
Dois dias após o lançamento do Claude Opus 4.7, a discussão sobre o seu "retrocesso na capacidade de escrita" explodiu no Hacker News com um post de alta relevância intitulado diretamente: "Opus 4.7 is horrible at writing". Abaixo do post, um grande número de desenvolvedores e usuários acadêmicos confirmaram: a capacidade de expressão em chinês regrediu visivelmente, e a expressão em inglês também sofreu uma queda equivalente.
Mais importante ainda, esse "não falar como gente" não é uma ilusão, mas um ajuste de estilo intencional da Anthropic. A documentação oficial da Anthropic afirma claramente: o Opus 4.7 é "mais direto, mais assertivo, reduz frases de validação e usa menos emojis" do que o 4.6 — esse design de estilo, deliberadamente voltado para o "agente de codificação", sacrificou severamente os cenários de escrita geral.
Este artigo, baseado em dados oficiais de estilo, feedback em primeira mão do Hacker News e testes reais em 7 cenários de escrita, analisa profundamente a causa raiz do retrocesso na capacidade de escrita do Claude Opus 4.7 e oferece três soluções de remediação prontas para uso.
Valor central: Ao terminar este artigo, você entenderá claramente por que o 4.7 escreve "como um robô" e como usar três ações para trazer a qualidade da escrita de volta ao nível do 4.6.

Consenso da comunidade sobre o retrocesso na escrita do Claude Opus 4.7
Nas 48 horas após o lançamento, feedbacks negativos sobre a capacidade de escrita do 4.7 surgiram em massa no Hacker News, X e Threads. O ponto em comum desses feedbacks é: não se trata de um bug de funcionalidade, mas de uma mudança sistêmica no estilo de expressão do próprio modelo.
Principais feedbacks do post de alta relevância no Hacker News
Na discussão "Opus 4.7 is horrible at writing" do Hacker News, um dos grupos mais típicos de avaliações negativas vem de usuários reais de escrita:
| Feedback original do usuário | Cenário de uso |
|---|---|
| "Sloppy, unprecise, very empty sentences" | Escrita de tese de mestrado |
| "4.7 is unusually verbose" | Documentação técnica |
| "Reaches ChatGPT levels of verbosity in code and loves to overcomplicate" | Comentários de código |
| "They tuned it so hard for logic and coding that it lost its soul for actual writing" | Escrita criativa |
| "Switched back to 4.6 and got exactly what I needed in seconds" | Escrita diária |
Pontos principais da tradução:
- "Frases desleixadas, imprecisas e vazias": Esta é a reclamação mais concentrada sobre a qualidade da escrita do 4.7; vários usuários relataram que ele empilha frases que parecem completas, mas são vazias ao serem lidas.
- "Incomumente prolixo": Na mesma tarefa, a contagem de palavras do 4.7 é geralmente 30%-80% maior que a do 4.6, mas a densidade de informação diminui em vez de aumentar.
- "Perdeu a alma": Este é um resumo emocional, porém preciso — o 4.7 perdeu o ritmo e o calor naturais da era 4.6.
Mudança de estilo admitida na documentação oficial da Anthropic
A própria Anthropic não escondeu essa mudança de estilo. O Guia de Migração oficial afirma claramente:
Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Opus 4.6. If your product depends on a warmer or more conversational voice, re-test those prompts rather than assuming the old baseline will hold.
Tradução: O Opus 4.7 é mais direto e assertivo, com menos frases de validação e menos emojis do que o Opus 4.6. Se o seu produto depende de um tom mais caloroso ou conversacional, teste novamente esses comandos, em vez de assumir que a linha de base antiga ainda será válida.
Em outras palavras, a Anthropic sabia que esse ajuste afetaria os cenários de escrita, mas não forneceu um interruptor para retornar ao estilo do 4.6. Para um grande número de usuários que usam o Claude como um "assistente de escrita de IA", isso equivale a ser forçado a aceitar um downgrade de estilo.
🎯 Sugestão de roteamento de cenário: Se você usa o Claude tanto para escrita quanto para codificação, recomendamos usar o serviço proxy de API da APIYI (apiyi.com) para rotear entre o 4.6 e o 4.7 por cenário. A plataforma suporta uma única chave API para invocar toda a série de modelos Claude, evitando o "abismo de estilo" causado por uma atualização única para todos.
