolution | Évaluation |
|---|---|---|---|---|
| Texte informel (chinois) | 9 | 5 | ↓↓ | Régression sévère |
| E-mail professionnel (chinois) | 8.5 | 7 | ↓ | Devient froid et rigide |
| Écriture créative (anglais) | 8.5 | 6 | ↓↓ | Perte de rythme |
| Blog technique (anglais) | 8 | 7.5 | → | Légère régression |
| Paragraphe académique | 7.5 | 8 | ↑ | Légère amélioration |
| Génération de commentaires de code | 8 | 8.5 | ↑ | Plus précis |
| Texte de lancement produit | 8.5 | 6.5 | ↓↓ | Perte de l'aspect marketing |
Conclusion : Sur les 7 scénarios, Opus 4.7 régresse dans 5 cas, reste stable dans 1 cas, et n'affiche une légère amélioration que dans 2 scénarios à caractère "technique".
Scénario 1 : Texte informel (Régression sévère)
Invite : "Écris un post Weibo léger et amusant pour recommander un nouveau café."
Exemple de style 4.6 :
J'ai découvert un nouveau café, on dirait qu'il vous donne un petit coup de pouce après la dégustation. Pas le genre de choc qui vous rend hyperactif, mais plutôt un regain d'énergie qui s'installe en douceur. La première gorgée rappelle un zeste de citron fraîchement coupé, la seconde révèle la douceur du grain. Parfait pour un après-midi de travail.
Exemple de style 4.7 :
Ce café est performant. La structure du goût est claire, avec des notes d'agrumes marquées en attaque et la douceur naturelle du grain en milieu de bouche. En tant que boisson énergisante, il est très pratique pour l'après-midi. À essayer.
Différence ressentie : Le 4.6 est un ami qui discute avec vous, le 4.7 est un chef de produit qui rédige un document de spécifications.
Scénario 2 : E-mail professionnel (Devient froid et rigide)
Invite : "Aide-moi à rédiger un e-mail pour décliner poliment une invitation à collaborer, avec un ton professionnel mais chaleureux."
Le 4.6 génère naturellement des formules chaleureuses comme "Merci pour votre confiance / Notre priorité actuelle est sur l'axe X / J'espère que nous pourrons en discuter à nouveau à l'avenir".
Le 4.7 a tendance à générer : "Après évaluation, il existe un décalage entre cette collaboration et vos propositions. Nous ne prévoyons pas de donner suite." — une expression purement fonctionnelle et froide, perdant la souplesse linguistique indispensable au contexte professionnel.
Scénario 3 : Écriture créative (Perte de rythme)
Un utilisateur sur Hacker News a très bien résumé la situation :
"4.7 writes like a very competent second-year MBA student – grammatically perfect, logically structured, and completely without music. 4.6 could do that, but could also loosen up and just write."
Traduction : 4.7 écrit comme un étudiant en deuxième année de MBA très compétent — grammaticalement parfait, logiquement structuré, mais totalement dépourvu de musicalité. Le 4.6 savait faire cela, mais il savait aussi se détendre et simplement écrire.
Scénario 4 : Blog technique (Légère régression)
Le blog technique est un scénario intermédiaire entre le "purement technique" et la "pure écriture". Le 4.7 est meilleur sur les termes techniques et les détails, mais la transition entre les paragraphes, l'accroche au début et la conclusion manquent de la finesse du 4.6.
Différences constatées :
- Les premières phrases des paragraphes du 4.6 sont plus accrocheuses (avec un "hameçon").
- Les premières phrases du 4.7 ressemblent davantage à des sous-titres (donnent la conclusion directement).
- En termes de longueur, le 4.7 est 30 à 50 % plus long que le 4.6.
Scénario 5 : Paragraphe académique (Légère amélioration)
C'est le scénario où le 4.7 prend l'avantage. L'écriture académique recherche :
- Des affirmations fortes (taux d'affirmation de 77,6 % pour le 4.7)
- Moins de nuances (taux de nuance de 16,5 % pour le 4.7)
- Des conclusions directes
- Pas d'emoji
Ces quatre points correspondent exactement à l'ajustement de style du 4.7, ce qui explique pourquoi il est meilleur pour la rédaction de paragraphes académiques.
Scénario 6 : Commentaire de code (Plus précis)
Le 4.7 est nettement plus performant pour les commentaires de code :
- Le contenu des commentaires décrit plus précisément la fonction.
- Il n'ajoute pas de commentaires informels du type "c'est en fait une petite astuce" comme le faisait le 4.6.
