
Nur 48 Stunden nach dem Release von Claude Opus 4.7 ist eine hitzige Debatte über die „nachlassenden Schreibfähigkeiten“ entbrannt. Auf Hacker News schlug ein Thread mit dem Titel "Opus 4.7 is horrible at writing" hohe Wellen. Zahlreiche Entwickler und Autoren bestätigen: Die Ausdrucksfähigkeit – sowohl im Chinesischen als auch im Englischen – hat spürbar abgenommen.
Das Entscheidende dabei: Dieses „Roboter-Deutsch“ (bzw. Englisch) ist kein Zufall, sondern eine bewusste Designentscheidung von Anthropic. In der offiziellen Dokumentation heißt es, Opus 4.7 sei „direkter, bestimmter, weniger validierend und emoji-arm“. Diese Optimierung für „Agenten-Coding“ geht massiv zu Lasten allgemeiner Schreibaufgaben.
Dieser Artikel analysiert basierend auf offiziellen Daten, Nutzerfeedback von Hacker News und sieben Praxistests die Gründe für den Leistungsabfall und liefert drei sofort umsetzbare Lösungen.
Kernnutzen: Sie erfahren, warum 4.7 „wie eine Maschine“ schreibt und wie Sie mit drei Handgriffen die Schreibqualität wieder auf das Niveau von 4.6 heben.

Community-Konsens zum Leistungsabfall von Claude Opus 4.7
Innerhalb von 48 Stunden nach Veröffentlichung häuften sich negative Rückmeldungen auf Hacker News, X und Threads. Der gemeinsame Nenner: Es handelt sich nicht um einen Bug, sondern um eine systematische Veränderung des Ausdrucksstils.
Kernfeedback aus dem Hacker News-Thread
In der Diskussion "Opus 4.7 is horrible at writing" finden sich typische Kritikpunkte von Anwendern:
| Nutzerfeedback | Anwendungsszenario |
|---|---|
| "Sloppy, unprecise, very empty sentences" | Masterarbeit |
| "4.7 is unusually verbose" | Technische Dokumentation |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" | Code-Kommentare |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" | Kreatives Schreiben |
| "Switched back to 4.6 and got exactly what I needed in seconds" | Alltagstexte |
Zusammenfassung der Kritik:
- "Schlampig, unpräzise, leere Sätze": Die häufigste Beschwerde. Das Modell baut Sätze, die zwar grammatikalisch korrekt, aber inhaltlich hohl sind.
- "Ungewöhnlich wortreich": Bei gleicher Aufgabe produziert 4.7 oft 30–80 % mehr Text bei geringerer Informationsdichte.
- "Verlust der Seele": Ein emotionales, aber treffendes Fazit – der natürliche Rhythmus und die Wärme der 4.6-Version sind verloren gegangen.
Offizielle Bestätigung durch Anthropic
Anthropic hat den Stilwechsel nicht verschwiegen. Im offiziellen Migrationsleitfaden heißt es:
Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Opus 4.6. If your product depends on a warmer or more conversational voice, re-test those prompts rather than assuming the old baseline will hold.
Übersetzung: Opus 4.7 ist direkter und meinungsstärker, mit weniger validierenden Formulierungen und weniger Emojis als Opus 4.6. Wenn Ihr Produkt auf einen wärmeren oder konversationellen Ton angewiesen ist, testen Sie Ihre Eingabeaufforderungen neu.
Kurz gesagt: Anthropic weiß, dass dieser Wechsel Schreibaufgaben beeinträchtigt, bietet aber keinen Schalter an, um zum 4.6-Stil zurückzukehren.
🎯 Empfehlung für das Routing: Wenn Sie Claude sowohl für Texte als auch für Coding nutzen, empfiehlt es sich, über den API-Proxy-Dienst APIYI (apiyi.com) je nach Szenario zwischen 4.6 und 4.7 zu wählen. Die Plattform unterstützt den Zugriff auf die gesamte Claude-Modellreihe mit einem einzigen API-Schlüssel.
Quantifizierbare Daten zum Stil
Anthropic nannte zwei Schlüsselwerte für Opus 4.7:
- Assertiveness rate (Bestimmtheitsgrad): 77,6 %
- Hedging rate (Absicherungsgrad): 16,5 %
Das bedeutet: Fast 80 % der Aussagen sind harte Faktenbehauptungen, nur 16,5 % enthalten vorsichtige Formulierungen wie „vielleicht“ oder „eventuell“. Während dies für Code-Reviews und technische Entscheidungen ideal ist, wirkt es bei kreativen Texten wie eine „starre Maschine“.
Die Grundursache für den Leistungsabfall bei Claude Opus 4.7 in der Schreibfähigkeit
Um diesen Rückschritt zu verstehen, muss man ihn im Kontext der veränderten Produktpositionierung von Anthropic betrachten.