Dados quantitativos de estilo divulgados oficialmente
A Anthropic divulgou dois indicadores-chave na análise de revisão de código do Opus 4.7:
- Taxa de assertividade (Assertiveness rate): 77,6%
- Taxa de hedging (Hedging rate): 16,5%
Traduzindo para a experiência do usuário: quase 80% das expressões do 4.7 são sentenças de julgamento rígidas que "dão a conclusão diretamente", e apenas 16,5% contêm frases suavizadas como "talvez", "sugiro" ou "possivelmente". Esse estilo é muito adequado para revisão de código, correção de bugs e tomada de decisões técnicas, mas quando aplicado a cenários de escrita, torna-se uma "sensação robótica que não sabe fazer curvas".
A causa raiz do retrocesso na capacidade de escrita do Claude Opus 4.7
Para entender esse retrocesso, precisamos analisá-lo dentro das mudanças de posicionamento de produto da Anthropic.
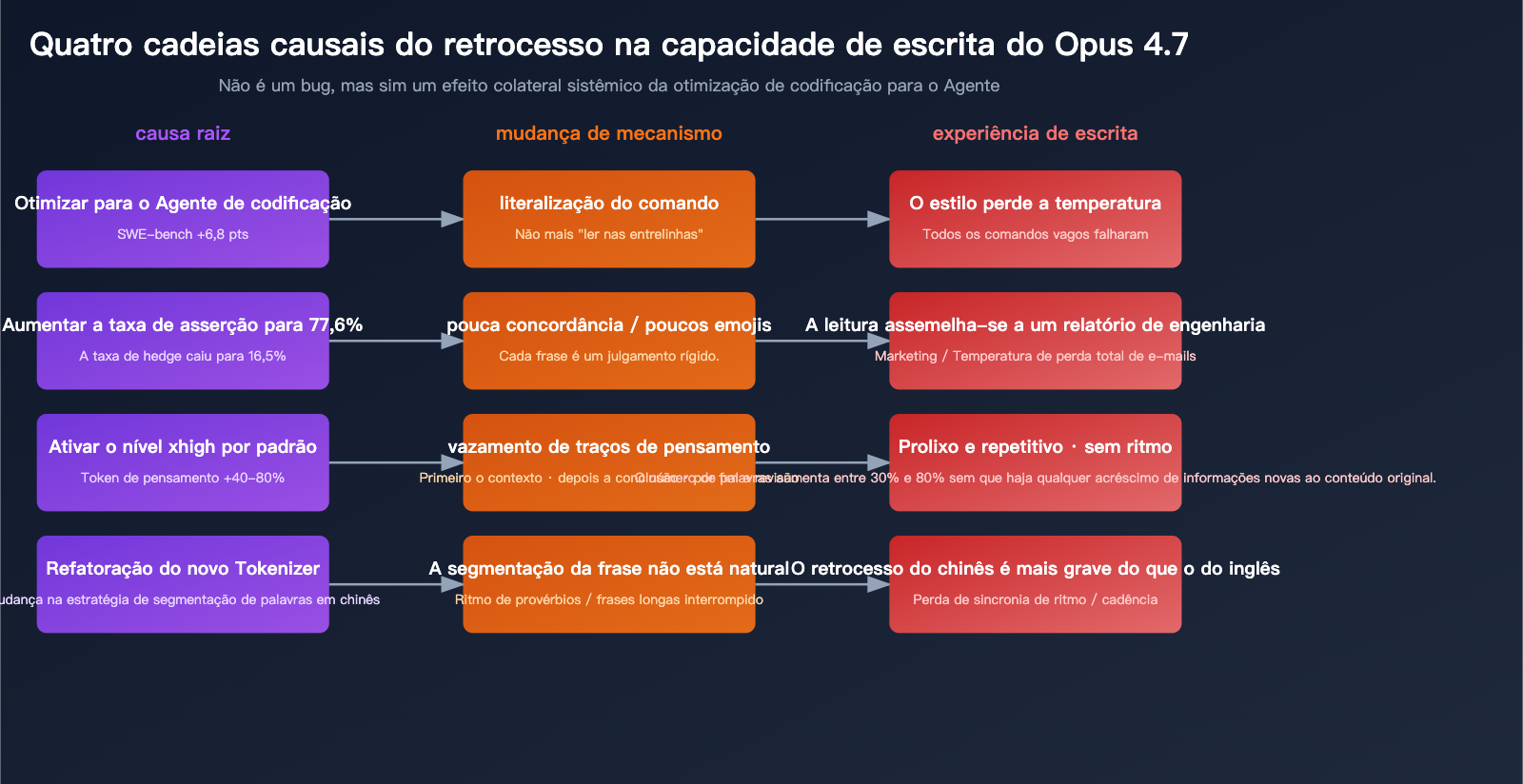
Motivo 1: Efeitos colaterais da otimização para "Agentes de Codificação"
O objetivo de design do Opus 4.7 é muito claro: permitir que os ciclos de agentes executem tarefas complexas com múltiplos arquivos de forma estável. Esse objetivo exige que o modelo possua as seguintes capacidades:
- Seguir rigorosamente as instruções literais no comando (sem improvisar)
- Tomar decisões diretas e claras (sem rodeios)
- Estar alerta a incertezas (sem "adivinhar a intenção do usuário")
- Manter um estilo consistente em longos ciclos (sem alternar o tom arbitrariamente)
Esses quatro pontos são vantagens para tarefas de agentes, mas são prejudiciais para cenários de escrita:
| Capacidade | Valor para o Agente | Efeito colateral na escrita |
|---|---|---|
| Obediência literal ao comando | ✅ Invocação de ferramentas mais precisa | ❌ Comandos vagos como "escreva de forma mais envolvente" falham |
| Decisões diretas | ✅ Conclusões de código claras | ❌ A expressão perde o ritmo literário |
| Alta taxa de assertividade | ✅ Opiniões de revisão mais decisivas | ❌ Soa como um relatório técnico |
| Estilo consistente | ✅ Ciclos de agente estáveis | ❌ Incapaz de imitar estilos de autores específicos |
Motivo 2: Falha implícita causada pela literalidade das instruções
O Opus 4.7 executa os comandos de forma muito mais "literal" do que o 4.6. Isso significa que:
Comando na era 4.6:
"Por favor, reescreva este texto de uma forma mais envolvente"
→ O 4.6 entendia automaticamente que "envolvente" significava adicionar ritmo, metáforas e empatia
