
Lidiar con tiempos de respuesta largos al llamar al modelo Gemini 3 Flash Preview es un reto común para los desarrolladores. En este artículo, presentaremos técnicas de configuración para parámetros clave como timeout, max_tokens y thinking_level, ayudándote a dominar rápidamente métodos prácticos para optimizar la velocidad de respuesta de Gemini 3 Flash Preview.
Valor central: Al terminar de leer, habrás aprendido a controlar el tiempo de respuesta de Gemini 3 Flash Preview mediante una configuración adecuada de parámetros, logrando una mejora significativa en la velocidad sin comprometer la calidad de la salida.

Análisis de las causas del largo tiempo de respuesta en Gemini 3 Flash Preview
Antes de profundizar en los trucos de optimización, debemos entender por qué Gemini 3 Flash Preview a veces tarda tanto en responder.
Mecanismo de Tokens de Pensamiento (Thinking Tokens)
Gemini 3 Flash Preview utiliza un mecanismo de pensamiento dinámico, que es la razón principal del aumento en el tiempo de respuesta:
| Factor de influencia | Descripción | Impacto en el tiempo de respuesta |
|---|---|---|
| Tareas de razonamiento complejo | Las preguntas que requieren razonamiento lógico necesitan más Tokens de pensamiento | Aumenta significativamente el tiempo de respuesta |
| Profundidad de pensamiento dinámica | El modelo ajusta automáticamente la cantidad de pensamiento según la complejidad de la pregunta | Rápido para preguntas simples, lento para las complejas |
| Salida no fluida (non-streaming) | En el modo no fluido, hay que esperar a que se complete toda la generación | El tiempo de espera total es mayor |
| Cantidad de Tokens de salida | Cuanto más contenido se complete, más tiempo tardará la generación | Aumenta el tiempo de respuesta de forma lineal |
Según los datos de prueba de Artificial Analysis, Gemini 3 Flash Preview puede utilizar hasta aproximadamente 160 millones de tokens en su nivel de pensamiento más alto, lo cual es más del doble que Gemini 2.5 Flash. Esto significa que en tareas complejas, el modelo consume una gran cantidad de "tiempo de pensamiento".
Análisis de caso real
Según los comentarios de los usuarios, cuando una tarea requiere rapidez en el tiempo de respuesta pero no una precisión extremadamente alta, la configuración predeterminada de Gemini 3 Flash Preview puede no ser ideal:
"Debido a que la tarea tiene requisitos de velocidad para el tiempo de respuesta y los requisitos de precisión no son altos, el razonamiento de gemini-3-flash-preview resulta muy largo"
La causa fundamental de esta situación es:
- El modelo utiliza pensamiento dinámico por defecto y realiza un razonamiento profundo automáticamente.
- La cantidad de tokens completados puede llegar a más de 7000.
- Además, hay que considerar los tokens de pensamiento consumidos durante el proceso de razonamiento.