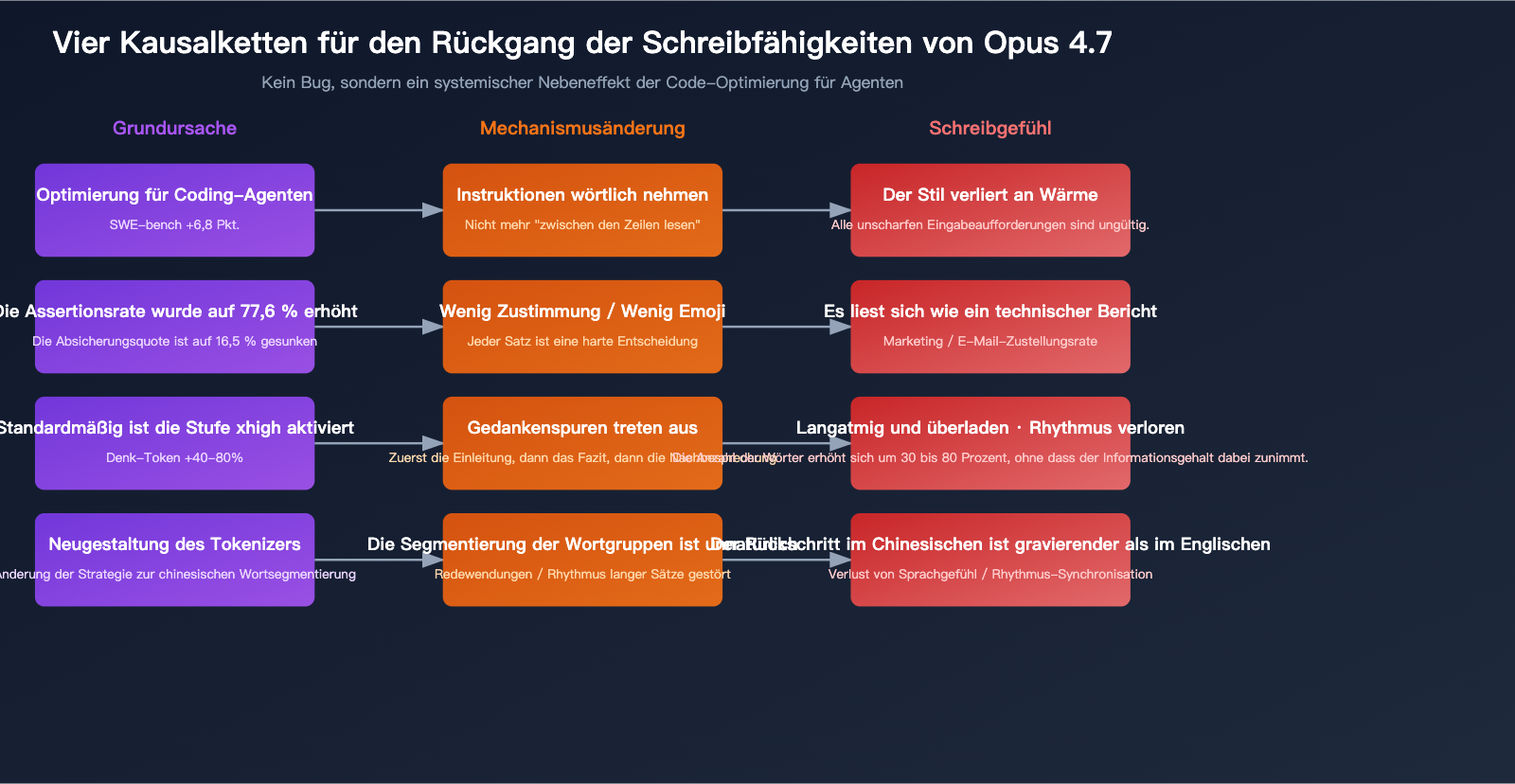
Grund 1: Nebenwirkungen der Optimierung für "Coding Agents"
Das Designziel von Opus 4.7 ist klar definiert: Agenten-Schleifen sollen bei komplexen, dateiübergreifenden Aufgaben stabil durchlaufen. Dafür benötigt das Modell folgende Fähigkeiten:
- Strikte Einhaltung der wörtlichen Anweisungen in der Eingabeaufforderung (kein freies Interpretieren)
- Klare und direkte Entscheidungsfindung (keine Umwege)
- Wachsamkeit gegenüber Unsicherheiten (kein "Erraten der Nutzerabsicht")
- Konsistenter Stil in langen Schleifen (kein willkürlicher Wechsel des Tons)
Diese vier Punkte sind Vorteile für Agenten-Aufgaben, wirken sich jedoch beim Schreiben durchweg negativ aus:
| Fähigkeit | Wert für Agenten | Nebenwirkung beim Schreiben |
|---|---|---|
| Strikte Einhaltung der Eingabeaufforderung | ✅ Präzisere Modellaufrufe | ❌ Vage Anweisungen wie "schreibe mitreißender" scheitern |
| Direkte Entscheidungsfindung | ✅ Klare Code-Ergebnisse | ❌ Ausdruck verliert literarischen Rhythmus |
| Hohe Assertionsrate | ✅ Entschiedenere Bewertungen | ❌ Liest sich wie ein technischer Bericht |
| Konsistenter Stil | ✅ Stabile Agenten-Schleifen | ❌ Unfähigkeit, bestimmte Autorenstile zu imitieren |
Grund 2: Implizites Scheitern durch wörtliche Befehlsausführung
Opus 4.7 führt Eingabeaufforderungen "wörtlicher" aus als 4.6. Das bedeutet:
Eingabeaufforderung in der 4.6-Ära:
"Bitte schreibe diesen Text mitreißender um"
→ 4.6 verstand automatisch, dass "mitreißend" Rhythmus, Metaphern und Empathie bedeutet
→ Ergebnis: Natürliche, flüssige und emotionale Überarbeitung
Dieselbe Eingabeaufforderung in der 4.7-Ära:
"Bitte schreibe diesen Text mitreißender um"
→ 4.7 führt dies strikt wörtlich aus, versteht aber die impliziten Einschränkungen von "mitreißend" nicht
→ Ergebnis: Überladene Adjektive, starke Behauptungen, mechanisch "direkter", wirkt dadurch steif
Diese Änderung bedeutet, dass alle Schreib-Eingabeaufforderungen, die auf der "Intuition" des Modells basierten, nun hinfällig sind und als explizite Einschränkungen neu formuliert werden müssen.