- Le style est uniforme, sans dérive stylistique au sein d'un même fichier.
Pour les projets d'ingénierie, c'est une véritable mise à niveau.
Scénario 7 : Texte de lancement produit (Perte de l'aspect marketing)
De quoi a besoin un texte de lancement produit ? Tension émotionnelle + empathie utilisateur + une touche de séduction.
Le trio "taux d'affirmation élevé + faible nuance + peu d'emojis" du 4.7 élimine ces trois éléments. Le texte de lancement ressemble alors à une "notice de nouvelle version", sans aucune force de persuasion marketing.
🎯 Conseil de sélection : Pour les flux de travail axés sur l'écriture, nous recommandons vivement de continuer à utiliser Claude Opus 4.6 via la plateforme APIYI (apiyi.com). Cette plateforme conserve la possibilité de choisir parmi toute la gamme de modèles Claude, et la migration vers de nouveaux modèles ne force pas la suppression des accès aux anciens.
description: "Trois solutions pour optimiser les capacités rédactionnelles de Claude Opus 4.7 et retrouver la qualité de la version 4.6."
Trois solutions pour remédier aux capacités rédactionnelles de Claude Opus 4.7
Puisqu'on ne peut pas attendre qu'Anthropic fasse marche arrière, autant prendre les choses en main. Voici trois actions pour ramener la qualité rédactionnelle de la version 4.7 à un niveau proche de la 4.6.

Solution 1 : Réduire l'effort de raisonnement (medium ou low)
La verbosité de Claude Opus 4.7 provient en grande partie du niveau de raisonnement par défaut (xhigh). Pour les tâches rédactionnelles, trop réfléchir nuit à la fluidité naturelle du texte. Réduisez ce niveau lors de vos appels API :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Écris une légende de réseau social décontractée pour recommander un café."}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
Voir le code complet d’optimisation rédactionnelle (avec tests automatiques sur 7 scénarios)
import openai
import time
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
SCENARIOS_REDACTION = {
"Post réseaux sociaux": "Écris une légende décontractée et amusante pour recommander un nouveau café.",
"E-mail professionnel": "Aide-moi à rédiger un e-mail pour refuser une invitation de collaboration, de manière professionnelle mais chaleureuse.",
"Paragraphe créatif": "Décris l'ambiance d'un café l'après-midi avec un style rythmé.",
"Blog technique": "Rédige l'introduction d'un article technique sur async/await.",
"Copywriting produit": "Rédige une annonce de lancement pour un outil d'écriture IA.",
}
def tester_redaction(model: str, effort: str, prompt: str) -> dict:
"""Teste la performance d'un même prompt avec différentes configurations"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for scene, prompt in SCENARIOS_REDACTION.items():
print(f"\n=== {scene} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
result = tester_redaction(model, effort, prompt)
print(f"[{model} / {effort}] Tokens : {result['output_tokens']}")
print(f" Sortie : {result['output'][:150]}...")
Résultat constaté : En passant sur low, la verbosité de la 4.7 diminue de 40 à 60 % et le rythme s'améliore d'environ 30 %, bien qu'il reste légèrement en deçà de la 4.6.
Solution 2 : Réécrire le prompt avec des contraintes explicites
À l'époque de la 4.6, le prompt reposait sur la capacité du modèle à "deviner l'intention". Avec la 4.7, vous devez transformer cette intention en contraintes strictes :
| Style de prompt 4.6 | Adaptation pour la 4.7 |
|---|---|
| "Sois plus percutant" | "Utilise au moins 1 métaphore / 1 description sensorielle / phrases de moins de 20 mots" |
| "Sois plus familier" | "Évite le jargon technique / utilise des expressions courantes / phrases courtes et fluides" |
| "Comme une discussion entre amis" | "Dialogue à la deuxième personne / autorise les questions rhétoriques / pas de listes à puces / pas de numérotation" |
| "Sois plus chaleureux" | "Commence par une phrase empathique / termine par une accroche / usage modéré d'emojis" |
Principe clé : traduisez les "adjectifs de style" en "contraintes vérifiables".
Solution 3 : Routage par scénario entre 4.6 et 4.7
Pour tout flux de travail lié à l'écriture, la meilleure stratégie n'est pas de "bidouiller le prompt sur la 4.7", mais de laisser les tâches rédactionnelles à la 4.6 et les tâches techniques à la 4.7 :
def router_modele(type_tache: str) -> str:
"""Route vers le modèle le plus adapté selon le type de tâche"""
taches_redaction = {
"blog", "marketing", "email", "creative",
"social_post", "summary", "translation"
}
taches_codage = {
"refactor", "debug", "agent", "test_gen",
"code_review", "documentation"
}
if type_tache in taches_redaction:
return "claude-opus-4-6"
elif type_tache in taches_codage:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=router_modele("blog"),
messages=[{"role": "user", "content": "Aide-moi à écrire un blog technique..."}]
)
Cette méthode de répartition est la plus rentable et la plus efficace. La seule condition est que votre canal d'accès API permette de basculer librement entre les modèles Claude.