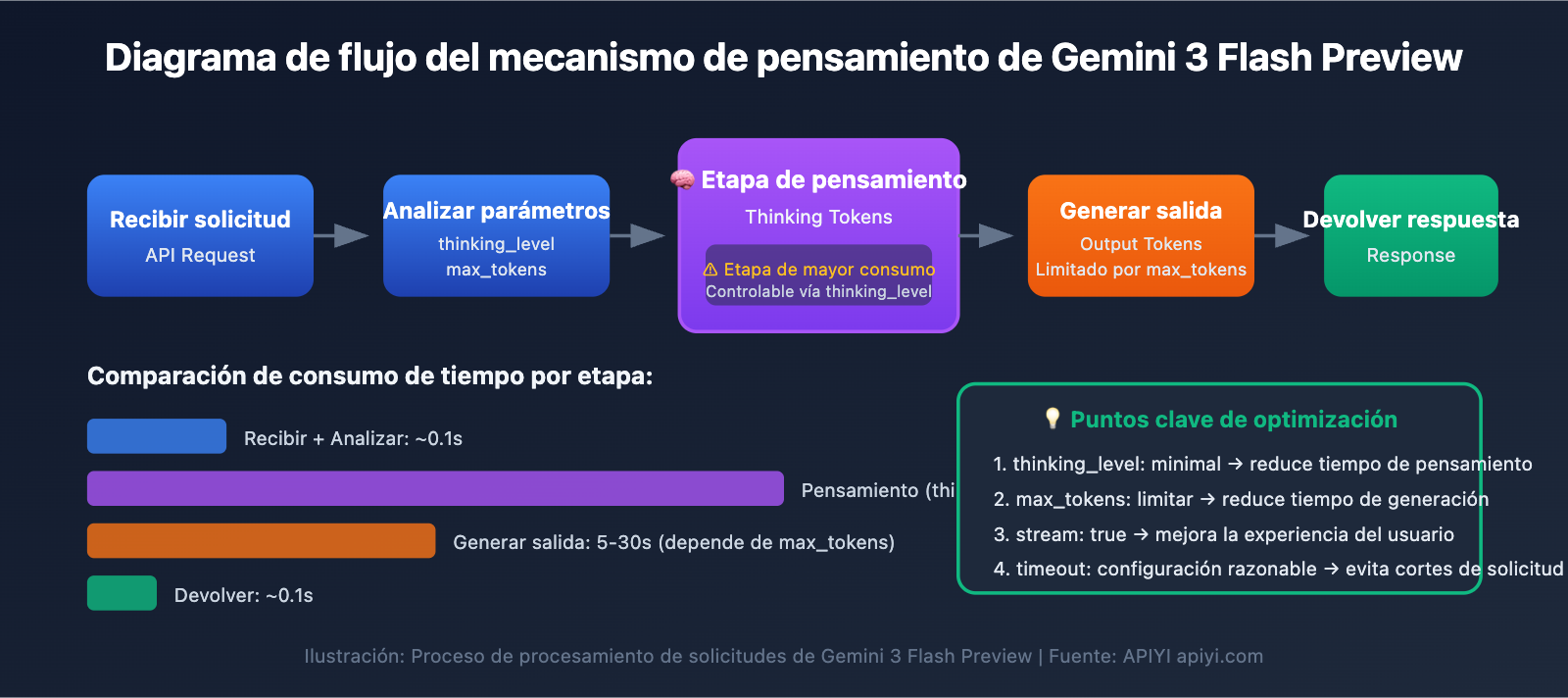
Puntos clave de optimización de la velocidad de respuesta en Gemini 3 Flash Preview
| Punto de optimización | Descripción | Efecto esperado |
|---|---|---|
| Configurar thinking_level | Controla la profundidad de razonamiento del modelo | Reduce el tiempo de respuesta entre un 30% y un 70% |
| Limitar max_tokens | Controla la longitud de la salida | Reduce el tiempo de generación |
| Ajustar el timeout | Establece un tiempo de espera razonable | Evita que la solicitud se interrumpa inesperadamente |
| Usar salida por streaming | Devuelve resultados a medida que se generan | Mejora la experiencia del usuario |
| Elegir el escenario adecuado | Usa niveles de pensamiento bajos para tareas sencillas | Aumento de la eficiencia general |
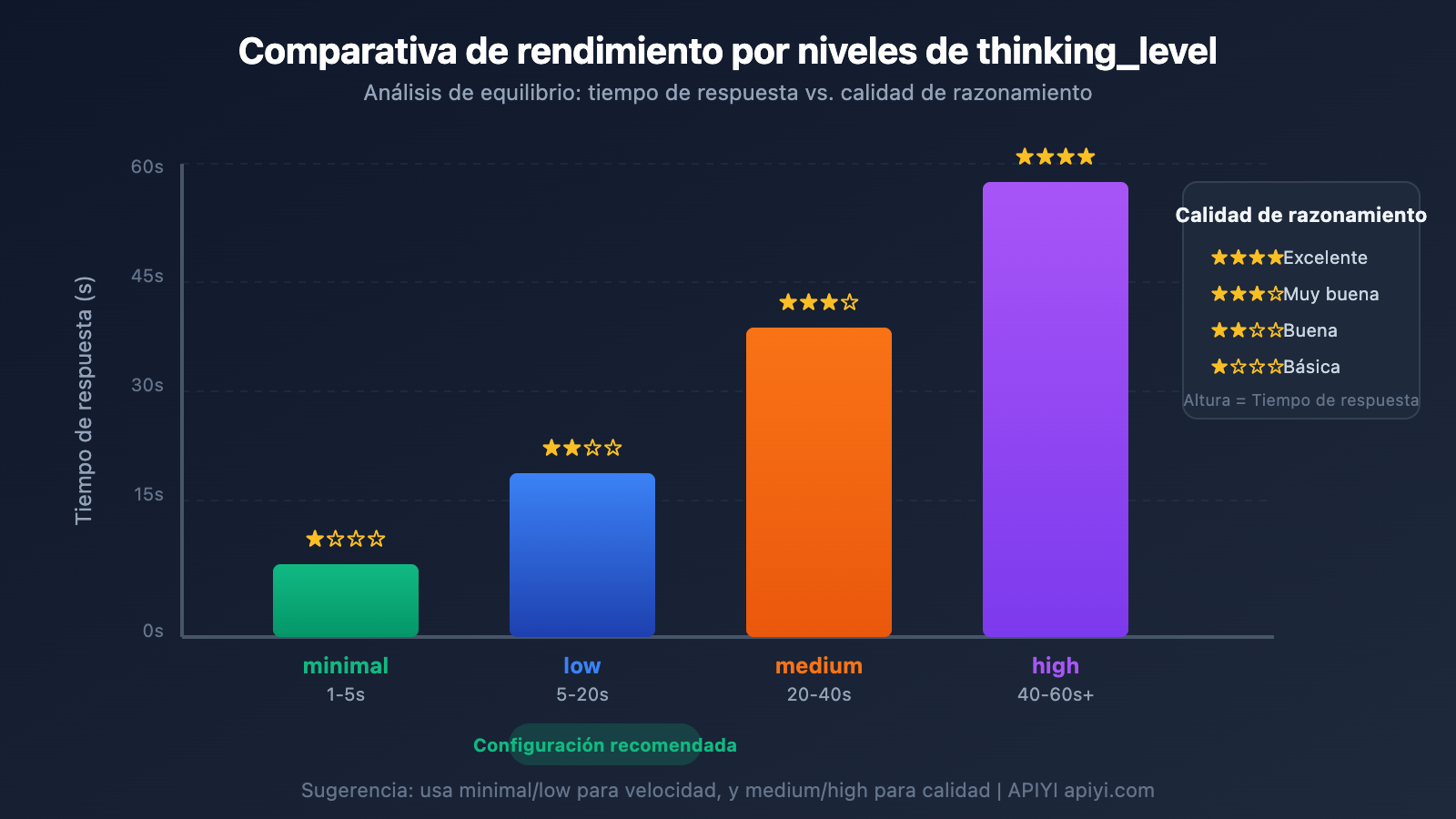
Detalles del parámetro thinking_level
Gemini 3 introduce el parámetro thinking_level, que es la configuración más crítica para controlar la velocidad de respuesta:
| thinking_level | Escenarios de uso | Velocidad de respuesta | Calidad de razonamiento |
|---|---|---|---|
| minimal | Conversaciones simples, respuestas rápidas | La más rápida ⚡ | Básica |
| low | Tareas cotidianas, razonamiento ligero | Rápida | Buena |
| medium | Tareas de complejidad media | Media | Muy buena |
| high | Razonamiento complejo, análisis profundo | Lenta | Óptima |
🎯 Sugerencia técnica: Si tu tarea no requiere una precisión extrema pero sí una respuesta rápida, te sugerimos configurar
thinking_levelcomominimalolow. Recomendamos usar la plataforma APIYI (apiyi.com) para realizar pruebas comparativas con diferentes niveles dethinking_levely encontrar rápidamente la configuración que mejor se adapte a tu caso de uso.
Estrategia de configuración del parámetro max_tokens
Limitar el max_tokens permite controlar eficazmente la longitud de la salida, reduciendo así el tiempo de respuesta:
Cantidad de tokens de salida → Influye directamente en el tiempo de generación
A mayor cantidad de tokens → Mayor tiempo de respuesta
Sugerencias de configuración:
- Escenario de respuestas breves: Configurar
max_tokensentre 500 y 1000. - Generación de contenido medio: Configurar
max_tokensentre 2000 y 4000. - Salida de contenido completo: Configurar según las necesidades reales, pero ojo con el riesgo de timeout.