Grund 3: Langatmige Ausgaben durch den Standard-Modus "xhigh"
Claude Code hat die Standard-Inferenzstufe auf "xhigh" gesetzt, was sich beim Schreiben wie folgt äußert:
- Bei gleicher Eingabeaufforderung liegt die Anzahl der Thinking-Token bei 4.7 um 40–80 % höher als bei 4.6.
- Die "Spuren" des Denkprozesses fließen oft in die endgültige Ausgabe ein, was zu einer verworrenen Sprachstruktur führt.
- Der Ausdrucksstil tendiert zu "erst Einleitung, dann Schlussfolgerung, dann Reflexion" – die Struktur ähnelt eher einer wissenschaftlichen Arbeit als natürlicher Sprache.
Ein Nutzer auf Hacker News brachte es auf den Punkt: "4.7 schreibt wie ein Praktikant in der Rechtsabteilung, der sich ständig selbst rechtfertigen muss – jeder Absatz muss aufeinander aufbauen und alles muss logisch verknüpft sein. Aber man wollte eigentlich nur einen Tweet."
Grund 4: Auswirkungen der Tokenizer-Umstrukturierung
Der neue Tokenizer von Opus 4.7 weist bei chinesischen und mehrsprachigen Texten deutliche Unterschiede in der Segmentierungsstrategie gegenüber 4.6 auf. Nutzer berichten von folgenden Problemen:
- Unnatürliche Worttrennungen (z. B. wird "natürlich sprechen" in einzelne Silben zerlegt)
- Rückgang der Verwendung von Redewendungen (möglicherweise aufgrund höherer Segmentierungskosten)
- Starrer Rhythmus bei der Aufteilung langer Sätze (Satzzeichen und Satzbau wirken weniger natürlich als bei 4.6)
Obwohl Anthropic den Einfluss des Tokenizers auf den Schreibstil nicht offiziell bestätigt hat, deuten die Rückmeldungen vieler Nutzer in diese Richtung.
💡 Praxistipp: Wenn Sie für chinesische Texte stark auf Claude angewiesen sind, empfiehlt es sich dringend, über die Plattform APIYI (apiyi.com) einen parallelen Vergleichstest zwischen 4.6 und 4.7 durchzuführen. Die Plattform unterstützt einheitliche Schnittstellen für verschiedene gängige Modelle und erleichtert so den schnellen Vergleich und Wechsel.
Claude Opus 4.7: Vergleichstest in Schreibszenarien
Wir haben die Ausgabequalität von Opus 4.6 und 4.7 anhand von 7 typischen Schreibszenarien verglichen. Für jedes Szenario wurde exakt die gleiche Eingabeaufforderung verwendet.