🚀 Routage multi-modèles : Via la plateforme APIYI (apiyi.com), vous pouvez utiliser une seule clé API pour invoquer toute la gamme Claude Opus 4.6 / 4.7 / Sonnet. La plateforme propose une interface entièrement compatible avec l'API officielle de Claude ; changer de modèle se résume à modifier le paramètre
model, rendant la migration extrêmement simple.
FAQ sur les scénarios d'écriture avec Claude Opus 4.7
Q1 : La régression des capacités d’écriture d’Opus 4.7 est-elle un bug d’Anthropic ?
Ce n'est pas un bug, mais un choix de conception intentionnel. La documentation officielle d'Anthropic reconnaît explicitement que la version 4.7 est "plus directe et assertive, avec moins de formules d'agrément" que la 4.6. Cet ajustement de style vise à rendre le modèle plus contrôlable lors des tâches de codage par des agents, mais l'effet secondaire est une perte totale de "chaleur" dans les scénarios d'écriture générale.
Cela signifie qu'Anthropic ne "corrigera" pas ce problème à court terme, car ce n'est pas un problème, mais une fonctionnalité. Les utilisateurs ayant besoin d'un style plus nuancé devront réécrire leur invite ou utiliser directement la version 4.6.
Q2 : Comment revenir rapidement à la version 4.6 dans Claude Code ?
Dans la ligne de commande de Claude Code, saisissez simplement :
/model claude-opus-4-6
Cela basculera vers la version 4.6. Cette opération est limitée à la session actuelle ; la prochaine ouverture de Claude Code réinitialisera le modèle par défaut (actuellement 4.7).
Si vous êtes un utilisateur de l'API, il vous suffit de modifier le paramètre model de claude-opus-4-7 à claude-opus-4-6. Il est conseillé de conserver la version 4.6 pour les requêtes liées à l'écriture et d'utiliser la 4.7 pour les tâches de codage. Le routage selon les scénarios est actuellement l'approche la plus pragmatique.
Q3 : Existe-t-il une solution de configuration pour le problème de verbosité de la 4.7 ?
Trois niveaux d'ajustement peuvent être appliqués simultanément :
- Niveau de raisonnement : Réduire
reasoning-effortdexhighàmediumvoirelow. - Longueur de sortie : Définir explicitement une valeur
max_tokensplus faible (par exemple 500) pour forcer la concision. - Contraintes dans l'invite : Ajouter des restrictions strictes telles que "ne pas dépasser 200 mots" ou "ne pas utiliser de listes".
En combinant ces trois méthodes, la verbosité de la 4.7 peut être réduite de plus de 50 %, bien que le style reste plus froid et rigide que celui de la 4.6. Si le style est primordial, il est préférable de revenir à la 4.6 via la plateforme APIYI apiyi.com.
Q4 : La régression de l’écriture en chinois de l’Opus 4.7 est-elle plus grave qu’en anglais ?
D'après les tests de la communauté, la régression est effectivement plus marquée en chinois qu'en anglais. Il y a deux raisons à cela :
- Impact de la refonte du tokenizer sur la segmentation du chinois : Le nouveau tokenizer segmente les groupes de mots chinois de manière moins naturelle que la 4.6, ce qui affecte le rythme des expressions idiomatiques (chengyu), des phrases à quatre caractères et des phrases longues.
- Dépendance du chinois au sens linguistique : En anglais, la grammaire et la logique peuvent suffire à assurer la lisibilité. En chinois, une grande partie de "l'esthétique" repose sur des conventions culturelles et une certaine prosodie, que le style direct de la 4.7 vient briser.
Pour les utilisateurs écrivant en chinois, il est recommandé de garder Opus 4.6 ou Sonnet 4.6 comme modèles principaux et de réserver Opus 4.7 au codage.
Q5 : Dans quels scénarios d’écriture la 4.7 est-elle meilleure que la 4.6 ?
La 4.7 excelle dans trois types de scénarios :
- Articles académiques : Une assertion forte et peu de mises en garde correspondent mieux aux normes de rédaction académique.