⚠️ Atención: Si el max_tokens es demasiado corto, la salida se cortará, afectando la integridad de la respuesta. Es necesario equilibrar la velocidad y la completitud según las necesidades de tu negocio.
Guía rápida para optimizar la velocidad de respuesta en Gemini 3 Flash Preview
Ejemplo minimalista
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Uso de la interfaz unificada de APIYI
)
# Configuración priorizando la velocidad
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "Explica brevemente qué es la inteligencia artificial"}],
max_tokens=1000, # Limitar la longitud de salida
extra_body={
"thinking_level": "minimal" # Mínima profundidad de pensamiento, respuesta más rápida
},
timeout=30 # Establecer un timeout de 30 segundos
)
print(response.choices[0].message.content)
Ver código completo – Incluye varios escenarios de configuración
import openai
from typing import Literal
def create_gemini_client(api_key: str):
"""Crear cliente para Gemini 3 Flash"""
return openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Uso de la interfaz unificada de APIYI
)
def call_gemini_optimized(
client: openai.OpenAI,
prompt: str,
thinking_level: Literal["minimal", "low", "medium", "high"] = "low",
max_tokens: int = 2000,
timeout: int = 60,
stream: bool = False
):
"""
Llamada optimizada a Gemini 3 Flash
Parámetros:
client: Cliente OpenAI
prompt: Entrada del usuario (indicación)
thinking_level: Profundidad de razonamiento (minimal/low/medium/high)
max_tokens: Número máximo de tokens de salida
timeout: Tiempo de espera (segundos)
stream: Si se usa salida por streaming
"""
params = {
"model": "gemini-3-flash-preview",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": stream,
"extra_body": {
"thinking_level": thinking_level
},
"timeout": timeout
}
if stream:
# Streaming - Mejora la experiencia del usuario
response = client.chat.completions.create(**params)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print() # Salto de línea
return full_content
else:
# Sin streaming - Retorno de una sola vez
response = client.chat.completions.create(**params)
return response.choices[0].message.content
# Ejemplo de uso
if __name__ == "__main__":
client = create_gemini_client("YOUR_API_KEY")
# Escenario 1: Prioridad de velocidad - Preguntas y respuestas simples
print("=== Configuración de prioridad de velocidad ===")
result = call_gemini_optimized(
client,
prompt="Explica en una frase qué es el aprendizaje automático",
thinking_level="minimal",
max_tokens=500,
timeout=15
)
print(f"Respuesta: {result}\n")
# Escenario 2: Configuración equilibrada - Tareas cotidianas
print("=== Configuración equilibrada ===")
result = call_gemini_optimized(
client,
prompt="Lista 5 buenas prácticas para el procesamiento de datos con Python",
thinking_level="low",
max_tokens=1500,
timeout=30
)
print(f"Respuesta: {result}\n")
# Escenario 3: Prioridad de calidad - Análisis complejo
print("=== Configuración de prioridad de calidad ===")
result = call_gemini_optimized(
client,
prompt="Analiza las innovaciones clave de la arquitectura Transformer y su impacto en el NLP",
thinking_level="high",
max_tokens=4000,
timeout=120
)
print(f"Respuesta: {result}\n")
# Escenario 4: Streaming - Mejora la experiencia
print("=== Salida por streaming ===")
result = call_gemini_optimized(
client,
prompt="Presenta las características principales de Gemini 3 Flash",
thinking_level="low",
max_tokens=2000,
timeout=60,
stream=True
)
🚀 Comienzo rápido: Te recomendamos usar la plataforma APIYI (apiyi.com) para probar rápidamente diferentes configuraciones de parámetros. Esta plataforma ofrece interfaces API listas para usar y compatibles con el Modelo de Lenguaje Grande Gemini 3 Flash Preview, lo que facilita la validación rápida de las optimizaciones.