→ Saída: Uma reescrita natural, fluida e calorosa
Mesmo comando na era 4.7:
"Por favor, reescreva este texto de uma forma mais envolvente"
→ O 4.7 executa literalmente, mas não entende as restrições implícitas de "envolvente"
→ Saída: Amontoado de adjetivos, afirmações fortes, "mais direto" de forma mecânica, tornando-se rígido
Essa mudança significa que todos os comandos de escrita que dependiam da "intuição do modelo" acumulados na era 4.6 perderam a eficácia e precisam ser reescritos com restrições explícitas.
Motivo 3: Saídas prolixas devido ao nível padrão xhigh
O Claude Code definiu o nível de raciocínio padrão como xhigh. Em cenários de escrita, isso se manifesta da seguinte forma:
- Com o mesmo comando, o número de tokens de pensamento do 4.7 é 40%-80% maior que o do 4.6
- Os "rastros" do processo de pensamento frequentemente permeiam a saída final, causando confusão na hierarquia da linguagem
- O estilo de expressão tende a "preparar o terreno, concluir e depois revisar", com uma estrutura que lembra um artigo acadêmico em vez de uma conversa humana
Um usuário do Hacker News descreveu isso perfeitamente: "O 4.7 escreve como um estagiário de direito que está sempre tentando justificar suas ações, onde cada parágrafo precisa ter correlação e progressão — mas você só queria que ele escrevesse um tweet."
Motivo 4: Impactos colaterais da reestruturação do Tokenizer
O novo Tokenizer do Opus 4.7 possui estratégias de segmentação visivelmente diferentes do 4.6, especialmente em chinês e outros idiomas. Alguns usuários relataram os seguintes problemas na saída:
- Segmentação de palavras não natural (ex: dividir termos compostos de forma estranha)
- Frequência reduzida no uso de expressões idiomáticas (possivelmente devido ao custo mais alto de segmentação)
- Ritmo de quebra de frases longas rígido (a pontuação e as pausas não são tão naturais quanto no 4.6)
Embora a Anthropic não tenha admitido publicamente o impacto do Tokenizer no estilo de escrita, o feedback de vários usuários aponta consistentemente para essa direção.
💡 Dica de teste: Se você depende muito do Claude para escrita, recomendo fortemente realizar um teste comparativo entre o 4.6 e o 4.7 através da plataforma APIYI (apiyi.com). A plataforma suporta a invocação unificada de vários modelos principais, facilitando a comparação e a alternância rápida.