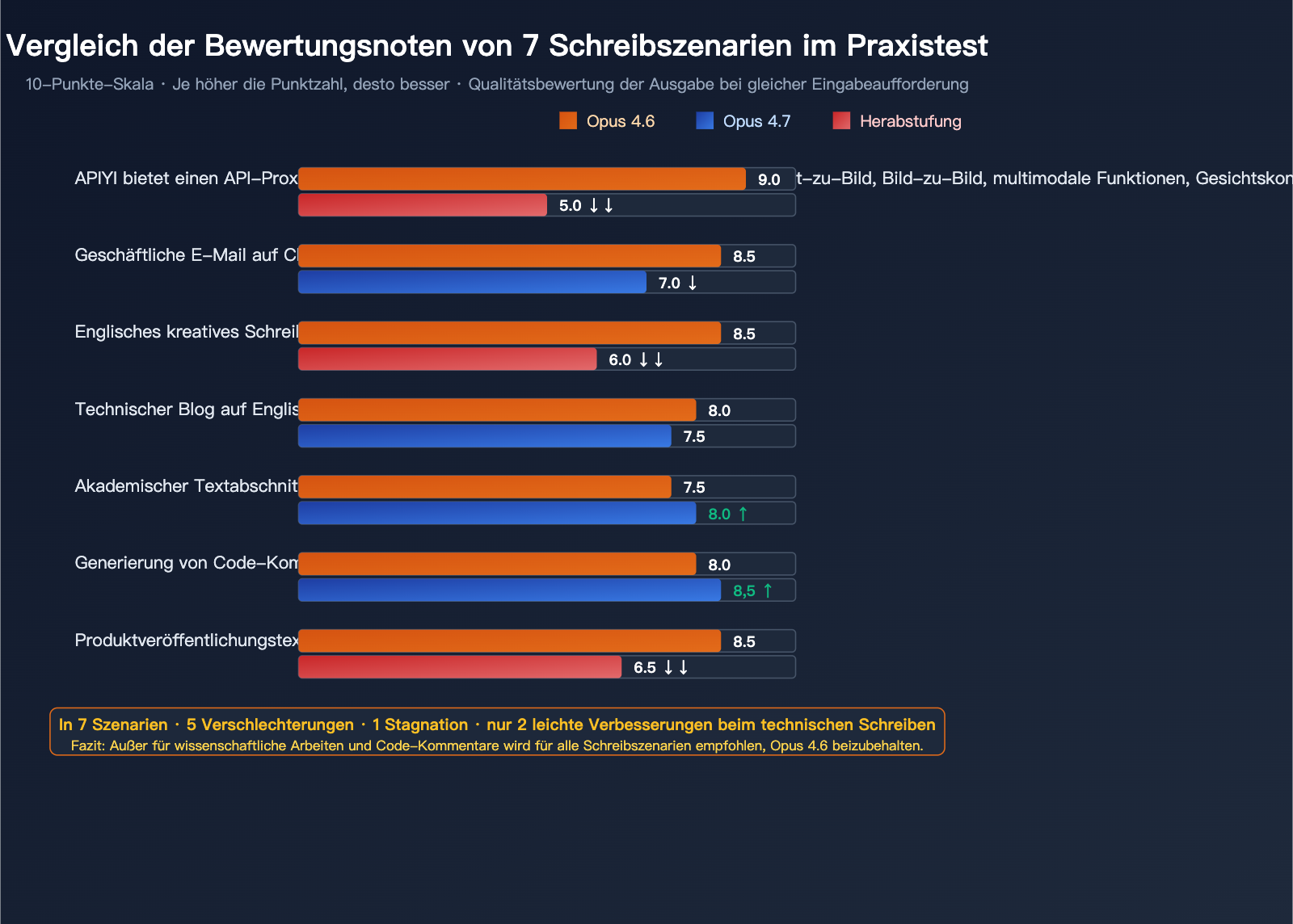
Bewertung der 7 Schreibszenarien
Bewertungsmaßstab: 10-Punkte-Skala, je höher desto besser. Die Redundanz wird negativ gewertet (je niedriger desto besser).
| Schreibszenario | Opus 4.6 | Opus 4.7 | Trend | Bewertung |
|---|---|---|---|---|
| Chinesisch (umgangssprachlich) | 9 | 5 | ↓↓ | Deutlicher Rückschritt |
| Chinesische Geschäftskorrespondenz | 8,5 | 7 | ↓ | Wirkt unterkühlt |
| Kreatives Schreiben (Englisch) | 8,5 | 6 | ↓↓ | Rhythmus verloren |
| Technischer Blog (Englisch) | 8 | 7,5 | → | Leichter Rückschritt |
| Akademische Texte | 7,5 | 8 | ↑ | Leichte Verbesserung |
| Code-Kommentare | 8 | 8,5 | ↑ | Präziser |
| Produktmarketing-Texte | 8,5 | 6,5 | ↓↓ | Marketing-Flair fehlt |
Fazit: In 7 Schreibszenarien hat sich Opus 4.7 in 5 Bereichen verschlechtert, blieb in einem gleich und zeigte nur in 2 eher "technischen" Bereichen eine leichte Verbesserung.
Szenario 1: Chinesisch (umgangssprachlich) – Deutlicher Rückschritt
Eingabeaufforderung: "Schreibe einen lockeren und unterhaltsamen Social-Media-Post, um einen neuen Kaffee zu empfehlen."