Guía de configuración de parámetros para optimizar la velocidad de respuesta en Gemini 3 Flash Preview
Configuración del tiempo de espera (timeout)
Cuando usas Gemini 3 Flash Preview para tareas de razonamiento complejo, el tiempo de espera por defecto puede no ser suficiente. Aquí tienes una estrategia de configuración de timeout recomendada:
| Tipo de tarea | timeout recomendado | Descripción |
|---|---|---|
| Preguntas y respuestas simples | 15-30 segundos | Úsalo con un thinking_level minimal |
| Tareas cotidianas | 30-60 segundos | Úsalo con un thinking_level low/medium |
| Análisis complejo | 60-120 segundos | Úsalo con un thinking_level high |
| Generación de textos largos | 120-180 segundos | Escenarios con una gran cantidad de Tokens de salida |
Consejos clave:
- En el modo de salida que no es por flujo (non-streaming), el sistema espera a que se genere todo el contenido antes de devolverlo.
- Si configuras un
timeoutdemasiado corto, la solicitud podría cortarse antes de terminar. - Te sugerimos ajustar el tiempo de forma dinámica según la cantidad de Tokens esperados y el
thinking_levelelegido.
Migración de thinking_budget (antiguo) a thinking_level (nuevo)
Google recomienda migrar del antiguo parámetro thinking_budget al nuevo thinking_level:
| thinking_budget (antiguo) | thinking_level (nuevo) | Notas de migración |
|---|---|---|
| 0 | minimal | Pensamiento mínimo; ten en cuenta que aún se debe procesar la firma de pensamiento. |
| 1-1000 | low | Pensamiento ligero. |
| 1001-5000 | medium | Pensamiento moderado. |
| 5001+ | high | Pensamiento profundo. |
⚠️ Atención: No utilices thinking_budget y thinking_level en la misma solicitud, ya que esto puede causar comportamientos inesperados.
Escenario de configuración para la optimización de la velocidad de respuesta en Gemini 3 Flash Preview
Escenario 1: Tareas sencillas de alta frecuencia (Prioridad: Velocidad)
Ideal para chatbots, preguntas y respuestas rápidas, resúmenes de contenido y otros escenarios sensibles a la latencia:
# 速度优先配置
config_speed_first = {
"thinking_level": "minimal",
"max_tokens": 500,
"timeout": 15,
"stream": True # 流式输出改善体验
}
Efecto esperado:
- Tiempo de respuesta: 1-5 segundos
- Adecuado para conversaciones simples y respuestas rápidas
Escenario 2: Tareas comerciales diarias (Configuración equilibrada)
Adecuado para generación de contenido, asistencia de código, procesamiento de documentos y otras tareas rutinarias:
# 平衡配置
config_balanced = {
"thinking_level": "low",
"max_tokens": 2000,
"timeout": 45,
"stream": True
}
Efecto esperado:
- Tiempo de respuesta: 5-20 segundos
- Un buen equilibrio entre calidad y velocidad
Escenario 3: Tareas de análisis complejo (Prioridad: Calidad)
Ideal para análisis de datos, diseño de soluciones técnicas, investigación profunda y otros escenarios que requieren un razonamiento exhaustivo:
# 质量优先配置
config_quality_first = {
"thinking_level": "high",
"max_tokens": 8000,
"timeout": 180,
"stream": True # 长任务建议用流式
}
Efecto esperado:
- Tiempo de respuesta: 30-120 segundos
- Calidad de razonamiento óptima
Tabla de decisión para la selección de configuración
| Tu necesidad | thinking_level recomendado | max_tokens recomendado | timeout recomendado |
|---|---|---|---|
| Respuesta rápida, pregunta sencilla | minimal | 500-1000 | 15-30s |
| Tareas diarias, calidad estándar | low | 1500-2500 | 30-60s |
| Mejor calidad, tiempo de espera aceptable | medium | 2500-4000 | 60-90s |
| Calidad máxima, tareas complejas | high | 4000-8000 | 120-180s |
💡 Sugerencia de selección: La elección de la configuración depende principalmente de tu caso de uso específico y tus requisitos de calidad. Recomendamos realizar pruebas reales a través de la plataforma APIYI (apiyi.com) para tomar la decisión que mejor se adapte a tus necesidades. Esta plataforma admite llamadas de interfaz unificada para Gemini 3 Flash Preview, lo que facilita comparar rápidamente los efectos de diferentes configuraciones.