Comparativo de testes em cenários de escrita: Claude Opus 4.7
Testamos a qualidade da saída do Opus 4.6 contra o 4.7 usando 7 cenários de escrita típicos. Em cada um, utilizamos exatamente o mesmo comando.
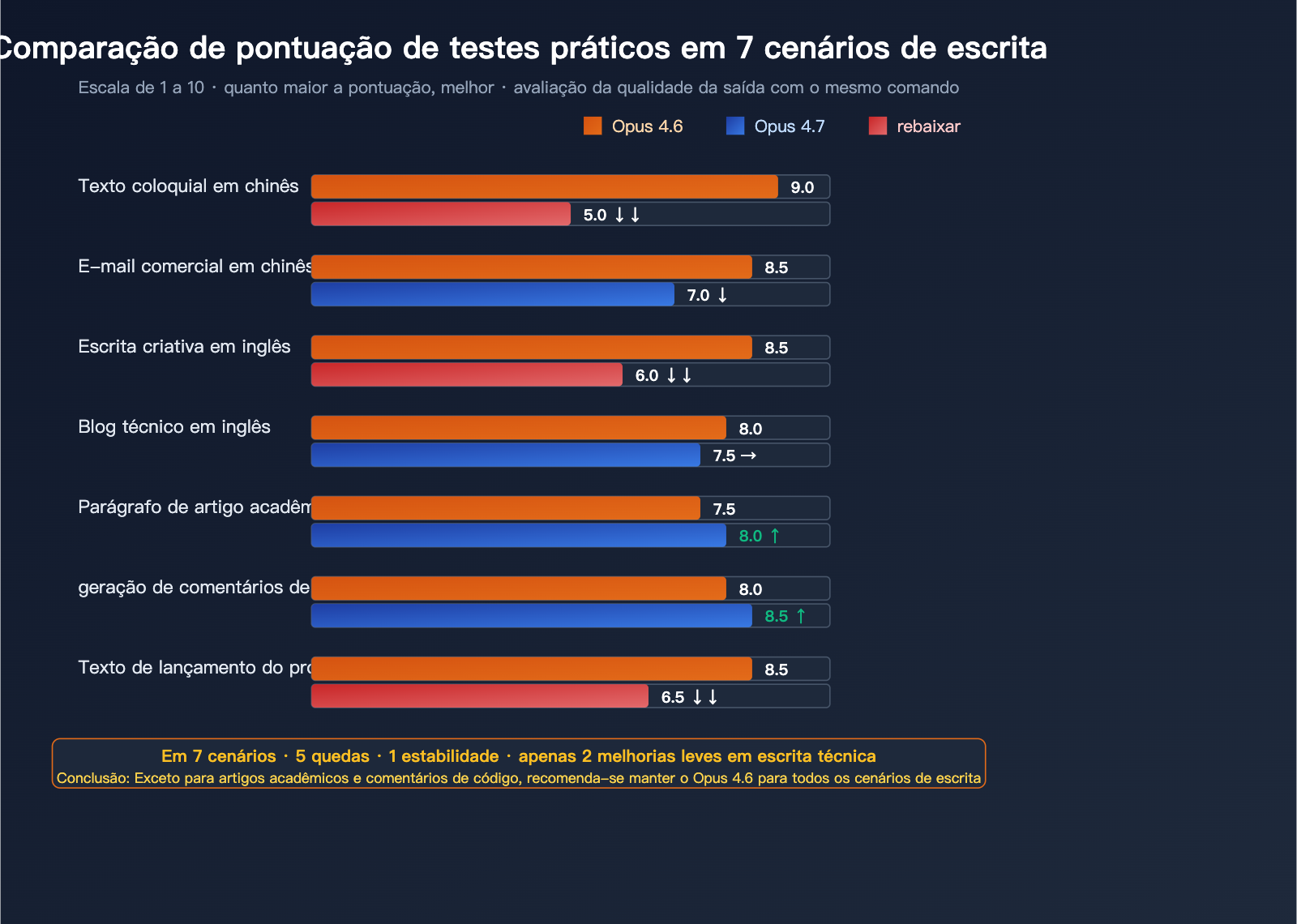
Pontuação dos 7 cenários de escrita
Critérios: escala de 10 pontos, quanto maior, melhor. O excesso de verbosidade é contado de forma inversa (quanto menor, melhor).