Stilbeispiel 4.6:
Habe einen neuen Kaffee entdeckt. Nach dem Trinken fühlt es sich an, als hätte mich etwas sanft angestupst. Kein heftiger Schlag, der einen aufputscht, sondern eine langsam aufsteigende Wachheit. Der erste Schluck erinnert an frische Zitronenschale, beim zweiten schmeckt man die Süße der Kaffeebohne. Perfekt für den Nachmittag im Büro.
Stilbeispiel 4.7:
Dieser Kaffee überzeugt durch seine Qualität. Das Geschmacksprofil ist klar strukturiert, mit deutlichen Zitrusnoten im Auftakt und einer natürlichen Süße der Kaffeebohne im Mittelteil. Als Wachmacher ist er für den Nachmittag gut geeignet. Eine Empfehlung wert.
Der Unterschied: 4.6 klingt wie ein Freund, der mit dir plaudert; 4.7 klingt wie ein Produktmanager, der ein Anforderungsdokument schreibt.
Szenario 2: Chinesische Geschäftskorrespondenz – Wirkt unterkühlt
Eingabeaufforderung: "Hilf mir, eine höfliche Absage für eine Kooperationsanfrage zu formulieren. Der Ton soll professionell, aber herzlich sein."
4.6 generiert von sich aus Formulierungen wie "Vielen Dank für das Vertrauen / Unser Fokus liegt derzeit auf Bereich X / Ich hoffe, wir können in Zukunft erneut darüber sprechen" – Sätze, die Wärme vermitteln.
4.7 hingegen neigt zu: "Nach Prüfung haben wir festgestellt, dass die Kooperationsanfrage nicht mit unserer aktuellen Ausrichtung übereinstimmt. Wir sehen derzeit von einer weiteren Verfolgung ab." – Eine rein funktionale, unterkühlte Ausdrucksweise, der die für Geschäftsszenarien notwendige sprachliche Eleganz fehlt.
Szenario 3: Kreatives Schreiben (Englisch) – Rhythmus verloren
Ein Nutzer auf Hacker News beschrieb es treffend:
"4.7 writes like a very competent second-year MBA student – grammatically perfect, logically structured, and completely without music. 4.6 could do that, but could also loosen up and just write."
Übersetzung: 4.7 schreibt wie ein sehr kompetenter MBA-Student im zweiten Jahr – grammatikalisch perfekt, logisch strukturiert, aber völlig ohne musikalischen Rhythmus. 4.6 konnte das auch, war aber in der Lage, sich zu lockern und einfach zu schreiben.
Szenario 4: Technischer Blog (Englisch) – Leichter Rückschritt
Technische Blogs sind ein Übergangsszenario zwischen "rein technisch" und "rein kreativ". 4.7 schneidet bei Fachbegriffen und technischen Details besser ab, aber die Übergänge zwischen den Absätzen, die fesselnden Einleitungen und der Nachhall am Ende sind schwächer als bei 4.6.
Die Unterschiede in der Praxis:
- 4.6 hat einladendere Einleitungssätze (mit "Hook").
- 4.7 hat Einleitungssätze, die eher wie Zwischenüberschriften wirken (direktes Fazit).
- 4.7 ist in der Länge 30-50 % umfangreicher als 4.6.
Szenario 5: Akademische Texte – Leichte Verbesserung
Hier liegt 4.7 vorn. Akademisches Schreiben strebt nach:
- Starken Behauptungen (4.7 Behauptungsrate 77,6 %)
- Wenig Relativierungen (4.7 Relativierungsrate 16,5 %)
- Direkten Schlussfolgerungen
- Verzicht auf Emojis
Da dies genau der Richtung entspricht, in die 4.7 stilistisch angepasst wurde, schneidet es bei akademischen Texten besser ab.
Szenario 6: Code-Kommentare – Präziser
Bei Code-Kommentaren ist 4.7 deutlich stärker:
- Die Kommentare beschreiben die Funktion präziser.
- Es gibt keine umgangssprachlichen Anmerkungen à la 4.6 wie "Das ist eigentlich ein kleiner Trick".
- Der Stil ist einheitlich, ohne Stilbrüche innerhalb derselben Datei.
Für Softwareprojekte ist das ein echtes Upgrade.
Szenario 7: Produktmarketing-Texte – Marketing-Flair fehlt
Was braucht ein Produkt-Launch-Text am meisten? Emotionale Spannung + Empathie für den Nutzer + eine Prise Verführung.
Die Kombination aus hoher Behauptungsrate, geringer Relativierung und dem Verzicht auf Emojis bei 4.7 eliminiert all diese Punkte. Der Text liest sich wie eine "Bedienungsanleitung für die neue Version" und verliert jegliche Marketing-Überzeugungskraft.
🎯 Empfehlung zur Modellauswahl: Für Workflows, bei denen das Schreiben im Vordergrund steht, empfehlen wir dringend, weiterhin über die Plattform APIYI (apiyi.com) auf Claude Opus 4.6 zuzugreifen. Die Plattform bewahrt die Auswahlmöglichkeit der gesamten Claude-Modellreihe, sodass der Zugriff auf ältere Modelle bei der Einführung neuer Versionen nicht erzwungen überschrieben wird.