Técnicas avanzadas para optimizar la velocidad de respuesta en Gemini 3 Flash Preview
Consejo 1: Usar salida en streaming para mejorar la experiencia del usuario
Incluso si el tiempo total de respuesta no cambia, la salida en streaming (flujo) mejora significativamente la percepción de velocidad del usuario:
# 流式输出示例
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
stream=True,
extra_body={"thinking_level": "low"}
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Ventajas:
- El usuario puede ver resultados parciales de inmediato.
- Reduce la "ansiedad de espera".
- Permite decidir si continuar con la generación mientras se procesa.
Consejo 2: Ajustar dinámicamente los parámetros según la complejidad de la entrada
def estimate_complexity(prompt: str) -> str:
"""根据 prompt 特征估算任务复杂度"""
indicators = {
"high": ["分析", "对比", "为什么", "原理", "深入", "详细解释"],
"medium": ["如何", "步骤", "方法", "介绍"],
"low": ["是什么", "简单", "快速", "一句话"]
}
prompt_lower = prompt.lower()
for level, keywords in indicators.items():
if any(kw in prompt_lower for kw in keywords):
return level
return "low" # 默认低复杂度
def get_optimized_config(prompt: str) -> dict:
"""根据 prompt 获取优化配置"""
complexity = estimate_complexity(prompt)
configs = {
"low": {"thinking_level": "minimal", "max_tokens": 1000, "timeout": 20},
"medium": {"thinking_level": "low", "max_tokens": 2500, "timeout": 45},
"high": {"thinking_level": "medium", "max_tokens": 4000, "timeout": 90}
}
return configs.get(complexity, configs["low"])
Consejo 3: Implementar un mecanismo de reintento de solicitudes
Para problemas ocasionales de tiempo de espera, puedes implementar un sistema de reintentos inteligente:
import time
from typing import Optional
def call_with_retry(
client,
prompt: str,
max_retries: int = 3,
initial_timeout: int = 30
) -> Optional[str]:
"""带重试机制的调用"""
for attempt in range(max_retries):
try:
timeout = initial_timeout * (attempt + 1) # 递增超时
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
timeout=timeout,
extra_body={"thinking_level": "low"}
)
return response.choices[0].message.content
except Exception as e:
print(f"尝试 {attempt + 1} 失败: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数退避
continue
return None

Referencia de datos de rendimiento de Gemini 3 Flash Preview
Según los datos de prueba de Artificial Analysis, el rendimiento de Gemini 3 Flash Preview es el siguiente:
| Métricas de rendimiento | Valor | Descripción |
|---|---|---|
| Rendimiento bruto (Throughput) | 218 tokens/seg | Velocidad de salida |
| Comparado con 2.5 Flash | 22% más lento | Debido a la mayor capacidad de razonamiento |
| Comparado con GPT-5.1 high | 74% más rápido | 125 tokens/seg |
| Comparado con DeepSeek V3.2 | 627% más rápido | 30 tokens/seg |
| Precio de entrada | $0.50 / 1M tokens | |
| Precio de salida | $3.00 / 1M tokens |
Equilibrio entre rendimiento y costo
| Configuración | Velocidad de respuesta | Consumo de tokens | Costo-beneficio |
|---|---|---|---|
| minimal thinking | La más rápida | Mínimo | Máximo |
| low thinking | Rápida | Bajo | Alto |
| medium thinking | Media | Medio | Medio |
| high thinking | Lenta | Alto | Ideal para priorizar la calidad |
💰 Optimización de costos: Para proyectos con presupuesto ajustado, puedes considerar llamar a la API de Gemini 3 Flash Preview a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece métodos de facturación flexibles que, combinados con las técnicas de optimización de velocidad de este artículo, te permiten obtener la mejor relación calidad-precio controlando los costos.