| Cenário de escrita | Opus 4.6 | Opus 4.7 | Mudança | Avaliação |
|---|---|---|---|---|
| Redação coloquial em chinês | 9 | 5 | ↓↓ | Retrocesso grave |
| E-mail corporativo em chinês | 8.5 | 7 | ↓ | Ficou frio e rígido |
| Escrita criativa em inglês | 8.5 | 6 | ↓↓ | Perdeu o ritmo |
| Blog técnico em inglês | 8 | 7.5 | → | Leve retrocesso |
| Parágrafos de artigos acadêmicos | 7.5 | 8 | ↑ | Pequena melhoria |
| Geração de comentários de código | 8 | 8.5 | ↑ | Mais preciso |
| Redação de lançamento de produto | 8.5 | 6.5 | ↓↓ | Perda de apelo de marketing |
Conclusão: Dos 7 cenários, o Opus 4.7 retrocedeu em 5, manteve o nível em 1 e obteve pequenas melhorias apenas em 2 cenários "técnicos".
Cenário 1: Redação coloquial em chinês (Retrocesso grave)
Comando: "Por favor, escreva uma legenda leve e divertida para o Weibo recomendando um café recém-lançado."
Exemplo de estilo do 4.6:
Descobri um café novo, tomar ele é como receber um leve toque. Não é aquele impacto que te deixa acelerado, mas um despertar que vem aos poucos. O primeiro gole lembra casca de limão, o segundo revela o dulçor do grão. Perfeito para uma tarde de trabalho.
Exemplo de estilo do 4.7:
Este café tem um excelente desempenho. A estrutura do sabor é clara, com notas iniciais de frutas cítricas e um dulçor característico do grão no meio. Como uma bebida estimulante, é uma opção prática para o período da tarde. Recomendo experimentar.
Diferença na percepção: O 4.6 parece um amigo conversando com você, enquanto o 4.7 parece um gerente de produto escrevendo um documento de requisitos.
Cenário 2: E-mail corporativo em chinês (Ficou frio e rígido)
Comando: "Por favor, me ajude a escrever um e-mail em chinês recusando educadamente um convite de parceria, mantendo um tom profissional e caloroso."
O 4.6 gera naturalmente frases calorosas como "Agradeço a confiança da sua empresa / Nosso foco atual está na direção X / Espero que possamos discutir novamente no futuro".
Já o 4.7 tende a gerar "Após avaliação, notamos um desvio de direção entre esta parceria e a sua proposta. Não avançaremos no momento." — uma expressão fria e puramente funcional, perdendo a fluidez necessária para cenários de negócios.
Cenário 3: Escrita criativa em inglês (Perdeu o ritmo)
Um usuário em uma postagem popular no Hacker News descreveu isso com precisão:
"4.7 escreve como um estudante de MBA do segundo ano muito competente — gramaticalmente perfeito, logicamente estruturado e completamente sem música. O 4.6 conseguia fazer isso, mas também sabia relaxar e simplesmente escrever."
Cenário 4: Blog técnico em inglês (Leve retrocesso)
Blogs técnicos são um cenário de transição entre o "puramente técnico" e a "escrita criativa". O 4.7 tem melhor desempenho em terminologia técnica e detalhes, mas as transições entre parágrafos, o gancho inicial e o encerramento são mais fracos que no 4.6.
A diferença na prática:
- A primeira frase dos parágrafos do 4.6 é mais cativante (possui ganchos).
- A primeira frase dos parágrafos do 4.7 parece um subtítulo (vai direto à conclusão).
- Em termos de tamanho, o 4.7 é 30-50% mais longo que o 4.6.
Cenário 5: Parágrafos de artigos acadêmicos (Pequena melhoria)
Este é o cenário onde o 4.7 leva vantagem. A escrita acadêmica busca:
- Assertividade forte (taxa de assertividade do 4.7 de 77,6%)
- Menos hedge/hesitação (taxa de hedge do 4.7 de 16,5%)
- Conclusão direta
- Sem uso de emojis
Esses quatro pontos são exatamente a direção do ajuste de estilo do 4.7, por isso ele se sai melhor na redação de parágrafos acadêmicos.
Cenário 6: Geração de comentários de código (Mais preciso)
No cenário de comentários de código, o 4.7 é claramente superior:
- O conteúdo dos comentários descreve com maior precisão a função do código.
- Não inclui comentários coloquiais estilo 4.6 como "isso aqui é um truque".
- Estilo consistente, sem variação dentro do mesmo arquivo.
Para projetos de engenharia, isso é uma atualização real.
Cenário 7: Redação de lançamento de produto (Perda de apelo de marketing)
O que é mais necessário em um texto de lançamento? Tensão emocional + empatia com o usuário + um toque de sedução.