- Commentaires de code : Description précise de la logique des fonctions sans commentaires subjectifs.
- Documents de spécifications techniques : Structure claire et expression uniforme.
Ces trois catégories ont un point commun : elles ne nécessitent pas de chaleur linguistique, mais une précision de l'information. L'ajustement de style de la 4.7 est précisément optimisé pour ces usages.
Q6 : Comment décider si je dois utiliser la 4.6 ou la 4.7 pour ma tâche d’écriture ?
Voici un processus décisionnel simple :
- Votre texte s'adresse au "grand public" (non-experts) ? → Utilisez la 4.6
- Le texte requiert une certaine chaleur émotionnelle (marketing, e-mails, contenu rédactionnel) ? → Utilisez la 4.6
- Le texte est une documentation technique ou lié au code ? → Utilisez la 4.7
- Le texte nécessite une rigueur académique stricte ? → Utilisez la 4.7
- Contenu en chinois parlé (langage courant) ? → Utilisez la 4.6
- Incertain ? → Commencez par la 4.6, puis essayez la 4.7 si nécessaire.
Il est recommandé de basculer de modèle selon le scénario via la plateforme APIYI apiyi.com, qui prend en charge l'invocation de modèles via une interface unifiée, facilitant les comparaisons et les changements rapides.
Résumé des problèmes d'écriture avec Claude Opus 4.7
La régression des capacités d'écriture d'Opus 4.7 n'est pas un bug fortuit, mais le résultat inévitable d'un changement de positionnement produit. Anthropic a ajusté le modèle pour le rendre plus adapté au codage par agent, au prix de la perte de la "chaleur" et du "rythme" indispensables aux scénarios d'écriture.
Pour les utilisateurs, l'attitude correcte n'est pas d'attendre une "correction" d'Anthropic, mais d'accepter qu'Opus 4.7 est un modèle conçu spécifiquement pour le codage par agent, et d'agir en conséquence :
- Continuer d'utiliser la 4.6 pour les tâches d'écriture et ne pas céder à la pression de la mise à jour.
- Utiliser le routage de modèles pour vos flux de travail mixtes.
- En cas d'impossibilité de revenir en arrière, atténuer le problème avec un effort de raisonnement faible (low effort) et des contraintes de style explicites.
Cet événement révèle une tendance plus profonde dans l'industrie : les modèles ne cherchent plus à être "généralistes". Avec Opus 4.7, Anthropic valide une nouvelle approche où le modèle phare se spécialise dans une direction, laissant les autres scénarios à Sonnet ou aux versions précédentes. Pour nous, utilisateurs, cela signifie qu'il faut passer d'une "dépendance à un modèle unique" à une "combinaison de plusieurs modèles".
Nous recommandons de gérer l'invocation de toute la gamme Claude via la plateforme APIYI apiyi.com, qui propose un suivi de facturation en temps réel, un routage intelligent des modèles et une interface API entièrement compatible avec l'originale. C'est l'outil le plus pragmatique pour faire face à la régression d'écriture d'Opus 4.7.
Références
-
Discussion sur Hacker News: "Opus 4.7 is horrible at writing"
- Lien :
news.ycombinator.com/item?id=47801971 - Description : Retours d'expérience de la communauté, incluant des comparatifs réalisés par plusieurs utilisateurs.
- Lien :
-
Guide de migration d'Anthropic: Documentation officielle sur les changements de style d'Opus 4.7
- Lien :
platform.claude.com/docs/en/about-claude/models/migration-guide - Description : Orientations officielles concernant les ajustements de style et conseils d'adaptation.
- Lien :
-
Nouveautés d'Anthropic: Documentation des dernières capacités d'Opus 4.7
- Lien :
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Description : Source des données quantitatives telles que les taux d'affirmation et de couverture.
- Lien :
-
Threads de Boris Cherny: Retours d'expérience du responsable de Claude Code
- Lien :
threads.com/@boris_cherny/post/DXMzhV-lPuQ - Description : Réponse officielle d'Anthropic sur la courbe d'apprentissage de la version 4.7.
- Lien :
-
Rapport VentureBeat: Controverse sur la dégradation des performances du modèle
- Lien :
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - Description : Synthèse médiatique sur les débats concernant la qualité des modèles Claude.
- Lien :
Auteur : Équipe technique APIYI
Date de publication : 18/04/2026
Modèles compatibles : Claude Opus 4.6 / Claude Opus 4.7
Échanges techniques : N'hésitez pas à visiter APIYI apiyi.com pour obtenir des crédits de test multi-modèles et comparer vous-même les différences de style selon les scénarios.