Preguntas frecuentes sobre la optimización de la velocidad de respuesta en Gemini 3 Flash Preview
Q1: ¿Por qué la respuesta sigue siendo lenta si configuré el límite de max_tokens?
El parámetro max_tokens solo limita la longitud de la salida, no afecta el proceso de pensamiento del modelo. Si la respuesta es lenta debido principalmente al tiempo de razonamiento, necesitas ajustar simultáneamente el parámetro thinking_level a minimal o low. Además, a través de la plataforma APIYI (apiyi.com) puedes obtener un servicio de API estable que, junto con las técnicas de configuración de parámetros de este artículo, mejorará eficazmente la velocidad de respuesta.
Q2: ¿Configurar thinking_level en minimal afectará la calidad de la respuesta?
Tendrá cierto impacto, pero para tareas sencillas no es muy notable. El nivel minimal es ideal para sesiones de preguntas y respuestas rápidas o diálogos simples. Si la tarea implica un razonamiento lógico complejo, se recomienda usar los niveles low o medium. Te sugerimos realizar pruebas A/B en la plataforma APIYI (apiyi.com) para comparar la calidad de salida con diferentes niveles de thinking_level y encontrar el punto de equilibrio ideal para tu negocio.
Q3: ¿Qué es más rápido, la salida en streaming (flujo) o la salida normal?
El tiempo total de generación es el mismo, pero la experiencia de usuario con la salida en streaming es mucho mejor. En el modo streaming, el usuario puede ver partes del resultado de inmediato, mientras que el modo sin streaming requiere esperar a que se complete toda la generación. Para tareas con tiempos de generación prolongados, se recomienda encarecidamente usar la salida en streaming.
Q4: ¿Cómo puedo determinar cuánto tiempo debe durar el timeout?
El timeout debe configurarse según la longitud de salida esperada y el thinking_level:
- minimal + 1000 tokens: 15-30 segundos
- low + 2000 tokens: 30-60 segundos
- medium + 4000 tokens: 60-90 segundos
- high + 8000 tokens: 120-180 segundos
Se recomienda probar primero con un timeout largo para medir el tiempo de respuesta real y luego ajustarlo en consecuencia.
Q5: ¿Se puede seguir usando el antiguo parámetro thinking_budget?
Sí, puedes seguir usándolo, pero Google recomienda migrar al parámetro thinking_level para obtener un rendimiento más predecible. Ten cuidado de no usar ambos parámetros en la misma solicitud. Si antes usabas thinking_budget=0, al migrar deberías configurar thinking_level="minimal".
Resumen
El núcleo de la optimización de la velocidad de respuesta en Gemini 3 Flash Preview reside en la configuración adecuada de tres parámetros clave:
- thinking_level: Elige la profundidad de pensamiento adecuada según la complejidad de la tarea.
- max_tokens: Limita la cantidad de tokens basándote en la longitud de salida esperada.
- timeout: Establece un tiempo de espera razonable de acuerdo con el
thinking_levely el volumen de salida.
Para escenarios donde "la tarea requiere rapidez en el tiempo de respuesta y la precisión no es la prioridad absoluta", recomendamos la siguiente configuración:
- thinking_level:
minimalolow - max_tokens: Configúralo según tus necesidades reales para evitar una longitud excesiva.
- timeout: Ajústalo en consecuencia para evitar que la respuesta se corte (truncado).
- stream:
True(mejora significativamente la experiencia del usuario).
Te recomendamos probar rápidamente diferentes combinaciones de parámetros a través de APIYI (apiyi.com) para encontrar la configuración que mejor se adapte a tu caso de uso específico.
Palabras clave: Gemini 3 Flash Preview, optimización de velocidad de respuesta, thinking_level, max_tokens, configuración de timeout, optimización de llamadas API.
Referencias:
- Documentación oficial de Google AI: ai.google.dev/gemini-api/docs/gemini-3
- Google DeepMind: deepmind.google/models/gemini/flash/
- Pruebas de rendimiento de Artificial Analysis: artificialanalysis.ai/articles/gemini-3-flash-everything-you-need-to-know
Este artículo fue redactado por el equipo técnico de APIYI Team. Para más consejos sobre el uso de modelos de IA, visita help.apiyi.com