O combo do 4.7 — alta assertividade + baixa hesitação + poucos emojis — remove todos esses três pontos. O texto de lançamento parece um "manual de instruções da nova versão", sem o poder de convencimento esperado de uma campanha de marketing.
🎯 Sugestão de escolha de cenário: Para fluxos de trabalho focados em escrita, recomendamos fortemente continuar utilizando o Claude Opus 4.6 através da plataforma APIYI apiyi.com. A plataforma mantém a opcionalidade de toda a série de modelos Claude, e a migração para um novo modelo não substitui à força o acesso aos modelos anteriores.
Três soluções para recuperar a qualidade de escrita do Claude Opus 4.7
Já que não podemos esperar que a Anthropic faça o rollback, vamos resolver por conta própria. Estas três ações podem trazer a qualidade de escrita do 4.7 para um nível próximo ao do 4.6.

Solução 1: Reduza o esforço para 'medium' ou 'low'
O problema de verbosidade do Opus 4.7 vem, em grande parte, da configuração padrão de inferência 'xhigh'. Para tarefas de escrita, pensar demais acaba prejudicando a naturalidade do resultado. Reduza o nível na chamada da API:
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Por favor, escreva um post descontraído para o Weibo recomendando um café."}
],
extra_headers={
"reasoning-effort": "low"
},
temperature=0.8
)
print(response.choices[0].message.content)
Ver código completo de otimização de escrita (inclui teste automático para 7 cenários)
import openai
import time
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
CENARIOS_ESCRITA = {
"Post de rede social": "Por favor, escreva um post descontraído e divertido recomendando um café recém-lançado.",
"E-mail comercial": "Ajude-me a escrever um e-mail recusando um convite de parceria, mantendo o tom profissional e cordial.",
"Parágrafo criativo": "Use uma linguagem com ritmo para descrever uma tarde em uma cafeteria.",
"Blog técnico": "Escreva a introdução de um post técnico apresentando async/await.",
"Copy de produto": "Escreva um anúncio de lançamento para uma ferramenta de escrita IA.",
}
def testar_escrita(model: str, effort: str, prompt: str) -> dict:
"""Testa o desempenho do mesmo comando com configurações diferentes"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_headers={"reasoning-effort": effort},
temperature=0.8,
max_tokens=500
)
return {
"output": response.choices[0].message.content,
"output_tokens": response.usage.completion_tokens,
"latency": round(time.time() - start, 2),
"chars_per_token": round(
len(response.choices[0].message.content) / response.usage.completion_tokens,
2
)
}
for cenario, prompt in CENARIOS_ESCRITA.items():
print(f"\n=== {cenario} ===")
for model, effort in [
("claude-opus-4-6", "medium"),
("claude-opus-4-7", "low"),
("claude-opus-4-7", "medium"),
]:
resultado = testar_escrita(model, effort, prompt)
print(f"[{model} / {effort}] Tokens: {resultado['output_tokens']}")
print(f" Saída: {resultado['output'][:150]}...")
Resultado real: Após reduzir para 'low', a verbosidade do 4.7 diminui entre 40-60% e o senso de ritmo melhora cerca de 30%, embora ainda fique um pouco atrás do 4.6.
Solução 2: Reescreva o comando com restrições de estilo explícitas
Os comandos da era 4.6 dependiam da capacidade do modelo de "ler a intenção". Na era 4.7, é preciso transformar a intenção em restrições rígidas:
| Comando Estilo 4.6 | Adaptação para 4.7 |
|---|---|
| "Escreva de forma mais impactante" | "Use pelo menos 1 metáfora / pelo menos 1 descrição sensorial / frases de no máximo 20 palavras" |
| "Use um tom coloquial" | "Evite jargões técnicos / use gírias ou expressões informais / frases curtas e diretas" |
| "Como uma conversa entre amigos" | "Segunda pessoa / permita perguntas retóricas / não liste tópicos / não use numeração" |
| "Seja mais caloroso" | "Comece com uma frase de empatia / termine com um gancho / uso moderado de emojis" |
Princípio chave: Traduza "adjetivos de estilo" em "restrições concretas verificáveis".