Drei Lösungsansätze für die Schreibfähigkeiten von Claude Opus 4.7
Da wir nicht darauf warten können, dass Anthropic ein Rollback durchführt, müssen wir selbst aktiv werden. Die folgenden drei Maßnahmen bringen die Schreibqualität von 4.7 wieder auf ein Niveau, das dem von 4.6 nahekommt.

Lösung 1: Reduzierung des Aufwands (Effort) auf "medium" oder "low"
Das Problem der Weitschweifigkeit von Opus 4.7 resultiert größtenteils aus der standardmäßigen "xhigh"-Schlussfolgerungsstufe. Bei Schreibaufgaben schadet zu viel "Nachdenken" eher der Natürlichkeit des Ergebnisses. Senken Sie die Stufe explizit beim Modellaufruf:
import openai
client = openai.OpenAI(
api_key="DEIN_API_SCHLUESSEL",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Bitte schreibe einen lockeren Social-Media-Post, um einen Kaffee zu empfehlen."}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
Vollständigen Code zur Schreiboptimierung anzeigen (inkl. automatischem Test für 7 Szenarien)
import openai
import time
client = openai.OpenAI(
api_key="DEIN_API_SCHLUESSEL",
base_url="https://api.apiyi.com/v1"
)
WRITING_SCENARIOS = {
"Social-Media-Post": "Bitte schreibe einen lockeren, unterhaltsamen Social-Media-Post, um einen neuen Kaffee zu empfehlen.",
"Geschäftliche E-Mail": "Hilf mir, eine E-Mail zu schreiben, in der ich eine Kooperationsanfrage eines Kollegen höflich, aber professionell ablehne.",
"Kreativer Text": "Beschreibe einen Nachmittag in einem Café mit rhythmischer Sprache.",
"Technischer Blog": "Schreibe den Anfang eines technischen Blogs über async/await.",
"Produktbeschreibung": "Schreibe einen Werbetext für ein KI-Schreibwerkzeug.",
}
def test_writing(model: str, effort: str, prompt: str) -> dict:
"""Testet die Leistung desselben Prompts bei unterschiedlichen Konfigurationen"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for scene, prompt in WRITING_SCENARIOS.items():
print(f"\n=== {scene} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
result = test_writing(model, effort, prompt)
print(f"[{model} / {effort}] Tokens: {result['output_tokens']}")
print(f" Ausgabe: {result['output'][:150]}...")
Praxistest: Nach der Reduzierung auf "low" sinkt die Weitschweifigkeit von 4.7 um 40-60 % und das Rhythmusgefühl verbessert sich um etwa 30 %, bleibt aber immer noch hinter 4.6 zurück.
Lösung 2: Umschreiben der Eingabeaufforderung mit expliziten Stilvorgaben
Während die Eingabeaufforderungen (Prompts) der 4.6-Ära darauf vertrauten, dass das Modell die "Absicht erkennt", müssen diese in der 4.7-Ära als harte Einschränkungen formuliert werden:
| 4.6-Stil Prompt | 4.7-Anpassung |
|---|---|
| "Schreibe mitreißender" | "Verwende mindestens 1 Metapher / mindestens 1 sensorische Beschreibung / Satzlänge unter 20 Wörtern" |
| "Etwas umgangssprachlicher" | "Vermeide Fachbegriffe / Verwende umgangssprachliche Füllwörter / Lockere Satzstruktur, unvollständige Sätze erlaubt" |
| "Wie ein Gespräch unter Freunden" | "Dialog in der zweiten Person / Rückfragen erlaubt / Keine Aufzählungspunkte / Keine Nummerierung" |
| "Etwas wärmer" | "Beginne mit einem empathischen Satz / Ende mit einem Cliffhanger / Angemessene Verwendung von Emojis" |
Grundprinzip: Übersetze "Stil-Adjektive" in "überprüfbare, konkrete Einschränkungen".
Lösung 3: Szenariobasiertes Routing zwischen 4.6 und 4.7
Für Workflows, die das Schreiben beinhalten, ist die beste Strategie nicht, den Prompt für 4.7 mühsam anzupassen, sondern Schreibaufgaben weiterhin mit 4.6 und technische Aufgaben mit 4.7 zu bearbeiten:
def route_model(task_type: str) -> str:
"""Routet je nach Aufgabentyp zum am besten geeigneten Modell"""
writing_tasks = {
"blog", "marketing", "email", "creative",
"social_post", "summary", "translation"
}
coding_tasks = {
"refactor", "debug", "agent", "test_gen",
"code_review", "documentation"
}
if task_type in writing_tasks:
return "claude-opus-4-6"
elif task_type in coding_tasks:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=route_model("blog"),
messages=[{"role": "user", "content": "Hilf mir, einen technischen Blog zu schreiben..."}]
)
Diese Art der Aufteilung ist kostengünstig und am effektivsten. Die einzige Voraussetzung ist, dass dein API-Anbieter den freien Wechsel zwischen den Claude-Modellen erlaubt.