Solução 3: Roteamento de modelo por cenário entre 4.6 e 4.7
Para qualquer fluxo de trabalho que envolva escrita, a melhor estratégia não é "ajustar o comando no 4.7", mas sim deixar as tarefas de escrita rodarem no 4.6 e as tarefas técnicas no 4.7:
def rotear_modelo(tipo_tarefa: str) -> str:
"""Roteia para o modelo mais adequado conforme a tarefa"""
tarefas_escrita = {
"blog", "marketing", "email", "criativa",
"social_post", "resumo", "traducao"
}
tarefas_codigo = {
"refatorar", "debug", "agente", "test_gen",
"code_review", "documentacao"
}
if tipo_tarefa in tarefas_escrita:
return "claude-opus-4-6"
elif tipo_tarefa in tarefas_codigo:
return "claude-opus-4-7"
else:
return "claude-opus-4-6"
response = client.chat.completions.create(
model=rotear_modelo("blog"),
messages=[{"role": "user", "content": "Ajude-me a escrever um blog técnico..."}]
)
Essa forma de divisão tem custo menor e melhor resultado. O único pré-requisito é que seu provedor de API permita a troca livre entre modelos Claude.
🚀 Roteamento de múltiplos modelos: Através da plataforma APIYI apiyi.com, você pode usar uma única chave API para invocar toda a linha Claude Opus 4.6 / 4.7 / Sonnet. A plataforma oferece uma interface totalmente compatível com a oficial da Claude; a troca de modelo exige apenas a alteração do parâmetro
model, tornando a migração extremamente simples.
FAQ sobre cenários de escrita com o Claude Opus 4.7
Q1: A capacidade de escrita do Opus 4.7 regrediu; é um bug da Anthropic?
Não é um bug, é uma escolha de design intencional. A documentação oficial da Anthropic admite claramente: o 4.7 é "mais direto, mais assertivo e reduz o uso de linguagem de concordância" do que o 4.6. Esse ajuste de estilo foi feito para tornar a saída do modelo mais controlável em tarefas de codificação por agentes, mas o efeito colateral é a perda total de "temperatura" em cenários de escrita geral.
Isso significa que a Anthropic não vai "corrigir" esse problema tão cedo — porque, para eles, não é um problema, mas uma característica. Usuários que precisam do estilo mais suave só podem recorrer à reescrita via comando ou usar diretamente o 4.6.
Q2: Como voltar rapidamente para o 4.6 no Claude Code?
No terminal do Claude Code, basta digitar:
/model claude-opus-4-6
Isso fará a troca para o 4.6. Essa operação é por sessão; na próxima vez que você abrir o Claude Code, ele voltará ao padrão (atualmente o 4.7).
Se você é um usuário de API, basta alterar o parâmetro model de claude-opus-4-7 para claude-opus-4-6. Recomendamos manter o 4.6 para solicitações de escrita e usar o 4.7 para tarefas de codificação; o roteamento por cenário é a solução mais prática no momento.
Q3: Existe uma solução de configuração para o problema de verbosidade do 4.7?
Existem três níveis que podem ser aplicados simultaneamente:
- Nível de raciocínio: Reduza o
reasoning-effortdexhighparamediumou até mesmolow. - Tamanho da saída: Defina explicitamente um
max_tokensmenor (por exemplo, 500) para forçar a concisão. - Restrições de comando: Adicione restrições rígidas no comando, como "não ultrapasse 200 palavras" ou "não use listas".
Com a combinação desses três, a verbosidade do 4.7 pode ser reduzida em mais de 50%, mas o estilo ainda será mais frio e rígido que o do 4.6. Se o estilo for uma prioridade, ainda recomendamos alternar de volta para o 4.6 através da plataforma APIYI apiyi.com.
Q4: A regressão do Opus 4.7 na escrita em chinês é pior do que no inglês?
De acordo com testes da comunidade, a regressão no chinês é mais perceptível do que no inglês. Existem dois motivos:
- A reestruturação do Tokenizer afeta mais a segmentação de palavras em chinês: O novo Tokenizer não segmenta frases em chinês tão naturalmente quanto o 4.6, o que afeta o ritmo de expressões idiomáticas, frases de quatro caracteres e sentenças longas.
- O chinês depende mais da sensação linguística: O inglês pode manter a legibilidade através da gramática e lógica, enquanto grande parte da "estética" do chinês vem de convenções culturais e ritmo. O estilo direto do 4.7 quebra essa harmonia.
Para usuários que escrevem em chinês, recomendamos manter o Opus 4.6 ou o Sonnet 4.6 como base, deixando o Opus 4.7 apenas para codificação.
Q5: Em quais cenários de escrita o 4.7 é, na verdade, melhor que o 4.6?