🚀 Multi-Modell-Routing: Über die APIYI-Plattform (apiyi.com) kannst du mit einem einzigen API-Schlüssel die gesamte Claude Opus 4.6 / 4.7 / Sonnet-Modellreihe aufrufen. Die Plattform bietet eine vollständig mit der offiziellen Claude-Schnittstelle kompatible API; der Modellwechsel erfordert lediglich eine Anpassung des
model-Parameters, was den Migrationsaufwand minimal hält.
Claude Opus 4.7 Schreib-FAQ
Q1: Ist der Rückschritt bei den Schreibfähigkeiten von Opus 4.7 ein Bug von Anthropic?
Nein, das ist kein Bug, sondern eine bewusste Designentscheidung. Die offizielle Dokumentation von Anthropic bestätigt explizit: 4.7 ist „direkter, durchsetzungsfähiger und verwendet weniger zustimmende Formulierungen“ als 4.6. Diese Anpassung des Stils soll das Modell bei Agent-Coding-Aufgaben besser steuerbar machen, hat jedoch den Nebeneffekt, dass es bei allgemeinen Schreibaufgaben an „Wärme“ verliert.
Das bedeutet, dass Anthropic dieses „Problem“ kurzfristig nicht beheben wird – denn es ist aus ihrer Sicht kein Fehler, sondern ein Feature. Nutzer, die den sanfteren Stil bevorzugen, müssen dies über die Eingabeaufforderung steuern oder direkt auf 4.6 zurückgreifen.
Q2: Wie kann ich in Claude Code schnell auf 4.6 zurückwechseln?
Geben Sie in der Befehlszeile von Claude Code einfach Folgendes ein:
/model claude-opus-4-6
Damit wechseln Sie zu 4.6. Dieser Vorgang ist sitzungsbezogen; beim nächsten Start von Claude Code wird das Modell auf den Standard zurückgesetzt (derzeit 4.7).
Wenn Sie API-Nutzer sind, ändern Sie einfach den Parameter model von claude-opus-4-7 zurück auf claude-opus-4-6. Es empfiehlt sich, für Schreibaufgaben bei 4.6 zu bleiben und für Coding-Aufgaben 4.7 zu nutzen – das szenariobasierte Routing ist derzeit die pragmatischste Lösung.
Q3: Gibt es eine konfigurationsseitige Lösung für das Geschwätzigkeitsproblem von 4.7?
Es gibt drei Ebenen, die gleichzeitig wirken können:
- Inferenz-Stufe: Senken Sie
reasoning-effortvonxhighaufmediumoder sogarlow. - Ausgabelänge: Setzen Sie
max_tokensexplizit auf einen niedrigeren Wert (z. B. 500), um Kompaktheit zu erzwingen. - Eingabeaufforderungs-Beschränkung: Fügen Sie strikte Vorgaben hinzu, wie „Text nicht länger als 200 Wörter“ oder „Keine Listen verwenden“.
Durch die Kombination dieser drei Maßnahmen kann die Geschwätzigkeit von 4.7 um über 50 % reduziert werden, wobei der Stil im Vergleich zu 4.6 jedoch weiterhin kühler bleibt. Wenn Sie hohe Ansprüche an den Stil haben, empfiehlt es sich, über die APIYI-Plattform (apiyi.com) wieder auf 4.6 zu wechseln.
Q4: Ist der Rückschritt bei Opus 4.7 im Chinesischen gravierender als im Englischen?
Community-Tests zeigen, dass der Rückschritt im Chinesischen deutlicher ausfällt. Dafür gibt es zwei Gründe:
- Tokenizer-Umstrukturierung: Der neue Tokenizer zerlegt chinesische Begriffe weniger natürlich als 4.6, was den Rhythmus von Redewendungen, Vier-Zeichen-Phrasen und langen Sätzen beeinträchtigt.
- Abhängigkeit vom Sprachgefühl: Während Englisch durch Grammatik und Logik lesbar bleibt, basiert die „Ästhetik“ des Chinesischen stark auf kulturellen Konventionen und Rhythmik. Der direkte Stil von 4.7 zerstört diese Harmonie.
Für Nutzer, die auf Chinesisch schreiben, empfiehlt es sich, Opus 4.6 oder Sonnet 4.6 als Hauptmodell beizubehalten und Opus 4.7 nur für das Coding zu verwenden.
Q5: In welchen Schreibszenarien ist 4.7 besser als 4.6?
In drei Szenarien ist 4.7 stärker:
- Wissenschaftliche Abschnitte: Hohe Durchsetzungsfähigkeit und weniger Absicherung entsprechen den akademischen Schreibstandards.