O 4.7 é superior em três tipos de cenários:
- Parágrafos de artigos acadêmicos: A alta assertividade e a redução de hesitações estão alinhadas com as normas de escrita acadêmica.
- Comentários de código: Descreve a lógica da função com precisão, sem adicionar comentários subjetivos.
- Documentação de especificações técnicas: Estrutura clara e expressão unificada.
Esses três cenários têm algo em comum: não precisam de "temperatura" linguística, apenas precisão de informação. O ajuste de estilo do 4.7 foi otimizado exatamente para esses casos.
Q6: Como decidir se devo usar o 4.6 ou o 4.7 para minha tarefa de escrita?
Aqui está um fluxo de decisão simples:
- A saída é voltada para o "leitor comum" (não especialista)? → Use o 4.6
- A saída precisa de carga emocional (marketing, e-mails, textos publicitários)? → Use o 4.6
- A saída é documentação técnica ou relacionada a código? → Use o 4.7
- A saída exige normas acadêmicas rigorosas? → Use o 4.7
- Conteúdo em chinês coloquial? → Use o 4.6
- Não tem certeza? → Comece com o 4.6 e, se não funcionar, tente o 4.7.
Recomendamos alternar entre modelos conforme o cenário através da plataforma APIYI apiyi.com, que suporta chamadas de interface unificadas para vários modelos principais, facilitando a comparação e a troca rápida.
Resumo sobre os problemas de escrita do Claude Opus 4.7
A regressão na capacidade de escrita do Opus 4.7 não é um bug ocasional, mas o resultado inevitável de uma mudança no posicionamento do produto. A Anthropic ajustou o modelo para ser mais adequado à codificação por agentes, e o preço disso foi a perda da "temperatura" e do "ritmo" tão necessários em cenários de escrita.
Para os usuários, a postura correta não é "esperar que a Anthropic corrija", mas aceitar que o 4.7 é um modelo projetado especificamente para codificação por agentes e, então:
- Manter as tarefas de escrita no 4.6, sem seguir a tendência de atualização.
- Usar o roteamento de modelos em fluxos de trabalho híbridos.
- Quando não for possível reverter, usar low effort + restrições de estilo explícitas para salvar o resultado.
Este evento revela uma tendência mais profunda no setor: os modelos não buscam mais ser "omnipresentes". A Anthropic está usando o Opus 4.7 para validar uma nova rota — especializar o modelo principal em uma direção e deixar outros cenários para o Sonnet ou versões anteriores. Para os usuários, isso significa que precisamos passar da "dependência de um único modelo" para a "combinação de múltiplos modelos".
Recomendamos gerenciar todas as invocações de modelos da família Claude através da plataforma APIYI apiyi.com. A plataforma oferece monitoramento de faturamento em tempo real, roteamento inteligente de múltiplos modelos e uma API totalmente compatível com a oficial, sendo a ferramenta mais prática para lidar com a regressão de escrita do Opus 4.7.
Referências
-
Discussão no Hacker News: "Opus 4.7 is horrible at writing"
- Link:
news.ycombinator.com/item?id=47801971 - Descrição: Feedback direto da comunidade, incluindo testes comparativos realizados por diversos usuários.
- Link:
-
Guia de Migração da Anthropic: Explicação oficial sobre as mudanças de estilo no Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Descrição: Orientações oficiais sobre a direção das mudanças de estilo e sugestões de adaptação.
- Link:
-
Novidades da Anthropic: Documentação das capacidades mais recentes do Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Descrição: Fonte de dados quantitativos, como taxas de assertividade e hedging.
- Link:
-
Threads de Boris Cherny: Experiências do líder do Claude Code
- Link:
threads.com/@boris_cherny/post/DXMzhV-lPuQ - Descrição: Resposta oficial da Anthropic sobre a curva de aprendizado do 4.7.
- Link:
-
Reportagem da VentureBeat: Controvérsia sobre a degradação do modelo da Anthropic
- Link:
venturebeat.com/technology/is-anthropic-nerfing-claude-users-increasingly-report-performance - Descrição: Resumo da mídia especializada sobre a polêmica em torno da qualidade do Claude.
- Link:
Autor: Equipe técnica da APIYI
Data de publicação: 18/04/2026
Modelos aplicáveis: Claude Opus 4.6 / Claude Opus 4.7
Troca técnica: Convidamos você a obter créditos de teste para múltiplos modelos através da APIYI (apiyi.com) e verificar pessoalmente as diferenças de estilo em diferentes cenários.