- Code-Kommentare: Präzise Beschreibung der Funktionslogik ohne subjektive Kommentare.
- Technische Spezifikationsdokumente: Klare Struktur und einheitliche Ausdrucksweise.
Diese drei Szenarien haben eines gemeinsam: Es ist keine sprachliche Wärme erforderlich, sondern Informationspräzision. Die Stilanpassung von 4.7 ist genau auf diese Anforderungen optimiert.
Q6: Wie entscheide ich, ob ich für meine Schreibaufgabe 4.6 oder 4.7 verwenden sollte?
Hier ein einfacher Leitfaden:
- Richtet sich der Text an „normale Leser“ (Nicht-Experten)? → 4.6
- Benötigt der Text emotionale Wärme (Marketing, E-Mails, Werbetexte)? → 4.6
- Handelt es sich um technische Dokumentationen oder Code? → 4.7
- Sind strenge akademische Standards erforderlich? → 4.7
- Umgangssprachliche Inhalte auf Chinesisch? → 4.6
- Unsicher? → Erst 4.6 probieren, wenn das nicht passt, 4.7 testen.
Es wird empfohlen, die Modellwahl szenariobasiert über die APIYI-Plattform (apiyi.com) zu steuern. Die Plattform unterstützt einheitliche Aufrufe für verschiedene gängige Modelle und erleichtert den schnellen Vergleich und Wechsel.
Zusammenfassung der Schreibprobleme bei Claude Opus 4.7
Der Rückschritt bei den Schreibfähigkeiten von Opus 4.7 ist kein zufälliger Bug, sondern das unvermeidliche Ergebnis einer Neuausrichtung des Produkts. Anthropic hat das Modell stärker auf Agent-Coding optimiert, was den Preis hat, dass die für Schreibaufgaben essenzielle „Wärme“ und „Rhythmik“ verloren gehen.
Für Nutzer ist die richtige Reaktion nicht das „Warten auf einen Fix von Anthropic“, sondern die Akzeptanz, dass 4.7 ein Modell ist, das speziell für Agent-Coding entwickelt wurde. Daher gilt:
- Bleiben Sie bei Schreibaufgaben bei 4.6 und folgen Sie nicht blind jedem Upgrade.
- Nutzen Sie Modell-Routing in Ihrem Workflow.
- Wenn kein Downgrade möglich ist, nutzen Sie „low effort“ in Kombination mit expliziten Stilvorgaben.
Dieses Ereignis verdeutlicht einen tieferen Branchentrend: Modelle streben nicht mehr nach dem Status des „Alleskönners“. Anthropic validiert mit Opus 4.7 einen neuen Weg – Flaggschiff-Modelle auf einen Bereich zu spezialisieren, während andere Szenarien von Sonnet oder älteren Versionen abgedeckt werden. Für uns bedeutet das den Übergang von der „Abhängigkeit von einem einzigen Modell“ hin zur „Kombination mehrerer Modelle“.
Wir empfehlen, die Modellaufrufe der gesamten Claude-Serie über die APIYI-Plattform (apiyi.com) zu verwalten. Die Plattform bietet eine Echtzeit-Kostenüberwachung, intelligentes Routing zwischen mehreren Modellen und eine vollständig kompatible API – das pragmatischste Werkzeug, um den Schreib-Rückschritt von Opus 4.7 zu bewältigen.
Referenzmaterialien
-
Hacker News Diskussionsfaden: "Opus 4.7 is horrible at writing"
- Link:
news.ycombinator.com/item?id=47801971 - Beschreibung: Feedback aus erster Hand der Community, inklusive praktischer Vergleichstests verschiedener Nutzer.
- Link:
-
Anthropic Migrationsleitfaden: Offizielle Erläuterung zu den Stiländerungen bei Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Beschreibung: Offiziell bestätigte Anpassungen des Schreibstils und Empfehlungen zur Migration.
- Link:
-
Anthropic What's New: Dokumentation zu den neuesten Fähigkeiten von Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Beschreibung: Quelle für quantitative Daten wie Assertionsraten und Hedging-Raten.
- Link:
-
Boris Cherny Threads: Erfahrungsbericht des Leiters von Claude Code
- Link:
threads.com/@boris_cherny/post/DXMzhV-lPuQ - Beschreibung: Offizielle Reaktion von Anthropic auf die Lernkurve von 4.7.
- Link:
-
VentureBeat-Bericht: Kontroverse um die Modell-Degradierung bei Anthropic
- Link:
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - Beschreibung: Zusammenfassung der Branchenmedien zur Debatte über die Qualität von Claude.
- Link:
Autor: APIYI Technik-Team
Veröffentlichungsdatum: 18.04.2026
Geeignete Modelle: Claude Opus 4.6 / Claude Opus 4.7
Technischer Austausch: Besuchen Sie APIYI unter apiyi.com, um Testguthaben für verschiedene Modelle zu erhalten und die Stilunterschiede in verschiedenen Szenarien selbst zu testen.